
dbt Cloudでドキュメントに記載のあるテストオプションを試してみた
かわばたです。
dbtテストの各オプションについてどのようなことが可能か、dbt Cloudで検証してみました。
対象読者
- dbtテストの各オプションについて確認したい方
検証環境と事前準備
検証環境
- dbt CloudのEnterprise版
- SnowflakeトライアルアカウントのEnterprise版
事前準備
検証用のデータ
test時にエラーとして確認したいため、重複や欠損をわざと作成しています。
raw_customers.csv
customer_id,first_name,last_name,status
1,Michael,Scott,active
2,Dwight,Schrute,active
3,Jim,Halpert,inactive
4,Pam,Beesly,active
4,Andy,Bernard,inactive
,Angela,Martin,active
6,Kevin,Malone,shipped
raw_orders.csv
order_id,customer_id,order_date,amount
1,1,2024-01-01,100
2,1,2024-01-15,150
3,2,2024-01-05,200
4,3,2024-01-20,50
5,4,2024-02-01,75
6,4,2024-02-10,125
7,99,2024-02-15,25
8,2,2024-02-20,-50
これらをseedフォルダへ格納しています。
また、テストを行うためにrawデータから簡易なモデルをstagingフォルダに作成しています。
※テストもstagingレイヤーで実施しますが、後述します。
stg_customers.sql
select
customer_id,
first_name,
last_name,
status
from {{ ref('raw_customers') }}
stg_orders.sql
select
order_id,
customer_id,
order_date,
amount
from {{ ref('raw_orders') }}

後続の処理を確認するため、martフォルダに簡易なモデルを作成します。
mart.sql
select
o.order_id,
o.customer_id,
o.order_date,
o.amount,
c.first_name,
c.last_name,
c.status
from {{ ref('stg_orders') }} AS o
left join {{ ref('stg_customers') }} AS c ON o.customer_id = c.customer_id

dbtテストのオプション確認
dbtのテストは、configブロックを使用することで、テストの挙動を細かく制御することができます。
各種設定オプションについて以下にまとめました。
詳細はドキュメントをご確認ください。
| 設定 | 設定可能な値 | デフォルト値 | 目的 | ユースケース |
|---|---|---|---|---|
| fail_calc | SQLの集計式 | count( * ) | テストの失敗数を計算する方法をカスタマイズする。 | 単純な行数ではなく、特定のビジネス指標(例:金額の差分)に基づいてテストの成否を判定したい場合に使用する。 |
| severity | error, warn | error | テスト失敗時の影響度を定義する。 | warnは、パイプラインを停止させたくないが監視は必要な軽微なデータ品質問題(例:推奨フィールドの欠損)に使用する。errorは、パイプラインを即時停止させるべき重大な問題(例:主キーの重複)に使用する。 |
