
ローカルから疑似工場センサーデータを流してSnowpipe Streamingを試してみた
さがらです。
SnowflakeのSnowpipe Streamingについて、High Performance Architectureが提供されており、Java / Python SDKやREST API経由で行単位のデータをほぼリアルタイムにSnowflakeテーブルへ取り込めるようになっています。Snowflake管理のApache Icebergテーブル(v2/v3)への取り込みも対応し、チャネルとoffset token trackingによるExactly-onceデリバリーが保証されています。
少し前に、DatabricksのZerobus IngestをローカルWSL2の疑似工場センサーデータで試した記事を書いたのですが、ほぼ同じことをSnowflake側でもやってみたいと思い、Snowpipe Streaming(High Performance)で試してみました。本記事ではその手順と確認結果をまとめます。
参考までに、Databricks Zerobus Ingest版の記事はこちらです。
機能概要
Snowpipe Streaming(High Performance Architecture)は、Snowflakeテーブルへ行単位のデータをサーバーレスで直接ストリーミング取り込みできる仕組みです。チャネルとoffset tokenによりExactly-onceの配送保証とチャネル内の順序保証を実現しています。なお、旧来のクラシックアーキテクチャ(snowflake-ingest-sdk Java SDK)は廃止予定が告知されており、現在のHigh Performance SDKへの移行が推奨されています。
主な特徴は以下の通りです。
- スループット: テーブルあたり最大10 GB/秒
- レイテンシ: 取り込みからクエリまでEnd-to-Endで最短5秒
- 配送保証: Exactly-onceデリバリー(offset token trackingにより実現)
- 対応SDK: Java 11+ / Python 3.9+(どちらもRustベースのクライアントコアを採用)
- REST API: 軽量連携用のエンドポイントも提供(チャネルあたり1 MBps / リクエストあたり最大4 MB / 10 RPS)
- Icebergテーブル: Snowflake管理のApache Iceberg v2/v3テーブルへの取り込みに対応
データの流れとしては、SDK / REST API → チャネル(offset token管理)→ PIPEオブジェクト(サーバ側でスキーマ検証・変換)→ ターゲットテーブル → (任意で)Dynamic Table等でマート化、という構成になります。
制限事項
2026年5月1日時点で、公式Docに記載のある主な制限事項は以下の通りです。
- Icebergテーブルへの書き込みはSnowflake管理のv2/v3のみ対応(パーティション付きIcebergテーブルは非対応)
- スキーマ進化は標準Snowflakeテーブルのみ対応(External Table / Iceberg Tableは非対応)
- スキーマ進化において構造化型(Structured Types)は非対応(新規カラムはVARIANTとして推論される)
- Default PIPEは変換・事前クラスタリングが不可(必要な場合はCustom PIPEを手動でCREATE)
- INSERT操作のみ対応(UPDATE / DELETE / MERGEは不可)
- Snowpark Container Services(SPCS)上からの利用は非対応
- アカウントあたり最大1,000 PIPEオブジェクト、パイプあたりデフォルト最大2,000アクティブチャネル、テーブルあたり最大10パイプ
コスト
Snowpipe Streaming High Performanceは非圧縮GBあたりのフラットレートで課金されます。課金対象はデータ値のバイト数であり、JSONキー部分は含まれません(レートはSnowflake Consumption Tableを参照)。例として1 MB/秒の非圧縮データを連続投入した場合、1時間あたり3.6 GBのデータ量になります。利用状況は以下のクエリで確認できます。
SELECT * FROM snowflake.account_usage.metering_history
WHERE service_type = 'SNOWPIPE_STREAMING';
前提条件
今回の検証環境は以下です。
- Snowflake: AWS東京リージョン(
ap-northeast-1)、Enterpriseエディション - Snowflakeデータベース:
SAGARA_SNOWPIPE_DB - スキーマ:
IOT - ターゲットテーブル:
SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING - 認証: サービスアカウントユーザー(
SAGARA_STREAMING_USER)+ Key Pair認証 - ローカル環境: WSL2上のUbuntu 24.04 LTS
- Python環境管理:
uv
事前準備
検証の流れとして、まずSnowflake側でDB / Schema / Table / サービスアカウントユーザーを準備し、その後WSL2側でuvプロジェクト・Key Pair・接続用設定を準備する形にします。
Snowflakeアカウント情報を確認する
SnowsightにログインしてアカウントIdentifierを確認します。左下のアカウント名をクリックし、Connect a tool to Snowflakeで確認できます。
SNOWFLAKE_ACCOUNT=<orgname>-<account_name>
SNOWFLAKE_HOST=<orgname>-<account_name>.snowflakecomputing.com
データベース・スキーマ・テーブルを作成する
Snowsight の SQL WorksheetでACCOUNTADMINロールを使い、検証用のDB / Schema / Tableを作成します。
USE ROLE ACCOUNTADMIN;
CREATE DATABASE IF NOT EXISTS SAGARA_SNOWPIPE_DB;
CREATE SCHEMA IF NOT EXISTS SAGARA_SNOWPIPE_DB.IOT;
ターゲットテーブルとして、温度・湿度・設備状態・電力・モーター回転数を持つ疑似工場テレメトリのテーブルを作成します。
CREATE TABLE IF NOT EXISTS SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING (
EVENT_ID STRING,
LINE_ID STRING,
DEVICE_ID STRING,
SEQ NUMBER,
OBSERVED_AT_MS NUMBER,
SENT_AT_MS NUMBER,
TEMP_C FLOAT,
HUMIDITY_PCT FLOAT,
MOTOR_RPM NUMBER,
POWER_KW FLOAT,
STATUS STRING,
SOURCE STRING,
PRODUCER_HOST STRING
);
作成されたテーブルの確認をします。
DESC TABLE SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING;
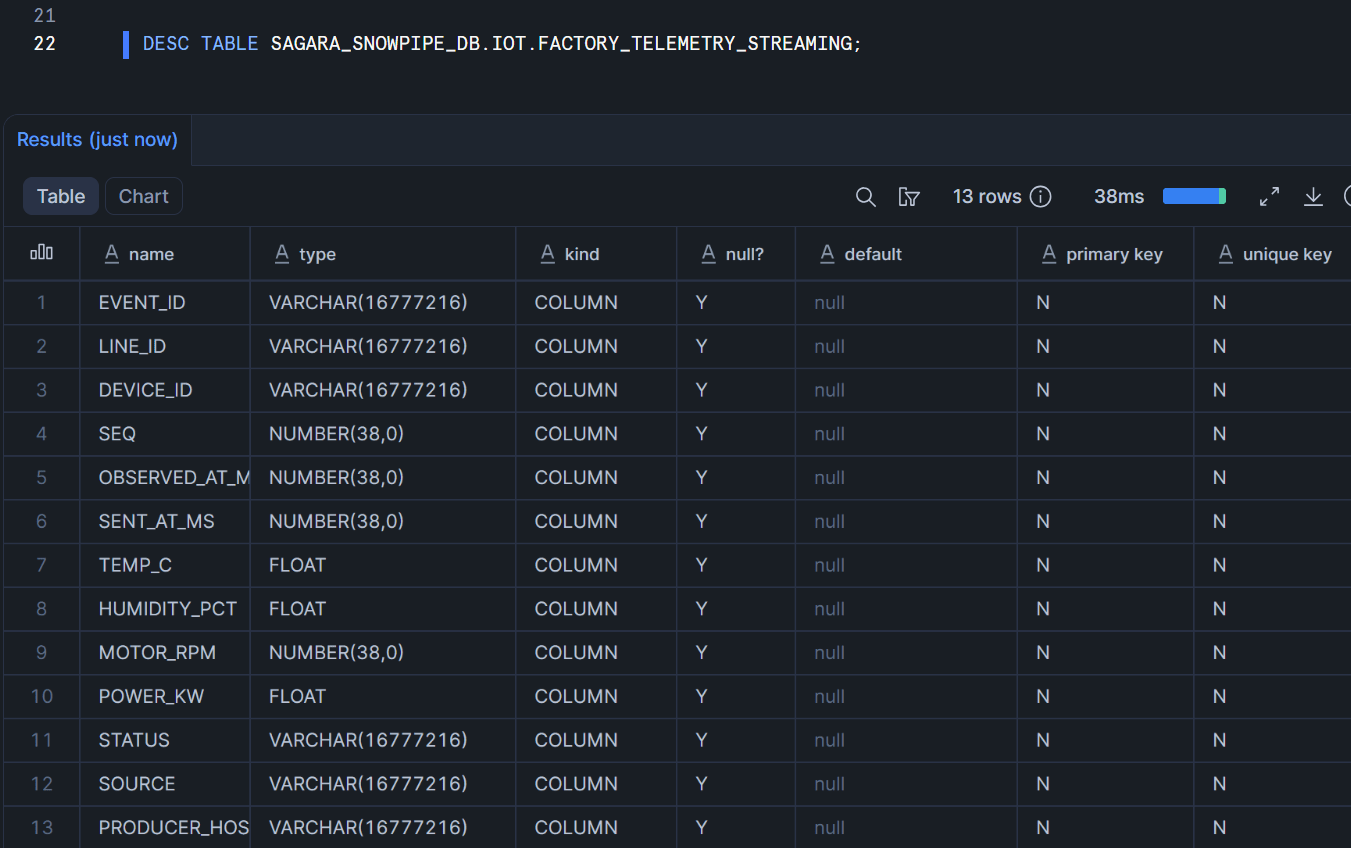
なお、Snowpipe Streaming High Performanceでは、テーブル作成後の最初のチャネル接続時にFACTORY_TELEMETRY_STREAMING-STREAMINGという名前でDefault PIPEがオンデマンドで自動作成されます。今回はCOPY INTO文でのデータ変換(in-flight変換)は不要なので、明示的なCREATE PIPEは行わずDefault PIPEに任せます。
検証用のロール・サービスアカウントユーザーを作成する
Snowpipe Streamingからの書き込み用に、専用ロールとサービスアカウントユーザーを作ります。Key Pair認証用にRSA公開鍵を後ほど登録するため、ユーザー作成時にはTYPE = SERVICEにしておきます。
USE ROLE ACCOUNTADMIN;
CREATE ROLE IF NOT EXISTS SAGARA_STREAMING_ROLE;
CREATE WAREHOUSE SAGARA_WH WITH WAREHOUSE_SIZE = XSMALL;
GRANT USAGE ON WAREHOUSE SAGARA_WH TO ROLE SAGARA_STREAMING_ROLE;
GRANT USAGE ON DATABASE SAGARA_SNOWPIPE_DB TO ROLE SAGARA_STREAMING_ROLE;
GRANT USAGE ON SCHEMA SAGARA_SNOWPIPE_DB.IOT TO ROLE SAGARA_STREAMING_ROLE;
GRANT INSERT, SELECT ON TABLE SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING
TO ROLE SAGARA_STREAMING_ROLE;
CREATE USER IF NOT EXISTS SAGARA_STREAMING_USER
TYPE = SERVICE
DEFAULT_ROLE = SAGARA_STREAMING_ROLE
DEFAULT_WAREHOUSE = SAGARA_WH;
GRANT ROLE SAGARA_STREAMING_ROLE TO USER SAGARA_STREAMING_USER;
Key Pair認証用のRSA鍵を作成する
WSL2側で以下を実行し、RSA秘密鍵 / 公開鍵を作成します。
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out rsa_key.p8 -nocrypt
openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub
併せて権限も絞ります。
chmod 600 rsa_key.p8
公開鍵の内容を取り出します。
cat rsa_key.pub
-----BEGIN PUBLIC KEY-----と-----END PUBLIC KEY-----に挟まれたBase64の中身だけをコピーし、Snowsightで以下を実行してユーザーに登録します。
USE ROLE ACCOUNTADMIN;
ALTER USER SAGARA_STREAMING_USER SET RSA_PUBLIC_KEY='<上で取り出したBase64の文字列>';
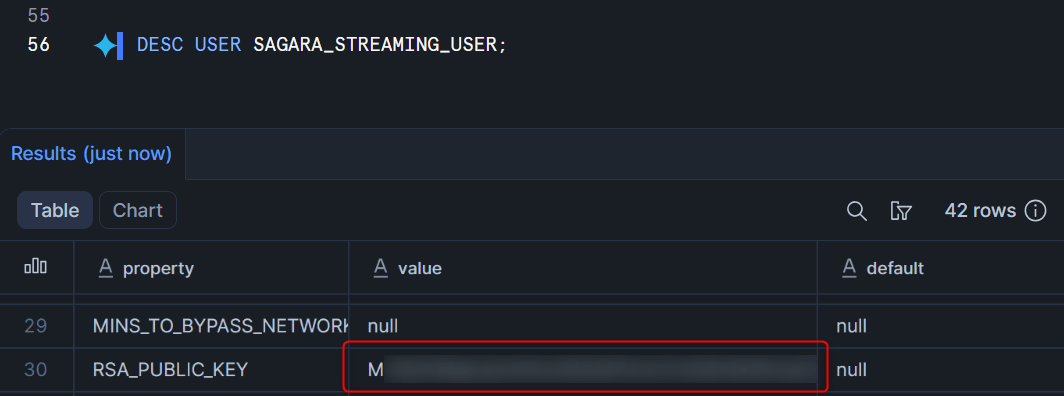
設定後、登録できたか以下で確認します。RSA_PUBLIC_KEY_FPの値が表示されていればOKです。
DESC USER SAGARA_STREAMING_USER;
WSL2側のuvプロジェクトを作成する
ここからはWSL2側の作業になります。
uvはPythonの依存関係をpyproject.tomlで管理し、uv initでプロジェクトを作成、uv addで依存追加、uv runで仮想環境込みのコマンド実行ができるツールです。
まず必要なOSパッケージを入れます。
sudo apt update
sudo apt install -y curl jq openssl
uvでプロジェクトを作成します。
uv init snowpipe-streaming-demo --python 3.12
cd snowpipe-streaming-demo
依存関係を追加します。Snowpipe Streaming High Performance用のSDKと、JWT生成に使うパッケージを入れておきます。
uv add snowpipe-streaming pyjwt cryptography
importできるか確認しておきます。
uv run python --version
uv run python -c "from snowflake.ingest.streaming import StreamingIngestClient; print('snowpipe streaming sdk import ok')"
snowpipe streaming sdk import okと表示されればOKです。(SDKのログも併せて表示されますが、問題ありません。)
接続設定ファイル profile.json を作成する
接続情報・認証設定・対象オブジェクトをすべてprofile.jsonに一元管理します。※今回の検証ではローカルファイルでsecret情報を扱っているため、本番運用時はご注意ください。
{
"user": "SAGARA_STREAMING_USER",
"account": "<orgname>-<account_name>",
"url": "https://<orgname>-<account_name>.snowflakecomputing.com:443",
"private_key_file": "<rsa_key.p8へのパス>",
"role": "SAGARA_STREAMING_ROLE",
"database": "SAGARA_SNOWPIPE_DB",
"schema": "IOT",
