
AWS DevOps Agent で Datadog アラートをトリガーにした自動インシデント調査をやってみた #AWSreInvent
こんにちは。オペレーション部のshiinaです。
はじめに
AWS DevOps Agent の「やってみた」記事が増えており、盛り上がっています。
AWS DevOps Agent ではオブザーバビリティツールの Datadog と連携が可能です。
今回は Datadog のアラートイベントを Webhook で AWS DevOps Agent に連携し、アラート発生と同時に AI が自動でインシデント調査をしてくれる仕組みを試してみました。
前提
- Datadog モニター作成済み
- AWS DevOps Agent の AgentSpace 作成済み
1. Webhook URL と API Key発行
Datadog MCP サーバセットアップ時の Webhook URL と APIkey を使用します。
事前準備として、以下の記事の「Datadog テレメトリー連携設定」を参考に MCP サーバをセットアップし、Webhook URL と APIkey を入手しておきます。
2. Datadog Webhooks インテグレーション設定
-
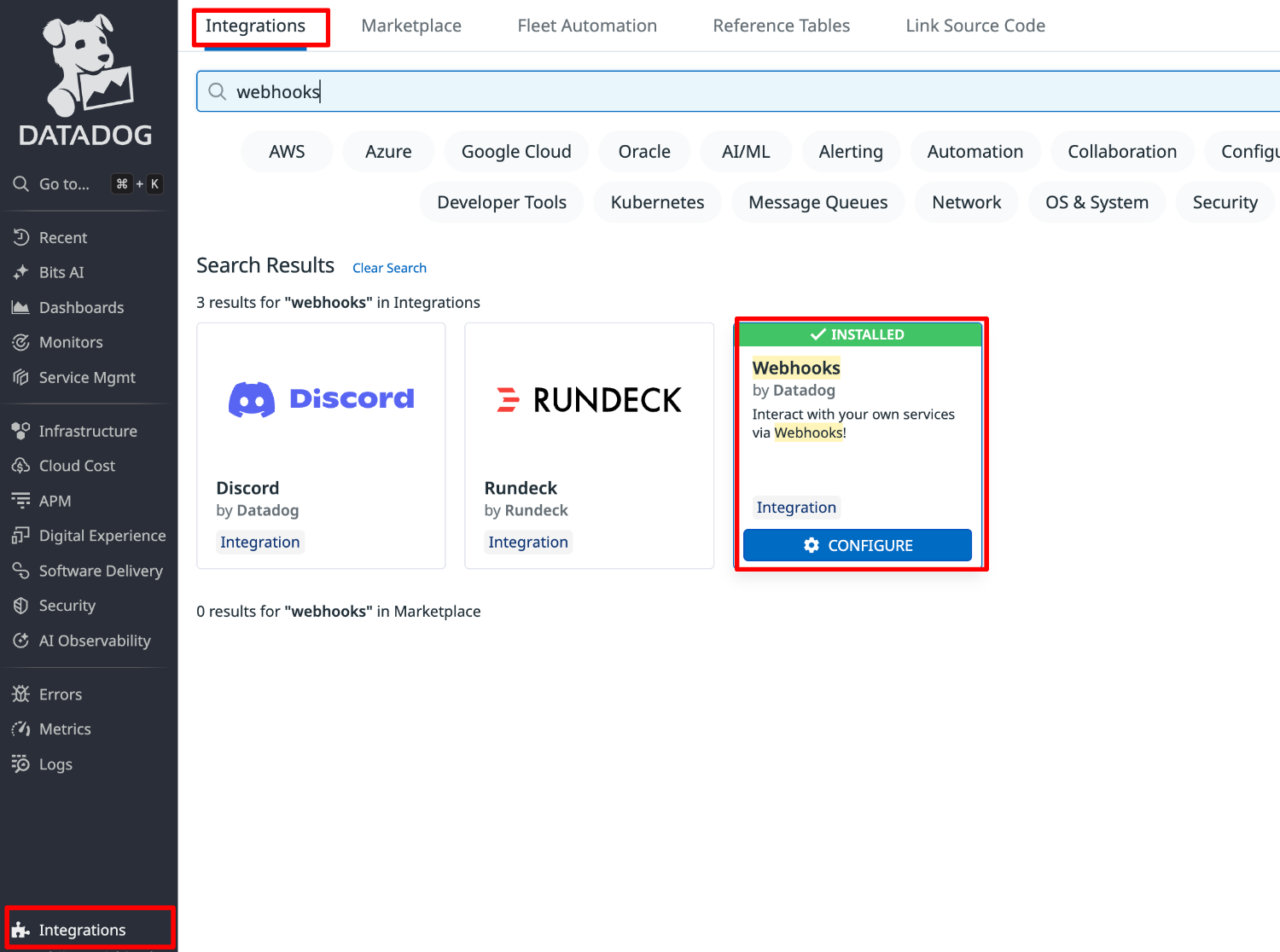
Datadog コンソールより Integrations にアクセスします。
-
一覧より Webhooks を選択します。
-
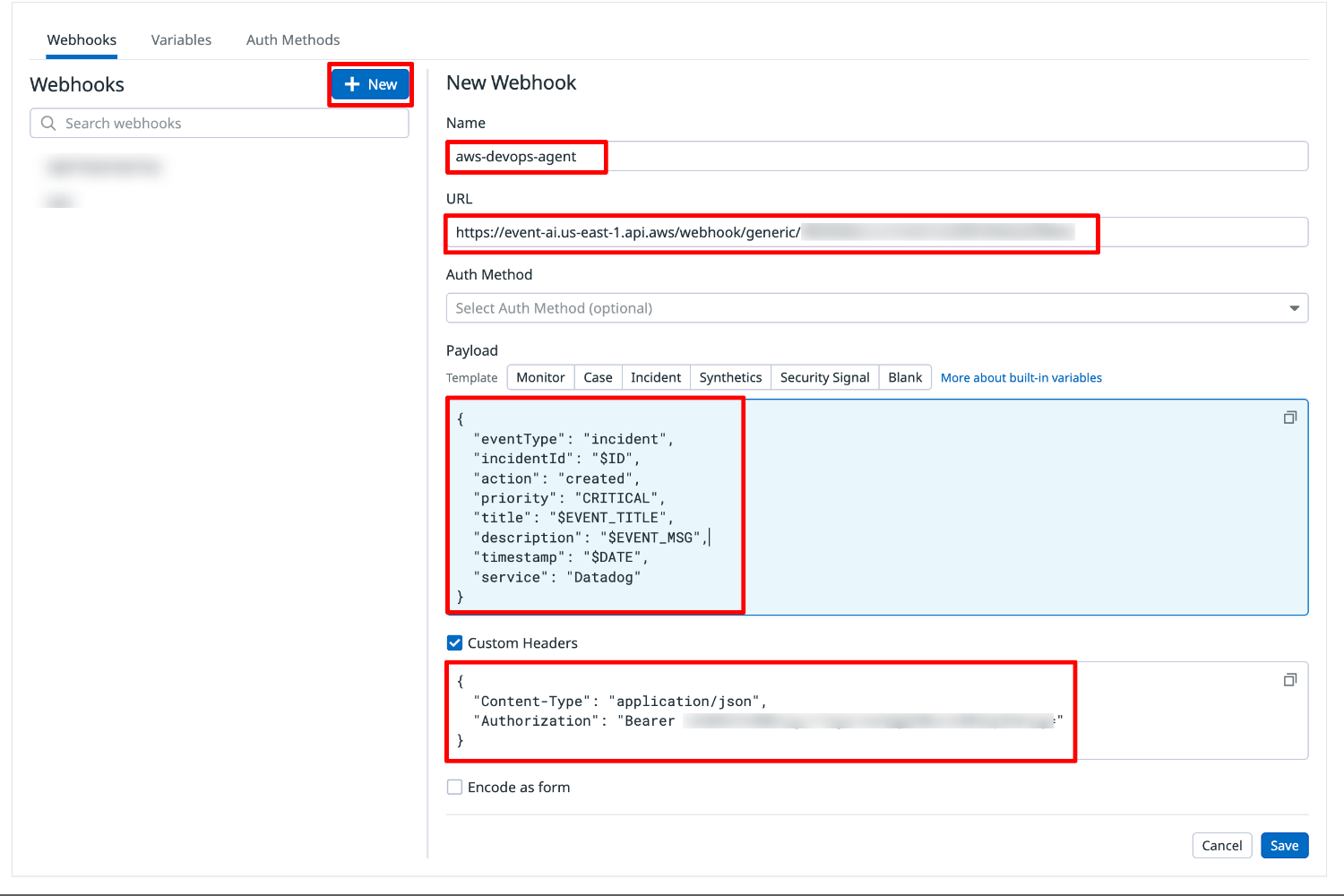
[+New] を選択し、以下の各フィールド設定値を入力の上、[Save]をクリックします。
-
Name:任意の名称
この名前は後述のモニター設定で利用します。ここではaws-devops-agentとしました。 -
