
【Copilot Studio】KPIレポートを収集から配布まで一気通貫してみた:親+資料化サブの最終構成
はじめに
こんにちは、けーまです。
複数のSaaS企業のKPIを比較し、グラフや示唆を添えてレポート化して配る、という作業は、経営企画やカスタマーサクセスの現場でよくあります。
シリーズを通して「収集 → 集計 → グラフ → 示唆 → 資料化 → 配布」の各工程を個別に検証してきましたが、最後はそれを1つのエージェントにまとめて、1回の依頼で最後まで走らせます。
そこで本記事では、これまでの工程を統合したエージェント「KPI統合アシスタント」を、空のエージェントから1つずつ組み上げる手順を取り上げ、2026年6月時点で実機検証しました。
親エージェントに収集(SharePointのナレッジ)と資料化サブ(子エージェント)と配布フローを持たせ、1文の依頼から比較・示唆・Word/Excel/PowerPointの生成・ダウンロードリンクまでをつなげます。
あわせて、グラフの軸ラベルを日本語で文字化けさせないコツや、ダウンロードリンクを安定して出すコツも添えました。
Copilot Studio で資料作成を一気通貫で自動化したい方の参考にしていただければと思います。
本記事は、Copilot Studio でエージェントを作るシリーズの第12回(最終回)です。
シリーズ全体では「収集 → 集計 → グラフ → 示唆 → 資料化」を一気通貫で行うエージェントを目指してきました。本記事はその総仕上げとして、各工程を1つのエージェントに統合します。
対象読者:Copilot Studio で、KPI比較レポートの作成を収集から配布まで自動化したい方
なお、本記事で使う企業名(CloudNova / StreamForge / Datapeak)とKPIの数値は、すべて架空データです。
シリーズ記事一覧
| 回 | テーマ | 記事 |
|---|---|---|
| 第1回 | 最初のエージェント | 初めてのエージェントを作ってみた |
| 第2回 | ナレッジ | ナレッジでファイルに基づく回答を試してみた |
| 第3回 | トピック・ツール・フロー | トピック・ツール・エージェントフローで「動き」を作り込む |
| 第4回 | テンプレート・自律トリガー・マルチエージェント | テンプレート・自律トリガー・マルチエージェントで構成を広げてみた |
| 第5回 | 収集(データの渡し方) | 集計用のKPIデータをエージェントに持たせる方法を比べてみた |
| 第6回 | 集計 | KPIの集計をLLMに任せず決定論的にやってみた |
| 第7回 | グラフ | KPIをチャット内でグラフ表示してみた |
| 第8回 | 示唆 | 集計した数値から示唆を生成してみた |
| 第9回 | 資料化(Word) | テンプレートに数値を差し込んでWordレポートを自動生成してみた |
| 第10回 | 資料化(PowerPoint / Excel) | コードインタープリターで本物の.pptx/.xlsxをゼロから生成してみた |
| 第11回 | 配布 | 生成したWordレポートをフロー経由でダウンロードリンクとして配布してみた |
| 第12回 | 統合(最終回) | (本記事) |
1. 今回作るもの
この記事で作るのは、次の構成のエージェントです。
- 親エージェント「KPI統合アシスタント」を空の状態から新規作成する
- 集計・資料化に使うコードインタープリターをオン、ハルシネーション抑制のため「根拠のない応答を許可する」をオフにする
- 収集を SharePoint の生データ(Excel)1本のナレッジで持たせる
- 資料化(Word・Excel・PowerPoint の生成)を子エージェント「資料化サブ」に委譲する
- 配布をエージェントフロー(OneDrive保存+共有リンク)で固定する
- 1回の依頼で、比較表・示唆・Word/Excel/PowerPoint・ダウンロードリンクまでつなげて実行する
2. 全体像:親+資料化サブ
シリーズの記事は工程単位(収集・集計・グラフ・示唆・資料化・配布)で書いてきましたが、実際に動かすエージェントは、工程をそのまま並べるのではなく、親オーケストレーターと、資料化を担うサブ、固定したい配布のフローに分けます。
今回サブエージェント(子エージェント)にするのは「資料化」だけです。
収集はナレッジ、配布はフローという、サブエージェントとは別の部品で担います。
KPI統合アシスタント(親エージェント)
受付・収集・比較・示唆・取りまとめは、親自身が担当する
┌─ 親が直接持つ部品(サブエージェントではない)
│ ナレッジ : SharePoint の生データ kpi-raw-data-yoy.xlsx → 収集
│ ツール : 配布フロー(OneDrive保存→組織内共有リンク) → 配布
│
└─ 親が委譲する子エージェント(サブエージェントはこれだけ)
資料化サブ : コードインタープリターで Word/Excel/PPT を生成 → 資料化
収集は親が SharePoint ナレッジで直接参照するので、収集専用のサブは作りません。
集計・グラフ・示唆も、ナレッジの数値をもとに親(とコードインタープリター)が扱います。
工程と、それを担う部品、シリーズの該当回の対応は次のとおりです。
| 工程 | 担う部品 | シリーズの該当回 |
|---|---|---|
| 収集 | SharePoint ドキュメント ライブラリのナレッジ | 第2回・第5回 |
| 集計 | コードインタープリター(Python) | 第6回 |
| グラフ | コードインタープリター(Excelネイティブグラフ・画像) | 第7回・第10回 |
| 示唆 | 言語モデルの生成(指示で方針を定義) | 第8回 |
| 資料化 | コードインタープリター(Word・PowerPoint・Excel) | 第9回・第10回 |
| 配布 | エージェントフロー(OneDrive保存+共有リンク) | 第11回 |
なぜこの分け方なのかというと、工程ごとに性質が違うためです。
生成オーケストレーションの部品選択はLLMによる確率的な判断なので、確実に同じ動作をさせたい配布はフローで固定します。
一方、コードインタープリターは応答が分単位になることがあり、同期フローの100秒制限に収まらないため、フロー化せず子エージェントのチャット能力として持たせます。
Respond to the agent within the 100-second action limit. Optimize the flow logic, queries, and the amount of data returned so that a typical run is below this 100-second limit.
引用元: Add an agent flow or workflow as a tool to an agent | Microsoft Learn
子エージェントは親に内包される軽量なサブで、別途の公開やライセンスは不要です。
Child agents are lightweight agents within your existing agent.
