
S3 Glacier 系ストレージクラスのデータを Athena からクエリする時の挙動を確認した
コーヒーが好きな emi です。最近はカフェインを控えています。
Athena でクエリしている S3 のデータで、アクセス頻度が下がる古いものを Glacier ストレージクラスに移動させたい要件がありました。Glacier 系のストレージクラスのデータを Athena からクエリする際の挙動がどうなるか検証しましたので、結果を記載します。
先にまとめ
- S3 Glacier Deep Archive の場合
- Athena でクエリを発行してもデータは取得されず、スキャンもされない(Athena スキャン料金削減が可能)
- S3 Glacier Flexible Retrieval (旧 Glacier) の場合
- Athena でクエリを発行してもデータは取得されず、スキャンもされない(Athena スキャン料金削減が可能)
- S3 Glacier Instant Retrieval の場合
- Athena でクエリを発行するとデータが取得できる
- 取り出し料金が発生する
検証イメージ
以下のように S3 プレフィックス(フォルダ)で日付による階層構造を表現してデータを格納し、Athena の Partition Projection で特定の期間のみクエリできるようにテーブルを作成します。
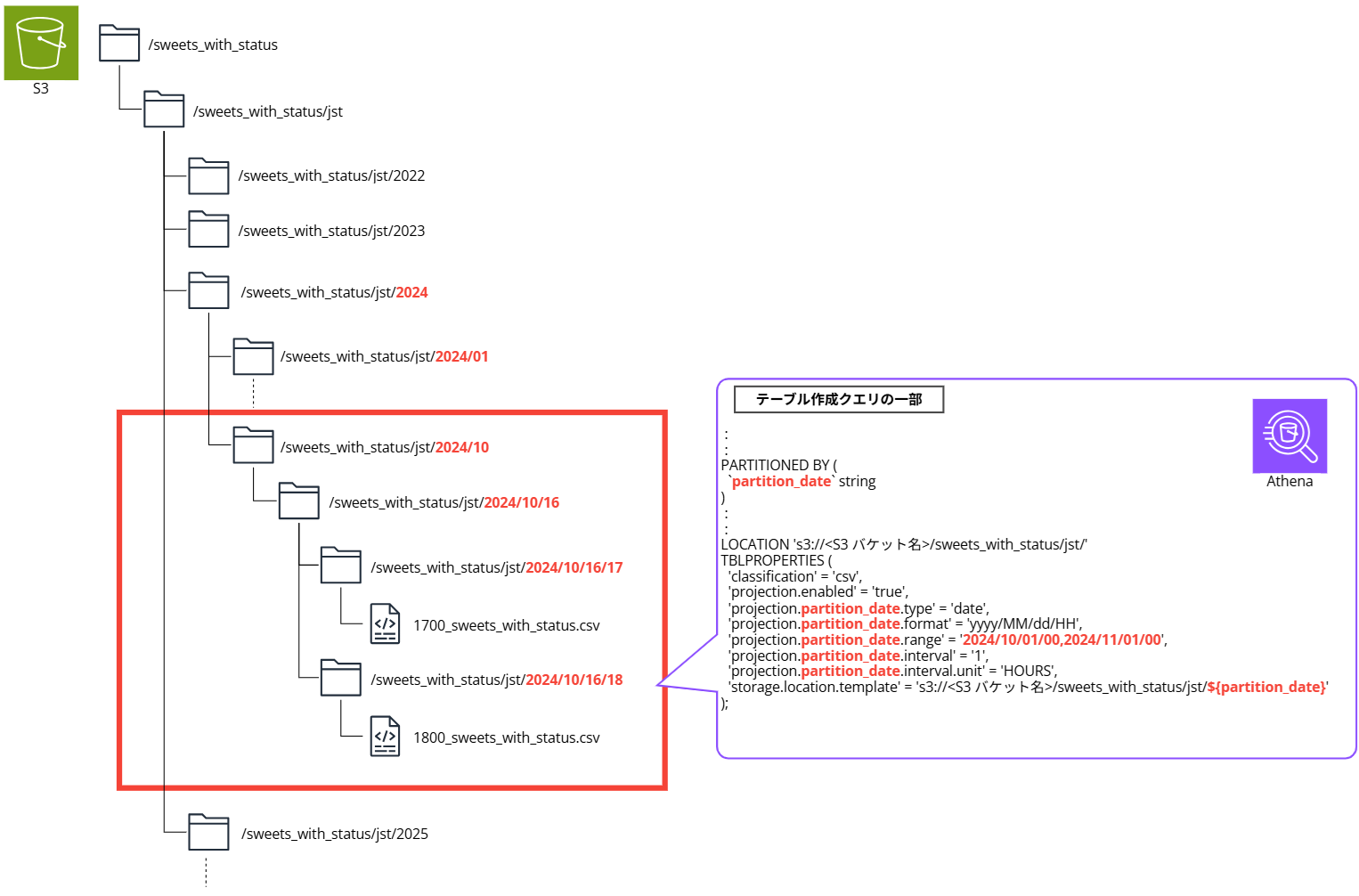
Partition Projection については以下のブログも参照ください。
Partition Projection でクエリする範囲のデータで、一部を Glacier 系のストレージクラスに変更し、クエリできるか検証します。
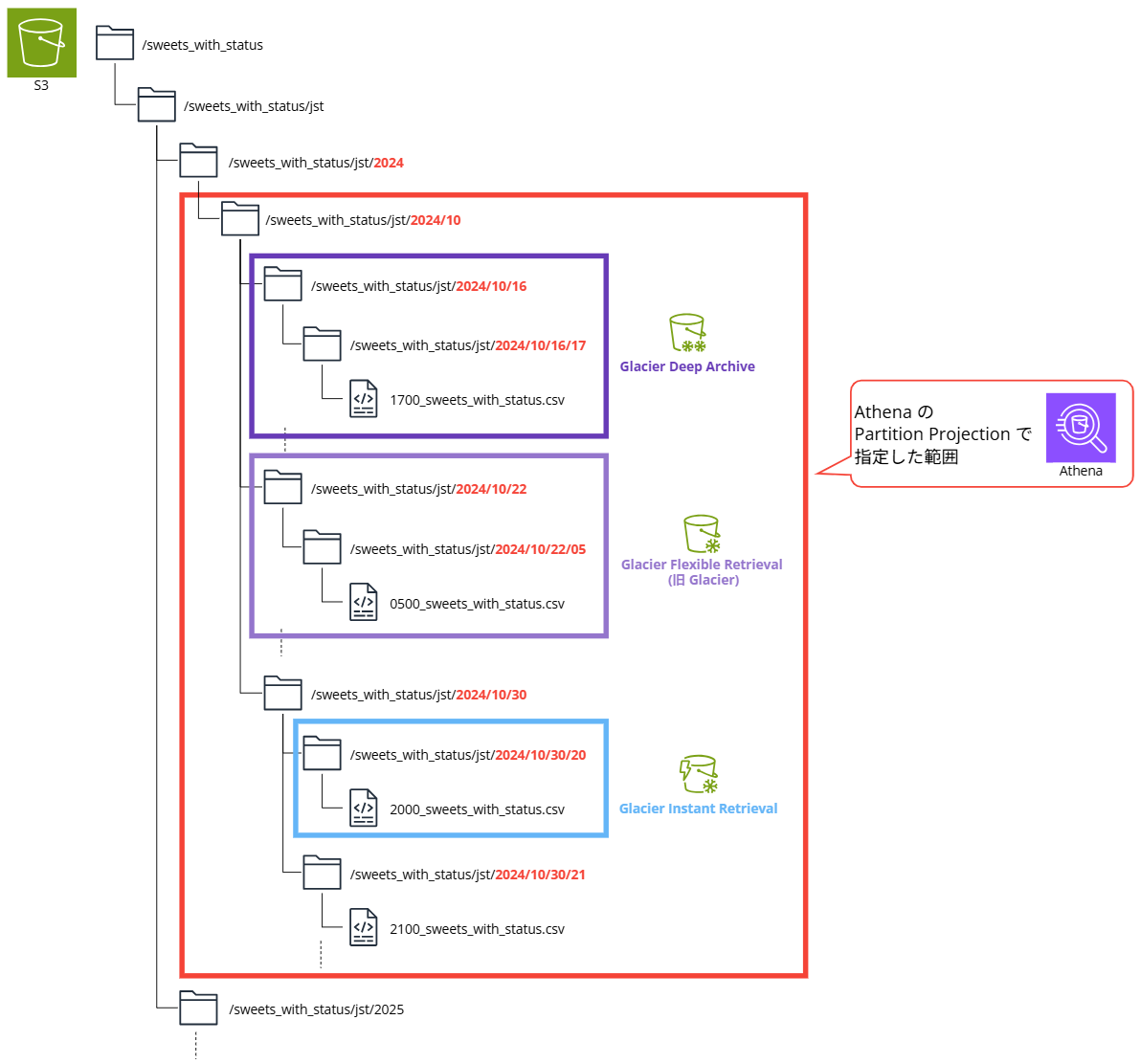
S3 ストレージクラスのおさらい
S3 Glacier Deep Archive
| S3 ストレージクラス | S3 Glacier Deep Archive |
|---|---|
| 特徴・用途 | アクセスがほとんどなく、取り出しに時間がかかる長期間保存データ |
| 保存データの例 | ・コンプライアンス要件により7~10 年以上保管の必要があるデータ ・バックアップや災害対策 ・磁気テープのデータ |
| データが保存される AZ | 3AZ 以上 |
| ストレージ料金 | すべてのストレージクラスの中で最も低額 |
| 取り出し料金 | ・標準:高額 ・大容量:低額 |
| 取り出しにかかる時間 | ・標準:12 時間以内 ・大容量:48 時間以内 |
データ取得の前に、別途取り出し操作が必要です。
S3 Glacier Flexible Retrieval
| S3 ストレージクラス | S3 Glacier Flexible Retrieval |
|---|---|
| 特徴・用途 | ・アクセスがほとんどなく、必要に応じて取り出し方法を柔軟に選択できる長期間保存データ ・すぐにアクセスする必要がない場合、大量データの無料取り出しも可能 |
| 保存データの例 | バックアップ、災害対策、オフサイトのデータストレージなど |
| データが保存される AZ | 3AZ 以上 |
| ストレージ料金 | S3 Glacier Instant Retrieval より低額 |
| 取り出し料金 | ・迅速:高額 ・標準:低額 ・大容量:無料 |
| 取り出しにかかる時間 | ・迅速:1~5 分 ・標準:3~5 時間 ・大容量:5~12 時間 |
データ取得の前に、別途取り出し操作が必要です。
S3 Glacier Instant Retrieval
| S3 ストレージクラス | S3 Glacier Instant Retrieval |
|---|---|
| 特徴・用途 | アクセスはほとんどないが、即時取り出しが必要な長期間保存データ |
| 保存データの例 | 医療画像、メディアアセットなど |
| データが保存される AZ | 3AZ 以上 |
| ストレージ料金 | S3 1 ゾーン IA より低額 |
| 取り出し料金 | S3 1 ゾーン IA より高額 |
| 取り出しにかかる時間 | 即時取り出し可能 |
取り出し操作不要で、データ取得できます。
やってみる
すべてのデータが S3 Standard に格納されている状態
以下のような CSV ファイルを S3 Standard に格納しています。
datetime,department,section,status,chocolate,donut,osenbei
2024-10-16 17:00:00.000,コンピューティング部,EC2課,不調,19,1,20
2024-10-16 17:00:00.000,コンピューティング部,Lambda課,不調,12,4,22
2024-10-16 17:00:00.000,コンピューティング部,Lightsail課,不調,13,3,24
2024-10-16 17:00:00.000,ストレージ部,EFS課,超ごきげん,18,7,29
2024-10-16 17:00:00.000,ストレージ部,FSx課,ごきげん,18,1,24
2024-10-16 17:00:00.000,ストレージ部,S3課,不調,15,2,20
2024-10-16 17:00:00.000,データベース部,RDS課,普通,14,2,28
2024-10-16 17:00:00.000,データベース部,DocumentDB課,不調,19,7,29
2024-10-16 17:00:00.000,データベース部,DynamoDB課,超ごきげん,11,2,24
S3 の構造はこんな感じです。
└── sweets_with_status
└── jst
└── 2024
└── 10
├── 16
│ ├── 17
│ │ └── 1700_sweets_with_status.csv
│ ├── 18
│ │ └── 1800_sweets_with_status.csv