URL:Datadog MCP サーバセットアップ時に入手した Webhook URL を指定します。
例:https://event-ai.us-east-1.api.aws/webhook/generic/XXXXXXXXXXXXX -
Auth Method:指定なし
-
Payload:以下の JSON を指定します。
{
"eventType": "incident",
"incidentId": "$ID",
"action": "created",
"priority": "CRITICAL",
"title": "$EVENT_TITLE",
"description": "$EVENT_MSG",
"timestamp": "$DATE",
"service": "Datadog"
}
DevOps Agent 側のスキーマと一致しないイベントは無視される可能性があります。
また、リクエスト本文にはインシデント調査に必要な情報を含める必要があります。
今回は、以下のキーについて Datadog Webhook 変数[1]を利用してマッピングを行い AWS DevOps Agent へ連携しました。
| キー | 値 | 説明 |
|---|---|---|
| incidentId | $ID |
イベント ID |
| title | $EVENT_TITLE |
イベントのタイトル |
| description | $EVENT_MSG |
イベントのテキスト |
| timestamp | $DATE |
イベントが発生した日付 |
- CustomHeader
認証のため、カスタムヘッダーオプションを利用する必要があります。
CustomHeader にチェックを入れ、以下の JSON を指定します。
{
"Content-Type": "application/json",
