
dbtの公式チュートリアル「Quickstart for dbt and Snowflake」をdbt Projects on Snowflakeでやってみた
さがらです。
dbt Cloud用の公式チュートリアルとして、「Quickstart for dbt and Snowflake」が提供されています。このチュートリアルはdbt自体のことを学ぶ始めの一歩として、おすすめの内容となっています。
また、2025年6月末にSnowflake内でdbtの開発・実行が行えるdbt Projects on Snowflakeがパブリックプレビューとなっています。
この「Quickstart for dbt and Snowflake」のチュートリアルをdbt Projects on Snowflakeでやってみたので、その内容を本記事でまとめてみます。
注意事項
以下のdbt Cloudを前提とした事項は本記事では対象外とします。ご注意ください。
- Managed Repositoryの利用
- 今回のチュートリアルではGit連携をせずに、開発を行います。
- dbt Projects on SnowflakeにおけるGit連携については、こちらのブログをご覧ください
- ドキュメントの閲覧
- Environment・Jobの設定(dbt Cloudのみの機能)
- dbt Projects on Snowflakeでは
profiles.ymlの定義と、dbt Projectsのデプロイ~タスク実行が該当しますので、これらの内容で代替します。
- dbt Projects on Snowflakeでは
0.事前準備
Snowflakeトライアルアカウントの作成
今回はSnowflakeのトライアルアカウントを利用しますので、トライアルアカウントを作成します。
セカンダリロールの有効化 ※もし有効化されていない場合
続いて、セカンダリロールが有効化されているかを、Workspace上で確認します。
Workspaceは、左のProjectsからWorkspacesを押せば起動できます。
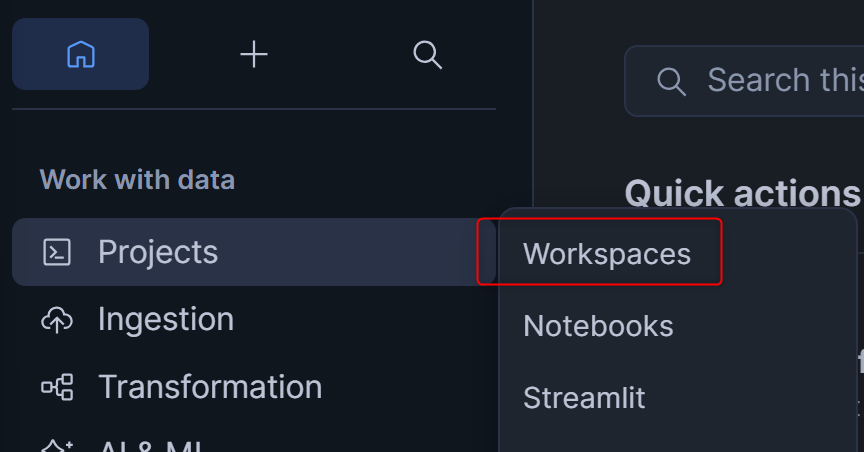
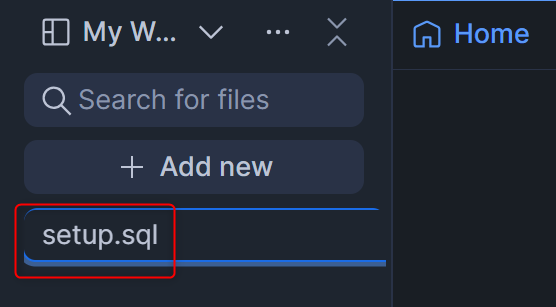
+ Add newを押して、SQL Fileを追加します。名称はsetup.sqlとします。

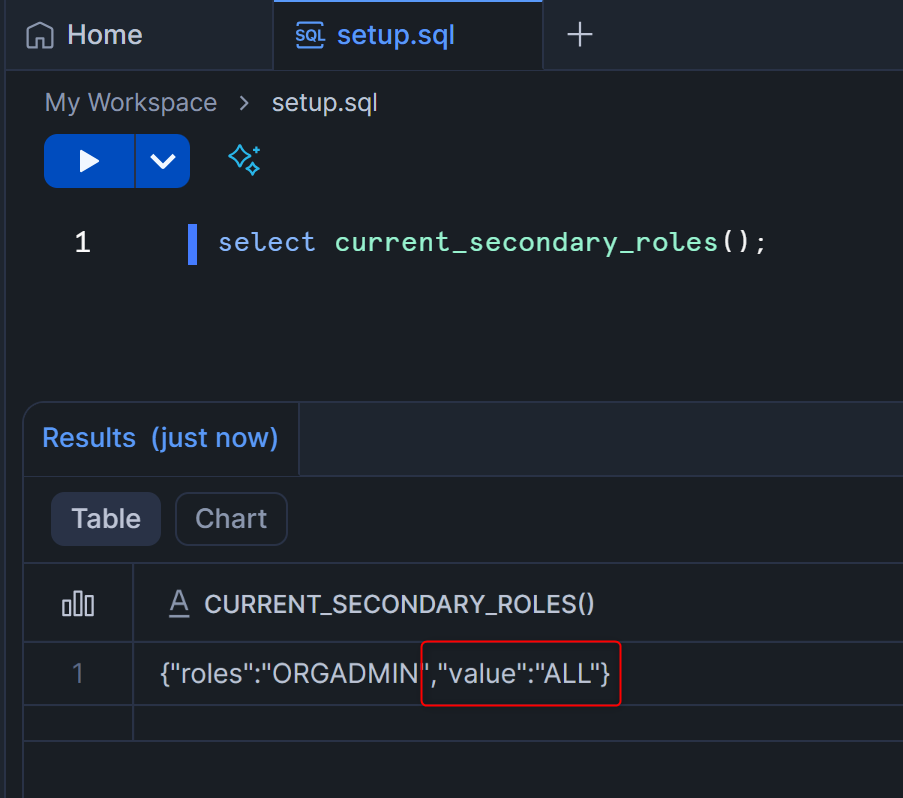
以下のクエリを貼り付けて実行し、valueが"ALL"になっていることを確認してください。
select current_secondary_roles();
もし、別の値だった場合は、以下のクエリを実行してセカンダリロールを有効化してください。
alter user <ユーザー名> set default_secondary_roles = ('all');
1.Introduction
この章では、このチュートリアルで何を行うかの説明があります。
以下はリンク先の英文を日本語に翻訳しただけですが、以下の内容を順番に行っていきます。
- 新しいSnowflakeワークシートを作成します。
- サンプルデータをSnowflakeアカウントにロードします。
- サンプルクエリをdbtプロジェクトのモデルに変換します。dbtのモデルはSELECT文です。
- dbtプロジェクトにソースを追加します。ソースを使用すると、Snowflakeに既にロードされている生データに名前を付け、説明を付けることができます。
- モデルにテストを追加します。
- モデルを文書化します。
- ジョブの実行をスケジュールします。
- ※ジョブについては、dbt Projectsのデプロイ~タスク実行で代替します。
2.Create a new Snowflake worksheet
この章では、Snowflakeでクエリを実行するためにワークシートを作成します。
なのですが、2025/11/7時点ではWorkspaceが一般提供となっており、今後ワークシートに置き換わると発表があるため、セカンダリロールの確認の際に用いたWorkspaceをそのまま使っていきます。
3.Load data
この章では、チュートリアルで使用するデータをロードします。
まず、以下のクエリを実行して、チュートリアルに必要なデータベース・スキーマ・テーブル・ウェアハウスを作成します。テーブルについてはパブリックのS3からデータロードも行います。
(セカンダリロール有効化の確認に用いたクエリはこのタイミングで削除してから、貼り付けましょう。)
注意点として、8行目のcreate schema analytics.dbt_ssagara;については、ご自身の名前などを用いて、自分のスキーマであることがわかるようにしてください。(私はsagara satoshiという名前のため、dbt_ssagaraとしています。)
use role accountadmin;
create warehouse transforming;
create database raw;
create database analytics;
create schema raw.jaffle_shop;
create schema raw.stripe;
create schema analytics.dbt_ssagara;
create schema analytics.prod;
create table raw.jaffle_shop.customers
( id integer,
first_name varchar,
last_name varchar
);
copy into raw.jaffle_shop.customers (id, first_name, last_name)
from 's3://dbt-tutorial-public/jaffle_shop_customers.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
create table raw.jaffle_shop.orders
( id integer,
user_id integer,
order_date date,
status varchar,
_etl_loaded_at timestamp default current_timestamp
);
copy into raw.jaffle_shop.orders (id, user_id, order_date, status)
from 's3://dbt-tutorial-public/jaffle_shop_orders.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
create table raw.stripe.payment
( id integer,
orderid integer,
paymentmethod varchar,
status varchar,
amount integer,
created date,
_batched_at timestamp default current_timestamp
);
copy into raw.stripe.payment (id, orderid, paymentmethod, status, amount, created)
from 's3://dbt-tutorial-public/stripe_payments.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
この後、以下のクエリを順番に実行して、問題なくデータが各テーブルにロードされていることを確認します。
select * from raw.jaffle_shop.customers;
select * from raw.jaffle_shop.orders;
select * from raw.stripe.payment;

4.Connect dbt to Snowflake
この章では、dbt CloudからSnowflakeへの接続の設定を行うのですが、dbt Projeccts on Snowflakeでは不要のため、スキップします。
5.Set up a dbt managed repository
この章では、dbt Cloud特有の機能であるManaged Repositoryのセットアップを行うのですが、dbt Projeccts on Snowflakeでは関係のない設定のため、スキップします。
本記事冒頭の注意事項でも書いたように、今回のチュートリアルではGit連携をせずに開発を行います。
参考までに、dbt Projects on SnowflakeにおけるGit連携については、以下のブログをご覧ください。
6.Initialize your dbt project and start developing
この章では、dbt Projectのセットアップを行います。dbt Projects on Snowflake自体の操作に移ります!
