
Amazon AthenaでCSVとParquetのスキャン量を比較してみた
はじめに
コンサルティング部のぐっさんです。さむいです。
前回の記事では、 Apache Parquet の仕組みについて確認しました。
今回は実際に AWS Athena を使って、CSV と Parquet でファイルサイズやSQLクエリのスキャン量にどんな違いがあるかを検証してみます。
そこまで大きなデータは用意していないので、クエリ実行の速さよりはスキャン量が実際にどれくらい変わるのかに注目しています。
一言まとめ
同じデータでも、Parquet 形式を使うとスキャン量が減り、コスト削減と高速化が期待できます。
検証の流れ
- テストデータ(10,000件)を Pythonを使用してCSV / Parquet で作成
- S3 にアップロード
- Athena でテーブルを作成
- 同じクエリを実行して比較
Amazon Athena とは
S3 上のデータに対して SQL でクエリできるサーバーレスサービスです。
料金はスキャンしたデータ量に応じた従量課金($5/TB)なので、巨大なデータを扱う場合はスキャン量を減らすことがそのままコスト削減につながります。
補足 Athena はオープンソースの Trino(旧 Presto)をベースにしており、アドホック分析(その場でサクッとクエリ)に強いのが特徴です。大量データのETL/バッチ処理には Athena for Apache Spark や AWS Glue が使われます。
とても詳しい入門記事はこちらです!
検証データ
冬なので、(いつか見たいという願望を含め)架空のオーロラ観測データ(10,000件)をそれっぽく作成してみます。
※地名は実際の都市や国を使用していますが、あくまでテストデータです。

データ構造:
| カラム | 型 | 説明 |
|---|---|---|
| id | int | 観測ID |
| observation_date | string | 観測日 |
| observation_hour | int | 観測時刻(時) |
| location | string | 観測地 |
| country | string | 国 |
| latitude | float | 緯度 |
| longitude | float | 経度 |
| temperature | int | 気温(℃) |
| kp_index | int | 地磁気活動指数(1-9) |
| duration_minutes | int | 観測時間(分) |
| color | string | オーロラの色 |
| intensity | int | 強度(1-5) |
| cloud_cover | int | 雲量(%) |
| is_photographed | bool | 撮影したか |
データ生成
後述するPython スクリプト(generate_aurora_data.py)を実行してデータを生成します。
