
【アップデート】Cloud Run Worker PoolsがGAになりました
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年4月14日付の Google Cloud リリースノートにて、Cloud Run Worker PoolsがGAとなりました。
Worker Pools は 2025年6月25日に Preview として公開されましたが、今回正式に GA となったことで SLA の保証された本番環境での利用が可能になりました。
今回は、Cloud Run Worker Pools の概要と Service・Job との違い、そして Pub/Sub プルサブスクリプションのコンシューマーを Worker Pool としてデプロイし、メッセージ処理を確認するまでの流れを見ていきたいと思います。
Cloud Run Worker Pools とは
Cloud Run では、コードをService、Job、 Worker Pool の 3 つのリソースタイプで実行できます。
| リソース | 概要 |
|---|---|
| Service | HTTP リクエストに応答するステートレスなインスタンス。トラフィックに応じてオートスケール |
| Job | 並列実行可能なタスクを手動またはスケジュールで実行し、完了まで処理する |
| Worker Pool | Kafka コンシューマ・Pub/Sub プル・RabbitMQ など、常時稼働するバックグラウンドワークロードを処理する |
Worker Pools は HTTP リクエストを必要としないプル型のバックグラウンドワークロードのために設計されたリソースタイプです。ロードバランサ経由の URL を持たないため、パブリックエンドポイントを不要とし、ネットワーク構成をシンプルに保てます。
Service との主な違い
| 項目 | Service | Worker Pool |
|---|---|---|
| エンドポイント(URL) | あり(ロードバランサ経由) | なし |
| オートスケーリング | 対応 | 非対応(手動スケーリング) |
| ロールアウト方式 | トラフィック分割 | インスタンス数分割 |
