
Amazon AppFlowを使ってコードを書かずにSalesforceへのリバースETLをやってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部インテグレーション部機械学習チーム・新納(にいの)です。
本記事はJapan AWS Top Engineers Advent Calendar 2024の24日目のエントリです。
先日、AWS Glueを使ったSalesforceへのリバースETLについて記事を書きました。
Glueだけでなく、Amazon AppFlowもSaleforceへのリバースETLが可能です。今回はAppFLowを使ったケースを試してみました。
リバースETLとは
通常のETLはSalesforceなどのSaaSサービスなどからデータウェアハウスにデータを集める仕組みです。一方、リバースETLは、データウェアハウスで分析したデータを再びSalesforceに戻す仕組みを指します。
例えば、データウェアハウスで算出した顧客の生涯価値(LTV)スコアや解約リスク予測などの分析結果を、Salesforceの顧客レコードに自動で反映させることができます。これにより、営業担当者は顧客データをより効果的に活用し、データに基づいた適切な対応が可能になります。
おさらい:Amazon AppFlowとは
Amazon AppFlowとは、SaaSサービスのデータをAmazon RedshiftやAmazon S3といったAWSサービスや、SnowflakeやSalesforceなどに転送できるフルマネージドなデータ統合サービスです。
多種多様なデータソースに接続でき、さらにマネジメントコンソールからGUIベースで設定をすれば、サーバーレスなデータパイプラインがすぐに出来上がるという優れものです。
想定シナリオ
以下の記事と同様のシナリオで進めます。
全体図は以下の通り。
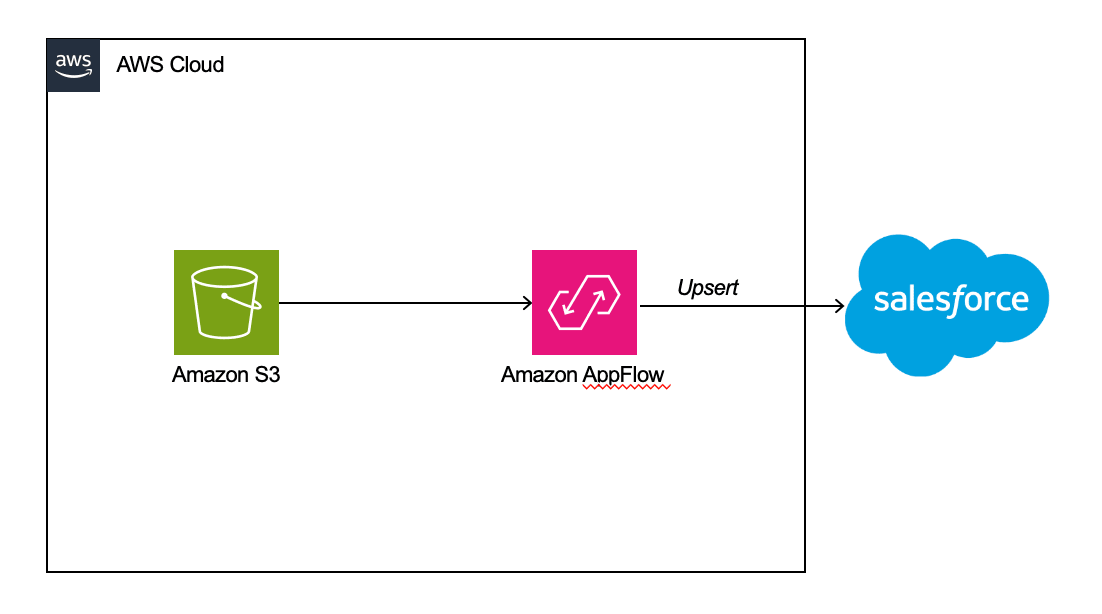
- Salesforceの取引先オブジェクトの評価(Hot/Warm/Cold)をアップデートする
- 顧客分析の結果、取引先の評価を定期的にアップデートしたい
- 対応するIDと評価はCSVファイルでS3バケットに連携される
- CSVファイルをAppFlowを使ってSalesforceへUPSERTする
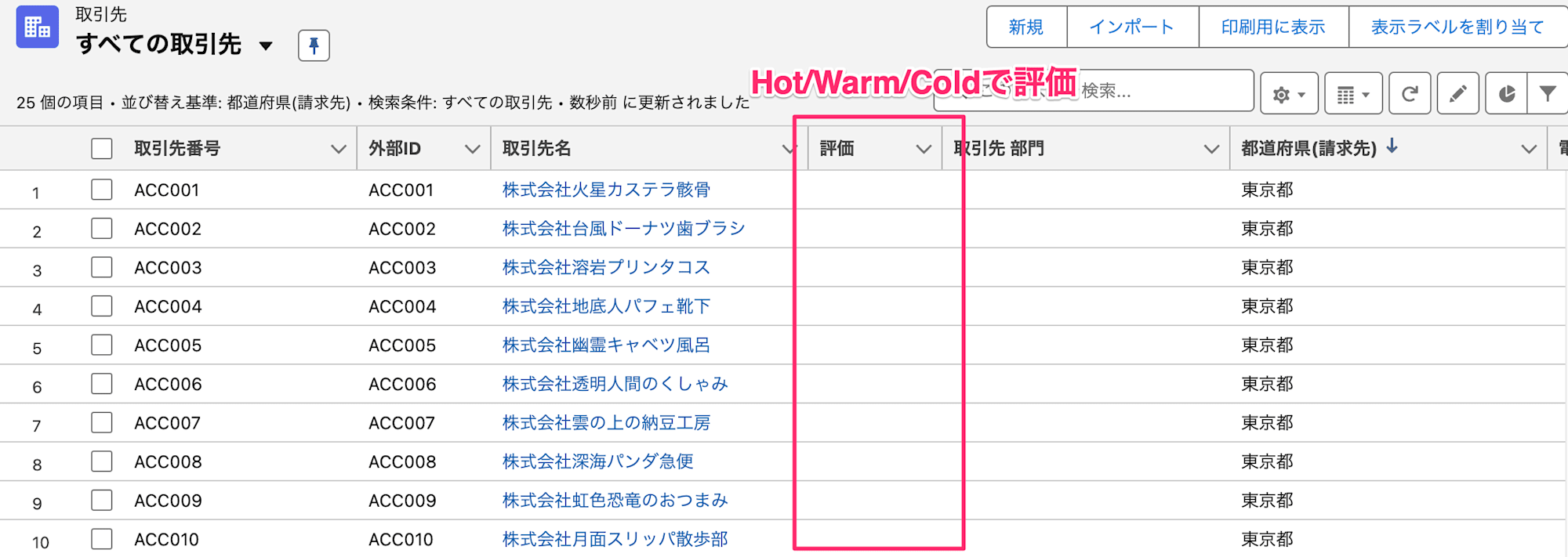
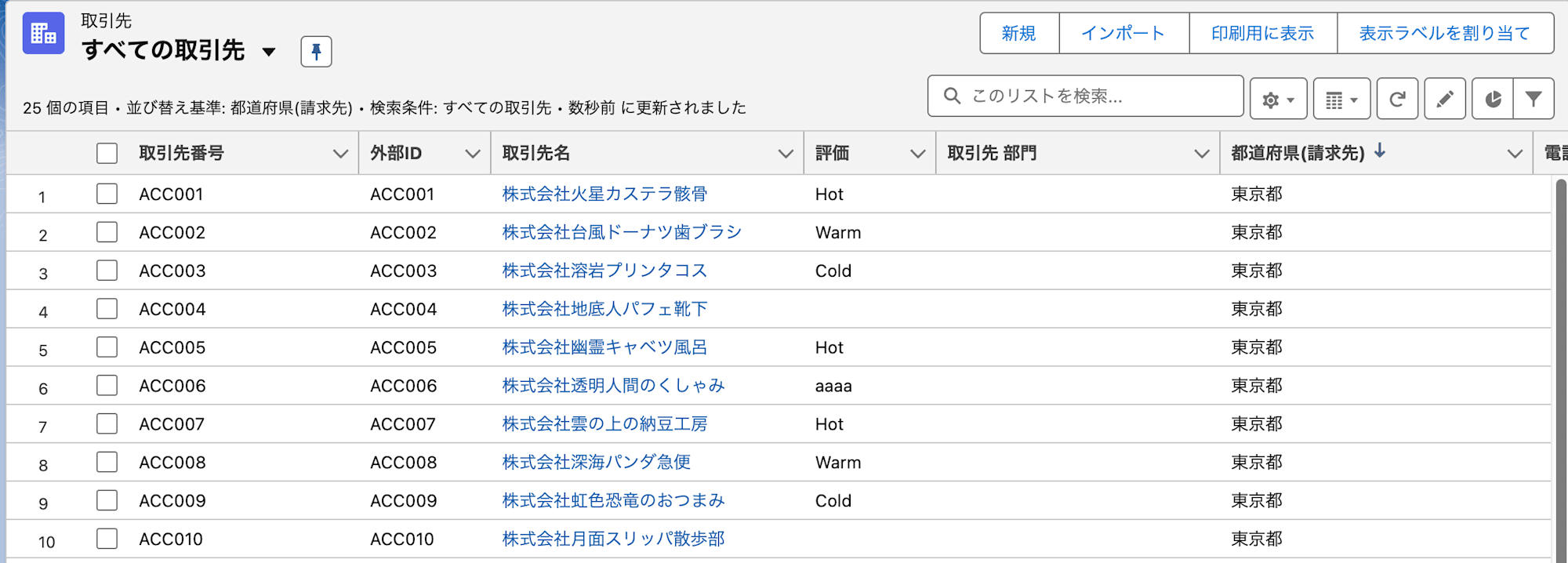
リバースETLする前のSalesforce上の取引先オブジェクトは以下の通り。赤枠の評価欄をリバースETLによってアップデートする想定です。