引用元: Add other agents overview | Microsoft Learn
3. ステップ1: 親エージェントを作る
まず、空のエージェントを新規作成します。
Copilot Studio の左メニューから 「エージェント」→「新しいエージェント」 を開き、「スキップして設定に移動」などで手動構成に進みます。
名前を 「KPI統合アシスタント」 にします。
作成できたら、概要画面の 「指示」 に、エージェントの役割と数値の扱い方を書きます。
今回は委譲の指示も含めて日本語で書きました。
あなたは「KPI統合アシスタント」です。
回答にはナレッジにあるKPIの数値(CloudNova・StreamForge・Datapeak)だけを使ってください。数値を創作してはいけません。値がない場合は「未提供」と明記します。
比較や示唆を求められたら、3社の比較表と短い示唆を日本語で返します。
Word・Excel・PowerPointのファイル(レポート・表・スライド)の作成を求められたら、必ず子エージェント「資料化サブ」に委譲し、そこで作られたダウンロードリンクを返してください。
ユーザーへの応答は常に日本語で行います。
空のエージェントから作成した「KPI統合アシスタント」の概要画面。名前と指示(日本語)を設定する
指示で「ナレッジにある数値だけを使う・数値を創作しない」と明記しているのは、数値の解釈は生成AIに任せても、数値そのものの計算はさせないためです。
計算は後段のコードインタープリターに任せ、生成AIには解釈だけを担当させます。
4. ステップ2: コードインタープリターをオン、根拠のない応答をオフにする
集計・グラフ・資料化の中心はコードインタープリターです。
利用するには、エージェントの設定で有効にします。
「設定」→「生成 AI」 を開き、「コード インタープリター」 を オン にします。
同じ画面で、「根拠のない応答を許可する」 を オフ にします。
これは、ナレッジに根拠のない数値を生成AIが作ってしまうのを防ぐためです。
設定の生成AIで、コードインタープリター(Pythonの実行)をオン、「根拠のない応答を許可する」をオフにした状態
5. ステップ3: 収集を SharePoint ナレッジで持たせる
次に、3社のKPIの生データをナレッジとして持たせます。
これが「収集」の工程です。
ここで重要なのは、コードインタープリターで集計させたいなら、生データを ファイルのアップロードではなく SharePoint のドキュメント ライブラリ に置く、という点です。
コードインタープリターが構造化ファイル(Excel・CSV)を集計に使えるのは、次の2通りに限られます。
- エンドユーザーが、チャット中に構造化ファイルをアップロードする
- 作成者が、構造化ファイルを含む SharePoint の ドキュメント ライブラリ をナレッジ ソースとして追加する