| ヘルスチェックポート | 必要 | 不要 |
| 課金モデル | リクエストベースまたはインスタンスベース | インスタンスベースのみ |
Worker Pools の主な特徴
手動スケーリング
Worker Pools はオートスケーリングをサポートしません。インスタンス数を手動で設定して使用します。ただし、Cloud Workflows や外部のオートスケーラーと組み合わせることで独自のスケーリングロジックを実装できます。Kafka コンシューマ向けには公式のオートスケーラーサンプルも提供されています。
デプロイ時はインスタンス数を 0 に設定することで Worker Pool を無効化でき、稼働中のインスタンス数の変更にはリデプロイ不要でスケール操作を実行できます。
リビジョン管理とロールアウト
Worker Pools もリビジョン管理に対応しています。新しいコンテナイメージのデプロイや設定変更時には新しいリビジョンが作成されます。ロールアウトはトラフィック分割ではなくインスタンス数の分割で制御します。たとえば 4 インスタンスのワーカープールに対して、新リビジョンに 25%(1 インスタンス)、安定版に 75%(3 インスタンス)を割り当てることが可能です。
VPC・GPU サポート
- Direct VPC egress/ingress に対応しており、VPC 内のリソース(Cloud SQL、Memorystore、Kafka など)へのプライベートアクセスが可能です
- NVIDIA L4 GPU(24 GB VRAM)をアタッチできます(NVIDIA RTX PRO 6000 Blackwell は Preview)
課金
Worker Pool の起動中はすべてのインスタンスがアクティブインスタンスとして課金されます(アイドル状態も同様)。インスタンスが停止している間は課金されません。最新の料金は公式の料金ページを参照してください。
ユースケース
Worker Pools が特に適しているシナリオは以下のとおりです。
- プル型メッセージング: Kafka Consumer、Pub/Sub プルサブスクリプション、RabbitMQ コンシューマ
