
【初心者】研修の復習のため、AIにPythonの練習問題を作らせて解いてみた~機械学習・回帰編~
はじめに
こんにちは。クラスメソッドオペレーションズの藤瀨です。
前回のブログでは、研修で学んだPythonのデータ分析を復習するため、AIに問題を作ってもらって解いてみました。
今回はそれに引き続き、機械学習の内容を復習するために同じようにClaudeで問題を作って一通り解きました。
前回と同様、私と同じ初心者の方向けにその問題を示し、初心者目線で解説とつまずいたポイントをまとめています。
機械学習を学んだばかりの方は、ぜひこのブログを活用してみてください!
また、前回のブログにAIに練習問題を作ってもらうプロンプトも掲載しているので、よろしければそちらも参照してください。
問題
本記事のコードを実行するには、以下のライブラリが必要です。インストールしていない方は、ターミナルで以下を実行してください。また、私はWindows OS環境で実行しています。
pip install pandas numpy matplotlib seaborn scikit-learn
各問題の下にヒントが隠れています。実際に解いてみようという方で、ヒントを参照したい場合は左側のトグルをクリックして展開してください。
共通データセット
今回の問題のデータセットにはseabornに組み込みの「ダイヤモンドデータセット」を使用しました。
カラット・カット・色・透明度といった特徴量から価格を予測するというテーマで、数値だけでなくカテゴリ変数も混ざっているためワンホットエンコーディングの練習(問題2設問1)もセットでできるのがポイントです。
まずはこのコードを実行してデータを準備してください。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import mean_squared_error, r2_score
# 日本語フォントの設定(文字化け対策)
import matplotlib
matplotlib.rcParams['font.family'] = 'MS Gothic'
# Macの場合: 'Hiragino Sans' または 'AppleGothic'
# Linuxの場合: 'IPAexGothic'
df = sns.load_dataset('diamonds')
データの概要は以下の通りです。
予測ターゲットは price で、まずは単回帰から始めて重回帰に移っていきます。
| 列名 | 内容 | 種類 |
|---|---|---|
| carat | ダイヤモンドの重さ(カラット) | 数値 |
| cut | カットの品質(Fair〜Ideal) | カテゴリ |
| color | 色(J=最低〜D=最高) | カテゴリ |
| clarity | 透明度(I1=最低〜IF=最高) | カテゴリ |
| depth / table | 形状に関わる比率 | 数値 |
| x / y / z | サイズ(mm) | 数値 |
| price | 価格(ドル)← 予測ターゲット | 数値 |
難易度⭐
問題1:データの確認 テーマ:データを把握する
読み込んだ df を使って、以下の情報を確認してください。
- データの行数・列数を確認してください。
- 各列のデータ型を確認してください。
- 数値列の基本統計量(平均・最大・最小など)を表示してください。
- 欠損値が含まれているか確認してください。
cut・color・clarity列それぞれに何種類の値があるか確認し、各値の件数も表示してください。
ヒント
| やること | 使うもの |
|---|---|
| 行数・列数を確認 | df.shape |
| 各列のデータ型 | df.dtypes |
| 数値列の基本統計量 | df.describe() |
| 欠損値の数 | df.isnull().sum() |
| 列の値ごとの件数 | df['列名'].value_counts() |
難易度⭐⭐
問題2:データの前処理 テーマ:カテゴリ変数をモデルに渡せる形に変換する
機械学習モデルは文字列データをそのまま扱えません。cut・color・clarity 列をダミー変数に変換し、モデルに入力できる形に整えてください。
pd.get_dummies()を使って、cut・color・clarityをダミー変数に変換してください。(ダミー変数トラップを避けるため、drop_first=Trueを使うこと)- 変換後のDataFrameの列数を確認してください(元は10列でした → 正解は24列)。
- 変換後のDataFrameから、特徴量
X(price以外の全列)とターゲットy(price列)を分けてください。 train_test_splitを使って、Xとyを学習用(80%)とテスト用(20%)に分割してください。(random_state=42を使って結果を固定すること)
ヒント
| やること | 使うもの |
|---|---|
| カテゴリをダミー変数に変換 | pd.get_dummies(df, columns=['列名'], drop_first=True) |
| 列を削除して特徴量を作る | df_encoded.drop('price', axis=1) |
| データを分割する | train_test_split(X, y, test_size=0.2, random_state=42) |
💡
pd.get_dummies()は変換した結果を返すだけで、元のdfは変更しません。必ず新しい変数に代入してください。
💡 ダミー変数トラップとは?
