
AWS HealthOmics がエフェメラルストレージに対応したので試してみた
はじめに
AWS HealthOmics のプライベートワークフローでエフェメラルストレージがサポートされました。各タスクの /tmp にタスク専用のローカルボリュームをマウントする機能です。容量は WDL、Nextflow、CWL の各ワークフロー定義のディレクティブで 16 GiB から最大 3,072 GiB まで指定できます。今回は Nextflow のプライベートワークフローで有効化し、/tmp を確認してみました。
確認結果
--scratch-storage-mode LOCAL を付けて Nextflow のプライベートワークフローを実行し、/tmp を確認しました。
LOCAL では /tmp がタスク専用のローカル NVMe ボリューム(/dev/nvme1n1、xfs)になりました。disk '100 GB' の指定は 16 GiB 刻みで切り上げられ、112 GiB が割り当てられました。デフォルトの SHARED では /tmp がラン共有の実行ストレージ(NFS)に置かれ、disk の指定は無視されました。
| 項目 | LOCAL | SHARED(デフォルト) |
|---|---|---|
/tmp の実体 |
タスク専用のローカルボリューム | ラン共有の実行ストレージ |
| デバイス / FS タイプ | /dev/nvme1n1 / xfs |
NFS 共有マウント / nfs4 |
| df 上の容量 | 112 GiB | 8.0E(共有 FS の見かけ容量) |
disk '100 GB' の反映 |
112 GiB(16 GiB 切り上げ) | 無視される |
manifest の scratchStorageReservedGiB |
112 | 出力されない |
エフェメラルストレージとは
エフェメラルストレージは、HealthOmics がワークフローの各タスクに専用ローカルボリュームを /tmp としてマウントする機能です。既存の実行ストレージ(DYNAMIC or STATIC で指定するストレージ)とは別物です。主にタスク内の中間データなど、高速な I/O が求められる一時的なデータを処理する scratch 領域として使います。
ゲノム解析ツール(samtools、GATK など)は中間ファイルを /tmp に書き出す設計のものが多く、共有ストレージへの I/O がボトルネックになりがちです。エフェメラルストレージではローカル NVMe ストレージに直接読み書きするためタスク単体の I/O 効率が上がります。
LOCAL で有効化すると、デフォルトの 16 GiB が /tmp の専用ボリュームとして自動で割り当てられます。容量指定は不要で、この範囲なら課金も発生しません。デフォルト設定の SHARED のままでは専用ボリュームは割り当てられず、/tmp は実行ストレージ上に置かれます。
- デフォルト 16 GiB/タスク(容量指定不要、無料)、上限 3,072 GiB/タスク
- 容量は 16 GiB 刻みで切り上げ(例: 100 GB の指定すると 112 GiB になる)
- 16 GiB 超過分のみ課金(容量 × タスク実行秒数)
- タスク終了時にデータは削除(実行ストレージも似たようなものです)
- GPU タスクは常にローカル NVMe(ディスクサイズはインスタンスタイプ依存し指定不可)
公式ドキュメントには、マウント先、暗号化、タスク終了時の削除が次のように明記されています。
When you enable ephemeral storage, HealthOmics mounts a dedicated local storage volume at
/tmpfor each workflow task instance. ... Ephemeral storage volumes are always deleted when the task terminates. ... All ephemeral storage is encrypted at rest using a service-managed AWS KMS key.出典: Ephemeral storage for HealthOmics workflow tasks - AWS HealthOmics User Guide
実行ストレージとの違い
実行ストレージはラン全体で共有し、ランの実行中だけ使えるファイルシステムです。--storage-type に DYNAMIC または STATIC を指定します(デフォルト値は DYNAMIC)。各タスクの /tmp に割り当てるエフェメラルストレージとはスコープが異なります。混同しやすいなと思ったので整理しました。
| 観点 | 実行ストレージ(ラン共有 FS) | エフェメラルストレージ(今回の新機能) |
|---|---|---|
| スコープ | ラン全体。全タスクが共有 | タスク単位。タスク間で共有不可 |
| マウント先 | ワーキングディレクトリ | 各タスクの /tmp(専用ローカルボリューム) |
