
AWS Step FunctionsでDynamoDBテーブルからLastEvaluatedKeyによる繰り返し取得をしたアイテムを一つの配列に結合する(AWS CDK v2)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
今回は、AWS Step FunctionsでDynamoDBテーブルからLastEvaluatedKeyによる繰り返し取得をしたアイテムを一つの配列に結合する構成を作ってみました。
なぜLastEvaluatedKey対応をするのか
DynamoDBテーブルへのScanやQueryの実施で取得されるアイテムセットのサイズが1MBを超えた場合は、すべてのアイテムを取得するためにはLastEvaluatedKeyによる繰り返し取得が必要となります。ここで注意点として、この1MBの上限はFilterExpressionやProjectionExpressionのパラメータを使用した場合でもそれらが適用される前の結果に適用されることです。
A single Query operation can retrieve a maximum of 1 MB of data. This limit applies before any FilterExpression or ProjectionExpression is applied to the results. If LastEvaluatedKey is present in the response and is non-null, you must paginate the result set (see Paginating Table Query Results).
よって前述のパラメータを使用して取得するデータサイズを減らしたとて、テーブル上のデータ量が多ければ繰り返し取得は避けられません。
よってStep FunctionsでのDynamoDBテーブルからのアイテム取得は基本的に数度に分けて行われることになるのですが、その際に繰り返し行ったそれぞれの取得結果のアイテムのリストをすべて1つの配列にまとめ、後続の処理で使いたい場合があると思います。
そこで今回はその方法を実現する構成を作ってみました。
やってみた
実装
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_dynamodb,
aws_stepfunctions,
aws_stepfunctions_tasks,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// Scan対象テーブル
const dataTable = new aws_dynamodb.Table(this, 'dataTable', {
tableName: 'dataTable',
partitionKey: {
name: 'id',
type: aws_dynamodb.AttributeType.STRING,
},
billingMode: aws_dynamodb.BillingMode.PAY_PER_REQUEST,
removalPolicy: RemovalPolicy.DESTROY,
});
// 初回Scan
const firstScanTask = new aws_stepfunctions_tasks.CallAwsService(
this,
'firstScanTask',
{
service: 'dynamodb',
action: 'scan',
parameters: {
TableName: dataTable.tableName,
Limit: 2,
},
iamResources: [dataTable.tableArn],
iamAction: 'dynamodb:Scan',
resultPath: '$.scanTaskOutPut',
},
);