"table": "FACTORY_TELEMETRY_STREAMING"
}
.gitignoreに追記して、Gitに含めないようにします。
# secrets
profile.json
試してみた
ここから本題のSnowpipe Streaming検証です。最小構成としてREST APIで1件だけ投入し、その後Python SDKで連続投入、最後にDynamic Tableで重複排除マートと工場監視マートを作成するところまで進めます。
1. REST APIで1件投入する
最小構成の確認として、まずはREST API(JWT認証)で1件だけ投入します。
公式チュートリアルとして、cURL + JWTでのSnowpipe Streaming High Performance利用手順が公開されています。
JWT生成を簡略化するために、Pythonワンショットスクリプトを噛ませる構成にします。プロジェクト直下にrest_insert_once.shを作成し、以下の内容にします。
#!/usr/bin/env bash
set -euo pipefail
PROFILE_JSON="profile.json"
SF_ACCOUNT=$(jq -r '.account' "$PROFILE_JSON")
SF_CONTROL_HOST="${SF_ACCOUNT}.snowflakecomputing.com"
SF_DATABASE=$(jq -r '.database' "$PROFILE_JSON")
SF_SCHEMA=$(jq -r '.schema' "$PROFILE_JSON")
SF_TABLE=$(jq -r '.table' "$PROFILE_JSON")
# Default PIPE 名
# 例: FACTORY_TELEMETRY_STREAMING-STREAMING
PIPE_NAME="${SF_TABLE}-STREAMING"
# 既存チャネルを使い回す場合は固定名でOK
CHANNEL_NAME="wsl2-rest-channel-001"
echo "Control host: ${SF_CONTROL_HOST}"
# JSONなら指定フィールドを取り出し、JSONでなければ生文字列として扱う
extract_json_field_or_raw() {
local input="$1"
local jq_expr="$2"
if printf '%s' "$input" | jq -e . >/dev/null 2>&1; then
printf '%s' "$input" | jq -r "$jq_expr"
else
printf '%s' "$input"
fi
}
# JWTを生成
JWT=$(uv run python - "$PROFILE_JSON" <<'PY'
import sys
import json
import time
import jwt
import hashlib
import base64
from cryptography.hazmat.primitives import serialization
with open(sys.argv[1]) as f:
profile = json.load(f)
with open(profile["private_key_file"], "rb") as f:
private_key = serialization.load_pem_private_key(f.read(), password=None)
public_key_der = private_key.public_key().public_bytes(
encoding=serialization.Encoding.DER,
format=serialization.PublicFormat.SubjectPublicKeyInfo,
)
fp = "SHA256:" + base64.b64encode(hashlib.sha256(public_key_der).digest()).decode()
account = profile["account"].upper()
user = profile["user"].upper()
qualified_user = f"{account}.{user}"
now = int(time.time())
payload = {
"iss": f"{qualified_user}.{fp}",
"sub": qualified_user,
"iat": now,
"exp": now + 3600,
}
print(jwt.encode(payload, private_key, algorithm="RS256"))
PY
)
echo "JWT generated"
# 1. Ingest host を取得
INGEST_HOST_RESP=$(curl -sS --fail-with-body -X GET \
"https://${SF_CONTROL_HOST}/v2/streaming/hostname" \
-H "Authorization: Bearer ${JWT}" \
-H "X-Snowflake-Authorization-Token-Type: KEYPAIR_JWT")
# 公式チュートリアルでは生文字列として扱われる一方、APIリファレンス上はJSON形式の記載もあるため両対応
INGEST_HOST=$(extract_json_field_or_raw "$INGEST_HOST_RESP" '.hostname // .')
# 改行除去 + underscore 対策
INGEST_HOST=$(printf '%s' "$INGEST_HOST" | tr -d '\r\n' | sed 's/_/-/g')
echo "Ingest host: ${INGEST_HOST}"
# 2. Scoped token を取得
SCOPED_TOKEN_RESP=$(curl -sS --fail-with-body -X POST \
"https://${SF_CONTROL_HOST}/oauth/token" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Authorization: Bearer ${JWT}" \
-d "grant_type=urn:ietf:params:oauth:grant-type:jwt-bearer&scope=${INGEST_HOST}")
# token / access_token / 生文字列 のどれでも扱えるようにする
SCOPED_TOKEN=$(extract_json_field_or_raw "$SCOPED_TOKEN_RESP" '.token // .access_token // .')