"Authorization": "Bearer <入手した APIKey を指定>"
}
3. Datadog モニターの設定
Datadog モニターの通知先として Webhook を設定し、アラート発生時に DevOps Agent で自動インシデント調査が始まるようにします。
-
Datadog コンソール Monitors より対象としたいモニターを選択します。
-
[Edit] を選択します。
-
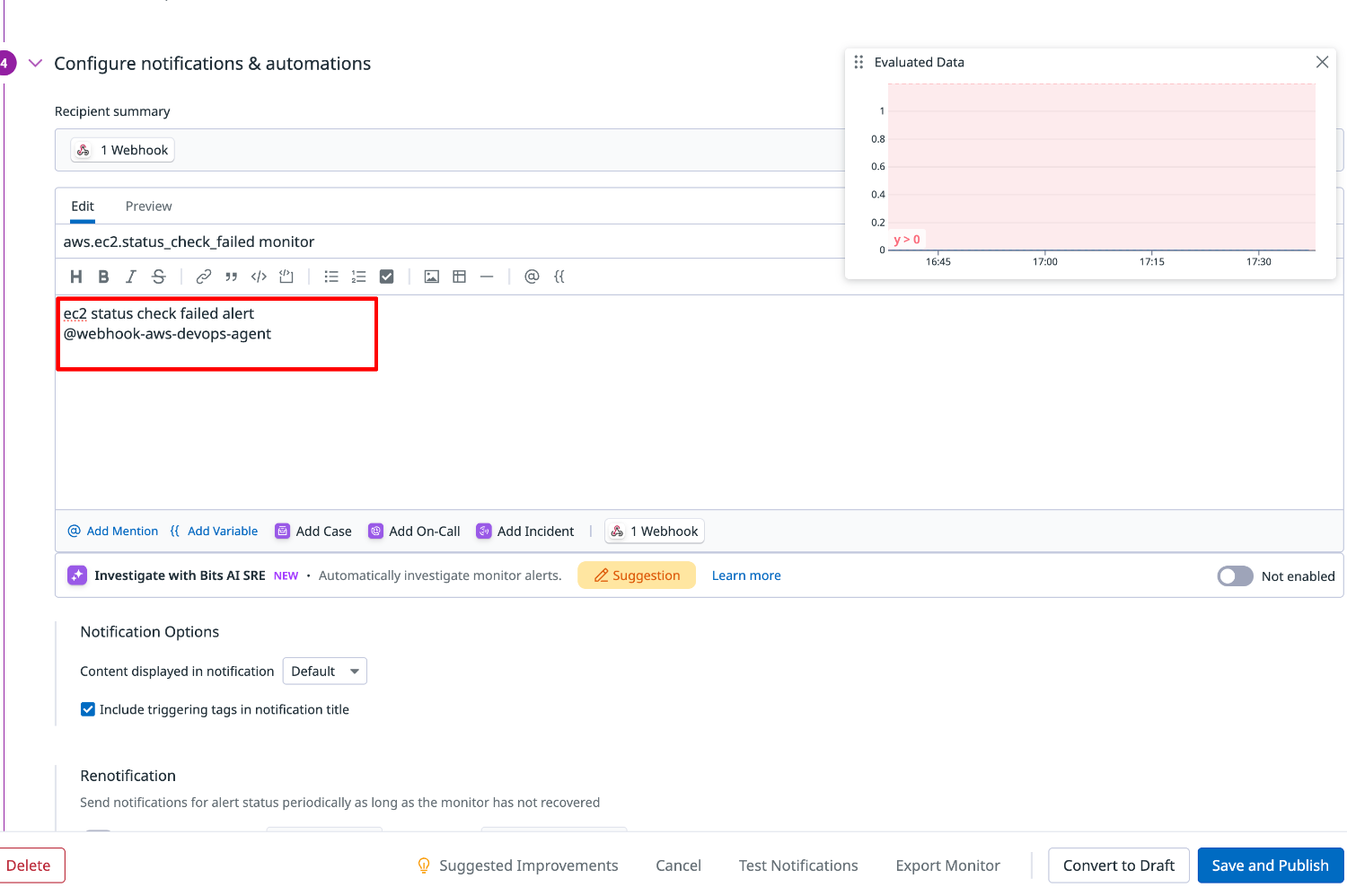
Configure notifactions & automations フィールドを修正の上、[Save and Publish]を選択します。
入力欄に@webと入力すると、Webhooks の一覧が表示されますので、先程作した Webhook 名を選択します。
例:@webhook-aws-devops-agent
4. Webhook の動作テスト
設定した Webhook が正しく動作しているか、Datadog モニターのテスト通知を使って確認します。
-
Datadog コンソールの Monitors から対象モニターを選択し、[Edit] をクリックします。
-
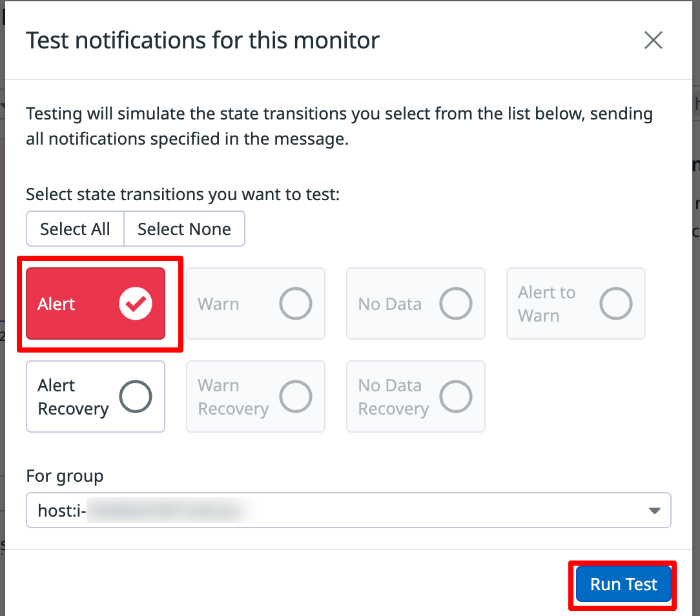
[Test Notifications]を選択します。
-
Alert にチェックをいれて[Run Test]を選択します。
-
グループにテスト通知が送信されたメッセージが表示されることを確認し、ウィンドウを閉じます。

-
Datadog コンソール Service Mgmt より All Events を選択します。

-
「Triggered on〜」で始まるモニターのアラートイベントが表示されていることを確認します。
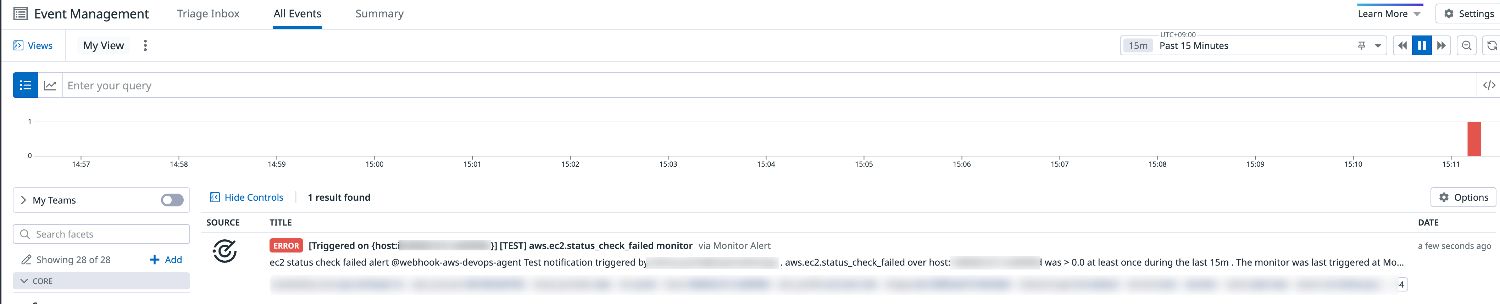