事前準備
Salesforceで外部IDを設定
今回はSalesforceへのアップサートを実施します。この場合、外部システムで利用しているIDをSalesforceでも利用できるID(外部ID)をキーとして利用する必要があります。設定方法は以下の記事をご参照ください。
リバースETL対象のCSVファイルを準備
Salesforceにデータを取り込む際は、まずAmazon S3バケット上にCSVファイル形式でデータを配置します。なお、CSVの他にもJSONファイル形式での取り込みにも対応しています。
今回は検証のため、以下のようにデータにバリエーションを持たせました。例えば、取引先評価(Rating)は通常「Hot」「Warm」「Cold」のいずれかを入力する仕様ですが、あえて全て小文字で入力したものや、「aaaa」といった不正な値も含めてテストを行いました。
AccountNumber,Rating
ACC001,Hot
ACC002,Warm
ACC003,Cold
ACC004,
ACC005,Hot
ACC006,aaaa
ACC007,hot
ACC008,warm
ACC009,cold
AppFlowでリバースETL
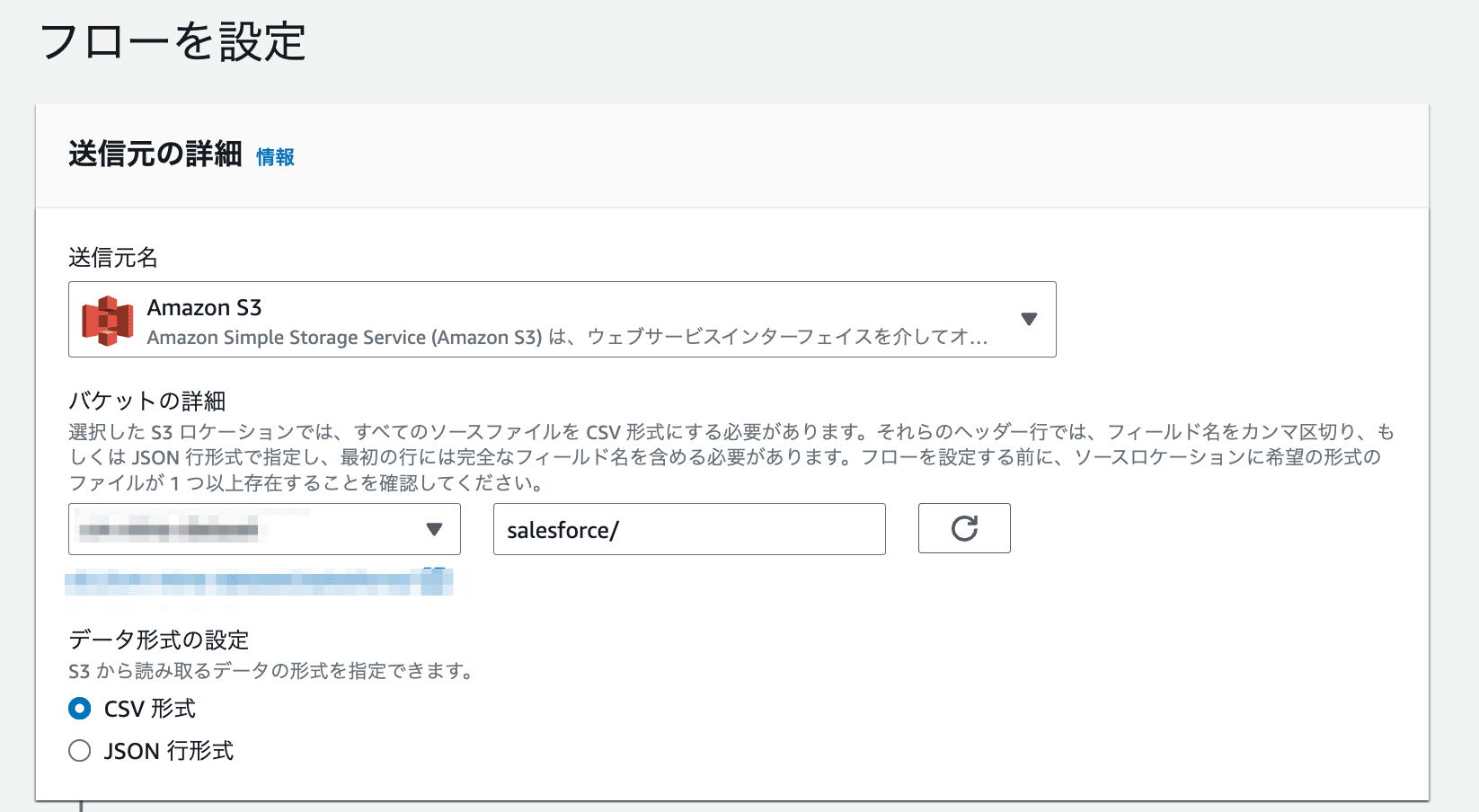
