
dbt Cloudのtarget変数を用いて環境ごとにソースの読み込みを動的変更する方法を試してみた
かわばたです。
大規模なデータに対して行う開発では、以下の課題があると思います。
- 長いクエリ実行時間
- 高コストなクエリを実行してしまうことへの懸念
その際に、本番環境と開発環境に応じてクエリの内容を動的に変更することで、開発環境では「直近1ヶ月分のデータのみを対象にしてフルスキャンを避ける」といった効率的な開発が可能です。
今回はdbt Cloudのtarget変数を用いて環境ごとにソースの読み込みを動的変更する方法を検証してみます。
対象読者
- dbt Cloudで環境ごとにクエリを動的変更する方法が気になる方
- 大規模なデータを扱っており、開発の生産性向上に課題がある方
検証環境
Snowflakeのアカウント:トライアルアカウントEnterprise版
dbt Cloudのアカウント:Enterprise版
Environmentとtarget
前述のとおり、dbtでは本番環境と開発環境を明示的に分けることができ、接続するウェアハウスの情報を設定することが出来ます。
詳しくは下記ドキュメントを参照ください。
それらの情報が、target変数に格納されています。
target変数には、環境を特定するための様々な属性が含まれています。
以下の表は、動的なロジックを構築する上で特に有用な属性をまとめたものです。
| 属性 | 説明 | ユースケース |
|---|---|---|
| target.name | dev,prod,ci | profiles.ymlまたはdbt Cloudのジョブ設定で定義されたアクティブなターゲット名。環境を区別するための主要なフラグです |
| target.schema | dbt_name,analytics | dbtが現在の実行でモデルをマテリアライズする先のターゲットスキーマ名 |
| target.database | DEV_DB,PROD_DB | 現在の実行におけるターゲットデータベース名 |
| target.warehouse | COMPUTE_XS,COMPUTE_L | 実行に使用されているSnowflakeの仮想ウェアハウス名 |
| target.user | name,dbt_cloud_service_account | データウェアハウスへの接続に使用されているユーザーアカウント名 |