- バッチ処理のポーリングループ: HTTP リクエストを受け付けず、キューや外部ストレージを定期的にポーリングして処理を実行するワークロード
- 常時稼働バックグラウンド処理: ストリームデータ処理、ログ収集エージェントなど
これらのユースケースではエンドポイントや HTTP ポートの管理が不要になり、処理ロジックのみに集中できます。
試してみた
Pub/Sub プルサブスクリプションのメッセージを継続的に処理するコンシューマーを Worker Pool としてデプロイし、実際にメッセージを投入して処理されることを確認します。
前提条件
- Google Cloud プロジェクトが作成済みであること
gcloudCLI がインストール・認証済みであること
ハンズオンの実行には、以下の IAM ロールが必要です。
| ロール | 用途 |
|---|---|
roles/run.admin |
Worker Pool のデプロイ・更新・削除 |
roles/cloudbuild.builds.editor |
ソースデプロイ時の Cloud Build ビルド実行 |
roles/artifactregistry.repoAdmin |
Artifact Registry リポジトリの作成・コンテナイメージのプッシュ |
roles/pubsub.admin |
Pub/Sub トピック・サブスクリプションの作成・IAM 設定・メッセージ発行 |
roles/iam.serviceAccountAdmin |
サービスアカウントの作成・削除 |
roles/iam.serviceAccountUser |
デプロイ時にカスタム SA を指定する権限 |
roles/serviceusage.serviceUsageAdmin |
必要な API の有効化 |
環境変数の設定と API の有効化
export PROJECT_ID="your-project-id" # ご自身のプロジェクト ID に変更してください
export REGION="asia-northeast1"
export TOPIC_ID="worker-pool-topic"
export SUBSCRIPTION_ID="worker-pool-subscription"
