
ローカルから疑似工場センサーデータを流してDatabricks Zerobus Ingestを試してみた
さがらです。
DatabricksのZerobus Ingestについて、Unity CatalogのDeltaテーブルに対してアプリケーションから直接データをプッシュできる、サーバレスかつブローカー管理不要の取り込みAPIとして提供されています。
トヨタ自動車社の事例として、工場の温度・湿度・設備テレメトリをSoracom Beam経由でZerobus Ingestに送り、Databricks上でほぼリアルタイムに分析する構成が紹介されています。事例では、既存ネットワークで平均4.5秒だったレイテンシが、gRPC利用時に約0.1秒まで短縮されたとされています。
このトヨタ自動車社の事例のミニチュア版として、ローカル(WSL2)上のPythonプログラムを疑似エッジデバイスに見立て、Zerobus Ingestを実際に試してみたので、本記事でまとめます。
機能概要
Zerobus Ingestは、Unity CatalogのDeltaテーブルに対してアプリケーションから直接データをプッシュできる、サーバレスの取り込みAPIです。gRPC / REST / OpenTelemetryの3つのプロトコルに対応しており、自分でブローカーやパーティションを管理する必要はありません。
主な特徴は以下の通りです。
- Unity Catalog管理のDeltaテーブルへ直接書き込みできる
- gRPC / REST / OpenTelemetryをサポート
- サーバレス・自動スケーリングで、ブローカー管理が不要
- Zerobus Ingest自体はテーブルを自動作成しないため、事前にターゲットDeltaテーブルを作成する必要がある
エンドポイントは次の形式となります。
https://<workspace-id>.zerobus.<region>.cloud.databricks.com
制限事項
2026年4月30日時点で、公式Docに記載のある主な制限事項は以下の通りです。
- 一部のリージョンでのみ利用可能で、ワークスペースとターゲットテーブルは同一の対応リージョン内にある必要があります
- 配送保証は at-least-once(少なくとも1回) のため、重複排除はアプリケーション側で設計する必要があります
- テーブル名・列名はASCII文字・数字・アンダースコアのみサポート
- 管理型Deltaテーブルのみ対応(デフォルトストレージ不可、カタログコミット非対応)
- 2000列を超えるプロトスキーマは非対応
- パーティション化テーブルでは、5秒間隔で1000パーティションを超える書き込みは非対応
- コンプライアンスセキュリティプロファイルワークスペース非対応
レイテンシの指標としては、耐久性確認とDeltaテーブルへの具体化時間が別の観点として整理されています。耐久性確認はP50で200ms / P95で500ms、Deltaテーブルへの具体化はP50で5秒 / P95で30秒程度とされています。「投げてすぐクエリで見える」わけではない点はご注意ください。
前提条件
今回の検証環境は以下です。
- Databricks: Free Edition(AWS)
- S3バケット: ユーザー側で用意した
s3://databricks-bucket-sagara/sagara-free-edition- Storage Credential / External Locationの構築はこちらのブログの手順に沿って実施済み
- ローカル環境: WSL2上のUbuntu 24.04 LTS
- Python環境管理:
uv
事前準備
検証の流れとして、まずDatabricks側でカタログ・スキーマ・テーブル・サービスプリンシパルを準備し、その後WSL2側でuvプロジェクトを準備する形にします。
Databricksワークスペース情報を確認する
Databricks Free Editionにログインし、ブラウザのURLからWorkspace URLとWorkspace IDを読み取ります。
https://dbc-xxxxxxxx-yyyy.cloud.databricks.com/?o=1234567890123456
上記の場合、以下のように分解できます。
DATABRICKS_WORKSPACE_URL=https://dbc-xxxxxxxx-yyyy.cloud.databricks.com
WORKSPACE_ID=1234567890123456
リージョン(例: us-west-2)はDatabricks UIのワークスペーススイッチャーから確認します。
確認できたら、Zerobus Ingestのエンドポイントを組み立てます。
https://1234567890123456.zerobus.us-west-2.cloud.databricks.com
カタログ・スキーマ・テーブルを作成する
Databricks SQL EditorまたはNotebookで以下を順に実行します。
ここで重要なポイントとして、Zerobus Ingestはデフォルトストレージ不可という制限があります。そのため、デフォルトストレージのカタログにテーブルを作成してZerobus Ingestから書き込もうとすると、以下のようなエラーが返ってきます。
{"error_code":"INVALID_PARAMETER_VALUE","message":"Unsupported table kind. Tables created in default storage are not supported. Error Code: 4024, Error State: 0."}
これを回避するため、カタログ作成時にMANAGED LOCATIONとしてユーザー管理のS3パスを指定します。今回は前提条件の通り、s3://databricks-bucket-sagara/sagara-free-editionを使用します。