架空データでCSVとParquetをまとめて作成し、それぞれのファイルサイズを出力するスクリプトにしています。
前回記事と同じ venv 環境を使用します。
# 仮想環境の有効化
source .venv/bin/activate
# データ生成スクリプトを実行
python generate_aurora_data.py
出力例
(.venv) % python generate_aurora_data.py
データ生成完了: 10000件
ファイルサイズ:
CSV: 704,164 bytes (687.7 KB)
Parquet: 180,910 bytes (176.7 KB)
先頭10件:
id observation_date observation_hour location country latitude longitude temperature kp_index duration_minutes color intensity cloud_cover is_photographed
0 1 2025-09-29 20 Kiruna Sweden 67.9 20.2 -12 5 72 red 2 94 True
1 2 2026-01-18 21 Kiruna Sweden 67.9 20.2 -17 7 18 green 1 27 True
2 3 2026-02-02 20 Rovaniemi Finland 66.5 25.7 -18 4 176 blue 4 28 False
3 4 2025-11-11 20 Rovaniemi Finland 66.5 25.7 -11 3 118 purple 3 19 True
4 5 2025-09-27 21 Reykjavik Iceland 64.1 -21.9 -23 2 101 purple 5 33 True
5 6 2025-12-27 4 Kiruna Sweden 67.9 20.2 -32 7 30 blue 3 80 False
6 7 2025-10-20 21 Rovaniemi Finland 66.5 25.7 -34 4 84 green 2 12 False
7 8 2025-12-26 1 Reykjavik Iceland 64.1 -21.9 -30 6 100 red 3 89 True
8 9 2026-02-10 22 Rovaniemi Finland 66.5 25.7 -18 4 51 pink 4 34 True
9 10 2025-11-23 20 Kiruna Sweden 67.9 20.2 -28 1 90 pink 3 8 True
圧縮オプションなしでも約 74% 削減されています。これは Parquet フォーマット自体の効率(バイナリ形式、重複値の効率的な保存等)によるものです。
補足 pandas の
