
dbt CloudでAmazon Athenaがサポートされたので使ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部インテグレーション部機械学習チーム・新納(にいの)です。
これまでdbt-AthenaはオープンソースのPythonパッケージであるdbt Coreでしか利用できませんでしたが、2024年11月にSaaS版であるdbt Cloudでもサポートされました。このアップデートにより、dbt Cloudのマネージドな環境での変換処理やドキュメントのホスティングができるようになります。
本記事ではdbt CloudでAthenaを使ったデータ変換を実際に試してみます。
利用するデータとシナリオ
以下のクイックスタートに沿って、データやモデルなどをアレンジしながら進めます。
データはクイックスタートのStep2からダウンロードできる以下のファイルを利用します。
-
jaffle_shop_orders.csv(注文履歴)
ID,USER_ID,ORDER_DATE,STATUS 1,1,2018-01-01,returned 2,3,2018-01-02,completed 3,94,2018-01-04,completed ... -
jaffle_shop_customers.csv(顧客情報)
ID,FIRST_NAME,LAST_NAME 1,Michael,P. 2,Shawn,M. 3,Kathleen,P. ...
クイックスタートではHive形式のテーブルを使用していますが、マージ機能を試すためIcebergテーブルとして作成します。利用したSQLは以下の通りです。まず上述のCSVファイルからHIVE形式のテーブルを作成し、CTASを使ってIcebergテーブルを作成します。
-- 1. CSVファイルを外部テーブルとして作成(orders)
CREATE EXTERNAL TABLE raw_orders (
id STRING,
user_id STRING,
order_date DATE,
status STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://<CSVファイルが置かれたS3ロケーションURI>/'
TBLPROPERTIES ('skip.header.line.count'='1');
-- 2. CTASを使用してIcebergテーブルを作成(orders)
CREATE TABLE orders
WITH (
table_type = 'ICEBERG',
format = 'parquet',
write_compression = 'snappy',
partitioning = ARRAY['order_date'],
is_external=false,
location='s3://<任意のS3ロケーションURI>/'
)
AS SELECT * FROM raw_orders;
-- 1. CSVファイルを外部テーブルとして作成(customers)
CREATE EXTERNAL TABLE raw_customers (
id STRING,