| 種類 | DYNAMIC(自動で容量調整)または STATIC(固定容量) | タスク専用のローカルボリューム(CPU は容量指定可、GPU はインスタンスサイズに依存) |
| 容量指定 | --storage-type と --storage-capacity |
ワークフロー定義の disk(Nextflow)、disks(WDL)、tmpdirMin(CWL) |
| 永続性 | ラン終了時に破棄 | タスク終了時に破棄 |
| デフォルト設定 | DYNAMIC | CPU タスクは SHARED指定(LOCAL 指定で有効化必要) |
| 課金 | GB-hour 課金 | 16 GiB 超過分のみ、容量 × タスク実行秒数 |
一言でまとめると、実行ストレージは「タスク間でデータを受け渡す共有ストレージ」で、エフェメラルストレージは「タスク内で閉じる scratch 領域」です。
実行ストレージの DYNAMIC(elastic throughput)については以下の記事で紹介しています。
今回の構成
事前準備と本記事で実行する手順の区分は次のとおりです。
| 区分 | リソース | 用途・備考 |
|---|---|---|
| 事前準備 | S3 バケット | ラン出力先。バケット名は start-run の --output-uri で使用 |
| 事前準備 | ECR プライベートリポジトリ | コンテナイメージ格納。HealthOmics はパブリックイメージを直接参照できないため ECR にミラーする |
| 事前準備 | HealthOmics サービスロール(IAM) | HealthOmics が S3、CloudWatch Logs、ECR にアクセスするためのロール |
| 本記事の手順 | Nextflow ワークフロー定義(main.nf) |
disk '100 GB' でエフェメラルストレージを指定した Hello World ワークフロー |
| 本記事の手順 | HealthOmics プライベートワークフロー | 上記 Nextflow 定義を登録したワークフロー |
| 本記事の手順 | HealthOmics ラン | --scratch-storage-mode LOCAL を付けて実行するラン |
コンテナイメージを ECR に用意する
HealthOmics のプライベートワークフローは ECR プライベートリポジトリのイメージのみ利用できます。今回は ubuntu:24.04 を ECR にミラーします。ミラーは docker pull と docker push でもできますが、今回はレジストリ間でイメージを直接コピーできる crane を試してみました。Docker デーモンを起動せずにコピーできます。
ECR にログインし、Docker Hub の ubuntu:24.04 を ECR へコピーします。
aws ecr get-login-password --region us-east-1 \
| crane auth login --username AWS --password-stdin \
<ACCOUNT_ID>.dkr.ecr.us-east-1.amazonaws.com
crane copy ubuntu:24.04 \
<ACCOUNT_ID>.dkr.ecr.us-east-1.amazonaws.com/healthomics-ephemeral-hello:24.04
ubuntu:24.04 はマルチアーキイメージで linux/amd64 を含むため、HealthOmics 側で amd64 が選択されます。
Nextflow ワークフロー定義を作成する
disk '100 GB' を指定して /tmp の容量を確認するワークフロー定義(main.nf)を作成します。disk ディレクティブは HealthOmics 固有の拡張ではなく Nextflow 標準のディレクティブです。HealthOmics は scratchStorageMode=LOCAL のとき、disk の値を 16 GiB 刻みで切り上げてエフェメラルボリュームをプロビジョニングします。
レポートファイルは publishDir '/mnt/workflow/pubdir' でエクスポートします。/mnt/workflow/pubdir に書いたファイルが --output-uri の S3 パスにコピーされる仕組みです。
nextflow.enable.dsl=2
process check_scratch {
container '<ACCOUNT_ID>.dkr.ecr.us-east-1.amazonaws.com/healthomics-ephemeral-hello:24.04'
publishDir '/mnt/workflow/pubdir', mode: 'copy'
disk '100 GB'
output:
path 'scratch_report.txt'
script:
"""
echo "== df -h /tmp (before write) ==" > scratch_report.txt
