
【初心者】研修の復習のため、AIにPythonの練習問題を作らせて解いてみた~機械学習・分類編~
はじめに
こんにちは。クラスメソッドオペレーションズの藤瀨です。
前々回はデータ分析、前回は機械学習の回帰をテーマに、AIに問題を作ってもらい、実際に解いてみました。
今回のブログはこのシリーズラスト、機械学習の分類を扱った内容になります。
これまでと同じように、Claudeに作ってもらった問題を解いてみて、つまずきポイントや解説を初学者目線でまとめています。
引き続き、このブログを練習問題としても活用していただけるとうれしいです。
前々回のブログにAIに問題を作成させるプロンプトも掲載しているので、あわせて参考にしてみてください!
問題
本記事のコードを実行するには、以下のライブラリが必要です。インストールしていない方は、ターミナルで以下を実行してください。また、私はWindows OS環境で実行しています。
pip install pandas numpy matplotlib seaborn scikit-learn
前回までと同様に、各問題の下にヒントが隠れています。実際に解いてみようという方で、ヒントを参照したい場合は左側のトグルをクリックして展開してください。
共通データセット
各問題では、seabornに組み込みで入っている「タイタニックデータセット」を使用します。まずはこのコードを実行してデータを準備してください。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import (accuracy_score, confusion_matrix,
precision_score, recall_score, f1_score,
roc_curve, roc_auc_score)
# 日本語フォントの設定(文字化け対策)
import matplotlib
matplotlib.rcParams['font.family'] = 'MS Gothic'
# Macの場合: 'Hiragino Sans' または 'AppleGothic'
# Linuxの場合: 'IPAexGothic'
df = sns.load_dataset('titanic')
データの概要は以下の通りです。
| 列名 | 内容 | 種類 |
|---|---|---|
| survived | 生存したか(0=死亡 / 1=生存)← 予測ターゲット | 数値 |
| pclass | チケットのクラス(1=一等 / 2=二等 / 3=三等) | 数値 |
| sex | 性別(male / female) | カテゴリ |
| age | 年齢 | 数値(欠損あり) |
| sibsp | 同乗している兄弟・配偶者の人数 | 数値 |
| parch | 同乗している親・子供の人数 | 数値 |
| fare | 運賃 | 数値 |
| embarked | 乗船港(C=シェルブール / Q=クイーンズタウン / S=サウサンプトン) | カテゴリ(欠損あり) |
難易度⭐
問題1:データの確認 テーマ:データを把握する
読み込んだ df を使って、以下の情報を確認してください。
- データの行数・列数を確認してください。
- 各列のデータ型を確認してください。
- 数値列の基本統計量(平均・最大・最小など)を表示してください。
- 欠損値の件数を列ごとに確認してください。
- ターゲット変数
survivedの値ごとの件数を確認し、生存率も計算してください。
ヒント
| やること | 使うもの |
|---|---|
| 行数・列数を確認 | df.shape |
| 各列のデータ型 | df.dtypes |
| 数値列の基本統計量 | df.describe() |
| 欠損値の数 | df.isnull().sum() |
| 列の値ごとの件数 | df['survived'].value_counts() |
| 生存率の計算 | df['survived'].mean() |
💡
df.dtypesはプロパティなので括弧不要です。df.shapeやdf.columnsなども同様です。
💡df.describe()のcount(件数)が全体件数より少ない列は欠損があるサインです。
💡df.isnull()だけだとTrue/Falseが全行返ってくるので、.sum()をつけて列ごとの件数に変換します。
💡survivedは0か1しかないため、mean()で「1の平均=1の割合=生存率」が直接計算できます。
難易度⭐⭐
問題2:データの前処理 テーマ:欠損値を補完し、カテゴリ変数をモデルに渡せる形に変換する
多くの機械学習モデルは、欠損値や文字列データをそのまま扱えないため、前処理によって補完や数値化を行う必要があります。
- 使用する列を