to_parquet()はcompressionパラメータでデフォルト snappy 圧縮が有効になっています。今回は圧縮なし(compression=None)にして、純粋な Parquet フォーマットとしての効率を確認しています。
generate_aurora_data.pyの中身はこちらです。
import pandas as pd
import random
from datetime import datetime, timedelta
# 再現性のためシード固定
random.seed(42)
# 観測地リスト
locations = [
{'name': 'Fairbanks', 'country': 'USA', 'lat': 64.8, 'lon': -147.7},
{'name': 'Tromso', 'country': 'Norway', 'lat': 69.6, 'lon': 19.0},
{'name': 'Reykjavik', 'country': 'Iceland', 'lat': 64.1, 'lon': -21.9},
{'name': 'Yellowknife', 'country': 'Canada', 'lat': 62.5, 'lon': -114.4},
{'name': 'Rovaniemi', 'country': 'Finland', 'lat': 66.5, 'lon': 25.7},
{'name': 'Kiruna', 'country': 'Sweden', 'lat': 67.9, 'lon': 20.2},
]
colors = ['green', 'red', 'purple', 'pink', 'blue']
# 10,000件のデータを生成
data = []
base_date = datetime(2025, 9, 1) # オーロラシーズン開始
for i in range(1, 10001):
loc = random.choice(locations)
obs_date = base_date + timedelta(days=random.randint(0, 180))
obs_hour = random.randint(20, 28) % 24 # 20時〜翌4時
data.append({
'id': i,
'observation_date': obs_date.strftime('%Y-%m-%d'),
'observation_hour': obs_hour,
'location': loc['name'],
'country': loc['country'],
'latitude': loc['lat'],
'longitude': loc['lon'],
'temperature': random.randint(-35, -5),
'kp_index': random.randint(1, 9),