CREATE CATALOG IF NOT EXISTS sagara_zerobus
MANAGED LOCATION 's3://databricks-bucket-sagara/sagara-free-edition';
スキーマ・テーブルもカタログ配下に作成します。カタログでManaged Locationが指定されていれば、配下のスキーマ・テーブルは自動でそのS3パス配下に作成されます。
CREATE SCHEMA IF NOT EXISTS sagara_zerobus.iot;
トヨタ自動車社の事例を意識して、温度・湿度・設備状態・電力・モーター回転数を持つ疑似工場テレメトリのテーブルを作成します。Zerobus Ingest側の制約に合わせて、テーブル名・列名はすべてASCIIで揃えています。
CREATE TABLE IF NOT EXISTS sagara_zerobus.iot.factory_telemetry_zerobus (
event_id STRING,
line_id STRING,
device_id STRING,
seq BIGINT,
observed_at_ms BIGINT,
sent_at_ms BIGINT,
temp_c DOUBLE,
humidity_pct DOUBLE,
motor_rpm INT,
power_kw DOUBLE,
status STRING,
source STRING,
producer_host STRING
);
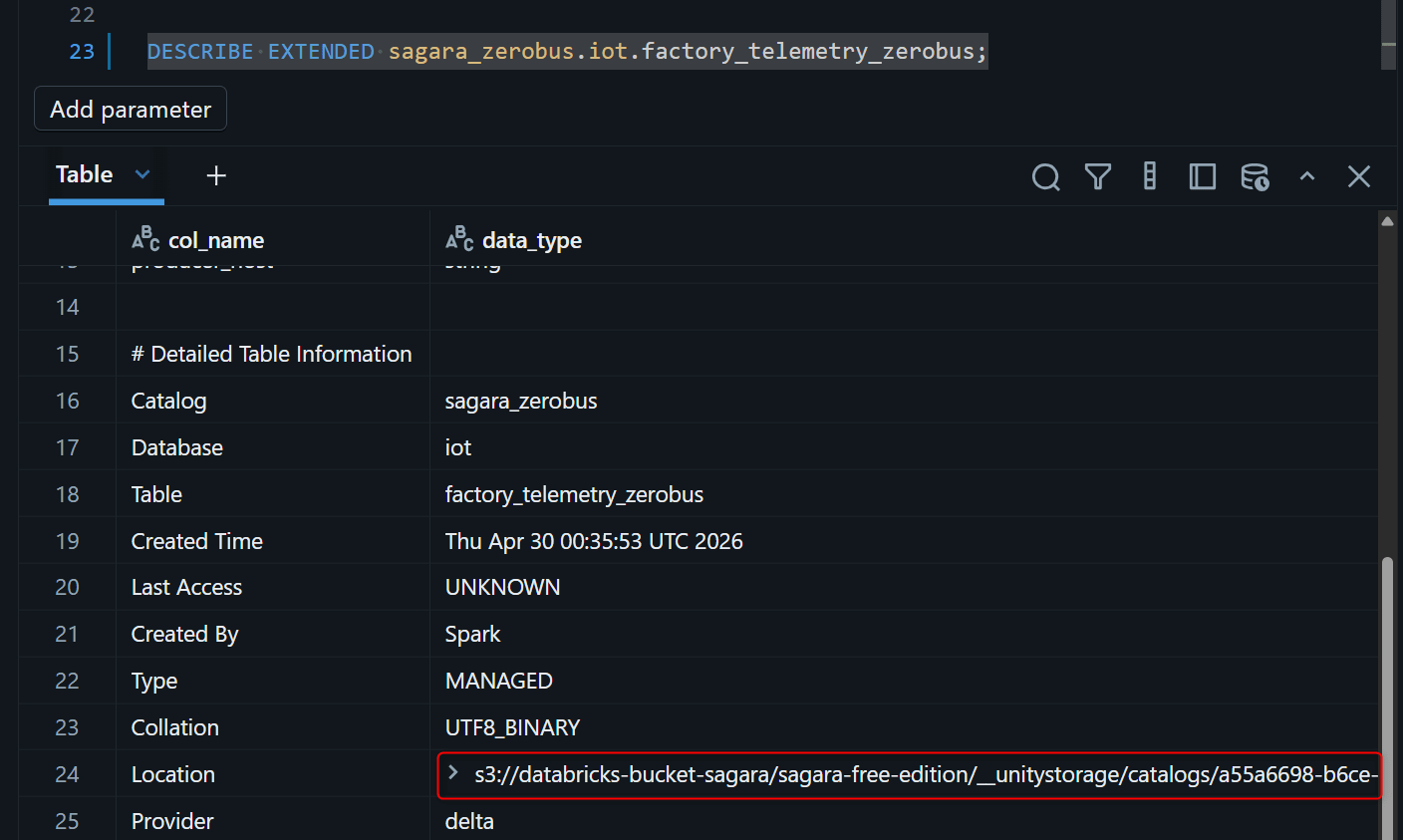
作成できたら、DESCRIBE EXTENDEDで確認しておきます。LocationがS3のパス(s3://databricks-bucket-sagara/sagara-free-edition/...)になっていればOKです。
DESCRIBE EXTENDED sagara_zerobus.iot.factory_telemetry_zerobus;
サービスプリンシパルを作成する
Databricks UIで以下のメニューに進みます。
Settings
→ Identity and access
→ Service principals
→ Manage
→ Add service principal
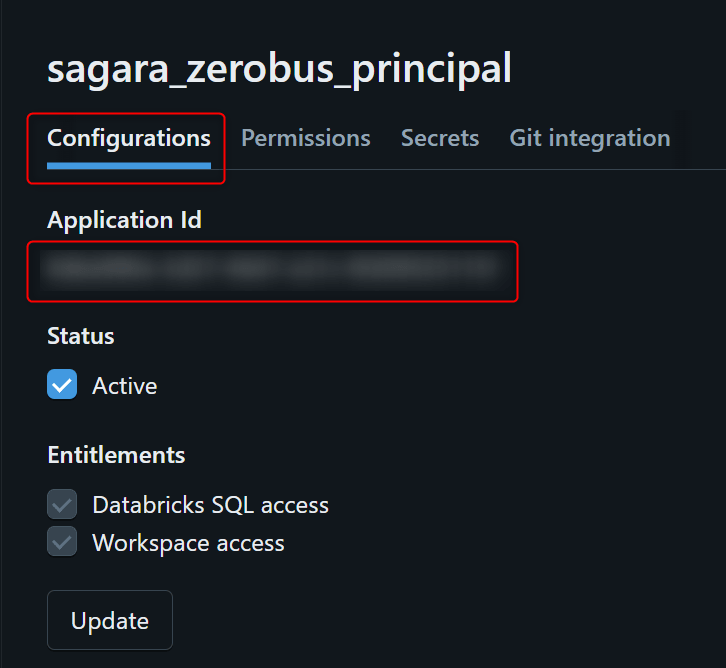
Add newを押して、sagara_zerobus_principalとします。
下図の手順でSecretを生成します。
表示されたSecretとClient IDを控えておきます。
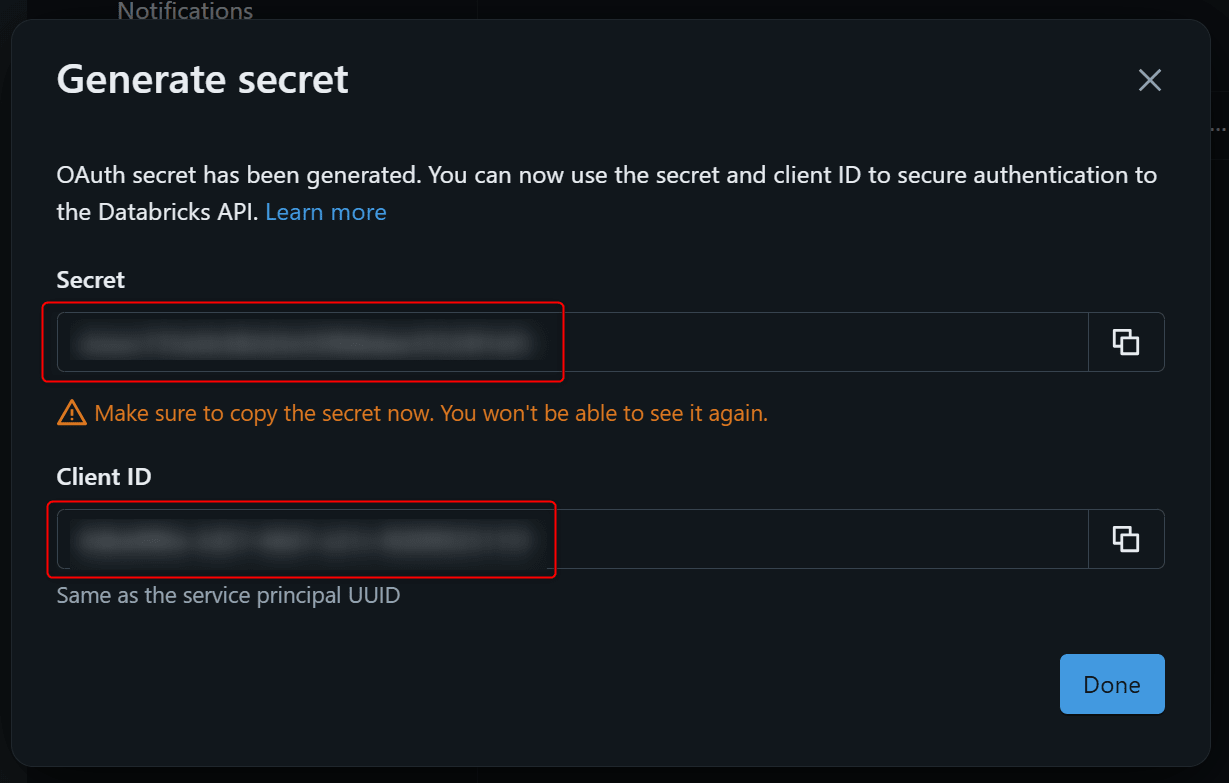
また、ConfigurationsタブからApplicatioon Idも控えます。
サービスプリンシパルに権限を付与する
<SERVICE_PRINCIPAL_APPLICATION_ID>を、サービスプリンシパルのApplicatioon Idに置き換えて以下を実行します。
GRANT USE CATALOG ON CATALOG sagara_zerobus
TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
GRANT USE SCHEMA ON SCHEMA sagara_zerobus.iot
TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
GRANT MODIFY, SELECT
ON TABLE sagara_zerobus.iot.factory_telemetry_zerobus
TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
エラーなく完了すればOKです。
WSL2側のuvプロジェクトを作成する
ここからはWSL2側の作業になります。
uvはPythonの依存関係をpyproject.tomlで管理し、uv initでプロジェクトを作成、uv addで依存追加、uv runで仮想環境込みのコマンド実行ができるツールです。uv runやuv syncを初めて実行すると、プロジェクト直下に.venvとuv.lockが自動で作成されます。
まず必要なOSパッケージを入れます。
sudo apt update
sudo apt install -y curl jq
uvでプロジェクトを作成します。
uv init zerobus-ingest-demo --python 3.12
cd zerobus-ingest-demo
作成後、概ね以下のような構成になっていればOKです。
zerobus-ingest-demo/
├─ .python-version
├─ README.md
├─ main.py
└─ pyproject.toml
依存関係を追加します。
uv add databricks-zerobus-ingest-sdk python-dotenv
databricks-zerobus-ingest-sdkはPython 3.9以上が必要で、JSONとProtocol Buffersをサポートしています。今回はシンプルにJSON形式で進めます。
importできるか確認しておきます。
uv run python --version
uv run python -c "import zerobus; print('zerobus sdk import ok')"
zerobus sdk import okと表示されればOKです。

.envを作成する
プロジェクト直下に.envを作成し、以下の内容にします。Workspace情報・サービスプリンシパル情報・Unity Catalogのターゲット情報をまとめています。 ※今回の検証では.envにsecret情報も記載しているため、本番運用時はご注意ください。