// 初回Scanで取得したアイテムのリストをitemsに指定
const pass = new aws_stepfunctions.Pass(this, 'pass', {
parameters: {
items: aws_stepfunctions.JsonPath.stringAt(
'$.scanTaskOutPut.Items[*].id.S',
),
scanTaskOutPut: aws_stepfunctions.JsonPath.stringAt('$.scanTaskOutPut'),
},
});
// 前回のScanでLastEvaluatedKeyが取得された場合の再Scan
const loopedScanTask = new aws_stepfunctions_tasks.CallAwsService(
this,
'loopedScanTask',
{
service: 'dynamodb',
action: 'scan',
parameters: {
TableName: dataTable.tableName,
Limit: 2,
ExclusiveStartKey: aws_stepfunctions.JsonPath.stringAt(
'$.scanTaskOutPut.LastEvaluatedKey',
),
},
iamResources: [dataTable.tableArn],
iamAction: 'dynamodb:Scan',
resultPath: '$.scanTaskOutPut',
},
);
// itemsと直前の再Scanの結果を結合して、新しいitemsを作る
const concatArraysTask = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'concatArraysTask',
{
expression: aws_stepfunctions.JsonPath.format(
'{}.concat({})',
aws_stepfunctions.JsonPath.stringAt('$.items'),
aws_stepfunctions.JsonPath.stringAt('$.scanTaskOutPut.Items[*].id.S'),
),
resultPath: '$.items',
},
);
// 前回のScan結果でLastEvaluatedKeyがあれば再Scanを行い、なければ行わない
const lastEvaluatedKeyChoice = new aws_stepfunctions.Choice(
this,
'lastEvaluatedKeyChoice',
);
lastEvaluatedKeyChoice.when(
aws_stepfunctions.Condition.isPresent(
aws_stepfunctions.JsonPath.stringAt(
'$.scanTaskOutPut.LastEvaluatedKey',
),
),
loopedScanTask,
);
lastEvaluatedKeyChoice.otherwise(
new aws_stepfunctions.Succeed(this, 'succeed'),
);
loopedScanTask.next(concatArraysTask).next(lastEvaluatedKeyChoice);
// State Machine
new aws_stepfunctions.StateMachine(this, 'stateMachine', {
stateMachineName: 'stateMachine',
definition: firstScanTask.next(pass).next(lastEvaluatedKeyChoice),
});
}
}
- 検証のため少ないデータ量でもLastEvaluatedKeyを取得できるように、