'duration_minutes': random.randint(10, 180),
'color': random.choice(colors),
'intensity': random.randint(1, 5),
'cloud_cover': random.randint(0, 100),
'is_photographed': random.choice([True, False])
})
df = pd.DataFrame(data)
# CSV と Parquet で保存(Parquet は圧縮なし)
df.to_csv('data/aurora_observations.csv', index=False)
df.to_parquet('data/aurora_observations.parquet', compression=None)
print(f"データ生成完了: {len(df)}件")
print(f"\nファイルサイズ:")
import os
csv_size = os.path.getsize('data/aurora_observations.csv')
parquet_size = os.path.getsize('data/aurora_observations.parquet')
print(f" CSV: {csv_size:,} bytes ({csv_size/1024:.1f} KB)")
print(f" Parquet: {parquet_size:,} bytes ({parquet_size/1024:.1f} KB)")
print(f"\n先頭10件:")
print(df.head(10))
S3 にアップロード
AWS CLI を使ってデータを S3 にアップロードします。
バケット作成
# バケット作成(バケット名は適宜変更してください)
aws s3 mb s3://your-bucket-name --region ap-northeast-1
データアップロード
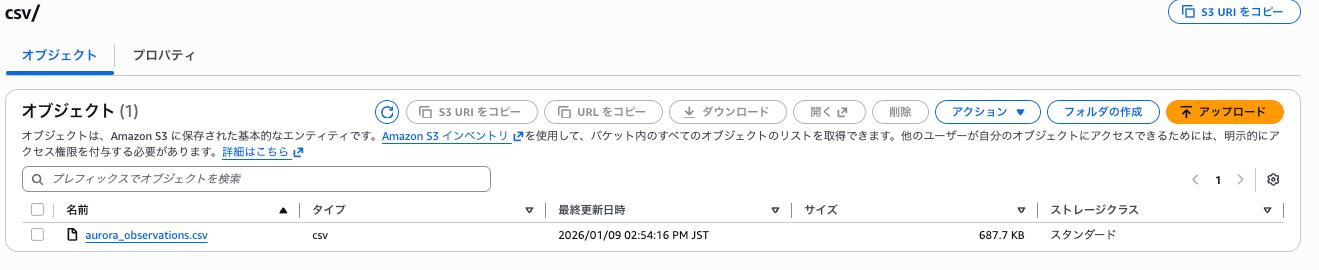
CSV と Parquet を別フォルダにアップロードします。
# CSV をアップロード
aws s3 cp data/aurora_observations.csv s3://your-bucket-name/csv/
# Parquet をアップロード
aws s3 cp data/aurora_observations.parquet s3://your-bucket-name/parquet/
確認
aws s3 ls s3://your-bucket-name/ --recursive
出力例
2026-01-09 14:54:16 704164 csv/aurora_observations.csv
2026-01-09 14:54:46 180910 parquet/aurora_observations.parquet
