
Amazon SageMaker HyperPod の継続的プロビジョニングと MinCount を図解で整理してみた
はじめに
Amazon SageMaker HyperPod の Slurm クラスターで、最小容量要件を指定する MinCount が利用できるようになりました。MinCount は、インスタンスグループが InService へ遷移するうえで必要な最小インスタンス数を決める新しい機能です。前提となる継続的プロビジョニング(NodeProvisioningMode を Continuous に設定)と合わせ図解で整理します。
確認結果
HyperPod に詳しい方は少数派だと思いますので本文を読んでいただければと幸いです。
- MinCount はワーカーグループが
InServiceになる前の最小確保台数を決める新機能 InServiceにはクラスター単位とインスタンスグループ単位の 2 つがあり、条件が異なる- 前提は継続的プロビジョニング(
NodeProvisioningModeをContinuous)で、Slurm 専用 MinInstanceCountは 0〜InstanceCountで設定でき、all-or-nothing と 1 台でも可の中間を選べる- MinCount を 3 時間で満たせなければ自動ロールバックし、新規グループは 0 台に戻って再スケールが必要
継続的プロビジョニングとは
MinCount を理解する前に、2026 年 3 月に追加された機能である継続的プロビジョニングを押さえておきます。
継続的プロビジョニングは、クラスターのキャパシティを段階的に確保できる仕組みです。
従来は all-or-nothing 型で、要求台数を確保できないと処理自体が失敗してロールバックしていました。昨今、GPU インスタンスはキャパシティ確保が難しく 16 台要求しても数台しか確保できないこともあり、すると全部やり直しになることが発生しやすい状況です。
継続的プロビジョニングは desired-state 型です。目標台数を設定し、確保できた台数で先に処理を開始します。足りないノードは非同期でリトライを続け、確保でき次第クラスターに追加されます。設定はデフォルトでは無効です。NodeProvisioningMode を Continuous に設定して有効化します。

コントローラーノードを優先で起動
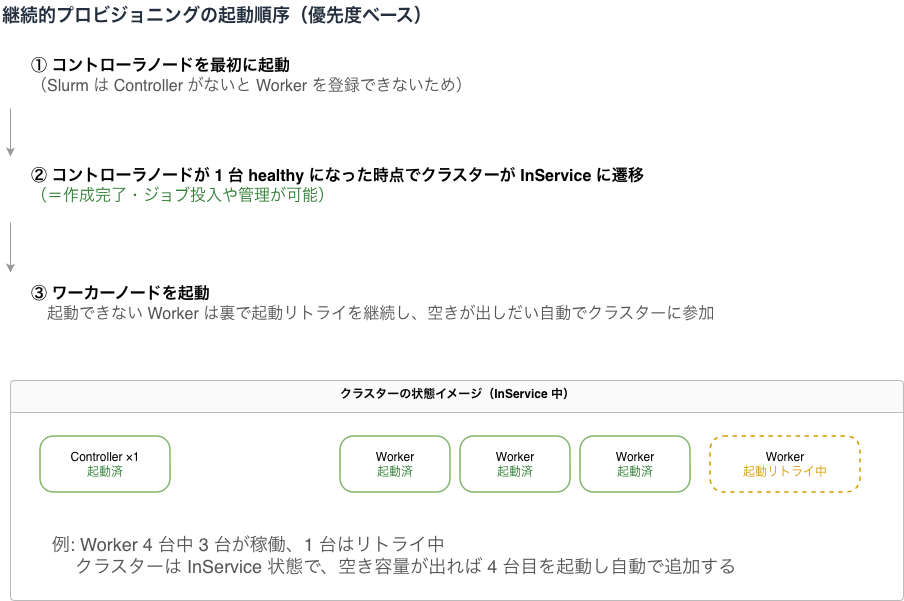
継続的プロビジョニングは優先度に基づいた順序で起動します。Slurm はコントローラーノードがないとワーカーノードを登録できないため、まずコントローラーグループを優先して起動します。コントローラーノードが 1 台 healthy になると、ログインノード(任意)とワーカーノードの起動を並列で開始します。
クラスターはコントローラーノードが起動した時点で InService へ遷移します。ログイングループを指定している場合は、ログインノードも 1 台起動した時点でInServiceとなります。ワーカーノードの起動状況は InService の条件に含まれません。
キャパシティ不足で起動できないワーカーノードは、非同期でリトライ処理に入ります。空きが出しだいクラスターに自動で追加されます。そのため、一部ワーカーノードが欠けた状態でもクラスター作成または、更新処理は失敗しません。
InService とは
図の②の InService はクラスター単位の状態で、「ジョブ投入や管理が可能になった」ことを意味します。
各ワーカーグループが「使える」とみなす最小台数は、後述の MinCount で別に決まります。
クラスターが InService でも、ワーカーグループはまだ Creating の状態は起こり得ます。
MinCount でワーカーノードの最小台数を保証
分散学習では一定数のノードがそろわないとジョブを開始できないものもあります。継続的プロビジョニングだけだと、ワーカーノードが少ない台数のまま InService に遷移し得ます。ここの下限の台数を設定できるのが MinCount です。 ここが今回のアップデートで追加された改善点です。
The MinCount feature allows you to specify the minimum number of instances that must be successfully provisioned before an instance group transitions to the
InServicestatus.出典: Continuous provisioning for enhanced cluster operations with Slurm - Amazon SageMaker AI
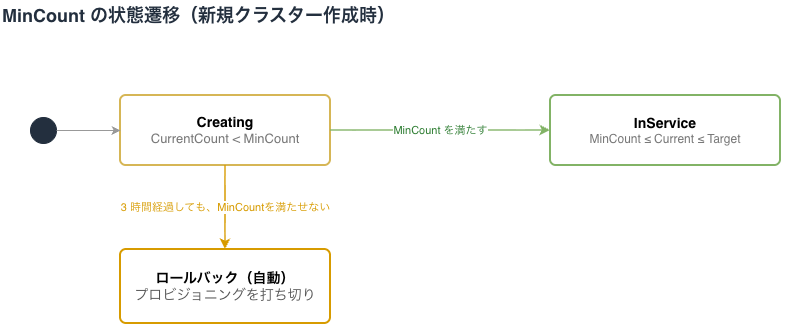
新規クラスターを作成するときの例で説明します。インスタンスグループは MinCount に達するまで Creating のままです。達すると InService へ遷移します。3 時間で達しない場合は自動的にロールバックします。
MinInstanceCount は 0〜InstanceCount の範囲で設定でき、3 通りの使い分けができます。
