
Claude DesktopのCoworkでエクセルファイル内のデータを分析してみた
データ事業本部の鈴木です。
AIエージェントは非常に強力なツールで、さまざまな業務を格段に速く行えるようになりました。
今回はClaude DesktopのCoworkでエクセルレポートの内容を抽出・追加分析してもらってみたのでご紹介します。
背景
AIエージェントが登場したことで、今まではなかなか自動化できず手動で行なっていたものの、効率化のヒントが見えてきた業務が多くあるのではないでしょうか。
エクセルの分析も1例に挙がると思います。スポットの分析なら手元にデータがあれば、エクセルを駆使してすぐに簡単な加工や可視化を行うことができます。
一方で、エクセルはデータが横持ちになりがちであったり、それ自体がレポートとなっていて、処理したいデータがシートの中途半端な位置から始まっていたりなど、追加の分析をしたくなった場合にはどうしてもプログラム化がしづらかったのではないでしょうか。
あるべき論で言えば、新規の分析をしたい場合、そもそもエクセルレポートのデータソースになっているデータソースからETLジョブでデータ分析用のシステムにデータを送り、レポートのためのBIツールやAIツールから利用するのが良いです。
ただ、いくら様々なツールがクラウドやSaaSで誰でも簡単に利用できるようになったとは言え、多少の準備期間や費用はかかりますし、その有効性を示すためにもまずは試しに分析をしたい場面はよくあると思います。
今回はそのようなケースを想定して、Claude Desktopの「Cowork」でどの程度のエクセルファイルなら処理可能かの肌感を紹介しつつ、データ分析基盤と組み合わせるとどんな棲み分けになるかを紹介します。
なお、Cowork機能については以下が参考になります。
準備