コンソールでもアップロードされたことを確認できます。

Athena テーブル作成
Athena コンソールのクエリエディタで DDL(CREATE TABLE 文)を実行してテーブルを作成します。
補足 初回利用時は、クエリ結果の出力先 S3 バケットの設定が必要です。Athena コンソールの「設定」から設定してください。なお、今回はワークグループなどの設定は特別実施せずにデフォルトのまま実行しています。
データベース作成
まず、テーブルを格納するデータベースを作成します。
エディタの枠内にSQL文を入力し「実行する」を押下します。
CREATE DATABASE IF NOT EXISTS northern_lights_db;
実行結果は以下のようになり、「クエリは成功しました」と出ました。
余談ですが、急にデータベース名をnorthern_lightsにしたのはなんだかAmazon Auroraと被ってややこしくなりそう?だったからです。
CSV テーブル作成
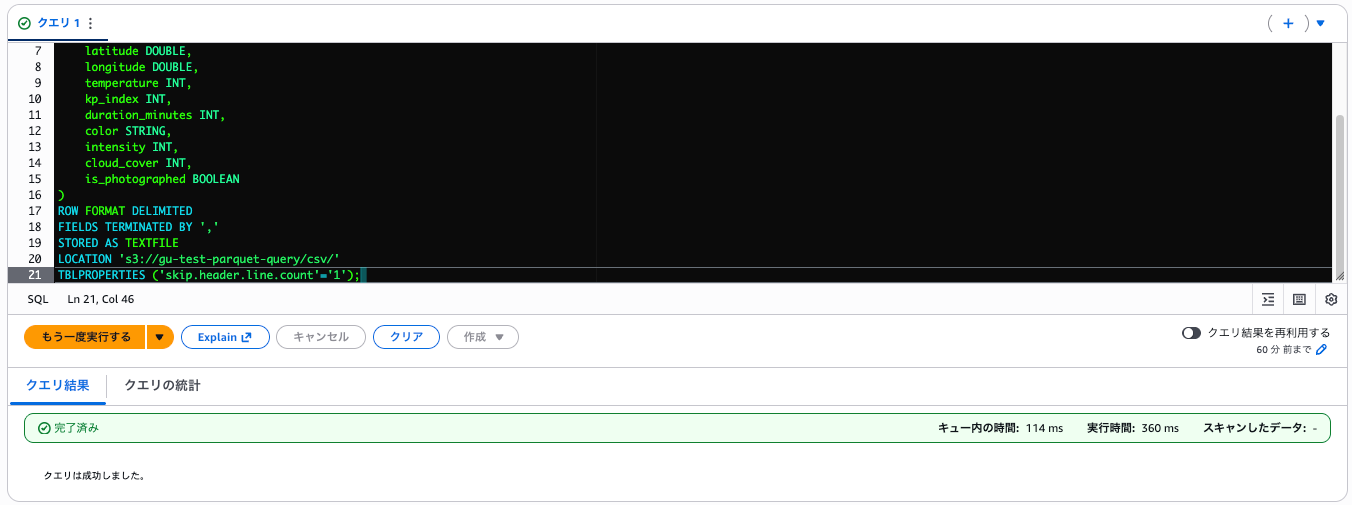
CREATE EXTERNAL TABLE northern_lights_db.aurora_csv (
id INT,
observation_date STRING,
observation_hour INT,
location STRING,
country STRING,
latitude DOUBLE,
longitude DOUBLE,
temperature INT,
kp_index INT,
duration_minutes INT,
color STRING,
intensity INT,
cloud_cover INT,
is_photographed BOOLEAN
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://your-bucket-name/csv/'
TBLPROPERTIES ('skip.header.line.count'='1');
補足
ROW FORMAT DELIMITEDで CSV 形式を指定skip.header.line.countでヘッダー行をスキップ- 全カラムの型を手動で定義する必要がある
Parquet テーブル作成
CREATE EXTERNAL TABLE northern_lights_db.aurora_parquet (
id INT,
observation_date STRING,
observation_hour INT,
location STRING,
country STRING,
latitude DOUBLE,
longitude DOUBLE,
temperature INT,
kp_index INT,
duration_minutes INT,
color STRING,
intensity INT,