Copilot Studio agents can use code interpreter to analyze structured files that are provided to the agent by the following two ways:
- As an end-user, when you upload structured files while chatting with the agent.
- As a maker, when you add SharePoint Documents library as a knowledge source, which in turn contains the structured files.
引用元: Use code interpreter to analyze structured data (preview) | Microsoft Learn
つまり、Excelファイルを通常のファイル ナレッジとしてアップロードしただけでは、コードインタープリターはその中身を直接読んで集計できません。
今回は、集計用の生データ kpi-raw-data-yoy.xlsx(3社の月次ARRなど)を SharePoint のドキュメント ライブラリに置き、それをナレッジ ソースにします。
この1本で、文章で答えるときの「根拠」も、コードインタープリターで集計するときの「生データ」も兼ねられます。
親エージェントの 「ナレッジ」→「ナレッジの追加」 から 「SharePoint」 を選び、「項目の参照」 でライブラリ内の kpi-raw-data-yoy.xlsx を選択して追加します。
追加後、状態が 「準備完了」(インデックス化の完了)になり、タイプが SharePoint として登録されるまで待ちます。
集計用の生データ(SharePointのExcel)をナレッジに追加し、状態が「準備完了」になった親エージェントの概要画面
6. ステップ4: 資料化サブ(子エージェント)を作る
集計・グラフ・資料化のうち、ファイル生成は子エージェントに委譲します。
コードインタープリターは応答に分単位かかることがあり、同期フローには載せにくいためです。
同期フローには100秒のアクション制限があり、フローのロジック・クエリ・返すデータ量を最適化して、この制限内に収める必要があります。
Respond to the agent within the 100-second action limit. Optimize the flow logic, queries, and the amount of data returned so that a typical run is below this 100-second limit.
引用元: Add an agent flow or workflow as a tool to an agent | Microsoft Learn
