![[アップデート] SageMaker HyperPod に追加された G7e と r5d.16xlarge を動かしてみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[アップデート] SageMaker HyperPod に追加された G7e と r5d.16xlarge を動かしてみた
はじめに
2026 年 4 月 27 日、Amazon SageMaker HyperPod が ml.g7e シリーズと ml.r5d.16xlarge に対応しました。
G7e は NVIDIA RTX PRO 6000 Blackwell Server Edition GPU を搭載した推論向けインスタンスです。最大構成(g7e.48xlarge)では 1 ノードあたり 768 GB の GPU メモリ(96 GB × 8 基)を利用できます。
r5d.16xlarge は 64 vCPU / 512 GB メモリ / NVMe SSD を持つメモリ集約型インスタンスで、前処理や特徴量エンジニアリングに向いています。
この 2 種類を 1 つの HyperPod クラスターに混在させ、Slurm の gpu / cpu パーティションとして起動できるか確認しました。
確認結果
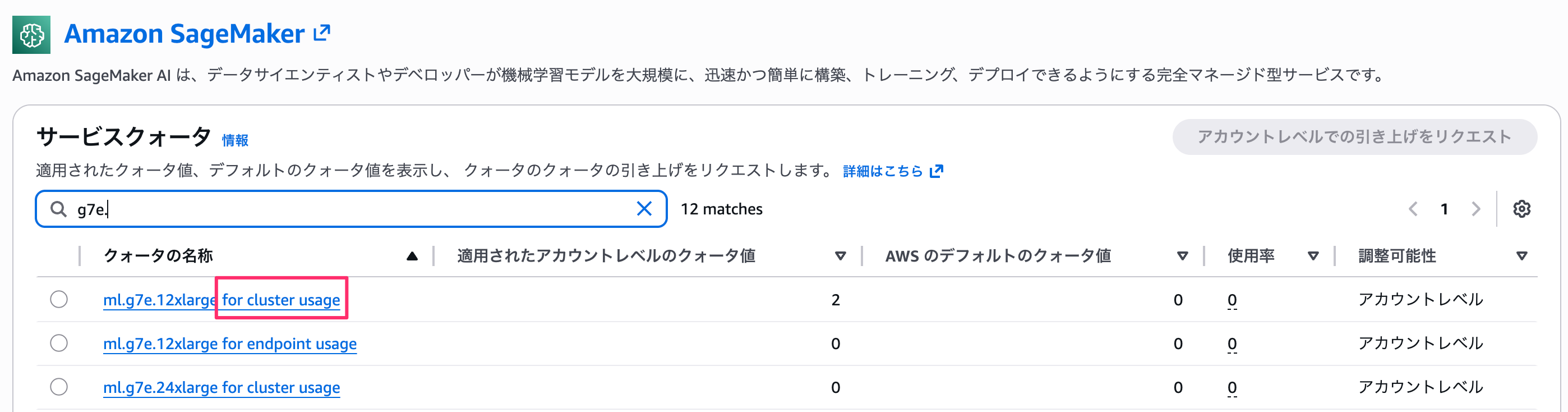
問題なく起動できました。該当のインスタンスのサービスクォータの初期値は 0 です。起動するときは事前に上限値を増やすことだけは気をつけてください。
アップデート内容
追加されたインスタンスタイプ
G7e は、NVIDIA RTX PRO 6000 Blackwell Server Edition GPU を搭載したインスタンスです。G6e 比で推論性能が最大 2.3 倍、最大構成(g7e.48xlarge)で 1 ノードあたり 768 GB の GPU メモリを利用できます。LLM のデプロイ、エージェンティック AI、マルチモーダル生成 AI 推論、中規模モデルのファインチューニングを主なワークロードとして想定しています。
HyperPod でサポートされる G7e のサイズは以下のとおりです。
| InstanceType | GPU 枚数 |
|---|---|
ml.g7e.2xlarge |
1 |
ml.g7e.4xlarge |
1 |
ml.g7e.8xlarge |
1 |
ml.g7e.12xlarge |
2 |
ml.g7e.24xlarge |
4 |
ml.g7e.48xlarge |
8 |
r5d.16xlarge は 64 vCPU / 512 GB メモリ / Intel Xeon Platinum プロセッサを搭載したインスタンスです。ストレージとして 4 台の NVMe SSD(各 600 GB、合計 2.4 TB)を持っています。なぜ今さら r5d の追加なのかわからないですけど要望があったのでしょう。
分散学習データの前処理、大規模特徴量エンジニアリング、メモリ集約的なオーケストレーションに適しています。
対応リージョン
| インスタンス | 対応リージョン |
|---|---|
| G7e | us-east-1 / us-east-2 / us-west-2 / ap-northeast-1(東京) |
| r5d.16xlarge | HyperPod が利用可能な全リージョン |
検証構成
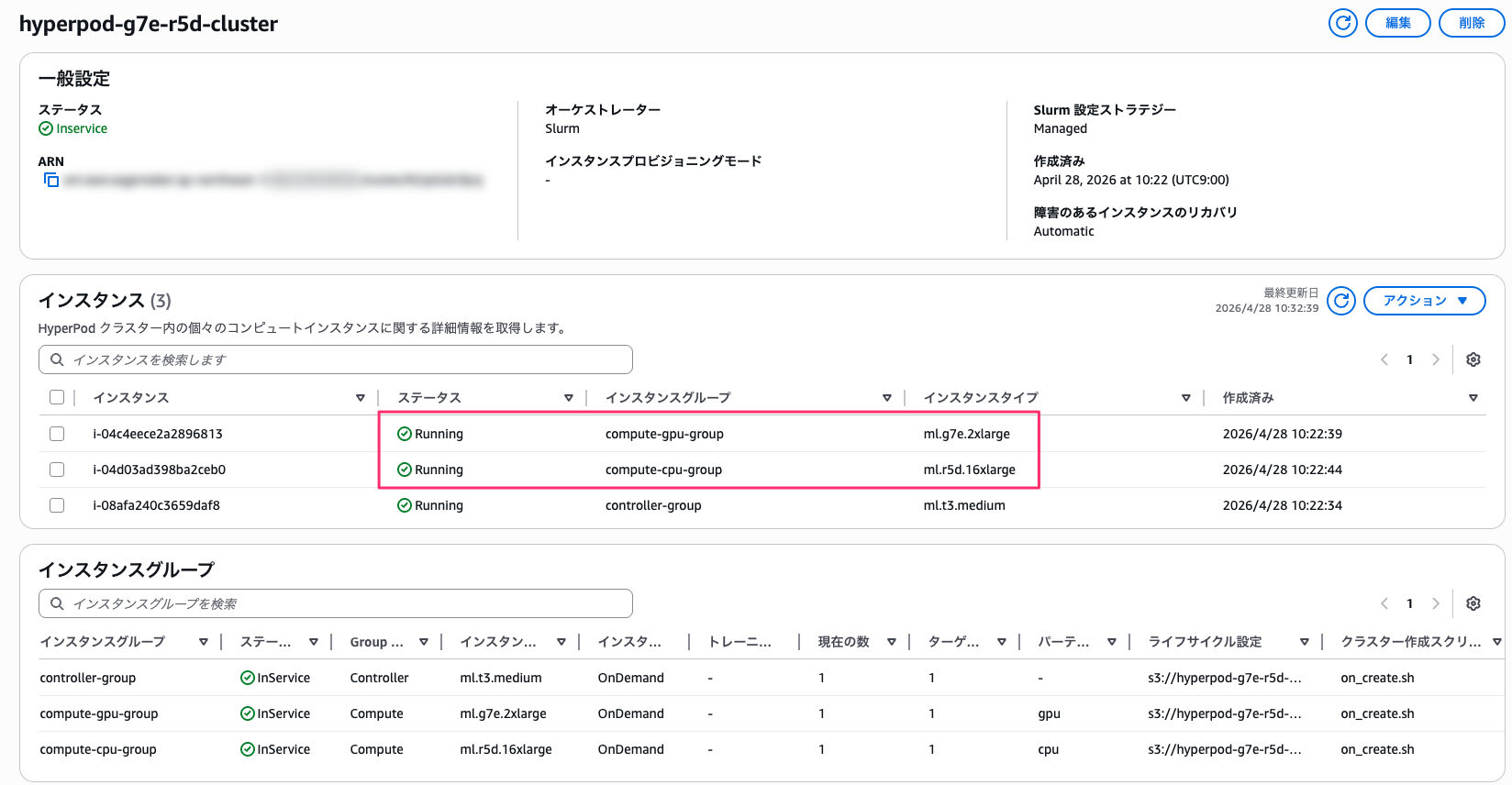
東京リージョンでコントローラー 1 台、G7e コンピュートノード 1 台、r5d.16xlarge コンピュートノード 1 台の計 3 ノード構成を組みました。クラスターは API 主導型 Slurm 設定(SlurmConfigStrategy: Managed)を使います。
| InstanceGroup | InstanceType | 台数 | Slurm パーティション |
|---|---|---|---|
controller-group |
ml.t3.medium |
1 | (コントローラー) |
compute-gpu-group |
ml.g7e.2xlarge |
1 | gpu |
compute-cpu-group |
ml.r5d.16xlarge |
1 | cpu |
クラスターの構築については以下記事を参照してください。
やってみた
CreateCluster の設定ファイル
クラスターの作成に使用した create_cluster.json の InstanceGroups の設定です。SlurmConfig.PartitionNames に gpu / cpu をそれぞれ指定することで、1 つのクラスターで 2 つのパーティションに分けています。
{
"ClusterName": "hyperpod-g7e-r5d-cluster",
"InstanceGroups": [
{