│ └── 19
│ └── 1900_sweets_with_status.csv
├── 21
├── 22
│ └── 05
│ └── 0500_sweets_with_status.csv
└── 30
├── 20
│ └── 2000_sweets_with_status.csv
├── 21
│ └── 2100_sweets_with_status.csv
├── 22
│ └── 2200_sweets_with_status.csv
└── 23
└── 2300_sweets_with_status.csv
tree 構造の取得方法
以下ブログの手順の通りに WSL と VSCode を導入し、WSL 内に AWS CLI コマンドをインストールしています。
以下ブログの手順でプロファイルを設定し、検証用 AWS アカウントにスイッチロールしています。
treeコマンドをインストール
sudo apt update && sudo apt install -y tree
▼実行結果
emiki@HL01290:~/work$ sudo apt update && sudo apt install -y tree
[sudo] password for emiki:
Get:1 https://deb.nodesource.com/node_22.x nodistro InRelease [12.1 kB]
Get:2 https://deb.nodesource.com/node_22.x nodistro/main amd64 Packages [7417 B]
Get:3 http://security.ubuntu.com/ubuntu jammy-security InRelease [129 kB]
Hit:4 http://archive.ubuntu.com/ubuntu jammy InRelease
Get:5 http://archive.ubuntu.com/ubuntu jammy-updates InRelease [128 kB]
Get:6 http://security.ubuntu.com/ubuntu jammy-security/main amd64 Packages [2557 kB]
Get:7 http://archive.ubuntu.com/ubuntu jammy-backports InRelease [127 kB]
Get:8 http://archive.ubuntu.com/ubuntu jammy-updates/main amd64 Packages [2802 kB]
Get:9 http://security.ubuntu.com/ubuntu jammy-security/main Translation-en [379 kB]
Get:10 http://security.ubuntu.com/ubuntu jammy-security/restricted amd64 Packages [4013 kB]
Get:11 http://archive.ubuntu.com/ubuntu jammy-updates/main Translation-en [443 kB]
Get:12 http://security.ubuntu.com/ubuntu jammy-security/restricted Translation-en [729 kB]
Get:13 http://archive.ubuntu.com/ubuntu jammy-updates/restricted amd64 Packages [4157 kB]
Get:14 http://security.ubuntu.com/ubuntu jammy-security/universe amd64 Packages [993 kB]
Get:15 http://security.ubuntu.com/ubuntu jammy-security/universe Translation-en [217 kB]
Get:16 http://archive.ubuntu.com/ubuntu jammy-updates/restricted Translation-en [753 kB]
Get:17 http://archive.ubuntu.com/ubuntu jammy-updates/universe amd64 Packages [1226 kB]
Get:18 http://archive.ubuntu.com/ubuntu jammy-updates/universe Translation-en [304 kB]
Get:19 http://archive.ubuntu.com/ubuntu jammy-updates/multiverse amd64 Packages [59.5 kB]
Get:20 http://archive.ubuntu.com/ubuntu jammy-updates/multiverse Translation-en [14.2 kB]
Get:21 http://archive.ubuntu.com/ubuntu jammy-backports/main amd64 Packages [68.8 kB]
Get:22 http://archive.ubuntu.com/ubuntu jammy-backports/universe amd64 Packages [30.0 kB]
Get:23 http://archive.ubuntu.com/ubuntu jammy-backports/universe Translation-en [16.5 kB]
Fetched 19.2 MB in 6s (3247 kB/s)
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
45 packages can be upgraded. Run 'apt list --upgradable' to see them.