first_name STRING,
last_name STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://<CSVファイルが置かれたS3ロケーションURI>/'
TBLPROPERTIES ('skip.header.line.count'='1');
-- 2. CTASを使用してIcebergテーブルを作成(customers)
CREATE TABLE customers
WITH (
table_type = 'ICEBERG',
format = 'parquet',
write_compression = 'snappy',
is_external=false,
location='s3://<任意のS3ロケーションURI>/'
)
AS SELECT * FROM raw_customers;
上記のテーブルを使って、顧客データと注文データを組み合わせた顧客ごとの注文サマリーを作成します。データが更新されたらデータをmergeで更新していくことを想定しています。
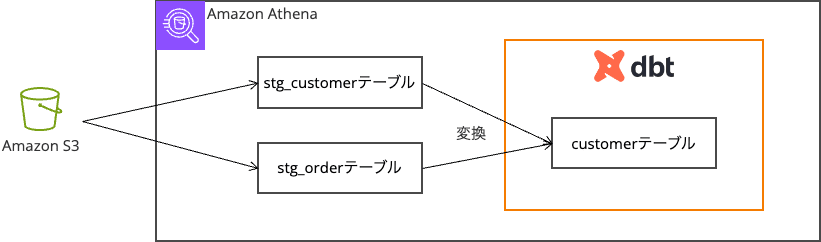
dbt CloudからAthenaへ接続する
dbt Cloudへログインし、Account Settingsに移動します。
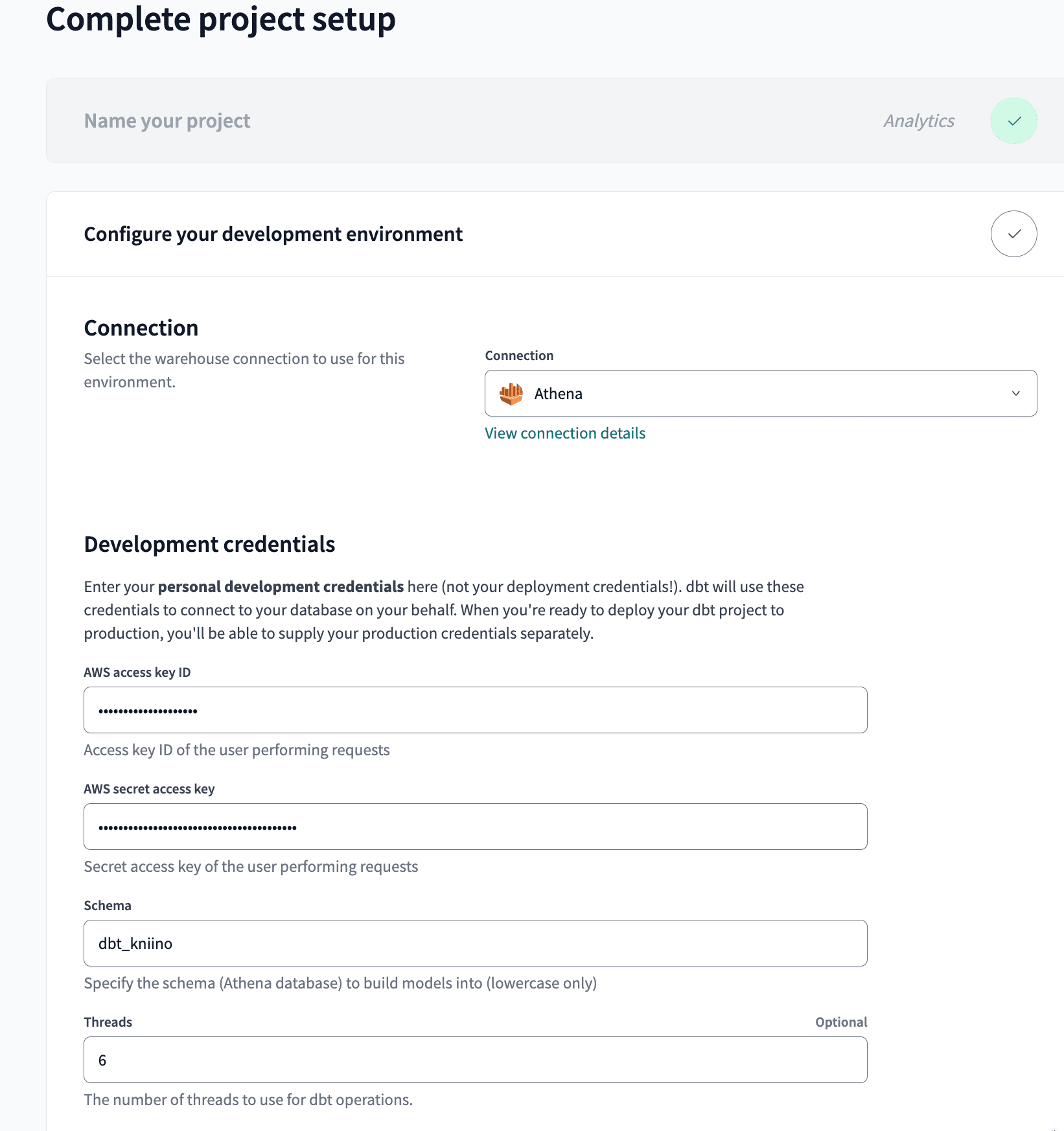
Projectsメニューから「+New Project」で任意の名前の新しいプロジェクトを作成します。ConnectionにはAthenaを指定し、必要情報を入力します。テスト接続も可能です。
