
Amazon AthenaのPartition projectionを設定したGlueテーブルをAWS CDK v2で作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
今回は、Amazon AthenaのPartition projectionを設定したGlueテーブルをAWS CDK v2で作成してみました。
Partition projectionとは
ALTER TABLE ADD PARTITIONやMSCK REPAIR TABLEなどのコマンドやGlue Crawlerを使えば、AWS Glue Data Catalogにパーティションを作成(パーティショニング)することができます。パーティショニングによりAmazon AthenaのクエリやGlue Jobによるデータ取得を効率化することが可能となります。
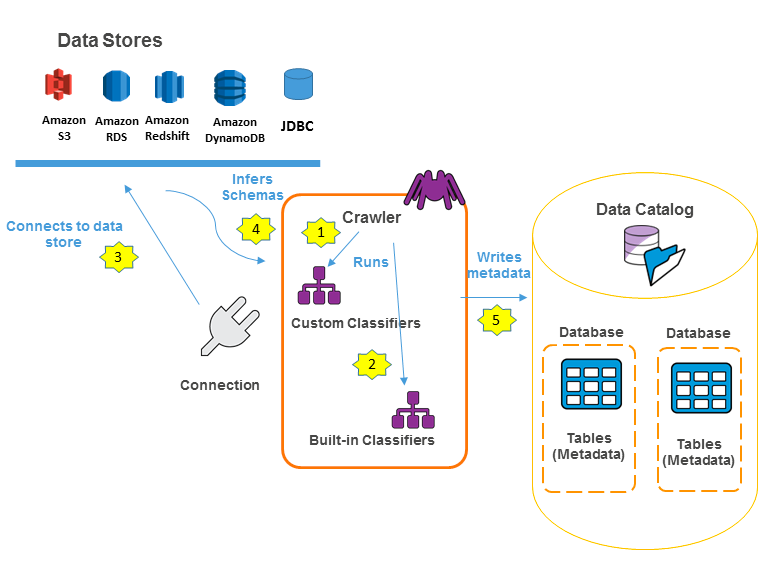 https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.htmlより
https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.htmlより
一方で、上記方法で作成したパーティションの他に、Amazon AthenaではPartition projectionによるパーティショニングも使用できます。Partition projectionでは、クエリ時にConfigを元にしてメモリ上でパーティションが自動計算されるためクエリ処理が効率化されます。また、Configの設定によりパーティション管理の自動化もできます。
今回、このPartition projectionを設定してAthenaでのクエリで使用してみます。
やってみた
実装
環境は次のようになります。
$ npm ls aws-cdk-lib aws-cdk @aws-cdk/aws-glue-alpha --depth=0 project@0.1.0 /path/to/project ├── @aws-cdk/aws-glue-alpha@2.29.1-alpha.0 ├── aws-cdk-lib@2.29.1 └── aws-cdk@2.29.1
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
Stack,
StackProps,
RemovalPolicy,
aws_glue,
} from 'aws-cdk-lib';
import * as glue_alpha from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// データ格納バケット
const dataBucket = new aws_s3.Bucket(this, 'dataBucket', {
bucketName: `data-${this.account}-${this.region}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
}
);
// データカタログ
const dataCatalog = new glue_alpha.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
const dataGlueTable = new glue_alpha.Table(this, 'sourceDataGlueTable', {
tableName: 'source_data_glue_table',
database: dataCatalog,
bucket: dataBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'date',
type: glue_alpha.Schema.STRING,
},
],
dataFormat: glue_alpha.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue_alpha.Schema.STRING,
},
{
name: 'count',
type: glue_alpha.Schema.FLOAT,
},
],
});
// データカタログテーブルへのPartition Projectionの設定