SCOPED_TOKEN=$(printf '%s' "$SCOPED_TOKEN" | tr -d '\r\n')
echo "Scoped token obtained"
# 3. Channel を open
echo "Opening channel: ${SF_DATABASE}.${SF_SCHEMA}.${PIPE_NAME}/${CHANNEL_NAME}"
OPEN_RESP=$(curl -sS --fail-with-body -X PUT \
"https://${INGEST_HOST}/v2/streaming/databases/${SF_DATABASE}/schemas/${SF_SCHEMA}/pipes/${PIPE_NAME}/channels/${CHANNEL_NAME}" \
-H "Authorization: Bearer ${SCOPED_TOKEN}" \
-H "Content-Type: application/json" \
-d '{}')
echo "Open channel response:"
echo "$OPEN_RESP" | jq .
CONT_TOKEN=$(echo "$OPEN_RESP" | jq -r '.next_continuation_token')
if [[ -z "$CONT_TOKEN" || "$CONT_TOKEN" == "null" ]]; then
echo "ERROR: next_continuation_token is empty"
exit 1
fi
LAST_OFFSET=$(echo "$OPEN_RESP" | jq -r '.channel_status.last_committed_offset_token // empty')
# 既存チャネルを使い回す場合、前回 offset が数値なら +1 する
# 初回または空の場合は 1
if [[ "$LAST_OFFSET" =~ ^[0-9]+$ ]]; then
NEW_OFFSET=$((LAST_OFFSET + 1))
else
NEW_OFFSET=1
fi
echo "Last committed offset token: ${LAST_OFFSET:-<empty>}"
echo "New offset token: ${NEW_OFFSET}"
# continuationToken を URL エンコード
CONT_TOKEN_ENC=$(uv run python -c 'import sys, urllib.parse; print(urllib.parse.quote(sys.argv[1], safe=""))' "$CONT_TOKEN")
NOW_MS=$(date +%s%3N)
EVENT_ID=$(uv run python -c "import uuid; print(uuid.uuid4())")
HOSTNAME_VAL=$(hostname)
# 4. NDJSON を作成
# Snowpipe Streaming REST API の Append Rows payload は NDJSON
cat > rows.ndjson <<JSON
{"EVENT_ID":"$EVENT_ID","LINE_ID":"line-a","DEVICE_ID":"wsl-sensor-001","SEQ":1,"OBSERVED_AT_MS":$NOW_MS,"SENT_AT_MS":$NOW_MS,"TEMP_C":31.5,"HUMIDITY_PCT":62.0,"MOTOR_RPM":1450,"POWER_KW":3.2,"STATUS":"normal","SOURCE":"wsl2-rest-uv","PRODUCER_HOST":"$HOSTNAME_VAL"}
JSON
echo "Created rows.ndjson:"
cat rows.ndjson
echo
# 5. Append Rows
echo "Appending row to: ${SF_DATABASE}.${SF_SCHEMA}.${PIPE_NAME}/${CHANNEL_NAME}"
APPEND_RESP=$(curl -sS --fail-with-body -X POST \
"https://${INGEST_HOST}/v2/streaming/data/databases/${SF_DATABASE}/schemas/${SF_SCHEMA}/pipes/${PIPE_NAME}/channels/${CHANNEL_NAME}/rows?continuationToken=${CONT_TOKEN_ENC}&offsetToken=${NEW_OFFSET}" \
-H "Authorization: Bearer ${SCOPED_TOKEN}" \
-H "Content-Type: application/x-ndjson" \
--data-binary @rows.ndjson)
echo "Append rows response:"
echo "$APPEND_RESP" | jq .
echo
echo "Done."
echo "EVENT_ID=${EVENT_ID}"
echo "OffsetToken=${NEW_OFFSET}"
作成したら、実行権限を付けて実行します。
chmod +x rest_insert_once.sh
./rest_insert_once.sh
成功すると、下図のようなレスポンスが返ってきます。
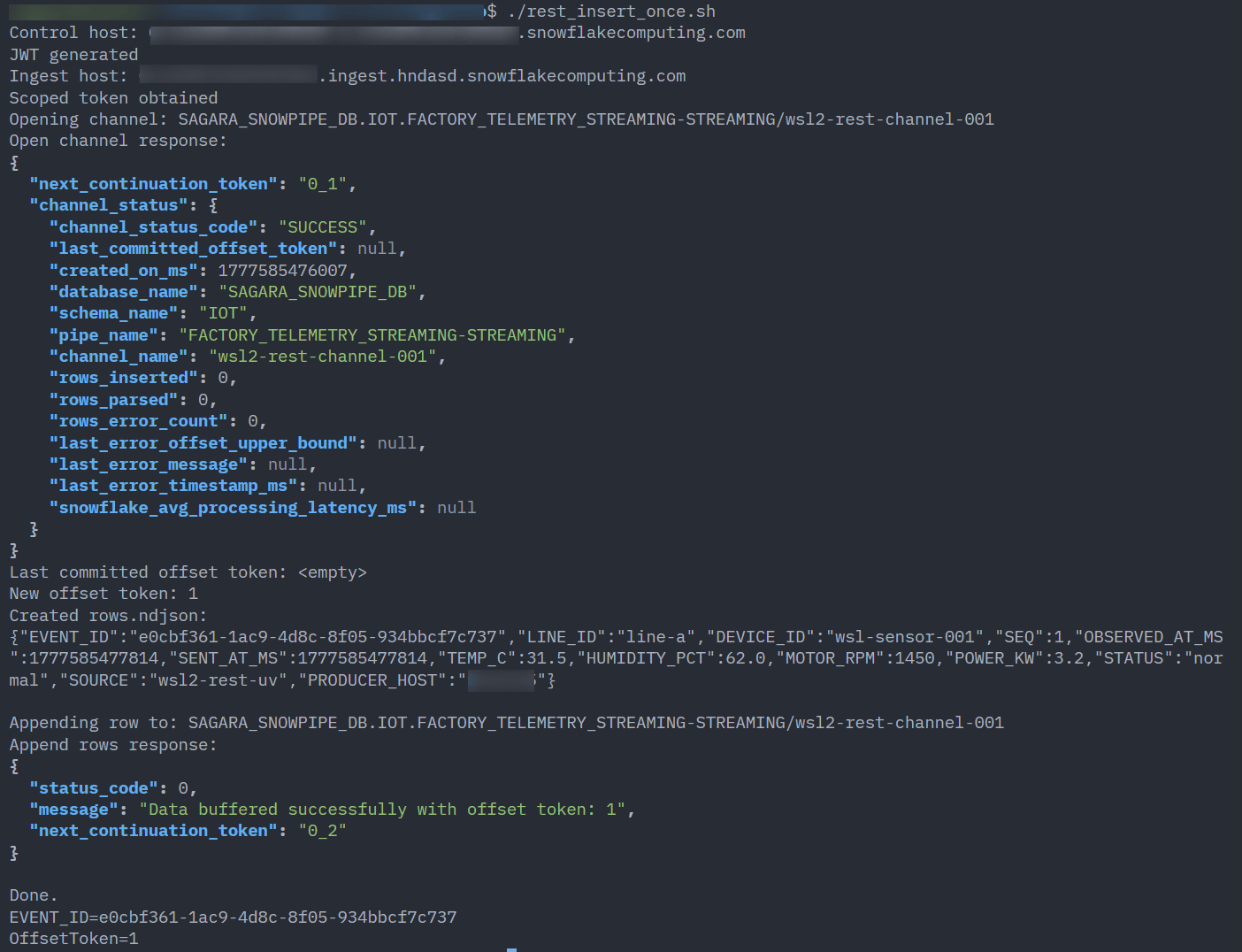
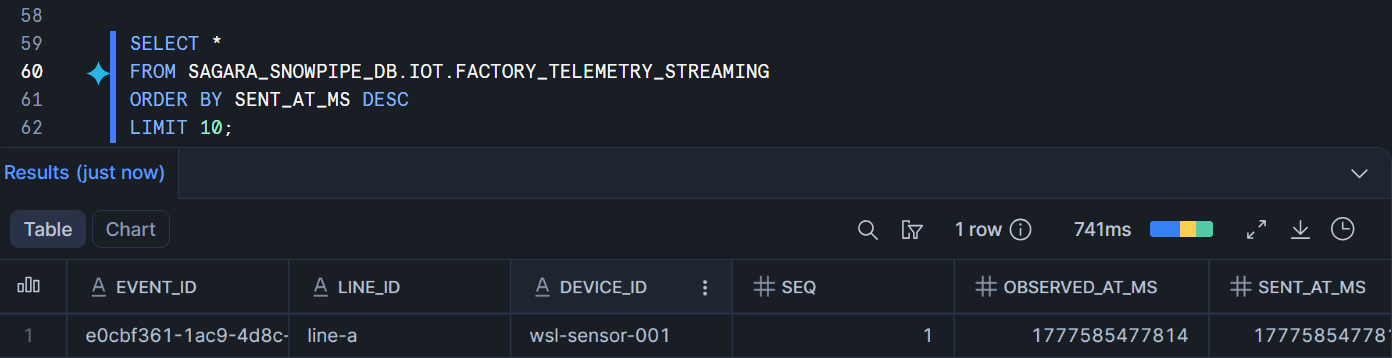
Snowsight側で確認します。
SELECT *
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING
ORDER BY SENT_AT_MS DESC
LIMIT 10;
投入したレコードが1件返ってくればOKです。Snowpipe Streaming High PerformanceのEnd-to-Endレイテンシは最短5秒とされているため、すぐに見えない場合は少し待ってから再度クエリしてみてください。
2. Python SDKで連続投入する
REST APIで1件投入が成功したら、次はPython SDKで連続投入を試します。
公式のsnowpipe-streaming Python SDKでチャネルをオープンし、行を送信、確認待ち、クローズという流れになります。サンプルは公式GitHubのsnowflakedb/snowpipe-streaming-sdk-examplesが参考になります。
プロジェクト直下にproducer_streaming.pyを作成し、以下の内容にします。通常時は25〜33℃、たまにwarning/criticalの高温イベントを混ぜる構成です。
`producer_streaming.py`の全文(クリックで展開)
import os
import time
import uuid
import json
import random
import socket
import argparse
import logging
from snowflake.ingest.streaming import StreamingIngestClient
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