AWSマネジメントコンソールからAppFlowの画面へ遷移し、新しいフローを作成から任意のフロー名を指定し、まずはデータソースを指定します。今回はS3バケットを指定し、上述のCSVファイルが置かれたフォルダを指定しました。バケットプレフィックスの欄に直接ファイル名を指定することもフォルダ名を指定することもできます。フォルダ名を指定する場合は必ず末尾に/を入力してください。入力しないまま設定を進めるとError while communicating to connector: Exception in parsing headers from CSV file.というエラーが発生します。(2024年12月現在)
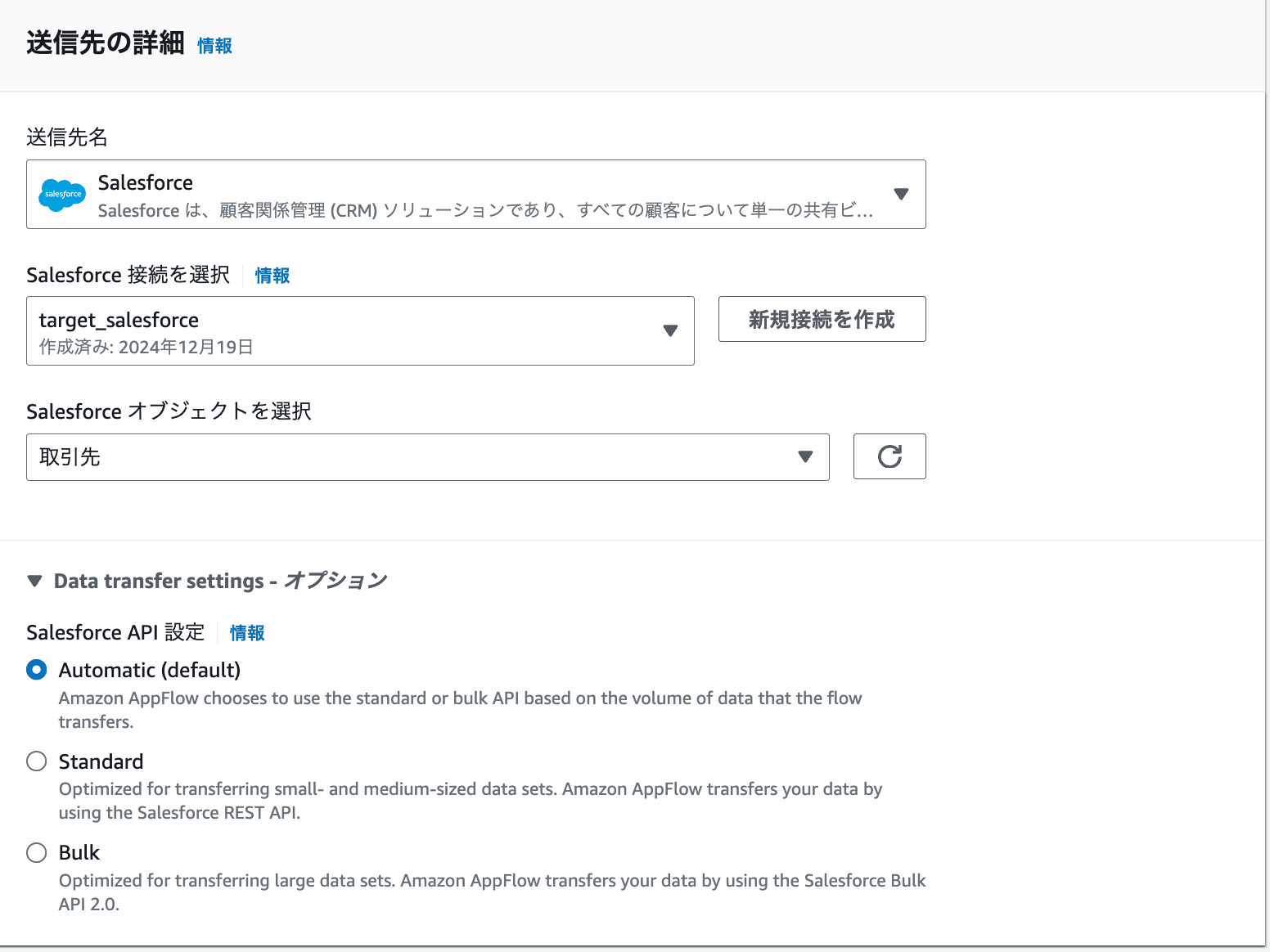
送信先にはSalesforceを指定します。設定済みのSalesforce接続を選択し、更新したいSalesforceオブジェクトを指定します。今回は取引先を選択しました。
オプションでどのSalesforce APIを利用するか選べるData transfer settingsを設定可能です。デフォルトではレコード数に応じて自動でAPIを選択するAutomaticが選択されていますが、他にもStandardやBulkも選択できます。それぞれの選択基準は以下の通りです。