export WORKER_POOL_NAME="pubsub-consumer"
export CONSUMER_SA="worker-pool-consumer-sa"
gcloud config set project $PROJECT_ID
# 必要な API を一括で有効化
gcloud services enable \
run.googleapis.com \
pubsub.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
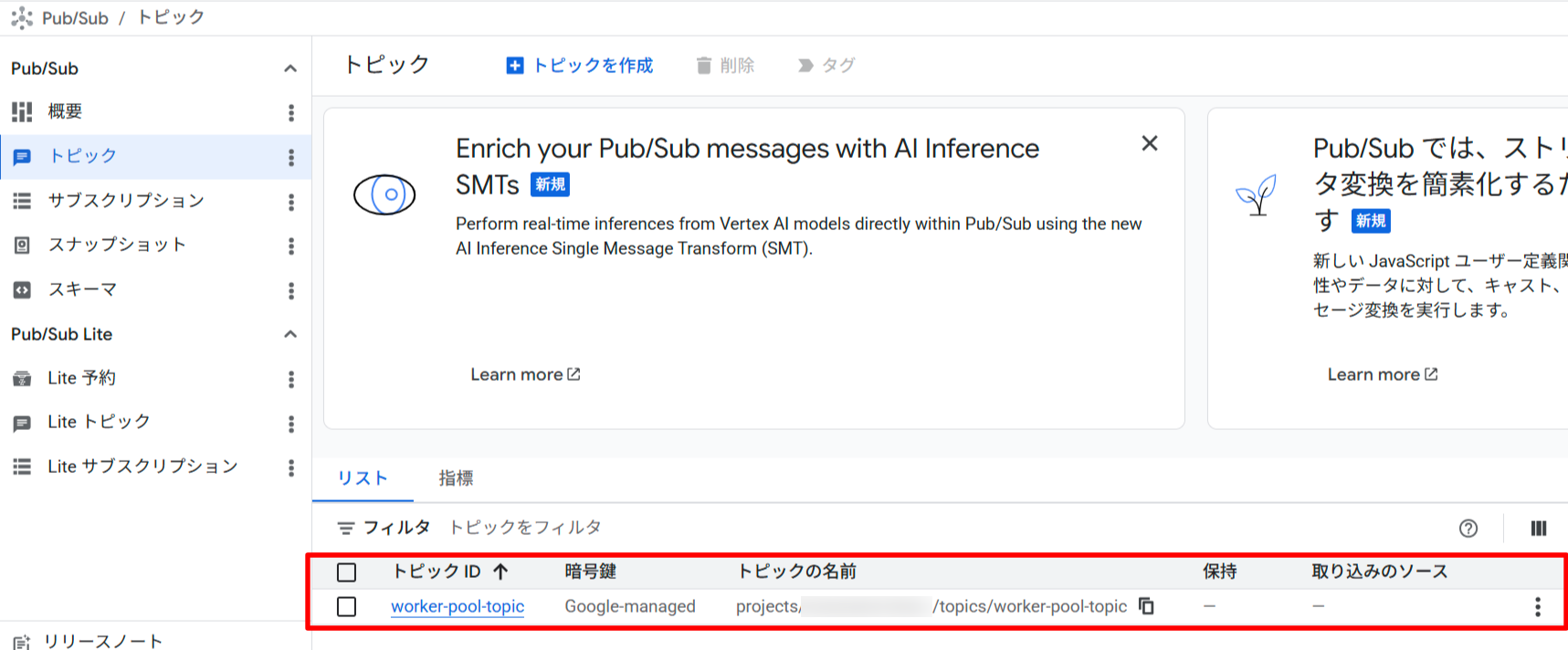
Pub/Sub トピックとサブスクリプションの作成
# トピックの作成
gcloud pubsub topics create $TOPIC_ID
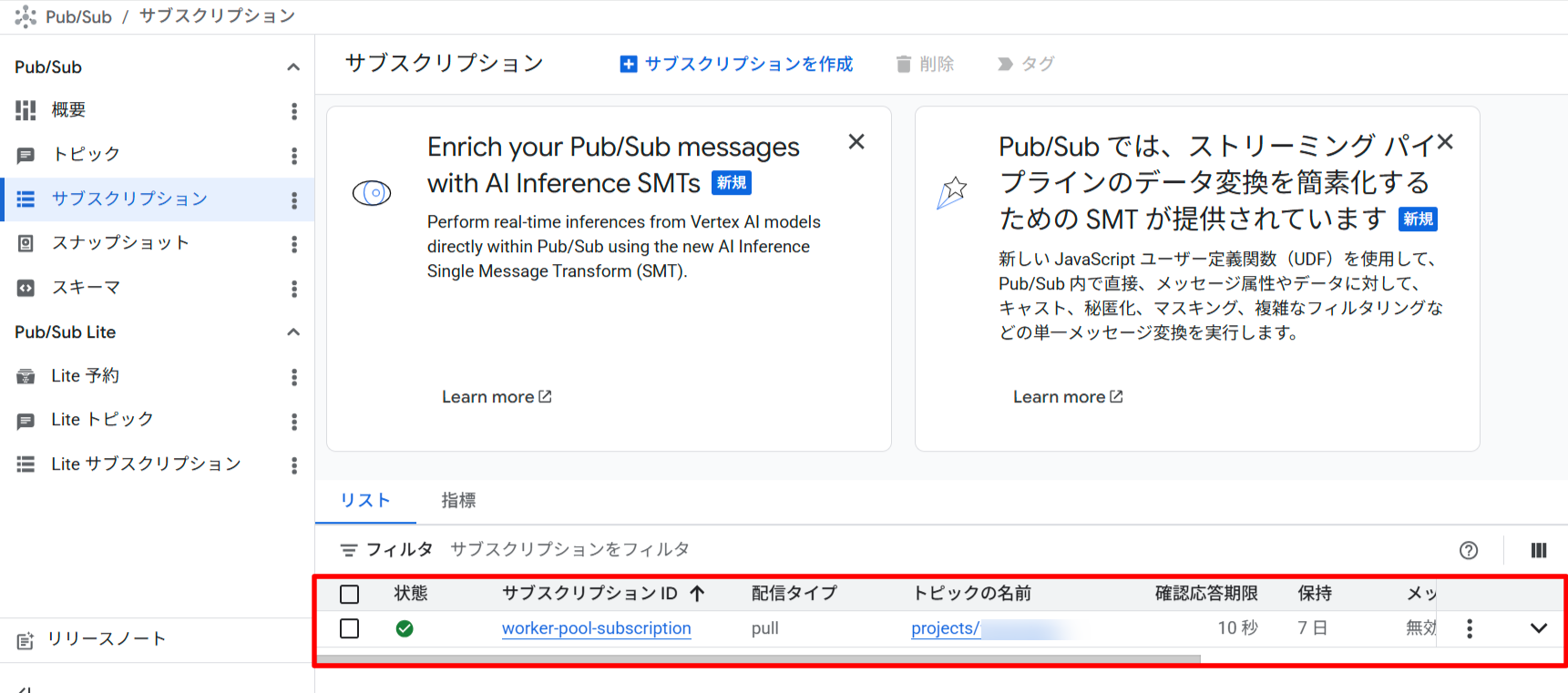
# プルサブスクリプションの作成
gcloud pubsub subscriptions create $SUBSCRIPTION_ID \
--topic=$TOPIC_ID
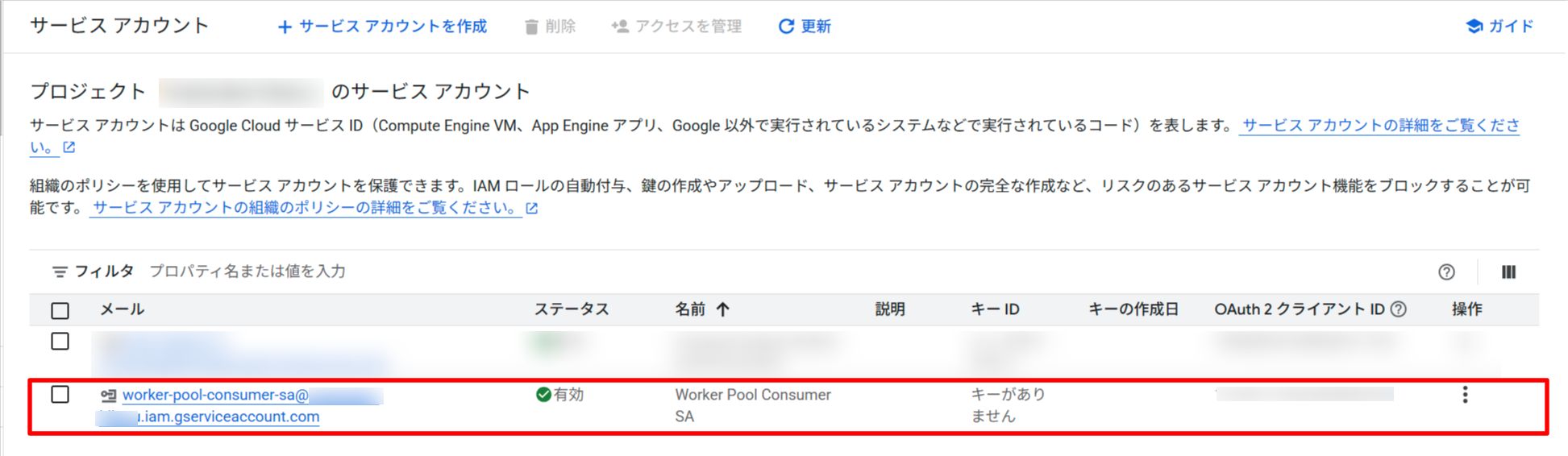
サービスアカウントの作成と権限付与
Worker Pool が Pub/Sub からメッセージをプルできるよう、専用のサービスアカウントを作成して最小権限を付与します。
# サービスアカウントの作成
gcloud iam service-accounts create $CONSUMER_SA \
--display-name="Worker Pool Consumer SA"
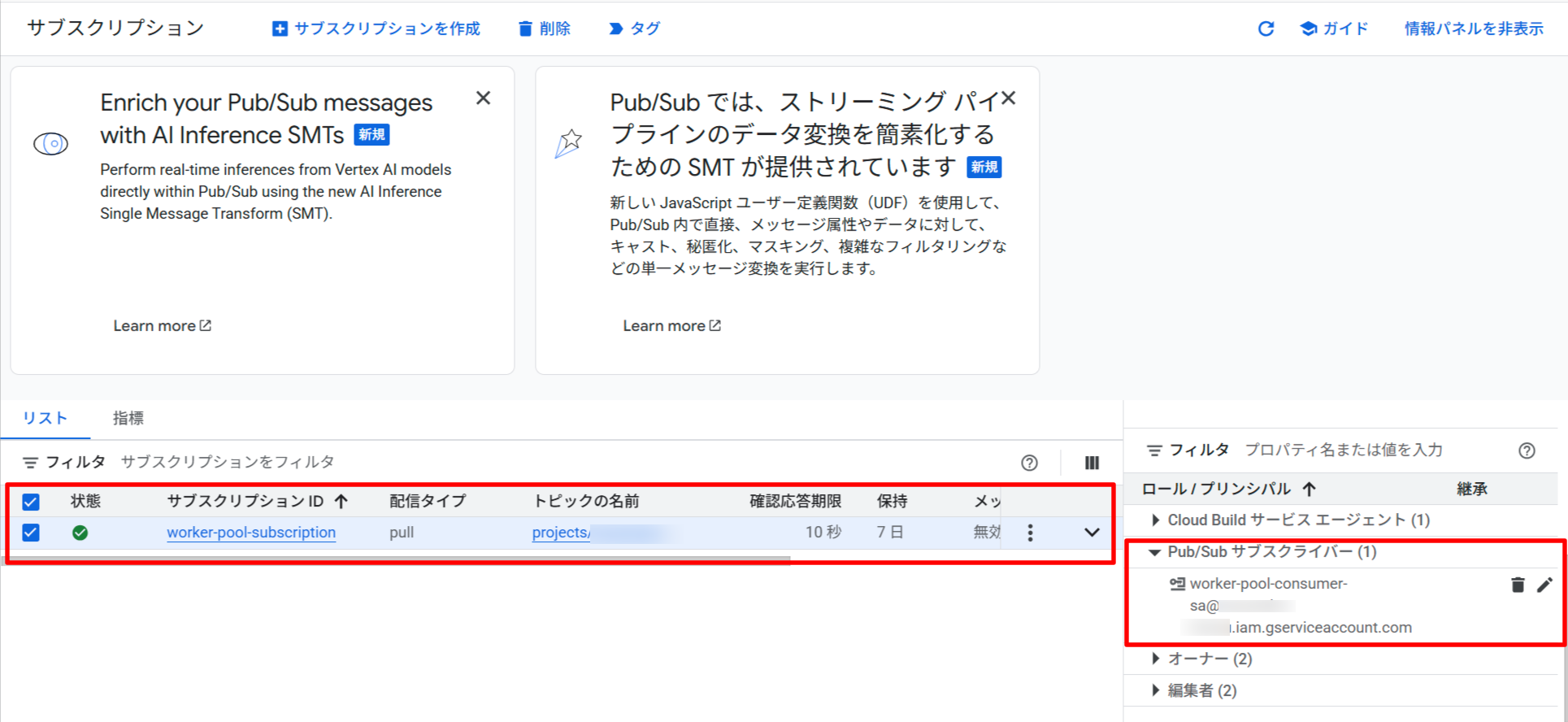
# Pub/Sub サブスクリプションのプル権限を付与
gcloud pubsub subscriptions add-iam-policy-binding $SUBSCRIPTION_ID \
--member="serviceAccount:$CONSUMER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/pubsub.subscriber"