PROFILE_PATH = os.environ.get("SNOWFLAKE_PROFILE_FILE", "profile.json")
HOSTNAME = socket.gethostname()
def build_record(device_id: str, line_id: str, seq: int) -> dict:
observed_at_ms = int(time.time() * 1000)
# 通常時は 25〜33℃、時々 warning / critical を発生させる
r = random.random()
if r < 0.05:
temp_c = round(random.uniform(37.0, 42.0), 2)
status = "critical"
elif r < 0.20:
temp_c = round(random.uniform(33.0, 37.0), 2)
status = "warning"
else:
temp_c = round(random.uniform(25.0, 33.0), 2)
status = "normal"
humidity_pct = round(random.uniform(45.0, 75.0), 2)
motor_rpm = random.randint(1200, 1800)
power_kw = round(random.uniform(2.5, 5.5), 2)
sent_at_ms = int(time.time() * 1000)
return {
"EVENT_ID": str(uuid.uuid4()),
"LINE_ID": line_id,
"DEVICE_ID": device_id,
"SEQ": seq,
"OBSERVED_AT_MS": observed_at_ms,
"SENT_AT_MS": sent_at_ms,
"TEMP_C": temp_c,
"HUMIDITY_PCT": humidity_pct,
"MOTOR_RPM": motor_rpm,
"POWER_KW": power_kw,
"STATUS": status,
"SOURCE": "wsl2-sdk-uv",
"PRODUCER_HOST": HOSTNAME,
}
def committed_at_least(expected_offset: int):
def checker(token: str | None) -> bool:
if token is None:
return False
try:
return int(token) >= expected_offset
except ValueError:
return token == str(expected_offset)
return checker
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--devices", type=int, default=5)
parser.add_argument("--seconds", type=int, default=60)
parser.add_argument("--interval", type=float, default=1.0)
parser.add_argument("--channel", type=str, default="wsl2-channel-001")
args = parser.parse_args()
with open(PROFILE_PATH) as f:
profile = json.load(f)
database = profile["database"]
schema = profile["schema"]
table = profile["table"]
# Default PIPE 名
# 例: FACTORY_TELEMETRY_STREAMING-STREAMING
pipe = f"{table}-STREAMING"
client = None
channel = None
try:
client = StreamingIngestClient(
client_name="sagara-streaming-client",
db_name=database,
schema_name=schema,
pipe_name=pipe,
profile_json=PROFILE_PATH,
)
logging.info(
"client created: database=%s schema=%s pipe=%s",
database,
schema,
pipe,
)
# open_channel は (channel, status) を返す
channel, status = client.open_channel(args.channel)
logging.info(
"channel opened: channel=%s status=%s latest_committed_offset_token=%s",
args.channel,
getattr(status, "status_code", None),
getattr(status, "latest_committed_offset_token", None),
)
latest_offset = getattr(status, "latest_committed_offset_token", None)
if latest_offset is not None:
try:
next_offset = int(latest_offset) + 1
except ValueError:
# 数値でない offset を使っていた場合の保険。
# 今回のサンプルでは数値 offset を使う前提。
next_offset = 1
else:
next_offset = 1
seq_by_device = {
f"wsl-sensor-{i:03d}": 0
for i in range(1, args.devices + 1)
}
start = time.time()
sent_count = 0
last_offset = None
while time.time() - start < args.seconds:
for device_id in seq_by_device.keys():
seq_by_device[device_id] += 1
record = build_record(
device_id=device_id,
line_id="line-a",
seq=seq_by_device[device_id],
)
offset_token = str(next_offset)
channel.append_row(
record,
offset_token=offset_token,
)
last_offset = next_offset
next_offset += 1
sent_count += 1
# 明示的に flush を開始する。
# 高頻度に呼びすぎるとスループットやコスト面で不利になるため、本番では調整してください。
channel.initiate_flush()
logging.info(
"sent_count=%s last_offset=%s",
sent_count,
last_offset,
)
time.sleep(args.interval)
if last_offset is not None:
logging.info("waiting for flush...")