| target.role | ANALYTICS_ENGINEER,DBT_PROD_ROLE | 実行に使用されているSnowflakeのロール名 |
詳しくは下記ドキュメントを参照ください。
クエリを動的変更する検証
上記の概念を使用して、開発環境で動的にクエリを実行する方法を検証します。
使用データ
今回はSnowflakeがサンプルデータとして提供しているSNOWFLAKE_SAMPLE_DATAという共有データベースからTPCH_SF1000スキーマのORDERSテーブルを使用します。
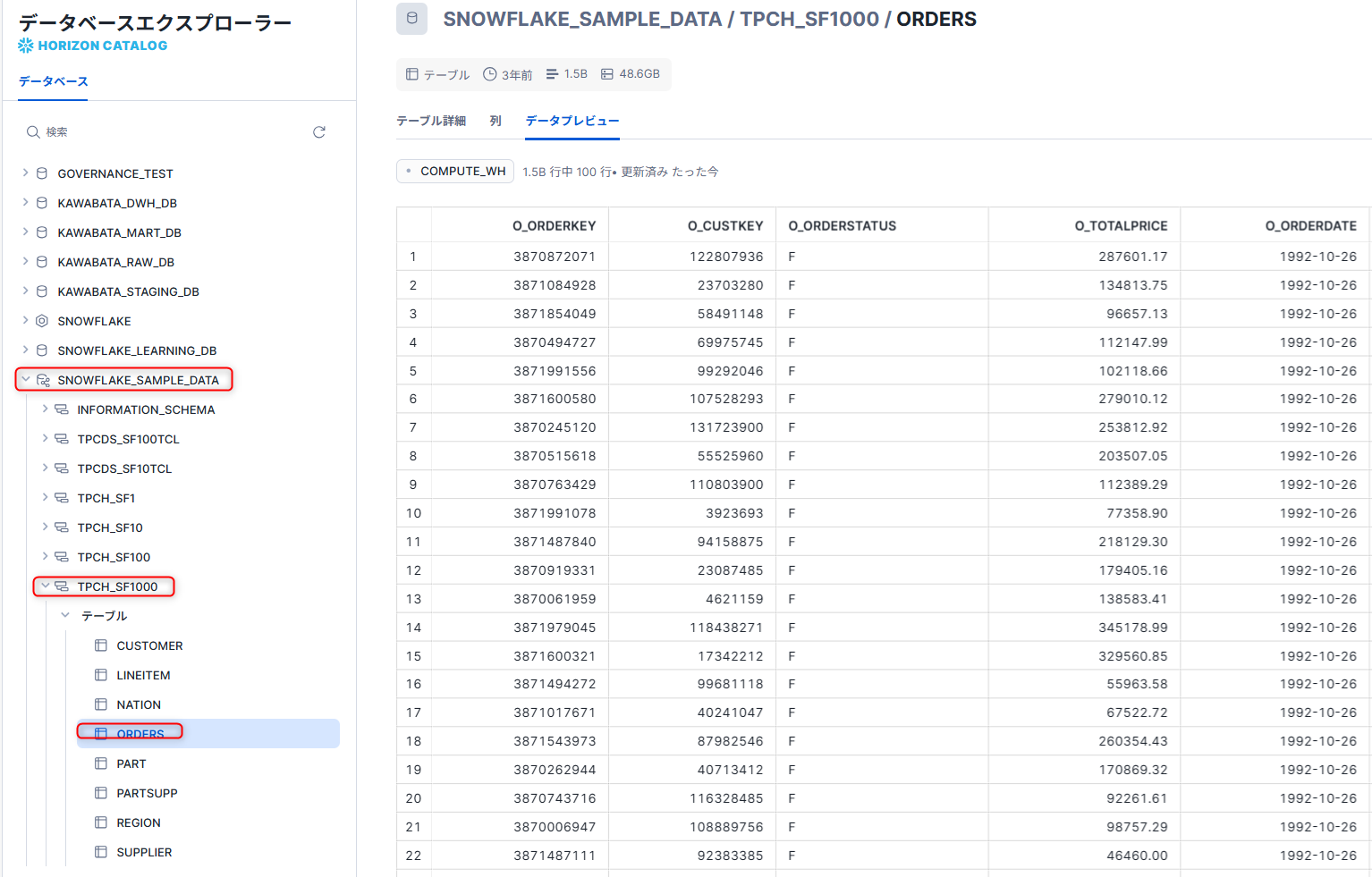
dbt Cloudでsourcesを定義
dbtプロジェクトのmodelsディレクトリ内に、sources.ymlを作成し、以下のようにデータソースを定義します。
version: 2
sources:
- name: tpch_sf1000
database: snowflake_sample_data
schema: tpch_sf1000
tables:
- name: orders
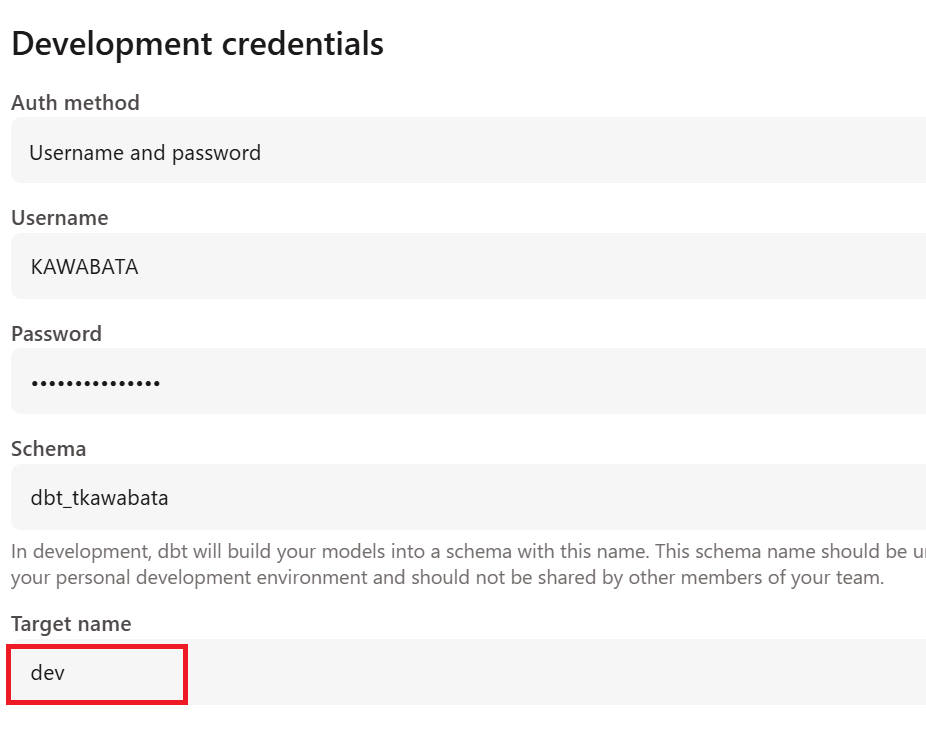
dbt CloudでTarget nameを定義