| store_failures | true, false | false | テストに失敗したレコードをデータベースに保存する。 | デバッグと原因分析を容易にするために使用する。失敗した具体的なレコードをデータオーナーやソースシステムの管理者に提示し、修正を依頼する際に非常に有効。 |
| store_failures_as | table, view, ephemeral | ephemeral | 失敗レコードの保存形式を指定する。 | tableは永続的な監査証跡として、viewは常に最新の失敗状況を確認したい場合に使用する。store_failuresよりも優先される。 |
| where | SQLのWHERE句の条件式 | なし | テスト対象となるレコードをフィルタリングする。 | 増分モデルの新規データ部分のみをテストしてパフォーマンスを向上させたり、特定のビジネス条件下(例:「有効な」ユーザーのみ)でテストを適用したりする。 |
| limit | 整数 | なし | テストクエリが返す失敗レコードの最大数を制限する。 | テストが大量のレコードを返す可能性がある場合に、パフォーマンスの低下を防ぎ、データベースへの負荷を軽減するために使用する。 |
| error_if | 比較式 (例:>100) | != 0 | errorと判定される失敗レコード数の閾値をカスタマイズする。 | 少数のエラー(例:10件未満の重複)は警告(warn)とし、多数のエラー(例:100件以上)が発生した場合にのみパイプラインを停止(error)させたい場合に使用する。 |
| warn_if | 比較式 (例: > 10) | != 0 | warnと判定される失敗レコード数の閾値をカスタマイズする。 | error_ifと組み合わせて、エラーレベルを段階的に設定する。例えば、「10件を超えたら警告、100件を超えたらエラー」といったルールを定義する。 |
実際に検証
テストの作成
今回はstagingレイヤーでテストを実施したいため、stagingフォルダ内にschema.ymlを作成しました。
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
description: "顧客の一意の識別"
tests:
# 'warn_if', 'error_if', 'limit' のデモ
- unique:
config:
# 1件の重複は警告とし、2件以上でエラーとする
warn_if: "= 1"
error_if: "> 1"
# パフォーマンスのため、失敗レコードを1件に制限
limit: 1
# 'where' のデモ
- not_null:
config:
# 'active'ステータスの顧客にのみ非NULL制約を適用
where: "status = 'active'"
- name: status
description: "顧客アカウントのステータス"
tests:
# 'severity' のデモ
- accepted_values:
values: ['active', 'inactive']
config:
# このテストが失敗してもパイプラインを止めず、警告のみを出す
severity: warn
- name: stg_orders
columns:
- name: customer_id
description: "顧客テーブルへの外部キー"
tests:
# 'store_failures'と'store_failures_as'のデモ
- relationships:
to: ref('stg_customers')
field: customer_id
config:
# --store-failures フラグ付きで実行した場合に失敗レコードを保存
store_failures: true
store_failures_as: view