channel.wait_for_flush(timeout_seconds=120)
logging.info("waiting for commit: expected_offset=%s", last_offset)
channel.wait_for_commit(
committed_at_least(last_offset),
timeout_seconds=180,
)
logging.info("commit confirmed: offset=%s", last_offset)
logging.info("total sent_count=%s", sent_count)
finally:
if channel is not None:
try:
channel.close(
wait_for_flush=True,
timeout_seconds=120,
)
logging.info("channel closed")
except Exception:
logging.exception("failed to close channel")
if client is not None:
try:
client.close(
wait_for_flush=True,
timeout_seconds=120,
)
logging.info("client closed")
except Exception:
logging.exception("failed to close client")
if __name__ == "__main__":
main()
最初は小さめのパラメータで流します。
uv run python producer_streaming.py \
--devices 5 \
--seconds 60 \
--interval 1.0
下図のようにログが流れ続ければOKです。
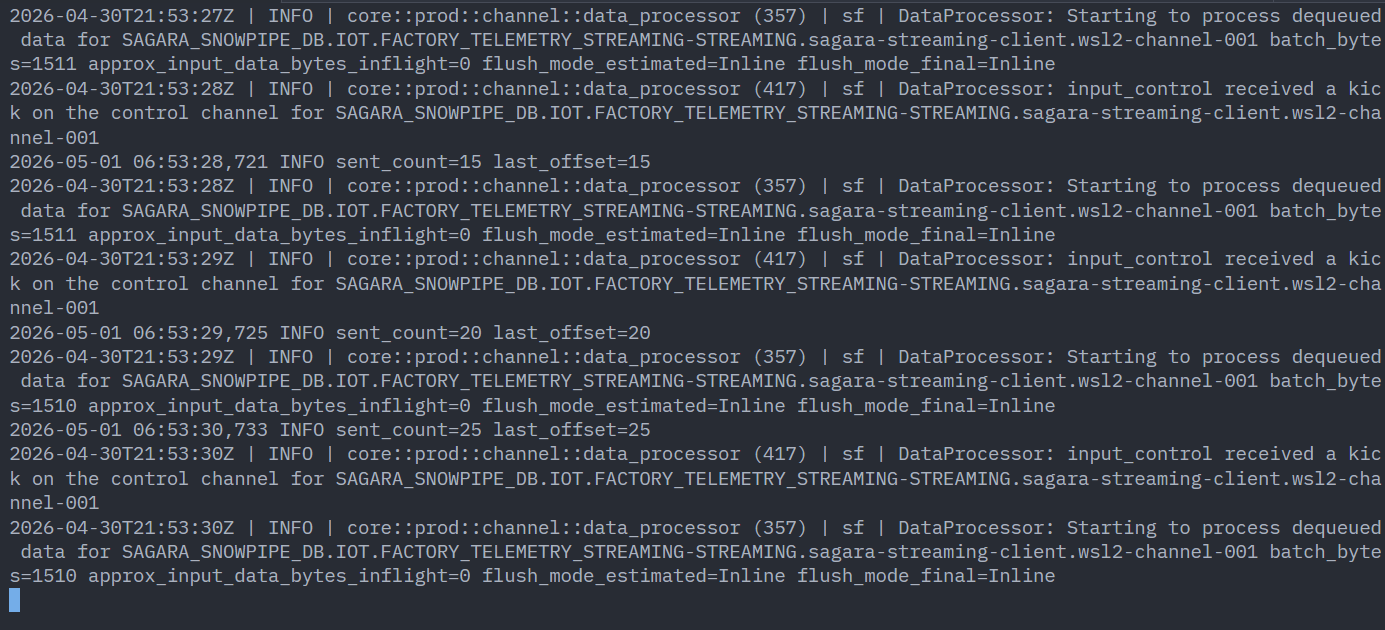
3. 連続投入中にロード状況をリアルタイムで確認する
producer_streaming.pyを実行している最中に、Snowsight側から対象テーブルに対して集計クエリを繰り返し実行することで、Snowpipe Streaming経由でレコードが継続的にロードされていく様子をリアルタイムに観察できます。
WSL2側でやや長めのパラメータでスクリプトを起動しておきます。今回は2分間流す形にしてみます。
uv run python producer_streaming.py \
--devices 5 \
--seconds 120 \
--interval 1.0
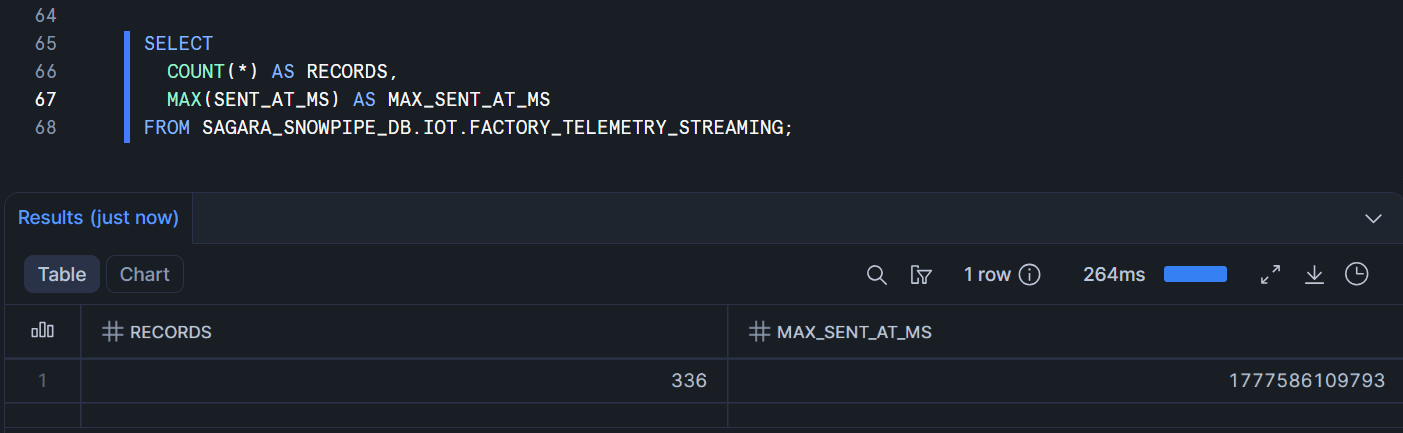
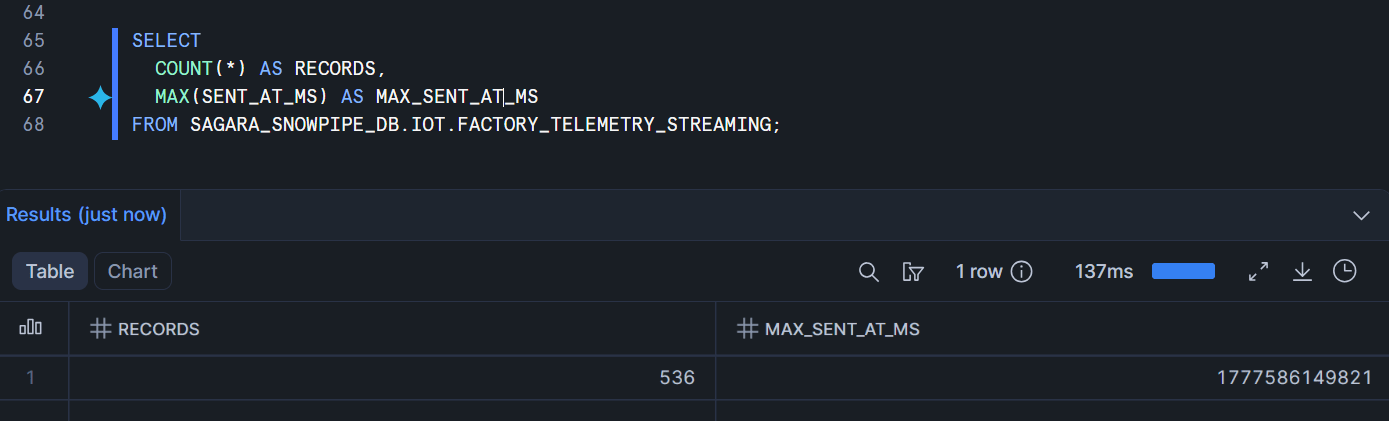
スクリプトが動いている間に、SnowsightのSQL Worksheetで以下のクエリを開いておき、数秒おきにRunボタンを押して件数の推移を観察します。