-
次に、AWS DevOps Agent コンソールより Agent Spaces を選択します。
-
対象の Agent Space の[View details]をクリックし、[Operator access]を選択します。
9. Incident Response Dashboard の Investigation 一覧に、「Triggered on 〜」で始まるインシデント調査履歴が存在すれば、自動インシデント調査は正しく動作しています。
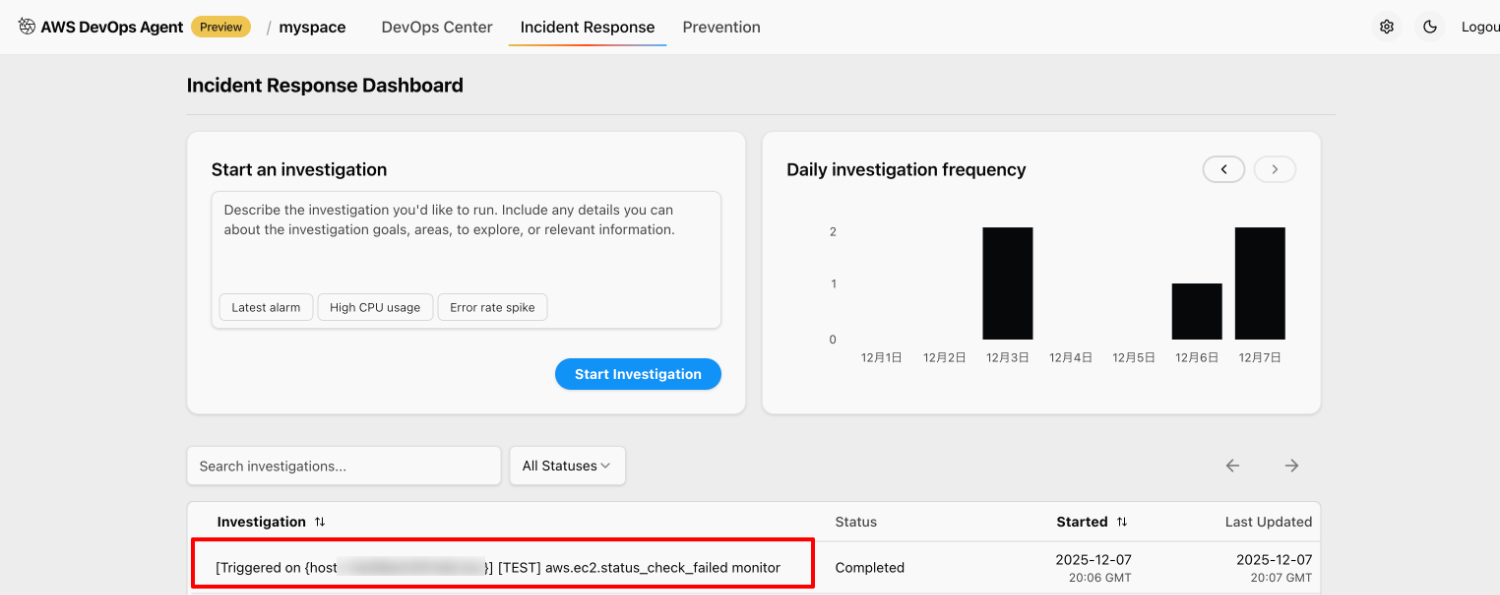
- 該当の履歴を選択し、インシデント調査イベントを確認します。
Datadog Webhook 変数で設定したイベントのタイトル・テキストが DevOps Agent 側に正しく連携されていることが確認できます。
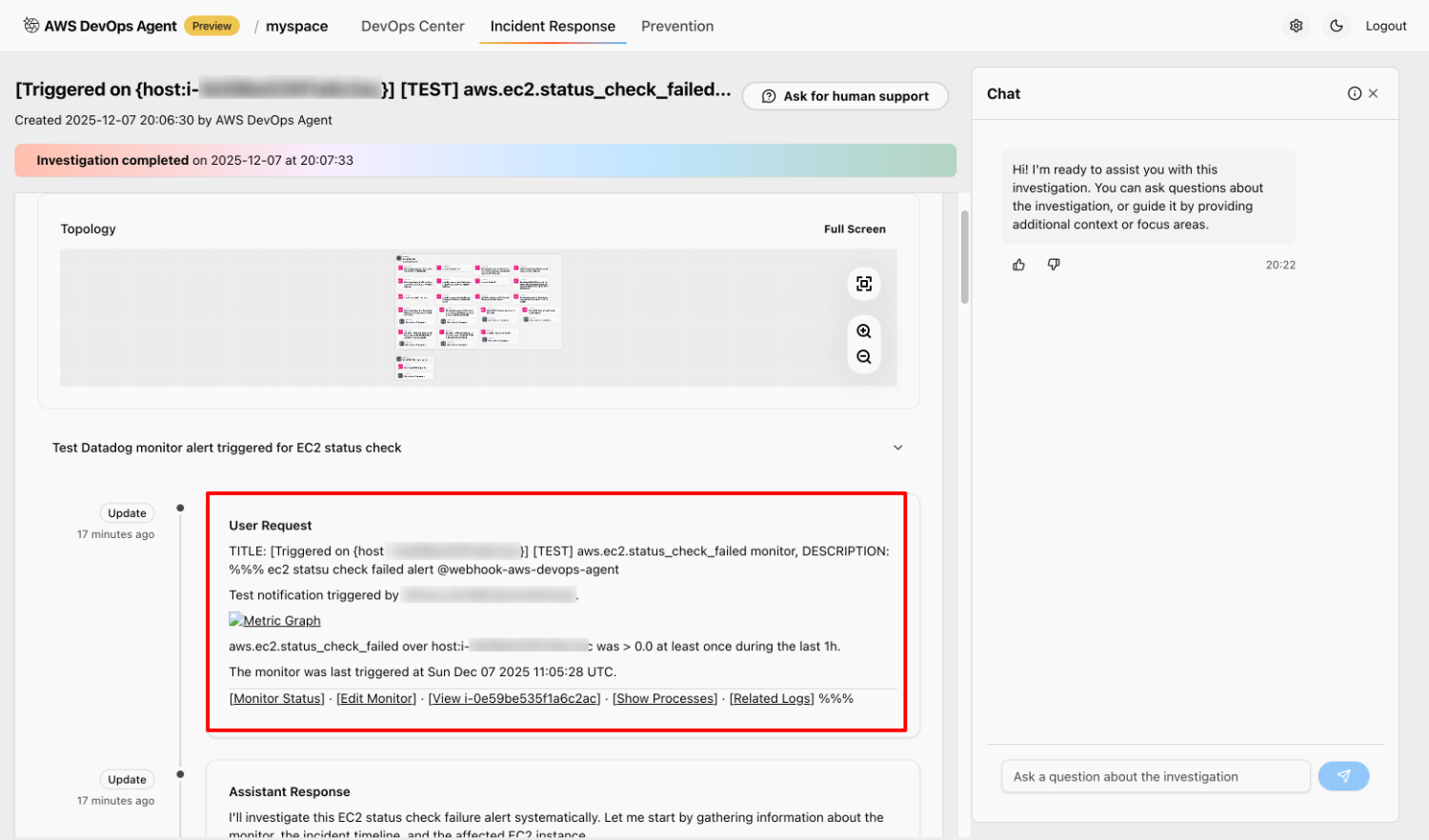
インシデント調査が完了したら、根本原因の分析結果も確認してみます。
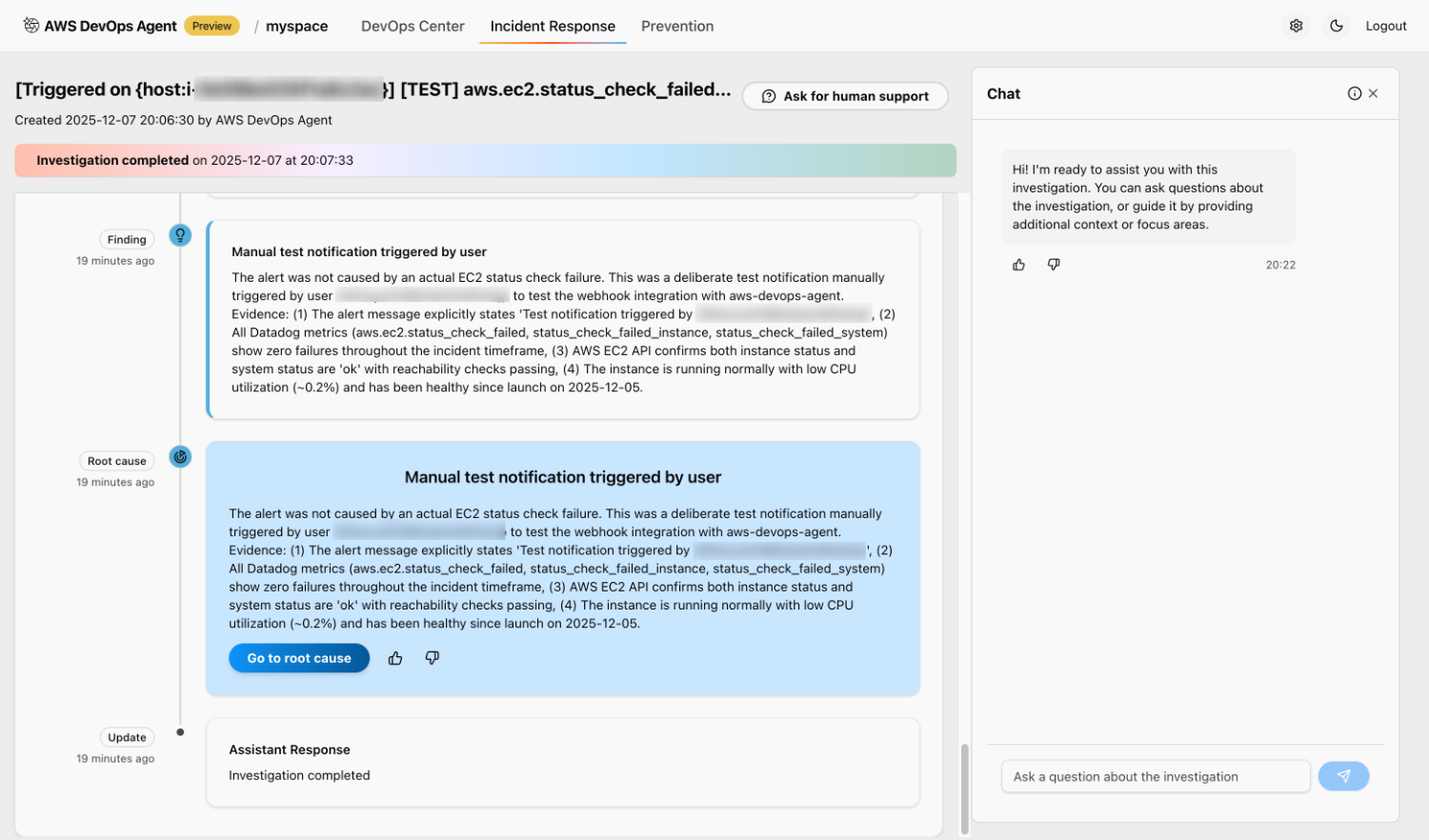
「手動テストがユーザによって実行された」という見出しで結果が出ていますね。[Go to root cause] から詳細を見てみましょう。
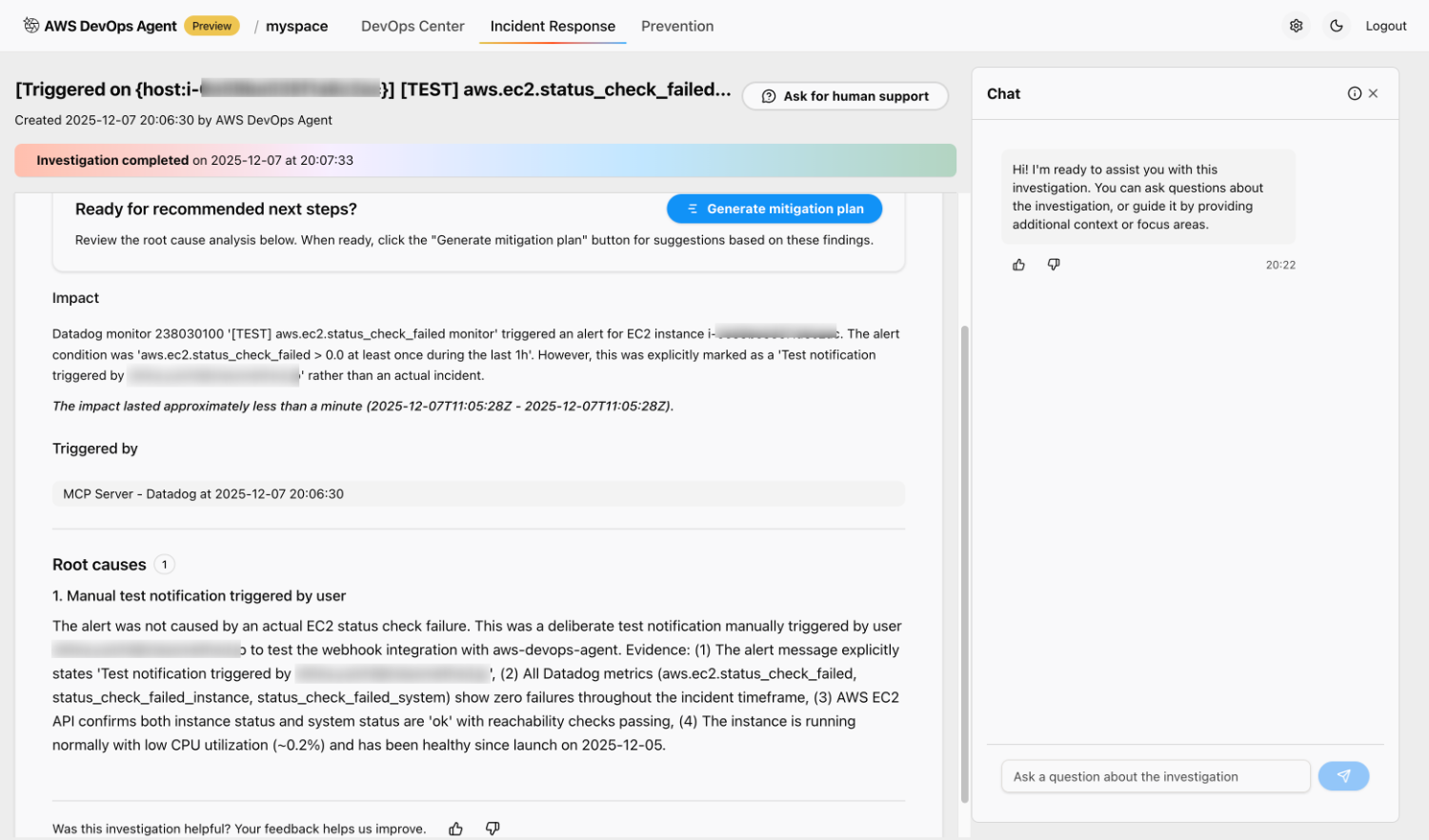
根拠を具体的に示しつつ、テスト通知であることをしっかり見抜いているところは、やはり AWS DevOps Agent のすごいところです。
インシデント調査結果(和訳)
インパクト
Datadog モニター XXXXXXXX「[TEST] aws.ec2.status_check_failed monitor」が、EC2 インスタンス i-XXXXXXXXXX に対してアラートをトリガーしました。