Limit:2としてdynamodb:scanを実施しています。 - 上記では使用していませんが、実際の利用では取得時にProjection Expressionsパラメータを使用して1アイテムあたりのデータ量を必要最低限にし、すべてのデータを取得してもペイロード上限の256KBを超過しないようにする工夫が必要です。
- どうしても256KBを超える場合は、超えない単位で別のStateMachineを非同期実行しそちらでデータを処理するなどの工夫が必要です。(これはまた別の機会に紹介したいと思います。)
上記をCDK Deployしてスタックをデプロイします。これにより次のDefinitionのステートマシンが作成されます。
{
"StartAt": "firstScanTask",
"States": {
"firstScanTask": {
"Next": "pass",
"Type": "Task",
"ResultPath": "$.scanTaskOutPut",
"Resource": "arn:aws:states:::aws-sdk:dynamodb:scan",
"Parameters": {
"TableName": "dataTable",
"Limit": 2
}
},
"pass": {
"Type": "Pass",
"Parameters": {
"items.$": "$.scanTaskOutPut.Items[*].id.S",
"scanTaskOutPut.$": "$.scanTaskOutPut"
},
"Next": "lastEvaluatedKeyChoice"
},
"lastEvaluatedKeyChoice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.scanTaskOutPut.LastEvaluatedKey",
"IsPresent": true,