画面左上の+ Add newを押し、dbt Projectを押します。
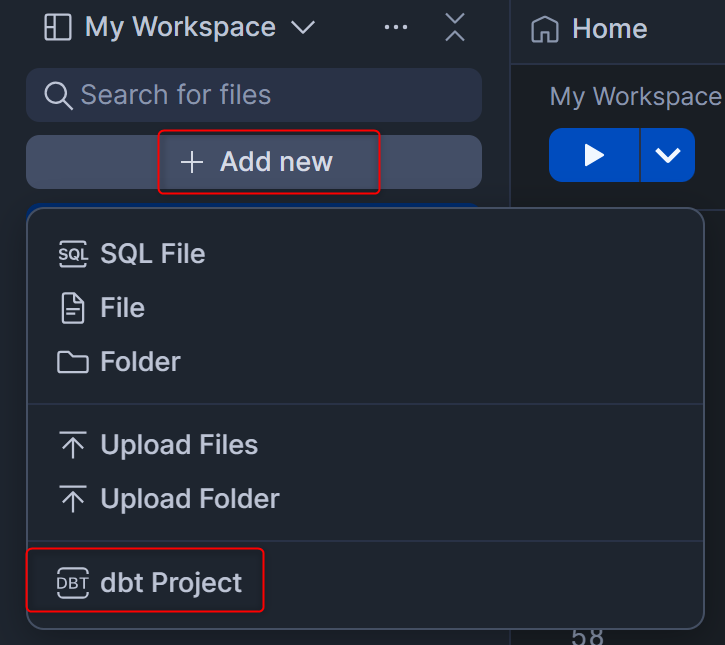
表示されたポップアップで以下の内容を入力して、右下のCreateを押します。
Project Name:dbt_quickstart- 任意の名称でOKです
Role:accountadmin- Workspace内のdbt Projectsを介してクエリが実行されるときに利用されるロール。今回はチュートリアルのためACCOUNTADMINを利用しますが、使用するデータベース・スキーマ・テーブルの参照権限と、dbtを介してオブジェクトを作りたい作成先となるデータベース・スキーマの作成権限があるロールであればOKです。
Warehouse:transforming- Workspace内のdbt Projectsを介してクエリが実行されるときに利用されるウェアハウス
Database:analytics- dbtの出力先となるデータベース
Schema:dbt_ssagara- dbtの開発時の出力スキーマ
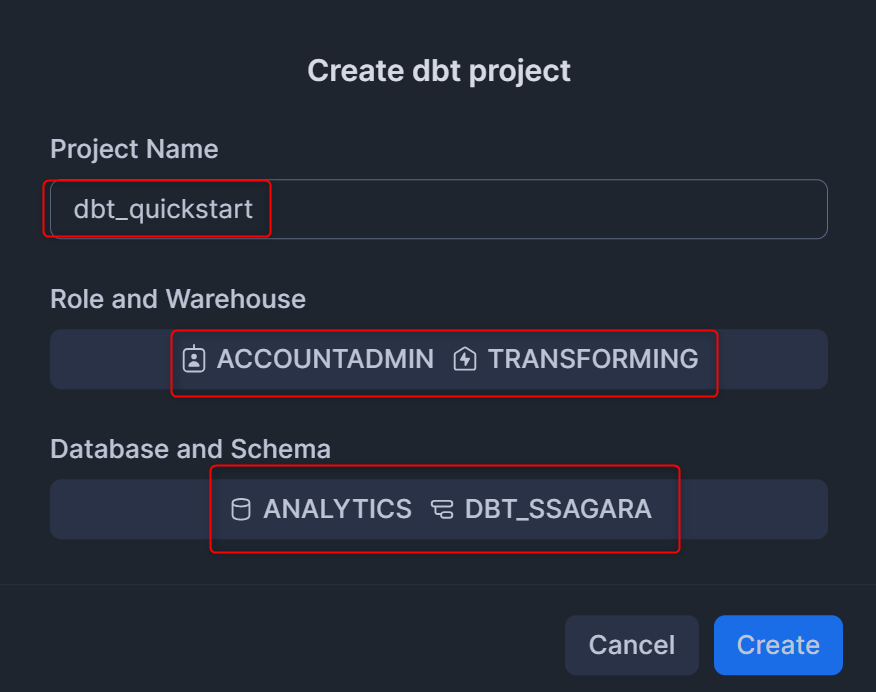
この操作により、新しいdbt Projectが作られます!
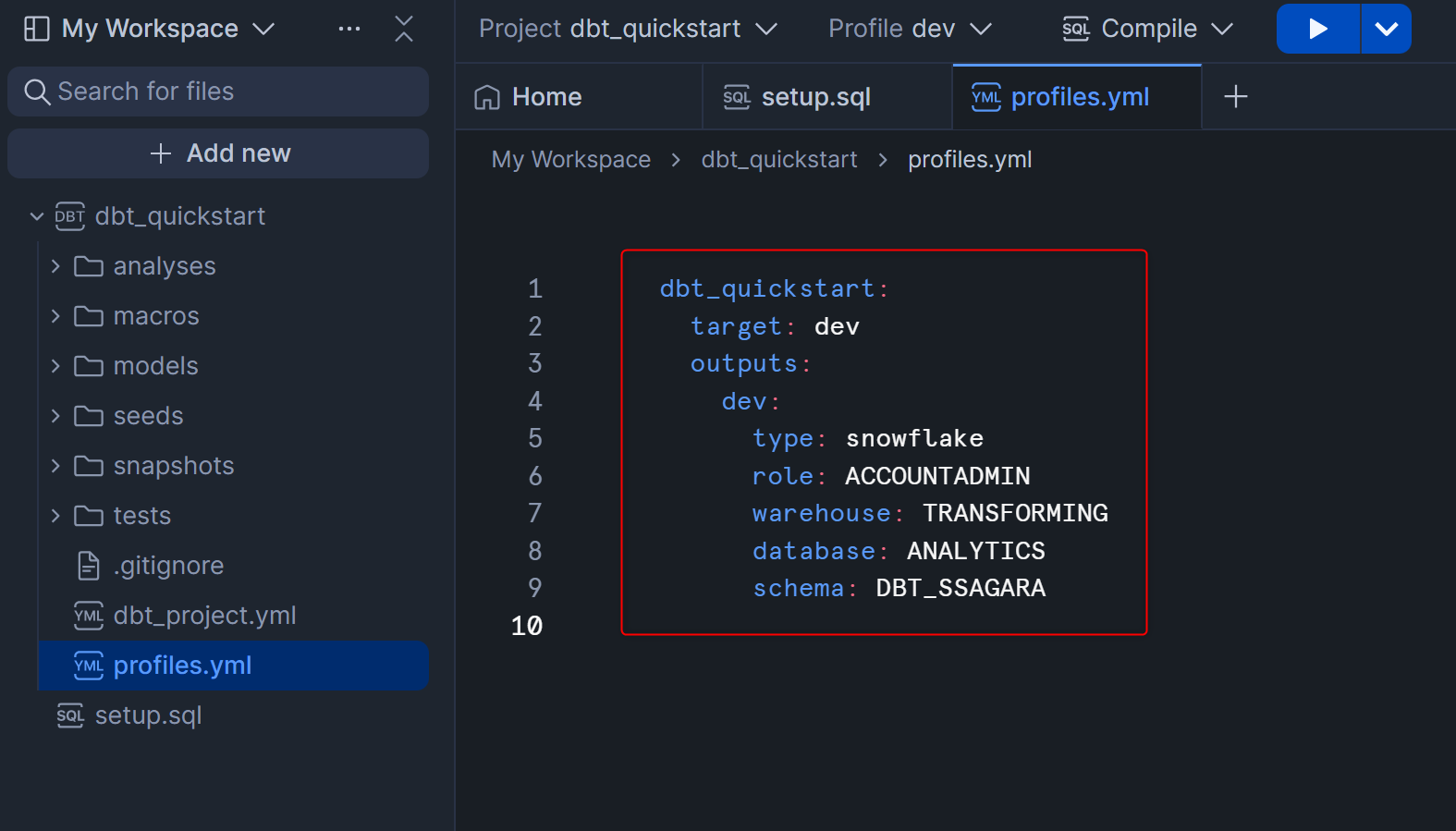
先ほど入力した内容は、profiles.ymlに記載されます。profiles.ymlについての公式ドキュメントはこちらになります。
profiles.ymlの内容を見ると、dev:と記載されていますが、これはdbtでいう開発環境・本番環境などdbtコマンドの実行先となる環境を切り替える際に利用できるtargetの名前となります。(dev以外の名前を設定しても問題ありませんが、現在設定されているprofileは開発環境向けなのでdevで問題ないと思います。)
また、target: devとなっていますが、これは「dbtコマンド実行時にtargetを指定しない場合はdevを使うよ」ということを意味しています。本番環境に対するprofileも後でprofiles.ymlに追記しますが、不用意なコマンドで本番環境を変更してしまわないように、target: devのまま変えないことを推奨します。
また、このタイミングで一度dbt runを実行してみます。dbt runは、modelsフォルダ内にある.sqlファイルで書かれたSELECT文を全て、指定したデータベース・スキーマに対してCTAS・CVAS文として実行するコマンドです。
右上のコマンドを指定するボタンからRunを選択し、再生ボタンを押します。
すると、Workspaceの下部にログが流れます。
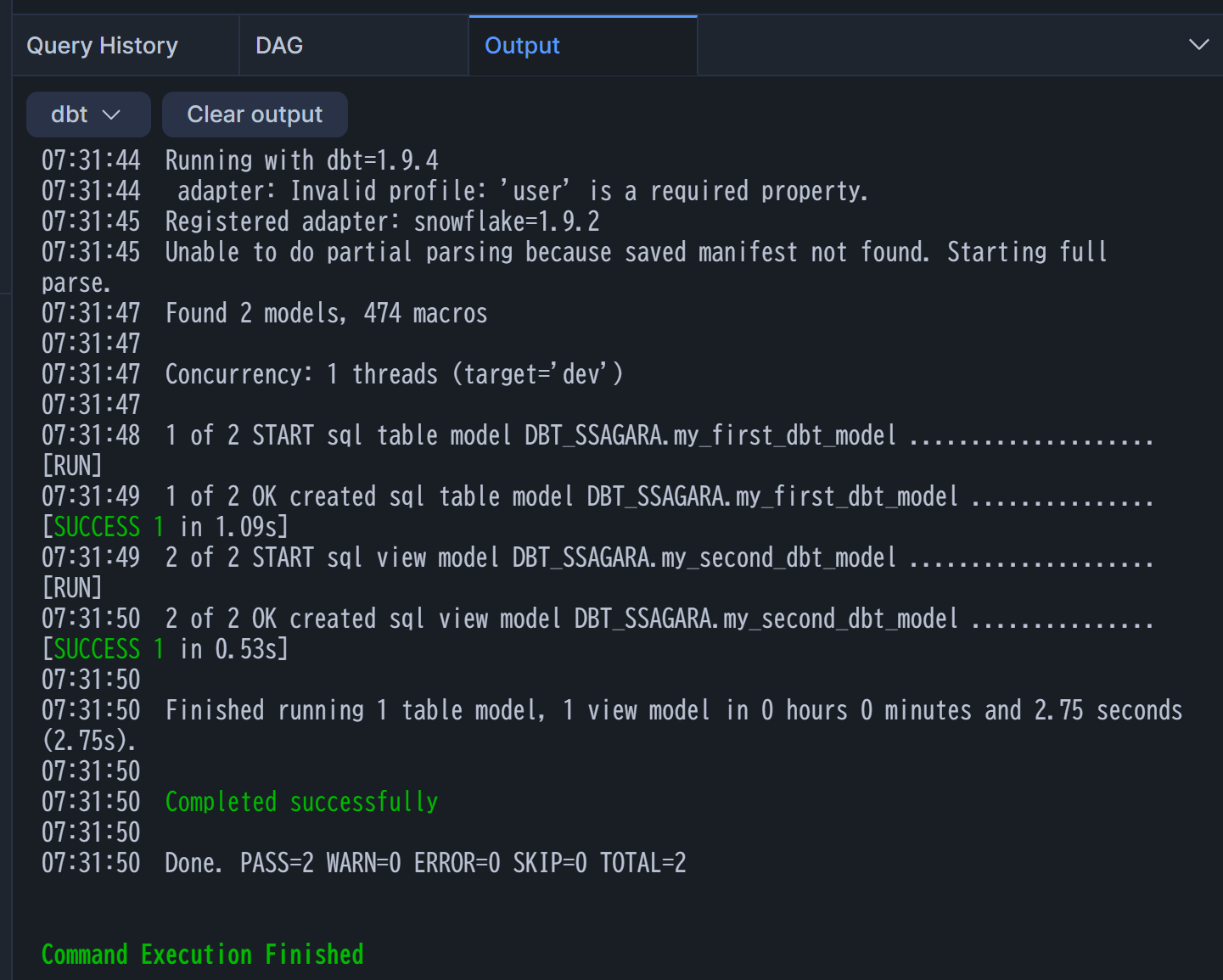
処理が完了したら、Workspace左下のObject Explorerからdbt_ssagaraスキーマを確認してみます。デフォルトでmodelsフォルダに入っていたMY_FIRST_DBT_MODELとMY_SECOND_DBT_MODELが作られているのがわかりますね!