アラート条件は「直近 1 時間の間に少なくとも 1 回、aws.ec2.status_check_failed > 0.0」で設定されていました。
しかし、このアラートは実際のインシデントではなく、「XXXXXXXX によってトリガーされたテスト通知」であることが明示されていました。
影響が続いた時間は 1 分未満で、2025-12-07T11:05:28Z から 2025-12-07T11:05:28Z の間でした。
トリガー元
MCP Server - Datadog(2025-12-07 20:06:30)
根本原因
1
1. ユーザーによる手動テスト通知
このアラートは、実際の EC2 ステータスチェックの失敗が原因ではありませんでした。ユーザー XXXXXXXX が、aws-devops-agent との Webhook 連携を検証する目的で意図的に手動発火させたテスト通知です。
根拠:
(1) アラートメッセージ内に明確に「Test notification triggered by XXXXXXXX 」と記載があること
(2) インシデント発生期間を通じて、Datadog の全ての関連メトリクス(aws.ec2.status_check_failed、status_check_failed_instance、status_check_failed_system)がいずれも 0(失敗なし)であること
(3) AWS EC2 API 上で、インスタンスステータスおよびシステムステータスがいずれも「ok」となっており、到達性チェックも合格していること
(4) 対象インスタンスは CPU 使用率がおおむね 0.2% 程度と低く、2025-12-05 の起動以来一貫して正常に稼働していること
5. 実際のインシデントをシミュレーションして自動インシデント調査
実際に障害をシミュレーションして、自動インシデント調査がどのように動くかを見てみます。