MinInstanceCount = 0(ワーカーグループのデフォルト)は 1 台でも起動すればInServiceとなる、従来どおりの継続的プロビジョニングの挙動0 < MinInstanceCount < InstanceCountは指定台数そろうまでCreatingで待機し、以降はInServiceとなる設定MinInstanceCount = InstanceCountは全台そろうまでInServiceにならない、実質 all-or-nothing の挙動
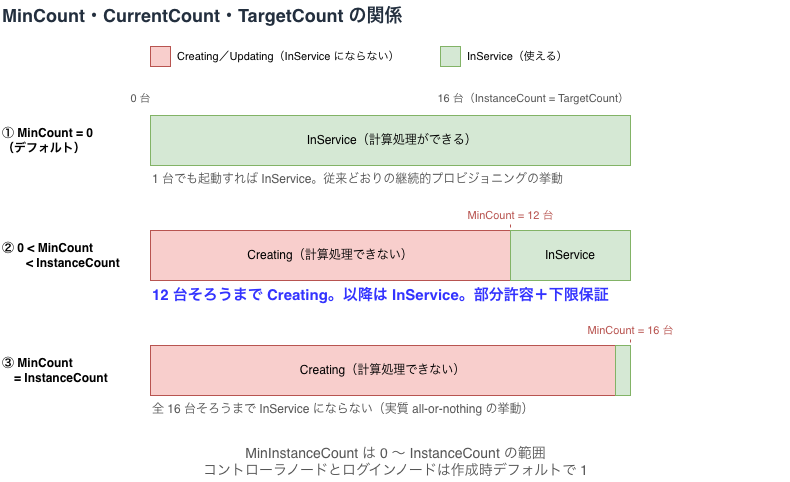
②のパターンが今回のアップデートの意図した使い方です。機械学習などの計算処理に使う際のインスタンス数の下限を保証できます。
なお、コントローラーグループとログイングループでは、作成時のデフォルト値が 1 になります。
3 時間で満たせなければ自動ロールバックする
MinCount を 3 時間で満たせない場合、無限に待機することを防ぐために自動でロールバックします。ロールバック後、インスタンスグループは InService に戻ります。新規グループでは 0 台に戻るため、要求容量は未確保で再度スケールが必要です。
設定方法
前提条件
継続的プロビジョニングと MinCount には、以下の前提があります。
- Slurm オーケストレーション専用(EKS は対象外)
- MinCount は
NodeProvisioningModeがContinuousのクラスターでのみ利用可能 - Slurm のトポロジ情報は API の
SlurmConfigで渡す必要があり、S3 上のprovisioning_parameters.jsonに依存する従来方式は非互換 slurm.confの管理は merge 動作に固定され、パーティション関連のみ追記更新(手動編集を保持)- 管理の戦略を選ぶ
SlurmConfigStrategy(Managed・Overwrite・Merge)は指定不可(どの値でも API エラー) - API ベースの Slurm トポロジによるマルチヘッドノード構成は現状非対応
設定の追加
継続的プロビジョニングと MinCount は、API 主導型 Slurm 設定が前提となっています。S3 上の provisioning_parameters.json を編集する従来方式では設定できません。ライフサイクルスクリプトは引き続き S3 から読み込みます。
API 主導型 Slurm 設定の手順は、AWS CLI を使った別記事で紹介しています。詳細は以下を参照してください。
前提として NodeProvisioningMode を Continuous にします。そのうえで、対象のワーカーグループに MinInstanceCount を追加します。具体的には次のような設定です。
{
"InstanceGroupName": "worker-group-1",
"InstanceType": "ml.c5.xlarge",
+ "MinInstanceCount": 1,
"InstanceCount": 2,
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["p1"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://amzn-s3-demo-bucket",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "arn:aws:iam::111122223333:role/iam-role-for-cluster",
"ThreadsPerCore": 1
}
まとめ
MinCount は、継続的プロビジョニングでクラスターを早く立ち上げつつ、学習に使えない台数では InService としない制御ができます。3 時間で満たせなければ自動ロールバックするため、見込みのない状態で課金が続くことも防げます。GPU インスタンスのキャパシティ確保が難しい大規模な学習環境ではとくに有効な機能でした。
おわりに
Slurm クラスターという共通点から、AWS ParallelCluster と動作が似ているように見え調べていました。思いの外、違ったので整理したものをまとめました。
ParallelCluster でジョブ投入時にノードがそろわず待機する挙動は、Slurm ジョブのスケジューリングの話です。一方 HyperPod の MinCount は、クラスターのインスタンスグループをプロビジョニングする段階の話です。
ちなみに ParallelCluster の設定にも MinCount という名前のパラメータがあります。ParallelCluster の MinCount は常時起動する static ノードの数を指します。HyperPod の MinInstanceCount はインスタンスグループが InService に遷移するための最小台数です。名前が似ていますが意味が異なるため、私の様な ParallelCluster ユーザーは混同に注意してください。