まずは分析対象とするエクセルのサンプルレポート作成と、検証に必要なClaude Desktopの設定を紹介します。
サンプルレポート
今回は以下のように1ヶ月ごとのなにかの製品の品番ごとの売上個数レポートを作成しました。
※内容はGPT-5.4に作ってもらったダミーデータです。
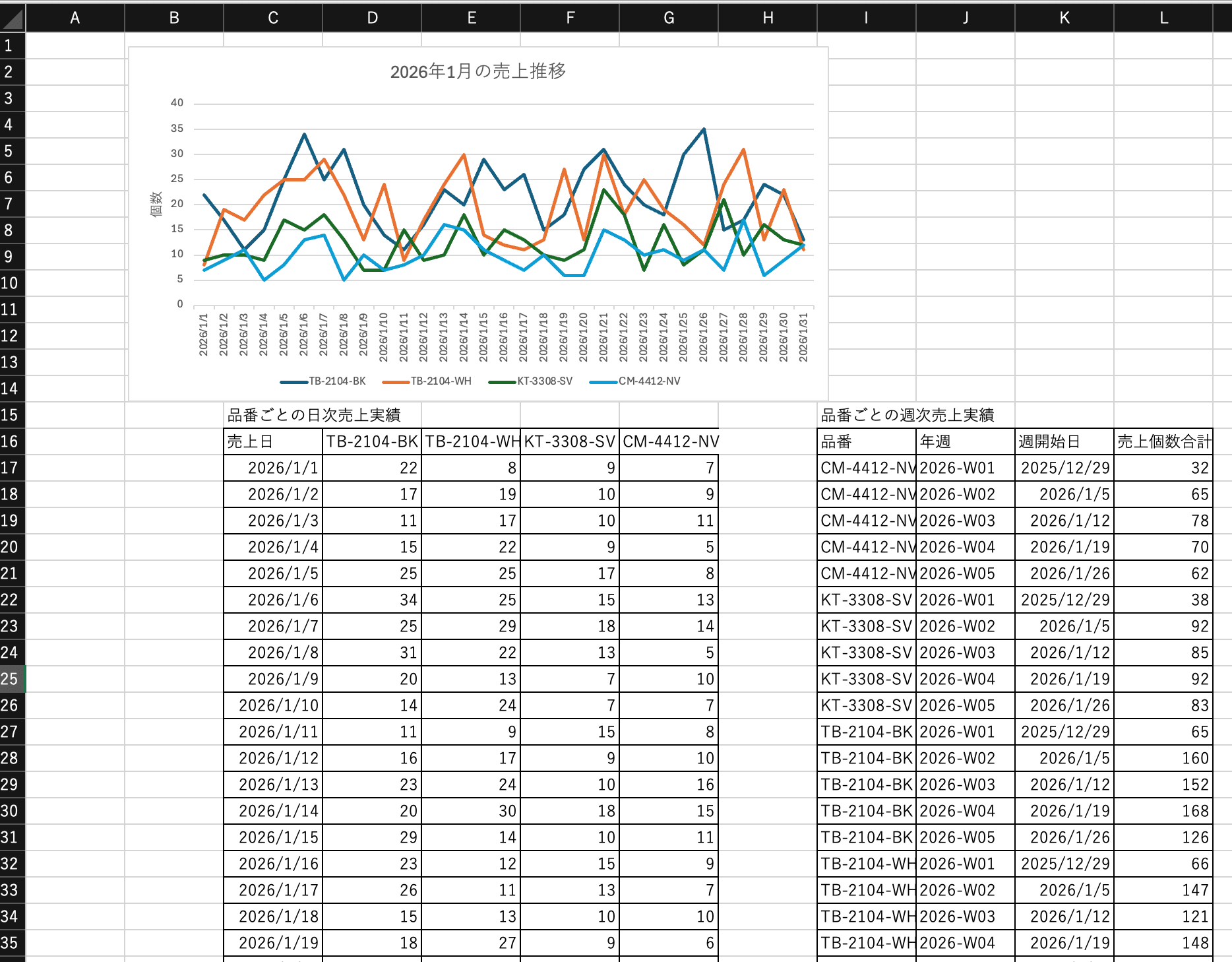
ポイントとして、このレポートは単純なシートではなく、今回Claudeで処理したいデータはシートの途中にあります。また、週単位の売上の表もごく近くにあります。
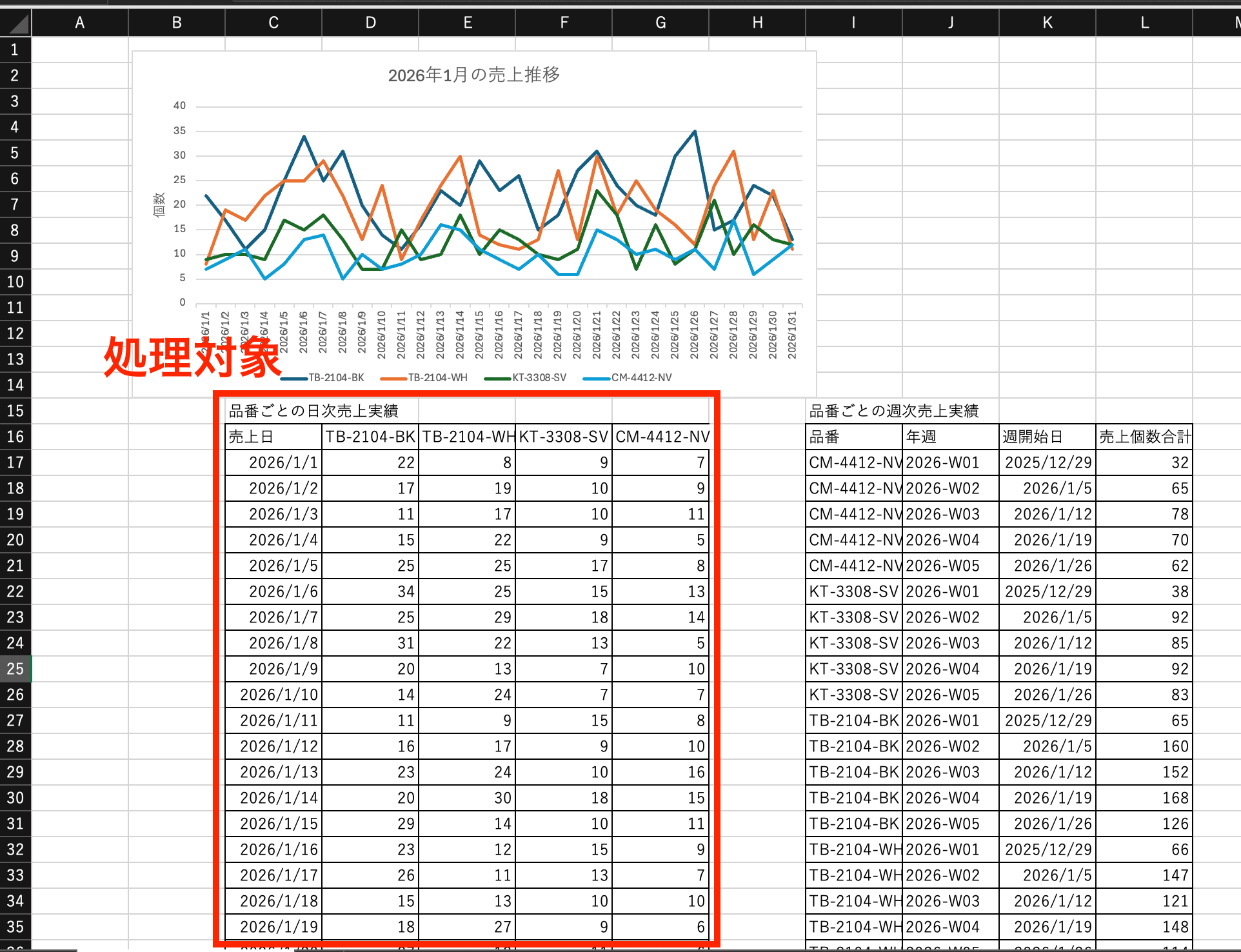
エクセルファイル中のシートはこの1枚です。複数シートあるエクセルファイルを分析することも想定されますが、その場合はプロンプトでどんなデータがどのシートにあるかくらいは指定すると思うので、今回の条件でも十分と考えました。
同じレイアウトで値や日数は異なるものを2026/1 ~ 2026/3まで作成しました。
Claude Desktopの設定
必須ではないですが、Claudeが処理対象のレポートがあるディレクトリを操作できるよう、filesystemMCPサーバーを設定しました。
また、後述するDuckDBも試したかったので、duckdbMCPサーバーも設定しました。
以下のようにclaude_desktop_config.jsonを変更しました。
各種パスは自身のものに置き換えてください。
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"レポートがあるディレクトリパス"
]
},
"duckdb": {
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path",
"ローカルのDBファイルパス"
]
}
},
...他の設定...