['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']に絞り込み、新しいDataFramedf_modelを作ってください。 age列の欠損値をageの中央値で補完してください。embarked列の欠損値がある行を削除してください。sexとembarked列をダミー変数に変換してください。(drop_first=Trueを使うこと)- 変換後のDataFrameから、特徴量
X(全列)とターゲットy(survived 列)を作ってください。ただしyは元のdfから取得すること。 train_test_splitを使って、Xとyを学習用(80%)とテスト用(20%)に分割してください。(random_state=42)
ヒント
| やること | 使うもの |
|---|---|
| 列を絞り込む | df[['pclass', 'sex', ...]].copy() |
| 中央値で欠損補完 | df_model['age'] = df_model['age'].fillna(df_model['age'].median()) |
| 特定列の欠損行を削除 | df_model.dropna(subset=['embarked']) |
| カテゴリをダミー変数に変換 | pd.get_dummies(df_model, columns=['sex', 'embarked'], drop_first=True) |
| インデックスを合わせてy取得 | df.loc[df_model.index, 'survived'] |
| データを分割する | train_test_split(X, y, test_size=0.2, random_state=42) |
💡
.copy()をつけることで元のdfと切り離した独立コピーになり、後で値を書き換えても警告が出ません。
💡fillna()は変換結果を返すだけで元のデータは変えません。必ず左辺に代入してください。
💡dropna()はsubset=を省略すると全列の欠損行が対象になります。削除する列を限定したいときはsubset=['embarked']のように指定します。
💡df.loc[df_model.index, 'survived']は「dfの中からdf_modelに残っている行番号の行だけを取り出す」という意味です。embarkedの欠損行を削除した後はdf_modelのインデックスが飛ぶため、df['survived']をそのまま使うとXと行数が合わなくなります。
問題3:ロジスティック回帰(単一特徴量) テーマ:1つの特徴量で生存を予測する
まずはシンプルに、fare(運賃)だけを使って生存を予測してみましょう。
fareだけを特徴量としてX_simpleを作り、ターゲットyとともに学習用(80%)・テスト用(20%)に分割してください。(random_state=42)LogisticRegressionを使ってモデルを学習させてください。- テストデータに対して予測を行い、正解率(accuracy)を表示してください。
- テストデータに対して各サンプルの生存確率(クラス1の確率)を取得してください。
- 運賃(fare)と生存確率の関係を散布図で可視化してください。
ヒント
| やること | 使うもの |
|---|---|
| 1列をDataFrame形式で取り出す | df[['fare']](二重ブラケット) |
| モデルの学習 | model.fit(X_train, y_train) |
| 予測ラベル | model.predict(X_test) |
| 正解率 | accuracy_score(y_test, y_pred) |
| 生存確率を取得 | model.predict_proba(X_test)[:, 1] |
💡 収束しない旨の警告が出た場合は
LogisticRegression(max_iter=1000)と指定してください。
💡predict_proba()は[死亡確率, 生存確率]の2列で返ってきます。生存確率(クラス1)だけを取り出すには[:, 1]でスライスします。
問題4:モデルの評価 テーマ:分類モデルの評価指標を理解する
問題3で作ったモデルを詳しく評価してみましょう。
- テストデータに対して、以下の指標を計算して表示してください。
- 正解率(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- F1スコア
- 混同行列(Confusion Matrix)を作成し、ヒートマップで可視化してください。
- Accuracy・Precision・Recall・F1・AUCそれぞれの意味をコメントで説明してください。
ヒント
| やること | 使うもの |
|---|---|
| 正解率 | accuracy_score(y_test, y_pred) |
| 適合率 | precision_score(y_test, y_pred) |
| 再現率 | recall_score(y_test, y_pred) |