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following NEW packages will be installed:
tree
0 upgraded, 1 newly installed, 0 to remove and 45 not upgraded.
Need to get 47.9 kB of archives.
After this operation, 116 kB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu jammy/universe amd64 tree amd64 2.0.2-1 [47.9 kB]
Fetched 47.9 kB in 1s (42.3 kB/s)
Selecting previously unselected package tree.
(Reading database ... 57389 files and directories currently installed.)
Preparing to unpack .../tree_2.0.2-1_amd64.deb ...
Unpacking tree (2.0.2-1) ...
Setting up tree (2.0.2-1) ...
Processing triggers for man-db (2.10.2-1) ...
emiki@HL01290:~/work$
ローカルに S3 構造を作成
~/work/blog/AthenaS3というフォルダを作成し移動しておく- 以下コマンドでローカルに S3 のデータをコピー
mkdir -p ./s3_structure
aws s3 ls s3://qs-athena-test-csv-emikitani --recursive | awk '{print $4}' | while read file; do
mkdir -p "./s3_structure/$(dirname "$file")"
touch "./s3_structure/$file"
done
▼実行結果
emiki@HL01290:~/work/blog/AthenaS3$ mkdir -p ./s3_structure
aws s3 ls s3://qs-athena-test-csv-emikitani --recursive | awk '{print $4}' | while read file; do
mkdir -p "./s3_structure/$(dirname "$file")"
touch "./s3_structure/$file"
done