dbt CloudではDevelopment credentialsでTarget nameを設定できます。
今回は以下のように、devと設定しました。
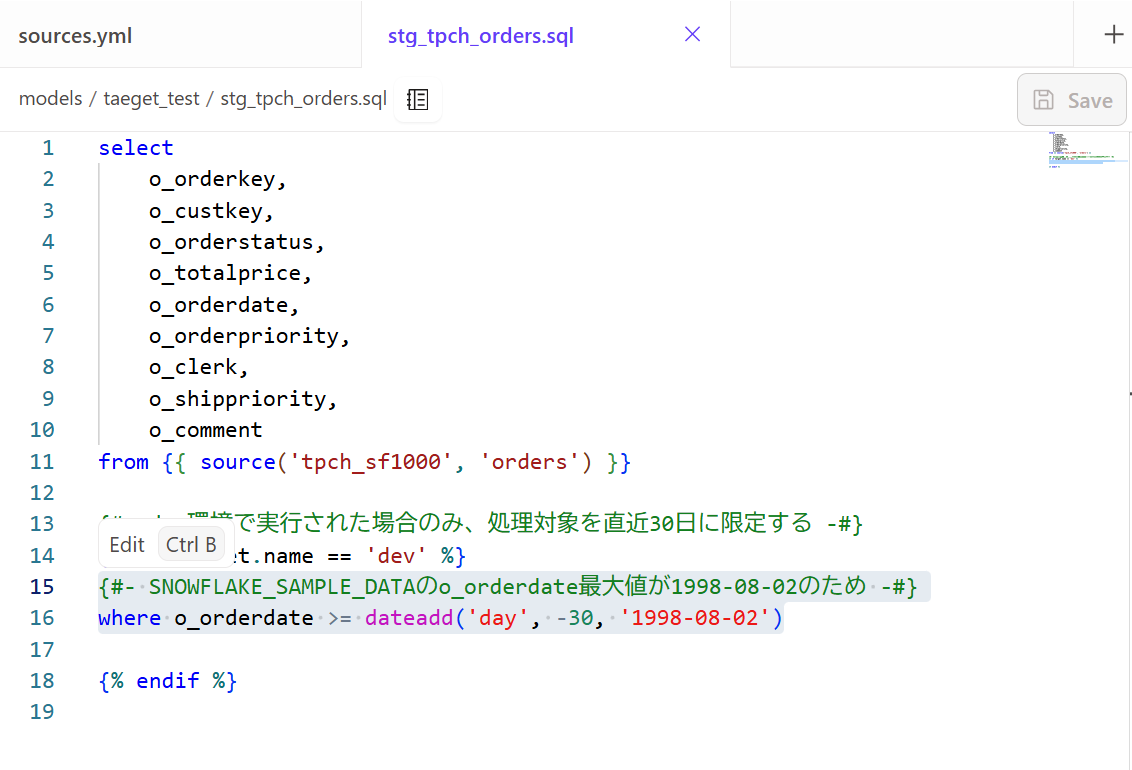
SQLモデルの作成
stg_tpch_orders.sqlという名前で新しいSQLファイルを作成し、以下のようにSQLを記述しました。
select
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_shippriority,
o_comment
from {{ source('tpch_sf1000', 'orders') }}
{#- dev環境で実行された場合のみ、処理対象を直近30日に限定する -#}
{% if target.name == 'dev' %}
where o_orderdate >= dateadd('day', -30, '1998-08-02')
{% endif %}
{#- SNOWFLAKE_SAMPLE_DATAのo_orderdate最大値が1998-08-02のため -#}
-- 30日分を取得
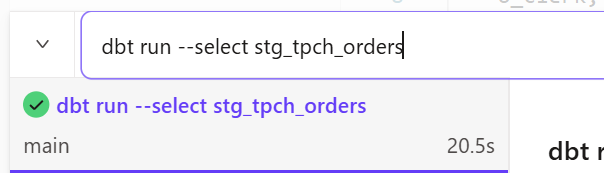