# Databricks workspace
DATABRICKS_WORKSPACE_URL=https://dbc-xxxxxxxx-yyyy.cloud.databricks.com
WORKSPACE_ID=1234567890123456
DATABRICKS_REGION=us-west-2
# Zerobus endpoint
ZEROBUS_ENDPOINT=https://1234567890123456.zerobus.us-west-2.cloud.databricks.com
# Service principal
DATABRICKS_CLIENT_ID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
DATABRICKS_CLIENT_SECRET=xxxxxxxxxxxxxxxxxxxxxxxx
# Unity Catalog target
CATALOG=sagara_zerobus
SCHEMA=iot
TABLE=factory_telemetry_zerobus
TABLE_NAME=sagara_zerobus.iot.factory_telemetry_zerobus
あわせて、.envの権限を絞っておきます。
chmod 600 .env
また、.envは.gitignoreに追記して、Gitに含めないようにしておきます。
# secrets
.env
試してみた
ここから本題のZerobus Ingest検証です。最小構成としてREST APIで1件だけ投入し、その後Python SDK / gRPCで連続投入、最後にDatabricks SQLで集計と重複排除ビューの作成まで進めます。
1. REST APIで1件投入する
最小構成の確認として、まずはREST APIで1件だけ投入します。Zerobus IngestのREST APIでは、/zerobus/v1/tables/<table-name>/insertにHTTP POSTし、Content-Type: application/jsonとAuthorization: Bearer <token>を指定します。
OAuthトークンの取得は、サービスプリンシパルのClient ID / Client Secretと、対象Unity Catalogオブジェクトへの権限情報(authorization_details)を組み合わせる形になります。
プロジェクト直下にrest_insert_once.shを作成し、以下の内容にします。
#!/usr/bin/env bash
set -euo pipefail
source .env
authorization_details=$(cat <<JSON
[{
"type": "unity_catalog_privileges",
"privileges": ["USE CATALOG"],
"object_type": "CATALOG",
"object_full_path": "$CATALOG"
},
{
"type": "unity_catalog_privileges",
"privileges": ["USE SCHEMA"],
"object_type": "SCHEMA",
"object_full_path": "$CATALOG.$SCHEMA"
},
{
"type": "unity_catalog_privileges",
"privileges": ["SELECT", "MODIFY"],
"object_type": "TABLE",
"object_full_path": "$CATALOG.$SCHEMA.$TABLE"
}]
JSON
)
echo "Getting OAuth token..."
OAUTH_RESPONSE=$(curl -s -X POST \
-u "$DATABRICKS_CLIENT_ID:$DATABRICKS_CLIENT_SECRET" \
-d "grant_type=client_credentials" \
-d "scope=all-apis" \
-d "resource=api://databricks/workspaces/$WORKSPACE_ID/zerobusDirectWriteApi" \
--data-urlencode "authorization_details=$authorization_details" \
"$DATABRICKS_WORKSPACE_URL/oidc/v1/token")
OAUTH_TOKEN=$(echo "$OAUTH_RESPONSE" | jq -r '.access_token')
if [ "$OAUTH_TOKEN" = "null" ] || [ -z "$OAUTH_TOKEN" ]; then
echo "Failed to get OAuth token."
echo "$OAUTH_RESPONSE" | jq .
exit 1
fi
now_ms=$(date +%s%3N)
event_id=$(uv run python - <<'PY'
import uuid
print(uuid.uuid4())
PY
)
payload=$(cat <<JSON
[{
"event_id": "$event_id",
"line_id": "line-a",
"device_id": "wsl-sensor-001",
"seq": 1,
"observed_at_ms": $now_ms,
"sent_at_ms": $now_ms,
"temp_c": 31.5,
"humidity_pct": 62.0,
"motor_rpm": 1450,
"power_kw": 3.2,
"status": "normal",
"source": "wsl2-rest-uv",
"producer_host": "$(hostname)"
}]
JSON
)
echo "Posting record to Zerobus Ingest..."