df -h /tmp >> scratch_report.txt
echo "== mount /tmp ==" >> scratch_report.txt
mount | grep ' /tmp ' >> scratch_report.txt 2>&1 || true
echo "== write 1 GiB to /tmp ==" >> scratch_report.txt
dd if=/dev/zero of=/tmp/test.bin bs=1M count=1024 status=none
echo "== df -h /tmp (after write) ==" >> scratch_report.txt
df -h /tmp >> scratch_report.txt
"""
}
workflow {
check_scratch()
}
定義ファイルを zip に固めます。
zip workflow.zip main.nf
ワークフローを HealthOmics に登録する
create-workflow で workflow.zip を登録します。
aws omics create-workflow \
--name healthomics-ephemeral-hello \
--engine NEXTFLOW \
--definition-zip fileb://workflow.zip \
--region us-east-1
id が返ります。作成直後のステータスは CREATING です。
{
"arn": "arn:aws:omics:us-east-1:<ACCOUNT_ID>:workflow/4627227",
"id": "4627227",
"status": "CREATING"
}
ステータスが ACTIVE になればランを実行できます。
エフェメラルストレージを有効化してランを実行する
--scratch-storage-mode LOCAL が今回の肝です。CPU タスクのデフォルトは SHARED で、disk ディレクティブが無視されます。このオプションを付けないとエフェメラルストレージは有効になりません。
公式ドキュメントには、scratchStorageMode のデフォルト値と SHARED 時の挙動が次のように記述されています。
Ephemeral storage is off by default. When
scratchStorageModeis omitted from aStartRunrequest,scratchStorageModeis set toSHARED(default). ... WhenscratchStorageModeisSHARED, alldiskand equivalent directives in the workflow definition are ignored and/tmpis backed by the shared filesystem.出典: Ephemeral storage for HealthOmics workflow tasks - AWS HealthOmics User Guide
なお --scratch-storage-mode が効くのは CPU タスクのみです。GPU タスクは常に LOCAL(ローカル NVMe)で、disk 指定はできません。
--scratch-storage-mode LOCAL を付けてランを実行します。コマンド内の --storage-type DYNAMIC は実行ストレージの種別(既定値の明示)で、エフェメラルストレージの設定とは別物です。
aws omics start-run \
--workflow-id 4627227 \
--role-arn <serviceRoleArn> \
--output-uri s3://<bucket>/output/ \
--storage-type DYNAMIC \
--scratch-storage-mode LOCAL \
--name ephemeral-local-run \
--region us-east-1
id が返り、ステータスは PENDING から始まります。
{
"arn": "arn:aws:omics:us-east-1:<ACCOUNT_ID>:run/3109928",
"id": "3109928",
"status": "PENDING",
"runOutputUri": "s3://.../output/3109928"
}
コンソールのラン詳細画面でも、ステータスが実行中であることを確認できます。
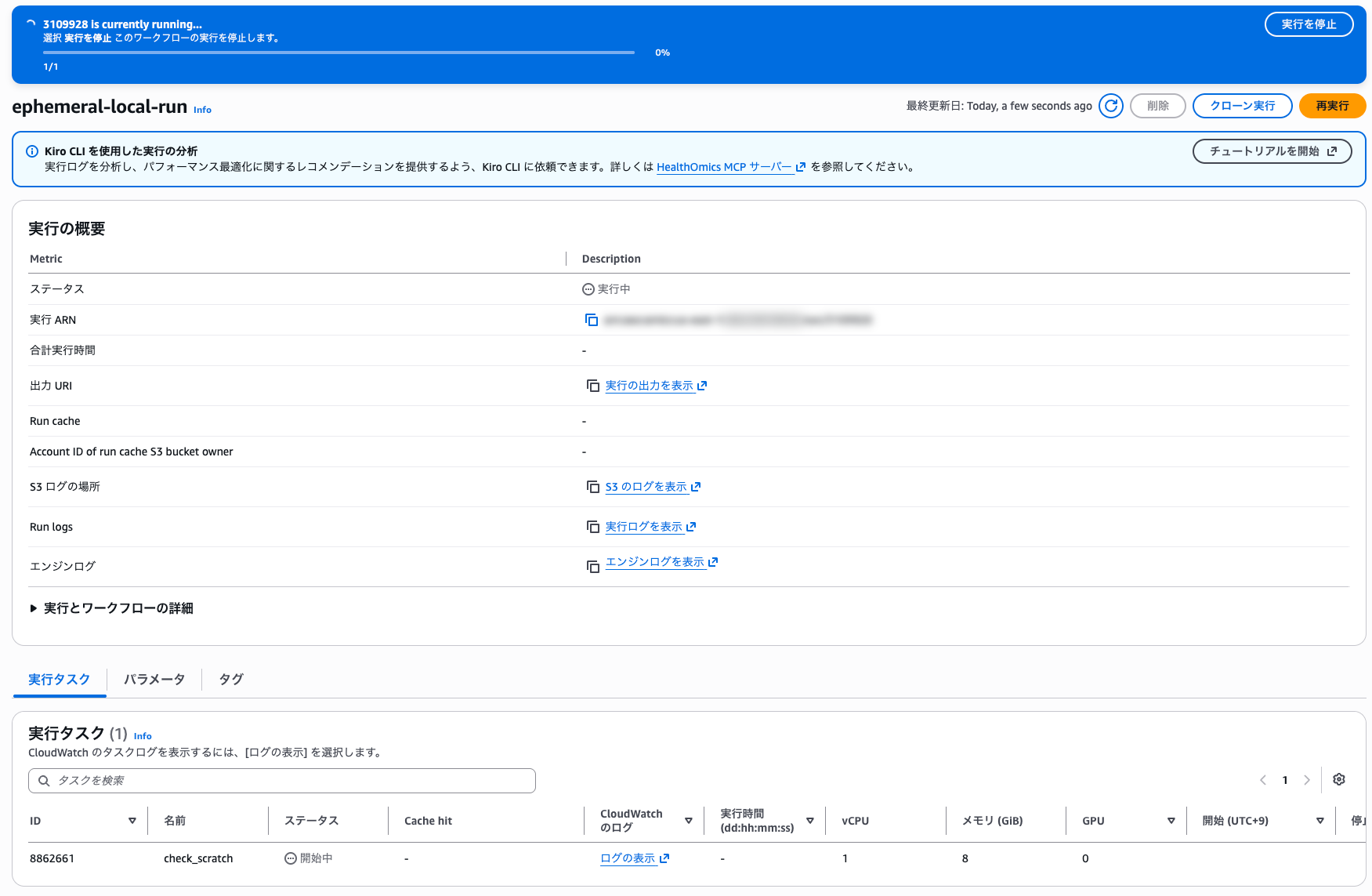
動作確認
get-run でステータスと scratchStorageMode を確認します。
aws omics get-run \
--id 3109928 \
--region us-east-1