SELECT
COUNT(*) AS RECORDS,
MAX(SENT_AT_MS) AS MAX_SENT_AT_MS
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING;
producer_streaming.pyが動いている間は、Runを押すたびにRECORDSの値が増え続け、MAX_SENT_AT_MSも進んでいく様子が見えるはずです。
4. Dynamic Tableで重複排除マートを作成する
Snowpipe StreamingはExactly-onceデリバリーをサポートしていますが、クライアント側のリトライや複数チャネルからの並行投入など実運用上の想定外ケースに備えて、EVENT_IDをキーにした重複排除マートを、Dynamic Tableで作成しておきます。
Dynamic TableはTARGET_LAGで許容する遅延を指定するだけで、Snowflakeが自動的にリフレッシュを管理してくれます。TARGET_LAG = '1 minute'なので、ベーステーブル更新から最大1分以内に重複排除マートに反映されます。
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE DYNAMIC TABLE SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_DEDUP
TARGET_LAG = '1 minute'
WAREHOUSE = SAGARA_WH
AS
SELECT
EVENT_ID,
LINE_ID,
DEVICE_ID,
SEQ,
OBSERVED_AT_MS,
SENT_AT_MS,
TEMP_C,
HUMIDITY_PCT,
MOTOR_RPM,
POWER_KW,
STATUS,
SOURCE,
PRODUCER_HOST
FROM (
SELECT
s.*,
ROW_NUMBER() OVER (PARTITION BY EVENT_ID ORDER BY SENT_AT_MS DESC) AS RN
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_STREAMING s
)
WHERE RN = 1;
5. Dynamic Tableで工場監視マートを作成する
重複排除マートを元に、工場監視マートをDynamic Tableで作ってみます。Dynamic TableはDynamic Tableをソースにして連鎖できるので、生データ → 重複排除 → 工場監視マート、のパイプラインが自然に組めます。
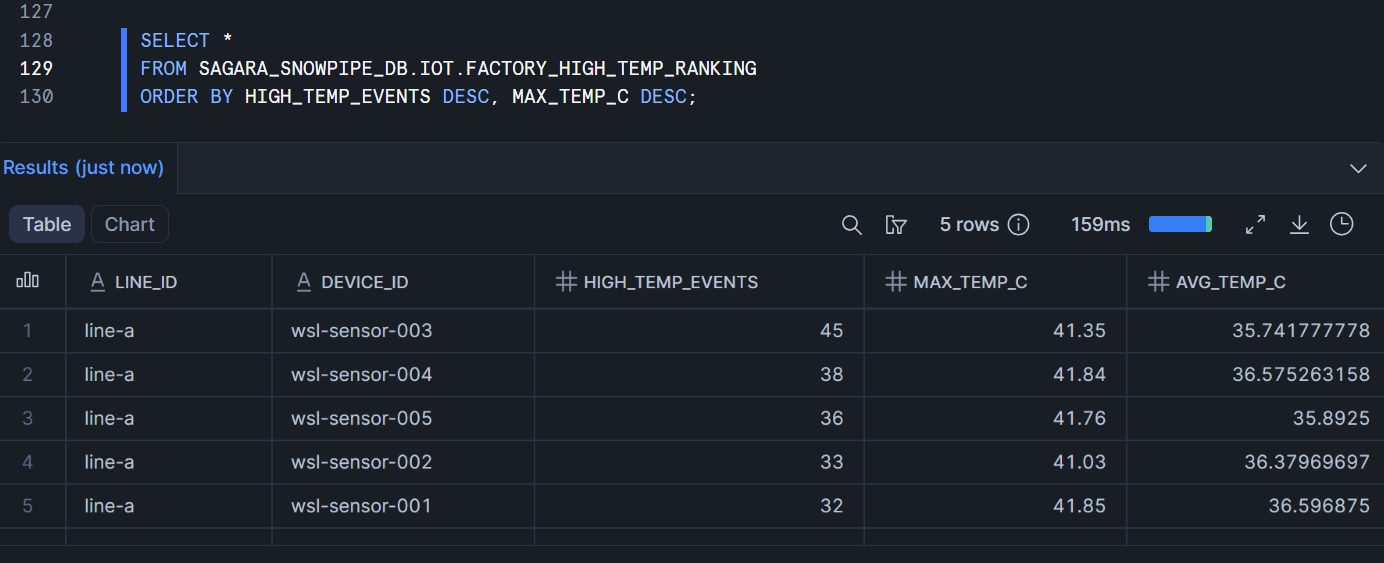
高温イベントの集計マートです。
CREATE OR REPLACE DYNAMIC TABLE SAGARA_SNOWPIPE_DB.IOT.FACTORY_HIGH_TEMP_RANKING