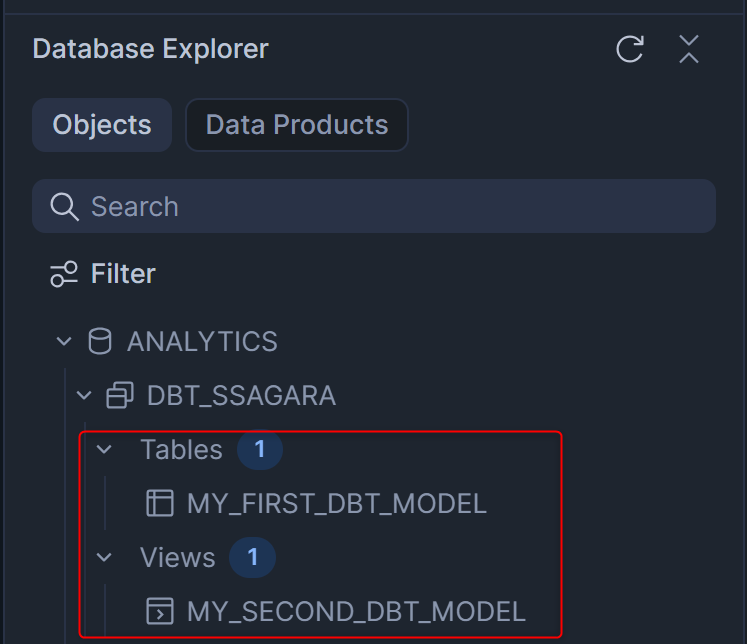
MY_FIRST_DBT_MODELとMY_SECOND_DBT_MODELは、dbt Projectを作成した時にデフォルトでmodelsフォルダに入っていた.sqlファイルです。dbtの開発では、基本的にmodelsフォルダ内で.sqlや.ymlファイルを開発していくことになります。
※「model」というワードですが、dbtではmodelsフォルダに格納された.sqlファイルを「model」と呼びます。
my_first_dbt_model.sql

my_second_dbt_model.sql
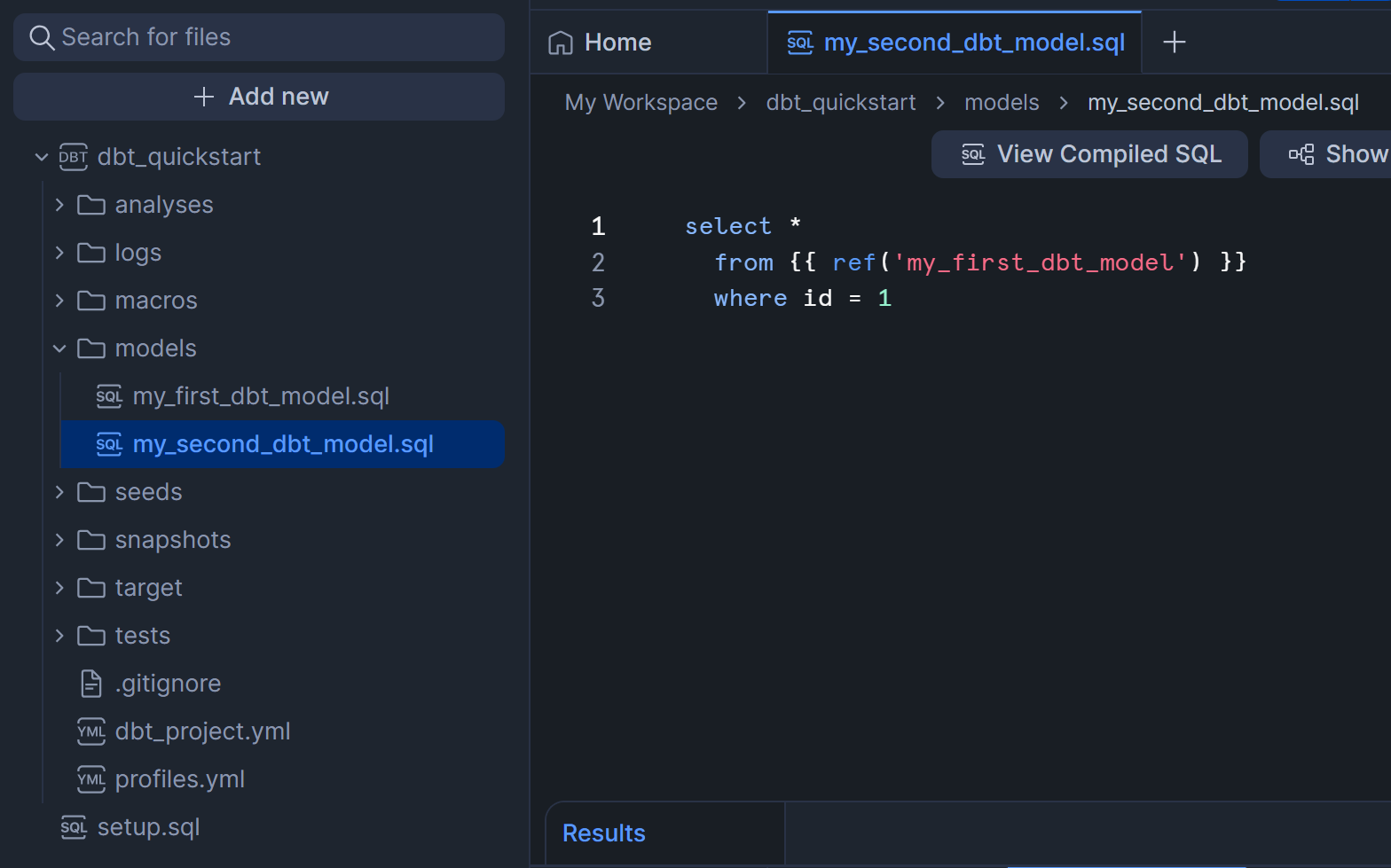
7.Build your first model
この章では、Snowflakeにロードしたデータを用いた新しい.sqlファイルを作成して、dbt runを実行してみます。
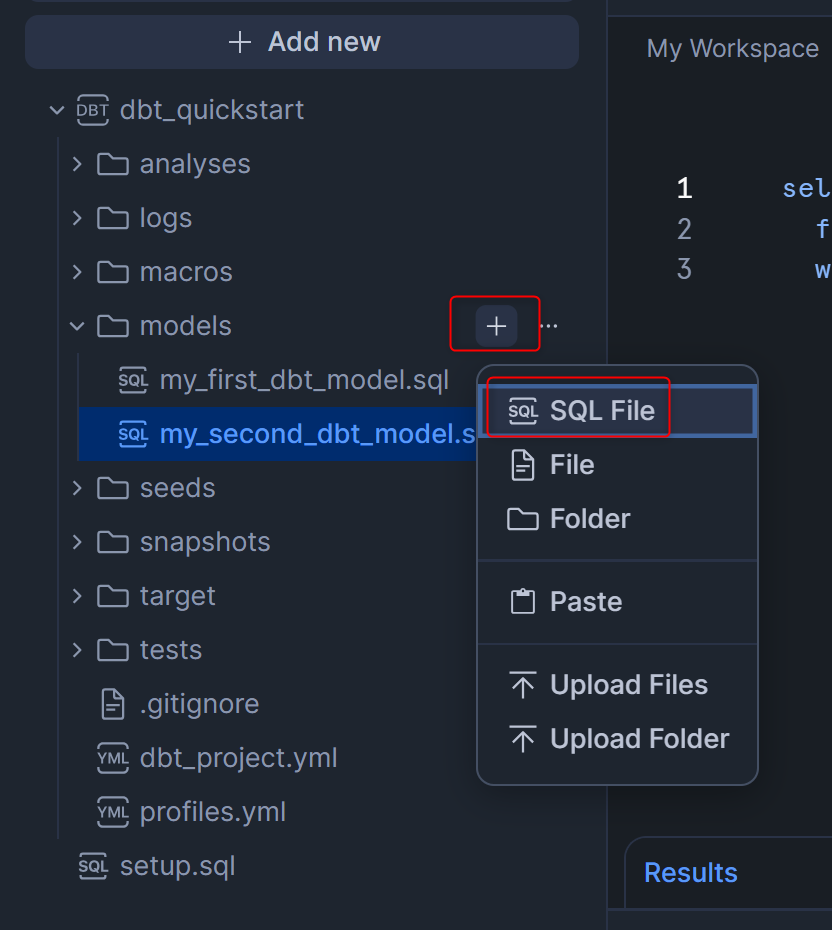
modelsフォルダの横の+を押してSQL Fileを選択し、customers.sqlというファイルを作成します。

右側のエディター欄でcustomers.sqlを編集できるようになりましたので、以下のSQLをコピーして貼り付けます。
with customers as (
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
貼り付けた後は下図のようになると思います。

dbt runを実行するため、右上のコマンドを指定するボタンからRunを選択し、再生ボタンを押します。
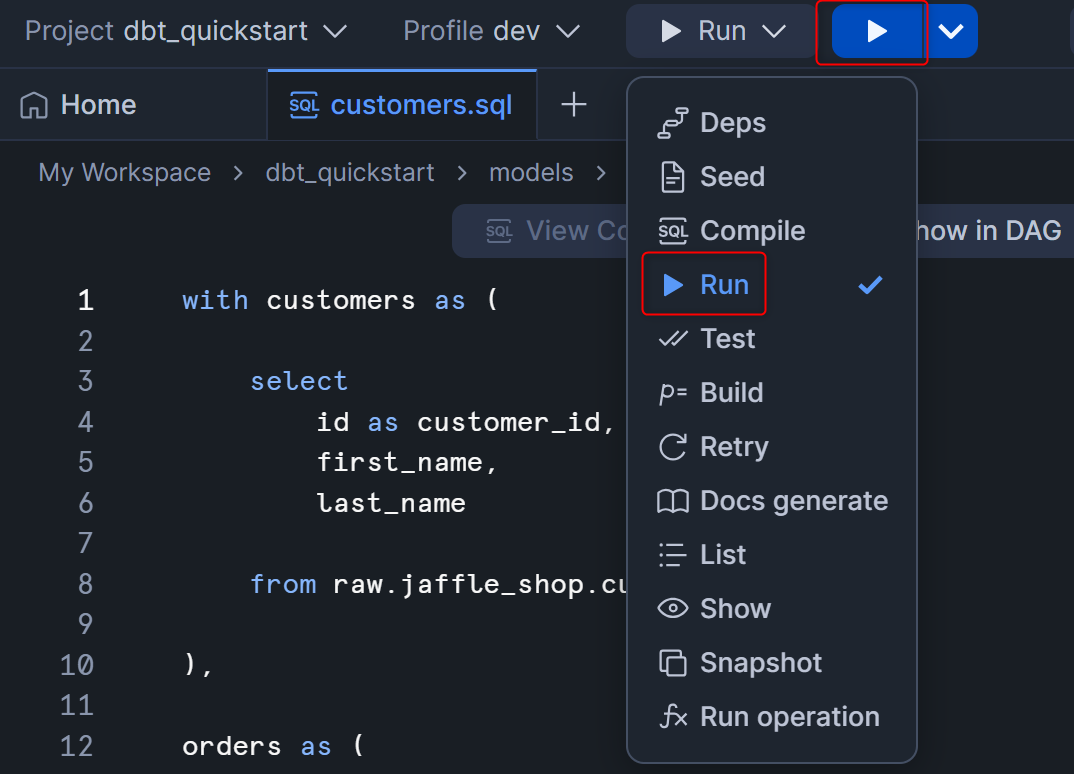
処理が完了したら、Workspace左下のObject Explorerからdbt_ssagaraスキーマを確認してみます。CUSTOMERSというビューが作られていることがわかります。

8.Change the way your model is materialized
この章では、Snowflakeに対してテーブル・ビューなど、どの方法で作成するのかを設定するMaterializationについて、試していきます。