touch: setting times of './s3_structure/sweets_with_status/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/16/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/16/17/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/16/18/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/16/19/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/21/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/21/11/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/22/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/22/05/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/30/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/30/20/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/30/21/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/30/22/': No such file or directory
touch: setting times of './s3_structure/sweets_with_status/jst/2024/10/30/23/': No such file or directory
emiki@HL01290:~/work/blog/AthenaS3$
コマンドの解説
mkdir -p ./s3_structure- 現在のフォルダに
s3_structureという新しいフォルダを作成
- 現在のフォルダに
aws s3 ls s3://qs-athena-test-csv-emikitani --recursive | awk '{print $4}'- S3バケットの全ファイル・フォルダを一覧表示
awk '{print $4}'でファイルパス部分だけを抽出- 例:
sweets_with_status/jst/2024/10/16/17/1700_sweets_with_status.csv
- 例:
while read file; do ... done- 各ファイルパスに対して以下を実行
mkdir -p "./s3_structure/$(dirname "$file")"- ファイルが入るフォルダを作成
- 例:
./s3_structure/sweets_with_status/jst/2024/10/16/17/
- 例:
- ファイルが入るフォルダを作成
touch "./s3_structure/$file"- 空のファイルを作成
- 例:
./s3_structure/sweets_with_status/jst/2024/10/16/17/1700_sweets_with_status.csv
- 例:
- 空のファイルを作成
- 各ファイルパスに対して以下を実行
ツリー表示
tree ./s3_structure
▼実行結果
emiki@HL01290:~/work/blog/AthenaS3$ tree ./s3_structure
./s3_structure
└── sweets_with_status
└── jst
└── 2024
└── 10
├── 16
│ ├── 17
│ │ └── 1700_sweets_with_status.csv
│ ├── 18
│ │ └── 1800_sweets_with_status.csv
│ └── 19
│ └── 1900_sweets_with_status.csv
├── 21
├── 22
│ └── 05
│ └── 0500_sweets_with_status.csv
└── 30
├── 20
│ └── 2000_sweets_with_status.csv
├── 21
│ └── 2100_sweets_with_status.csv
├── 22
│ └── 2200_sweets_with_status.csv
└── 23
└── 2300_sweets_with_status.csv
16 directories, 8 files
emiki@HL01290:~/work/blog/AthenaS3$
作業用ファイルの削除(コピーした S3 構造を削除)
rm -rf ./s3_structure
▼実行結果
emiki@HL01290:~/work/blog/AthenaS3$ rm -rf ./s3_structure
削除確認
ls -la ./s3_structure
▼実行結果
emiki@HL01290:~/work/blog/AthenaS3$ ls -la ./s3_structure
ls: cannot access './s3_structure': No such file or directory
emiki@HL01290:~/work/blog/AthenaS3$
=== tree 構造の取得方法ここまで ===
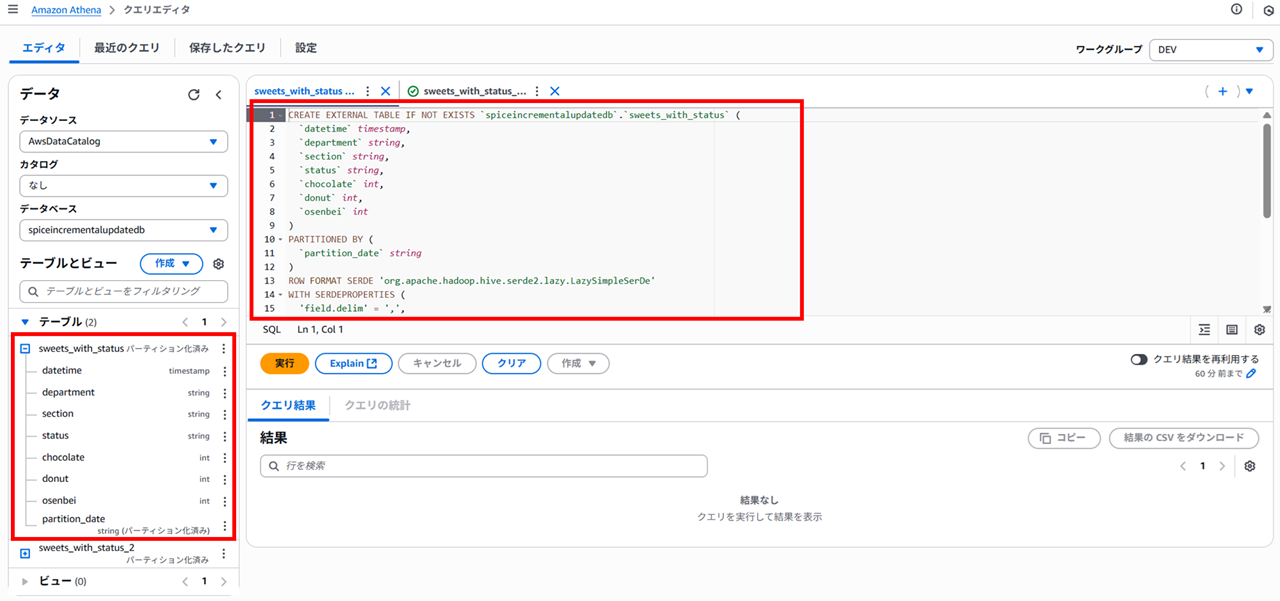
Athena で S3 構造を取得するテーブルを作成しておきます。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status` (