cloud_cover INT,
is_photographed BOOLEAN
)
STORED AS PARQUET
LOCATION 's3://your-bucket-name/parquet/';
補足
STORED AS PARQUETだけでフォーマット指定完了- Parquet はスキーマを内蔵しているが、Athena では DDL でも定義が必要
テーブル確認
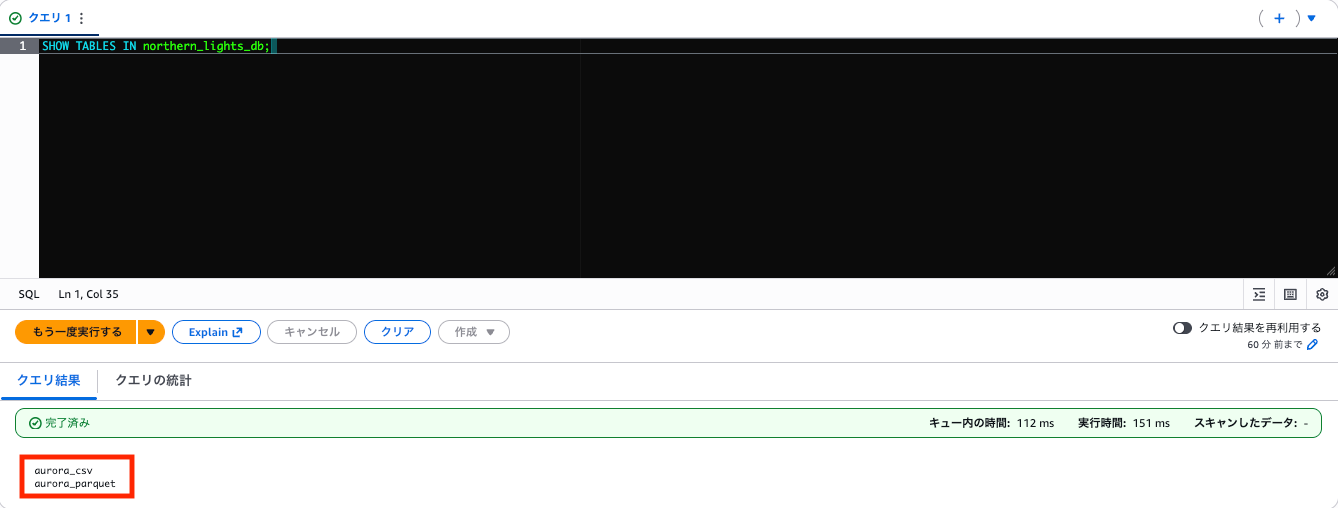
SHOW TABLES IN northern_lights_db;
これでテーブルの準備ができました!実際にクエリを実行し、比較してみます。
クエリ比較
同じクエリを CSV テーブルと Parquet テーブルに実行し、スキャン量を比較します。
クエリ1: 1列のみ使用(観測地集計)
観測地(location)ごとの観測回数をカウントし、多い順に並べるクエリです。
列としては1列のみを使用します。
CSV テーブル
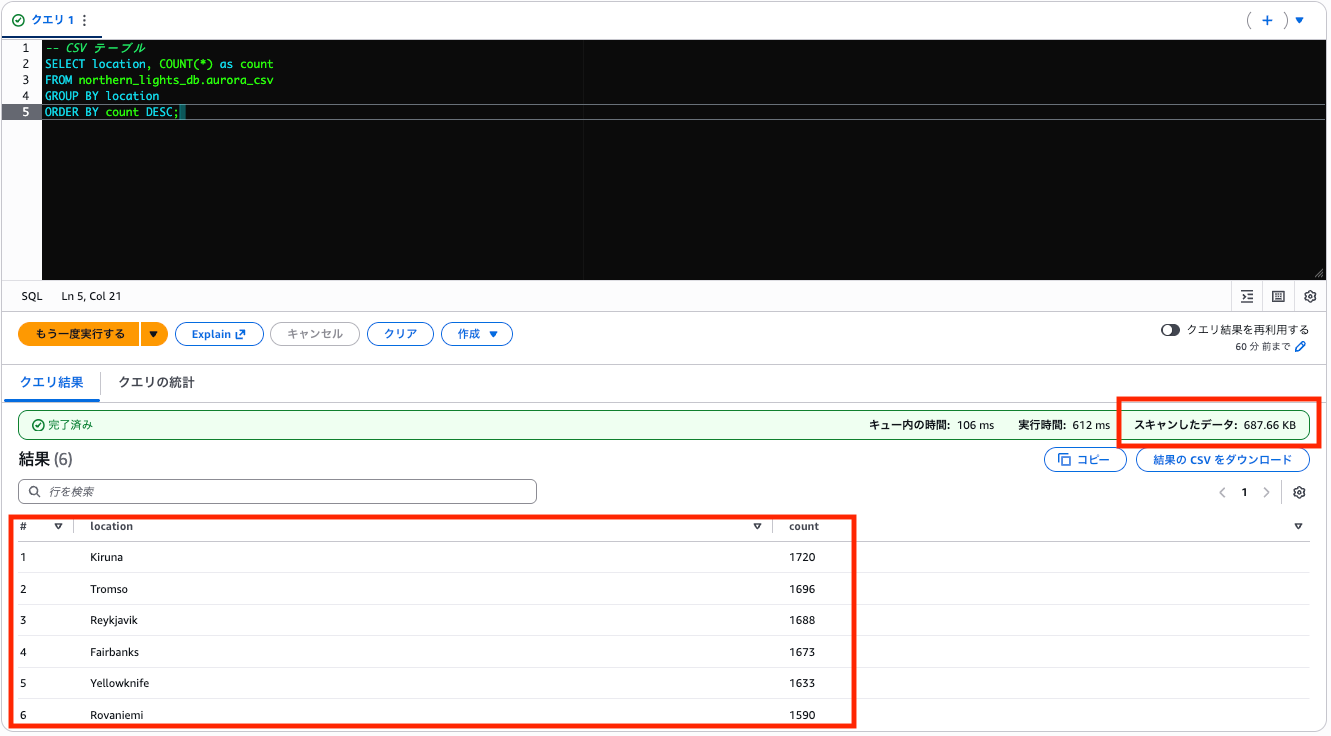
-- CSV テーブル
SELECT location, COUNT(*) as count
FROM northern_lights_db.aurora_csv
GROUP BY location
ORDER BY count DESC;
Parquet テーブル
-- Parquet テーブル
SELECT location, COUNT(*) as count
FROM northern_lights_db.aurora_parquet
GROUP BY location
ORDER BY count DESC;
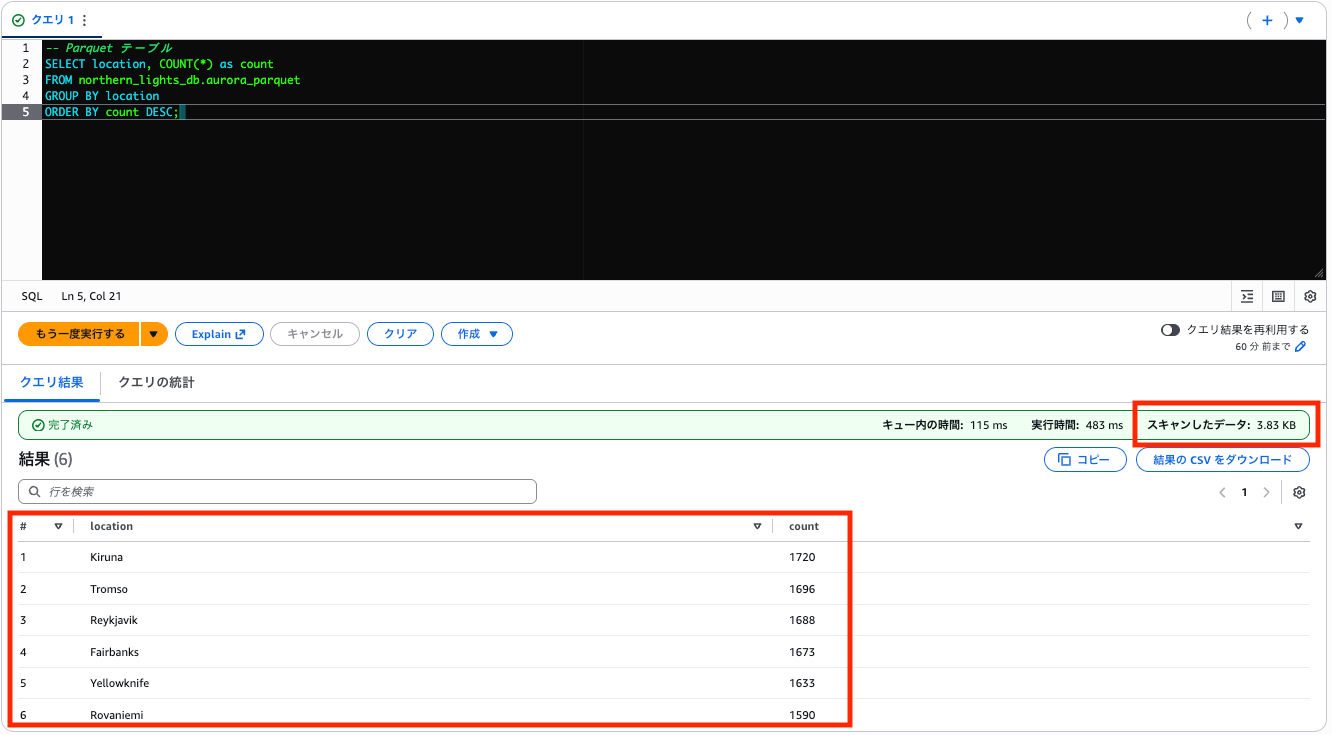
同じクエリ・同じ結果ですが、スキャン量は CSV が 687.66 KB に対し Parquet はわずか 3.83 KB。約 99% 削減されています。Parquet は location 列だけを読めば良いので、他の 13 列分のスキャンが不要になります。
クエリの実行時間も若干Parquetの方が速いですね。
クエリ2: 複数列取得 + フィルタ
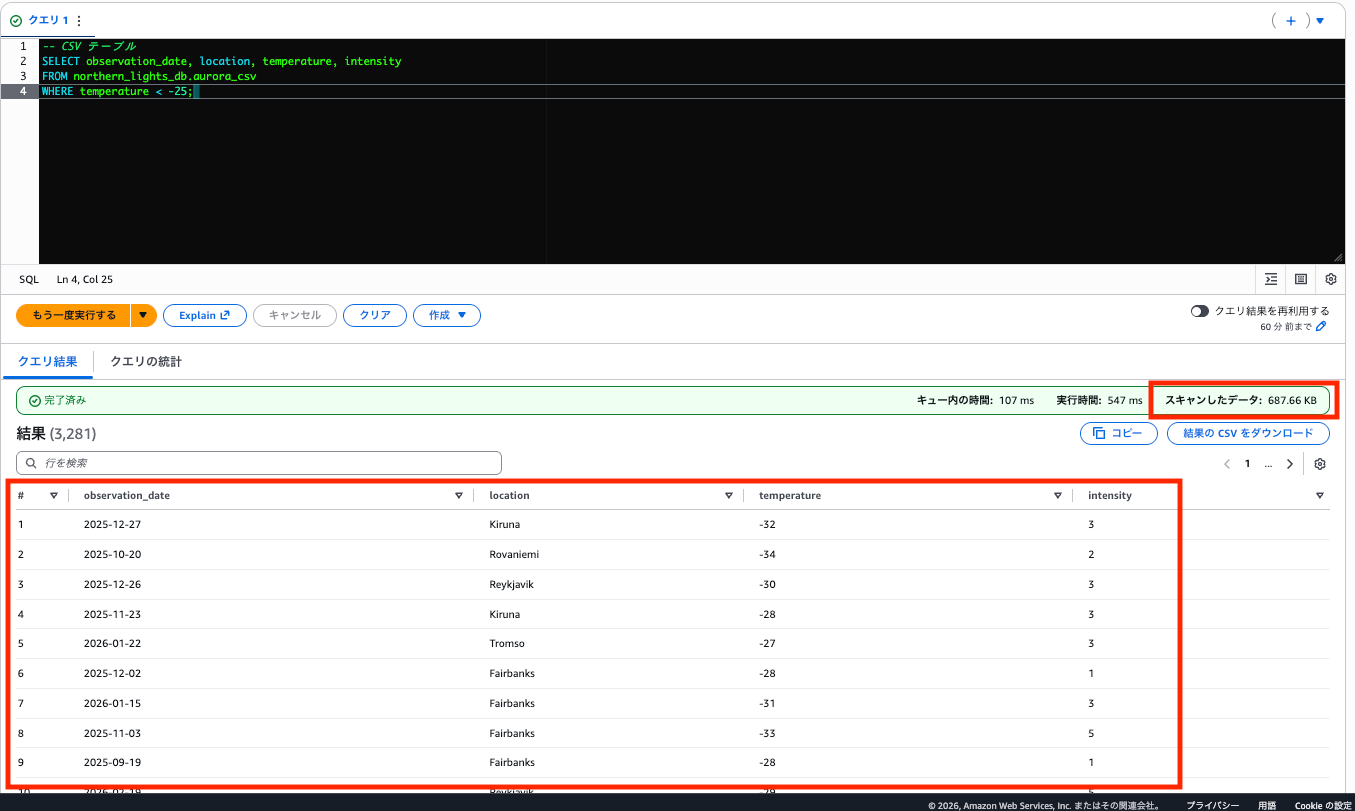
日付・場所・気温・強度の 4 列を取得し、気温 -25℃ 未満でフィルタするクエリです。列が増えるとどうなるでしょう。
CSV テーブル
-- CSV テーブル
SELECT observation_date, location, temperature, intensity
FROM northern_lights_db.aurora_csv
WHERE temperature < -25;
Parquet テーブル
-- Parquet テーブル
SELECT observation_date, location, temperature, intensity