const cfnTable = dataGlueTable.node.defaultChild as aws_glue.CfnTable;
cfnTable.addPropertyOverride('TableInput.Parameters', {
'projection.enabled': true,
'projection.date.type': 'date',
'projection.date.range': '2022/06/28,NOW',
'projection.date.format': 'yyyy/MM/dd',
'projection.date.interval': 1,
'projection.date.interval.unit': 'DAYS',
'storage.location.template':
`s3://${dataBucket.bucketName}/data/` + '${date}',
});
// Athenaワークグループ
new aws_athena.CfnWorkGroup(this, 'athenaWorkGroup', {
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
recursiveDeleteOption: true,
});
}
}
- AWS CDK v2(aws-cdk-lib)にはAWS GlueのL2 ConstructのClassがまだ無いため、alphaモジュール(@aws-cdk/aws-glue-alpha)を導入してL2 Constructを使用しています。
- Partition projectionはGlueテーブルの設定ですが、alphaモジュールのL2 Constructにはプロパティがないため、Construct nodeを取得して直接設定しています。
2022/06/28からNOW(UTC現在時刻)までのyyyy/MM/ddパスを1日単位で射影するパーティションを設定しています。
上記をCDK Deployしてスタックをデプロイします。
JSON Lines形式のデータを作成します。
$ cat data1
{"userId":"u001","count":3}
{"userId":"u001","count":1}
{"userId":"u002","count":5}
{"userId":"u002","count":8}
{"userId":"u003","count":2}
$ cat data2
{"userId":"u001","count":14}
{"userId":"u002","count":10}
{"userId":"u003","count":12}
$ cat data3
{"userId":"u001","count":4}
{"userId":"u002","count":4}
{"userId":"u003","count":0}
$ cat data4
{"userId":"u001","count":5}
各ファイルをそれぞれS3 Bucketの日付パーティションのパスにアップロードします。
aws s3 cp data1 s3://${BUCKET_NAME}/data/2022/06/27/data1
aws s3 cp data1 s3://${BUCKET_NAME}/data/2022/06/28/data2
aws s3 cp data2 s3://${BUCKET_NAME}/data/2022/06/29/data3
aws s3 cp data3 s3://${BUCKET_NAME}/data/2022/06/30/data4
動作確認
現在Glueテーブルにパーティションは1つも作成されていません。
$ aws glue get-partitions \
--database-name ${GLUE_DATABASE_NAME} \
--table-name ${DATA_SOURCE_GLUE_TABLE_NAME}
{
"Partitions": []
}
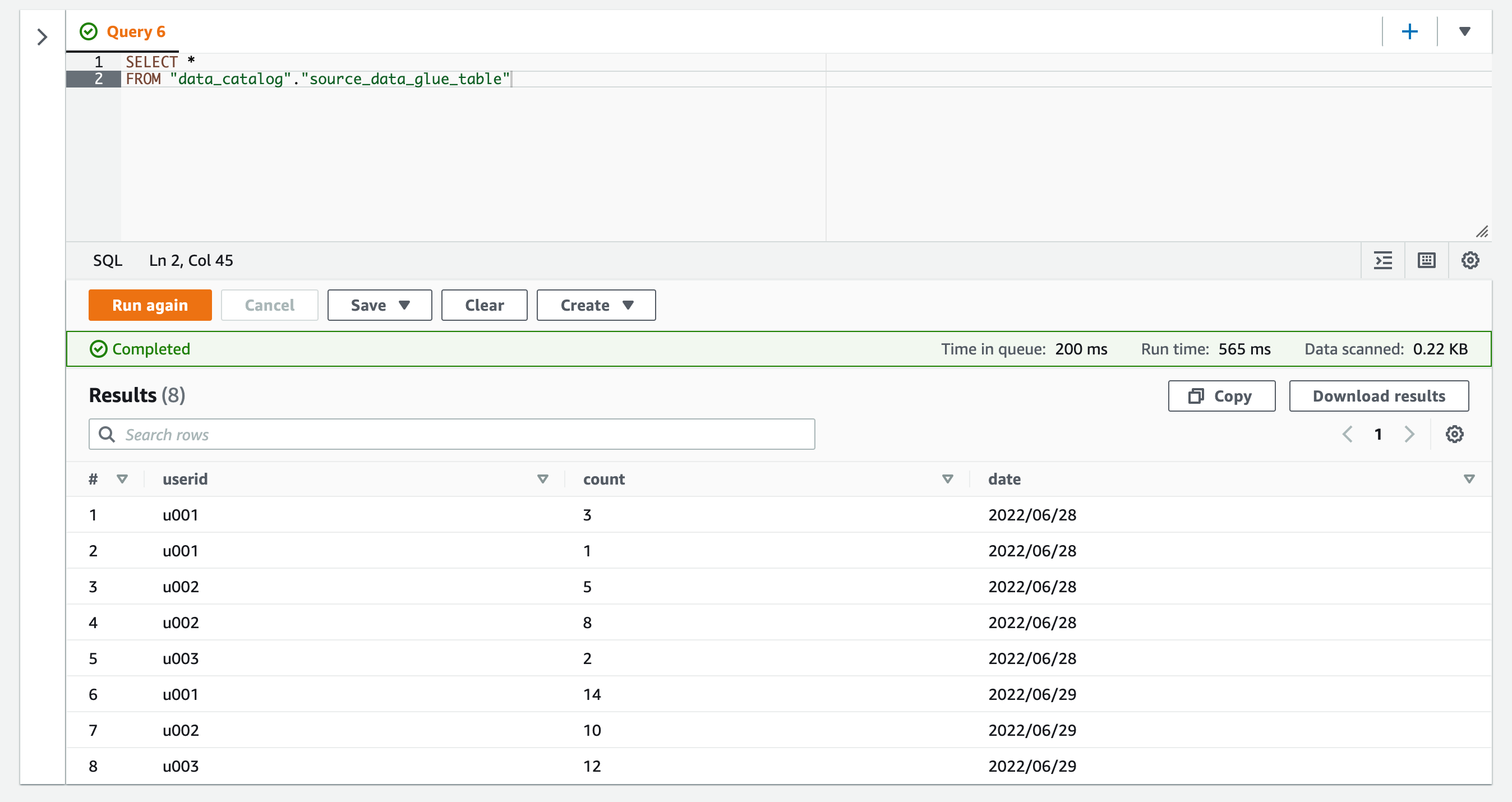
SELECTクエリを実行します。
SELECT * FROM "data_catalog"."source_data_glue_table"
するとPartition射影の対象である2022/06/28および2022/06/29(現在のUTC日付)のデータが取得できています。Partition projectionがきちんと使用できていますね!