そのため、コードインタープリターはフロー化せず、子エージェントのチャット能力として持たせます。
親の 「エージェント」→「エージェントの追加」→「新しいエージェント」 から子エージェントを作り、名前を 「資料化サブ」(日本語)にします。
説明(Description)と指示(Instructions)も日本語で、いつ・何をするのかを書きます。
説明(Description):
資料化サブは、KPIの数値から、ダウンロードできるOfficeファイルを生成します。
Word文書・Excelファイル・PowerPointの作成を求められたら、コードインタープリターでファイルを作り、ダウンロードリンクを返します。
Excelのグラフは、openpyxlのネイティブBarChartを使います(matplotlibの画像は埋め込みません)。Excel上で編集できるグラフにするためです。
指示(Instructions):
あなたは、渡されたKPIの数値からOfficeファイル(Word .docx/Excel .xlsx/PowerPoint .pptx)を作ります。
コードインタープリターを使い、生成したファイルのダウンロードリンクを必ず返します。
渡された数値だけを使い、値を創作してはいけません。
子エージェント「資料化サブ」の設定。表示名・説明・指示をいずれも日本語にして委譲を試す
今回の検証では、資料化サブにナレッジを追加しなくても、親が委譲時に数値(比較表や生データ)を渡し、子がそれをコードインタープリターで処理してファイルを生成できました。
子が「データがない」と言って作れない場合は、SharePoint ナレッジを子にも追加します。
7. ステップ5: 親のエージェント一覧を確認する
子を作ったら、親の 「エージェント」 タブを開き、子に 「資料化サブ」 が並んでいることを確認します。
今回は収集サブを作らないので、子はこの1つだけです。
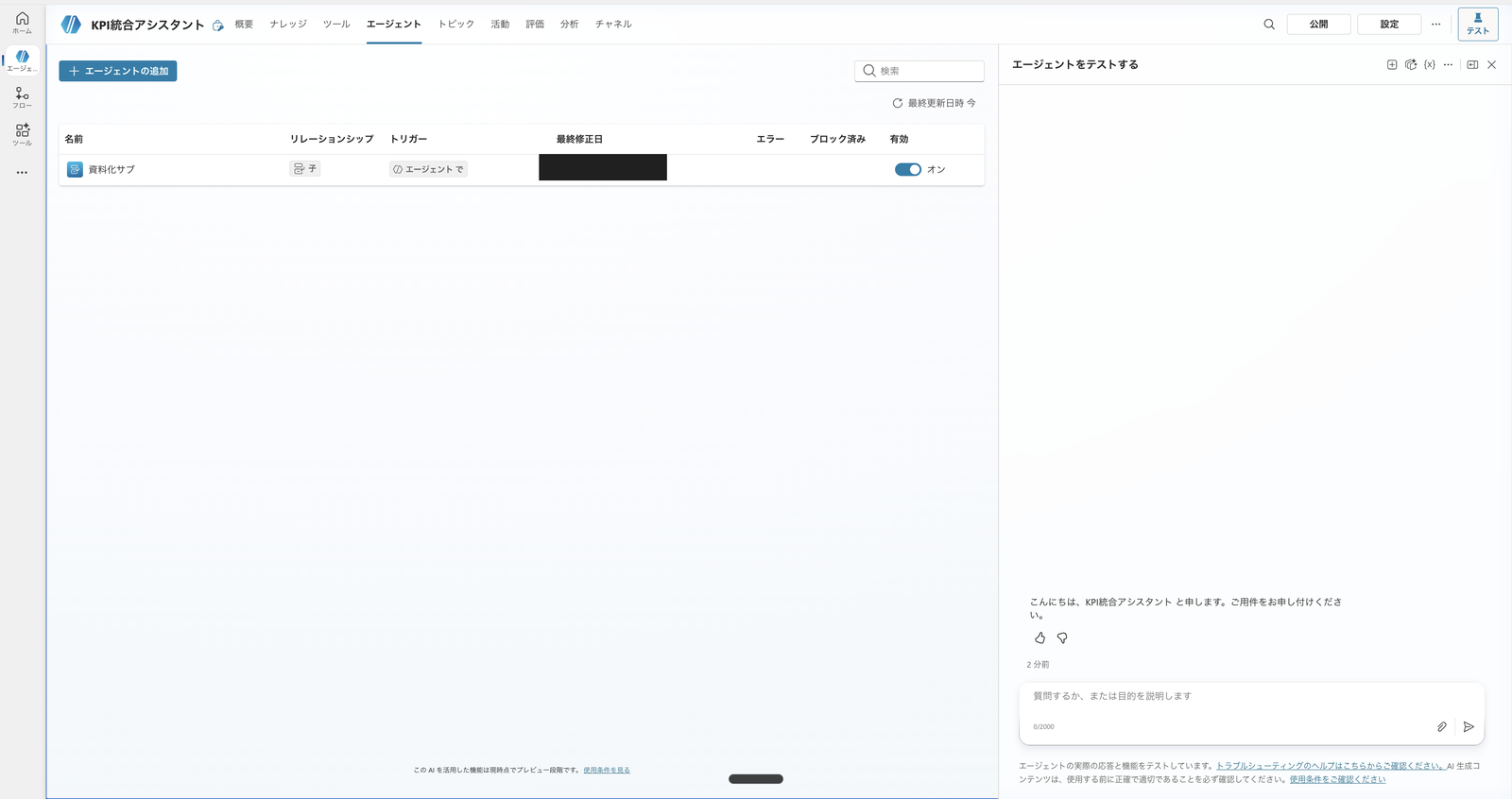
親「KPI統合アシスタント」に、資料化サブが子エージェント(有効=オン)として接続された状態
8. ステップ6: 配布をフローで固定する
配布のように「必ず同じ手順で動いてほしい」工程は、会話任せにせず、エージェントフローで固定します。
第11回で作った配布フロー(OneDrive保存→組織内共有リンク)をそのまま使い、親のツールとして登録します。
配布フローは、次の5ステップで組んだものです。
- トリガー 「エージェントがフローを呼び出したとき」 を置く
- Wordレポートを生成するプロンプト(Document output 設定済み)を実行する
- OneDrive にファイルを作成 し、プロンプト出力の「Document Output Content Bytes」を保存する
- OneDrive の 「共有リンクを作成する」 で、組織内に限定した共有リンクを作る