カテゴリ変数をダミー化したとき、全カテゴリ分の列を作ると「他の列の値が決まれば自動的に決まる列」が生まれてしまいます。
例えばcutに Fair・Good・Ideal の3種類があるとき、3列全て作ると「Fair列もGood列も0なら必ずIdeal」となり1列が冗長になります。
この冗長な列がモデルの計算に悪影響を与えることをダミー変数トラップと呼びます。drop_first=Trueで1列削除することで防げます。
問題3:単回帰モデルの構築 テーマ:1つの特徴量でpriceを予測する
まずはシンプルに、carat(重さ)だけを使って price を予測してみましょう。
caratだけを特徴量としてX_simpleを作り、y(price)とともに学習用(80%)・テスト用(20%)に分割してください(random_state=42)。LinearRegressionを使ってモデルを学習させてください。- テストデータに対して予測を行ってください。
- 学習済みモデルの「切片」と「係数」を表示してください。
- 散布図(
caratvsprice)の上に、モデルの予測直線を重ねて表示してください。
ヒント
| やること | 使うもの |
|---|---|
| 1列をDataFrame形式で取り出す | df[['carat']](二重ブラケット) |
| モデルの学習 | model.fit(X_train, y_train) |
| 予測 | model.predict(X_test) |
| 切片・係数 | model.intercept_ / model.coef_ |
💡
df['carat'](シングルブラケット)はSeries(1次元)になります。scikit-learnは特徴量Xに2次元のデータを期待しているので、df[['carat']](二重ブラケット)でDataFrame形式にする必要があります。
ターゲットyは逆に1次元(Series)のまま渡すのが正しいです。X は2次元・y は1次元がscikit-learnのルールです。
問題4:モデルの評価 テーマ:予測の精度を数値で評価する
問題3で作った単回帰モデルを評価してみましょう。
- テストデータに対して、以下の指標を計算して表示してください。
- MSE(平均二乗誤差)
- RMSE(平方根平均二乗誤差)
- R²(決定係数)
- 予測値と実際の値を比較した散布図を作成してください。(x軸:実際のprice、y軸:予測price 対角線(y=x)も引くこと)
- MSE・RMSE・R²の意味をそれぞれコメントで説明してください。
ヒント
| やること | 使うもの |
|---|---|
| MSEの計算 | mean_squared_error(y_test, y_pred) |
| RMSEの計算 | np.sqrt(mean_squared_error(y_test, y_pred)) |
| R²の計算 | r2_score(y_test, y_pred) |
| 対角線を引く | plt.plot([min, max], [min, max]) |
💡 散布図のx軸には
y_test_s(テストデータの正解値)を使います。y_simple(全データ)を渡すとサイズ不一致エラーになります。
難易度⭐⭐⭐
問題5:重回帰モデルの構築と比較 テーマ:複数の特徴量を使って精度を上げる
問題2で前処理したデータ(全特徴量)を使って重回帰モデルを構築し、単回帰と比較してみましょう。
- 問題2で作った
X_train・X_test・y_train・y_testを使って、重回帰モデルを学習させてください。 - テストデータに対して RMSE と R² を計算してください。
- 単回帰モデル(問題3・4)と重回帰モデルの精度を比較して、どちらが良いか確認してください。
- 重回帰モデルの各特徴量の係数を取り出し、影響が大きい上位10特徴量を棒グラフで表示してください。
ヒント
| やること | 使うもの |
|---|---|
| 係数を列名つきで取り出す | pd.Series(model.coef_, index=X_train.columns) |
| 絶対値が大きい上位N件 | .abs().nlargest(N) |
問題6:正則化と交差検証 テーマ:過学習を防いでモデルをより頑健にする
- Ridge回帰(
alpha=1.0)を使って重回帰と同じデータでモデルを学習させ、R²を確認してください。 - Lasso回帰(
alpha=1.0)でも同様に学習・評価してください。 - 重回帰・Ridge・Lassoの3つのR²を並べて比較してください。
cross_val_scoreを使って、重回帰モデルに 5分割交差検証 を適用し、各分割のR²と平均R²を表示してください。
ヒント
| やること | 使うもの |
|---|---|
| Ridge回帰 | Ridge(alpha=1.0) |
| Lasso回帰 | Lasso(alpha=1.0) |
| 交差検証 | cross_val_score(model, X, y, cv=5, scoring='r2') |
💡 Ridge・Lasso回帰とは?