実行とパフォーマンス確認
先ほど作成したモデルを開発環境で実行します。
-- 先ほど作成したstg_tpch_ordersモデルのみdbt run
dbt run --select stg_tpch_orders
今回はテーブルに保存する形をとりましたが、結果を確認すると20秒ほどかかっていました。
Snowflake側も確認してみました。
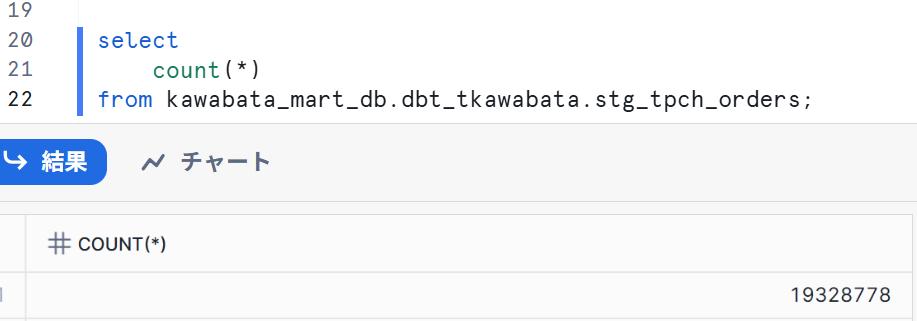
30日分の件数なので想定通りの挙動になっていました。
本番環境でも試してみます。
新しいjobを下記のような形で作成し実行しました。
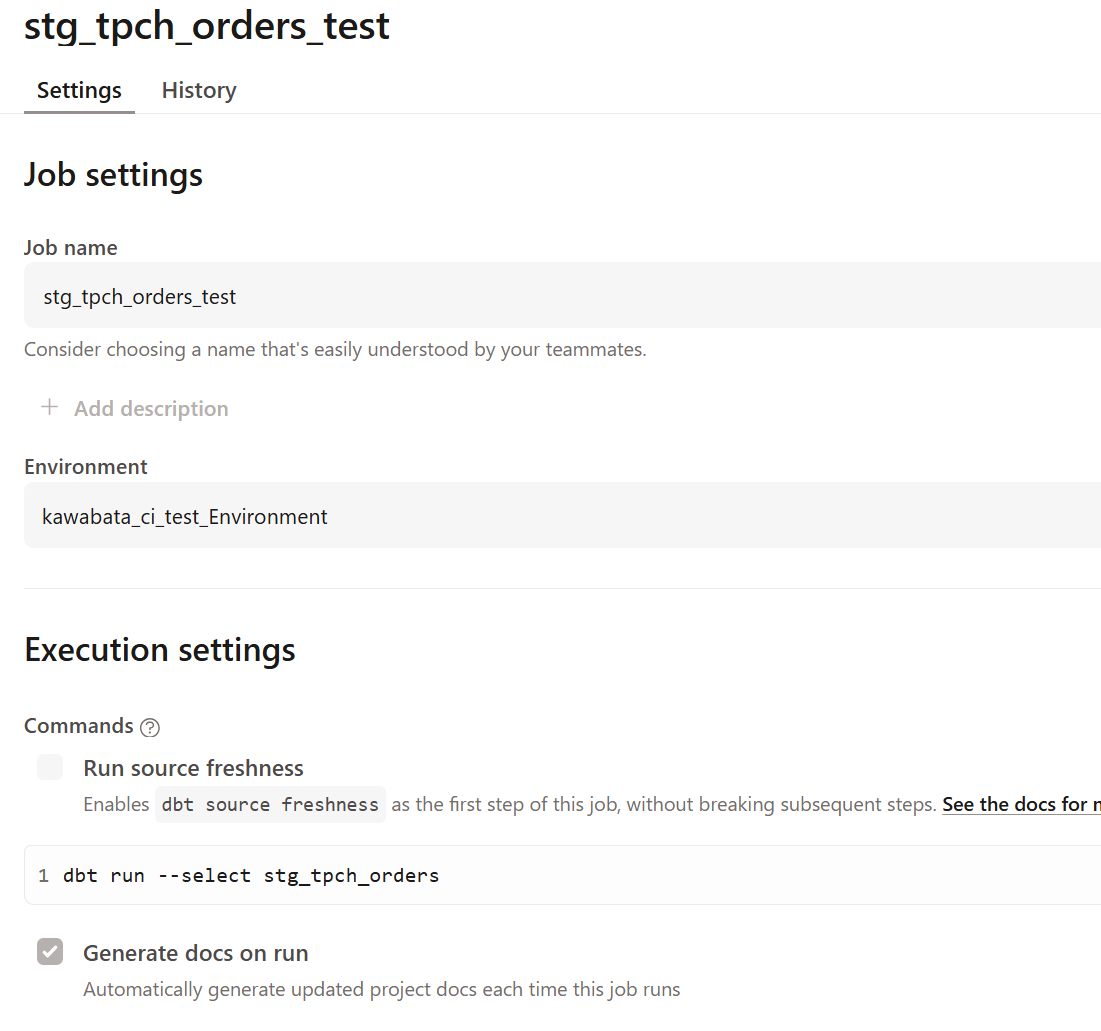
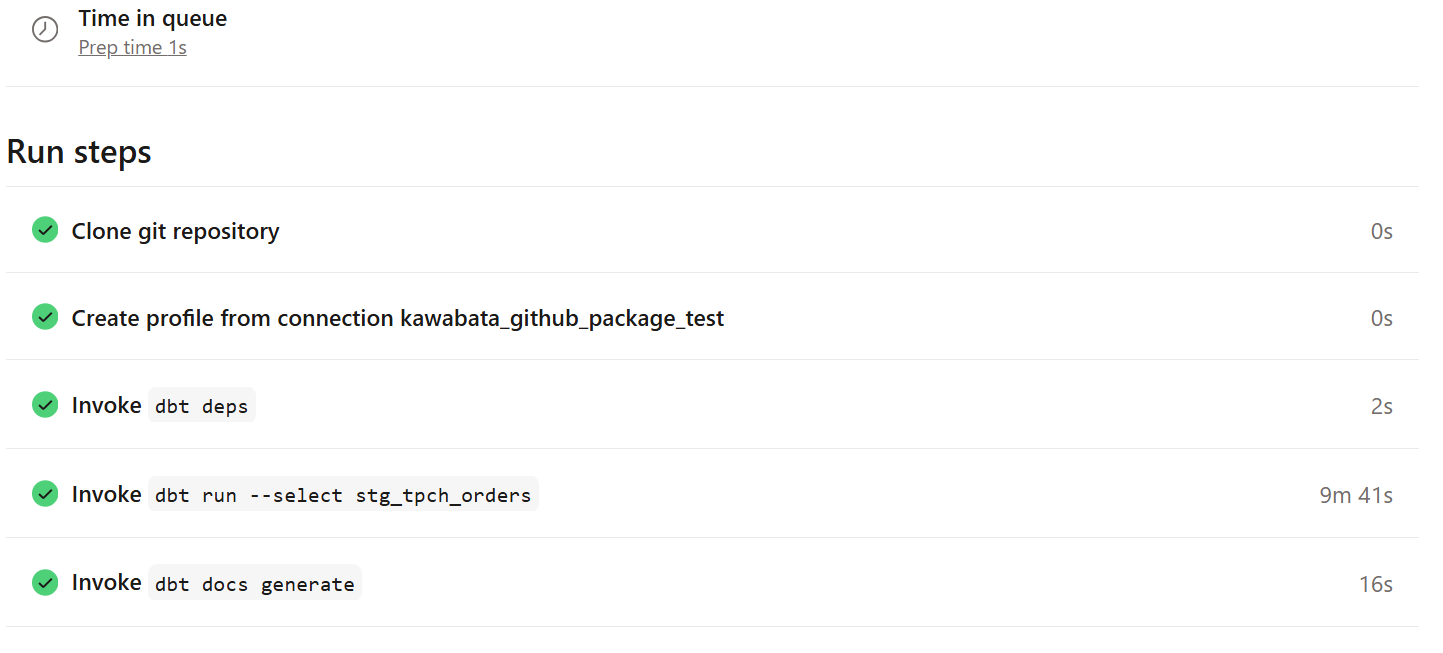
処理時間が10分ほどかかっていました。
Snowflake側も確認し、下記のようになりました。
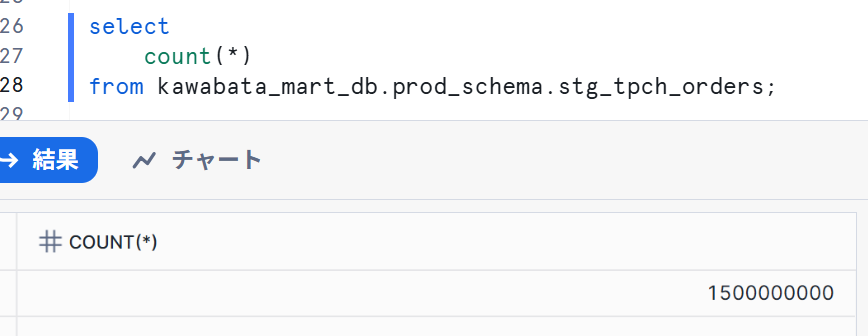
想定通り、開発環境と本番環境で動くクエリを変更することが出来ました。
データ量がそもそも多く、日付などで切り出すことが可能な場合は利用することが出来そうです!