まず、dbt_project.ymlを開きます。このファイルは、dbt Project全体の設定やフォルダパスの指定などを行える、dbtにとって必須のファイルとなります。
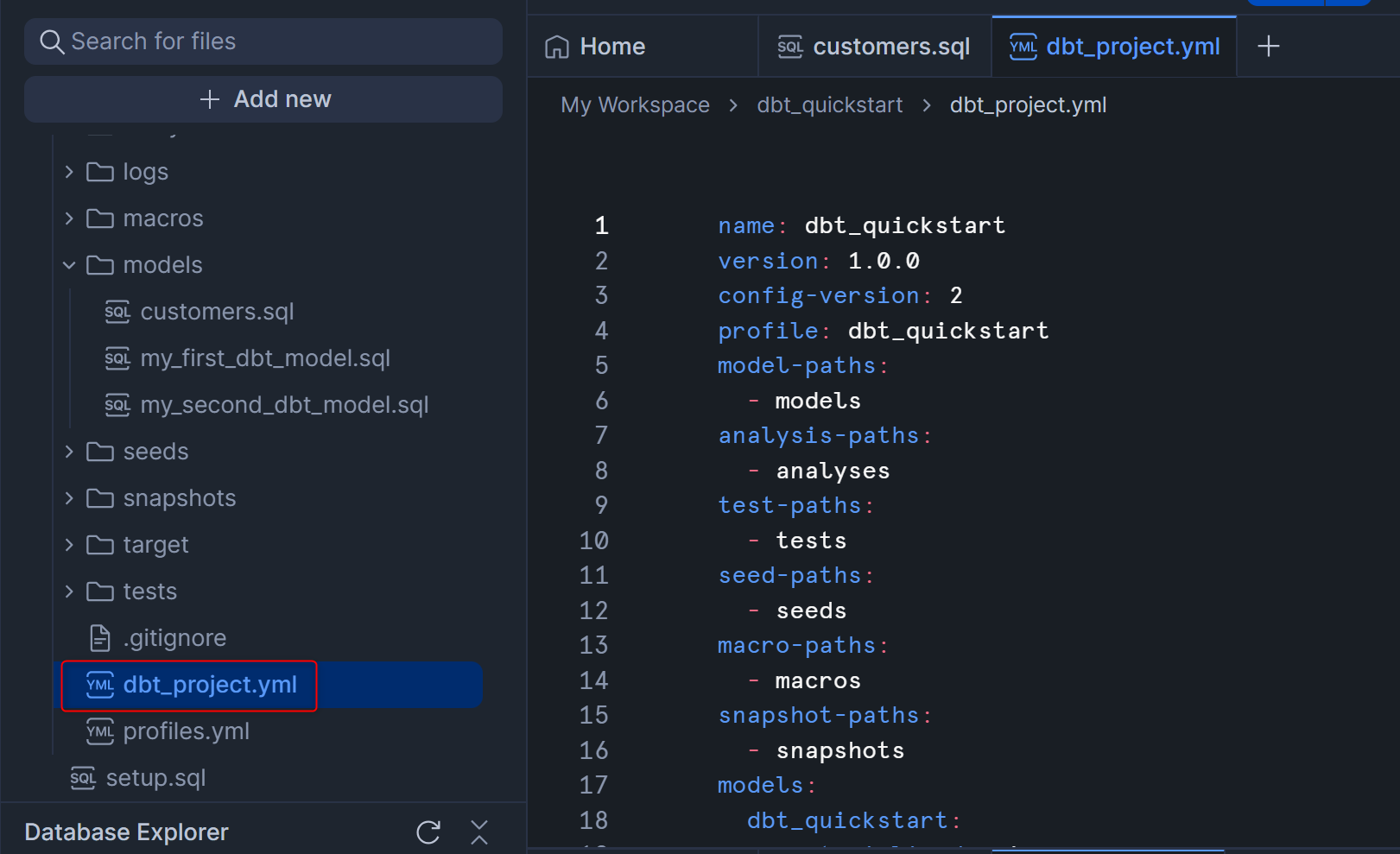
最下部のmodels:のコードを、下記のように書き換えます。
- Before
models:
dbt_quickstart:
+materialized: view
- After
models:
dbt_quickstart:
+materialized: table
書き換えたあとは下図のようになります。
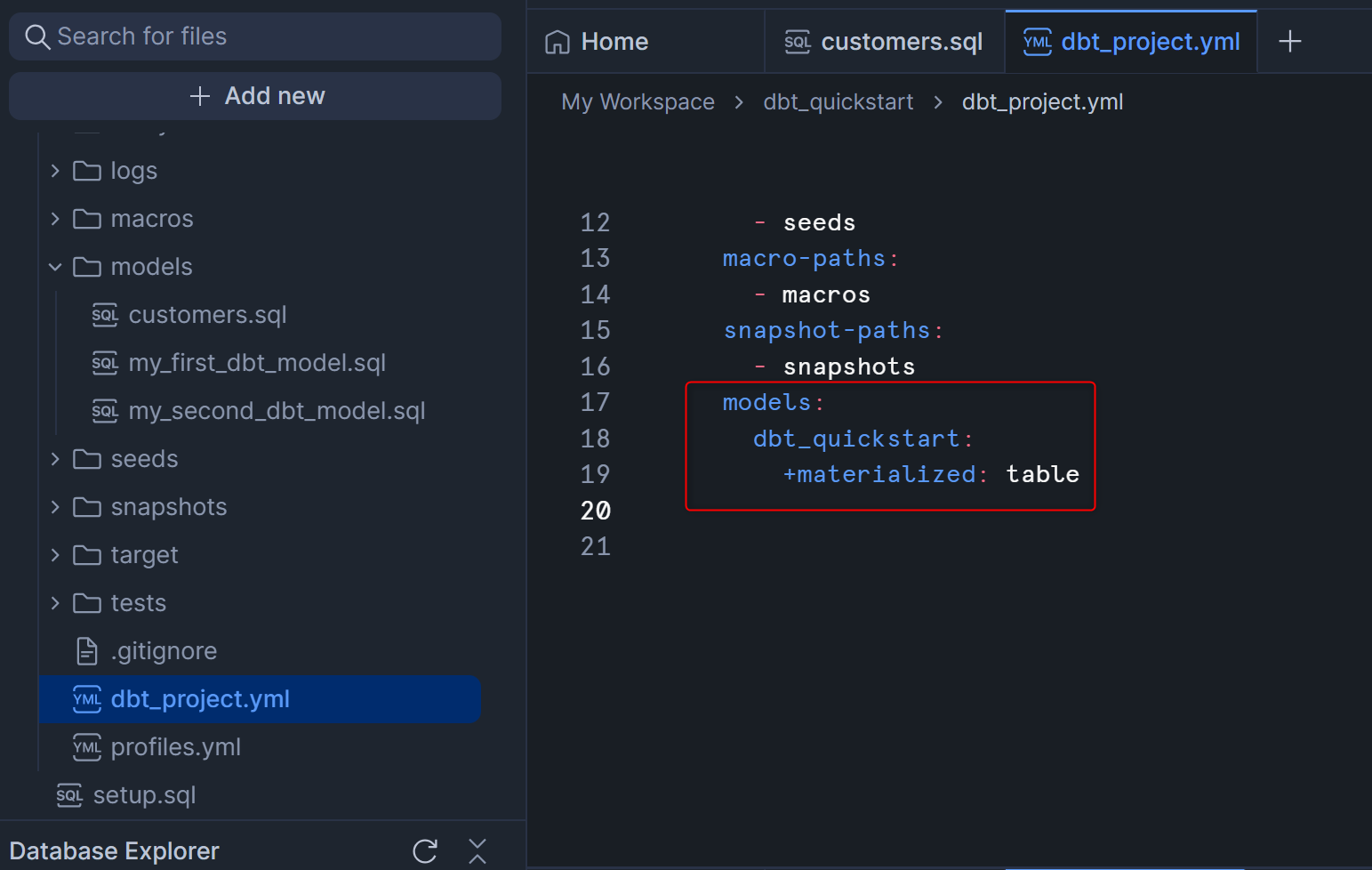
この状態でdbt runを実行してどう変わるか挙動を確認します。右上のコマンドを指定するボタンからRunを選択し、再生ボタンを押します。
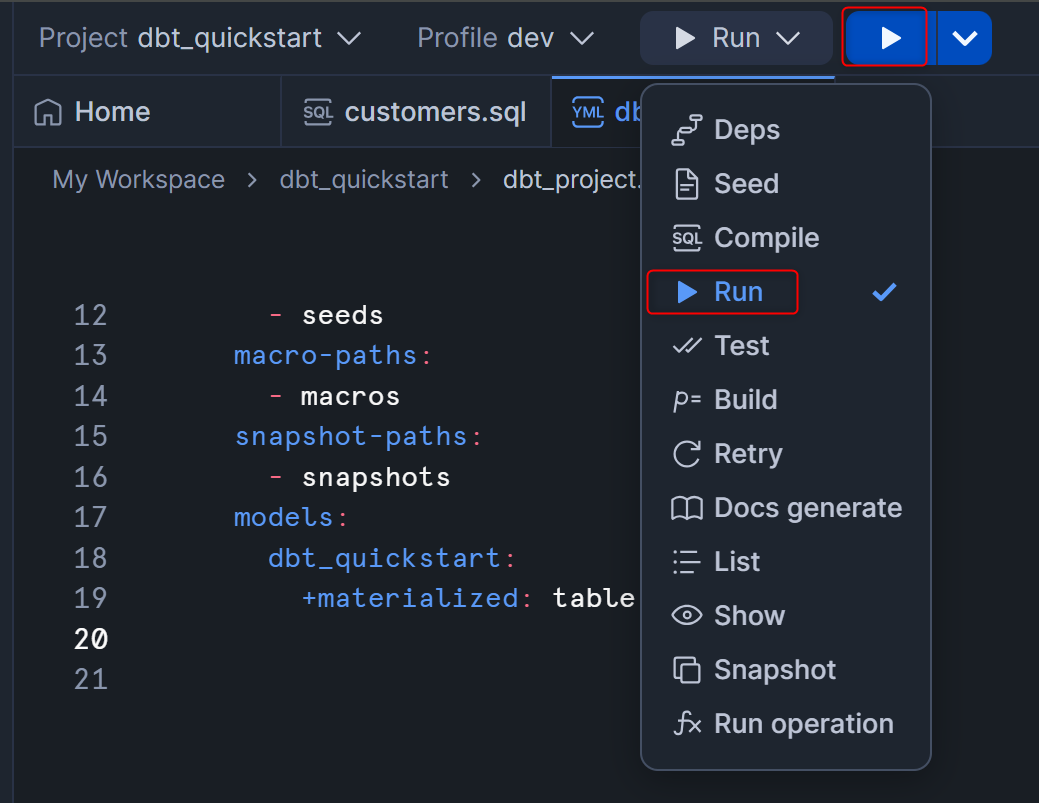
処理が完了したら、Workspace左下のDatabase Explorerからdbt_ssagaraスキーマを確認してみます。全てテーブルで作られていることがわかると思います。

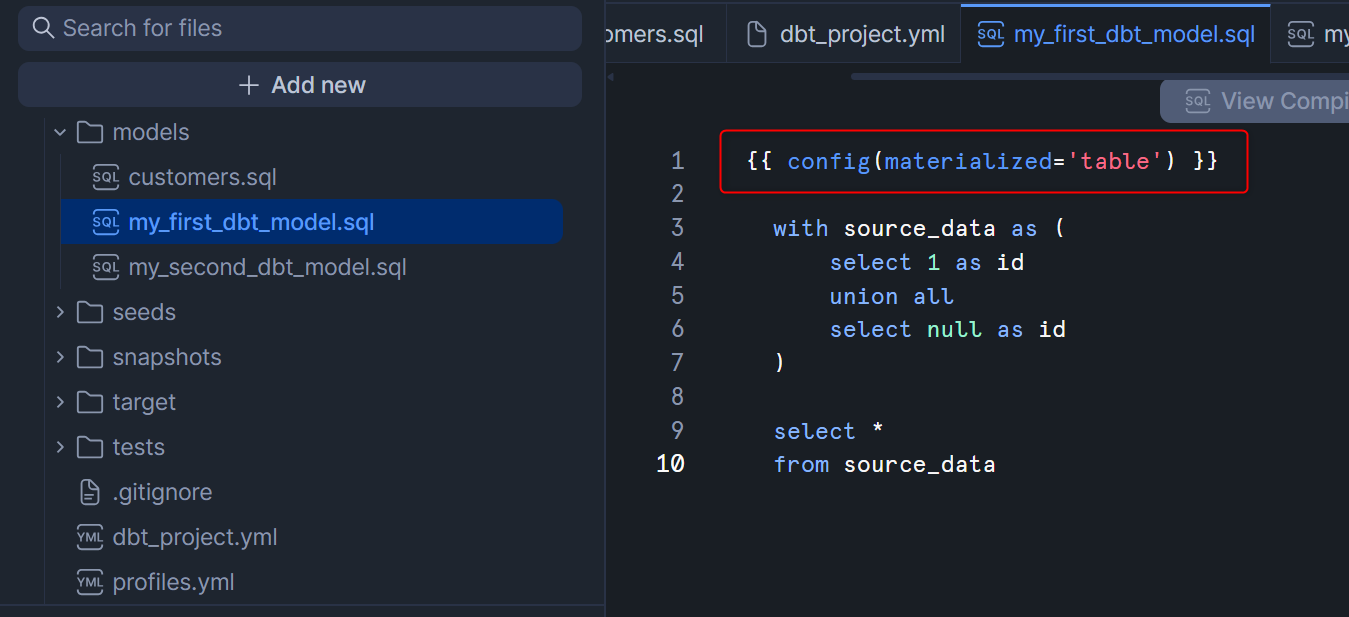
参考情報として、Materializationの設定はdbt_project.ymlでプロジェクト全体やフォルダレベルで設定することに加えて、各.sqlファイル内でも指定可能です。例としてmy_first_dbt_model.sqlを見ると、下図のようにconfigの指定があると思います。dbt_project.ymlでも.sqlファイルでも同じconfigの設定がある場合は、.sqlファイルの方が優先される仕様となっています。
もう一つ参考情報として、Materializationはテーブルとビューだけでなく、増分更新に対応したincremental、オブジェクトは生成せずWITH句として使われるだけのephemeral、もあります。これらの詳細については以下の公式ドキュメントをご覧ください。