ワーカーコードの作成
作業ディレクトリを作成してコンシューマーコードを記述します。
mkdir pubsub-consumer && cd pubsub-consumer
worker.py
import os
import time
from google.cloud import pubsub_v1
PROJECT_ID = os.environ.get('PROJECT_ID')
SUBSCRIPTION_ID = os.environ.get('SUBSCRIPTION_ID')
subscription_path = f"projects/{PROJECT_ID}/subscriptions/{SUBSCRIPTION_ID}"
print(f"Worker Pool instance starting. Watching {subscription_path}...")
subscriber = pubsub_v1.SubscriberClient()
def callback(message):
try:
data = message.data.decode("utf-8")
print(f"Processing job: {data}")
time.sleep(2) # 処理のシミュレーション
print(f"Done: {data}")
message.ack()
except Exception as e:
print(f"Error processing message: {e}")
message.nack()
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
print(f"Listening for messages on {subscription_path}...")
with subscriber:
streaming_pull_future.result()
Dockerfile
FROM python:3.12-slim
RUN pip install google-cloud-pubsub
COPY worker.py .
CMD ["python", "-u", "worker.py"]
Worker Pool のデプロイ
--source . を指定することで、ローカルのコードを Cloud Build でビルドし、Artifact Registry に push して Worker Pool としてデプロイします。
gcloud beta run worker-pools deploy $WORKER_POOL_NAME \
--source . \
--region $REGION \
--service-account="$CONSUMER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID,SUBSCRIPTION_ID=$SUBSCRIPTION_ID
デプロイ完了後、Cloud Run コンソールの Worker pools に pubsub-consumer が表示されます。
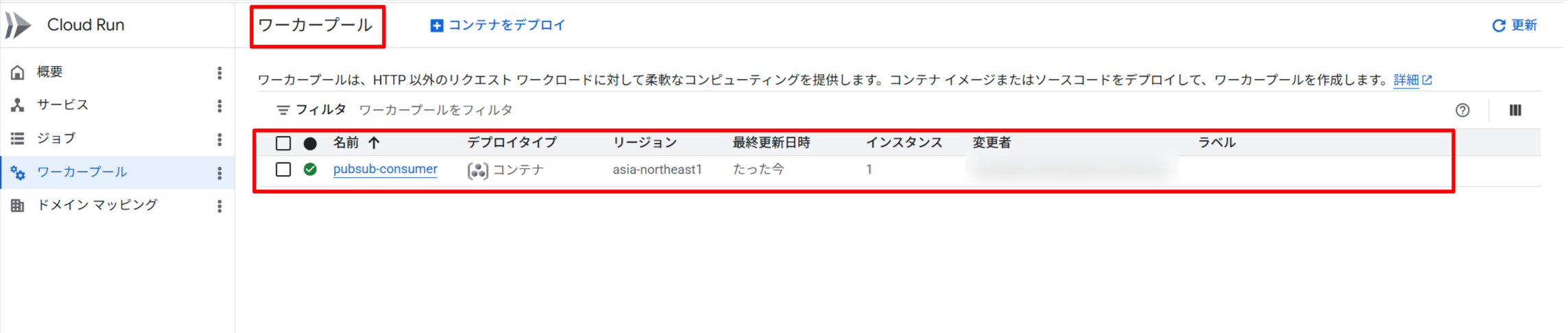
テストメッセージのパブリッシュと処理確認
Pub/Sub トピックにメッセージを投入して、Worker Pool がプルして処理することを確認します。
# テストメッセージを 3 件パブリッシュ
gcloud pubsub topics publish $TOPIC_ID --message "job-001"
gcloud pubsub topics publish $TOPIC_ID --message "job-002"
gcloud pubsub topics publish $TOPIC_ID --message "job-003"
Cloud Console の Worker pools → pubsub-consumer → Logs タブでログを確認すると、以下のような出力が確認できます。
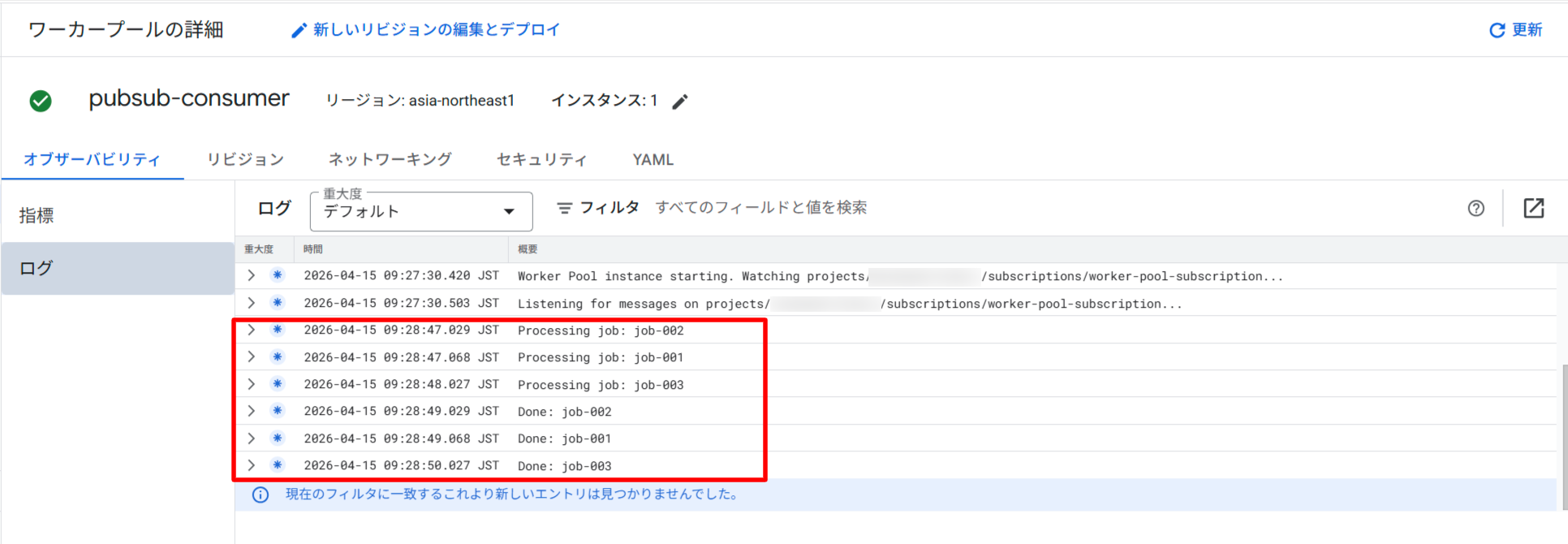
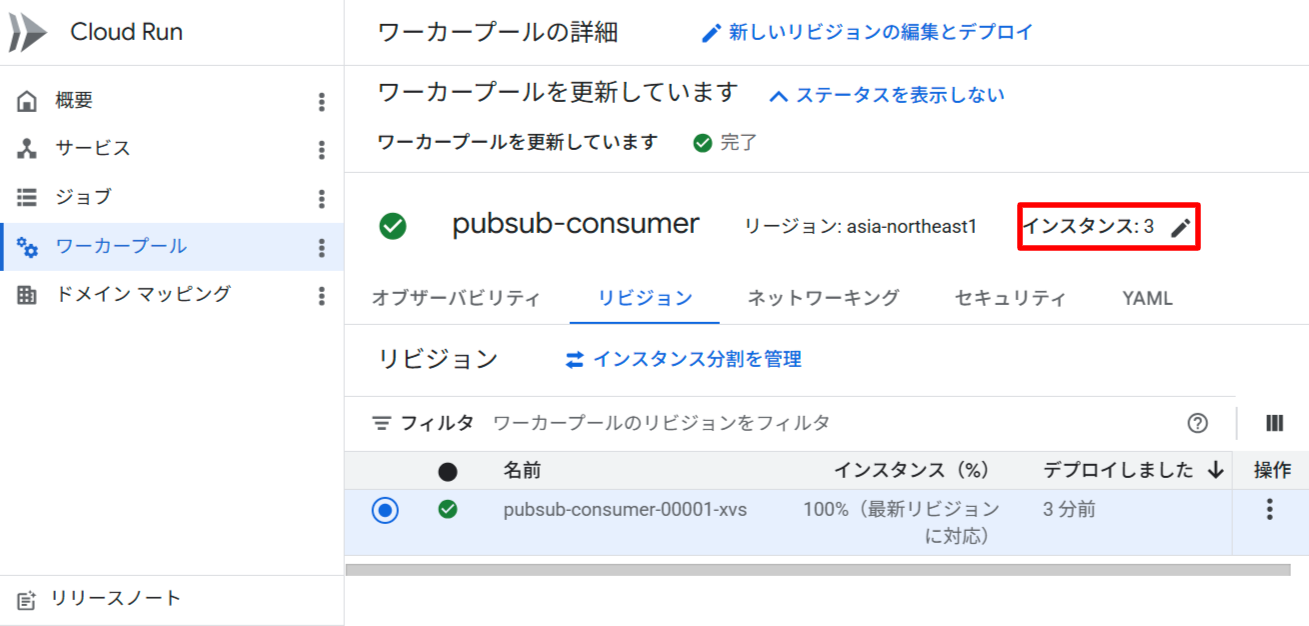
インスタンス数のスケール
メッセージ量が増えた場合、インスタンス数を増やすことでスループットを向上させられます。スケールにリデプロイは不要です。
# インスタンス数を 3 に変更
gcloud beta run worker-pools update $WORKER_POOL_NAME \