echo "Target: $CATALOG.$SCHEMA.$TABLE"
curl -i -X POST \
"$ZEROBUS_ENDPOINT/zerobus/v1/tables/$CATALOG.$SCHEMA.$TABLE/insert" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OAUTH_TOKEN" \
-d "$payload"
echo
作成したら、実行権限を付けておきます。
chmod +x rest_insert_once.sh
実行します。
./rest_insert_once.sh
成功すると、HTTP 200が返ります。
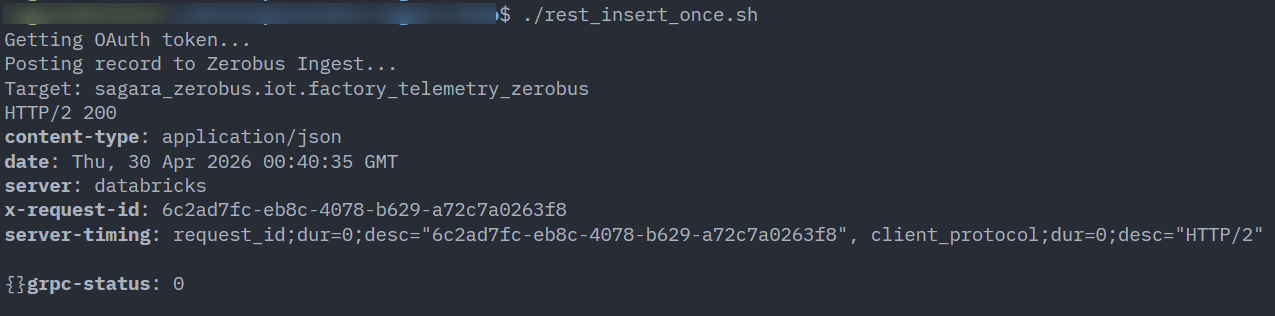
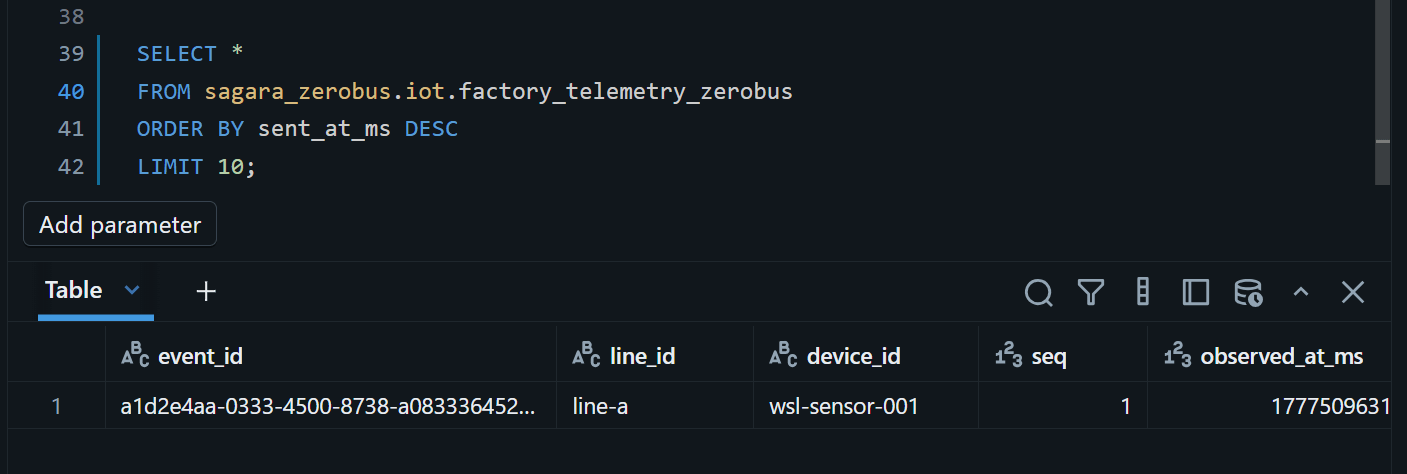
Databricks SQL側で確認します。
SELECT *
FROM sagara_zerobus.iot.factory_telemetry_zerobus
ORDER BY sent_at_ms DESC
LIMIT 10;
投入したレコードが1件返ってくればOKです。前述の通り、Deltaテーブルへの具体化はP50で5秒・P95で30秒程度とされているため、すぐに見えない場合は少し待ってから再度クエリを実行してみてください。
2. Python SDK / gRPCで連続投入する
REST APIで1件投入が成功したら、次はPython SDK / gRPCで連続投入を試します。公式ドキュメントでは、大容量ストリームにはgRPC、低頻度な多数のエッジデバイスにはREST、OpenTelemetry計測済み環境にはOTLPという使い分けが説明されています。今回はgRPCで進めます。
プロジェクト直下にproducer_grpc.pyを作成し、以下の内容にします。通常時は25〜33℃、たまにwarning/criticalの高温イベントを混ぜる構成にしています。
`producer_grpc.py`の全文(クリックで展開)
import os
import time
import uuid
import random
import socket
import argparse
import logging
from dotenv import load_dotenv
from zerobus.sdk.sync import ZerobusSdk
from zerobus.sdk.shared import RecordType, StreamConfigurationOptions, TableProperties
load_dotenv()
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
SERVER_ENDPOINT = os.environ["ZEROBUS_ENDPOINT"]
DATABRICKS_WORKSPACE_URL = os.environ["DATABRICKS_WORKSPACE_URL"]
TABLE_NAME = os.environ["TABLE_NAME"]
CLIENT_ID = os.environ["DATABRICKS_CLIENT_ID"]
CLIENT_SECRET = os.environ["DATABRICKS_CLIENT_SECRET"]
HOSTNAME = socket.gethostname()
def build_record(device_id: str, line_id: str, seq: int) -> dict:
observed_at_ms = int(time.time() * 1000)
# 通常時は 25〜33℃、時々 warning / critical を発生させる
r = random.random()
if r < 0.05:
temp_c = round(random.uniform(37.0, 42.0), 2)
status = "critical"
elif r < 0.20:
temp_c = round(random.uniform(33.0, 37.0), 2)
status = "warning"
else:
temp_c = round(random.uniform(25.0, 33.0), 2)
status = "normal"
humidity_pct = round(random.uniform(45.0, 75.0), 2)
motor_rpm = random.randint(1200, 1800)
power_kw = round(random.uniform(2.5, 5.5), 2)
sent_at_ms = int(time.time() * 1000)
return {
"event_id": str(uuid.uuid4()),
"line_id": line_id,
"device_id": device_id,
"seq": seq,
"observed_at_ms": observed_at_ms,
"sent_at_ms": sent_at_ms,
"temp_c": temp_c,
"humidity_pct": humidity_pct,
"motor_rpm": motor_rpm,
"power_kw": power_kw,
"status": status,
"source": "wsl2-grpc-uv",
"producer_host": HOSTNAME,
}
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--devices", type=int, default=5)
parser.add_argument("--seconds", type=int, default=60)
parser.add_argument("--interval", type=float, default=1.0)
parser.add_argument("--wait-each", action="store_true")
args = parser.parse_args()
logging.info("server_endpoint=%s", SERVER_ENDPOINT)
logging.info("workspace_url=%s", DATABRICKS_WORKSPACE_URL)
logging.info("table_name=%s", TABLE_NAME)
sdk = ZerobusSdk(
SERVER_ENDPOINT,
DATABRICKS_WORKSPACE_URL
)
table_properties = TableProperties(TABLE_NAME)
options = StreamConfigurationOptions(record_type=RecordType.JSON)
stream = sdk.create_stream(
CLIENT_ID,
CLIENT_SECRET,
table_properties,
options
)
logging.info("Zerobus stream opened")
seq_by_device = {
f"wsl-sensor-{i:03d}": 0
for i in range(1, args.devices + 1)
}
start = time.time()
sent_count = 0
last_offset = None
ack_latencies_ms = []
try:
while time.time() - start < args.seconds:
for device_id in seq_by_device.keys():
seq_by_device[device_id] += 1
record = build_record(
device_id=device_id,
line_id="line-a",
seq=seq_by_device[device_id]
)
t0 = time.time()
offset = stream.ingest_record_offset(record)
last_offset = offset
if args.wait_each:
stream.wait_for_offset(offset)
ack_latency_ms = (time.time() - t0) * 1000
ack_latencies_ms.append(ack_latency_ms)
sent_count += 1
logging.info("sent_count=%s", sent_count)
time.sleep(args.interval)
if last_offset is not None and not args.wait_each:
logging.info("waiting for last offset...")