9.Delete the example models
この章では、デフォルトで追加されていたサンプルの.sqlファイルを削除します。
modelsフォルダから、my_first_dbt_model.sqlとmy_second_dbt_model.sql、それぞれ横の「・・・」を押し、Deleteを押します。
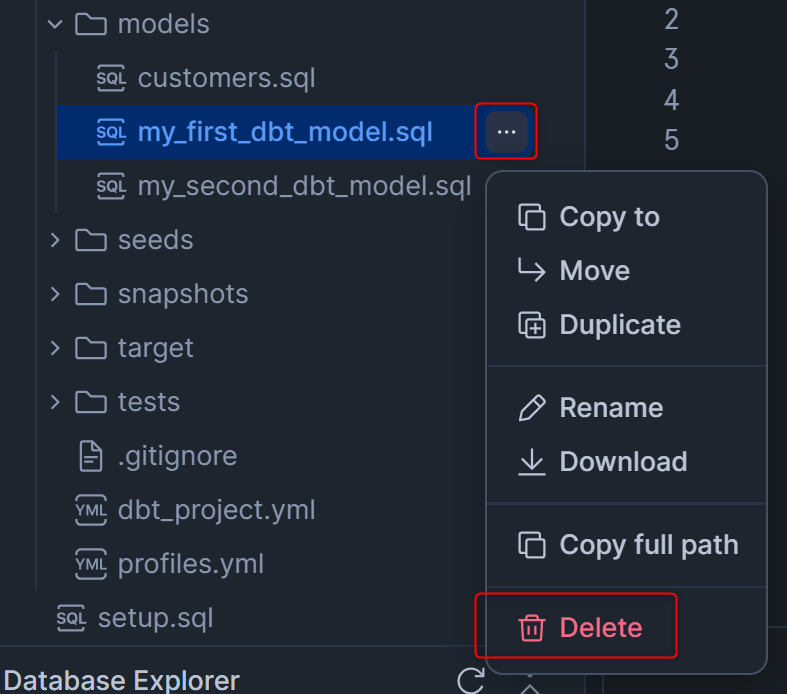

これでこの章で行うこととしては終わりなのですが、注意点としては、dbtは.sqlファイルが削除されたからといって、その.sqlファイルに対応するテーブル・ビューが削除される仕様ではないということです。.sqlファイル削除後は、ユーザー側で手動のSQLコマンド実行はもちろん、何かしらの方法でテーブル・ビューを削除する必要がありますのでご注意ください。
10.Build models on top of other models
この章では、dbtのベストプラクティスに沿って、データをクリーンアップするロジックを分解して別の.sqlファイルを作っていきます。(Staging層に該当します。)
まず、Staging層となる以下2つの新しい.sqlファイルをmodelsフォルダの直下に作成します。
stg_customers.sql
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
stg_orders.sql
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
この2つの.sqlファイル作成後は、下図のようなフォルダ構成となっていると思います。
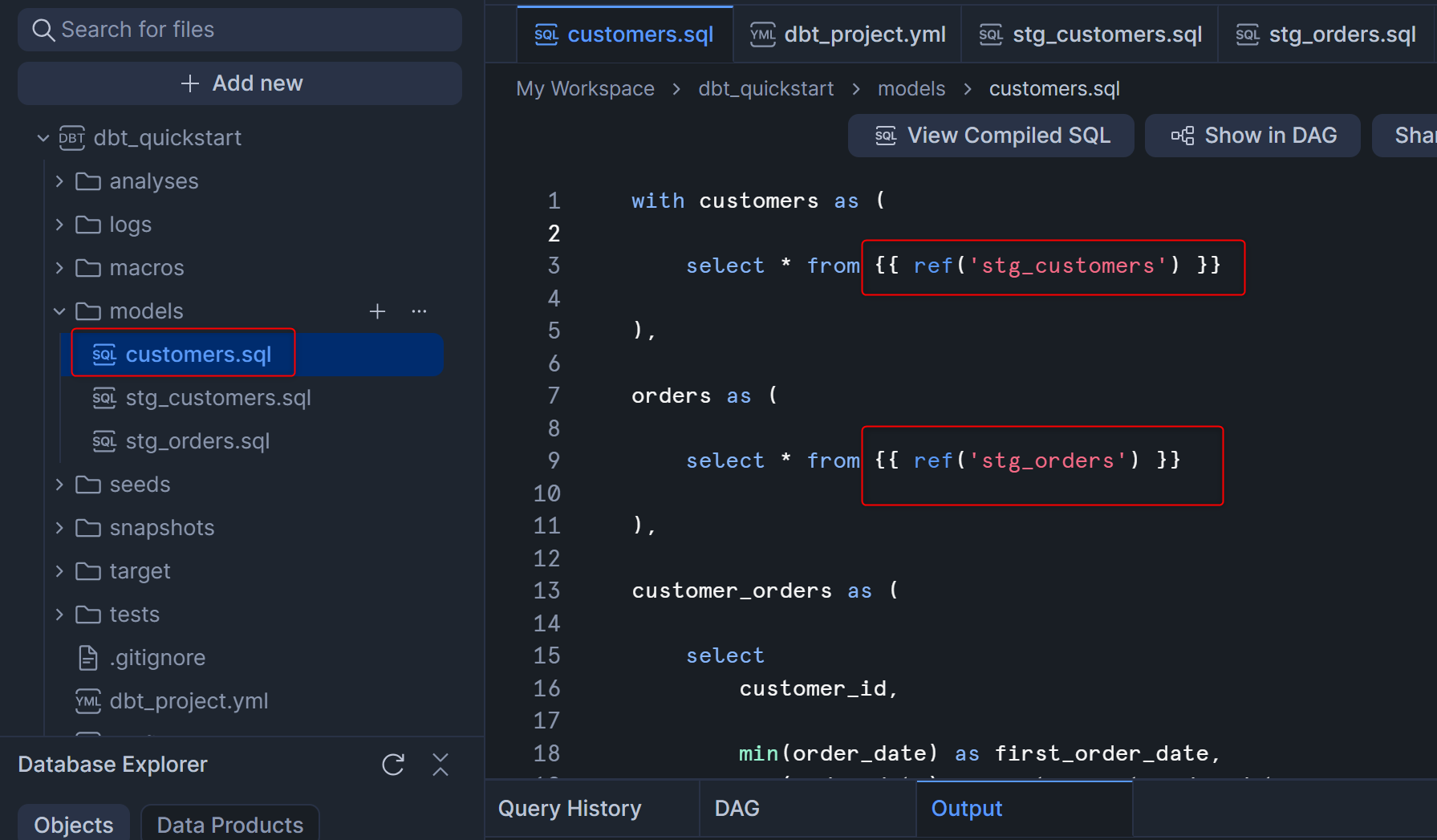
この後、先程作成していたcustomers.sqlも以下の内容に書き換えます。ポイントは、{{ ref() }}という書き方で既存の.sqlファイルの名前部分を指定することで、指定した.sqlファイルの実行が終わった後にこの.sqlファイルを実行するように処理の依存関係を構築することができます。
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