`datetime` timestamp,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://qs-athena-test-csv-emikitani/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/01/00,2024/11/01/00',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://qs-athena-test-csv-emikitani/sweets_with_status/jst/${partition_date}'
);
range の指定は以下ブログも参考にしてください。
続いて Athena で作成したテーブルに対し、select クエリを発行し S3 のデータを取得します。
SELECT
date_parse(partition_date, '%Y/%m/%d/%H') AS formatted_date,
department,
section,
status,
donut
FROM
spiceincrementalupdatedb.sweets_with_status
GROUP BY
partition_date,
department,
section,
status,
donut
ORDER BY
formatted_date,
department,
section
以下のように結果が得られました。
- キュー内の時間:102 ms
- 実行時間:11.878 sec
- スキャンしたデータ:5.96 KB
- 結果:72(行)
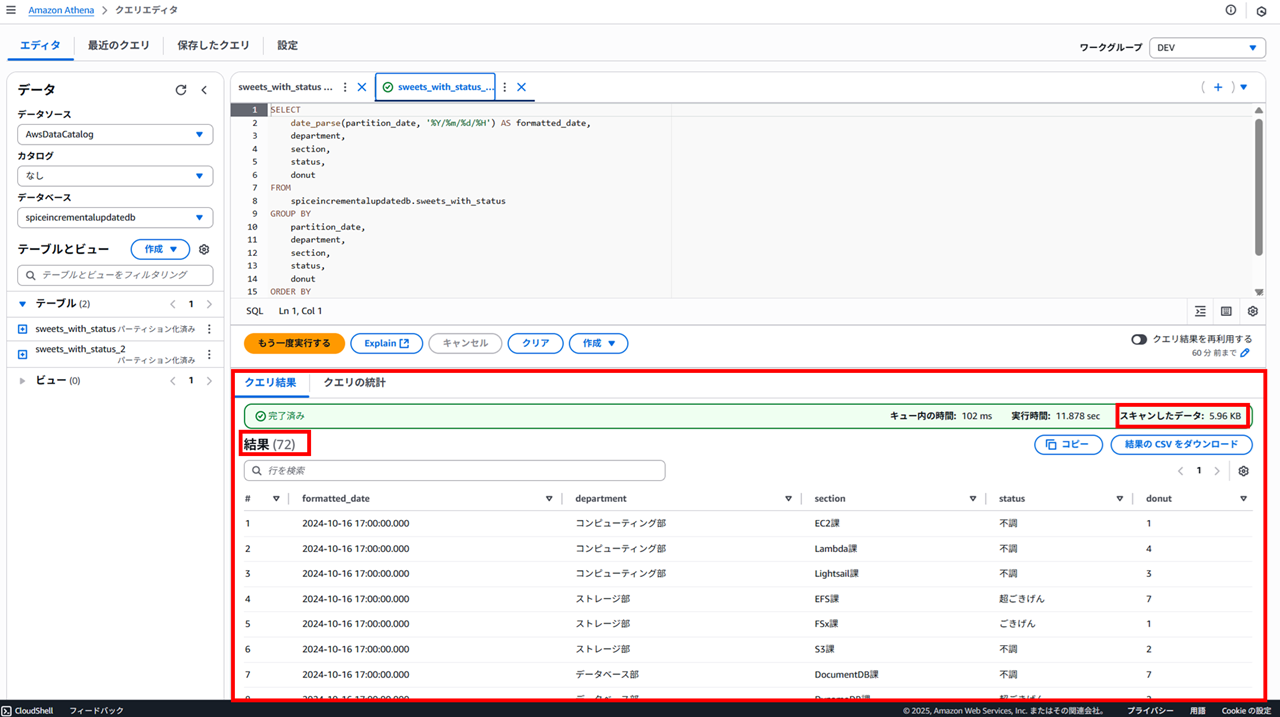
一部のデータを S3 Glacier Deep Archive に移動
2024/10/16 のデータを S3 Glacier Deep Archive に移動します。
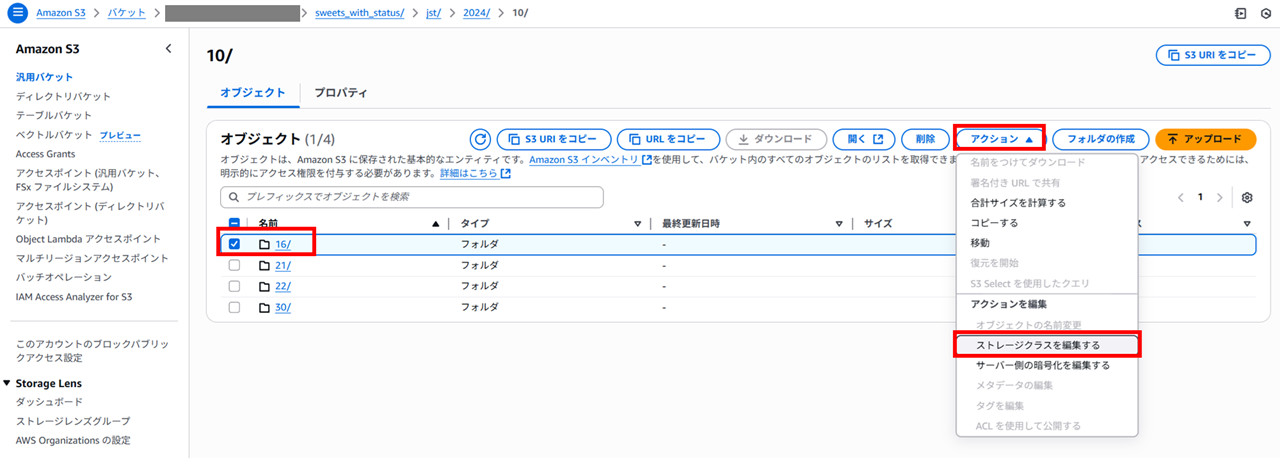
以下のようにストレージクラスが選択できます。
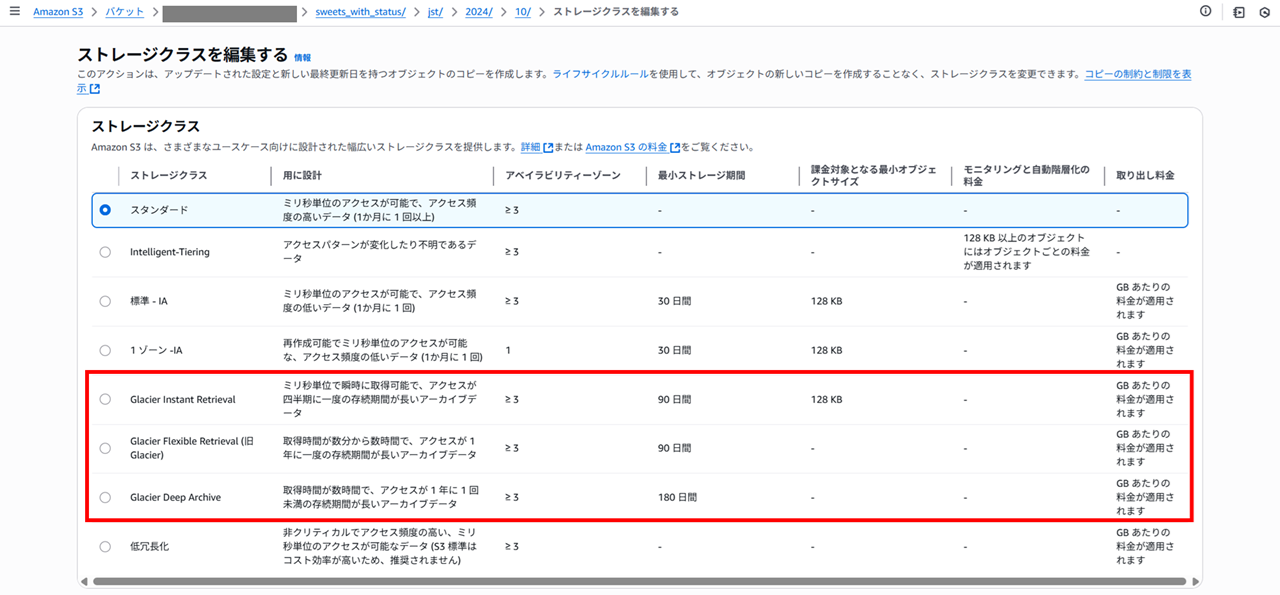
(おさらい)低冗長化ストレージクラスとは
一番下の 「低冗長化」 って何だっけ?と思い、調べました。マネジメントコンソールの表示言語を英語にして確認してみます。
言語を変えるとエラーになるので、S3 の階層構造のリンクをクリックして再表示します。

「Reduced Redundancy」 となっています。思い出してきました。昔存在していた RRS というストレージクラスのことですね。
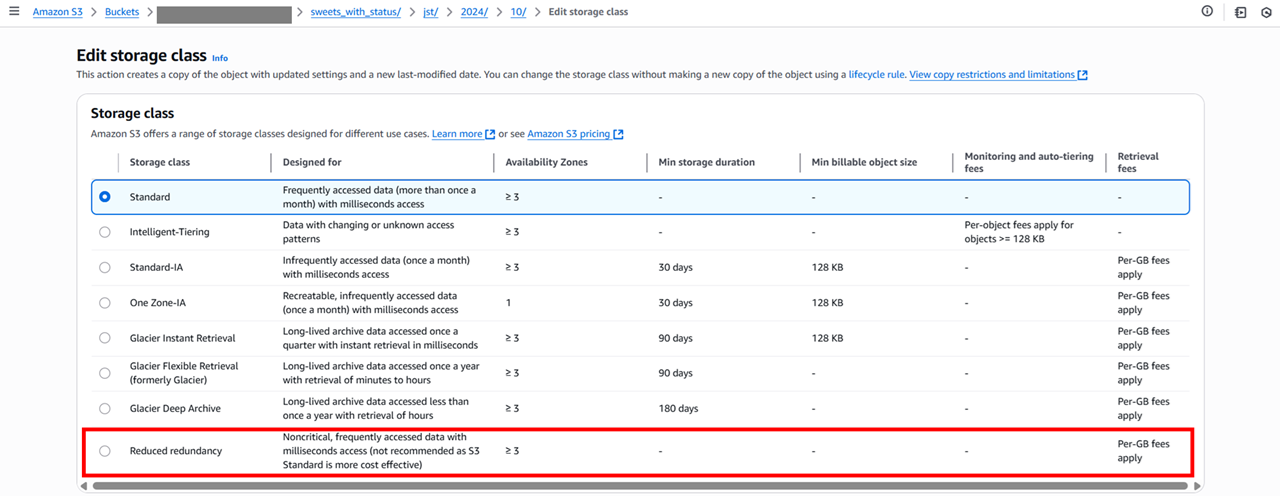
以下のページには書いてないストレージクラスです。
以下のストレージクラスです。S3 Standard が値下げされたことによりアクセスは遅く Standard より料金が高くなってしまっている非推奨ストレージのことでした。