ソースを動的変更する検証
先ほどはクエリ上で行っていましたが、データウェアハウス上で本番環境と開発環境が分かれている場合に、動的に読み込むソースを指定する方法を試していきます。
環境準備
先ほど作成した30日分のデータをDEV_RAW_DBへ、本番環境で実行したデータをPRD_RAW_DBへ格納します。
-- 検証用データベースの作成
CREATE DATABASE IF NOT EXISTS PRD_RAW_DB;
CREATE DATABASE IF NOT EXISTS DEV_RAW_DB;
-- データベース内にスキーマを作成
CREATE SCHEMA IF NOT EXISTS PRD_RAW_DB.CONFIRM;
CREATE SCHEMA IF NOT EXISTS DEV_RAW_DB.CONFIRM;
-- 6年分のデータを本番環境へ
CREATE TRANSIENT TABLE PRD_RAW_DB.CONFIRM.STG_TPCH_ORDERS
CLONE KAWABATA_MART_DB.PROD_SCHEMA.STG_TPCH_ORDERS;
-- 30日分のデータを開発環境へ
CREATE TRANSIENT TABLE DEV_RAW_DB.CONFIRM.STG_TPCH_ORDERS
CLONE KAWABATA_MART_DB.DBT_TKAWABATA.STG_TPCH_ORDERS;
dbt Cloudでsourcesを定義
dbtプロジェクトのmodelsディレクトリ内に、sources.ymlを作成し、以下のようにデータソースを定義します。
前述のとおりDevelopment credentialsでTarget nameをdevと定義しています。