| Salesforce API設定 | 内容 | 選択基準 |
|---|---|---|
| Automatic(default) | レコード数に応じて自動的にAPIを選択します。 ・ソースの場合:100万件未満はREST API、100万件以上はBulk API 2.0 ・送信先の場合:1,000件未満はREST API、1,000件以上はBulk API 2.0 ※APIによってデータ形式が異なるため、実行ごとに出力形式が変わる可能性があります。 ※Bulk API 2.0では複合項目の転送ができません。 |
・データ量が実行ごとに大きく変動する場合 ・パフォーマンスを最優先する場合 ・データ形式の一貫性にこだわらない場合 |
| Standard | Salesforce REST APIのみを使用します。 小〜中規模のデータ転送に最適化されており、一貫した出力形式を保証します。 ※大規模なデータセットを転送しようとするとタイムアウトエラーが発生する可能性があります。 |
・データ量が少ない(数千件程度まで) ・データ形式の一貫性が重要な場合 ・複合項目の転送が必要な場合 ・リアルタイム性が求められる場合 |
| Bulk | Salesforce Bulk API 2.0のみを使用します。 非同期データ転送を実行し、大規模なデータセットに最適です。 ※複合項目の転送はサポートされていません。 |
・大量データ(数万件以上)の転送が必要な場合 ・バッチ処理での実行が許容される場合 ・複合項目を使用していない場合 ・データ形式の一貫性が重要な場合 |
Salesforce接続が未作成の場合、「新規接続を作成」から設定可能です。接続名を入力し、OAuthグラントタイプをJWTか認証コードのどちらかから選びます。今回は認証コードで進めていきます。

Salesforceログイン時に利用するユーザー・パスワードを入力し、「Amazon AppFlow Embedded Login App」を許可します。許可すると接続先名が「Salesforce接続を選択」ドロップダウンリストから選択できるようになります。
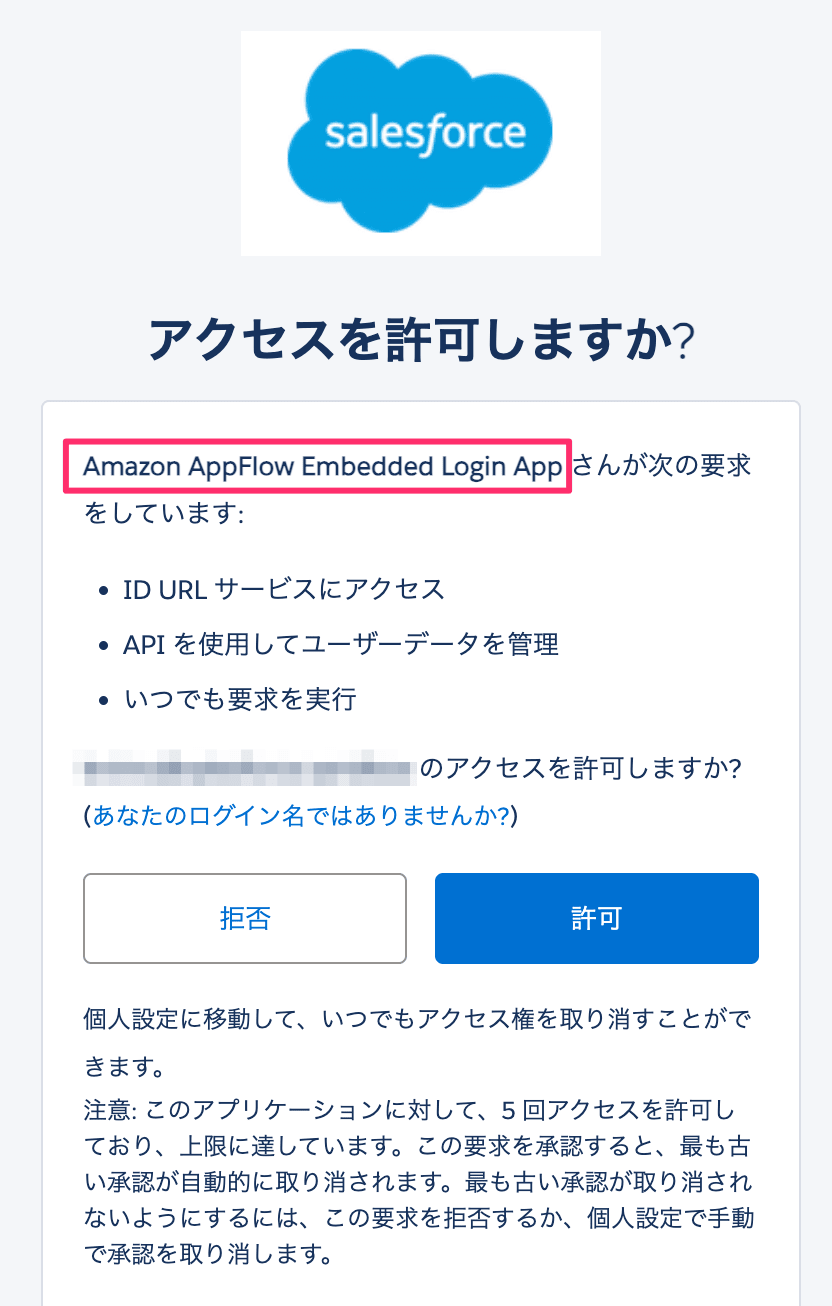
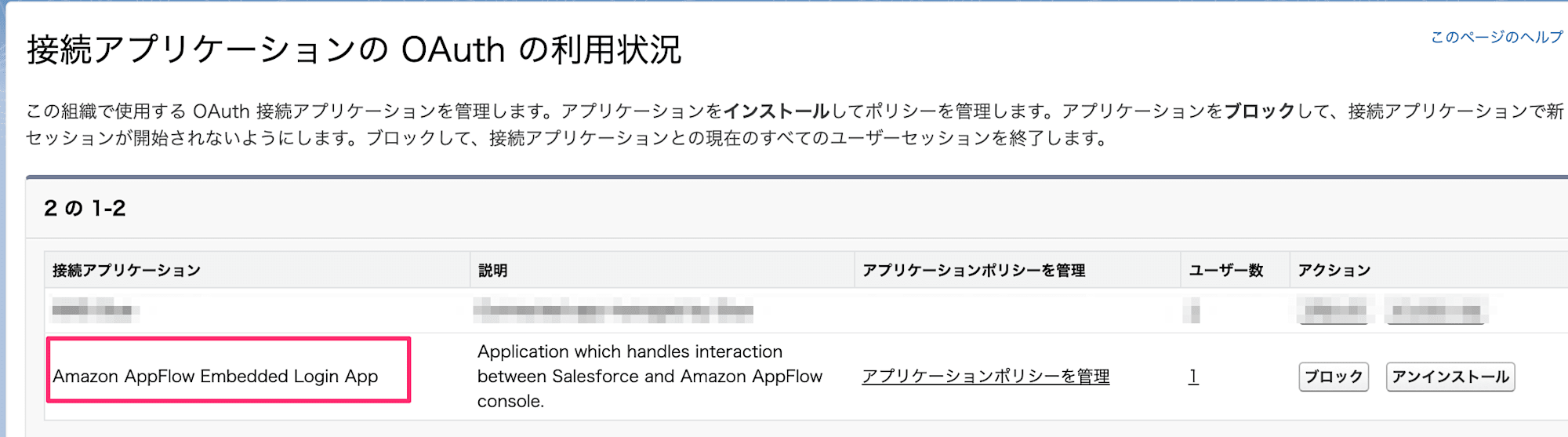
なお、許可するとSalesforceの「接続アプリケーションのOAuthの利用状況」メニューより「Amazon AppFlow Embedded Login App」が確認できるようになります。不要になればここからブロックやアンインストールもできます。
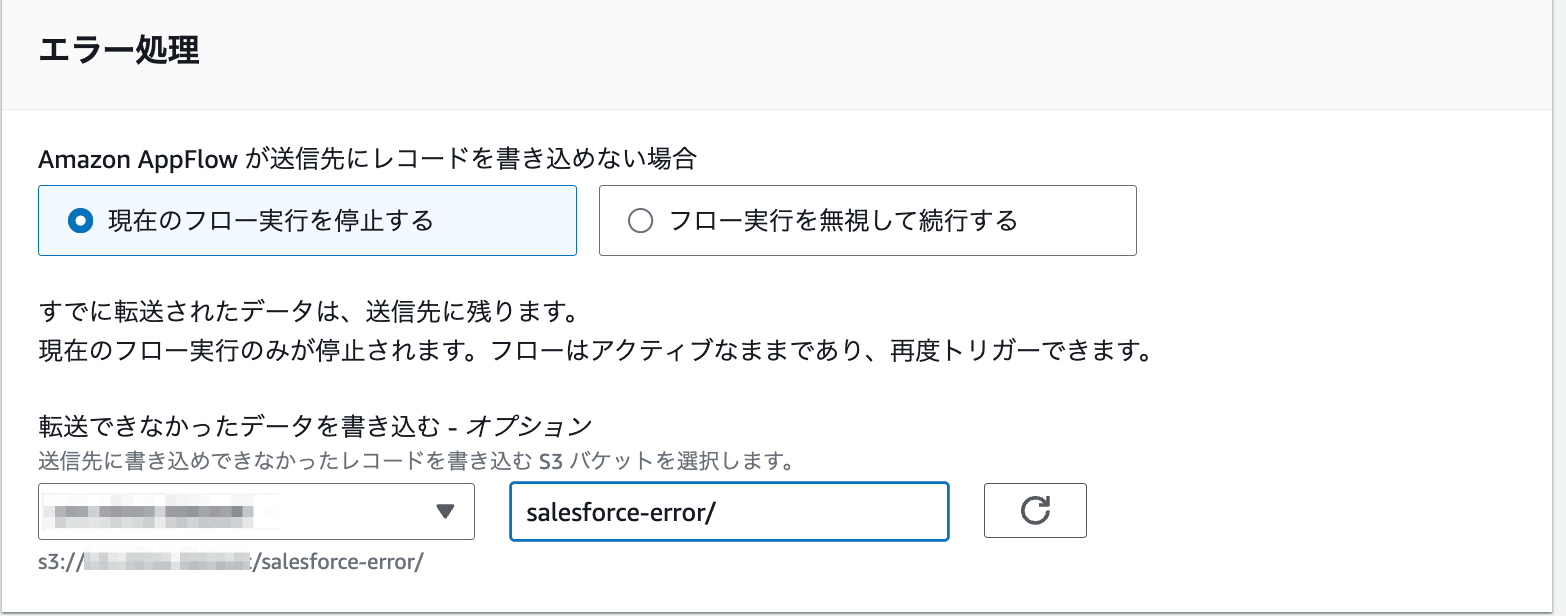