}
- https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem
- https://github.com/motherduckdb/mcp-server-motherduck
特にserver-filesystemは以下も参考になりました。
やってみた
ローカル上のサンプルレポートをデータソースに、Claudeで内部的にPythonを書かせて分析する例と、DuckDBというノートパソコンなどでも実行可能な列指向RDBMSをClaudeと組み合わせて使う例を試してみます。
1. エクセルレポートを直接処理する例
まずはエクセルレポートを直接処理する例を実施してみました。
Coworkを開き、レポートのあるディレクトリを指定し、エクセル売上レポートフォルダ内のエクセルレポート内の売上実績値から、TB-2104-BKの2026年1,2,3月の総売上個数推移を見たい。のプロンプトで問い合わせをしました。モデルはSonnet 4.6を使いました。
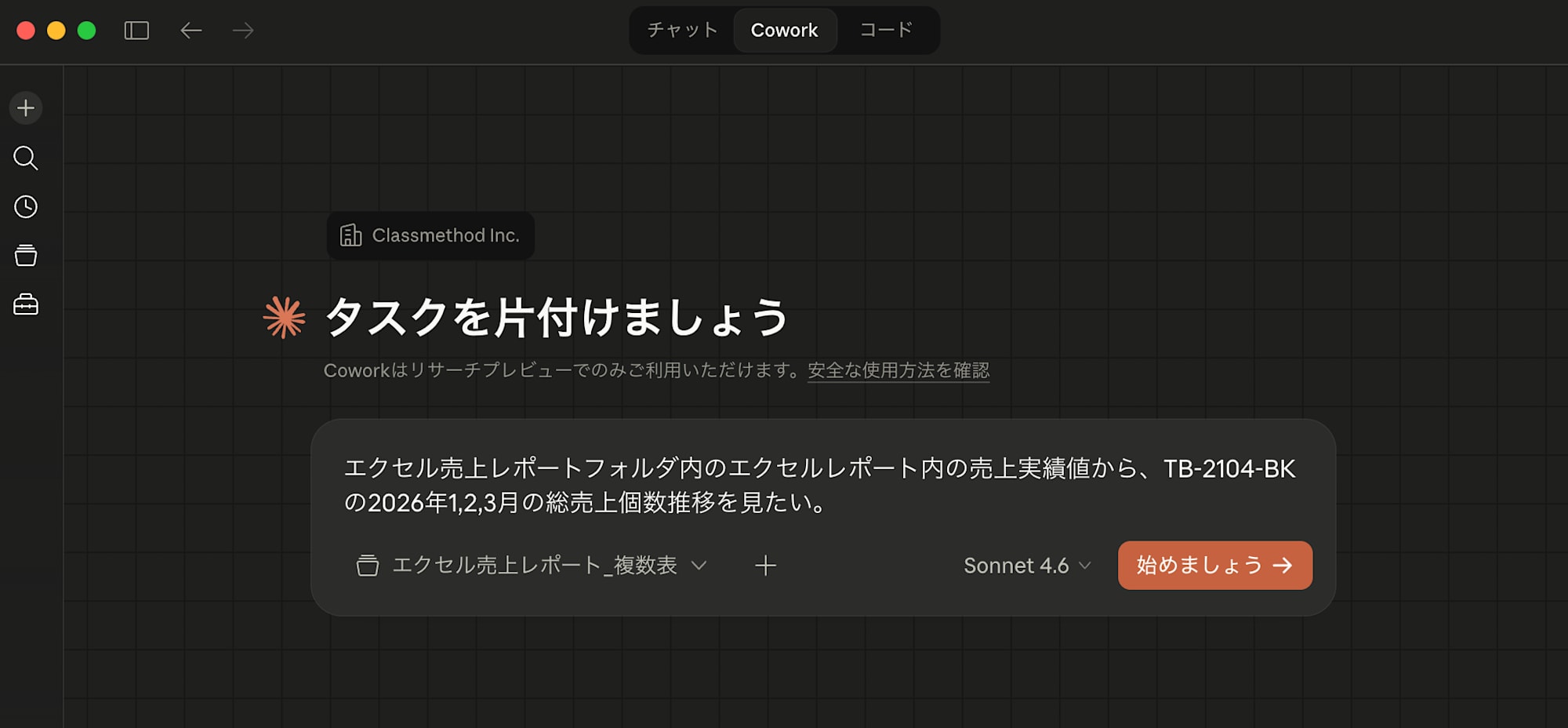
以下のように分析を行い、回答および新規のエクセルファイルに分析をまとめてくれました。
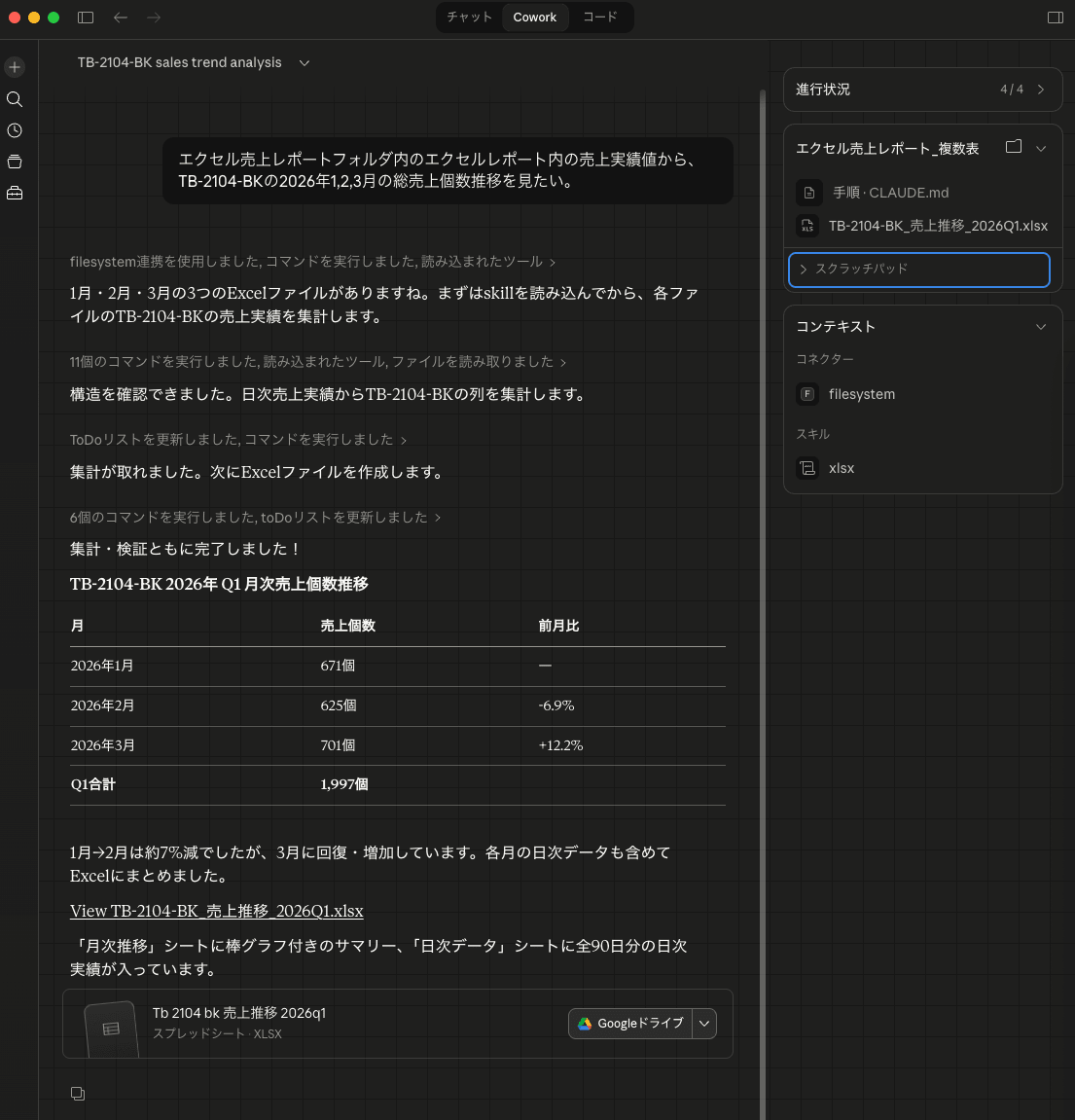
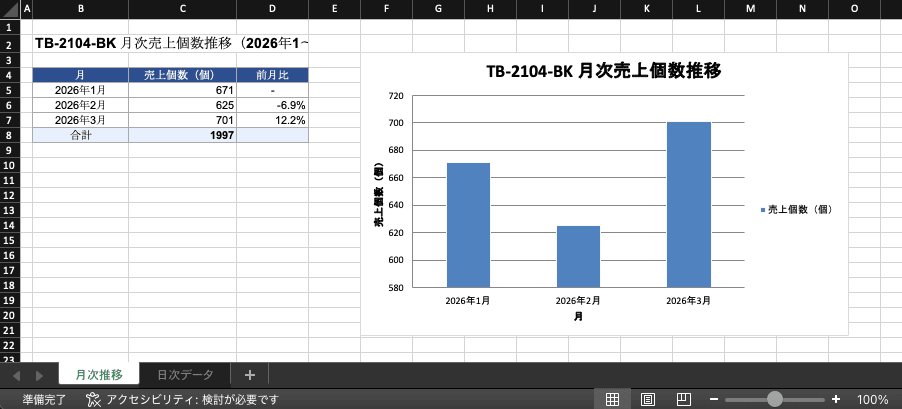
作成されたエクセル結果は以下のようになります。いい感じですね!
特に気になるエクセルからの読み込みは、以下のようにPythonスクリプトでエクセルファイルを解析していました。
python3 << 'EOF'
import os, pandas as pd
base = '/sessions/gracious-inspiring-darwin/mnt/'
folder = None
for f in os.listdir(base):