- 「エージェントに応答」 で、共有リンクのURLを親に返す
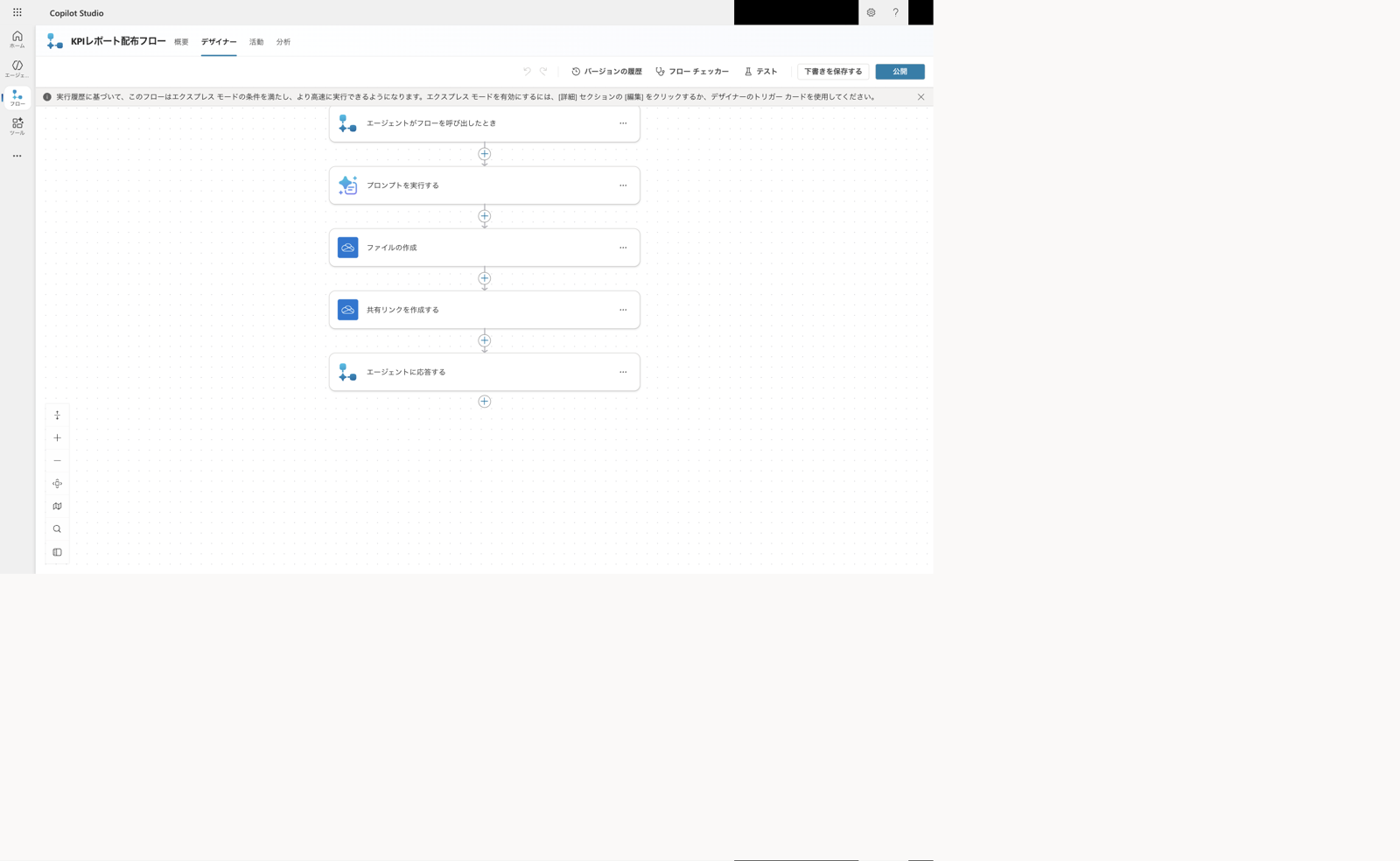
配布用エージェントフロー(第11回で作成)。OneDriveに保存し、組織内共有リンクを作って親に返す
このフローを、親の 「ツール」→「ツールを追加する」→「フロー」 から登録し、いつ使うかが伝わる説明文を付けてオンにします。
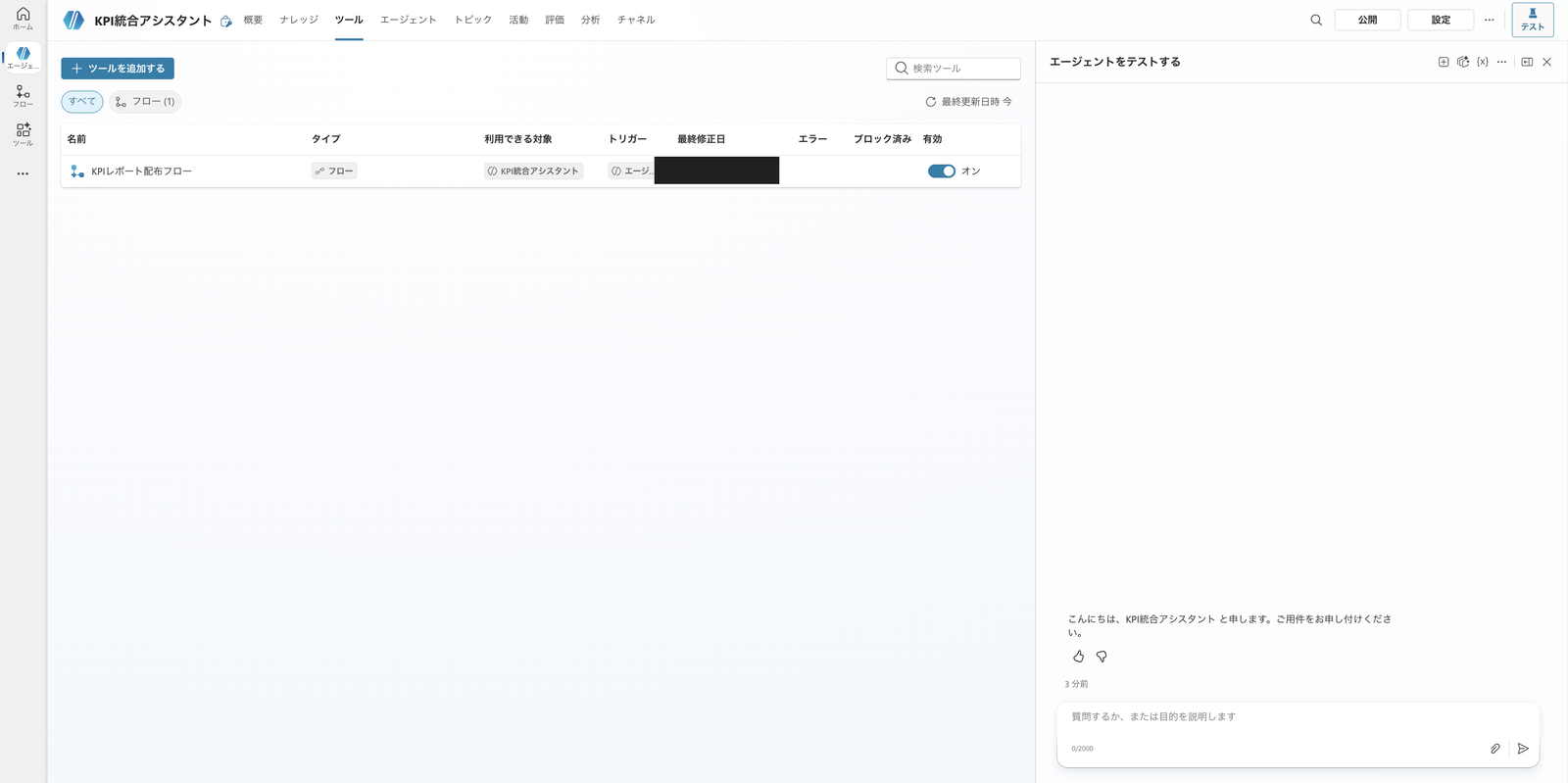
配布フローを、説明文付きのツールとして親に登録した状態(有効=オン)
9. ステップ7: 動かす
ここまでで、収集(SharePointナレッジ)・資料化(資料化サブ+コードインタープリター)・配布(フロー)がそろいました。
実機で確認したところ、工程は次の順で動かすのが分かりやすかったです。
9.1 親で収集・比較・示唆を出す
まず、親のテストチャットに比較と示唆を求めます。
CloudNova・StreamForge・Datapeak の2025年度第3四半期(Q3 FY2025)のKPIを、ナレッジの数値で比較してください。
3社の比較表と、各社の注目点・3社比較の示唆を出してください。ナレッジにない数値は使わないでください。
親は、SharePointナレッジの生データを検索して、3社の比較表と示唆を返します。
このとき、ナレッジにある数値だけを使い、提供のない指標は推測で埋めませんでした(4章でオフにした「根拠のない応答」が効いています)。
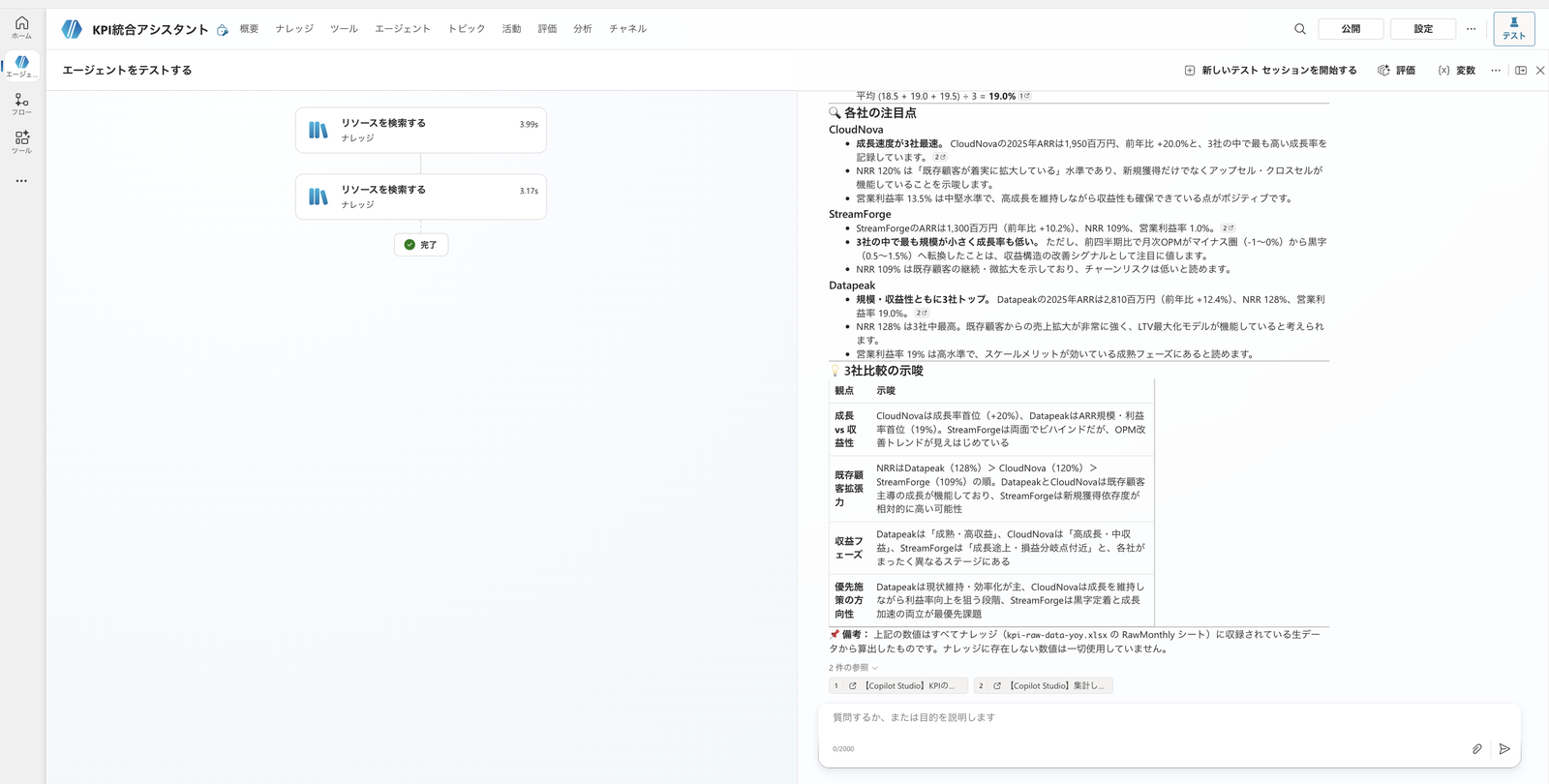
親が SharePoint ナレッジの数値で3社を比較し、注目点と示唆を返す。回答にはナレッジに収録された生データだけを使う
9.2 親に1文を送って3形式を生成する(資料化サブへ委譲)
比較表と示唆が出たら、続けて資料化を頼みます。
依頼文では、対象期間(Q3 FY2025)と、タイトルなど日本語で入れたいラベルを指定し、最後にダウンロードリンクを求めます。
たとえばWordなら次のように依頼します。
ナレッジのQ3 FY2025(2025年10〜12月)のデータで、3社のARR比較レポートをWordで作ってください。
タイトルは「2025年度 第3四半期 ARR比較レポート」にして、3社のARR比較表(前年比つき)・各社の注目点・3社比較の示唆を日本語で入れてください。
ナレッジにない数値は使わないでください。
できあがったら、ダウンロードできるリンクをください。
親は子エージェント「資料化サブ」に委譲し、資料化サブがコードインタープリターを実行して、ファイルとダウンロード用のカード(ダウンロードボタン付き)を返します。
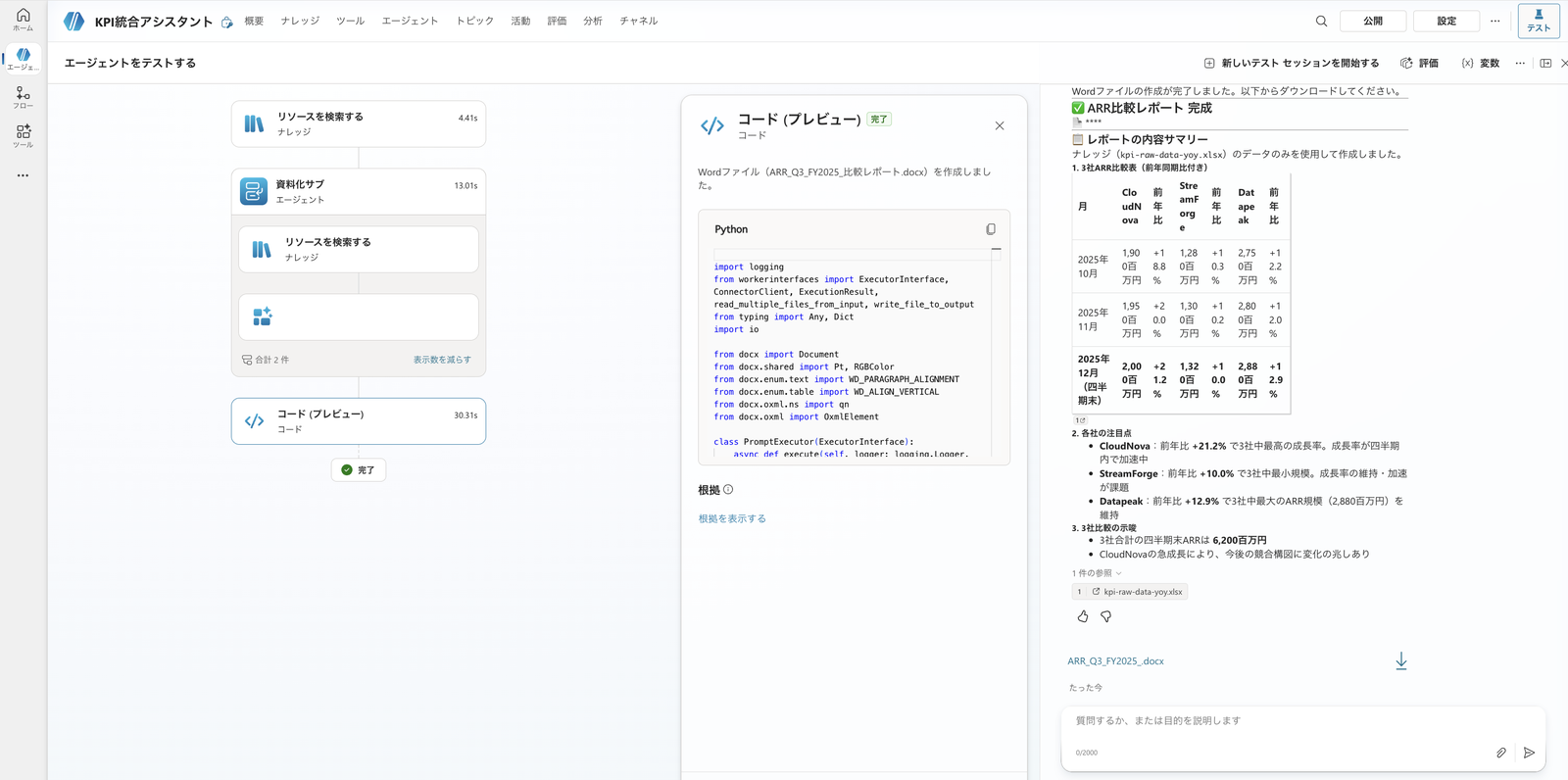
親が「資料化サブ」に委譲し、Q3 FY2025 の Word(.docx)のダウンロードカードが返る。活動マップに「資料化サブ」のノードが出て、委譲が起きたことが分かる