| F1スコア | f1_score(y_test, y_pred) |
| 混同行列 | confusion_matrix(y_test, y_pred) |
| ヒートマップ | sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') |
💡 混同行列は予測結果を「実際のクラス × 予測クラス」の2×2の表にまとめたものです。左上・右下が正解予測、左下・右上が誤予測です。
問題5:複数特徴量のロジスティック回帰 テーマ:複数の特徴量を使って精度を上げる
問題2で前処理したデータ(全特徴量)を使ってロジスティック回帰モデルを構築し、単一特徴量モデルと比較してみましょう。
- 問題2で作った
X_train・X_test・y_train・y_testを使って、ロジスティック回帰モデルを学習させてください。 - テストデータに対してAccuracy・F1スコアを計算してください。
- 単一特徴量モデル(問題3・4)と複数特徴量モデルの精度を比較して、どちらが良いか確認してください。
- 各特徴量の係数を取り出し、影響が大きい上位10特徴量を棒グラフで表示してください。
ヒント
| やること | 使うもの |
|---|---|
| 係数を列名つきで取り出す | pd.Series(model.coef_[0], index=X_train.columns) |
| 絶対値が大きい上位N件 | .abs().nlargest(N) |
💡 ロジスティック回帰の
model.coef_は(クラス数, 特徴量数)の形状の2次元配列です。2値分類ではmodel.coef_[0](1行目)を使います。回帰のmodel.coef_とは形が異なるので注意してください。
難易度⭐⭐⭐
問題6:決定木と交差検証 テーマ:別のアルゴリズムと比較し、モデルをより頑健に評価する
DecisionTreeClassifier(max_depth=5,random_state=42)を使って、問題2と同じデータでモデルを学習させ、Accuracyを確認してください。- ロジスティック回帰と決定木の Accuracy・F1スコアを並べて比較してください。
cross_val_scoreを使って、ロジスティック回帰モデルに5分割交差検証を適用し、各分割のAccuracyと平均Accuracyを表示してください。- 決定木の特徴量重要度(
feature_importances_)を取り出し、棒グラフで可視化してください。
ヒント
| やること | 使うもの |
|---|---|
| 決定木 | DecisionTreeClassifier(max_depth=5, random_state=42) |
| 交差検証 | cross_val_score(model, X, y, cv=5, scoring='accuracy') |
| 特徴量重要度 | model.feature_importances_ |
💡
cross_val_scoreのcvとscoringはキーワード引数で指定する必要があります。またscoringには文字列'accuracy'を渡します(関数オブジェクトではありません)。
💡cross_val_scoreにはX_trainではなく**全データ(X・y)**を渡します。内部で自動的に分割してくれます。
解説とつまずきポイント
問題ごとの解答例と解説、それから私が解いたときにミスしたりエラーになったりした点があれば合わせて記載します。
問題1
解答
# 1. 行数・列数
print(df.shape)
# → (891, 15)
# 2. データ型
print(df.dtypes)
# 3. 基本統計量
print(df.describe())
# 4. 欠損値の確認
print(df.isnull().sum())
# → age: 177件、deck: 688件 など
# 5. 生存者数と生存率
print(df['survived'].value_counts())
print(f'生存率: {df["survived"].mean():.1%}')
# → 生存率: 38.4%
解説
設問1 df.shape は (行数, 列数) のタプルを返します。891件のデータがあります。
設問2 df.dtypes で各列のデータ型を確認できます。sex・embarked などが object(文字列)型になっており、このままモデルには渡せないことがわかります。
設問3 df.describe() は数値列の基本統計量をまとめて表示します。age の件数が714と全891件より少ないことから欠損があることが読み取れます。
設問4 df.isnull().sum() で列ごとの欠損値を確認します。age が177件(約20%)・deck が688件(約77%)と多く欠損しています。deck は欠損が多すぎるため今回は使用しません。