customers.sqlを書き換えたあとは、下図のようになっていると思います。
このModel間の依存関係をWorkspace上で確認できるため、各SQLファイルをコンパイルするdbt compileコマンドを実行します。

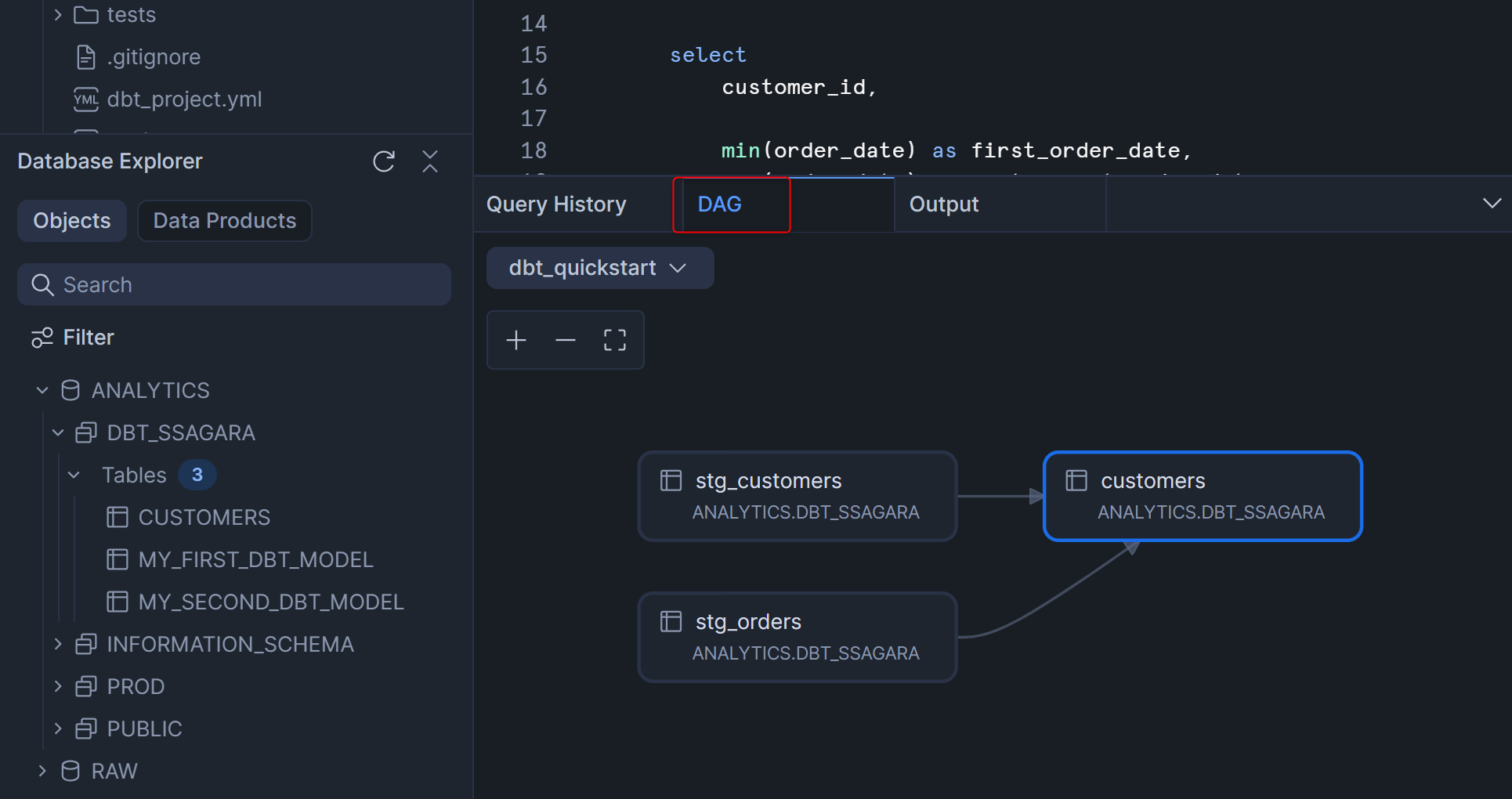
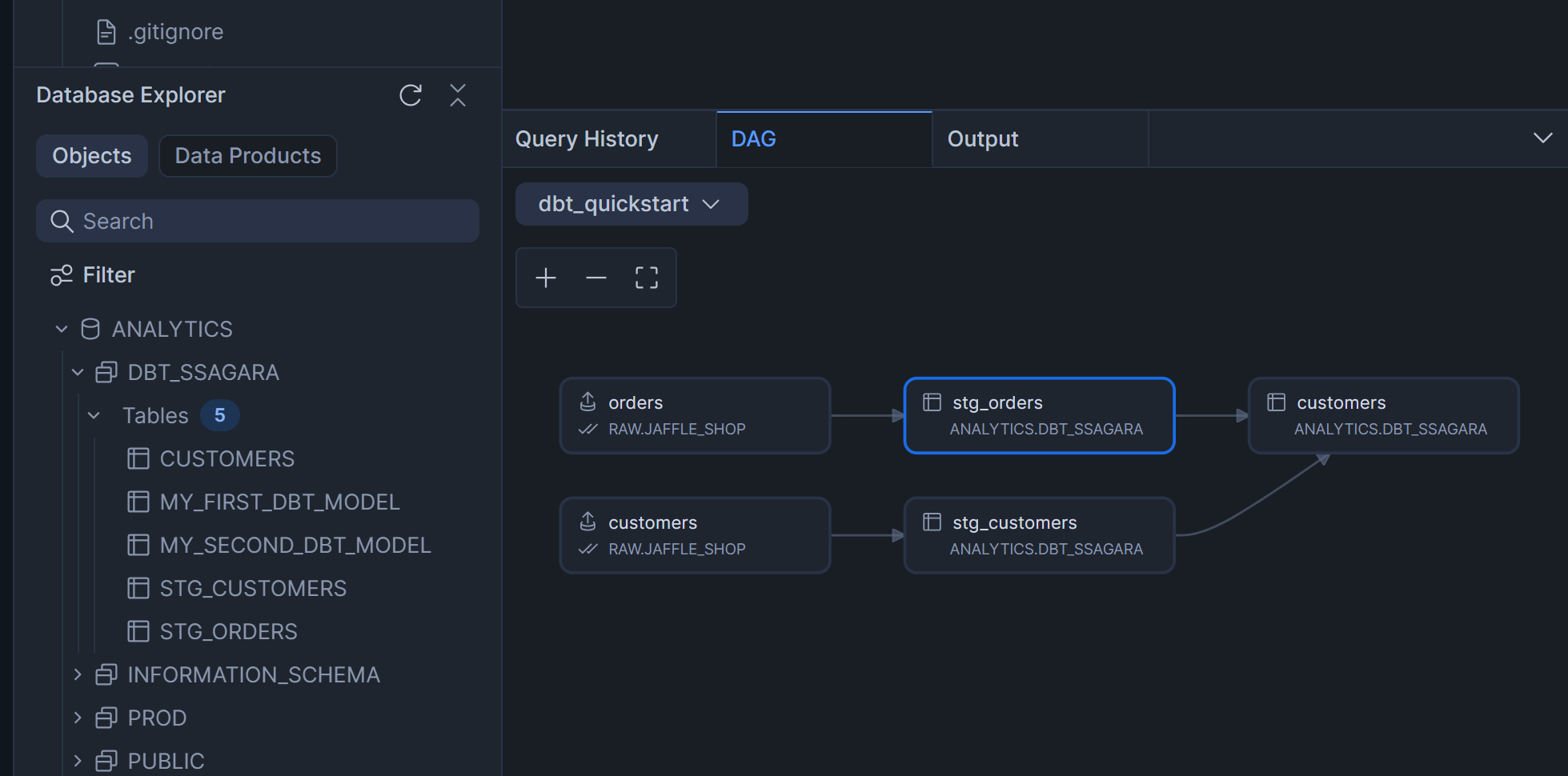
dbt compileコマンド実行後、Workspaceの画面右下のDAGを押すと、下図のように依存関係を表したリネージが表示されます。
この章の最後に、dbt runを実行して開発環境のスキーマに出力してみます。右上のコマンドを指定するボタンからRunを選択し、再生ボタンを押します。

処理が完了したら、Workspace左下のDatabase Explorerからdbt_ssagaraスキーマを確認してみます。新しく作成した2つの.sqlファイルが、テーブルとして出力されていることがわかります。
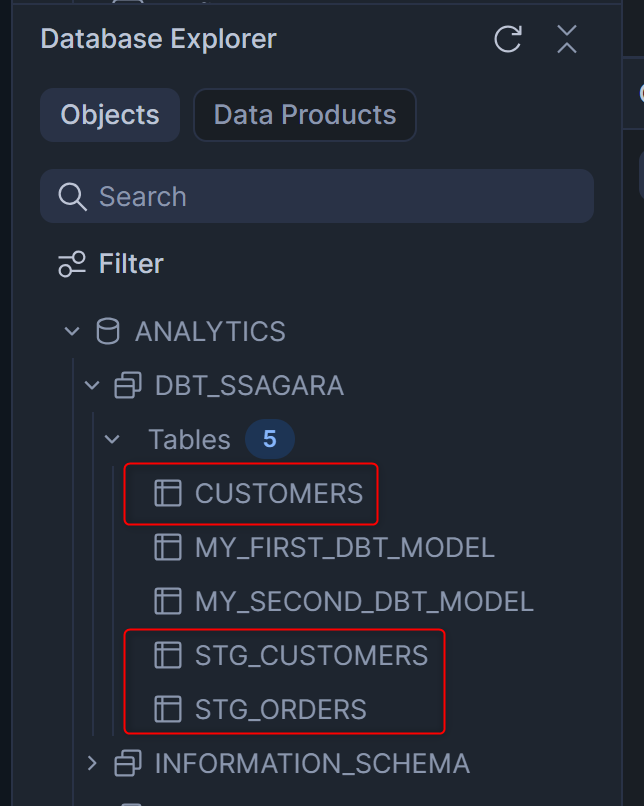
11.Build models on top of sources
この章では、dbtでの加工元となるソースデータを定義する「source」の設定を行っていきます。sourceを設定することで、リネージ上にソースデータを表示したり、12章で行うテストをソースデータに対して行った後にdbtでの変換を行う、ということが可能となります。
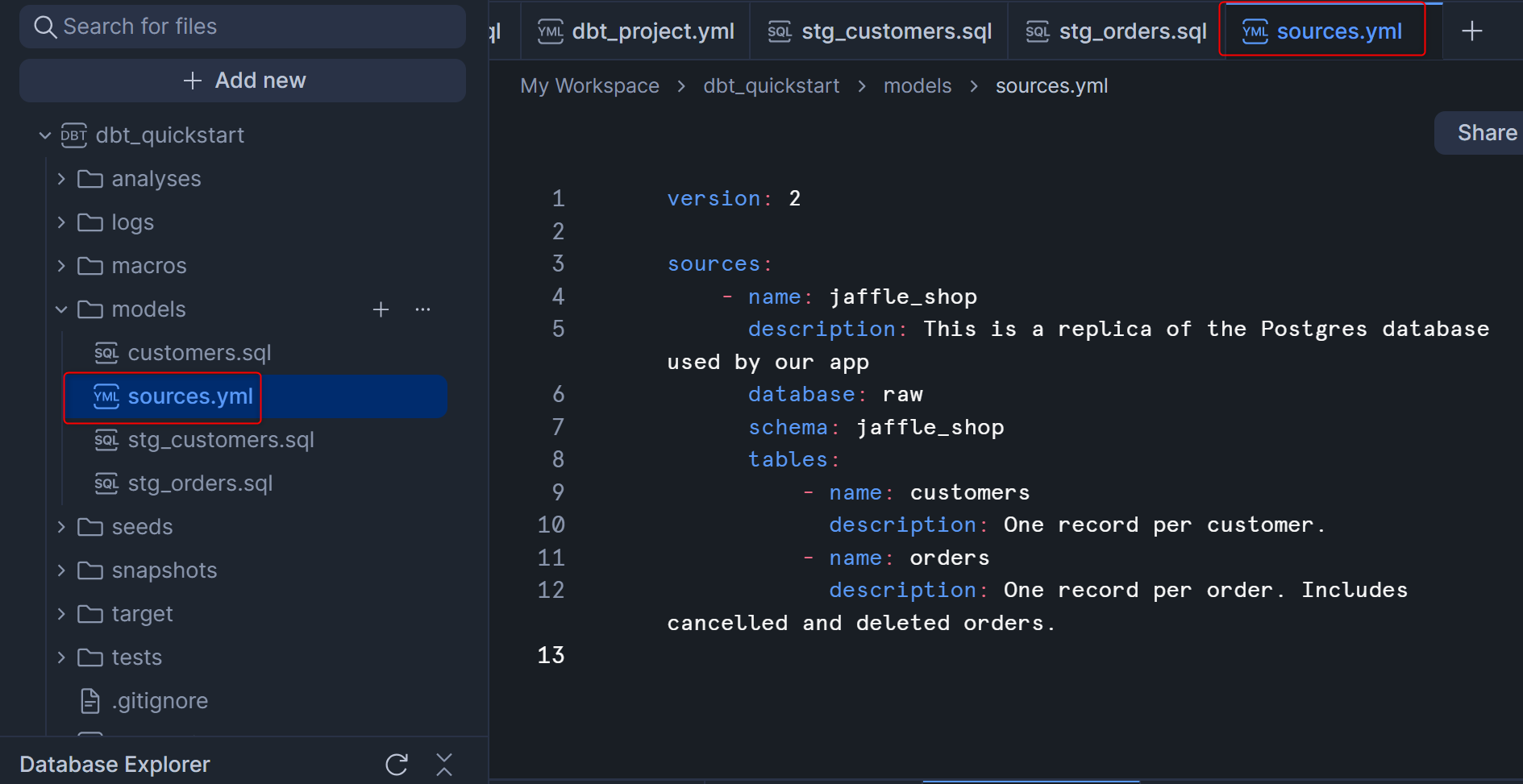
まず、modelsフォルダの配下にsources.ymlを以下の内容で作成します。
version: 2
sources:
- name: jaffle_shop
description: This is a replica of the Postgres database used by our app
database: raw
schema: jaffle_shop
tables:
- name: customers
description: One record per customer.