シナリオ
StatusCheckFailed_Instanceを失敗させ、擬似的にStatusCheckFailedメトリクスを発生させてみます。
セッションマネージャーから EC2 インスタンスへログインし、インスタンス内のネットワークインターフェース(NIC)を停止します。
※インターフェース名は環境により異なります。
ip link set enX0 down
インスタンスステータスチェック失敗
EC2 コンソールからインスタンスのステータスチェックを確認すると、StatusCheckFailed_Instanceが失敗していることが確認できます。
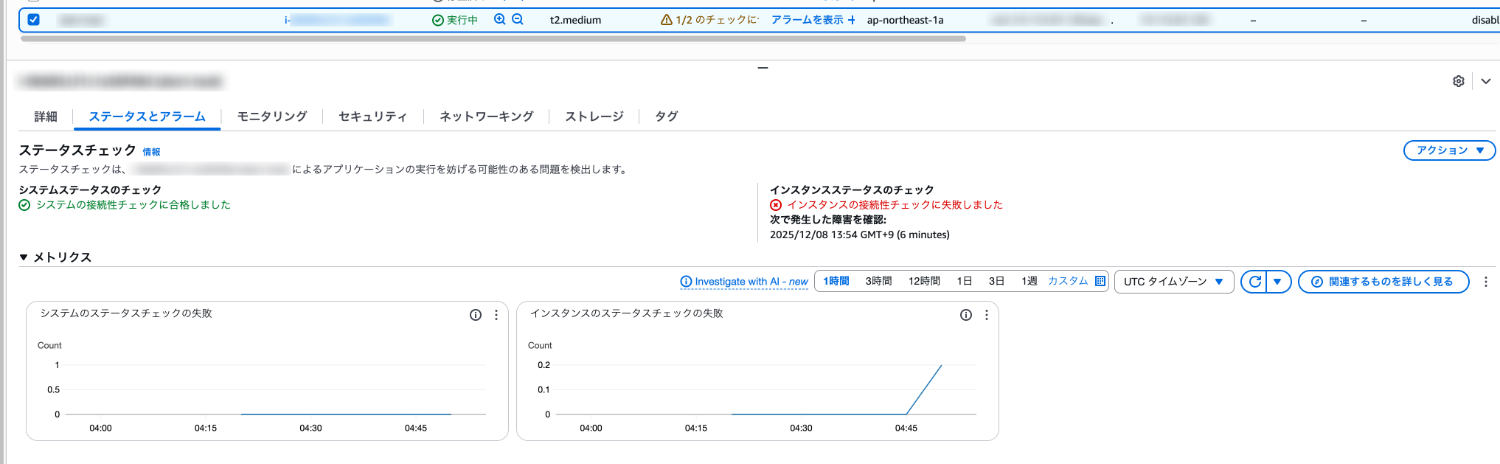
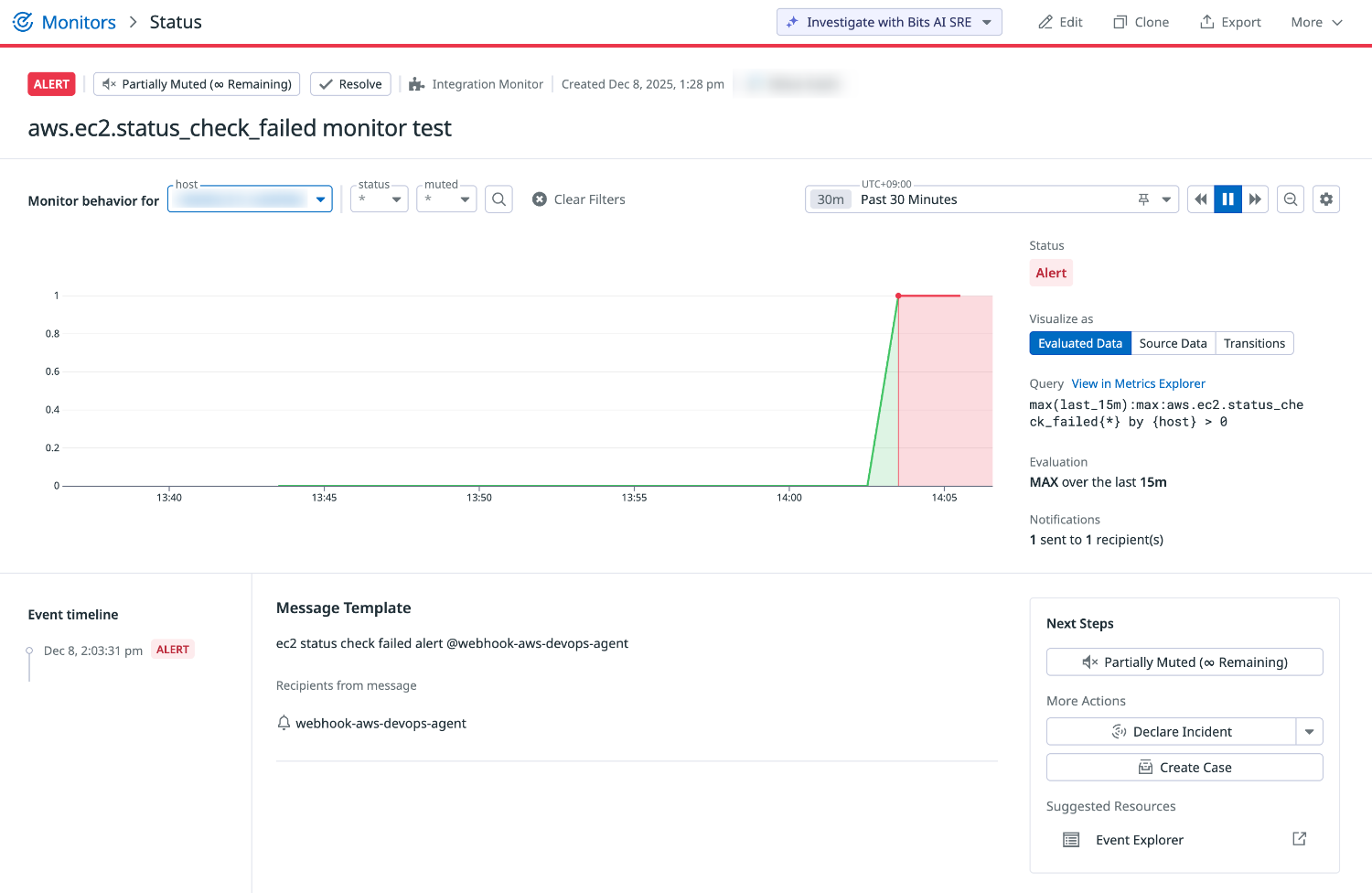
Datadog モニタのアラート検知
Datadog コンソールの対象モニターを確認すると、ステータスが ALERT になっていることがわかります。
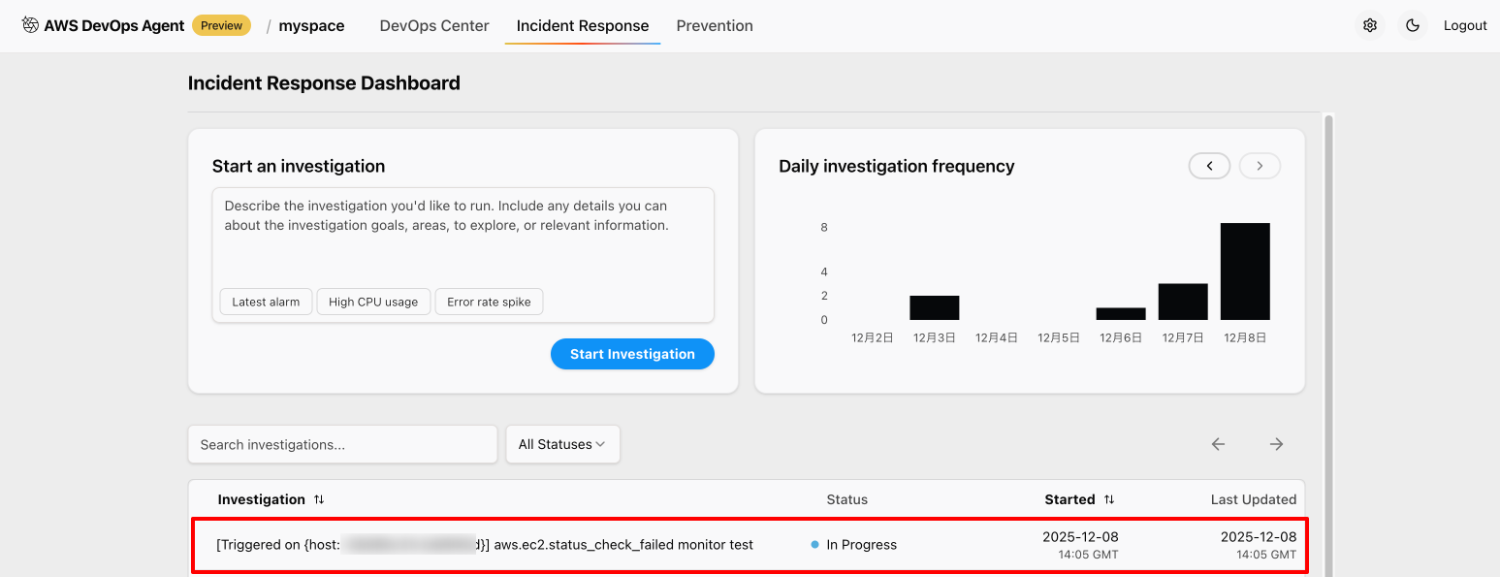
インシデント調査の確認
DevOps Agent コンソールでインシデント調査一覧を確認します。
「Triggered on 〜」で始まる調査が [In progress] になっており、自動調査が進行中であることが確認できます。
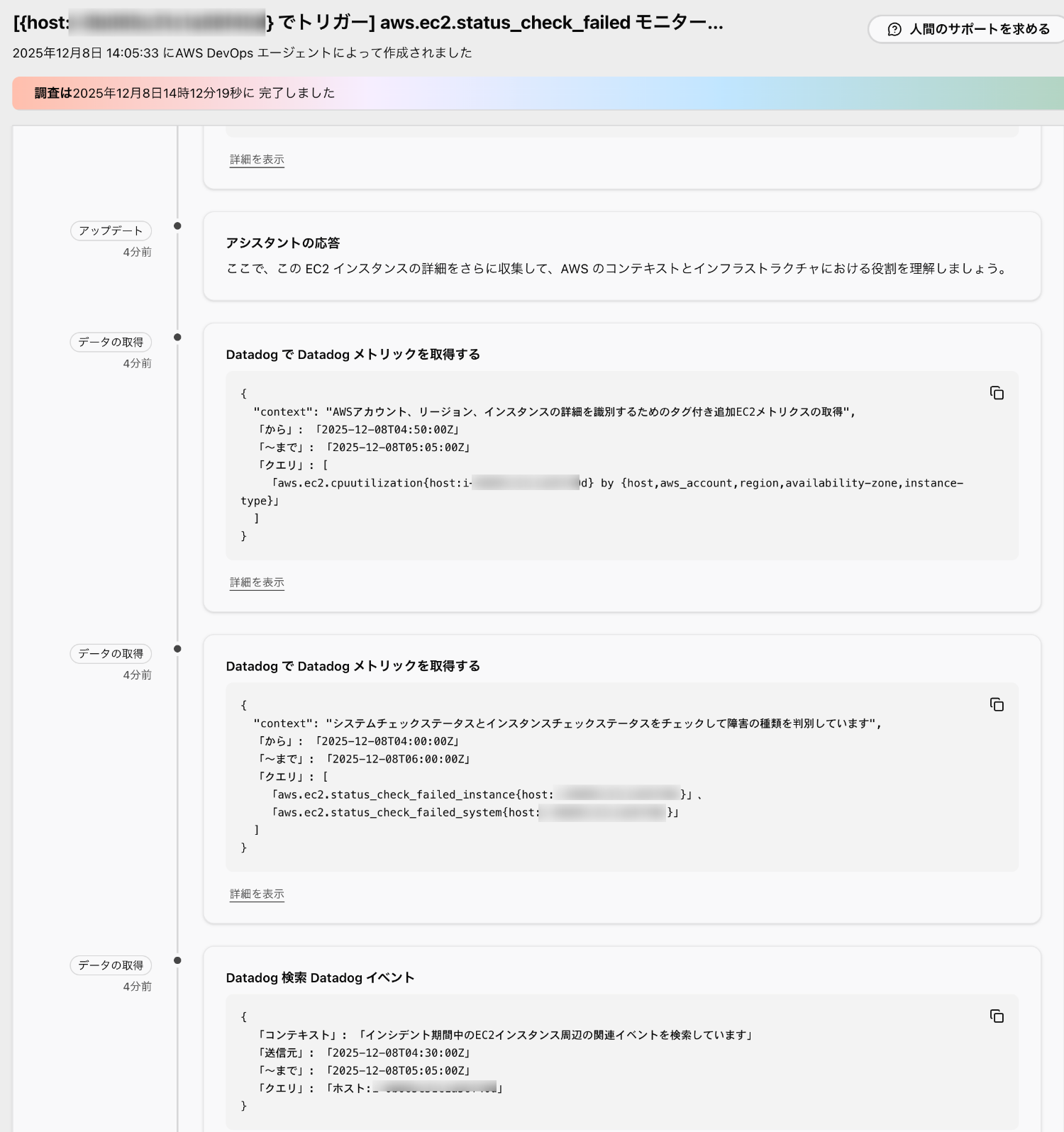
調査結果の確認
どのような調査が行われたのか、詳細を見ていきます。
※スクリーンショットはブラウザの翻訳機能を使用しています。
-
まず MCP サーバー経由で Datadog のメトリクスやイベントを確認しているようです。
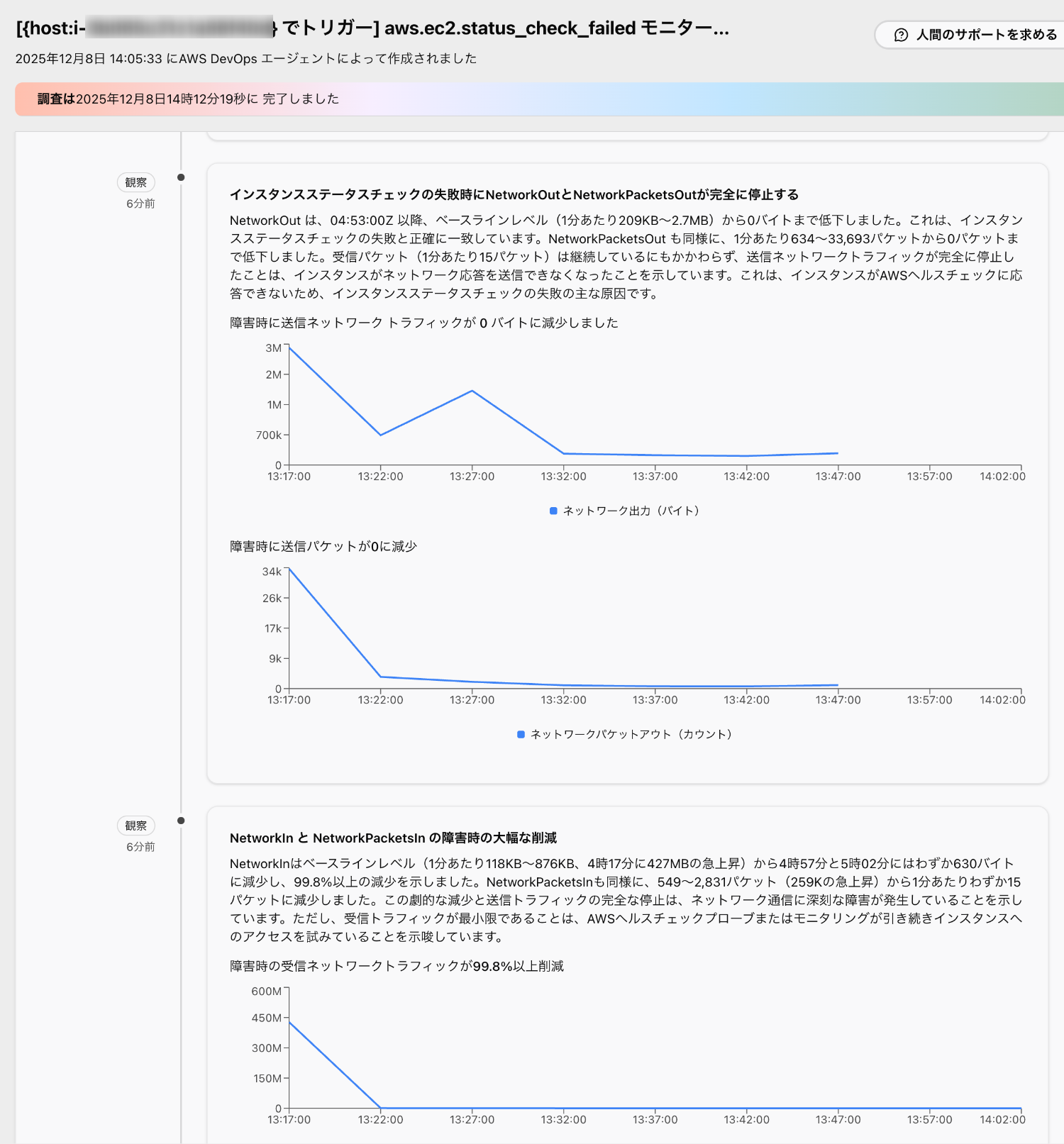
-
そこでネットワークトラフィックに関する異常な観察結果が見つかります。