stream.wait_for_offset(last_offset)
finally:
stream.close()
logging.info("Zerobus stream closed")
if ack_latencies_ms:
ack_latencies_ms.sort()
p50 = ack_latencies_ms[int(len(ack_latencies_ms) * 0.50)]
p95_index = max(int(len(ack_latencies_ms) * 0.95) - 1, 0)
p95 = ack_latencies_ms[p95_index]
logging.info("ack_latency_ms p50=%.2f p95=%.2f", p50, p95)
logging.info("total sent_count=%s", sent_count)
if __name__ == "__main__":
main()
SDKの基本的な流れは、ZerobusSdkを作り、TablePropertiesとStreamConfigurationOptionsを指定してストリームを開き、ingest_record_offsetで送信し、必要に応じてwait_for_offsetで確認を待つ形です。
最初は小さめのパラメータで流します。
uv run python producer_grpc.py \
--devices 5 \
--seconds 60 \
--interval 1.0 \
--wait-each
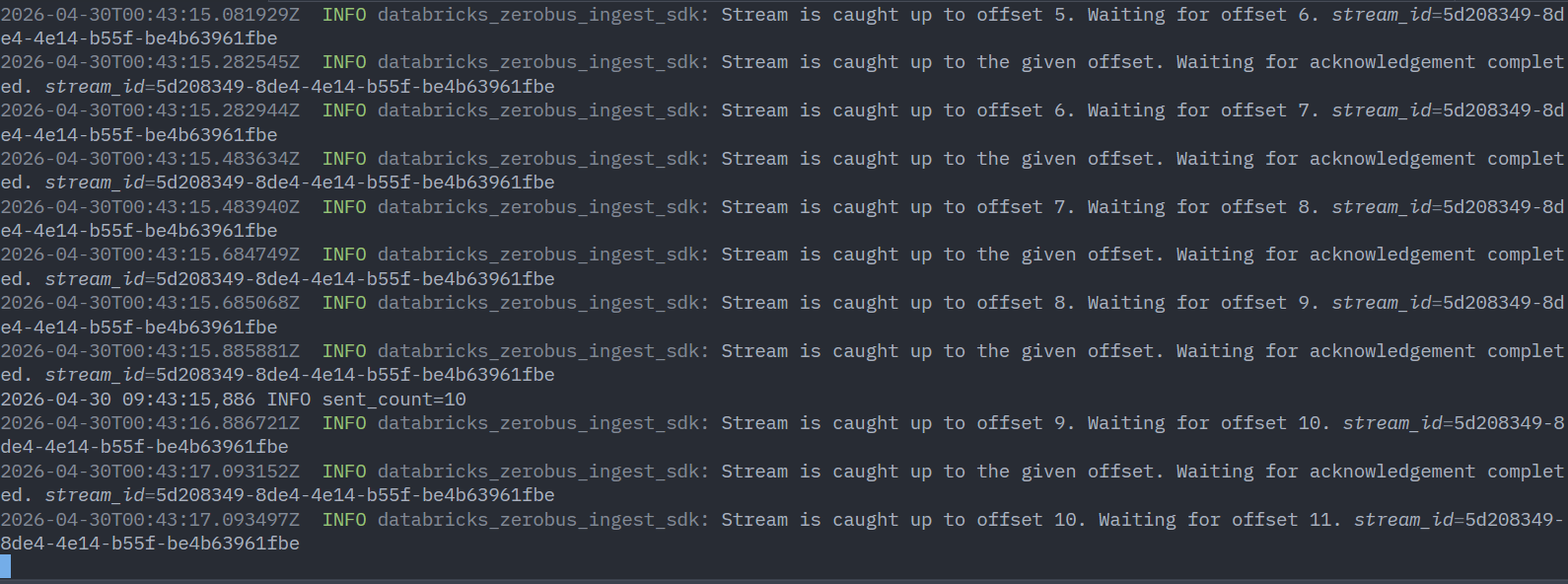
実行ログとして、Zerobus stream opened → sent_count=... → Zerobus stream closedの順で出力され、最後にack_latency_ms p50=... p95=...が表示されればOKです。--wait-eachを付けているので、各送信のack待ち時間がp50 / p95で簡易計測されます。
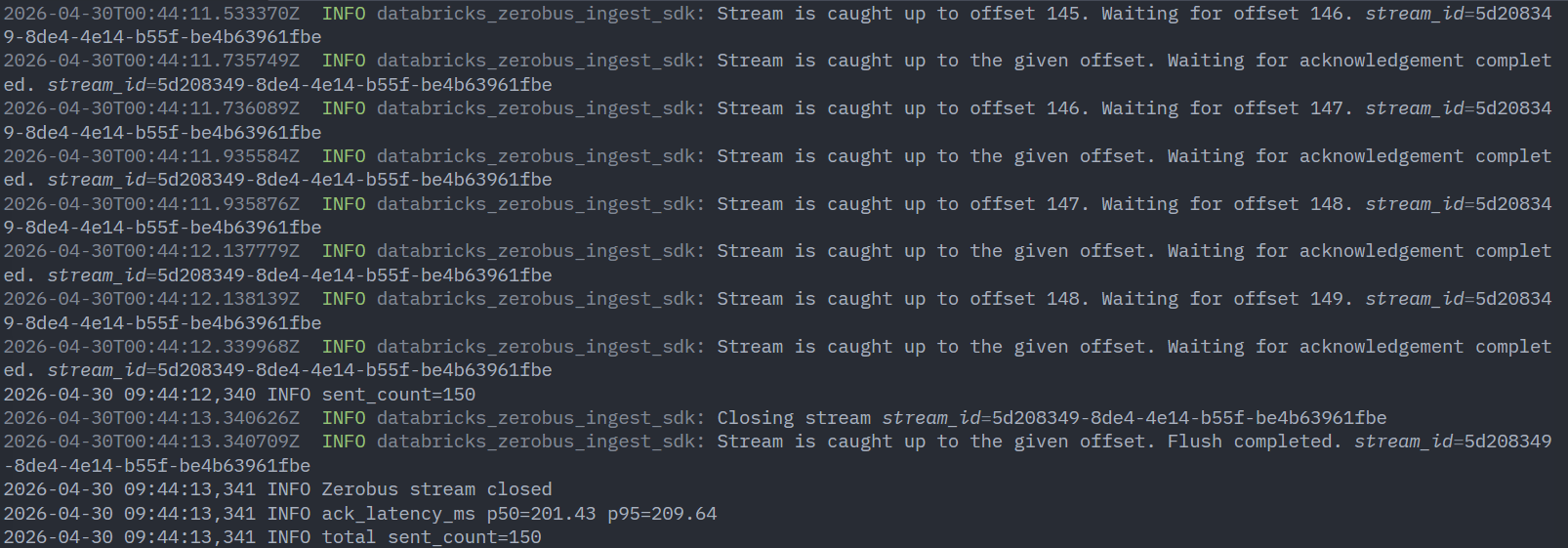
3. 連続投入中にロード状況をリアルタイムで確認する
producer_grpc.pyを実行している最中に、Databricks側から対象テーブルに対して集計クエリを繰り返し実行することで、Zerobus Ingest経由でレコードが継続的にロードされていく様子をリアルタイムに観察できます。