設問5 value_counts() で死亡(0)が549件・生存(1)が342件と確認できます。mean() で生存率38.4%が計算できます。survived 列は0と1しかないため、平均の計算式「合計 ÷ 件数」に当てはめると「生存者数 ÷ 全体数 = 生存率」になります。0/1フラグ列の割合を求めるときは mean() が使えると覚えておくと便利です。
問題2
解答
# 1. 使用する列に絞り込む
df_model = df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']].copy()
# 2. age の欠損値を中央値で補完
df_model['age'] = df_model['age'].fillna(df_model['age'].median())
# 3. embarked の欠損行を削除(2行のみ)
df_model = df_model.dropna(subset=['embarked'])
# 4. カテゴリ変数をダミー変数に変換
df_encoded = pd.get_dummies(df_model, columns=['sex', 'embarked'], drop_first=True)
print(df_encoded.shape)
# → (889, 8)
# 5. 特徴量 X とターゲット y に分ける
X = df_encoded
y = df.loc[df_model.index, 'survived']
# 6. 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f'学習データ: {X_train.shape}')
print(f'テストデータ: {X_test.shape}')
解説
設問1 .copy() をつける理由は「SettingWithCopyWarning」を防ぐためです。df[...] で作ったDataFrameは元の df のビュー(参照)になっている場合があり、その後で値を書き換えようとすると警告が出ます。.copy() をつけることで独立したコピーになります。
設問2 fillna() は結果を返すだけで元のデータは変更しません。必ず df_model['age'] = のように代入してください。中央値を使う理由は、外れ値(極端に高い年齢など)の影響を受けにくいためです。
設問3 dropna(subset=['embarked']) で embarked が欠損している行だけを削除します。dropna() だけにすると全列の欠損をチェックして削除してしまうので、subset= で列を指定するのが大切です。
設問4 sex が sex_male(1=男性、0=女性)に変換されます。embarked は embarked_Q・embarked_S の2列になります(Cが基準として削除)。
設問5 embarked の欠損行を削除したため df_model のインデックスに飛びが生じます。df['survived'] そのままでは df_model と行数が合わないため、df.loc[df_model.index, 'survived'] でインデックスを合わせて取得します。
問題3
解答
# 1. fare だけを使って分割
X_simple = df[['fare']]
y_simple = df['survived']
X_train_s, X_test_s, y_train_s, y_test_s = train_test_split(
X_simple, y_simple, test_size=0.2, random_state=42
)
# 2. モデルの学習
model_simple = LogisticRegression(max_iter=1000)
model_simple.fit(X_train_s, y_train_s)
# 3. 予測と正解率
y_pred_s = model_simple.predict(X_test_s)
print(f'正解率(Accuracy): {accuracy_score(y_test_s, y_pred_s):.4f}')
# 4. 生存確率
y_prob_s = model_simple.predict_proba(X_test_s)[:, 1]
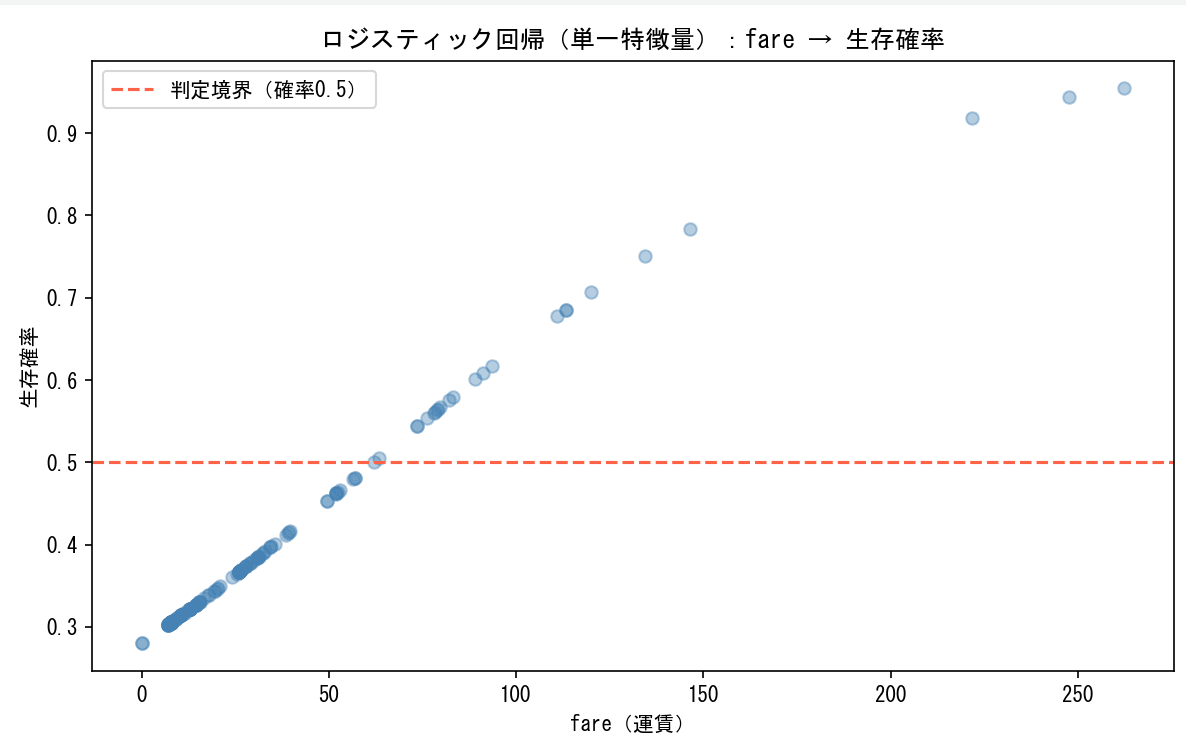
# 5. fare と生存確率の散布図
plt.figure(figsize=(8, 5))
plt.scatter(X_test_s['fare'], y_prob_s, alpha=0.4, color='steelblue')
plt.xlabel('fare(運賃)')
plt.ylabel('生存確率')
plt.title('ロジスティック回帰(単一特徴量):fare → 生存確率')
plt.tight_layout()