-
続いて、インスタンスに対して最近行われた変更がないかを調査しています。
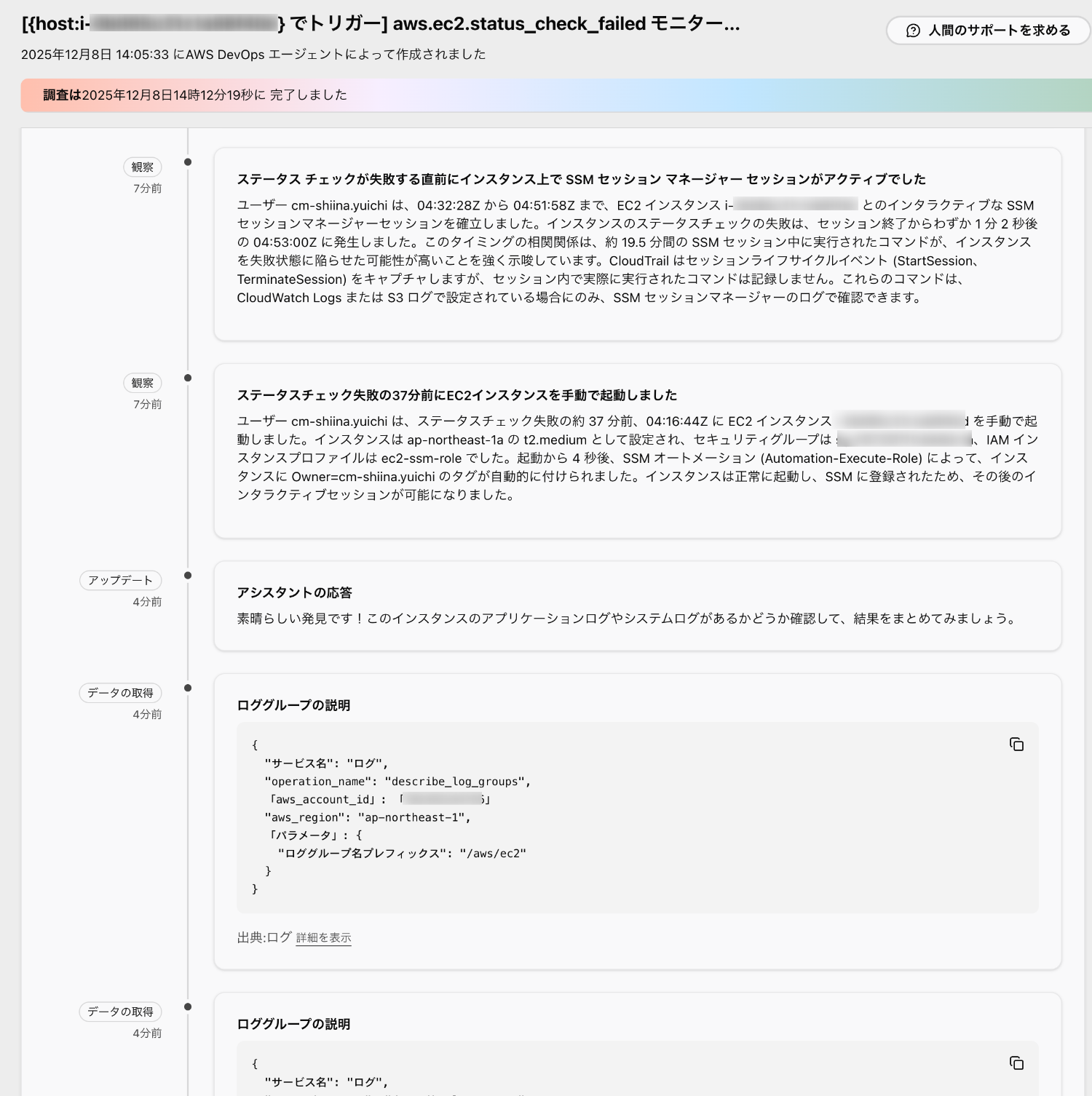
-
その中で、セッションマネージャーのセッションがアクティブだった、という観察も得られています。
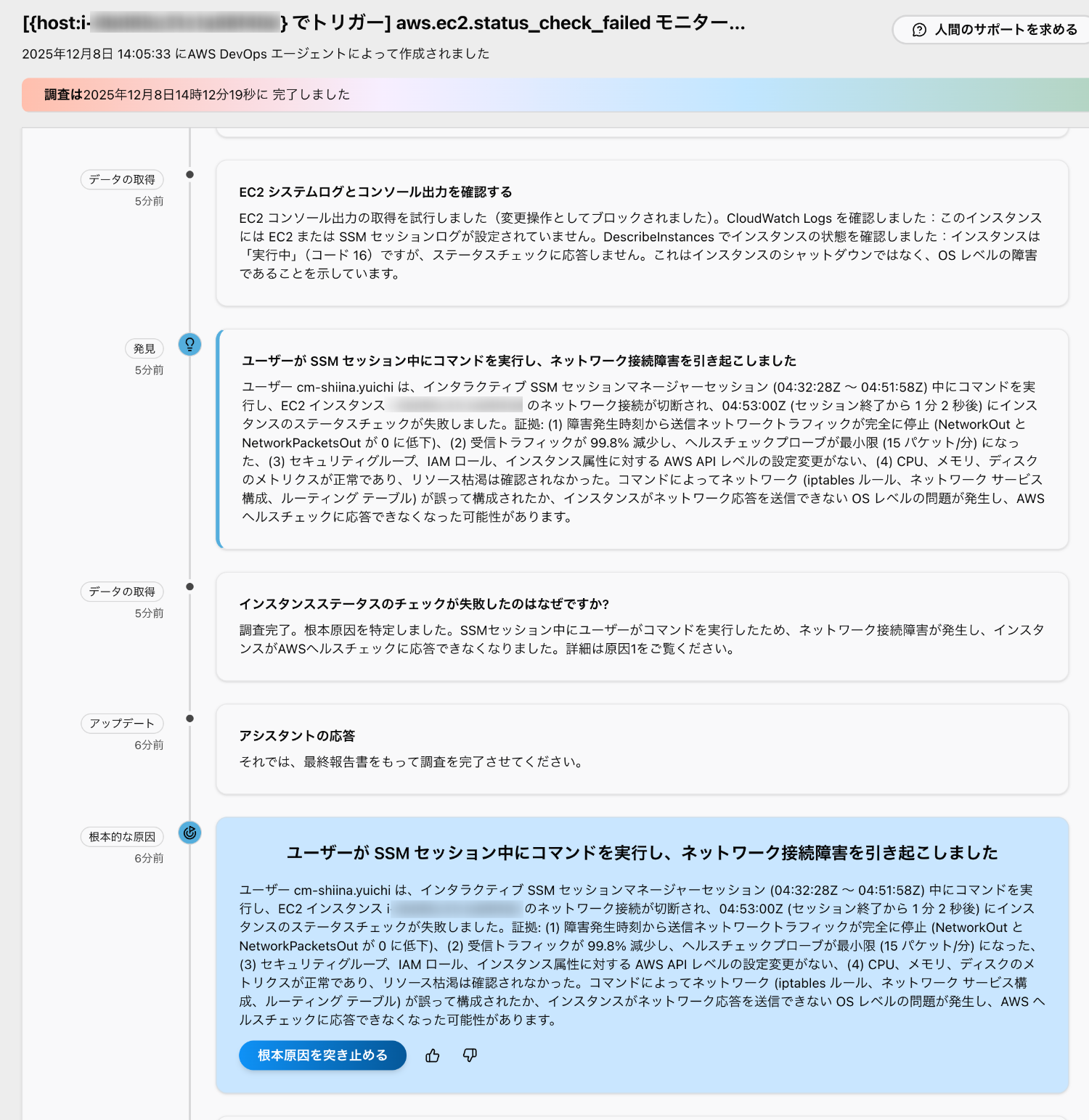
調査が完了すると、結論が提示されます。
「ユーザがSSMセッション中にコマンドを実行し、ネットワーク接続障害を引き起こしました」
まさに的中です。さまざまなログやメトリクスを踏まえて、かなり納得感のあるストーリーで原因を特定してくれました。
根本原因レポートを見ると、複数の観察結果を根拠として積み上げながら結論に至っている様子がわかります。
実運用のトラブルシュートにも、そのまま使えそうなレベルの精度だと感じました。

ハマったところ
自動インシデント調査機能を試す中で、いくつかハマりポイントがあったので共有します。
-
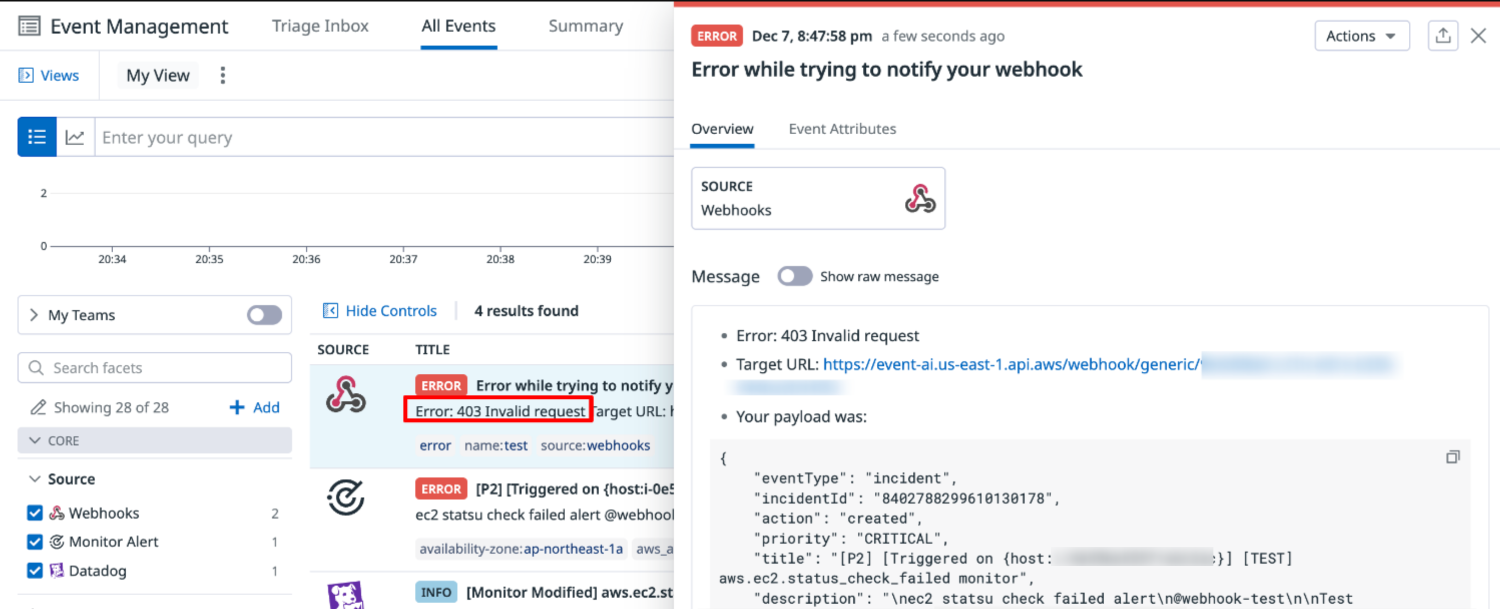
Error: 403 Invalid request
CustomHeader (特に Authorization)の指定漏れ、もしくは APIKey 誤りが考えられます。
-
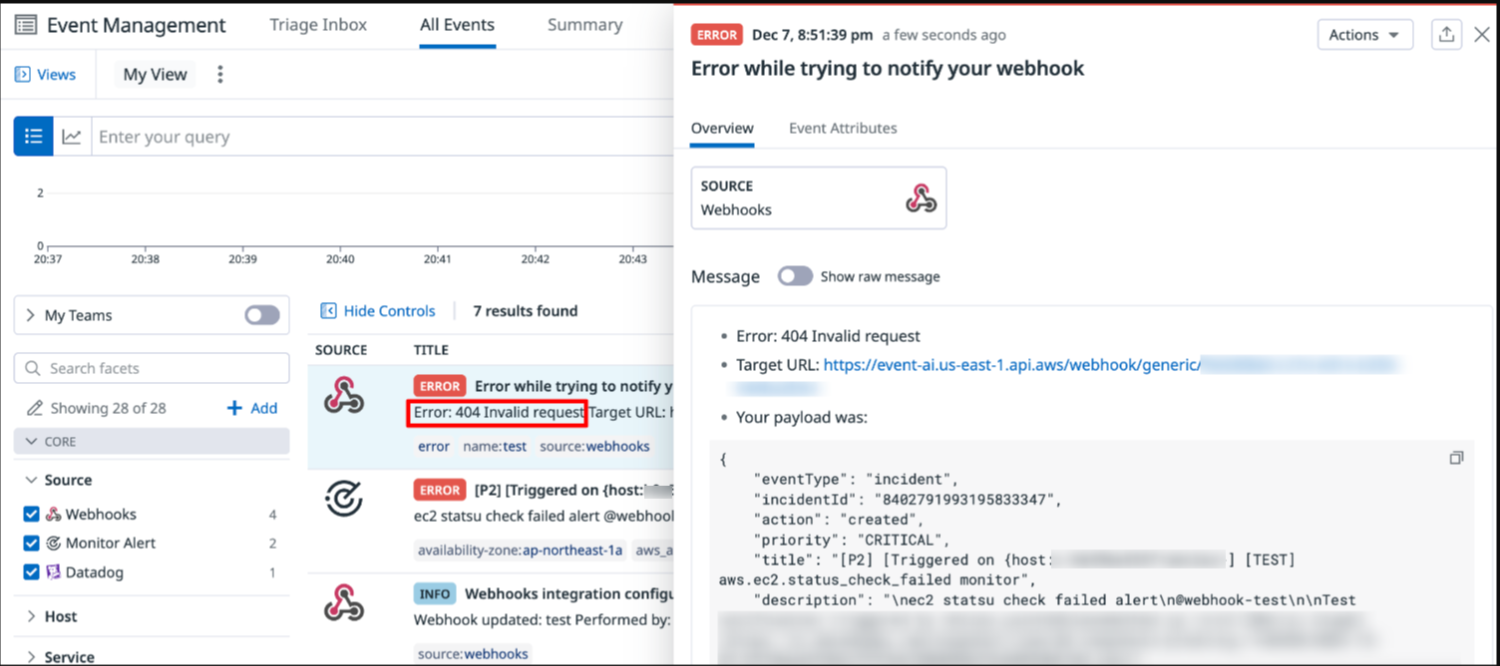
Error: 404 Invalid request
Webhook の URL 誤りが考えられます。
-
自動インシデント調査が行われない
Datadog Event Management に Webhook のエラー記録はなく、DevOps Agent 側の Investigation 一覧にもインシデントが連携されていませんでした。
原因は、Payload にserviceを指定していなかったことでした。