WSL2側でやや長めのパラメータでスクリプトを起動しておきます。今回は2分間流す形にしてみます。
uv run python producer_grpc.py \
--devices 5 \
--seconds 120 \
--interval 1.0 \
--wait-each
スクリプトが動いている間に、Databricks SQL Editorで以下のクエリを開いておき、数秒おきにRunボタンを押して件数の推移を観察します。
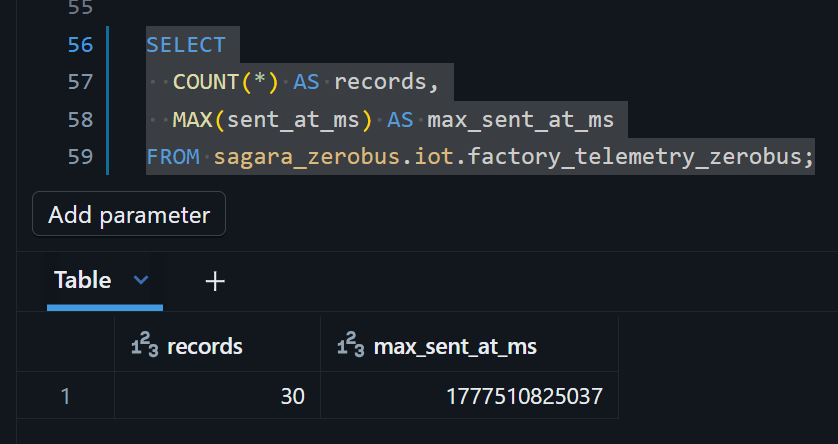
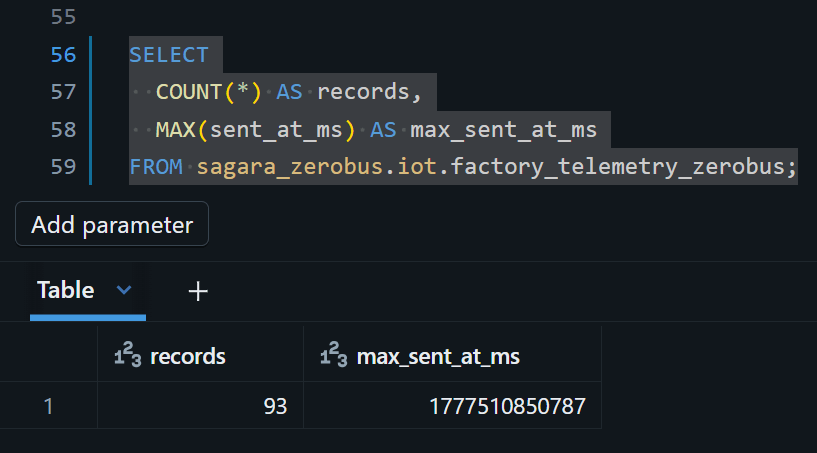
SELECT
COUNT(*) AS records,
MAX(sent_at_ms) AS max_sent_at_ms
FROM sagara_zerobus.iot.factory_telemetry_zerobus;
producer_grpc.pyが動いている間は、Runを押すたびにrecordsの値が増え続け、max_sent_at_msも進んでいく様子が見えるはずです。
4. 重複排除ビューを作成する
Zerobus Ingestはat-least-onceの配送保証のため、再送や障害時に同じイベントが重複して届く可能性があります。event_idをキーに重複排除するビューを作っておくと、後段の分析クエリで安心して使えます。
CREATE OR REPLACE VIEW sagara_zerobus.iot.factory_telemetry_zerobus_dedup AS
WITH ranked AS (
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY event_id
ORDER BY sent_at_ms DESC
) AS rn
FROM sagara_zerobus.iot.factory_telemetry_zerobus
)
SELECT
event_id,
line_id,
device_id,
seq,
observed_at_ms,
sent_at_ms,
temp_c,
humidity_pct,
motor_rpm,
power_kw,
status,
source,
producer_host