if 'エクセル' in f:
folder = os.path.join(base, f)
break
months = {
'2026-01': '売上レポート202601.xlsx',
'2026-02': '売上レポート202602.xlsx',
'2026-03': '売上レポート202603.xlsx',
}
results = {}
for month_key, fname in months.items():
path = os.path.join(folder, fname)
df = pd.read_excel(path, sheet_name=0, header=None)
# ヘッダー行を探す(「売上日」が含まれる行)
header_row = None
tb_col = None
for i, row in df.iterrows():
for j, val in row.items():
if val == '売上日':
header_row = i
break
if header_row is not None:
break
# 品番列のインデックスを特定
header = df.iloc[header_row]
for j, val in header.items():
if val == 'TB-2104-BK':
tb_col = j
break
print(f"{month_key}: header_row={header_row}, TB-2104-BK col={tb_col}")
# データ行を抽出
data = df.iloc[header_row+1:].copy()
date_col = header[header == '売上日'].index[0]
# 日付列と売上列を取得
dates = pd.to_datetime(data.iloc[:, date_col], errors='coerce')
sales = pd.to_numeric(data.iloc[:, tb_col], errors='coerce')
valid = dates.notna() & sales.notna()
total = int(sales[valid].sum())
daily_data = list(zip(dates[valid].dt.strftime('%Y-%m-%d'), sales[valid].astype(int)))
results[month_key] = {'total': total, 'daily': daily_data}
print(f" 月間合計: {total}個")
print(f" 日次データ件数: {len(daily_data)}")
print("\n=== 月次推移サマリー ===")
for month, data in results.items():
print(f"{month}: {data['total']}個")
EOF
確かにこういったスクリプトを書けばこのエクセルから該当箇所を抜き出して処理することが可能です。人間だとこのような細かなファイル操作のスクリプトを書くのに結構時間がかかってしまいますが、一瞬で書けてしまうのはAIの強みですね。
今回使ったサンプルのエクセルファイルくらいであれば、Claudeにお願いするだけで大体の分析はできそうです。これより複雑なエクセルファイルや、データ量が非常に多い場合は難しいこともありそうです。
また、Pythonスクリプトを読むと、プロンプトで指定した特定の品番を手がかりにデータを読み取っています。ほかの品番の質問をすると、生成するスクリプトは変わりそうです。
この処理の汎用性は使うモデルや会話履歴にもよると思いますが、考え方としてはプロンプトごとに毎回ゼロから行われると思うのが良さそうです。
2. DuckDBを使う例
①エクセルからのデータ抽出と整然データ化