scratchStorageMode が LOCAL で返れば有効化されています。このフィールドは --scratch-storage-mode を明示したランにのみ含まれます。ランは約 5 分 24 秒で COMPLETED になりました。
{
"status": "COMPLETED",
"scratchStorageMode": "LOCAL",
"storageType": "DYNAMIC",
"startTime": "2026-06-29T00:30:38Z",
"stopTime": "2026-06-29T00:36:02Z"
}
コンソールのラン詳細からも完了を確認しました。

完了後、S3 出力から scratch_report.txt を取得します。
aws s3 cp s3://<bucket>/output/3109928/pubdir/scratch_report.txt . --region us-east-1
/tmp がローカル NVMe デバイス /dev/nvme1n1(xfs)に 112 GiB でマウントされています。disk '100 GB' の指定が 16 GiB 刻みで切り上げられ 112 GiB(100 ÷ 16 = 6.25 を 7 に切り上げて 7 × 16)になりました。1 GiB 書き込むと使用量が 839M から 1.9G に増え、ローカルボリュームへ実際に書き込まれていることがわかります。
== df -h /tmp (before write) ==
Filesystem Size Used Avail Use% Mounted on
/dev/nvme1n1 112G 839M 112G 1% /tmp
== mount /tmp ==
/dev/nvme1n1 on /tmp type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,sunit=8,swidth=8,noquota)
== write 1 GiB to /tmp ==
== df -h /tmp (after write) ==
Filesystem Size Used Avail Use% Mounted on
+/dev/nvme1n1 112G 1.9G 111G 2% /tmp
タスクごとのメトリクスを記録する manifest ログにも、scratch ストレージの値が出力されます。scratchStorageReservedGiB が 112 で、df で見た 112 GiB と一致します。
{
"cpusReserved": 2,
"memoryReservedGiB": 4,
"runningSeconds": 15.94,
"scratchStorageReservedGiB": 112
}
公式ドキュメントでは使用量を表す scratchStorageUtilizedGiB も記録されるとされていますが、今回の manifest には現れませんでした。タスク実行が 15.94 秒と短くサンプリングできなかった可能性があります。プロビジョニング容量の scratchStorageReservedGiB(112)は出力されていました。
SHARED モードの場合
--scratch-storage-mode を省略するとデフォルトの SHARED になります。同じワークフローを SHARED で実行すると、/tmp の見え方が変わります。
このとき /tmp は専用ボリュームではなく実行ストレージ上に置かれます。今回は実行ストレージに DYNAMIC を使ったため /tmp は NFS(nfs4)になり、スクラッチ I/O はワーキングディレクトリと競合します。disk '100 GB' の指定も無視されています。
== df -h /tmp (before write) ==
Filesystem Size Used Avail Use% Mounted on
127.0.0.1:/e2/...service/tmp 8.0E 0 8.0E 0% /tmp
== mount /tmp ==
127.0.0.1:/e2/...service/tmp on /tmp type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,...)
エフェメラルストレージを使うには --scratch-storage-mode LOCAL の指定が必須で、省略すると disk ディレクティブは効きません。
まとめ
AWS HealthOmics のプライベートワークフローで各タスクの /tmp に専用ローカルボリュームをマウントできるようになりました。Nextflow の disk ディレクティブで容量を指定し、--scratch-storage-mode LOCAL を付けてランを実行します。デフォルト 16 GiB は無料で使えます。CPU タスクで LOCAL を省略すると disk が無視され、/tmp は共有 FS になります。
おわりに
ゲノム解析ツールの多くは中間ファイルを /tmp へ書き出したくなるので、エフェメラルストレージの登場でタスク単位の I/O 効率を上げやすくなりました。これは良いアップデート。