FROM ranked
WHERE rn = 1;
5. 工場監視に使えそうな分析クエリを試す
先ほど作成した重複排除ビューに対して、工場監視ライクなクエリを試してみます。
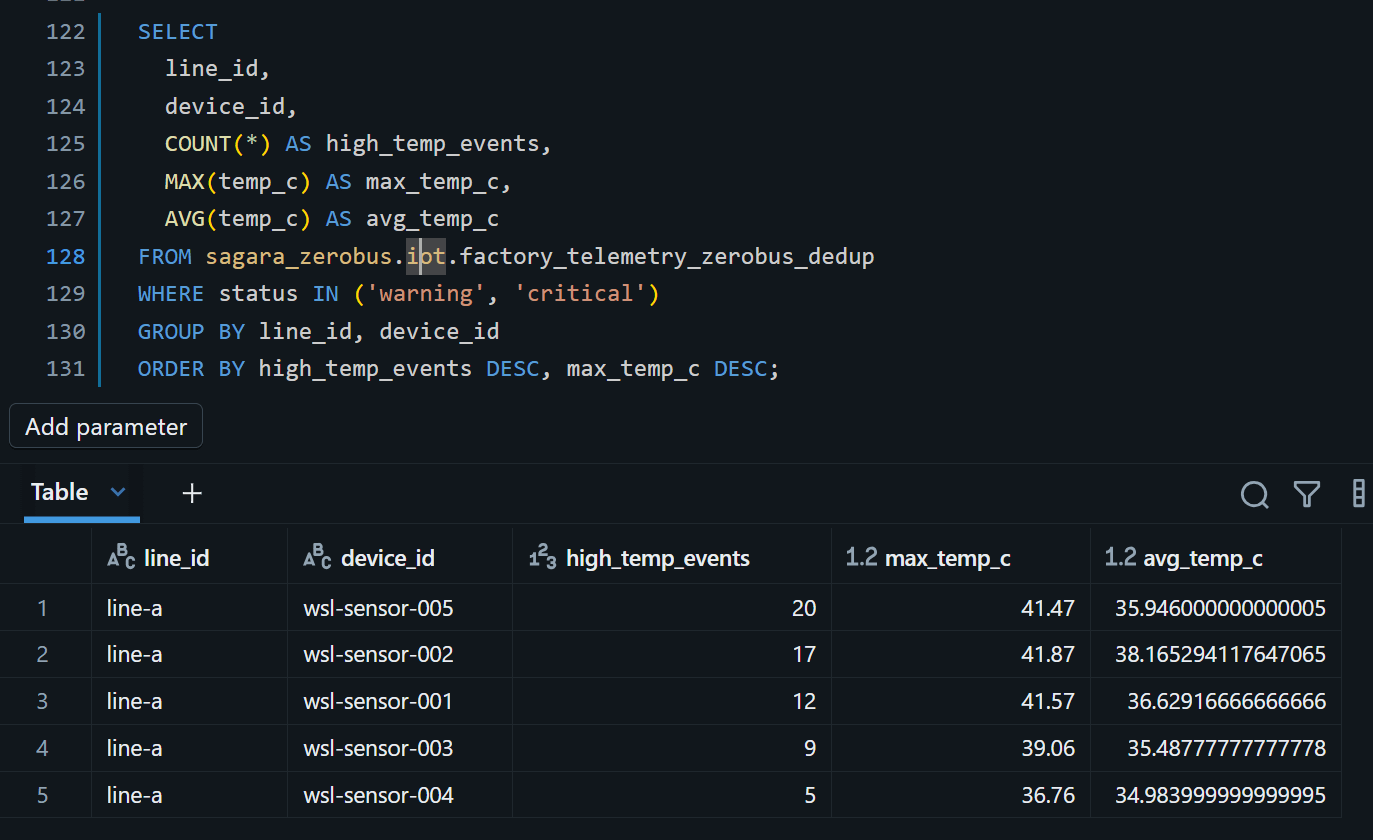
- 高温設備ランキング
SELECT
line_id,
device_id,
COUNT(*) AS high_temp_events,
MAX(temp_c) AS max_temp_c,
AVG(temp_c) AS avg_temp_c
FROM sagara_zerobus.iot.factory_telemetry_zerobus_dedup
WHERE status IN ('warning', 'critical')
GROUP BY line_id, device_id
ORDER BY high_temp_events DESC, max_temp_c DESC;
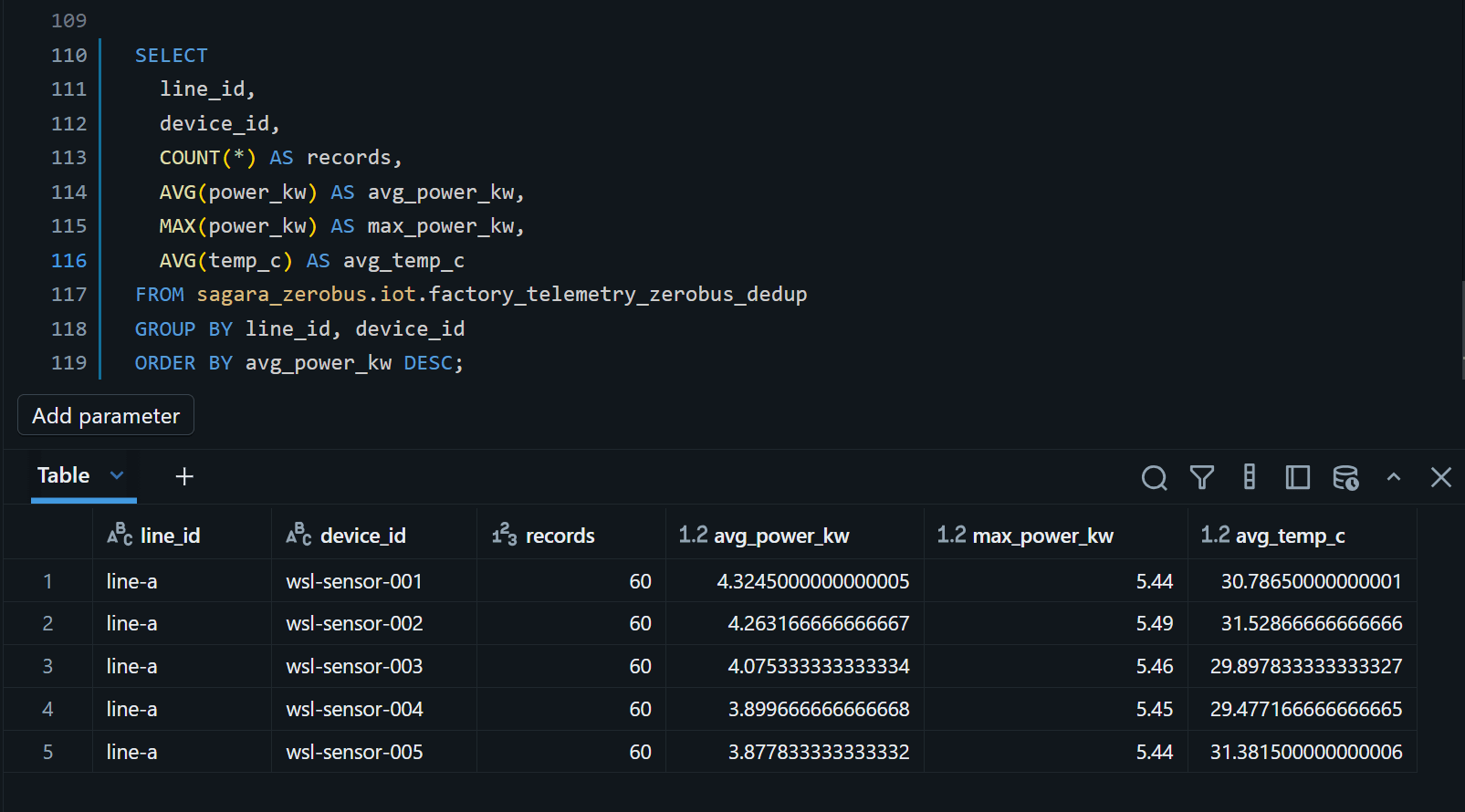
- 電力消費が高い設備の確認
SELECT
line_id,
device_id,
COUNT(*) AS records,
AVG(power_kw) AS avg_power_kw,
MAX(power_kw) AS max_power_kw,
AVG(temp_c) AS avg_temp_c
FROM sagara_zerobus.iot.factory_telemetry_zerobus_dedup
GROUP BY line_id, device_id
ORDER BY avg_power_kw DESC;
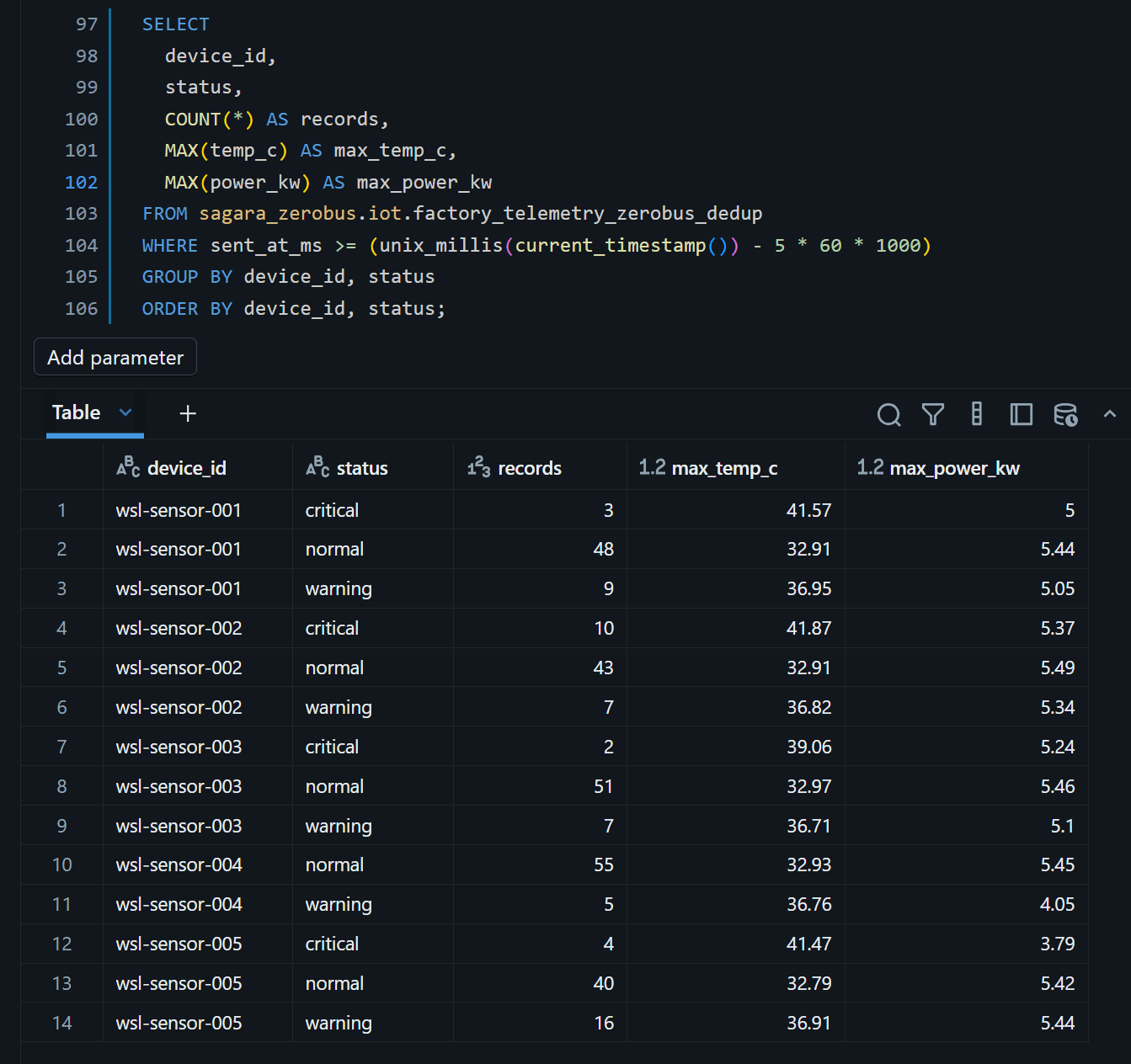
- 直近5分のステータス別状態
SELECT
device_id,
status,
COUNT(*) AS records,
MAX(temp_c) AS max_temp_c,
MAX(power_kw) AS max_power_kw
FROM sagara_zerobus.iot.factory_telemetry_zerobus_dedup
WHERE sent_at_ms >= (unix_millis(current_timestamp()) - 5 * 60 * 1000)
GROUP BY device_id, status