先の例だとプロンプトに応じた書き捨てのPythonスクリプトをClaudeが書いてエクセルファイルからデータを取得・集計してくれましたが、もう少しSQLも交えて汎用的に寄せたい場合は、DuckDBも便利です。
エクセルだと、今回のレポート例のように横持ちで持つことが多いですが、SQLで分析する場合、整然データと呼ばれる縦持ちの形にした方がかなり簡潔に処理を表現できます。
簡潔にSQLをかけた方がトークン数削減や処理速度アップに繋がりやすいです。
まずは整然データに加工するため、スキルを作成しました。
※流れが若干唐突ですが、直前に一度試してみて、処理を使い回ししたいなと思ったのでスキル化しました。
Claude DesktopからClaudeでクリエイティブにでスキルを作成しました。
処理内容を伝えます。
今回のタスクは難なくできて、スキルも作成されました。
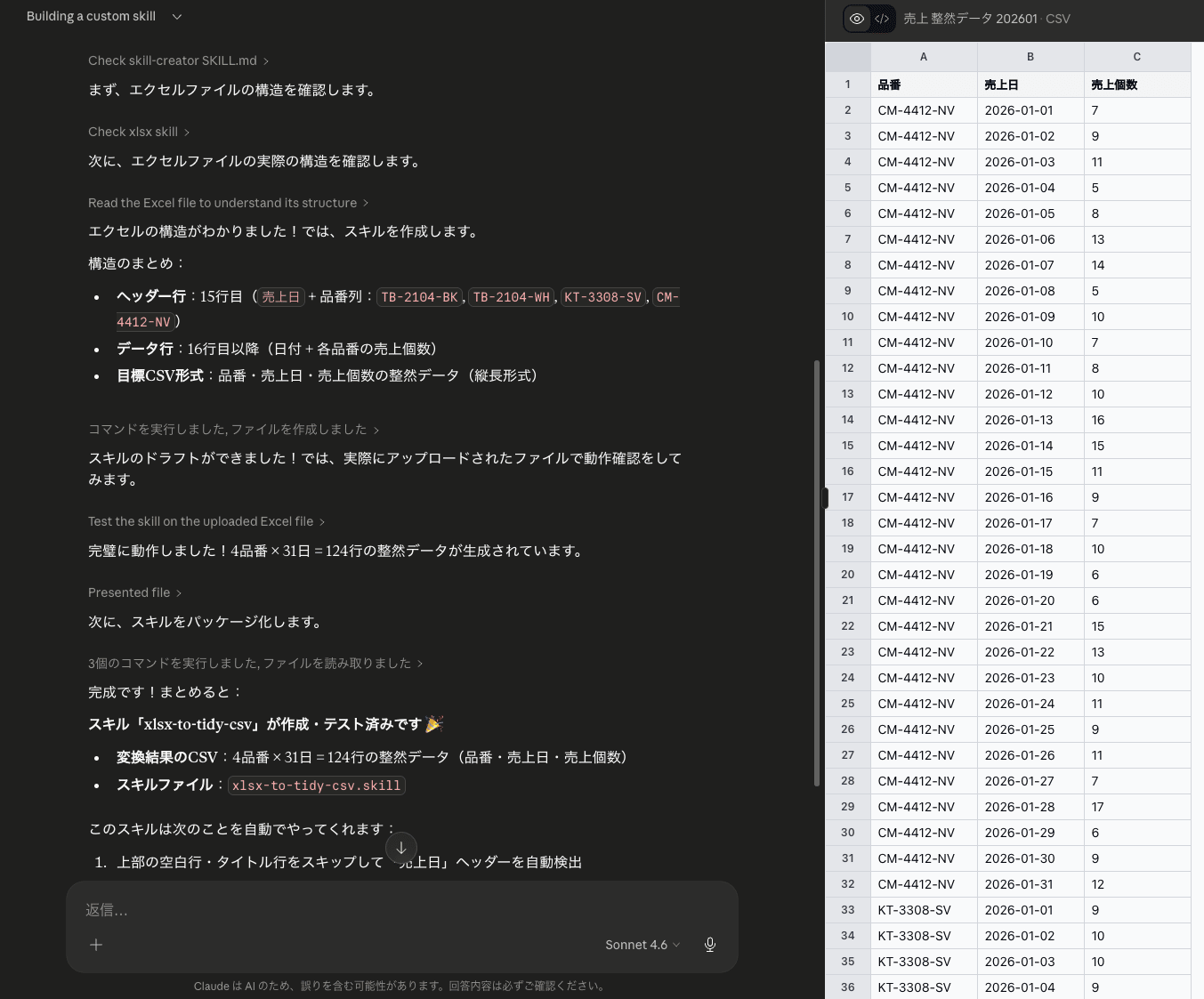
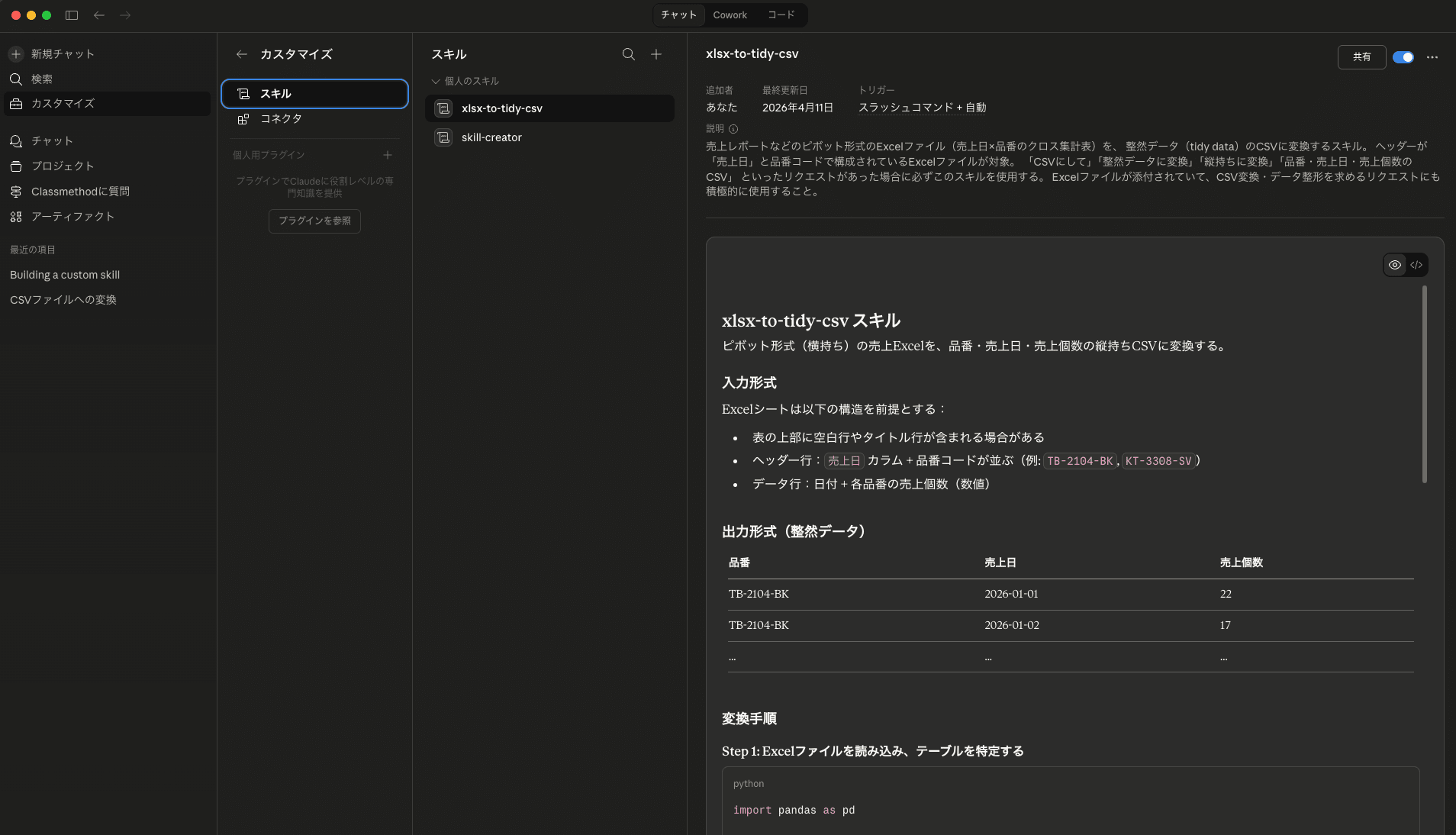
このスキルを使って、エクセル内からデータを抜き出し、整然形式に持ち直ししてもらいました。
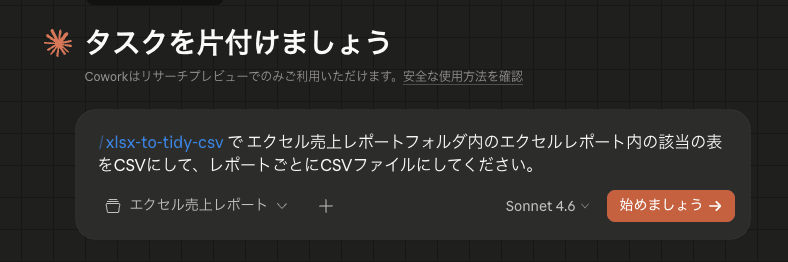
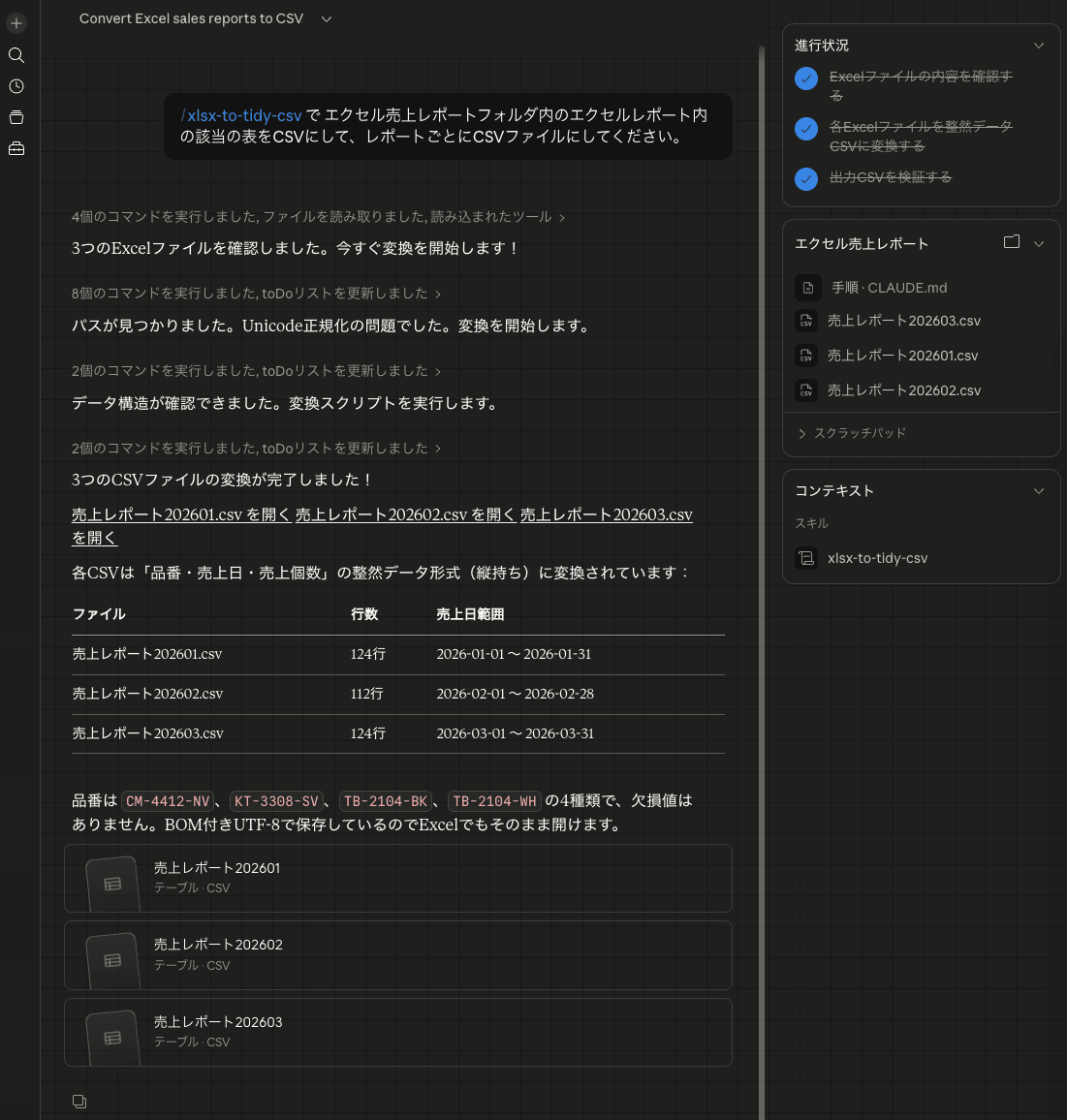
②DuckDBでの分析
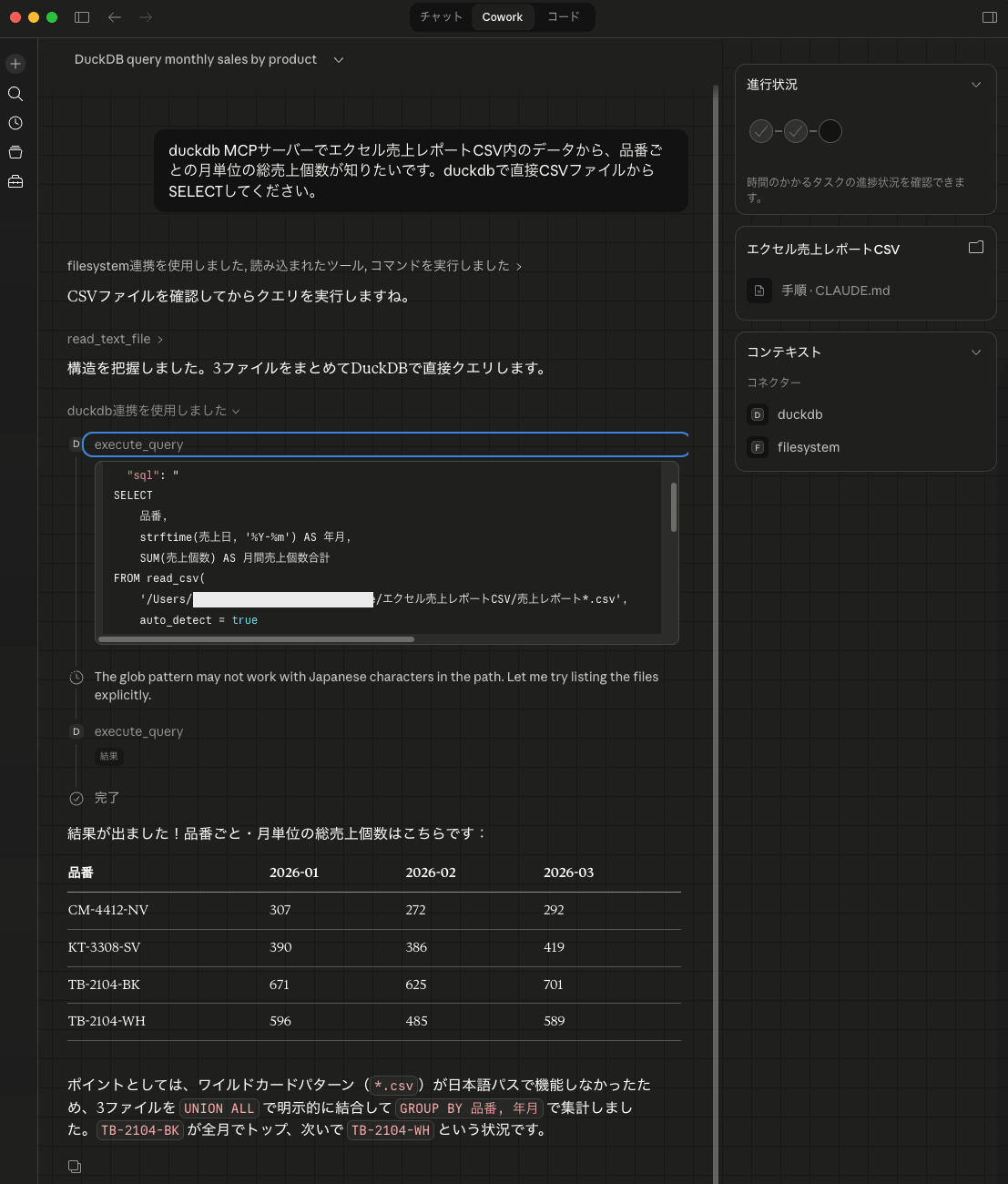
ここまでできると手動でDuckDBで分析できますが、せっかくなのでClaude Desktopから分析してもらいましょう。整然データはエクセル売上レポートCSVというディレクトリに配置されたとして、以下のように分析を依頼しました。
duckdb MCPサーバーでエクセル売上レポートCSV内のデータから、品番ごとの月単位の総売上個数が知りたいです。duckdbで直接CSVファイルからSELECTしてください。