任意の値でよいのでserviceを指定したところ、自動インシデント調査が正常に動くようになりました。
データスキーマではservice?[2]となっており、オプショナルに見えますが、実際には指定が必要なようです。
{
eventType: 'incident';
incidentId: string;
action: 'created' | 'updated' | 'closed' | 'resolved';
priority: "CRITICAL" | "HIGH" | "MEDIUM" | "LOW" | "MINIMAL";
title: string;
description?: string;
timestamp?: string;
service?: string;
// The original event generated by service is attached here.
data?: object;
}
まとめ
今回は AWS DevOps Agent と Datadog を Webhook 連携させることで、アラート発生と同時に AI が自動でインシデント調査を始める仕組みを試してみました。
テスト通知と障害シナリオの両方で試してみましたが、メトリクスやイベントを根拠にしっかり切り分けてくれる精度の高さが印象的でした。
自動連携によりアラートが鳴るころには、すでに原因候補や影響範囲が整理されているので、人は初動調査よりも判断と対処に集中できそうですね。
一方で、Webhook Payload には細かいスキーマ要件を満たさないと動かないポイントもあり、注意が重要です。
今後、オブザーバビリティツールと組み合わせていくことで、インシデント対応のスタイルそのものを変えていけそうで、とてもワクワクしています。
本記事が参考になれば幸いです。
#AWSreInvent
参考