- name: orders
description: One record per order. Includes cancelled and deleted orders.
sources.yml作成後は、下図のようになると思います。
次に、Staging層として先ほど作成した2つの.sqlファイルを以下の内容に修正し、sourceを参照するようにします。sourceを参照する際は、{{ source('jaffle_shop', 'customers') }}のように記述します。
stg_customers.sql
select
id as customer_id,
first_name,
last_name
from {{ source('jaffle_shop', 'customers') }}
stg_orders.sql
select
id as order_id,
user_id as customer_id,
order_date,
status
from {{ source('jaffle_shop', 'orders') }}
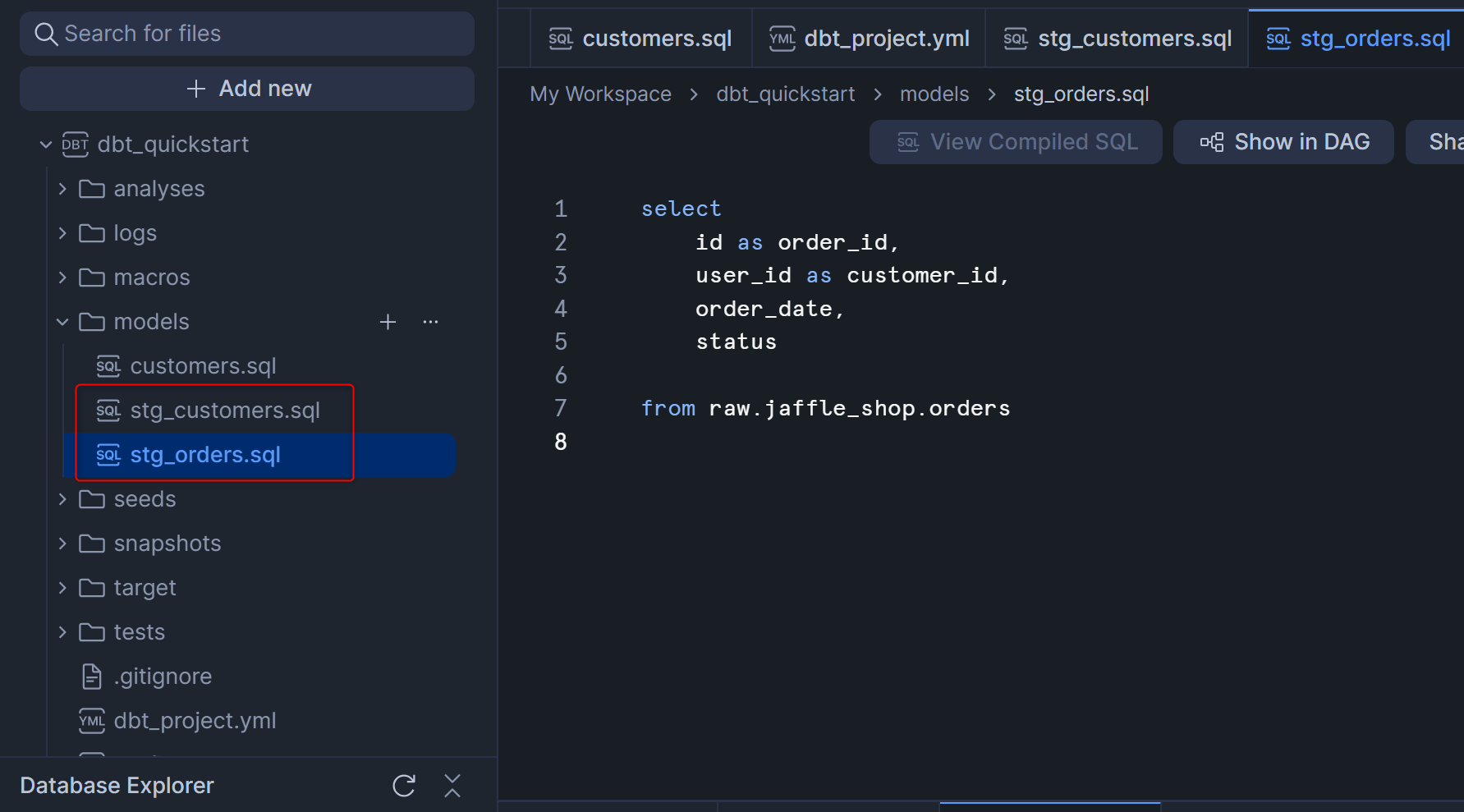
Staging層として先ほど作成した2つの.sqlファイル修正後は、下図のようになると思います。(下図はstg_orders.sqlの例)

sourceも含めた依存関係をWorkspace上で確認できるため、各SQLファイルをコンパイルするdbt compileコマンドを実行します。
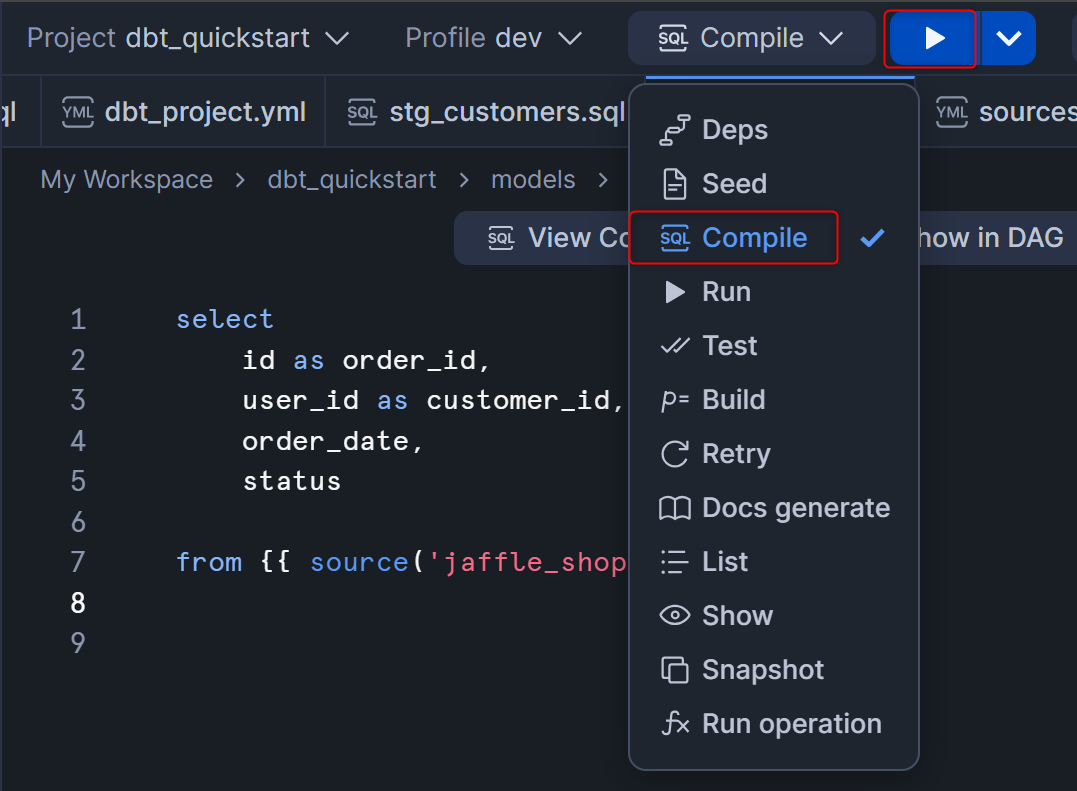
この後、Workspaceの画面右下のDAGを押すと、sourceも含めたリネージが表示されます。
また、dbt compileを実行したことで、targetフォルダ内のcompiledフォルダにて、コンパイルされた各.sqlファイルを確認可能です。下図のように、sourceの箇所が適切なテーブル名に置き換わっていることがわかります。
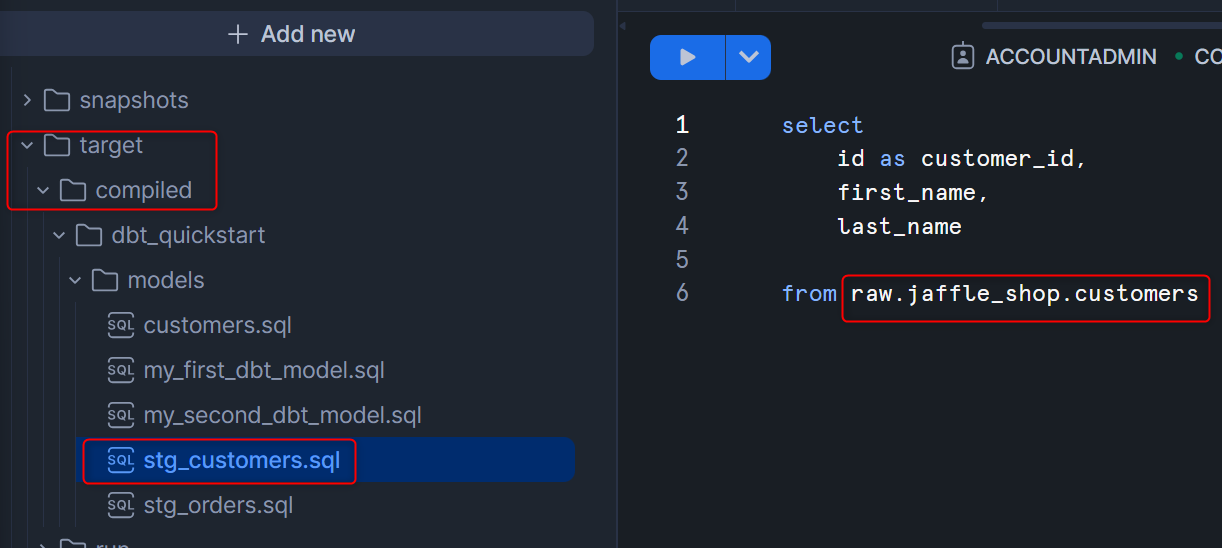
12.Add tests to your models
この章では、dbt特有の機能と言えるデータテストの機能を試していきます。
データテストはyamlファイルで定義を行うため、modelsフォルダ内でschema.ymlを作成し、以下の内容を記述します。
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
data_tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
data_tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
data_tests:
- unique
- not_null
- name: status
data_tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