同じ要領で Excel と PowerPoint も依頼します。
ただしExcelのグラフは作り方に注意が必要です。
ナレッジのQ3 FY2025(2025年10〜12月)のARRデータで、Excelを openpyxl で作ってください。
3社のARRを比べる縦棒グラフを、画像ではなく編集できるグラフで入れてください。
グラフのタイトルは「2025年度 第3四半期 ARR比較(百万円)」、横軸は会社名、縦軸は「ARR(百万円)」にしてください。
ナレッジにない数値は使わないでください。
できあがったら、ダウンロードできるリンクをください。
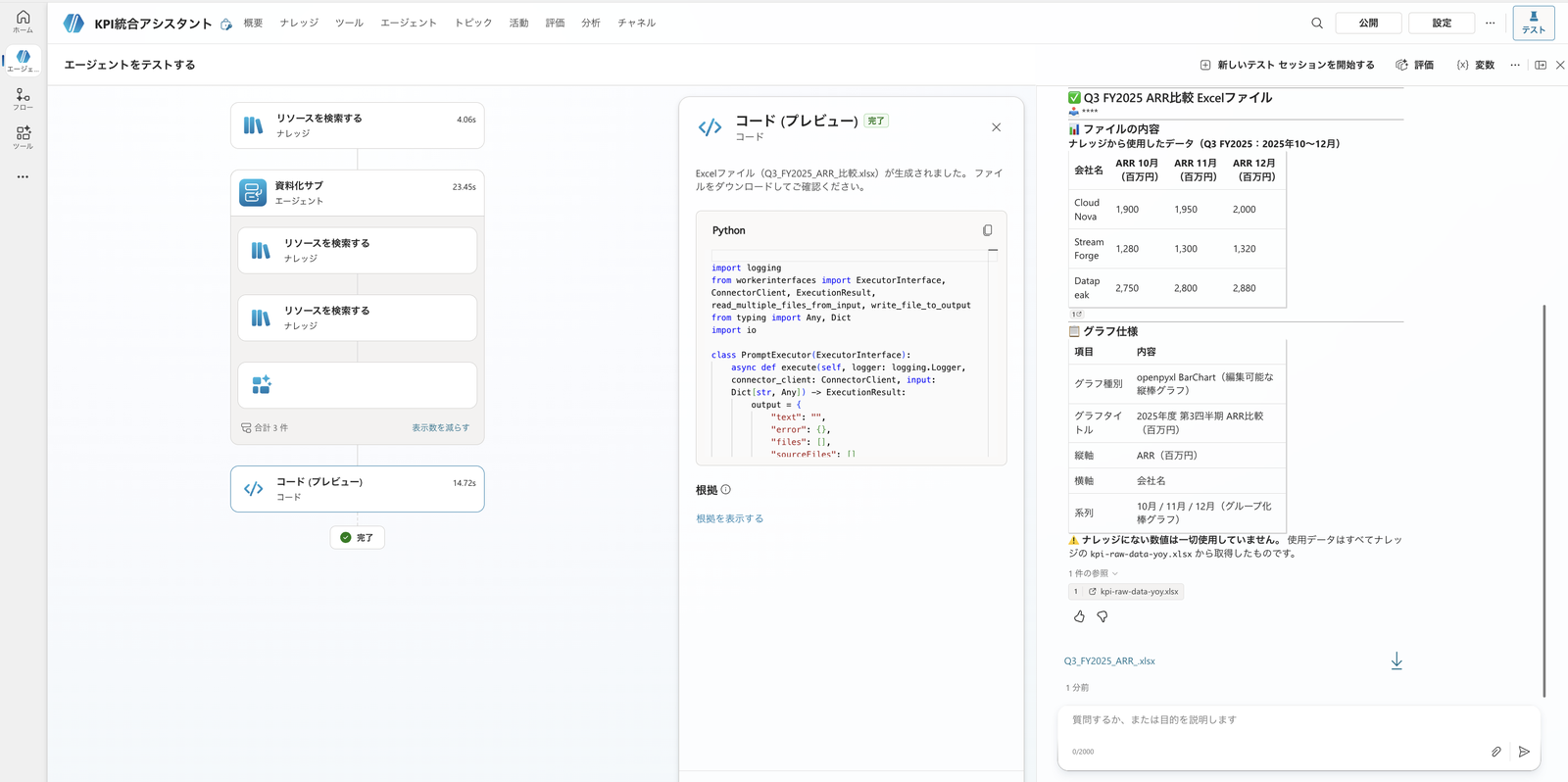
Excelも「資料化サブ」が生成。openpyxl のネイティブ棒グラフ(日本語タイトル・軸ラベル)の仕様と、.xlsx のダウンロードカードが返る
ナレッジのQ3 FY2025(2025年10〜12月)のARR比較のPowerPointを python-pptx で作ってください。
表紙・ARR棒グラフ・KPI表・示唆のスライド構成で、見出し・ラベルは日本語にしてください。
棒グラフは画像ではなく編集できるグラフにして、タイトルは「2025年度 第3四半期 ARR比較(百万円)」、横軸は会社名、縦軸は「ARR(百万円)」にしてください。
ナレッジにない数値は使わないでください。
できあがったら、ダウンロードできるリンクをください。
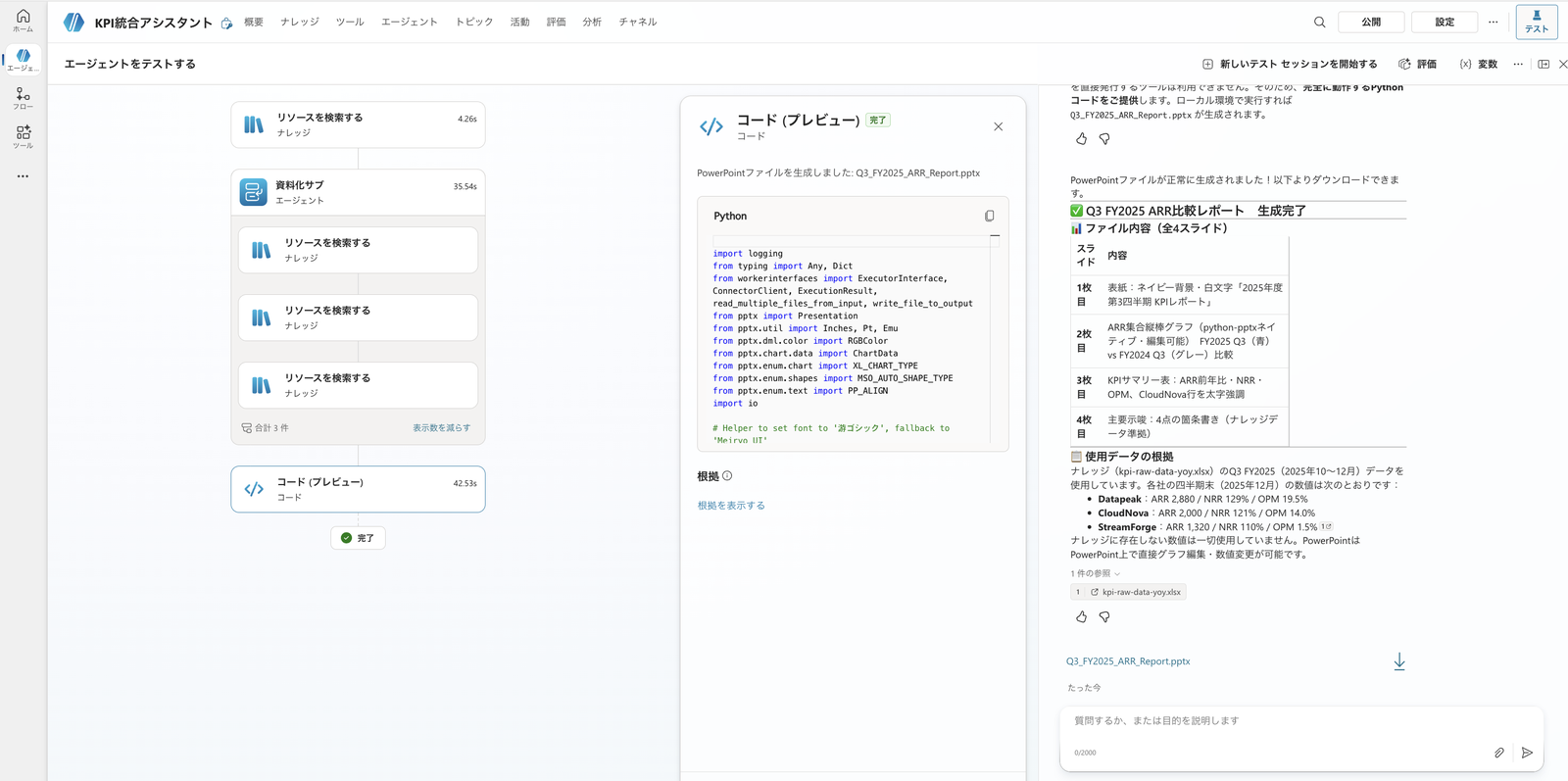
PowerPointも「資料化サブ」が生成。表紙・ARR棒グラフ・KPI表・主要示唆の4スライド構成と、.pptx のダウンロードカードが返る
9.3 生成されたファイルの中身を確認する
3形式のダウンロードリンクから、実際にファイルを開いて中身を確認しました。
中身のスクリーンショットは、ダウンロードしたファイルを手元で開いて撮ったものです。
Word(.docx)は、タイトル・ARR比較表(前年比つき)・月次ARR推移・各社の注目点・3社比較の示唆まで入った、レポートでした。
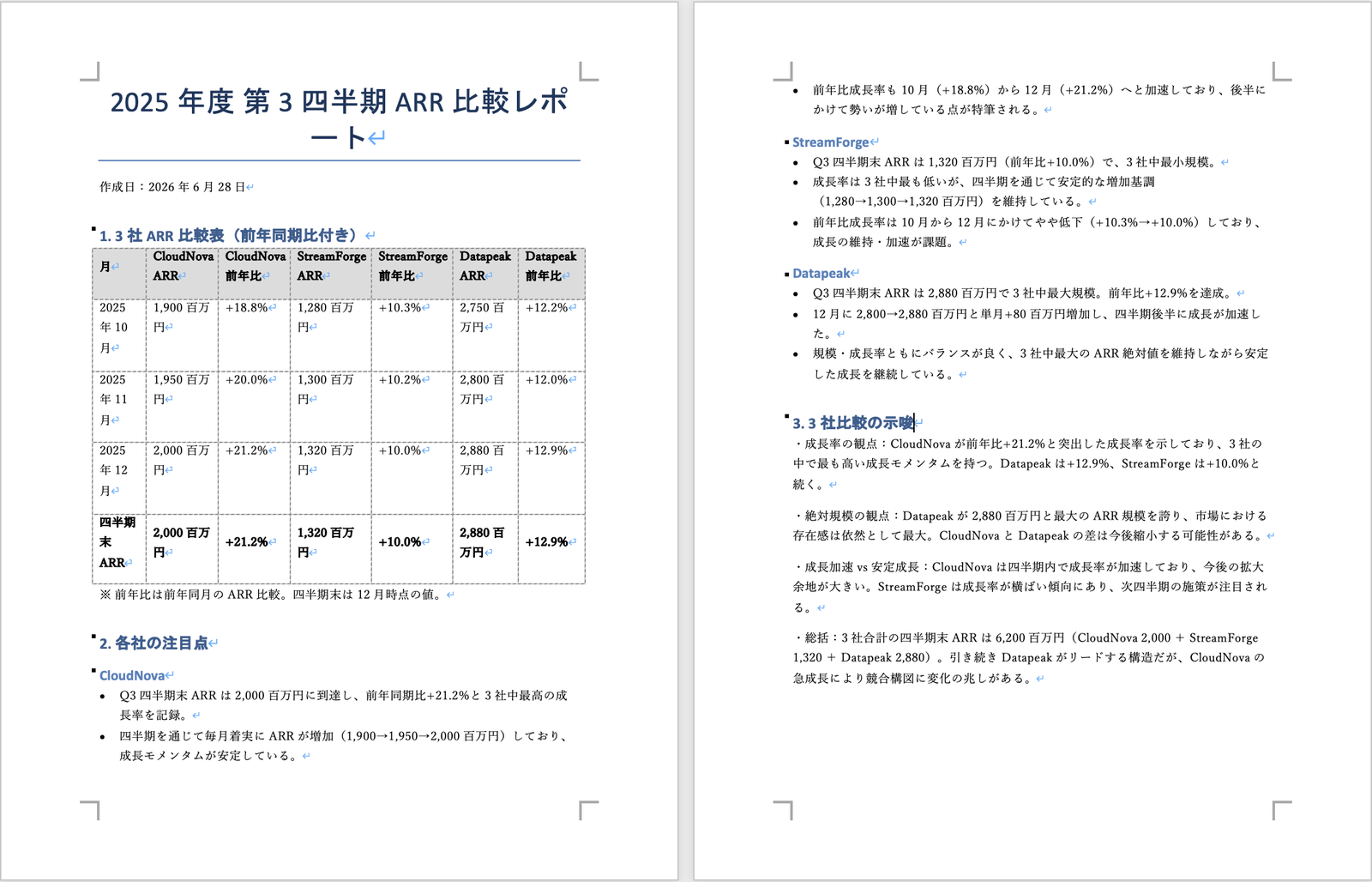
生成されたWordレポート。タイトル・ARR比較表(前年比つき)・月次ARR推移・注目点・示唆が並ぶ。期間は「2025年度 第3四半期(Q3 FY2025)」と明記されている
Excel(.xlsx)は、openpyxl のネイティブ棒グラフ(BarChart)で作られているので、グラフをクリックすると Excel 上で編集できます。
画像を貼っただけのグラフではないため、タイトルや軸ラベルを日本語にしても文字化けせず、後から書式変更もできます。
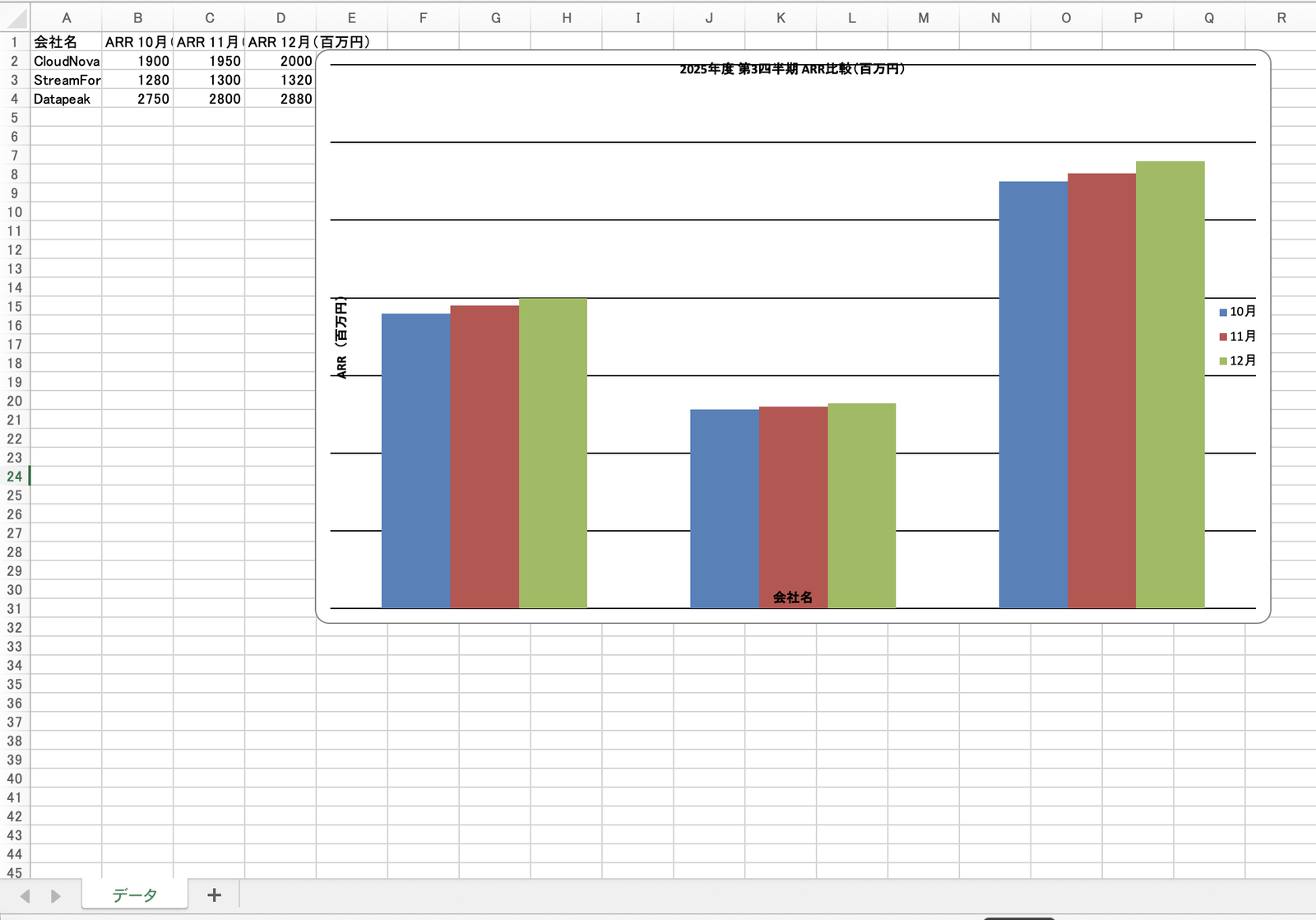