次に、エラー処理の方式を選択します。
| エラーハンドリング | 内容 |
|---|---|
| 現在のフロー実行を停止する | 処理できないレコードがあった場合にフローを異常終了します。すでに処理されたレコードは連携先に残り、異常レコード以降は処理されません。 |
| フロー実行を無視して続行する | 処理できないレコードがあってもフローは異常終了しません。異常レコードのみが処理されません。 |
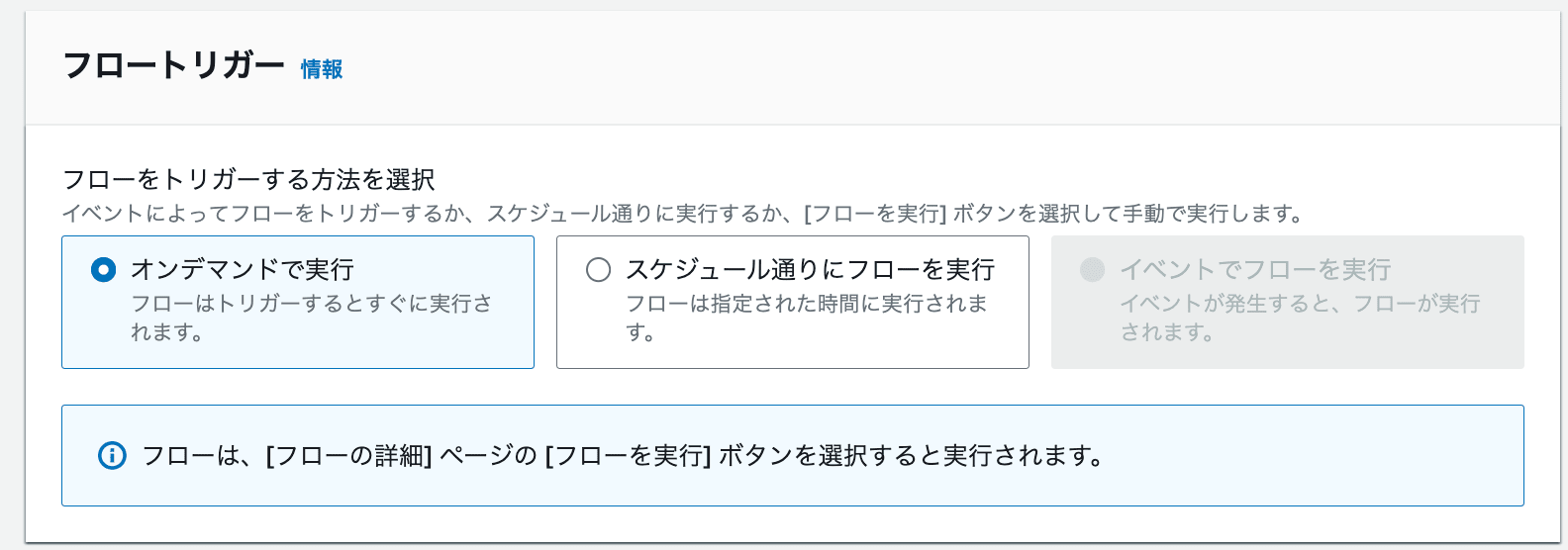
スケジュールを設定可能です。今回はオンデマンドで実行します。
次に送信レコードの設定をします。今回はキーに一致するレコードはアップデートし、IDがSalesforce上に存在しないケースは新しくレコードを作るため、UPSERTレコードを選択します。キーにはSalesforce上で外部IDとして指定可能なフィールドを指定します。
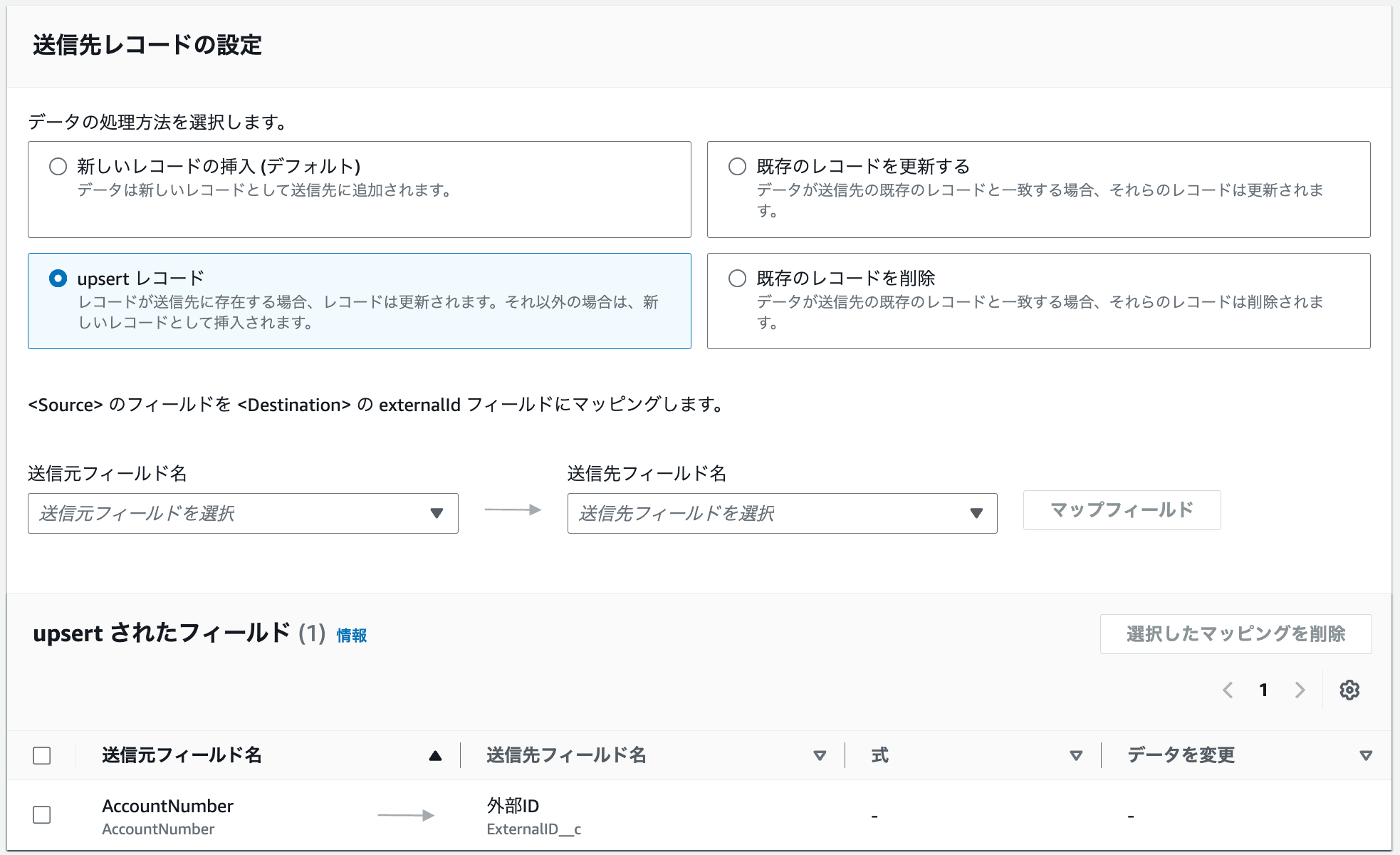
次に、データファイルのそれぞれどの項目がSalesforce上のどの項目と紐づいているのかを指定します。

最後に、オプションでバリデーションの設定が可能です。値が負/NULL/0/テキストの場合にフローを終了するかレコードを無視するか選択可能です。