確かに 非クリティカルでアクセス頻度の高い、ミリ秒単位のアクセスが可能なデータ (S3 標準はコスト効率が高いため、推奨されません) と書かれていますね。
=== (おさらい)低冗長化ストレージクラスとは ここまで ===
Glacier Deep Archive を選択して変更します。
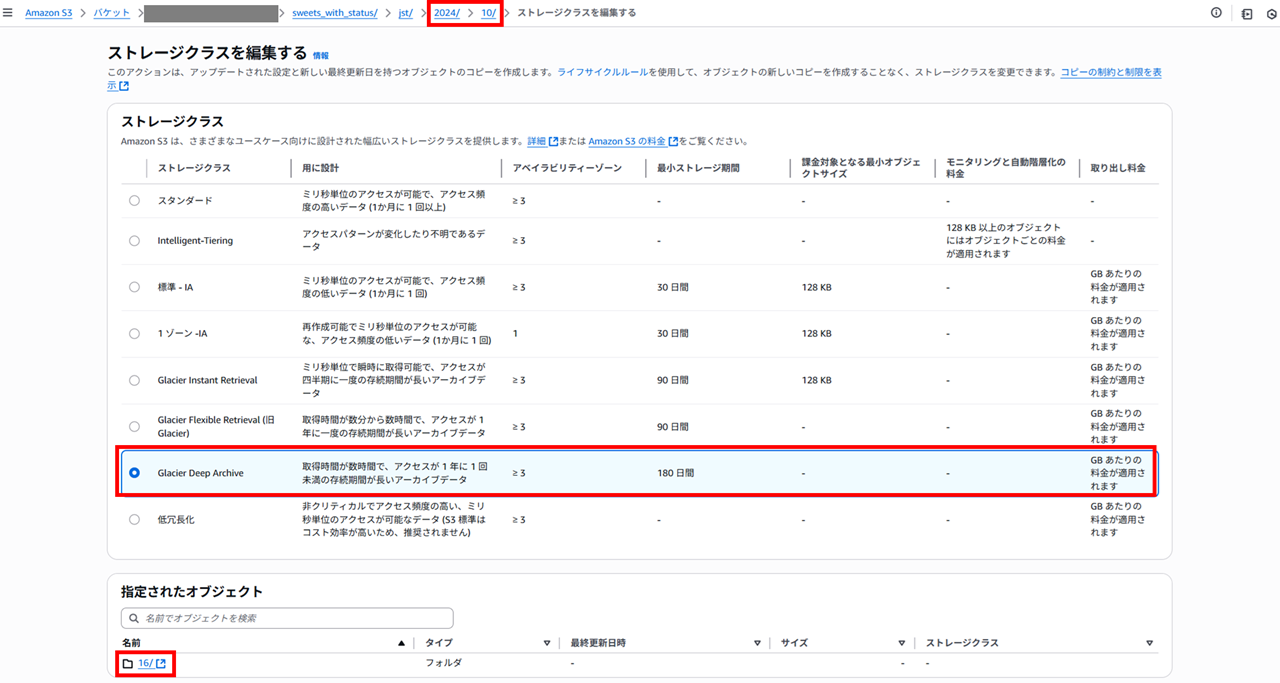
その他のコピー設定は 「ソース設定をコピー」 のまま、変更を保存します。

変更されました。
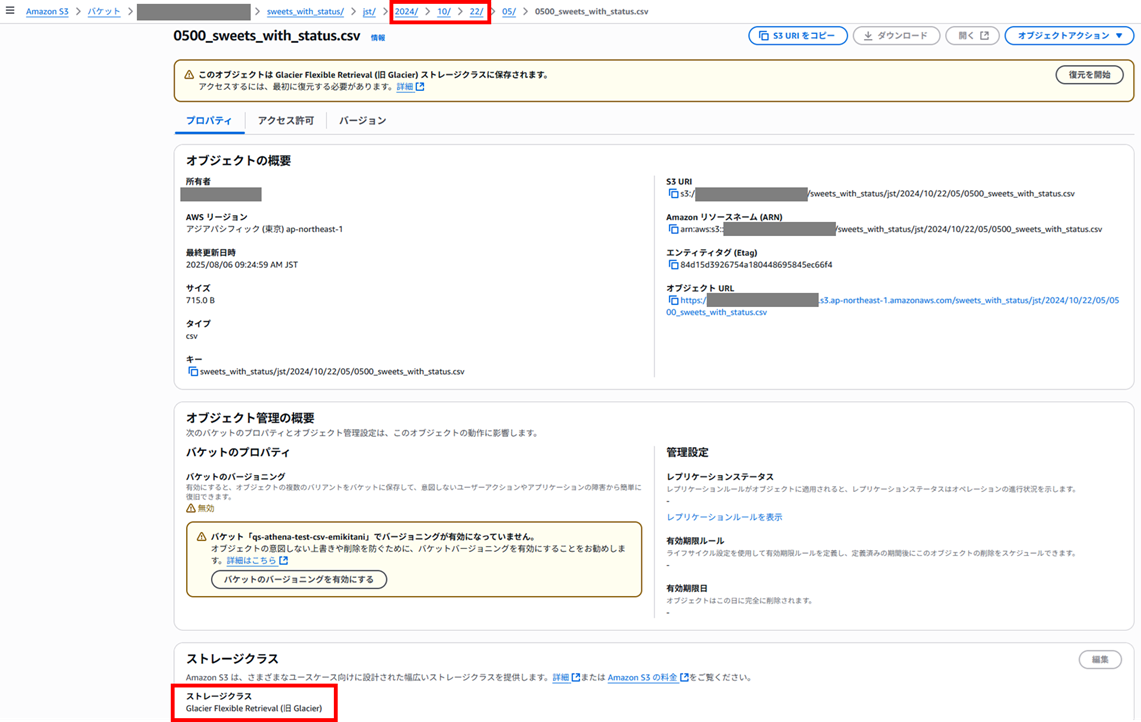
オブジェクトを確認すると、ストレージクラスが Glacier Deep Archive となっていることが確認できます。
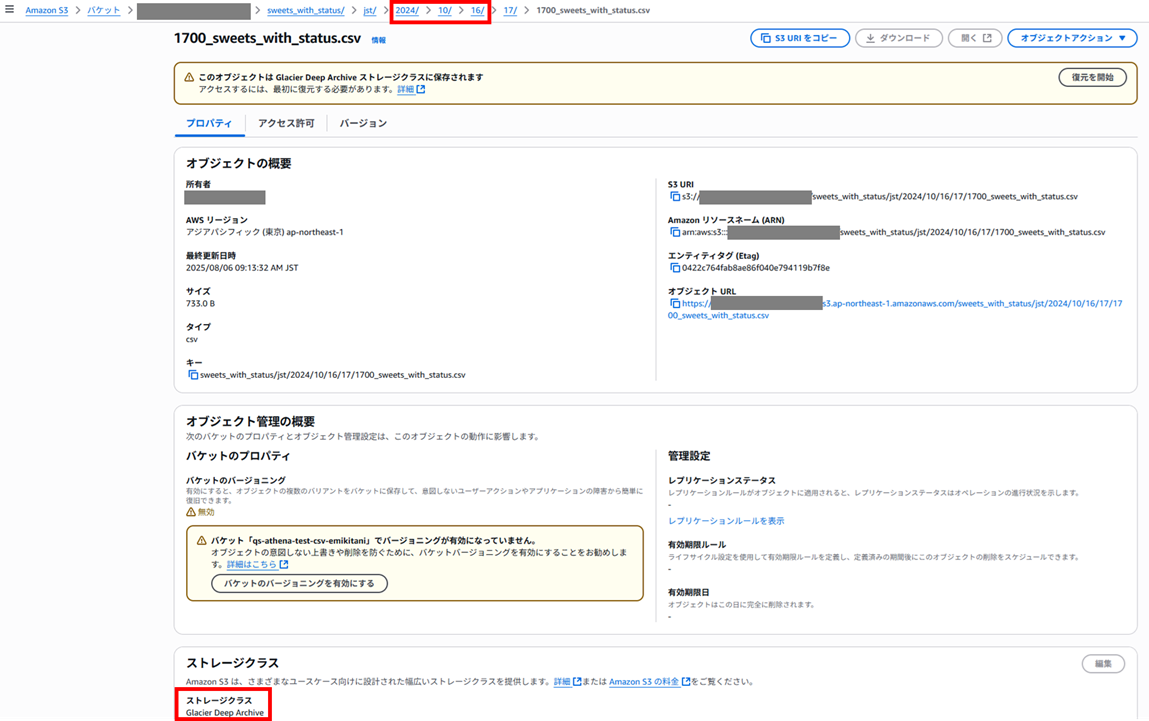
では、Athena から先ほどと同じ select クエリを実行し、データを取得します。
以下のように結果が得られました。
- キュー内の時間:139 ms
- 実行時間:11.031 sec
- スキャンしたデータ:3.78 KB
- 結果:45(行)
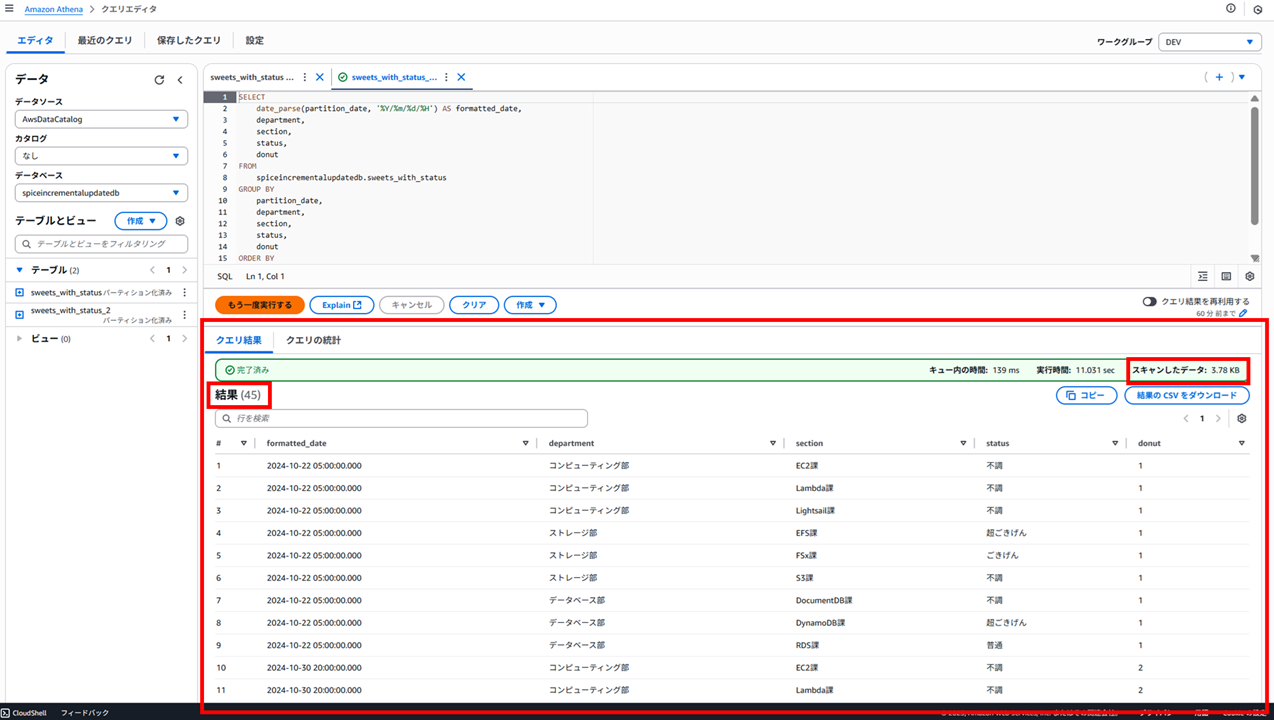
結果の日付を見ると、Glacier Deep Archive に変更した 2024/10/16 のデータが取得されていないことが分かります。また、スキャンしたデータ量も減っています。
どうやら Glacier Deep Archive のデータはそもそもスキャンされない挙動になるようです。
一部のデータを Glacier Flexible Retrieval (旧 Glacier) に移動
続いて 2024/10/22 のデータを S3 Glacier Flexible Retrieval (旧 Glacier) に移動します。
では、Athena から先ほどと同じ select クエリを実行し、データを取得します。
以下のように結果が得られました。
- キュー内の時間:58 ms
- 実行時間:11.552 sec
- スキャンしたデータ:3.09 KB
- 結果:36(行)
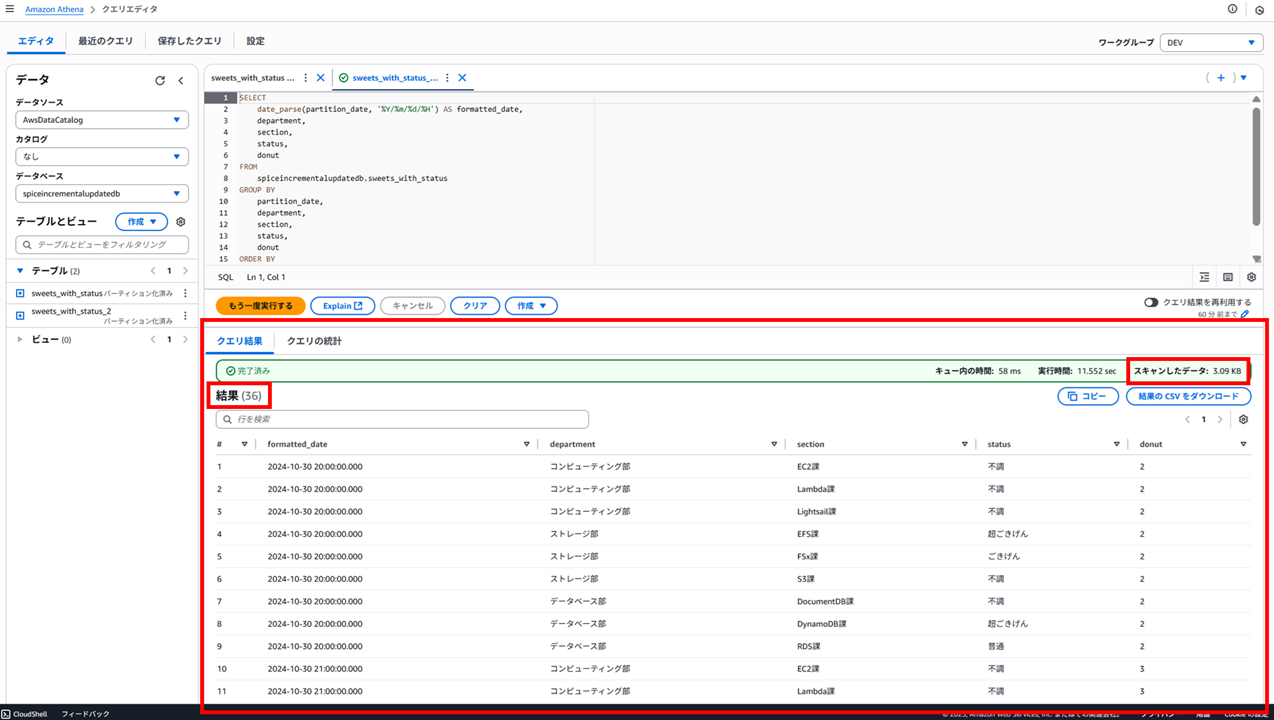
結果の日付を見ると、Glacier Flexible Retrieval (旧 Glacier) に変更した 2024/10/22 のデータが取得されていないことが分かります。また、スキャンしたデータ量も減っています。
Glacier Deep Archive と同様、Glacier Flexible Retrieval (旧 Glacier) のデータはそもそもスキャンされない挙動になるようです。
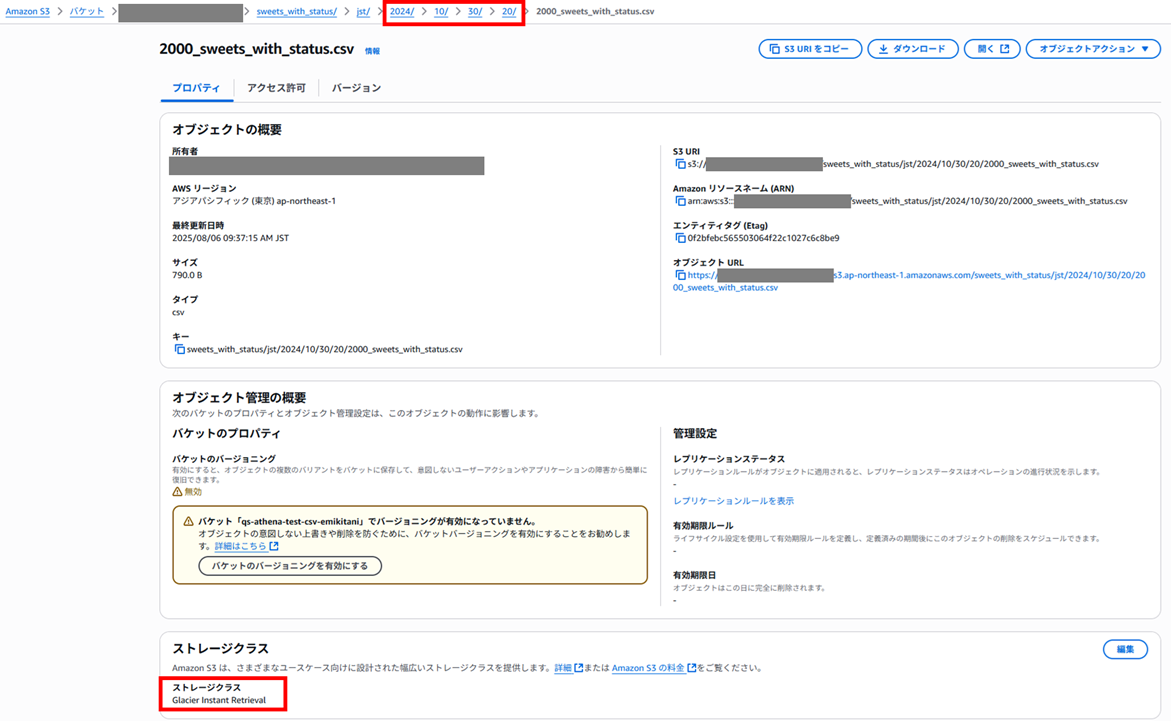
一部のデータを Glacier Instant Retrieval に移動
最後に 2024/10/30 20:00 のデータを S3 Glacier Instant Retrieval に移動します。