1つのymlファイル内にテストを一括管理もできますが、各層・各モデルで定義をした方が修正ミスが減らせるのではないかを考えています。メリット・デメリットあるので組織の活用用途に応じて確認ください。
| テスト管理方法 | メリット | デメリット |
|---|---|---|
| 一括管理 | ファイル数が少ない | テストを一括管理するので、ymlファイル内が煩雑になる |
| モデルごとに管理 | モデルとテストが対応していて修正ミスが減らせる | モデル増加ごとにテストファイルも増えるのでファイル管理を検討が必要 |
テストの実行
実際にdbt buildを行っていきます。
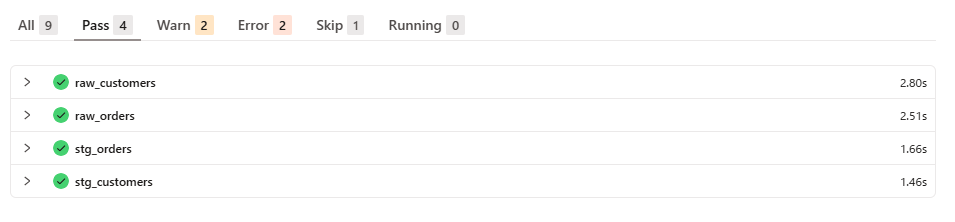
Passが4件、Warnが2件、Errorが2件、Skipが1件でした。順に確認していきます。
-
Pass
seedとstagingのモデルは通っています。
-
Warn
- accepted_values_stg_customers_status__active__inactive
- このテストは
statusカラムに不正な値が存在するため失敗します。ただ、severityがwarnに設定されているため、実行結果のステータスWARNとなります。
- このテストは
- unique_stg_customers_customer_id
- このテストは
customer_idの重複を検出します。limit: 1が設定されているため、dbtが生成するテストクエリの末尾にlimit 1句が追加されます。もし何千もの重複があったとしても、この設定によりパフォーマンスの低下を防ぎます。 warn_if: "= 1"の条件に一致するため、テストのステータスはFAILではなくWARNになります。もし重複が2件以上あれば、error_if: "> 1"の条件に一致し、ステータスはFAILとなります。
- このテストは
- accepted_values_stg_customers_status__active__inactive

- Error
- not_null_stg_customers_customer_id
where: "status = 'active'"句によって、statusがactiveのレコードのみを対象とします。statusがactiveのレコードでcustomer_idがNULLのレコードが存在するためErrorとなります。
- relationships_stg_orders_customer_id__customer_id__ref_stg_customers_
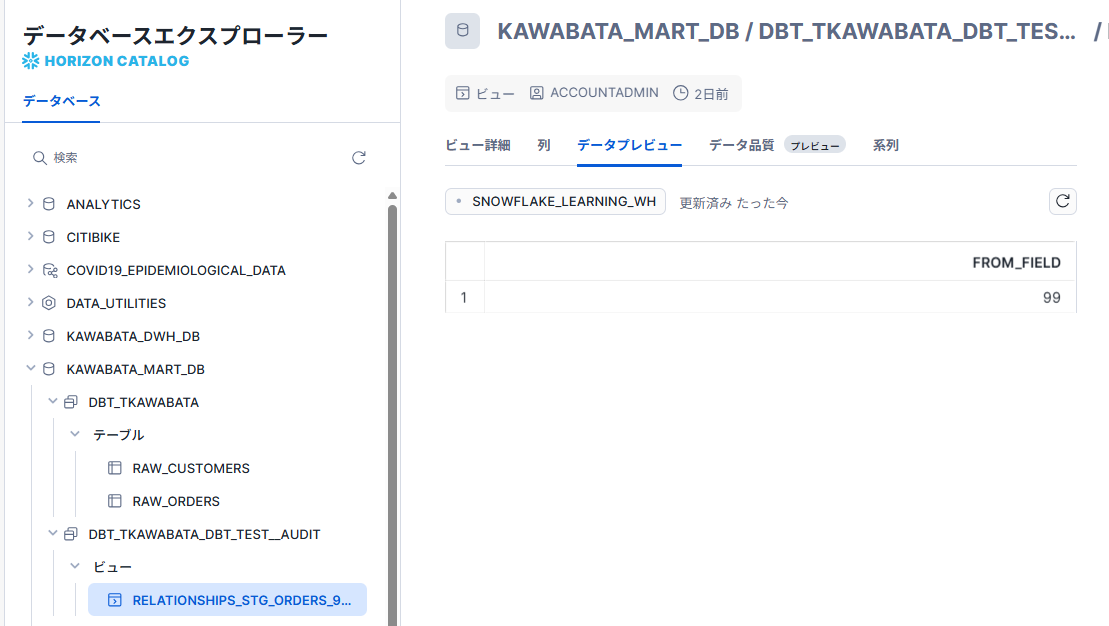
stg_ordersに存在するcustomer_id: 99がstg_customersに存在しないためFAILします。store_failures_asの方が優先されるためviewとしてエラー箇所が保存されます。
- not_null_stg_customers_customer_id

store_failures_asによってエラー箇所がviewとしてSnowflakeに保存されていることが確認できました。
store_failuresでtrue(テーブルで保存)としてますが、store_failures_asが優先されていることが分かります。
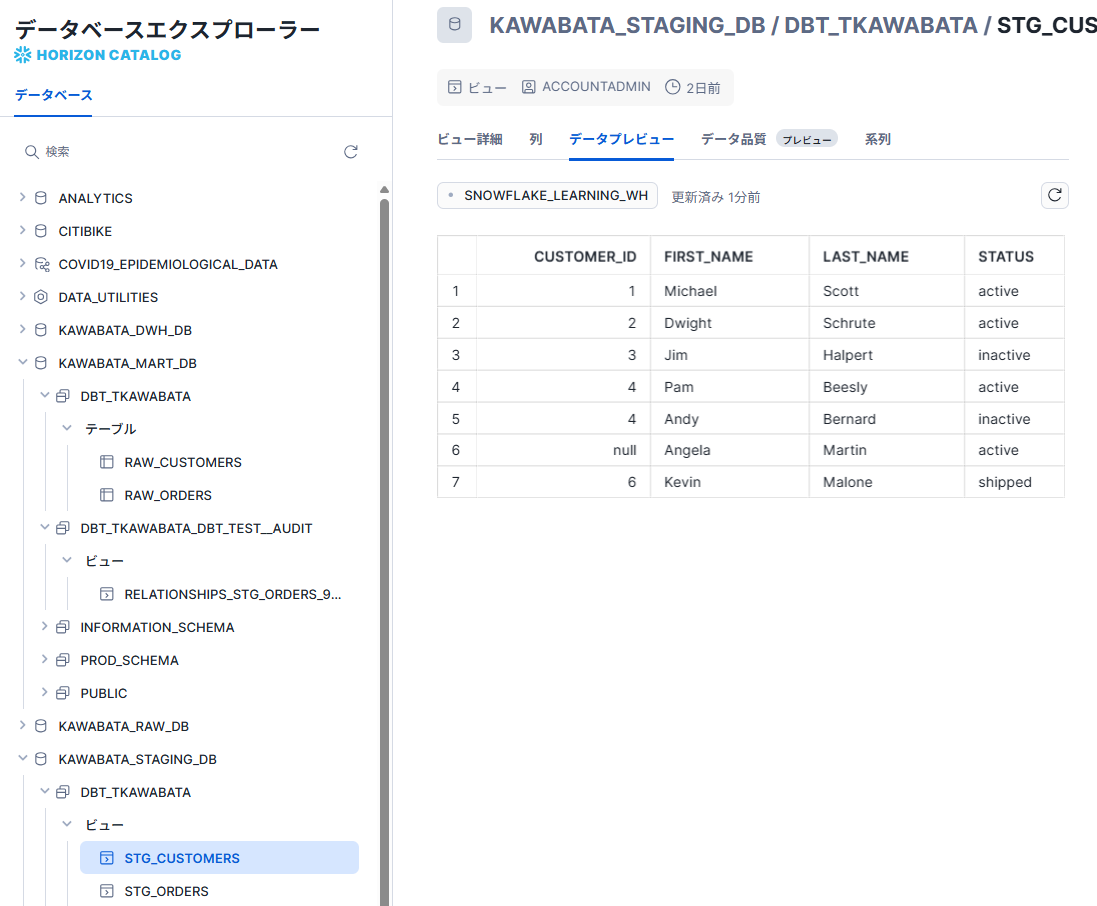
合わせてSnowflakeを確認すると、seedとstagingのモデルは作成されていましたが、'mart.sql'は作成されていませんでした。
fail_calcのテスト
fail_calcのテストも実行します。
下記のようにschema.ymlを編集し、テストを作成します。
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
description: "The unique identifier for a customer."