"Next": "loopedScanTask"
}
],
"Default": "succeed"
},
"concatArraysTask": {
"Next": "lastEvaluatedKeyChoice",
"Type": "Task",
"ResultPath": "$.items",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-IoBrEfNMlFoW",
"Parameters": {
"expression.$": "States.Format('{}.concat({})', $.items, $.scanTaskOutPut.Items[*].id.S)",
"expressionAttributeValues": {}
}
},
"loopedScanTask": {
"Next": "concatArraysTask",
"Type": "Task",
"ResultPath": "$.scanTaskOutPut",
"Resource": "arn:aws:states:::aws-sdk:dynamodb:scan",
"Parameters": {
"TableName": "dataTable",
"Limit": 2,
"ExclusiveStartKey.$": "$.scanTaskOutPut.LastEvaluatedKey"
}
},
"succeed": {
"Type": "Succeed"
}
}
}
動作確認
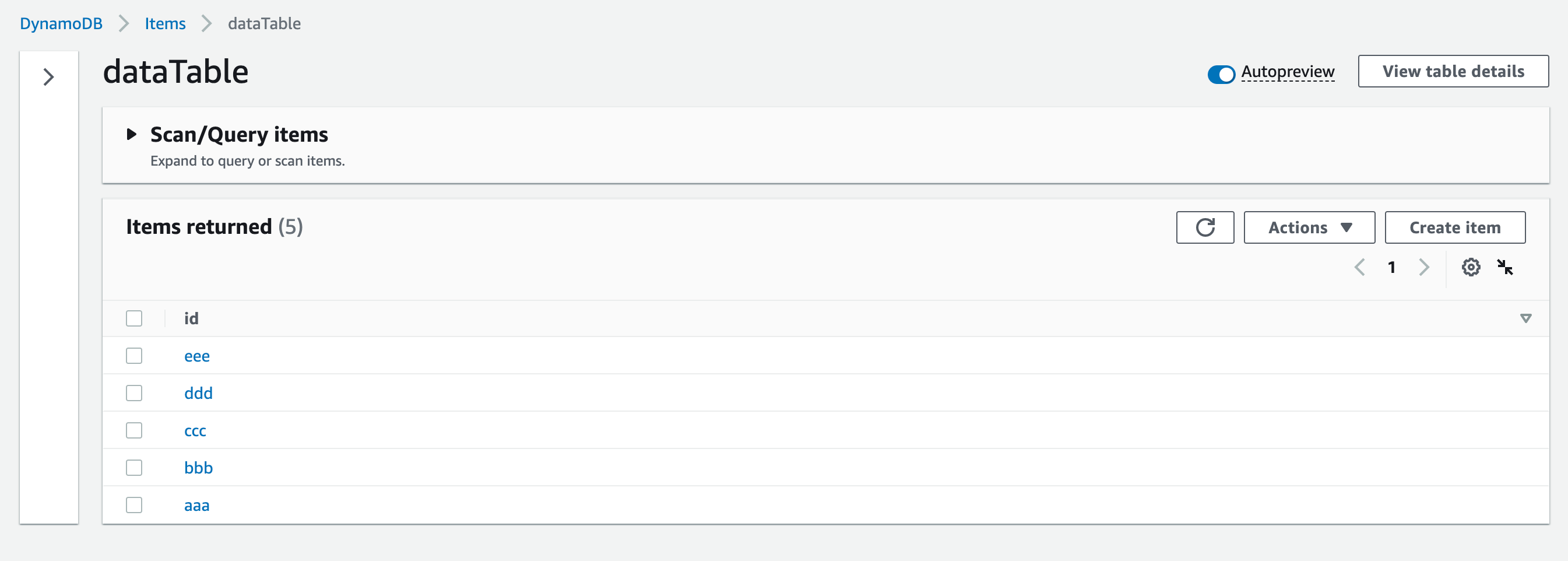
Scan対象のDynamoDBテーブルにデータを作成しておきます。
ステートマシンを実行します。
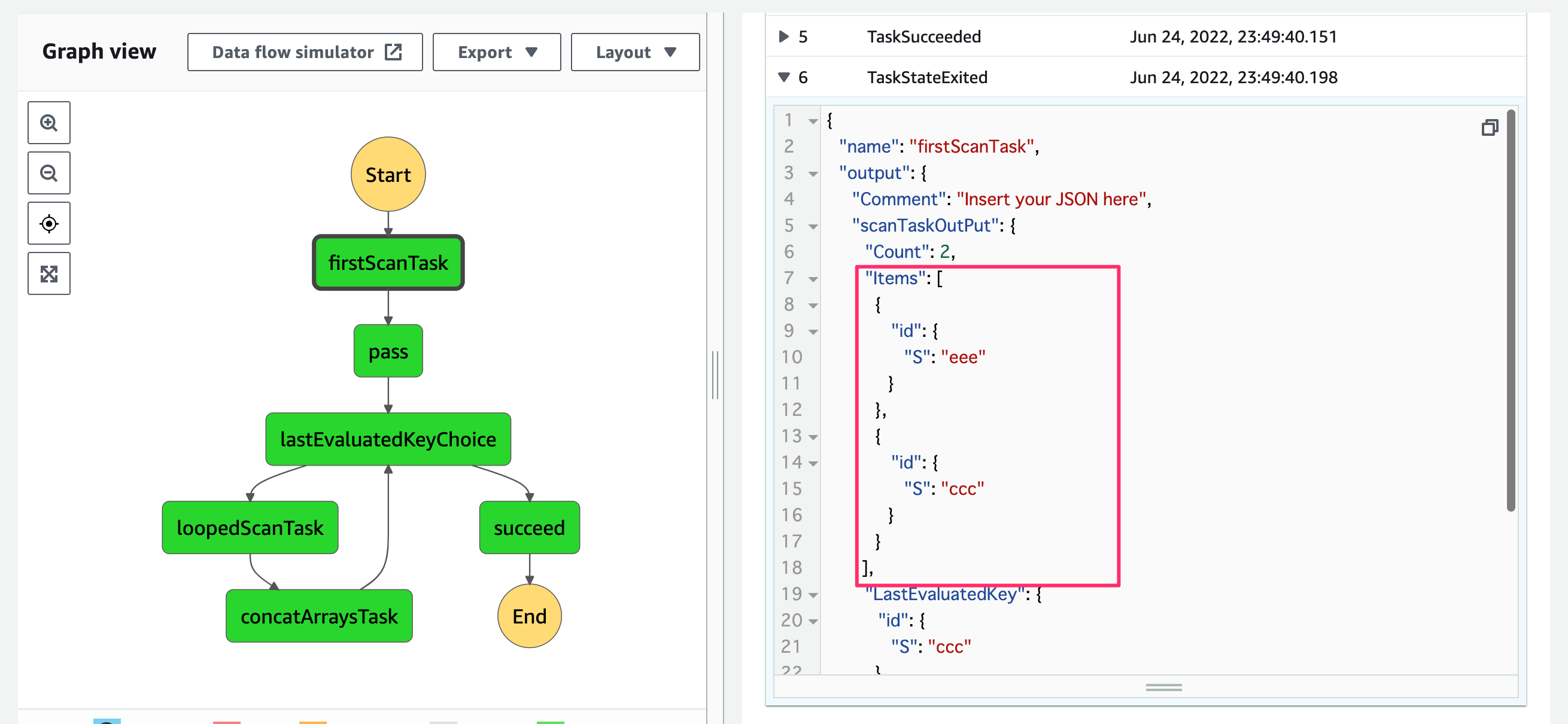
すると実行が成功しました。初回のScanではeeeとcccが取得されています。また出力にLastEvaluatedKeyが含まれているため、Choiceで2回目以降のScanを行う分岐へ進んでいます。