TARGET_LAG = '1 minutes'
WAREHOUSE = SAGARA_WH
AS
SELECT
LINE_ID,
DEVICE_ID,
COUNT(*) AS HIGH_TEMP_EVENTS,
MAX(TEMP_C) AS MAX_TEMP_C,
AVG(TEMP_C) AS AVG_TEMP_C
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_DEDUP
WHERE STATUS IN ('warning', 'critical')
GROUP BY LINE_ID, DEVICE_ID;
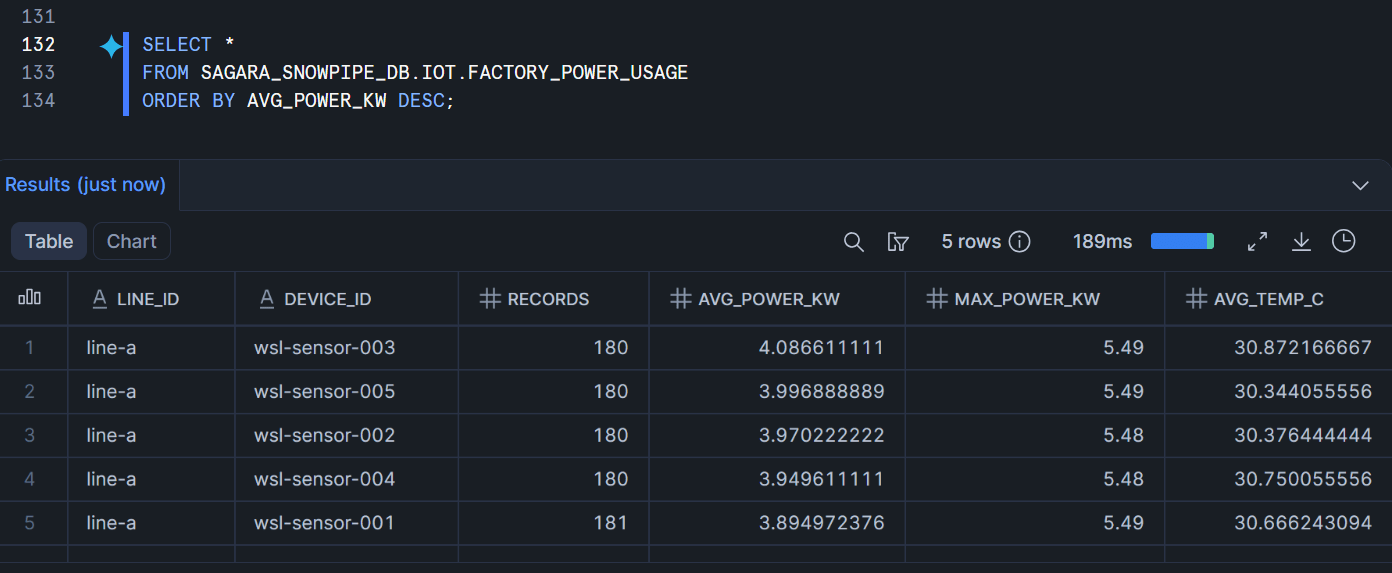
電力消費マートです。
CREATE OR REPLACE DYNAMIC TABLE SAGARA_SNOWPIPE_DB.IOT.FACTORY_POWER_USAGE
TARGET_LAG = '1 minutes'
WAREHOUSE = SAGARA_WH
AS
SELECT
LINE_ID,
DEVICE_ID,
COUNT(*) AS RECORDS,
AVG(POWER_KW) AS AVG_POWER_KW,
MAX(POWER_KW) AS MAX_POWER_KW,
AVG(TEMP_C) AS AVG_TEMP_C
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_TELEMETRY_DEDUP
GROUP BY LINE_ID, DEVICE_ID;
作成したDynamic Tableをクエリしてみます。
SELECT *
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_HIGH_TEMP_RANKING
ORDER BY HIGH_TEMP_EVENTS DESC, MAX_TEMP_C DESC;
SELECT *
FROM SAGARA_SNOWPIPE_DB.IOT.FACTORY_POWER_USAGE
ORDER BY AVG_POWER_KW DESC;
最後に
ローカル(WSL2)上の疑似工場センサーデータをSnowpipe Streaming(High Performance)経由でSnowflakeに流し、Dynamic Tableで重複排除マート・工場監視マートを構築するところまで試してみました。
今回は試していませんが、Snowflake管理のApache Icebergテーブルへのストリーミング取り込みも対応されているため、Iceberg形式でのレイクハウス構成を検討している場合も選択肢に入ってきます。
Snowpipe Streaming High PerformanceとDynamic Tableの組み合わせは、IoTやログ系のニアリアルタイム取り込み+分析にハマる構成だと感じました。気になっている方の参考になれば幸いです。