FROM northern_lights_db.aurora_parquet
WHERE temperature < -25;

4 列を使用するため、クエリ1(1列)よりスキャン量は増えますが、それでも CSV の 687.66 KB に対し Parquet は 26.69 KB と約 96% 削減されています。
どこも寒そうですね・・・、この中だとロヴァニエミに行ったことがありますが、当時は残念ながらオーロラ見られずでした。。。再チャレンジしたいですね。旅行会社にいた頃の噂によると、イエローナイフはわりと観測しやすいらしいです。(今はどうでしょう?)
クリーンアップ
検証が終わったら、作成したリソースを削除しておきましょう。
Athena テーブル・データベースの削除
DROP TABLE IF EXISTS northern_lights_db.aurora_csv;
DROP TABLE IF EXISTS northern_lights_db.aurora_parquet;
DROP DATABASE IF EXISTS northern_lights_db;
検証用 S3 バケットの削除
# バケット内のオブジェクトを削除
aws s3 rm s3://your-bucket-name/ --recursive
# バケット削除
aws s3 rb s3://your-bucket-name
クエリ結果の削除 (任意)
Athena のクエリ結果が保存されている S3 バケットの中身も、不要であれば削除してください。
まとめ
| クエリ | CSV スキャン量 | Parquet スキャン量 | 削減率 |
|---|---|---|---|
| クエリ1: 1列のみ使用(観測地集計) | 687.66 KB | 3.83 KB | 99% |
| クエリ2: 複数列取得+フィルタ | 687.66 KB | 26.69 KB | 96% |
テストデータを用いて改めて、CSV は列数に関係なく全データを読むのに対し、Parquet は使用する列数に応じてスキャン量が変わることが分かりました。
補足 今回はデータ量が少なく Row Group が1つだけでしたが、大規模データで複数の Row Group がある場合は「述語プッシュダウン」の効果も期待できます。WHERE 句の条件に合わない Row Group を、メタデータ(min/max 統計)を見てスキップできるため、さらにスキャン量を削減できます。
Parquet を使うメリット
- 列指向なので必要な列だけスキャン → クエリコスト/時間削減
- 圧縮効率が高い → ストレージコスト削減
- 型情報を持つ → スキーマ管理が楽
今後は さらに巨大なデータでの検証や、Apache Iceberg やそれをマネージドで扱える S3 Tables なども触ってみたいと思います。
最後までお読みいただきありがとうございました!