| 項目 | 値 |
|---|---|
| AWS access key ID | AWSリソースにアクセスするためのアクセスキー(今回はAmazonAthenaFullPolicy、AmazonS3FullAccess、AWSGlueServiceRoleポリシーを指定したIAMユーザーで検証) |
| AWS secret access key | AWSリソースにアクセスするためのシークレットキー |
| schema | dbtで作成したテーブルを配置するAthenaのデータベース名 |
| Threads | dbtが実行する際の並列処理のスレッド数(任意) |
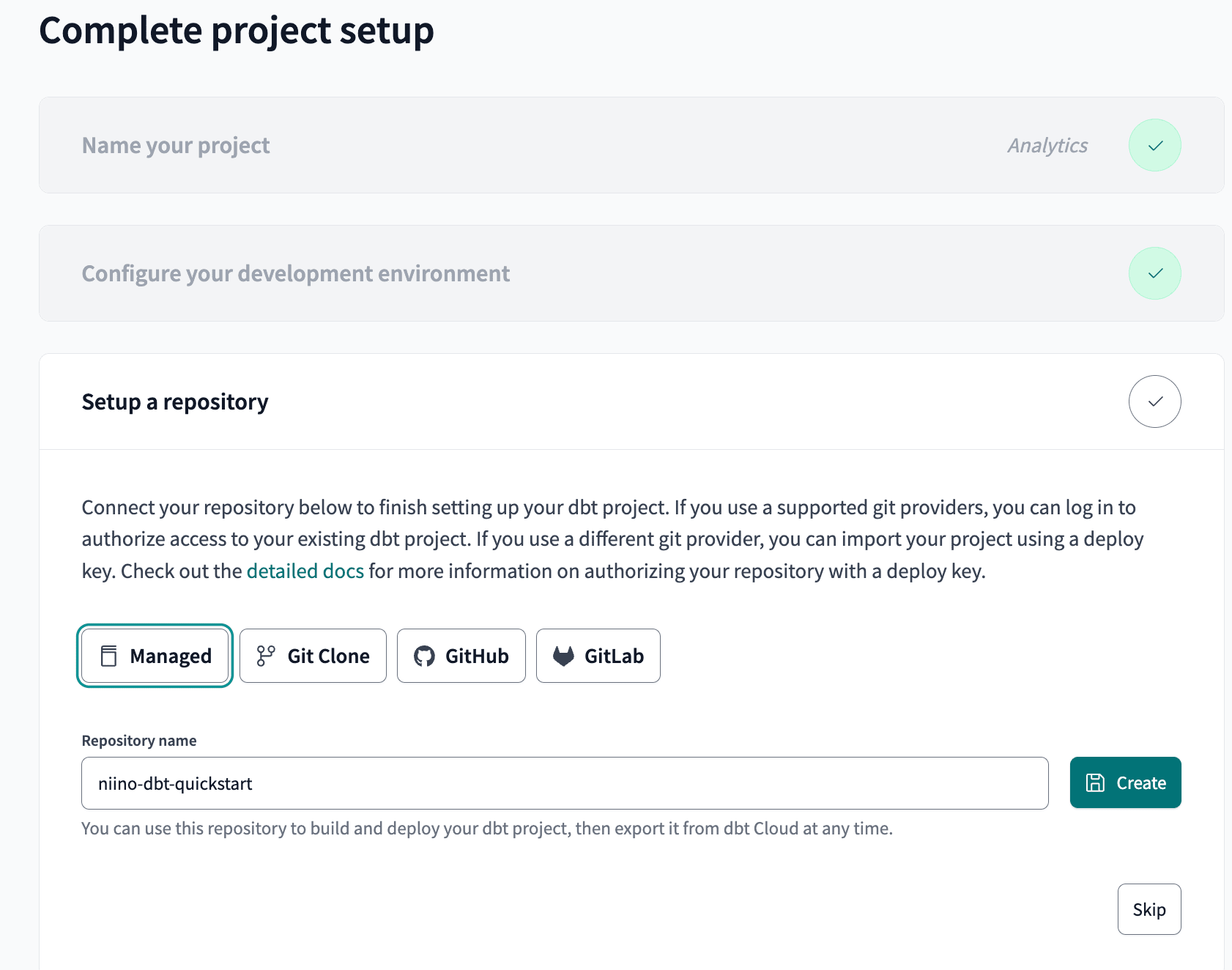
リポジトリをセットアップします。今回は検証のため、dbt Cloudのマネージドのリポジトリを使用しました。
これでAthenaへの接続が確立されました。
モデルを作成する
上述の画面から「Start developing in the IDE」を選ぶとコードエディタが表示されます。最初はInitialize dbt projectでプロジェクトを初期化し、コミットする必要があります。
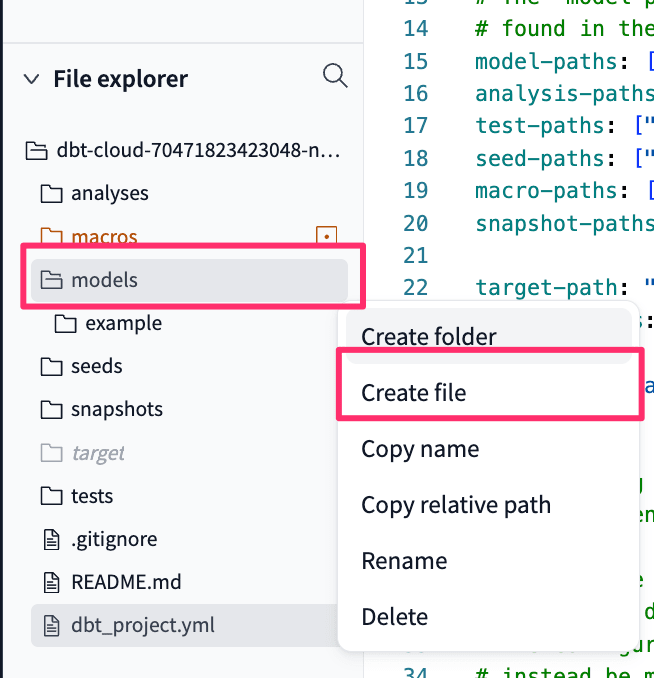
まずはmodel配下に新しいファイルを作成しましょう。modelディレクトリの3点リーダからCreate fileを選択し、sqlファイルを作成します。