どちらも係数が大きくなりすぎないようにするペナルティを加えて過学習を防ぐ手法です。
Ridgeは全ての係数を小さく抑えるのに対し、Lassoは重要でない特徴量の係数を0にする性質があり、特徴量の選択も兼ねられます。
alphaが大きいほど制約が強くなります。
💡cross_val_scoreにはX_trainではなく全データ(X,y)を渡します。内部で自動的に分割してくれます。
解説とつまずきポイント
問題ごとの解答例と解説、それから私が解いたときにミスしたりエラーになったりした点があれば合わせて記載します。
問題1
解答
# 1. 行数・列数
print(df.shape)
# → (53940, 10)
# 2. データ型
print(df.dtypes)
# 3. 基本統計量
print(df.describe())
# 4. 欠損値の確認
print(df.isnull().sum())
# → 全列 0:欠損値なし
# 5. カテゴリ列の種類と件数
for col in ['cut', 'color', 'clarity']:
print(f'\n【{col}】')
print(df[col].value_counts())
解説
設問1 df.shape は (行数, 列数) のタプルを返します。53,940件という大きなデータセットです。
設問2 df.dtypes で各列のデータ型を確認できます。cut・color・clarity は category 型になっており、機械学習モデルにそのまま渡せないことがわかります。
設問3 df.describe() は数値列の基本統計量(平均・標準偏差・最大・最小など)をまとめて表示します。price の最小値が326ドル、最大値が18,823ドルと幅広いことが確認できます。
設問4 df.isnull().sum() で列ごとの欠損値の件数を確認できます。すべての列が0であり、このデータには欠損値がなく、非常に綺麗な状態だとわかります。実務のデータでは欠損値があることがほとんどなので、まず確認する習慣をつけましょう。
設問5 value_counts() で各カテゴリの件数が多い順に表示されます。cut はIdealが最多、color はGが最多といった傾向が確認できます。
プラスα:describe() の表示が省略される
列数が多いと describe() の結果が ... で省略されてしまいます。全列を表示したい場合は事前に以下を設定します。
pd.set_option('display.max_columns', None)
print(df.describe())
None を指定することで列数の上限がなくなり、全列が表示されます。
問題2
解答
# 1. ダミー変数に変換
df_encoded = pd.get_dummies(df, columns=['cut', 'color', 'clarity'], drop_first=True)
# 2. 変換後の列数を確認
print(df_encoded.shape)
# → (53940, 24) 10列 → 24列に増えた
# 3. 特徴量 X とターゲット y に分ける
X = df_encoded.drop('price', axis=1)
y = df_encoded['price']
# 4. 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f'学習データ: {X_train.shape}')
print(f'テストデータ: {X_test.shape}')
解説