また、Deploy Jobの設定画面でTarget nameをprodと定義しています。
※ジョブの設定画面は後述します。
version: 2
sources:
- name: Environment_switching_test
database: |
{%- if target.name == 'prod' -%}
prd_raw_db
{%- else -%}
dev_raw_db
{%- endif -%}
schema: confirm
tables:
- name: STG_TPCH_ORDERS
モデルの作成
以下のようにtest_ordersモデルを作成しました。
select
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_shippriority,
o_comment
from {{ source('Environment_switching_test', 'STG_TPCH_ORDERS') }}
実際に以下のように実行しました。
dbt run --select test_orders
Snowflakeで画面を確認すると、DEV_RAW_DBのSTG_TPCH_ORDERSからデータを読み込んでいることが分かりました。
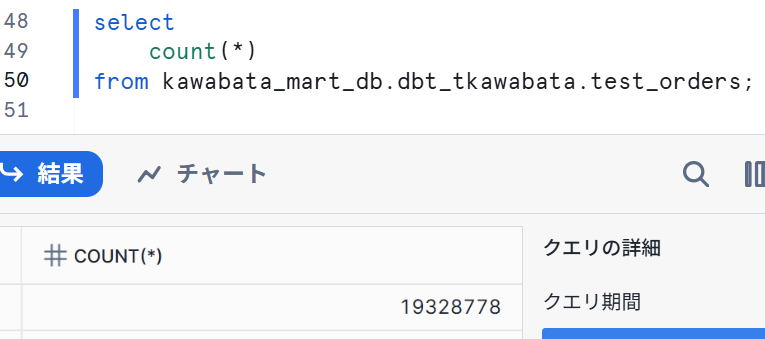
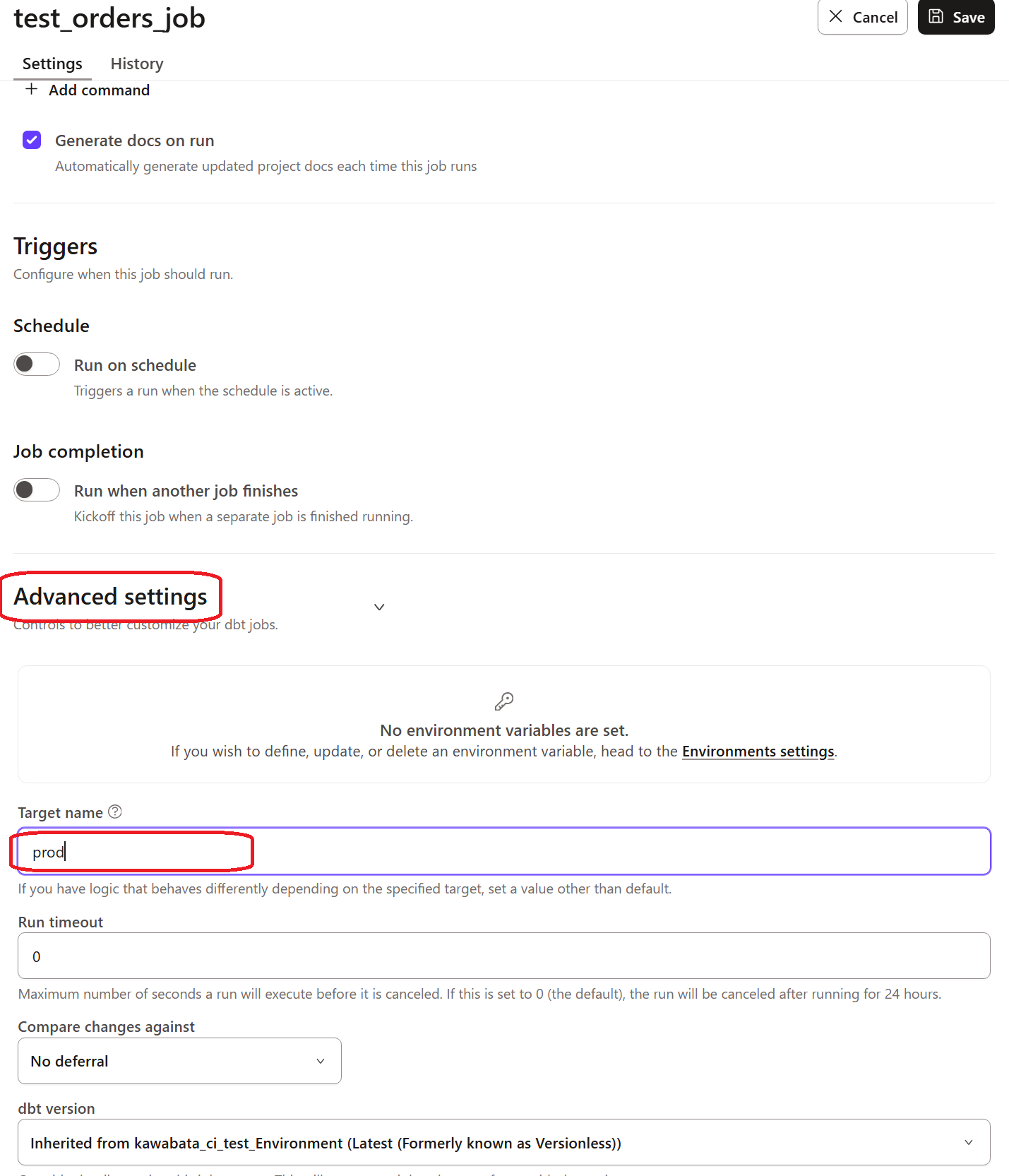
本番環境でも確認してみます。以下のようにジョブを設定しました。Advanced settingsのTarget nameへprodと記載しています。
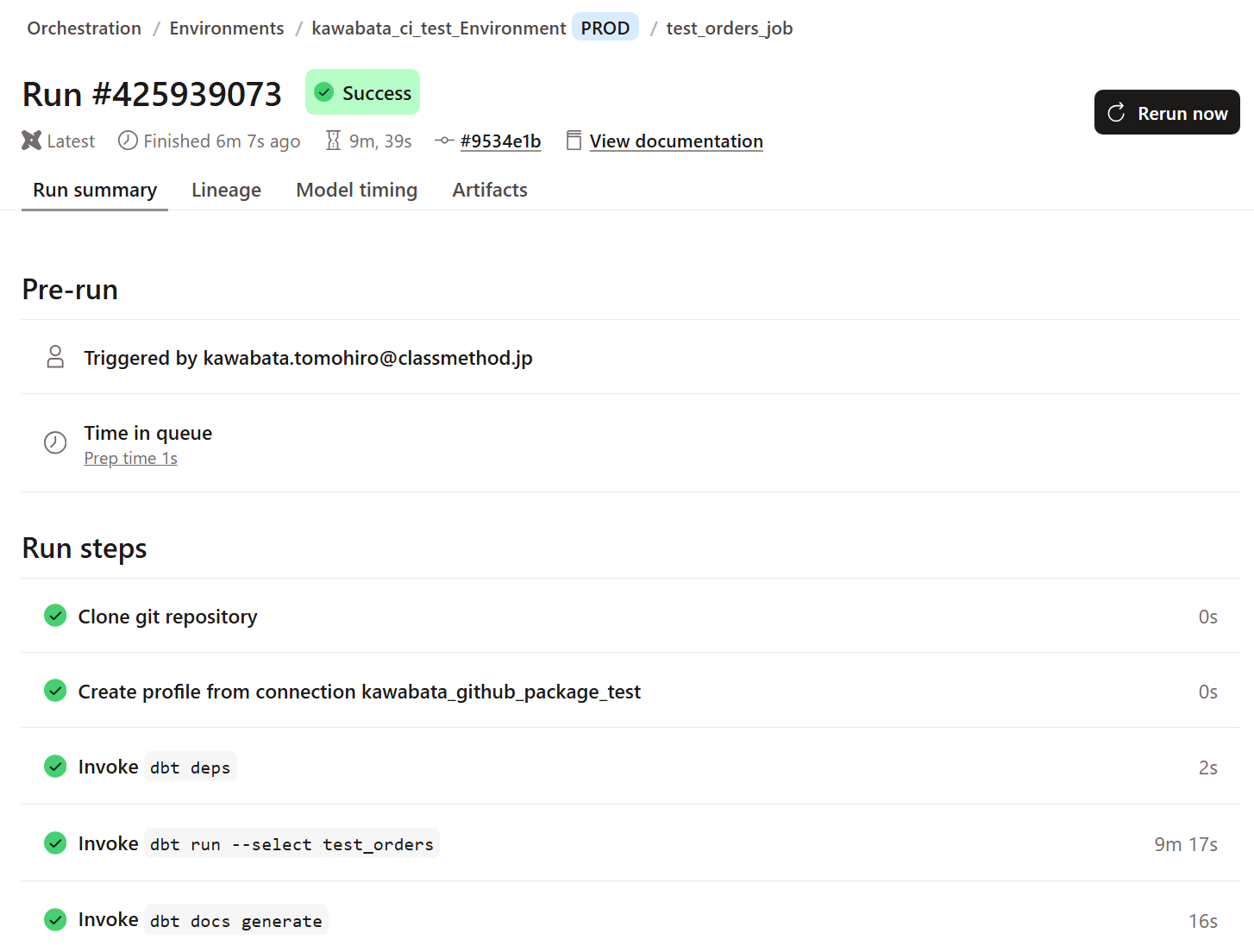