ゴールはAthenaで事前に作っておいたcustomersテーブルとordersテーブルを結合し、新たなテーブルを作成することです。sqlファイルを2つ作成し、customersとordersから必要なカラムをSELECTするクエリを記載します。
select
id as customer_id,
first_name,
last_name
from default.customers
select
id as order_id,
user_id as customer_id,
order_date,
status
from default.orders
上記でSELECTしたデータを結合するためのクエリを別のsqlファイルで作成します。stg_customersとstg_ordersは上述で作成したものを参照するように記載しています。
{{
config(
materialized='incremental',
table_type='iceberg',
unique_key='customer_id',
incremental_strategy='merge'
)
}}
with stg_customers as (
select * from {{ ref('stg_customers') }}
),
stg_orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from stg_orders
group by 1
),
final as (
select
customer_id,
first_name,
last_name,
first_order_date,
most_recent_order_date,
coalesce(number_of_orders, 0) as number_of_orders
from stg_customers
left join customer_orders using (customer_id)
)
select * from final
先頭のconfig部分は以下の意味を持ちます。
- Icebergテーブルとして作成
- 新規または変更されたデータのみを処理するincremental更新を採用
- customer_idをユニークキーとして使用
{{
config(
materialized='incremental',
table_type='iceberg',
unique_key='customer_id',
incremental_strategy='merge'
)
}}
モデルの実行をする
実行前にテストする
dbtには、データソースや変換処理後のデータが意図した通りになっているかを検証する機能があります。models配下にschema.ymlを作成し、それぞれのスキーマを定義しておきます。
今回はクイックスタートに記載されているyamlファイルをそのまま利用します。ポイントは以下の通り。
-
customersテーブル
-
customer_id: 一意、NOT NULL
-
first_order_date: 初回注文日(NULL許容)
-
-
stg_customersテーブル
- customer_id: 一意、NOT NULL
-
stg_ordersテーブル
-