設問1 pd.get_dummies() でカテゴリ変数をダミー変数化します。drop_first=True を使う理由は「ダミー変数トラップ」を防ぐためです。例えば cut に5種類の値があるとき、5列全てを作ると1列が他の列から計算できてしまい、モデルの計算に悪影響が出ます。1列削除することでこれを防げます。
設問2 変換後の列数は24列になります。内訳は数値列7列(carat・depth・table・price・x・y・z)+ cut の4列+ color の6列+ clarity の7列です。
設問3 drop('price', axis=1) で price 列を除いた全列を特徴量 X とし、price 列だけを取り出してターゲット y とします。
設問4 train_test_split でデータを学習用80%・テスト用20%に分割します。random_state=42 で乱数を固定すると、何度実行しても同じ分割結果が得られます。
問題3
解答
# 1. carat だけを使って分割
X_simple = df[['carat']] # 二重ブラケット(DataFrame形式)が重要
y_simple = df['price']
X_train_s, X_test_s, y_train_s, y_test_s = train_test_split(
X_simple, y_simple, test_size=0.2, random_state=42
)
# 2. モデルの学習
model_simple = LinearRegression()
model_simple.fit(X_train_s, y_train_s)
# 3. 予測
y_pred_s = model_simple.predict(X_test_s)
# 4. 切片と係数
print(f'切片(intercept): {model_simple.intercept_:.2f}')
print(f'係数(coef): {model_simple.coef_[0]:.2f}')
# → price = -2261.91 + 7768.91 × carat
# 5. 散布図+予測直線
plt.figure(figsize=(8, 5))
plt.scatter(X_test_s, y_test_s, alpha=0.3, color='steelblue', label='実際の値')
x_line = np.linspace(X_test_s['carat'].min(), X_test_s['carat'].max(), 100)
y_line = model_simple.predict(x_line.reshape(-1, 1))
plt.plot(x_line, y_line, color='tomato', linewidth=2, label='予測直線')
plt.xlabel('carat(重さ)')
plt.ylabel('price(価格)')
plt.title('単回帰:carat → price')
plt.legend()
plt.tight_layout()
plt.show()
解説
設問1 df[['carat']](二重ブラケット)で carat 列をDataFrame形式(2次元)で取り出します。scikit-learnは特徴量 X に2次元のデータを期待しているためこの書き方が必要です。ターゲット y は逆に1次元(Series)のまま渡します。
設問2 model.fit(X_train, y_train) でモデルに学習(勉強)させます。予測のときは学習に使っていない X_test_s を使うのがポイントで、学習データで評価すると「答えを覚えてテストに臨む」状態になり本当の実力が測れません(過学習)。
設問3 model.predict(X_test) でテストデータに対して予測を行います。返ってくるのはNumPy配列です。