"InstanceGroupName": "controller-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "arn:aws:iam::123456789012:role/hyperpod-g7e-r5d-exec-role",
"SlurmConfig": {
"NodeType": "Controller"
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://hyperpod-g7e-r5d-lcc-07fd7298/base-config/",
"OnCreate": "on_create.sh"
}
},
{
"InstanceGroupName": "compute-gpu-group",
"InstanceType": "ml.g7e.2xlarge",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "arn:aws:iam::123456789012:role/hyperpod-g7e-r5d-exec-role",
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["gpu"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://hyperpod-g7e-r5d-lcc-07fd7298/base-config/",
"OnCreate": "on_create.sh"
}
},
{
"InstanceGroupName": "compute-cpu-group",
"InstanceType": "ml.r5d.16xlarge",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "arn:aws:iam::123456789012:role/hyperpod-g7e-r5d-exec-role",
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["cpu"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://hyperpod-g7e-r5d-lcc-07fd7298/base-config/",
"OnCreate": "on_create.sh"
}
}
],
"Orchestrator": {
"Slurm": {
"SlurmConfigStrategy": "Managed"
}
},
"VpcConfig": {
"SecurityGroupIds": ["sg-07e3b161544e56001"],
"Subnets": ["subnet-01c6b08828ab94db1"]
},
"Tags": [
{"Key": "Project", "Value": "hyperpod-g7e-r5d-blog"},
{"Key": "ManagedBy", "Value": "manual"}
]
}
クラスターを作成する
シンプルな構成なので 10 分ほどでデプロイできます。
aws sagemaker create-cluster \
--cli-input-json file://scripts/create_cluster.json \
--region ap-northeast-1
コンソールでクラスターの状態を確認する
クラスターがデプロイされました。今回のアップデートの確認対象である CPU/GPU のインスタンスグループも問題なく起動状態です。
コントローラーに SSM 接続して Slurm パーティションを確認する
コントローラーノードの Instance ID を取得し、Session Manager で接続します。
CONTROLLER_INSTANCE_ID=$(aws sagemaker list-cluster-nodes \
--cluster-name hyperpod-g7e-r5d-cluster \
--region ap-northeast-1 \
--query 'ClusterNodeSummaries[?InstanceGroupName==`controller-group`].InstanceId' \
--output text)
aws ssm start-session \
--target "sagemaker-cluster:hyperpod-g7e-r5d-cluster_controller-group-${CONTROLLER_INSTANCE_ID}" \
--region ap-northeast-1
パーティションの設定状況を確認してみます。
$ sinfo
gpu パーティションに 1 ノード、cpu パーティションに 1 ノードが idle で割り当てられています。dev は自動的に作成されるパーティションで、すべてのコンピュートノードが含まれたテスト用のパーティションです。
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