以下のようにSQLで分析してくれました。縦持ちにした甲斐もあって、先ほどのPythonスクリプトに対して圧倒的に簡潔ですね。
データ分析基盤との棲み分け
データ向けのプラットフォームが必要になる背景
ここまでで、「データ分析ってエクセルとClaudeだけあれば良くない?」と思ってしまいます。もちろんPythonでデータ分析が済むような分析であれば十分な場合もありますが、より大きな規模も含む一般的なケースでは以下のような課題になります。
- 分析対象のデータ量が多く、大きなコンピューティングリソースが必要
- 複数の従業員で使うため、共通プラットフォームが必要
- 固定のモニタリング観点があり、ダッシュボードの方が適している
- 継続的に集計・分析を実行したい
- ローカル環境上にデータを保存したくない
など...
こういった課題は現在ではクラウドデータウェアハウスを中核としたデータ分析基盤を構築することが一般的な解決策の一つになっており、AWSやGoogle Cloudを始めとした様々な製品があります。
私は直近ではSnowflakeをよく使っているため、ここではSnowflakeを念頭に説明します。
ざっくりとしたデータ活用までの道筋を以下のように図示しました。今回はバッチ処理を念頭にメダリオンアーキテクチャを想定しました。
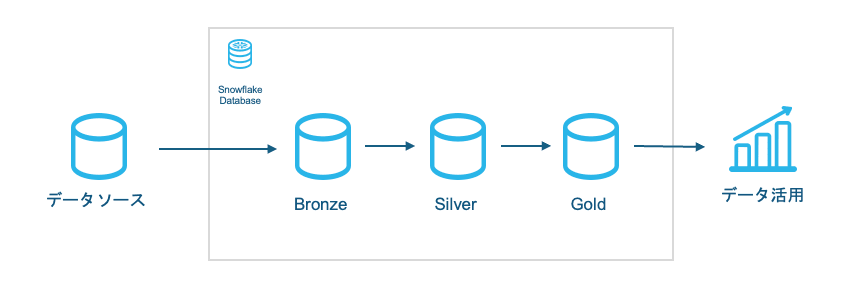
メダリオンアーキテクチャは大きく3つの層から構成されます。
まず業務データベースから分析したいデータを取り出してデータウェアハウスに取り込んだものがブロンズ層、クレンジングや標準化・重複排除・整合性確認などを行ったキュレーション済みのものがシルバー層、プロジェクト向けに分析しやすいよう非正規化や集計が行われたものがゴールド層です。