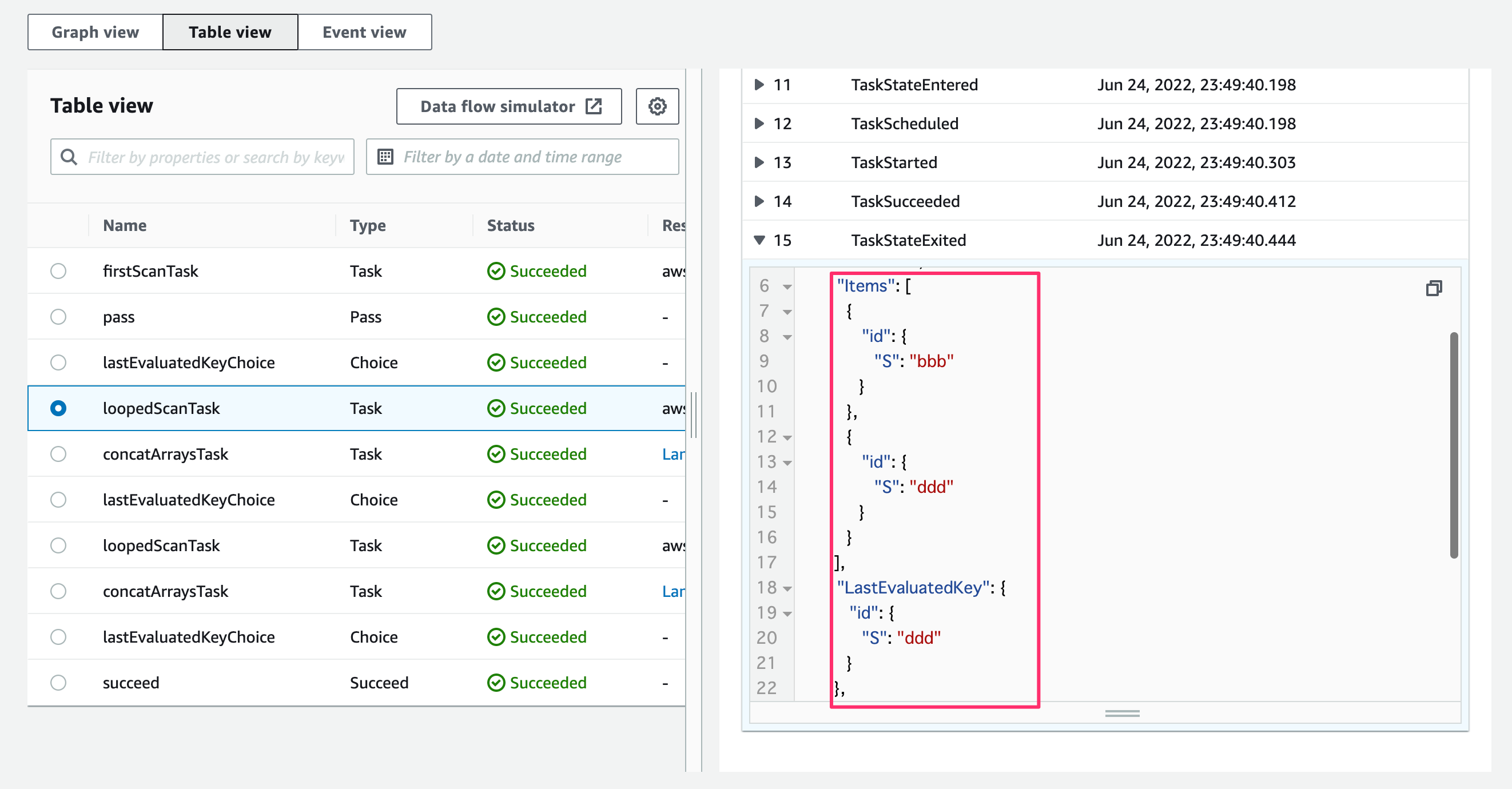
2回目のScanではbbbとdddが取得されています。またこちらでも出力にLastEvaluatedKeyが含まれています。
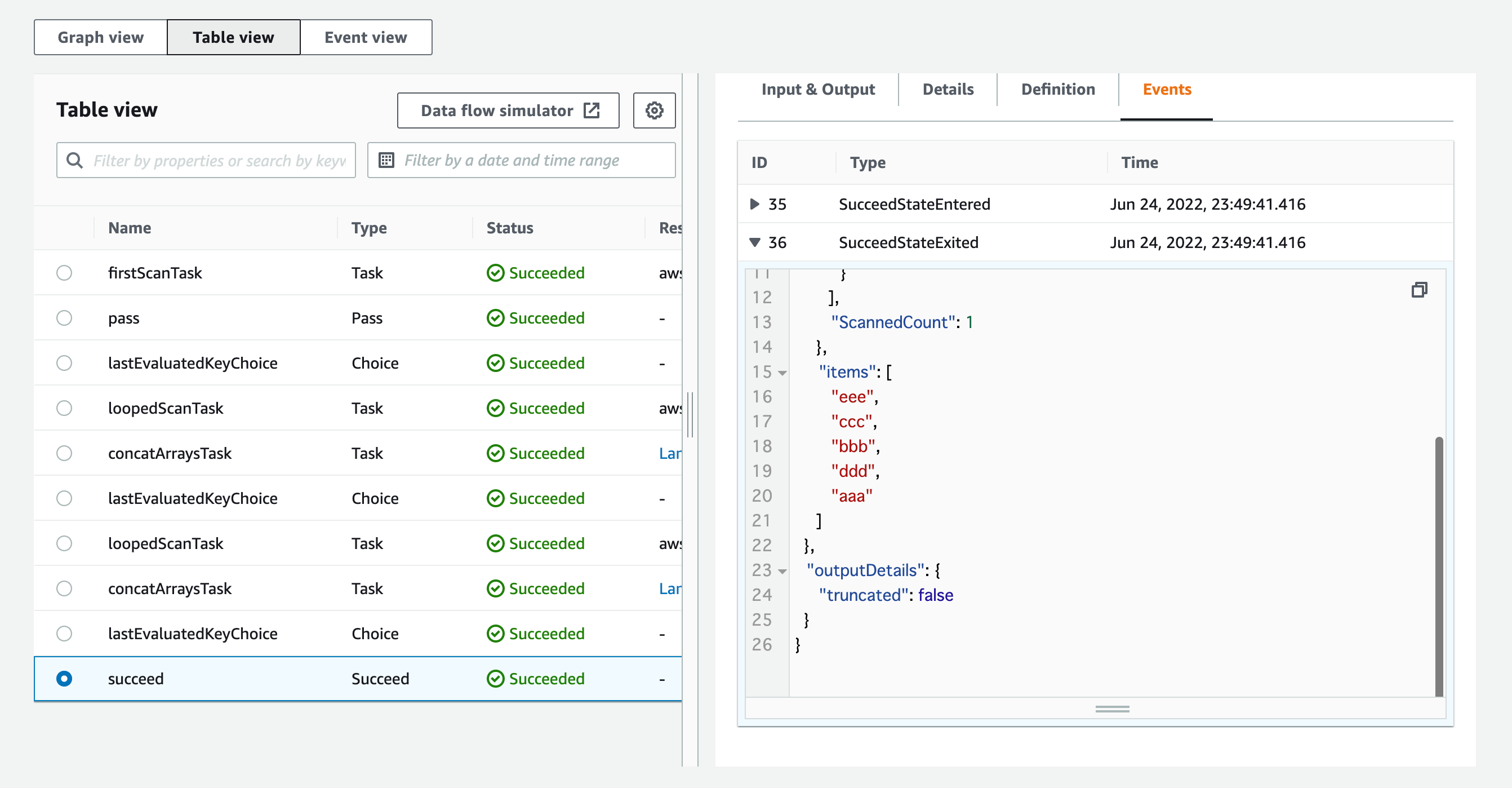
そしてconcatArraysTaskの出力を見ると、初回と2回目のScanで取得されたアイテムが1つの配列に結合されています!
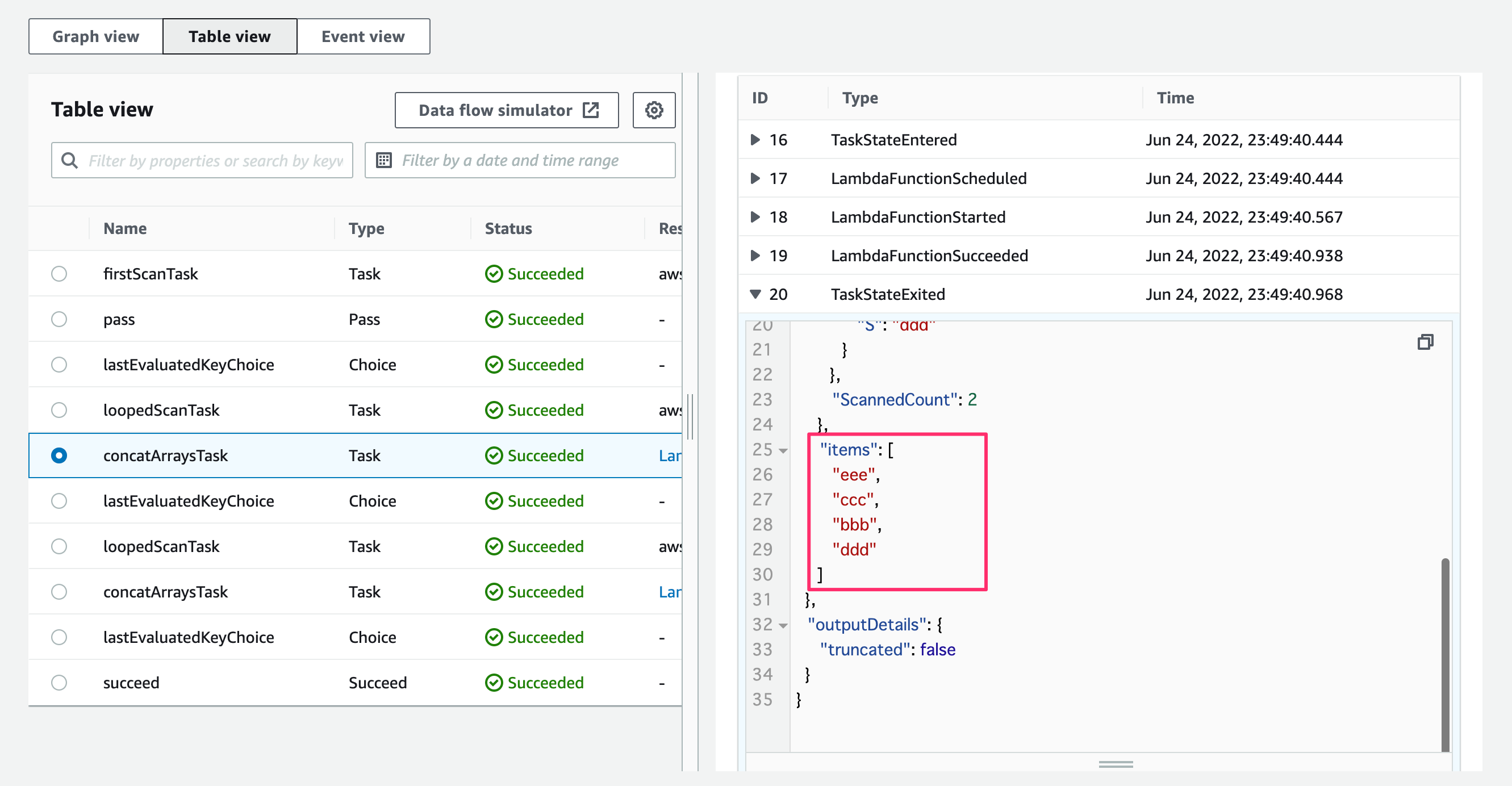
3回目のScanが終わりループを抜けた後の最終的な出力を見ると、繰り返し取得されたすべてのアイテムが一つの配列に結合されています!
おわりに
AWS Step FunctionsでDynamoDBテーブルからLastEvaluatedKeyによる繰り返し取得をしたアイテムを一つの配列に結合する実装をしてみました。
前回Scan時のLastEvaluatedKeyを保持しつつ、Scan毎にアイテムを一つの配列に結合する処理をどうしたら実現できるのか結構悩みました。どこか外部の一時領域にアイテムを保持する方法も思い浮かびましたが、最終的になかなかスマートな方法に着地できて良かったです。
参考
- [AWS Step Functions / AWS CDK] EvaluateExpressionタスクを使って配列の操作(要素追加、結合、Map処理など)をしてみた | DevelopersIO
- AWS Step Functionsでは組み込み関数だけで配列のフィルターやスライスができる(AWS CDK v2) | DevelopersIO
- AWS Step FunctionsによるDynamoDBテーブルからのデータ取得時のLastEvaluatedKey対応をしてみた | DevelopersIO
以上