order_id: 一意、NOT NULL
-
status: 5つの値のみ許容(placed, shipped, completed, return_pending, returned)
-
customer_id: NOT NULL、stg_customersテーブルに存在する値のみ許容
-
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
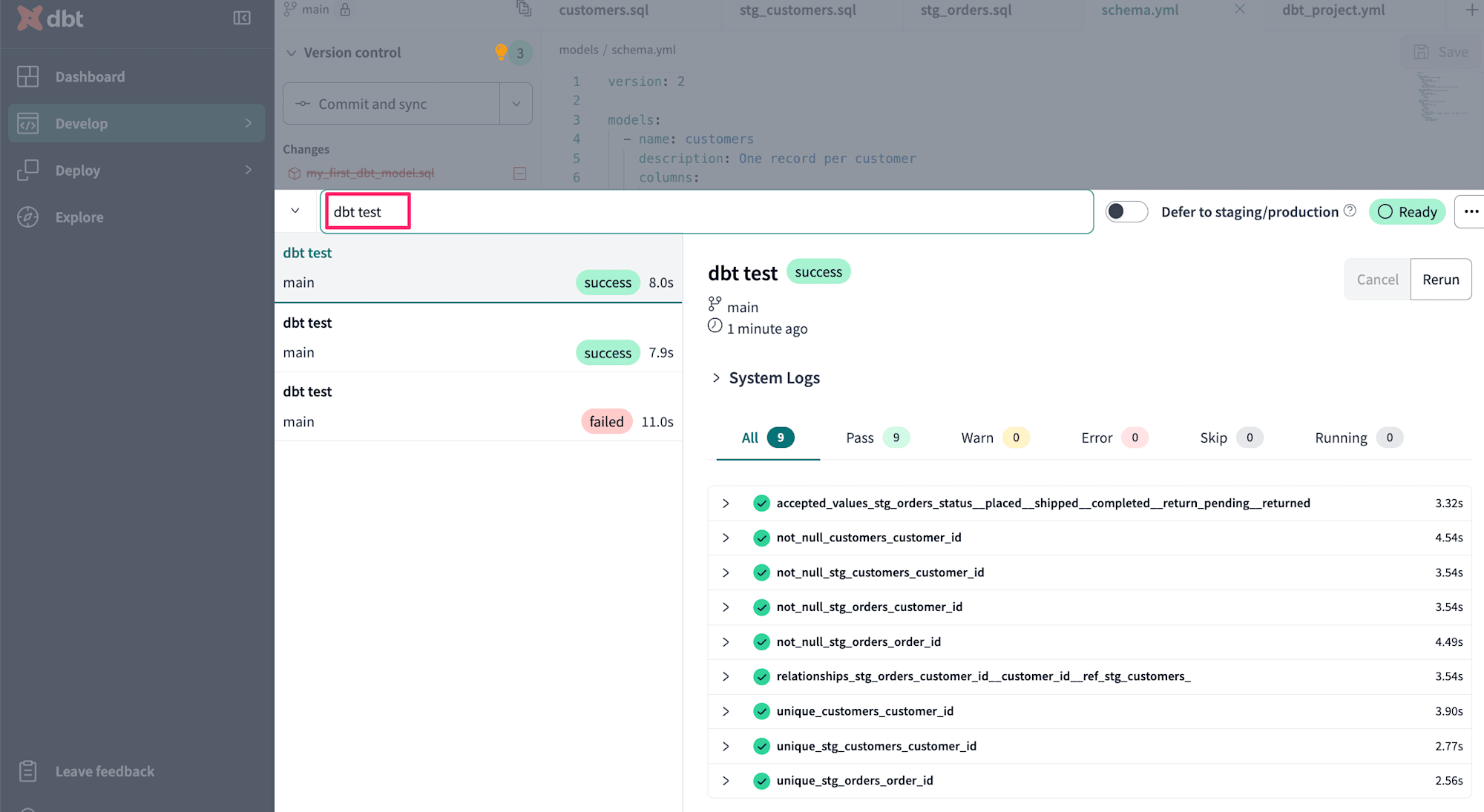
dbt Cloudでは画面下部にコマンドを入力する箇所があります。ここでdbt testコマンドを実行することでテスト可能です。
モデルを実行してテーブルを作成する
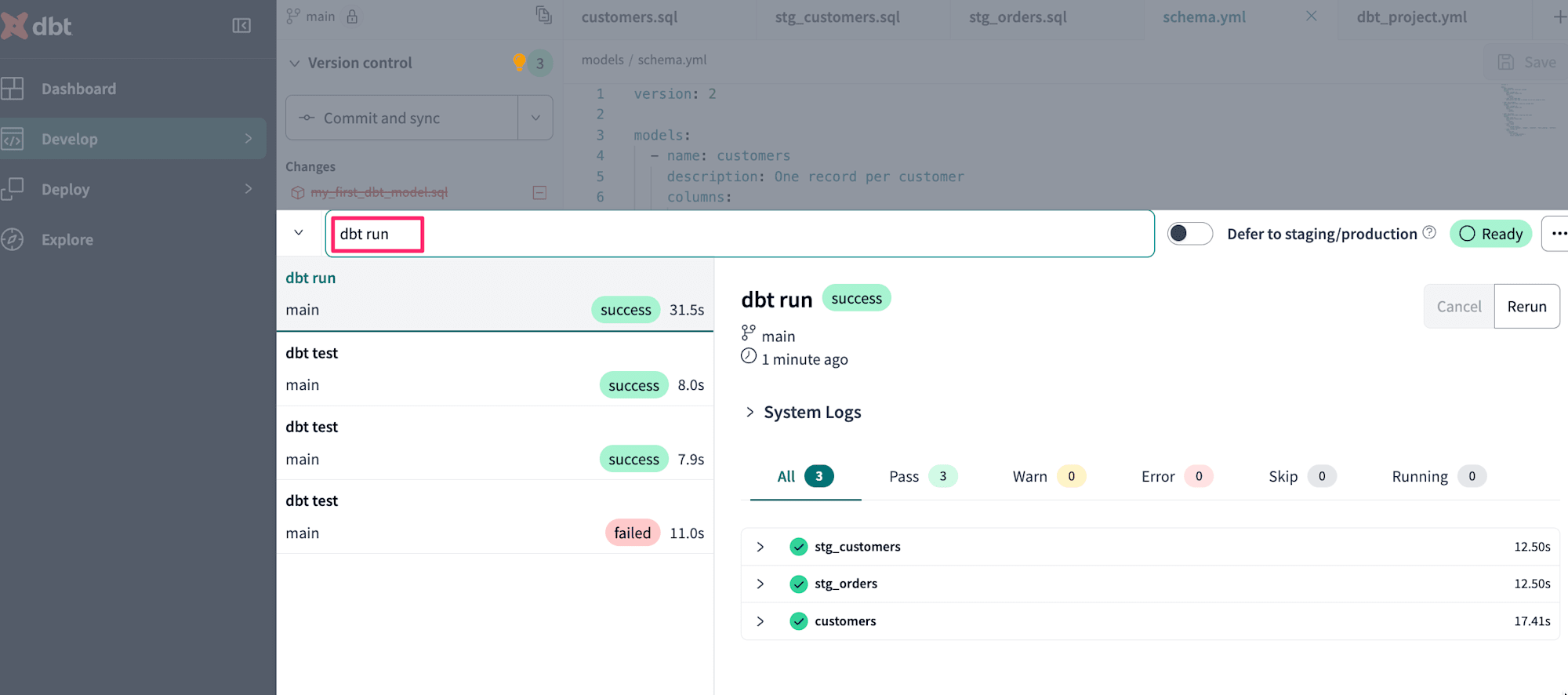
テスト結果に問題がないことが確認できたら今度は作成したモデルを実行してみましょう。dbt runを実行します。
Athenaを確認すると、作成したモデル3つのテーブルが確認できました。
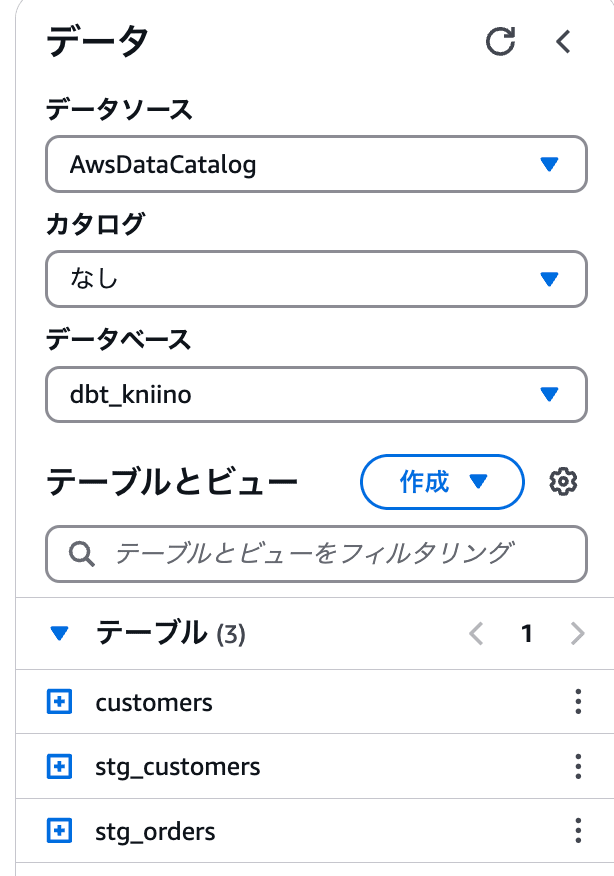
2回目の実行では、Query Historyでmerge文が実行されていることが確認できます。

ドキュメントを生成する
dbtでは、作成したモデルやデータソースの情報を元に自動でドキュメントを生成する機能があります。データカタログのように利用できて非常に便利ですので、生成しておきましょう。
方法はdbt docs generateを実行するだけです。