plt.show()
解説
設問1 df[['fare']](二重ブラケット)でDataFrame形式(2次元)にします。一重ブラケット df['fare'] だとSeries(1次元)になってしまいますが、scikit-learnは特徴量Xに行列(2次元)を期待しているためエラーになります。列が1つだけでも二重ブラケットが必要です。なお、ターゲット y は逆に1次元(Series)のまま渡すのが正しいです。X は2次元・y は1次元がscikit-learnのルールです。
設問2 LogisticRegression(max_iter=1000) で学習します。max_iter はモデルが収束するまでの最大反復回数で、デフォルト(100)だと収束しない警告が出ることがあります。
設問3 predict() は各サンプルを「生存(1)」か「死亡(0)」に分類します。accuracy_score() でその正解率を計算します。fare だけではAccuracyが63〜65%程度にとどまり、運賃だけでは予測に限界があることがわかります。
設問4 predict_proba() は各乗客について「死亡確率・生存確率」を2列で返します。
[[0.67, 0.33], # 乗客A:死亡67%、生存33%
[0.71, 0.29], # 乗客B:死亡71%、生存29%
[0.45, 0.55], # 乗客C:死亡45%、生存55%
...]
[:, 1] で「全行の2列目(生存確率)だけ」を取り出すことで、1次元の配列になります。
設問5 散布図で確認すると、運賃が高くなるほど生存確率が上がる傾向が見えますが、高運賃帯でもばらつきがあります。
プラスα:散布図に判定境界線を引く
plt.axhline() を使うと、グラフ上の指定したy座標に水平線を引けます。ロジスティック回帰は確率が0.5以上なら生存・未満なら死亡と判定するので、その境界を破線で示すと「線より上が生存予測、下が死亡予測」と視覚的にわかりやすくなります。
plt.axhline(0.5, color='tomato', linestyle='--', label='判定境界(確率0.5)')
plt.legend()
問題4
解答
# 1. 各評価指標
# Accuracy:全予測のうち正解した割合
acc = accuracy_score(y_test_s, y_pred_s)
# Precision:「生存」と予測したうち実際に生存していた割合(予測の正確さ)
prec = precision_score(y_test_s, y_pred_s)
# Recall:実際の生存者のうち「生存」と予測できた割合(見つける力)
rec = recall_score(y_test_s, y_pred_s)
# F1:PrecisionとRecallの調和平均(両方のバランスを見る指標)
f1 = f1_score(y_test_s, y_pred_s)
print(f'Accuracy : {acc:.4f}')
print(f'Precision: {prec:.4f}')
print(f'Recall : {rec:.4f}')
print(f'F1 Score : {f1:.4f}')
# 2. 混同行列のヒートマップ
cm = confusion_matrix(y_test_s, y_pred_s)
plt.figure(figsize=(5, 4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['予測:死亡', '予測:生存'],
yticklabels=['実際:死亡', '実際:生存'])
plt.title('混同行列(単一特徴量モデル)')
plt.tight_layout()
plt.show()
解説
回帰編では「MSE・RMSE・R²」の3指標でしたが、分類ではより多くの指標が登場します。それぞれの意味を整理します。
まず前提として、混同行列(Confusion Matrix) とは予測結果を「実際のクラス×予測クラス」の表にまとめたものです。
| 予測:死亡 | 予測:生存 | |
|---|---|---|
| 実際:死亡 | 正しく死亡と予測 | 死亡を生存と誤予測 |
| 実際:生存 | 生存を死亡と誤予測 | 正しく生存と予測 |
この4マスを使って以下の各指標が計算されます。
Accuracy(正解率):全予測のうち正解した割合
わかりやすい指標ですが、タイタニックのように死亡(62%)・生存(38%)と不均衡なデータでは「全員死亡と予測する」だけでAccuracy 62%が出てしまいます。Accuracyだけで判断すると実態を見誤るケースがあります。
Precision(適合率):生存と予測したもののうち、実際に生存していた割合
「誤検知(死亡なのに生存と予測)」を減らしたいときに重視します。
Recall(再現率):実際の生存者のうち、モデルが生存と予測できた割合