dev* up infinite 2 idle ip-10-0-1-[49,185]
gpu up infinite 1 idle ip-10-0-1-49
cpu up infinite 1 idle ip-10-0-1-185
各パーティションの詳細は scontrol show partition で確認できます。
scontrol show partition gpu
scontrol show partition cpu
gpu パーティションの抜粋です。TRES 行で gres/gpu=1 が認識されており、ml.g7e.2xlarge の GPU が Slurm 側で正しく扱える状態になっています。
PartitionName=gpu
Nodes=ip-10-0-1-49
State=UP TotalCPUs=4 TotalNodes=1
TRES=cpu=4,mem=64G,node=1,billing=4,gres/gpu=1
cpu パーティションの抜粋です。mem=512G が認識されており、ml.r5d.16xlarge のメモリリソースを Slurm がフルに認識しています。
PartitionName=cpu
Nodes=ip-10-0-1-185
State=UP TotalCPUs=32 TotalNodes=1
TRES=cpu=32,mem=512G,node=1,billing=32
GPU パーティションで nvidia-smi を実行する
gpu パーティションでジョブが GPU を確保できるかを srun で確認します。--gres=gpu:1 で GPU リソースを 1 基要求します。
srun --partition=gpu --gres=gpu:1 nvidia-smi
ml.g7e.2xlarge 上で実行された結果です。見切れていますがNVIDIA RTX PRO 6000 Blackwell Server Edition が認識されています。
Tue Apr 28 01:40:51 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX PRO 6000 Blac... On | 00000000:2B:00.0 Off | 0 |
| N/A 26C P8 29W / 600W | 0MiB / 97887MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
GPU に多少負荷を与えてみる
sbatch でバッチジョブとして PyTorch の matmul ベンチを流し、Blackwell GPU で実際に計算が回ることを確認します。
事前準備として、GPU ノードに PyTorch を導入します(HyperPod 標準 AMI には含まれていません)。pip install --user で /home/ubuntu/.local/ に入れます。
srun --partition=gpu --gres=gpu:1 pip install --user numpy torch --quiet
ジョブスクリプトを用意します。FP32 / BF16 / FP16 の 3 種類で 8192 × 8192 行列積を 50 回繰り返し、TFLOPS を計測します。
gpu_bench.sbatch(全文)
cat > ~/gpu_bench.sbatch << 'EOF'
#!/bin/bash
#SBATCH --job-name=gpu-bench
#SBATCH --partition=gpu
#SBATCH --gres=gpu:1
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=4
#SBATCH --time=00:05:00
#SBATCH --output=gpu-bench-%j.out
set -euo pipefail
echo "=== Job: ${SLURM_JOB_ID} on $(hostname) ==="
date
nvidia-smi --query-gpu=name,driver_version,memory.total --format=csv
echo ""
echo "=== PyTorch matmul benchmark ==="
python3 - <<'PY'
import time
import torch
assert torch.cuda.is_available(), "CUDA not available"
device = torch.device("cuda")
print("Device:", torch.cuda.get_device_name(0))
print("PyTorch:", torch.__version__, "CUDA:", torch.version.cuda)
torch.manual_seed(0)
def bench(dtype, size=8192, iters=50, warmup=5):
a = torch.randn(size, size, device=device, dtype=dtype)