実行してみると、実行時間が伸びているので想定通りの動きをしていそうです。
Snowflakeでも確認し、以下のようになりました。
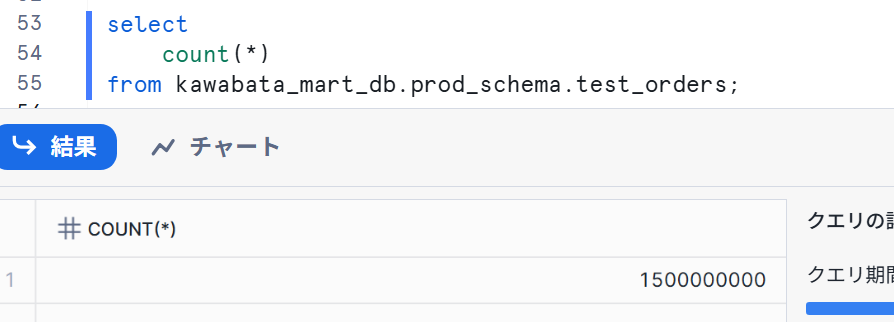
このように環境によって、読み込むソースを動的に変更することが出来ました!
まとめ
2つのパターンを試してみて、実際にどちらを使用するべきかは状況によって異なります。
以下に観点を生成AIに整理してもらいました。
| 観点 | 動的なWHERE句の実装が適しているケース | 動的なソース選択が適しているケース |
|---|---|---|
| 最優先事項 | 開発スピードとコスト効率 | セキュリティと環境の厳密な分離 |
| データアクセス | 開発者が本番データへ読み取りアクセス可能な場合 | 開発者は本番データへ一切アクセスさせたくない場合(PIIなど機密情報を含む場合) |
| データセット | ソースが巨大で、開発用のコピー作成が困難または高コストな場合 | 開発用のデータセットを容易に準備できる仕組みがある場合(例:Snowflakeのゼロコピークローン) |
| テスト要件 | 直近のデータでほとんどのテストケースをカバーできる場合 | 特定の過去データや、意図的に作成したデータでのテストが不可欠な場合 |
| チームの成熟度 | dbtを迅速に導入したい、またはシンプルな構成を維持したい場合 | データガバナンスが確立されており、環境管理の運用プロセスを構築できる場合 |
最後に
いかがでしたでしょうか。
2つのパターンで環境ごとにソースの読み込みを変更する方法を試してみましたが、それぞれ特徴が異なるので状況に合わせて活用したいです。
この記事が何かの参考になれば幸いです!