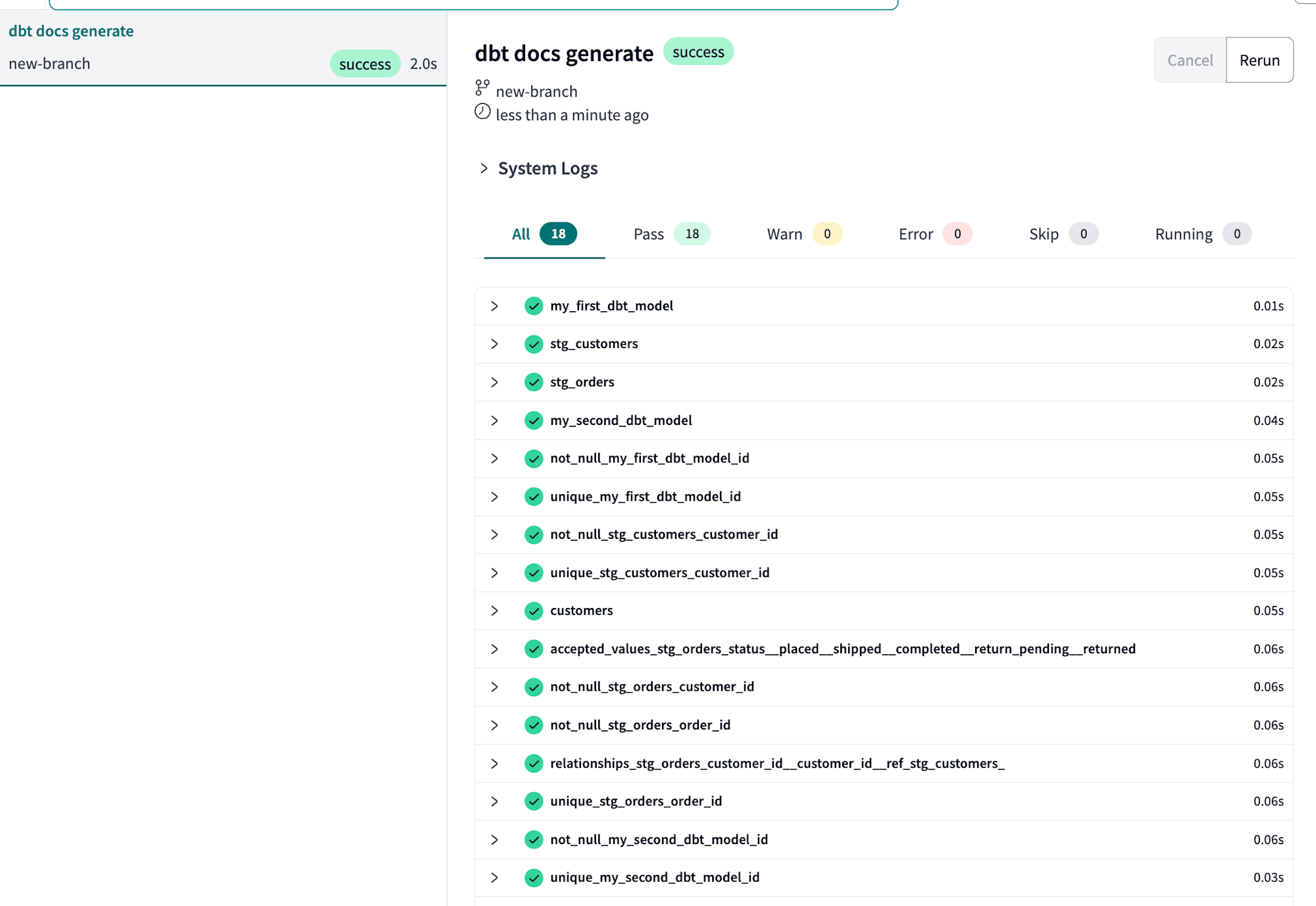
ブランチ名の隣にある本のマークをクリックするとドキュメントへアクセス可能です。

アクセスすると各データのカラムやリネージが確認できるようになりました。
dbt Coreと違って自分でどこにホスティングするかを考える必要がなく、dbt Cloudでホスティングしてくれるので運用もとても楽ですね。
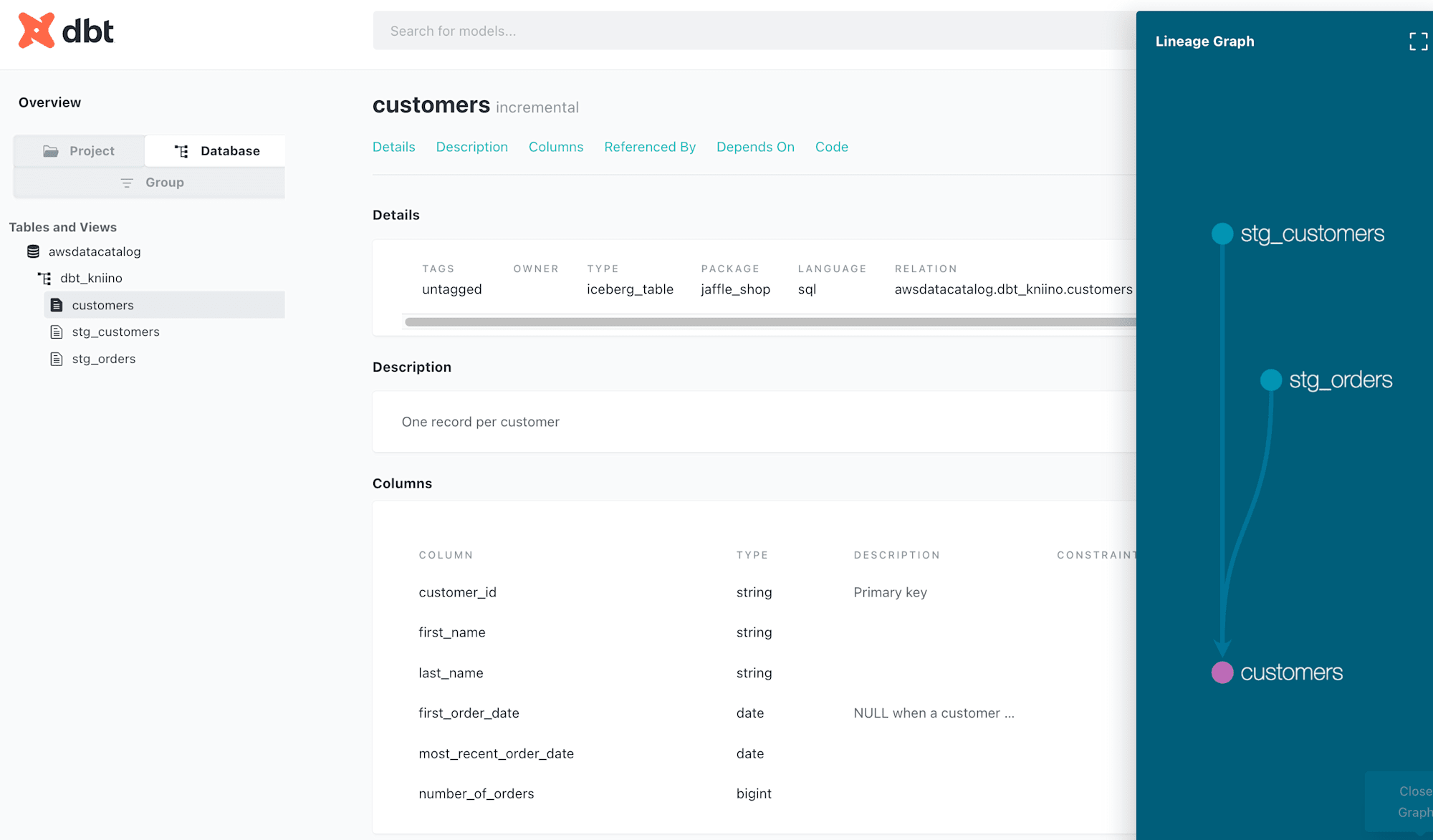
あとは変更内容をコミット・デプロイし、スケジュールされたジョブをdbt Cloud上で作成します。この部分はどのデータソースでも変わらない操作となりますので、以下のブログを参照してください。
最後に
dbt CloudでついにAthenaのアダプタが利用できるようになったのでクイックスタートを元に利用してみました。これまではdbt Coreでしか使えなかったため、ECSとStep FunctionsやEC2などを組み合わせて実行するなどの工夫が必要でした。dbt Cloudだとホスティングやジョブの実行も全てマネージド環境で行えるので、考えることが減ってとても便利です。また、Icebergテーブルと組み合わせることでデータ更新にmergeを利用でき、コストを抑えつつもデータウェアハウスのように扱える利点もあります。
dbt Cloudは14日間のフリートライアルや、条件付きではありますが無料で使えるDeveloperプランがあります。
dbt CoreでAthenaを利用する際のベストプラクティスについては以下をご参照ください。