では、Athena から先ほどと同じ select クエリを実行し、データを取得します。
以下のように結果が得られました。
- キュー内の時間:112 ms
- 実行時間:11.568 sec
- スキャンしたデータ:3.09 KB
- 結果:36(行)
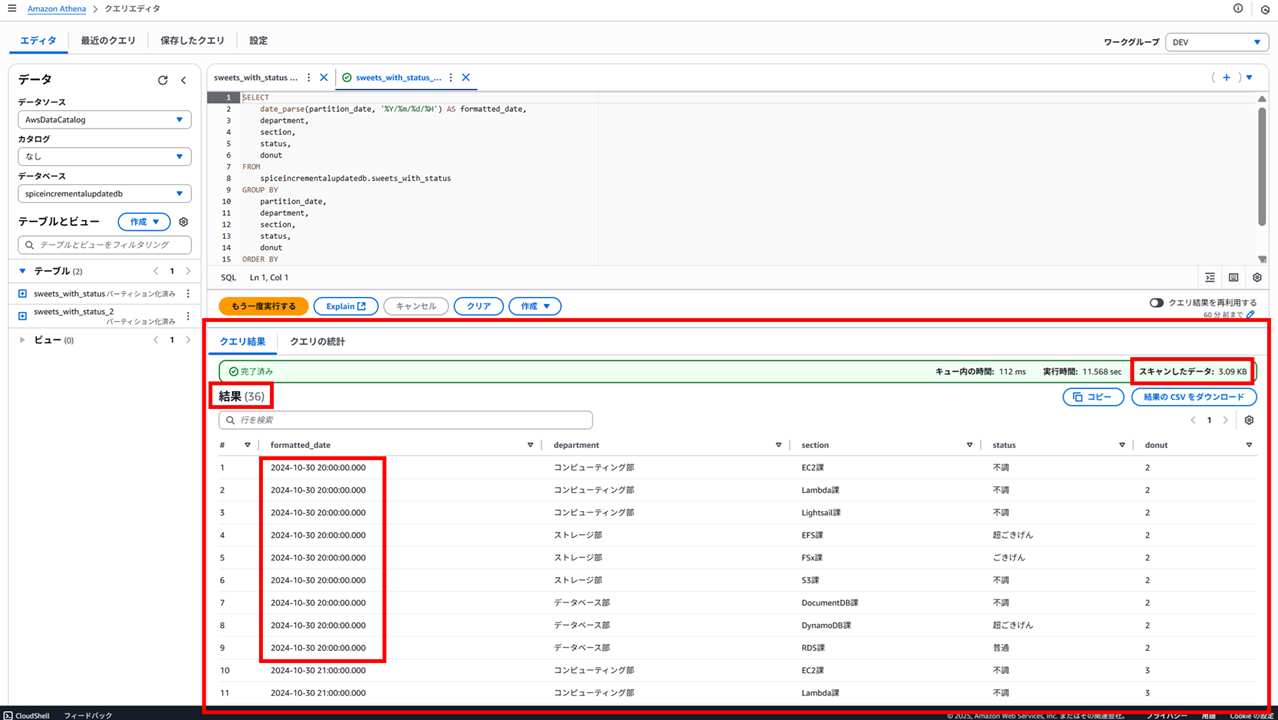
結果の日付を見ると、Glacier Instant Retrieval に変更した 2024/10/30 20:00 のデータは取得できていることが分かります。また、スキャンしたデータ量も先ほどと変わらず、増えても減ってもいません。
Glacier Instant Retrieval は即時取り出しが可能な長期間保存データの格納に適したストレージです。取り出し操作が不要なので、Athena でも取得できたと考えられます。
また、実行時間はやや長くなっているようです。Glacier Instant Retrieval は即時取り出し可能とはいえ、通常 S3 Standard と比較すると少し遅いのかもしれませんね。
結果
データ取得の前に別途取り出し操作が必要な S3 Glacier Deep Archive と S3 Glacier Flexible Retrieval は Athena からクエリでデータ取得できず、スキャンもされませんでした。
データ取得の前に取り出し操作が不要な S3 Glacier Instant Retrieval では、Athena からクエリでデータ取得できました。
注意
S3 Glacier Instant Retrieval は S3 Standard と異なりデータを取得する際に料金が発生します。
※「リクエストとデータ取り出し」 の 「データ取り出し (GB あたり)」 が該当します
S3 Standard 以外のストレージクラスでは取り出し料金がかかります。また、書き込み料金(PUT リクエストによる課金)もストレージクラスによって異なります。
アクセスが少ないデータに関してはライフサイクルポリシーで Glacier へ移行することも考えられますが、Glacier への PUT リクエストが S3 Standard の保存料金よりも高額になる場合があるため、1 オブジェクトのサイズが小さくオブジェクト数が大量にあるというケースでは、Glacier へのライフサイクルポリシーで移行することによって逆にコスト増になってしまう場合があります。
データ 1 つ 1 つが小さい場合は、ライフサイクルポリシーで Glacier へ移行するのではなく、そのまま削除してしまう方がコスト削減になります。
※DELETE リクエストおよび CANCEL リクエストは無料です。
おわりに
本記事への質問やご要望については画面下部のお問い合わせ「DevelopersIO について」からご連絡ください。記事に関してお問い合わせいただけます。
参考