b = torch.randn(size, size, device=device, dtype=dtype)
for _ in range(warmup):
c = a @ b
torch.cuda.synchronize()
t0 = time.time()
for _ in range(iters):
c = a @ b
torch.cuda.synchronize()
elapsed = time.time() - t0
tflops = 2 * size ** 3 * iters / elapsed / 1e12
print(f" {str(dtype):20s} size={size}x{size} iters={iters} elapsed={elapsed:6.2f}s perf={tflops:7.2f} TFLOPS")
print("\n[FP32]")
bench(torch.float32)
print("\n[BF16]")
bench(torch.bfloat16)
print("\n[FP16]")
bench(torch.float16)
PY
echo ""
echo "=== nvidia-smi after benchmark ==="
nvidia-smi
date
EOF
sbatch ~/gpu_bench.sbatch
ジョブが投入されたら squeue で実行状況を確認します。
squeue
R(Running)になり、実行ノードが ip-10-0-1-49(g7e.2xlarge)であることが分かります。
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
8 gpu gpu-benc ubuntu R 0:02 1 ip-10-0-1-49
ジョブの出力結果から、8192 × 8192 の行列積を Blackwell の Tensor Core で動かしたところ、FP32 で 75 TFLOPS 級を観測しました。BF16 / FP16 では 400 TFLOPS 級まで上がります。数値は実装・ビルドの最適化次第で変動するため、「Slurm ジョブとして PyTorch + CUDA + Blackwell GPU が動く」ことの確認結果としてみてください。
=== Job: 8 on ip-10-0-1-49 ===
name, driver_version, memory.total [MiB]
NVIDIA RTX PRO 6000 Blackwell Server Edition, 580.126.09, 97887 MiB
=== PyTorch matmul benchmark ===
Device: NVIDIA RTX PRO 6000 Blackwell Server Edition
PyTorch: 2.11.0+cu130 CUDA: 13.0
[FP32]
torch.float32 size=8192x8192 iters=50 elapsed= 0.73s perf= 75.54 TFLOPS
[BF16]
torch.bfloat16 size=8192x8192 iters=50 elapsed= 0.13s perf= 427.56 TFLOPS
[FP16]
torch.float16 size=8192x8192 iters=50 elapsed= 0.13s perf= 416.35 TFLOPS
ベンチマーク直後の nvidia-smi では消費電力が 385W / 600W、温度がアイドル時の 26°C から 33°C に上昇しており、GPU に負荷がかかっていた証拠と言えるでしょう。
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
|=========================================+========================+======================|
| 0 NVIDIA RTX PRO 6000 Blac... On | 00000000:2B:00.0 Off | 0 |
| N/A 33C P0 385W / 600W | 0MiB / 97887MiB | 16% Default |
+-----------------------------------------+------------------------+----------------------+
さいごに
検証の結果、gpu パーティションで G7e の GPU(96 GB / CUDA 13.0)が動作することを確認できました。cpu パーティションでは r5d.16xlarge の 512 GB メモリが Slurm 側で認識されました。
G7e の追加により、東京リージョンで HyperPod を使ったメモリリッチな GPU 推論環境を組めるようになりました。GPU 難なご時世ですし、P 系よりも安価な価格の GPU インスタンスが HyperPod に対応したのはありがたいですね。