tests:
# 'fail_calc' のデモ
- unique:
config:
# 失敗の計算方法を「重複している値の数」から「重複しているレコードの総数」に変更
fail_calc: "case when count(*) > 0 then sum(n_records) else 0 end"
# fail_calcの変更により、失敗数が2になるため、WARNになる
error_if: "< 2"
warn_if: ">= 2"
再び、dbt buildを実行し、下記のように警告となりました。
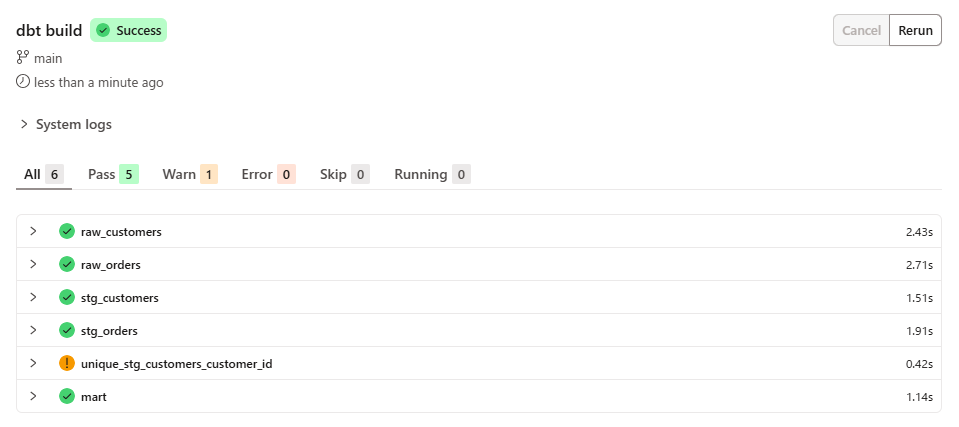
- Warn_fail_calc
- unique_stg_customers_customer_id
- デフォルトでは、テストの失敗数は失敗したレコードのグループ数(count(*))で計算されます。
customer_id: 4の重複は1つのグループなので、失敗数は1です。しかし、fail_calcをsum(n_records)に設定することで、失敗の計算方法を「重複しているレコードの総数」に変更しました。customer_id: 4のレコードは2つあるため、失敗数は2になります。この変更により、warn_if: ">= 2"の条件が満たされ、テストのステータスはFAILではなくWARNとして表示されます。
- デフォルトでは、テストの失敗数は失敗したレコードのグループ数(count(*))で計算されます。
- unique_stg_customers_customer_id
Warnだけでテスト実行
実際にWarnとなった場合、後続のmart.sqlモデルが作成されるのか確認していきます。
先ほどテストを記載していたschema.ymlを編集し、エラーとなっていた箇所をコメントアウトして保存します。
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
description: "顧客の一意の識別"
tests:
# 'warn_if', 'error_if', 'limit' のデモ
- unique:
config:
# 1件の重複は警告とし、2件以上でエラーとする
warn_if: "= 1"
error_if: "> 1"
# パフォーマンスのため、失敗レコードを1件に制限
limit: 1
# 'where' のデモ
# - not_null:
# config:
# # 'active'ステータスの顧客にのみ非NULL制約を適用
# where: "status = 'active'"
- name: status
description: "顧客アカウントのステータス"
tests:
# 'severity' のデモ
- accepted_values:
values: ['active', 'inactive']
config:
# このテストが失敗してもパイプラインを止めず、警告のみを出す
severity: warn
再び、dbt buildを実行します。
想定通り、mart.sqlモデルまで実行できており、コマンド自体もSuccessとなっています。
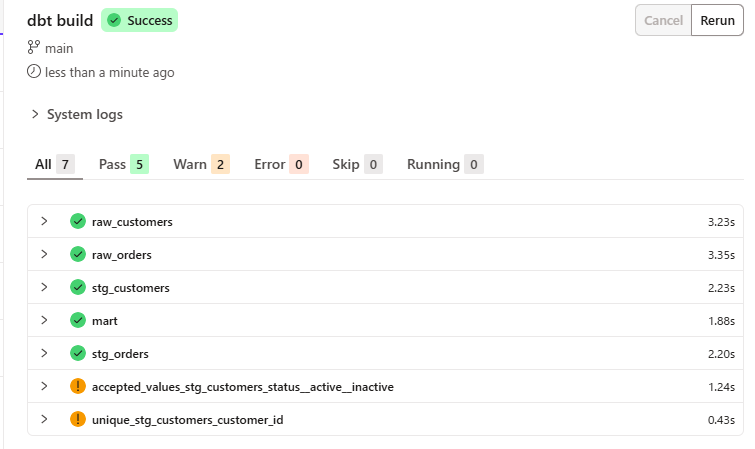
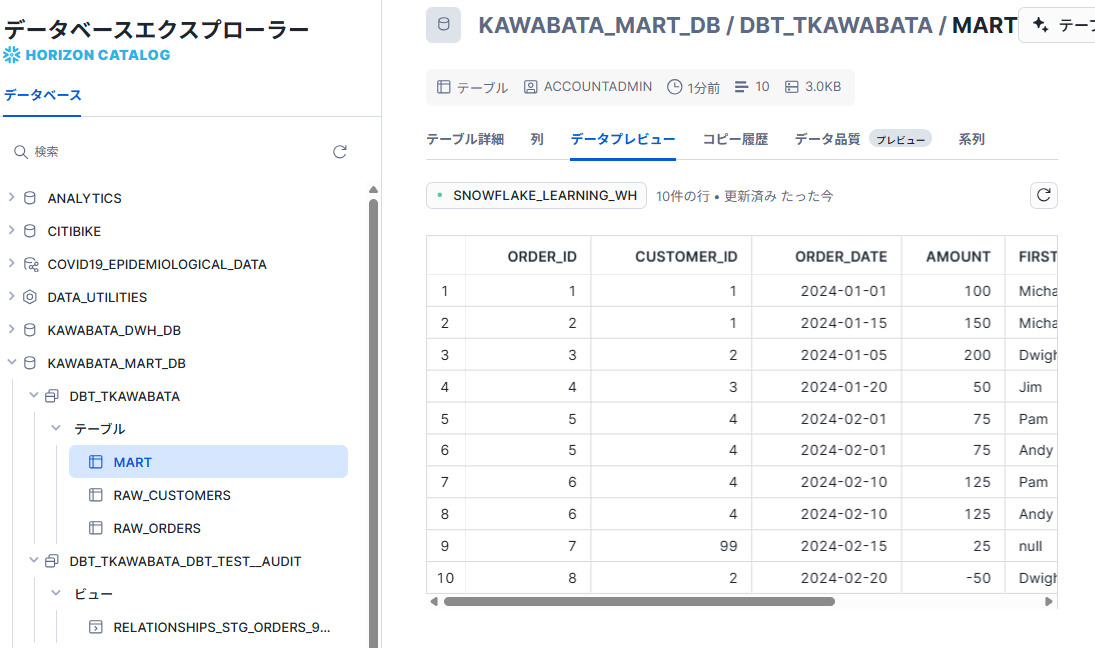
Snowflake側も確認し、反映されていることが確認できました。
最後に
dbtテストの各オプションについて確認しました。
store_failuresはテスト失敗レコードの保存を有効にするかどうかの設定で、store_failures_asは保存形式(テーブルやビュー)を指定します。store_failures_asを設定すれば自動的に失敗レコードが保存されるため、基本的には store_failures_asを使用するほうが良いかなと考えています。
※個人的にエラー箇所が保存されるのは、リカバリを実施する際に調査が楽になると感じました。
また、WarnとErrorの制御ですが、基本的にはErrorとしてパイプラインを止める形が良いと考えています。理由としては、データが正しくない状態で後続処理をしてしまい結果として手戻りが発生してしまう可能性が高いためです。
こちらの記事が参考になれば幸いです!