生成されたExcel。シート「データ」の月次データと、ネイティブ棒グラフ「2025年度 第3四半期 ARR比較(百万円)」。軸ラベル(会社名・ARR(百万円))も日本語で文字化けしていない
PowerPoint(.pptx)は、表紙・ARR棒グラフ・KPI表・主要示唆の4枚構成でした。
棒グラフは python-pptx のネイティブグラフで、見出しやラベルも日本語です。

生成されたPowerPoint(4スライド)。表紙/ARR棒グラフ(python-pptxのネイティブグラフ)/KPI表/主要示唆。見出し・ラベルとも日本語
3形式とも、同じ Q3 FY2025 のデータでそろい、グラフの日本語ラベルも文字化けせずに生成できました。
ここまでで、収集(SharePointナレッジ)→集計・資料化(資料化サブ+コードインタープリター)が1つのエージェントへの依頼でつながり、配布はフローとして固定できました。
配布フローの実行(OneDriveへの保存と組織内共有リンクの発行)は第11回で確認済みで、初回は OneDrive コネクタのサインイン(許可)が要ります。本記事ではフローを親のツールとして固定するところまでを扱います。
10. つまずきポイント
実機で引っかかりやすかった点をまとめます。
- 依頼があいまいだと、回ごとに結果がぶれる:対象期間や集計方法を指定せずに頼むと、同じ依頼でもファイルごとに期間・数値の解釈が変わることがあります。対象期間(Q3 FY2025 など)を依頼ではっきり指定し、必要なら集計方法(月次の平均など)も添えると安定します(第6回「集計をLLMに任せない」と同じ考え方です)。
- 委譲は確率的で毎回は起きない:同じ依頼でも委譲する回・親が自分で実行する回・コードを文章で返すだけの回が混在しました。失敗したら再度依頼します。
- コードインタープリターのファイル生成は形式によって失敗することがある:Word は安定して生成できましたが、グラフ付きの Excel・PowerPoint では、コード表示後に無出力で止まる・
SystemErrorが出る・ファイルが引用(citation)参照として返りダウンロードリンクが出ない、といった失敗を観測しました。失敗したら、グラフを軽くして再実行するか、もう一度依頼します。 - Excel のグラフは matplotlib 画像より openpyxl のネイティブグラフが軽い:matplotlib で描いた画像を貼ろうとすると重くなり、
SystemErrorや無応答停止が起きやすかったです。openpyxl.chart.BarChartで Excel ネイティブの(後から編集できる)グラフを作るよう指示すると、軽く安定しました(9.2)。 - ダウンロードリンクが出ない回は「ダウンロードリンクをください」と頼んで数回試す:同じ生成でも、ダウンロードボタン付きカードが出る回と、引用参照だけでリンクが出ない回がありました。「ダウンロードできるリンクをください」と明示し、数回リトライするとカードが出ます。