設問4 切片と係数の結果は price = -2261.91 + 7768.91 × carat という直線になります。「caratが1増えるごとに価格が約7,769ドル上がる」という関係が読み取れ、直感的にも納得できる結果です。
設問5 plt.scatter() で散布図を描いた後、np.linspace() で均等な100点を生成して予測直線を重ねます。alpha=0.3 を指定することでデータの密度が視覚的に伝わるようになります。
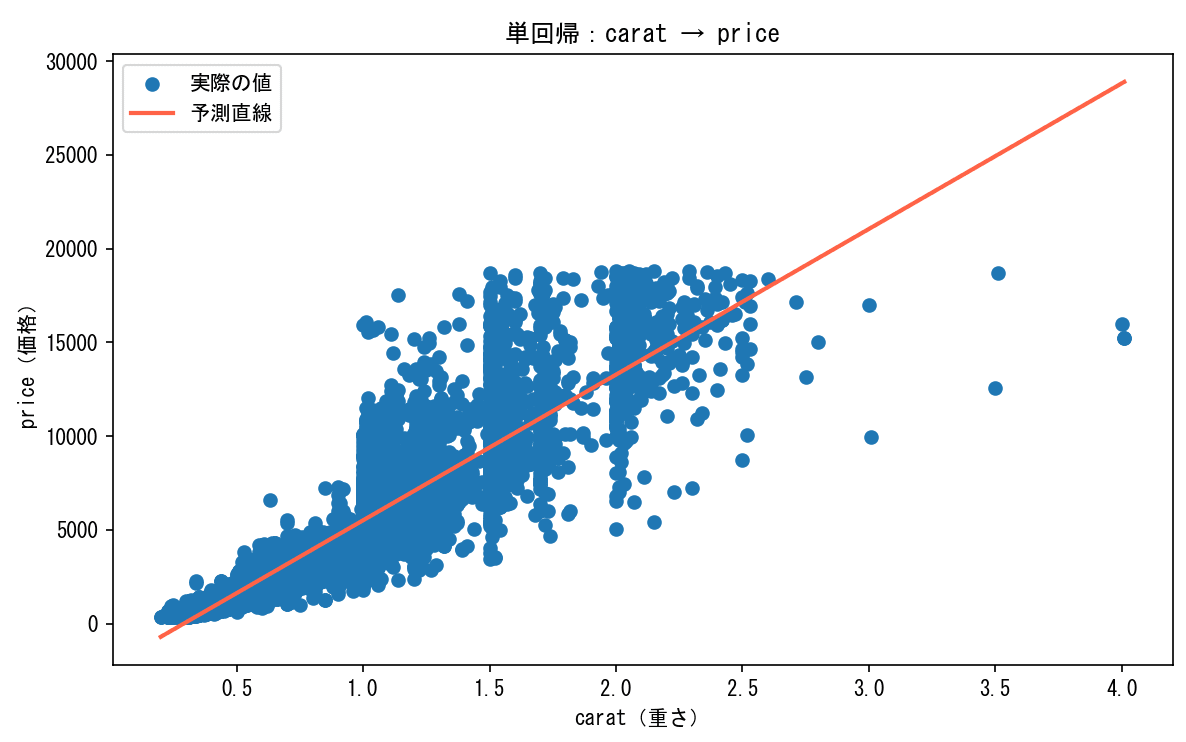
プラスα:散布図に alpha を指定しないと点が潰れて見える
データが5万件以上あるため、alpha なしだと点が重なって全体が真っ青な塊になってしまいます。alpha=0.3 にすることで点が重なっている部分が濃く、少ない部分が薄く表示され、データの密度が視覚的に伝わるようになります。
alpha指定なし
alpha=0.3
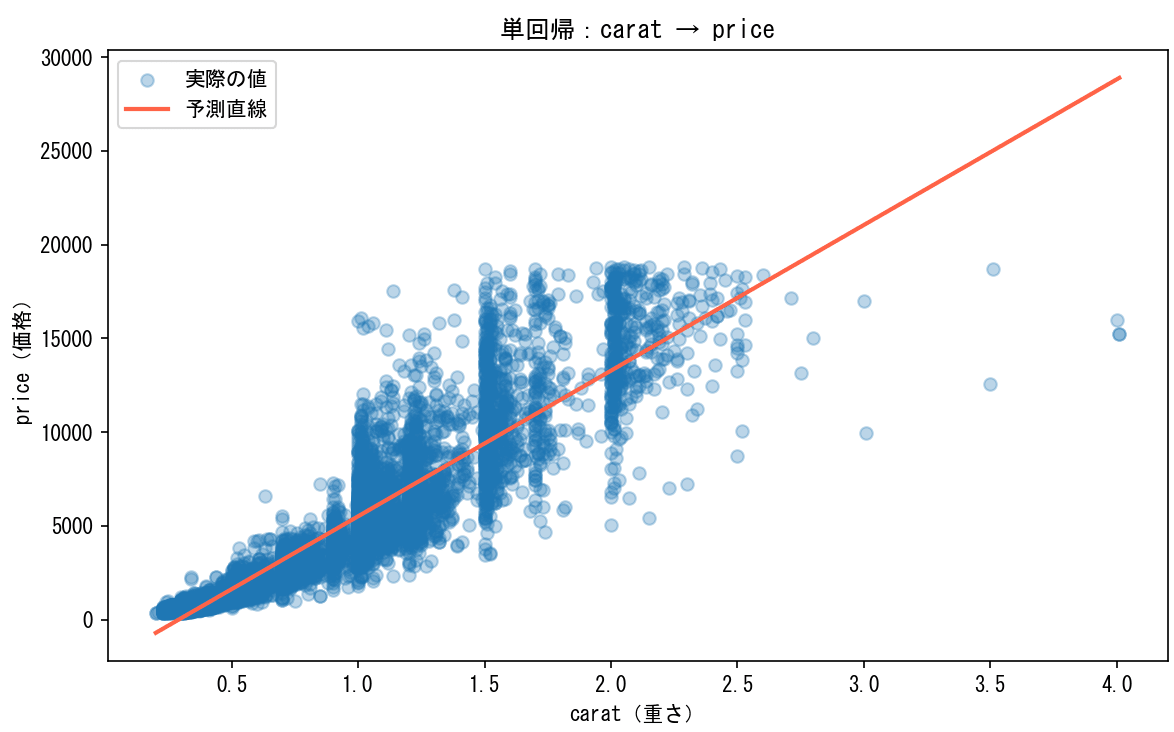
データ件数が多い場合は必ず指定する習慣をつけると良いです。
問題4
解答
# 1. 評価指標
mse = mean_squared_error(y_test_s, y_pred_s)
rmse = np.sqrt(mse)
r2 = r2_score(y_test_s, y_pred_s)
# MSE:誤差の二乗の平均。大きいほど予測が外れている(単位が二乗なので直感的に分かりにくい)
print(f'MSE : {mse:,.2f}')
# RMSE:MSEの平方根。価格と同じ単位(ドル)なので「平均的に〇〇ドル外れた」と読める
print(f'RMSE : {rmse:,.2f}')
# R²:0〜1の範囲で、1に近いほど精度が高い
print(f'R² : {r2:.4f}')
# 2. 予測値 vs 実際の値の散布図
plt.figure(figsize=(7, 6))
plt.scatter(y_test_s, y_pred_s, alpha=0.3, color='steelblue')
min_val = min(y_test_s.min(), y_pred_s.min())
max_val = max(y_test_s.max(), y_pred_s.max())
plt.plot([min_val, max_val], [min_val, max_val], color='tomato', linewidth=2, label='y=x(完璧な予測)')
plt.xlabel('実際のprice')
plt.ylabel('予測price')
plt.title('単回帰モデル:予測 vs 実際')
plt.legend()
plt.tight_layout()
plt.show()
解説
設問1 MSEが3,000万〜4,000万という数値が出てきて最初は「こんなに外れているの?」と焦りましたが、MSEは誤差を二乗した値の平均なので単位が価格(ドル)の二乗になっており、そのままでは直感的に読めません。RMSE(RootMSE)はMSEの平方根で元の単位(ドル)に戻るので「平均的に〇〇ドル外れた」と解釈できます。R²(決定係数) は0〜1の範囲で1に近いほど精度が高いです。
設問2 x軸に実際の価格、y軸に予測価格をプロットします。対角線(y=x)に点が集まるほど予測精度が高いことを意味します。単回帰のR²は0.85前後で、carat だけでもある程度は予測できていますが、高額のダイヤモンドになるほど散布図のばらつきが大きく、他の特徴量の情報も必要だとわかります。