今回Claudeで行なったサンプルレポートは、「業務データベースのデータを、手動や業務アプリを使ってレポート化して取得したもの」をイメージしています。つまりかなり後工程の成果物をClaudeで処理しました。
より様々なデータ分析を継続的に業務データを元に行う場合、業務データベースや業務アプリの役割や負荷が重くなってしまうため、上記のようなデータ向けの仕組みの導入が求められます。
Snowflakeを例にネイティブのデータ活用機能と比較
例えばSnowflakeではネイティブのリモートMCPサーバーがあり、Claudeがデータを使えるように設定することもできます。ネイティブのAI機能もあり、よりSnowflake内のデータを活用するのに特化したCortex Agentsというエージェント機能があります。この機能もMCPサーバー経由で利用できます。
Snowflake IntelligenceというCortex Agents向けのSnowflakeネイティブのUIも用意されています。
また、Cortex Codeという機能も提供されており、自然言語でSnowflake内のデータ分析やコード生成、操作も可能です。
ここまで、AIエージェントの紹介が多くなりましたが、既存のBI機能が不要になった訳ではなく、目的に応じて合わせて使うのが良いと考えています。こちらについては以下で紹介しました。
SnowflakeではStreamlit in Snowflakeという機能があり、Pythonスクリプトで定義したデータアプリを構築できます。Pythonといっても、Cortex Codeもあるため実装自体はかなり簡単になりましたが、ノーコーディングが望ましい場合は別途BIツールが必要かもしれません。
最後に
Claude DesktopのCoworkを使って、エクセルレポート内のデータに対する分析が可能か確認しました。また、Claude Desktopでカバーできるケースとデータ分析基盤が必要になるケースについても比較しました。参考になりましたら幸いです。