--instances 3 \
--region $REGION
注意点と制限事項
- gcloud コマンドは
betaサブコマンド: 現時点ではgcloud beta run worker-poolsの形式でのみ操作できます。GA 後もこの形式が継続している場合があります - オートスケーリング非対応: デフォルトのオートスケーリングはないため、動的なスケーリングが必要な場合は Cloud Workflows や外部システムとの連携が必要です
- 最小インスタンス数 1 以上: インスタンス数を 0 に設定すると Worker Pool は起動しません(無効化扱い)
- アイドル課金: 起動中のインスタンスはアイドル状態でも課金される点に注意が必要です
まとめ
今回は、2026年4月14日にGAされたCloud Run Worker Poolsについて紹介しました。
Cloud Run Worker Pools の GA により、Kafka コンシューマや Pub/Sub プル処理など、常時稼働するバックグラウンドワークロードを Cloud Run のフルマネージド環境で本番運用できるようになりました。
特に注目すべきポイントは以下の 3 点です。
- URL を持たないアーキテクチャにより、パブリックエンドポイントなしでバックグラウンド処理を実行でき、ネットワーク構成のセキュリティを高められる
- インスタンス数ベースのスケーリングにより、プル型ワークロードに最適なスケーリング制御ができ、独自のオートスケーラーとも容易に連携できる
- Cloud Run エコシステムとの統合により、Artifact Registry・Cloud Logging・Cloud Monitoring・Direct VPC といった既存サービスをそのまま活用できる
HTTP リクエストを必要としない常時稼働ワークロードを Cloud Run で実行したい方は、ぜひ Worker Pools の本番利用を検討してみてはいかがでしょうか。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!