設問3 設問1のコード内のコメントをご参照ください。
問題5
解答
# 1. 重回帰モデルの学習
model_multi = LinearRegression()
model_multi.fit(X_train, y_train)
# 2. テストデータで評価
y_pred_m = model_multi.predict(X_test)
rmse_multi = np.sqrt(mean_squared_error(y_test, y_pred_m))
r2_multi = r2_score(y_test, y_pred_m)
print(f'重回帰 RMSE: {rmse_multi:,.2f}')
print(f'重回帰 R² : {r2_multi:.4f}')
# 3. 単回帰との比較
print('\n--- モデル比較 ---')
print(f'単回帰 RMSE: {rmse:,.2f} R²: {r2:.4f}')
print(f'重回帰 RMSE: {rmse_multi:,.2f} R²: {r2_multi:.4f}')
# 4. 特徴量の係数(上位10件)
coef_series = pd.Series(model_multi.coef_, index=X_train.columns)
top10 = coef_series.abs().nlargest(10)
plt.figure(figsize=(9, 5))
coef_series[top10.index].sort_values().plot(kind='barh', color='steelblue')
plt.axvline(0, color='black', linewidth=0.8)
plt.title('重回帰モデル:影響が大きい上位10特徴量の係数')
plt.xlabel('係数の値')
plt.tight_layout()
plt.show()
解説
設問1・2 問題3の単回帰と全く同じ手順で、学習・予測・評価ができます。使う特徴量が1列から24列に増えただけです。
設問3 結果の例はこうなります。
--- モデル比較 ---
単回帰 RMSE: 6,128.85 R²: 0.8493
重回帰 RMSE: 1,130.12 R²: 0.9804
RMSEが大幅に下がり、R²も0.98まで上がりました。特徴量を増やした効果がはっきり出ています。
設問4 pd.Series(model.coef_, index=X_train.columns) で係数に列名をつけてSeries化します。.abs().nlargest(10) で絶対値が大きい上位10件を取り出し、棒グラフで可視化します。
問題6
解答
# 1. Ridge回帰
model_ridge = Ridge(alpha=1.0)
model_ridge.fit(X_train, y_train)
r2_ridge = r2_score(y_test, model_ridge.predict(X_test))
print(f'Ridge R²: {r2_ridge:.4f}')
# 2. Lasso回帰
model_lasso = Lasso(alpha=1.0)
model_lasso.fit(X_train, y_train)
r2_lasso = r2_score(y_test, model_lasso.predict(X_test))
print(f'Lasso R²: {r2_lasso:.4f}')
# 3. 3モデルの比較
print('\n--- 正則化の比較 ---')
print(f'通常の重回帰 R²: {r2_multi:.4f}')
print(f'Ridge回帰 R²: {r2_ridge:.4f}')