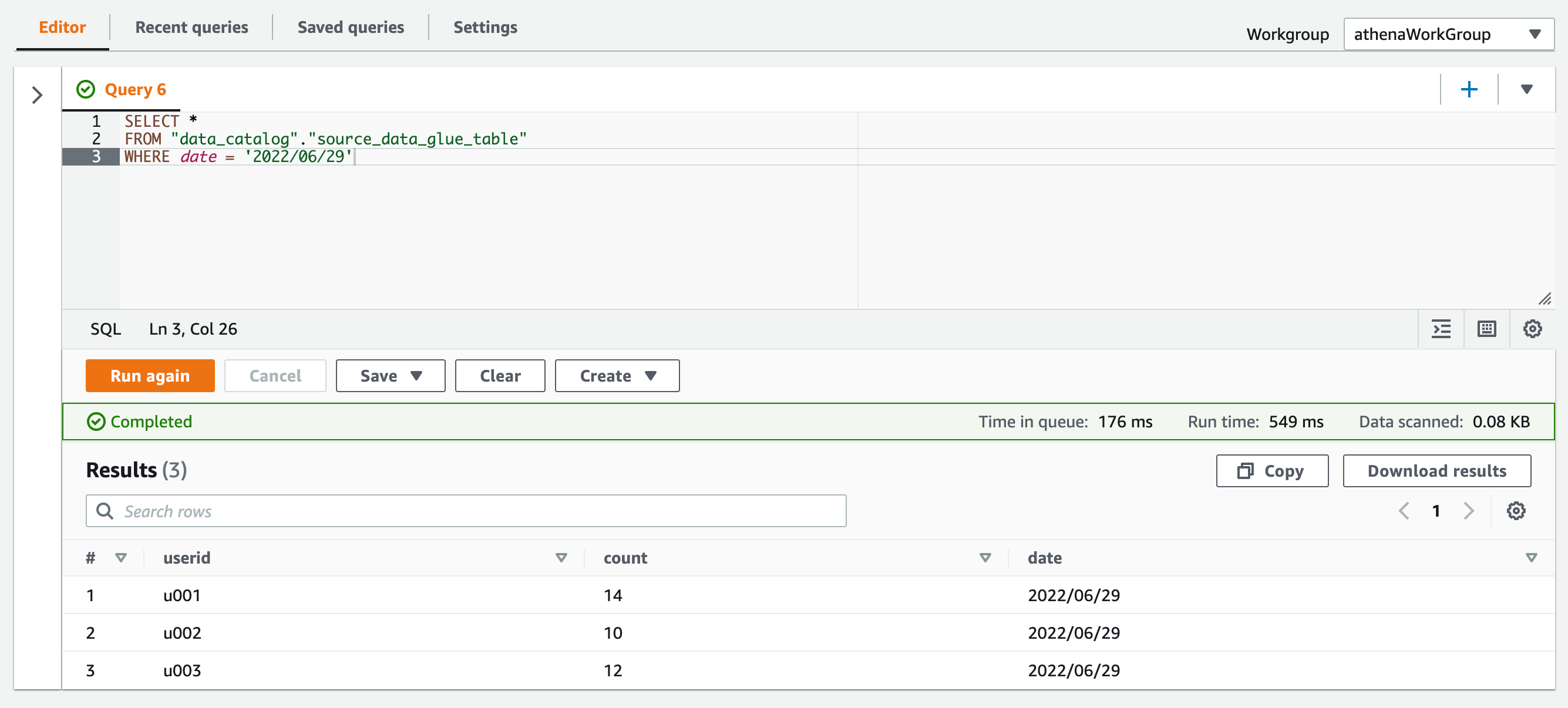
またパーティションキーをWHERE句でも使用できています!
SELECT * FROM "data_catalog"."source_data_glue_table" WHERE date = '2022/06/29'
おわりに
Amazon AthenaのPartition projectionを設定したGlueテーブルをAWS CDK v2で作成してみました。
パーティションの自動計算によりクエリ実行毎に動的にパーティショニングを行えるため、例えば日次でパーティション対象のパスが増えるシステムなどでわざわざパーティションを追加するための処理を設けずに済むのが嬉しいですね。
参考
- Setting up Partition projection - Amazon Athena
- (aws-glue) add option to pass in more parameters (e.g. Partition projection, regex serde, etc.) · Issue #16660 · aws/aws-cdk
- CloudFrontのアクセスログをパーティション射影を使ってコスパ良くAthenaでクエリーする仕組みをCDKで作った
- Amazon Athena - Column cannot be resolved on basic SQL WHERE query - Stack Overflow
- Amazon AthenaのPartition projectionを設定したGlueテーブルをCloudFormationで作成してみた | DevelopersIO
- [Amazon Athena] ALTER TABLE ADD PARTITIONコマンドでnon-Hiveなパーティションを追加してみた | DevelopersIO
以上