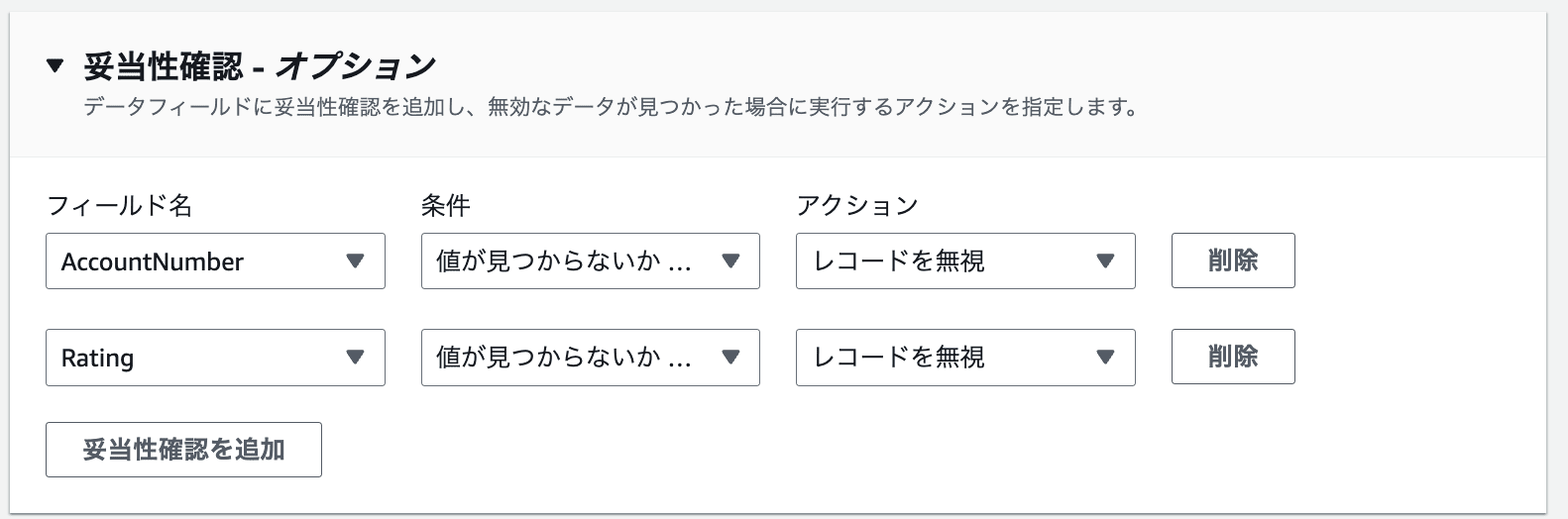
保存してフローを実行すると、Salesforceの取引先オブジェクトが更新されていることが確認できました。小文字を使った値は先頭が大文字に変わっている一方、Hot/Warm/Cold以外の値を指定したものはそのまま連携されているようです。AppFlowでのバリデーションはごく簡単なもののみ設定できるため、連携される値のチェックは事前に済ませておく必要がありそうです。
最後に
先日紹介したAWS Glueに続き、今回はAmazon AppFlowを利用したリバースETLを検証してみました。AppFlowはGlueと比較して認証設定が非常に簡単で、フィールドのマッピング設定だけで即座にデータパイプラインを構築できます。また、Glueジョブのようなバージョンアップ対応やコードメンテナンスが不要という点は、運用負荷を大幅に軽減できる強力なメリットだと感じました。
ただし、より厳密なデータ検証や複雑な前処理が必要なケースでは、AppFlow単体での対応は難しく、他のAWSサービスとの組み合わせや別のソリューションの検討が必要になります。利用シーンや要件によって最適なソリューションが変わってくるため、システムの規模や運用体制、必要な機能などを総合的に判断することが重要です。
参考