ORDER BY device_id, status;
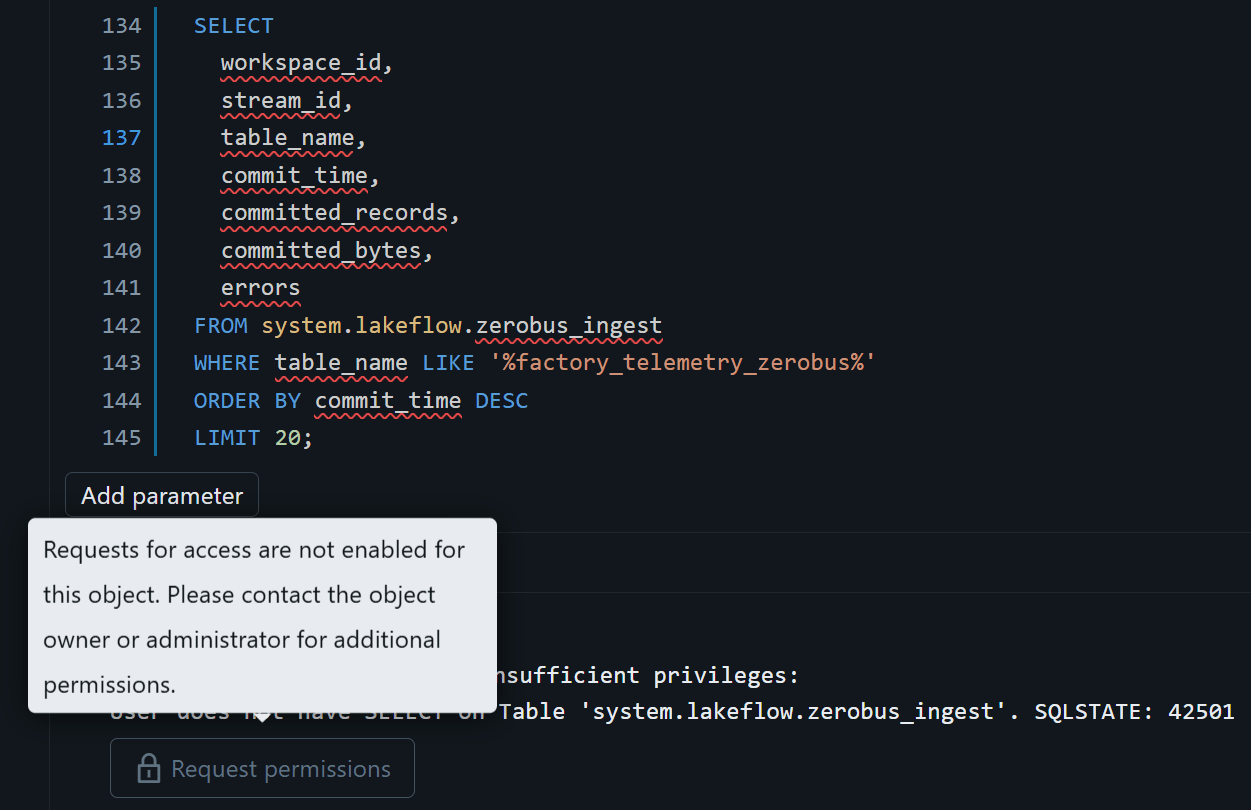
6. Zerobus Ingestのシステムテーブル確認
通常のDatabricks環境であれば、Zerobus Ingestの使用状況はsystem.lakeflow.zerobus_streamおよびsystem.lakeflow.zerobus_ingestのシステムテーブルで監視できます。参照できる環境では、以下のようなクエリでストリームのopen/closeや、コミットされたレコード数・バイト数を確認できます。
SELECT
workspace_id,
stream_id,
table_name,
opened_time,
closed_time,
errors
FROM system.lakeflow.zerobus_stream
WHERE table_name LIKE '%factory_telemetry_zerobus%'
ORDER BY opened_time DESC
LIMIT 20;
SELECT
workspace_id,
stream_id,
table_name,
commit_time,
committed_records,
committed_bytes,
errors
FROM system.lakeflow.zerobus_ingest
WHERE table_name LIKE '%factory_telemetry_zerobus%'
ORDER BY commit_time DESC
LIMIT 20;
ただし、本記事の検証環境であるDatabricks Free Editionでは、これらのシステムテーブルを参照することができませんでした。そのため、本記事ではシステムテーブルでの確認はスキップしています。
※下図のように、エラーが出ました。
通常のDatabricksワークスペースで本格的に運用する場合は、上記のシステムテーブルでストリームの稼働状況やコミット状況を継続監視するのがよいでしょう。
最後に
ローカル(WSL2)上の疑似工場センサーデータをZerobus Ingest経由でDatabricksに流し、Unity Catalog上で集計するところまで試してみました。
Zerobus Ingestが気になっている方の参考になれば幸いです。