「見落とし(生存なのに死亡と予測)」を減らしたいときに重視します。医療診断などでは見落としのコストが大きいため Recall が重視されます。
F1スコア:PrecisionとRecallの調和平均
PrecisionとRecallの両方のバランスを1つの数値で見られます。不均衡データでの評価に適しています。
問題5
解答
# 1. 複数特徴量のロジスティック回帰
model_multi = LogisticRegression(max_iter=1000)
model_multi.fit(X_train, y_train)
# 2. テストデータで評価
y_pred_m = model_multi.predict(X_test)
acc_multi = accuracy_score(y_test, y_pred_m)
f1_multi = f1_score(y_test, y_pred_m)
print(f'複数特徴量 Accuracy: {acc_multi:.4f}')
print(f'複数特徴量 F1 Score: {f1_multi:.4f}')
# 3. 単一 vs 複数の比較
print('\n--- モデル比較 ---')
print(f'単一特徴量(fare) Accuracy: {acc:.4f} F1: {f1:.4f}')
print(f'複数特徴量 Accuracy: {acc_multi:.4f} F1: {f1_multi:.4f}')
# → 複数特徴量の方が Accuracy・F1 ともに高くなるはず
# 4. 特徴量の係数(上位10件)
coef_series = pd.Series(model_multi.coef_[0], index=X_train.columns)
top10 = coef_series.abs().nlargest(10)
plt.figure(figsize=(9, 5))
coef_series[top10.index].sort_values().plot(kind='barh', color='steelblue')
plt.axvline(0, color='black', linewidth=0.8)
plt.title('ロジスティック回帰:影響が大きい上位10特徴量の係数')
plt.xlabel('係数の値(正→生存方向、負→死亡方向)')
plt.tight_layout()
plt.show()
解説
設問1・2 手順は問題3の単一特徴量と全く同じで、使う特徴量が1列から8列に増えただけです。
設問3 結果の例はこうなります。
--- モデル比較 ---
単一特徴量(fare) Accuracy: 0.6425 F1: 0.5349
複数特徴量 Accuracy: 0.8034 F1: 0.7317
Accuracyが64%から80%、F1が0.53から0.73と大幅に改善しました。複数の特徴量を組み合わせることの効果がはっきり出ています。
設問4 model.coef_[0] で係数を取り出します。係数が正の特徴量は生存方向、負の特徴量は死亡方向に影響することを意味します。グラフを見ると sex_male(男性フラグ)の係数が大きく負になっており、性別が生存予測に強く影響していることが読み取れます。
問題6
解答
# 1. 決定木モデル
model_tree = DecisionTreeClassifier(max_depth=5, random_state=42)
model_tree.fit(X_train, y_train)
y_pred_tree = model_tree.predict(X_test)
acc_tree = accuracy_score(y_test, y_pred_tree)
f1_tree = f1_score(y_test, y_pred_tree)
print(f'決定木 Accuracy: {acc_tree:.4f}')
print(f'決定木 F1 Score: {f1_tree:.4f}')
# 2. 2モデルの比較
print('\n--- アルゴリズム比較 ---')
print(f'ロジスティック回帰 Accuracy: {acc_multi:.4f} F1: {f1_multi:.4f}')
print(f'決定木 Accuracy: {acc_tree:.4f} F1: {f1_tree:.4f}')
# 3. 5分割交差検証(ロジスティック回帰)
scores = cross_val_score(LogisticRegression(max_iter=1000), X, y, cv=5, scoring='accuracy')
print('\n--- 5分割交差検証(ロジスティック回帰)---')
print(f'各分割のAccuracy: {scores.round(4)}')
print(f'平均Accuracy : {scores.mean():.4f}')