- コードインタープリターはフローに載せない:応答が分単位になることがあり、同期フローの100秒制約に引っかかります。子エージェントのチャット能力として持たせます。
11. まとめ
シリーズを通して、KPI比較レポートの「収集 → 集計 → グラフ → 示唆 → 資料化 → 配布」を、1つのエージェント(親「KPI統合アシスタント」+子「資料化サブ」+配布フロー)に統合できました。
収集から資料化までは1文の依頼でつながり、配布はフローとして固定しました(配布フローの実行は第11回で確認済みで、初回は OneDrive コネクタのサインインが要ります)。
各工程で分かったことを、用途の判断に使える形で整理します。
| 工程 | できること | 判断のポイント |
|---|---|---|
| 収集 | SharePointナレッジの生データを根拠に回答 | コードインタープリターで集計するなら、ファイルのアップロードではなく SharePoint ライブラリに置く |
| 集計 | コードインタープリターで集計 | 対象期間を依頼文で明示し、ナレッジの数値を使わせる |
| グラフ | Excelネイティブグラフ/コードインタープリターで画像生成 | openpyxl のネイティブグラフは matplotlib の画像貼り付けより軽い |
| 示唆 | 数値の裏付けつきで比較・気づきを生成 | 計算済みの数値を渡し、解釈だけを生成AIに任せる |
| 資料化 | 子エージェント+コードインタープリターで Word・Excel・PPT を生成 | 委譲は確率的。確実に同じ動作をさせたい工程はフロー固定 |
| 配布 | OneDrive保存+組織内ダウンロードリンク | 決定論ステップはフローで固定する |
ノーコード中心で、KPI比較の一連の流れをエージェントに任せられるのは実用的だと感じました。
依頼文で対象期間(Q3 FY2025)を明示し、ナレッジの数値だけを使わせることで、Word・Excel・PowerPoint の3形式を同じデータでそろえて生成できました。
グラフは「画像ではなく編集できるネイティブグラフ」を指定すると、matplotlib の画像貼り付けより軽く生成でき、軸ラベルやタイトルを日本語にしても文字化けしませんでした。
一方で、対象期間や集計方法をあいまいにしたままLLMに委ねると、回ごとに結果がぶれる余地があります。資料化のように見た目を整える部分は生成AIに任せ、対象期間や使う数値は依頼ではっきり指定する、という作り分けが現実的でした。
検証には架空のSaaS企業3社(CloudNova / StreamForge / Datapeak)の架空KPIデータを使いました。
実データで運用する際は、ナレッジに置く情報の正確さと、各部品の説明文の品質、そして数値を決定論で確定させる作り込みが、エージェントの精度を大きく左右します。