print(f'Lasso回帰 R²: {r2_lasso:.4f}')
# 4. 5分割交差検証
scores = cross_val_score(LinearRegression(), X, y, cv=5, scoring='r2')
print('\n--- 5分割交差検証(重回帰)---')
print(f'各分割のR²: {scores.round(4)}')
print(f'平均R² : {scores.mean():.4f}')
解説
設問1・2 Ridge・Lassoはどちらも通常の重回帰と全く同じ書き方で fit・predict が使えます。alpha はペナルティの強さで、大きいほど係数が小さくなる方向に制約がかかります。
設問3 3モデルのR²を比較します。このデータでは通常の重回帰と大きく変わらない結果になるはずです。これはデータの性質によるもので、今回のダイヤモンドデータセットはサンプル数が約54,000件と非常に多く、モデルが「答えを丸暗記する」、すなわち過学習の状態になりにくいと考えられます。正則化はそもそも過学習を防ぐための手法なので、もとから過学習しにくいデータに対しては効果が薄くなります。
設問4 5分割交差検証では、データを5つのブロックに分けて「4ブロックで学習・1ブロックでテスト」を5回繰り返します。毎回テストデータが変わるためモデルの精度をより信頼性高く評価できます。
まとめ
一通り問題を解いてみて、データ前処理から評価まで一連の流れを手を動かしながら確認できました。
データをモデルに渡す前の準備には、前回のブログで取り上げたデータ分析の知識が必要であることを実感できて、改めて復習にもなったのがよかったです。
機械学習は複雑な式や評価指標が出てきたりして、イメージを掴むのが難しかったのですが、実際に一通りの流れを体感することで、数字が何を意味しているのかを理解することができたと感じます。
なにより、単回帰→重回帰の精度変化がRMSEとR²の数値ではっきり見えるのが面白かったです。
将来ダイヤモンドを購入することがあれば……と言いたいところですが、あくまで練習用モデルなので実際の購入判断にはご注意ください笑
次回はタイタニックの生存者のデータを用いて、機械学習の分類編に取り組む予定です。
最後までお読みいただきありがとうございました!
付録:よく使うメソッド早見表
| 操作 | コード例 |
|---|---|
| データの行数・列数 | df.shape |
| 各列のデータ型 | df.dtypes |
| 基本統計量 | df.describe() |
| 欠損値の数 | df.isnull().sum() |
| カテゴリ変数のダミー化 | pd.get_dummies(df, columns=[...], drop_first=True) |
| データの分割 | train_test_split(X, y, test_size=0.2, random_state=42) |
| モデルの学習 | model.fit(X_train, y_train) |
| 予測 | model.predict(X_test) |
| RMSE | np.sqrt(mean_squared_error(y_test, y_pred)) |
| R² | r2_score(y_test, y_pred) |
| 交差検証 | cross_val_score(model, X, y, cv=5, scoring='r2') |
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイトをぜひご覧ください。
※2026年1月 アノテーション㈱から社名変更しました。