# 4. 決定木の特徴量重要度
importance_series = pd.Series(model_tree.feature_importances_, index=X_train.columns)
plt.figure(figsize=(9, 5))
importance_series.sort_values().plot(kind='barh', color='steelblue')
plt.title('決定木:特徴量重要度')
plt.xlabel('重要度')
plt.tight_layout()
plt.show()
解説
設問1・2 決定木はロジスティック回帰とほぼ同程度か、やや高い精度になることが多いです(Accuracy 79〜81%程度)。決定木が高くなりやすい理由は、ロジスティック回帰が「特徴量と生存率の関係が直線的である」という前提に基づくのに対し、決定木は「pclass が1かつ sex が female なら生存」のように条件の組み合わせで非線形な境界を表現できるためです。タイタニックのデータはこうした複合条件が効きやすく、決定木が有利になります。
設問3 5分割交差検証の結果は以下のようになります。
--- 5分割交差検証(ロジスティック回帰)---
各分割のAccuracy: [0.7989 0.8090 0.7865 0.8034 0.7921]
平均Accuracy : 0.7980
各分割で79〜81%と安定しており、特定の分割に偏っていないことが確認できます。
設問4 決定木の特徴量重要度は「その特徴量がノード分割にどれだけ貢献したか」を表しています。グラフでは sex_male・fare・age が上位に来ており、これらが予測に大きく寄与していることが読み取れます。特徴量重要度でモデルの根拠を確認できる点が決定木の利点の一つです。
まとめ
一通り問題を解いてみて、回帰との違いを体感しながら分類の基礎を確認できました。
回帰編との最大の違いは評価指標の多様さだと思います。回帰はRMSEやR²のような「数値の誤差」を測れますが、分類は正解か不正解かの2択なので、Accuracy・Precision・Recall・F1・AUCと複数の角度から評価する必要があります。特に不均衡データではAccuracyだけを見ると実力を誤解してしまうという点が、最初は難しく感じました。
また今回は欠損値の処理が初めて登場しました。実務のデータでは欠損はむしろ当たり前で、どう補完するかがモデルの精度に直結します。今回は中央値補完という基本的な方法を使いましたが、補完方法の選択はデータの性質や目的によって変わるので、引き続き学んでいきたいと思います。
このシリーズを通して、AIに問題を作ってもらって演習を行うことの学習効果を実感することができました。
自分のやりたい内容で即座に問題を生成し、気軽に質問ができるAIは、自己学習において非常に心強いパートナーになると思います。
より良い使い方も模索しながらこれからも活用していきたいです!
最後までお読みいただきありがとうございました!
付録:よく使うメソッド早見表
| 操作 | コード例 |
|---|---|
| データの行数・列数 | df.shape |
| 各列のデータ型 | df.dtypes |
| 基本統計量 | df.describe() |
| 欠損値の数 | df.isnull().sum() |
| 欠損値を中央値で補完 | df['col'] = df['col'].fillna(df['col'].median()) |
| 特定列の欠損行を削除 | df.dropna(subset=['col']) |
| カテゴリ変数のダミー化 | pd.get_dummies(df, columns=[...], drop_first=True) |
| データの分割 | train_test_split(X, y, test_size=0.2, random_state=42) |
| モデルの学習 | model.fit(X_train, y_train) |
| 予測ラベル | model.predict(X_test) |
| 予測確率 | model.predict_proba(X_test)[:, 1] |
| 正解率 | accuracy_score(y_test, y_pred) |
| F1スコア | f1_score(y_test, y_pred) |
| AUC | roc_auc_score(y_test, y_prob) |
| 交差検証 | cross_val_score(model, X, y, cv=5, scoring='accuracy') |
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイトをぜひご覧ください。
※2026年1月 アノテーション㈱から社名変更しました。