data_tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
schema.ymlを作成後は下図のようになると思います。
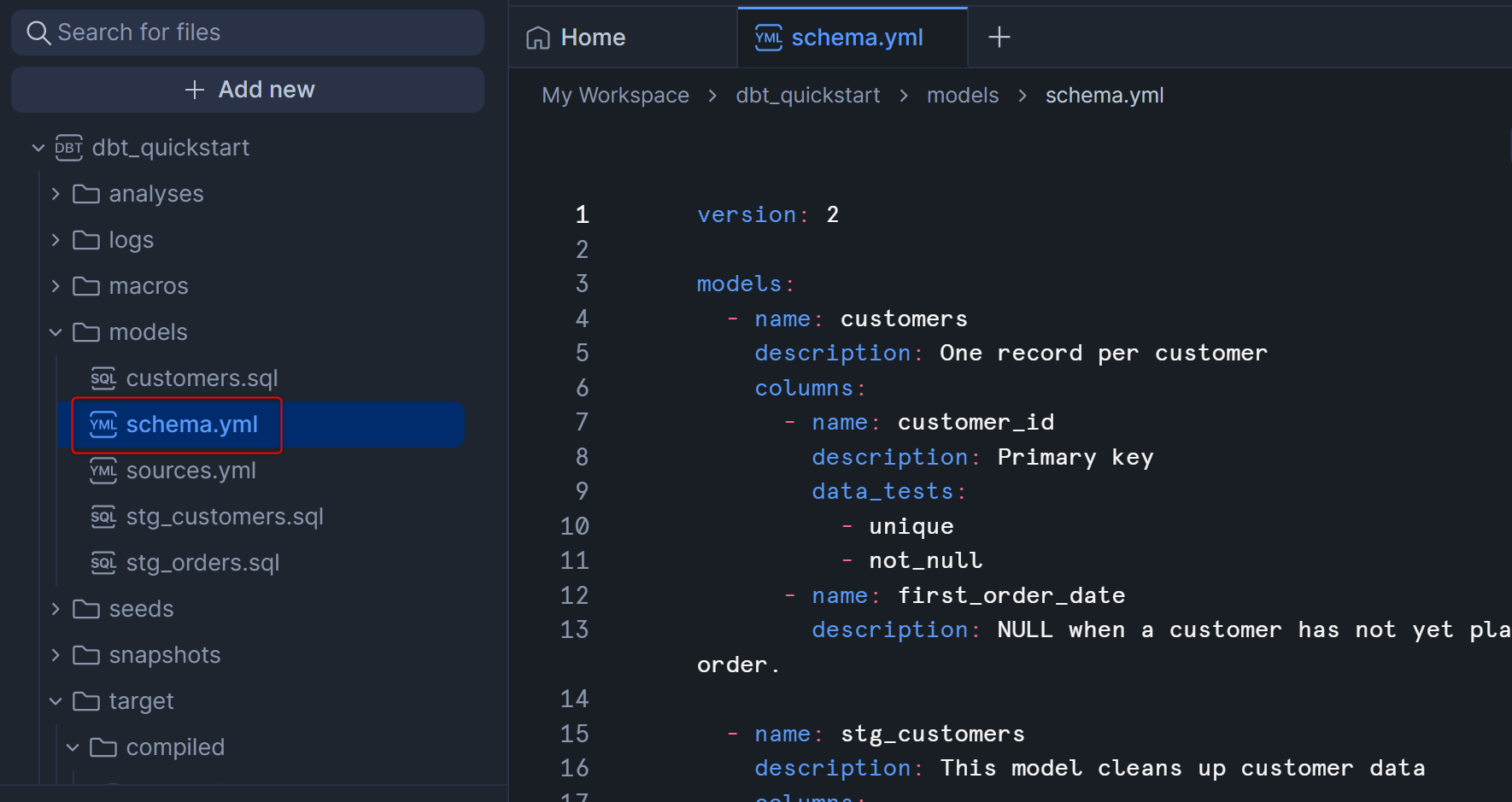
上述のschema.ymlについて、データテストの定義のポイントはdate_testsのところで、以下4つのテストから必要なテストを各カラムに対して定義しています。
- unique
- 対象のカラムの値が、全レコードで比較して一意であるかを見るテスト
- not_null
- 対象のカラムの値が、全レコードで比較してでnullでないかを見るテスト
- accepted_values
- 対象のカラムの値が、リストで指定した値のいずれかであることを見るテスト
- relationships
- 技術的に言うと参照整合性の確認を行うテスト
- 上述のコードで言うと、「
stg_ordersのcustomer_id列は、stg_customersのcustomer_id列の値から構成されている」ことを確認しています
schema.ymlの作成後、データテストを実際に行いたいので、dbt testを実行します。
実行完了後にWorkspaceの右下からログを確認してみます。各テストが実行されてPASSとなっている場合はそのテストをクリアしたことを意味します。

13.Document your models
この章は、dbtのドキュメント生成機能を試す内容となっています。
ただし、Workspace上でdbt docs generateコマンドを実行しても、生成されたドキュメントはすぐに閲覧ができませんのでご注意ください。(何かしらのサーバー等に、生成されたドキュメントをホストする必要があります。SPCSやGitHub Pages辺りが手っ取り早いと思います。)
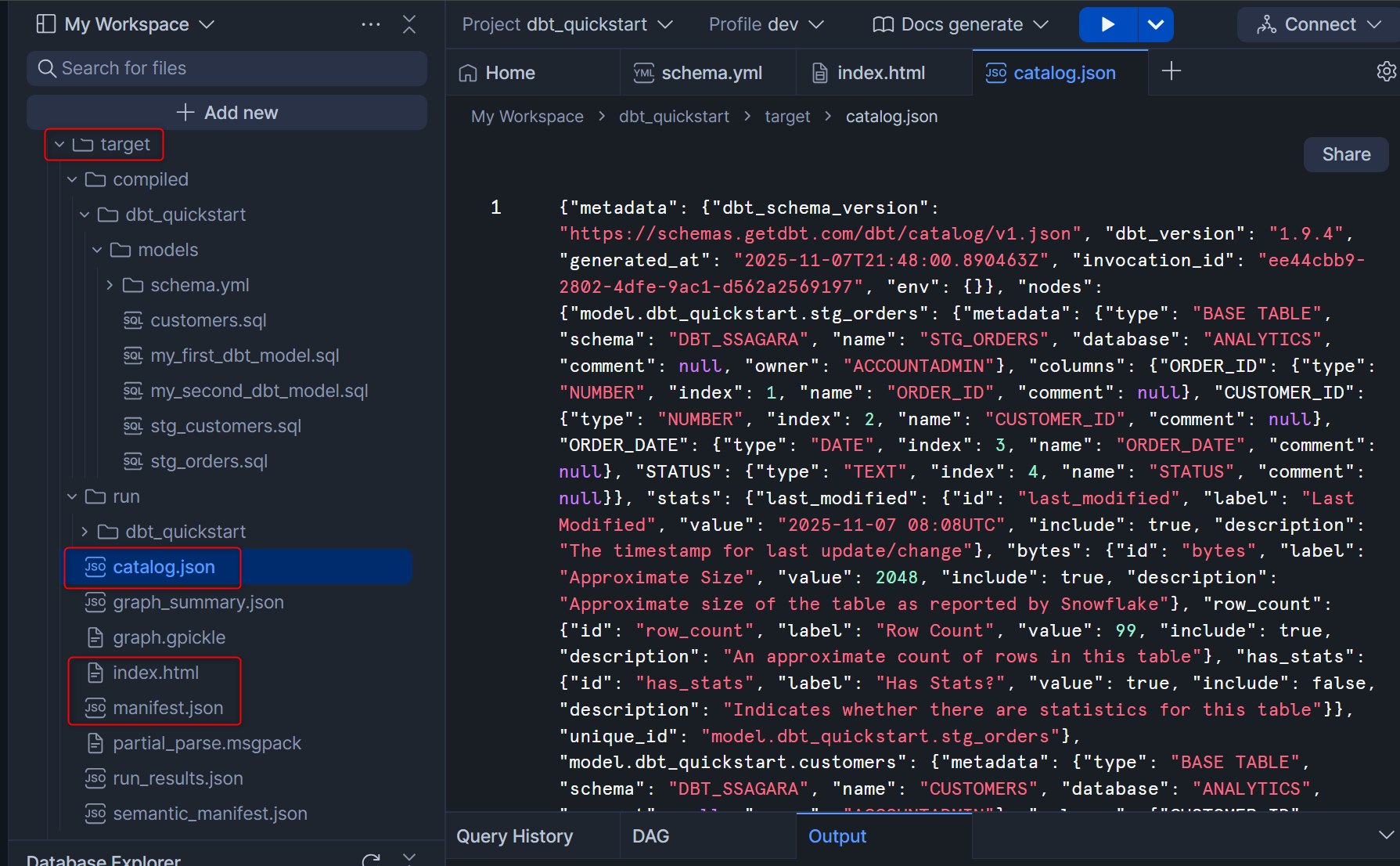
今回は、dbt docs generateを実行して何が生成されるのかを確認してみます。Workspaceの右上からdocs generateを選択して実行します。

そうすると、targetフォルダにてcatalog.jsonとindex.htmlが生成されます。(参考までに、manifest.jsonも更新されています。)
catalog.json:データベースに接続してテーブル/ビューの列名・データ型などを照会した結果を含む。モデル出力のスキーマ情報(列情報など)をドキュメントで表示するのに必要manifest.json:プロジェクト内のすべてのモデル・ソース・テスト・マクロなどの構造、説明、依存関係などを持つ主要なメタデータファイルindex.html:ドキュメントのフロントページ
これらのファイルを用いてホストすることで、下図のようにドキュメントを閲覧することが可能です。(この図は公式Docより引用)
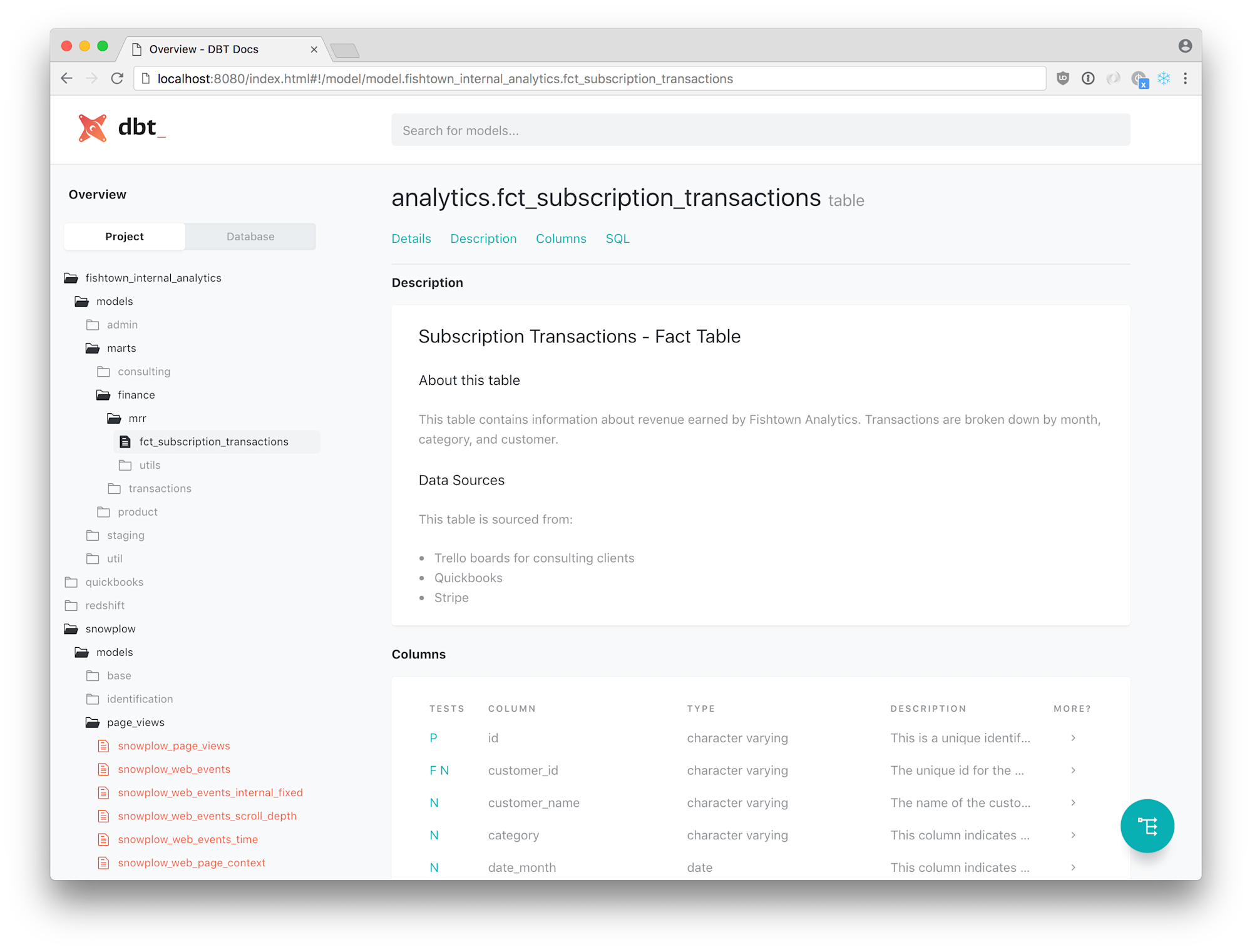
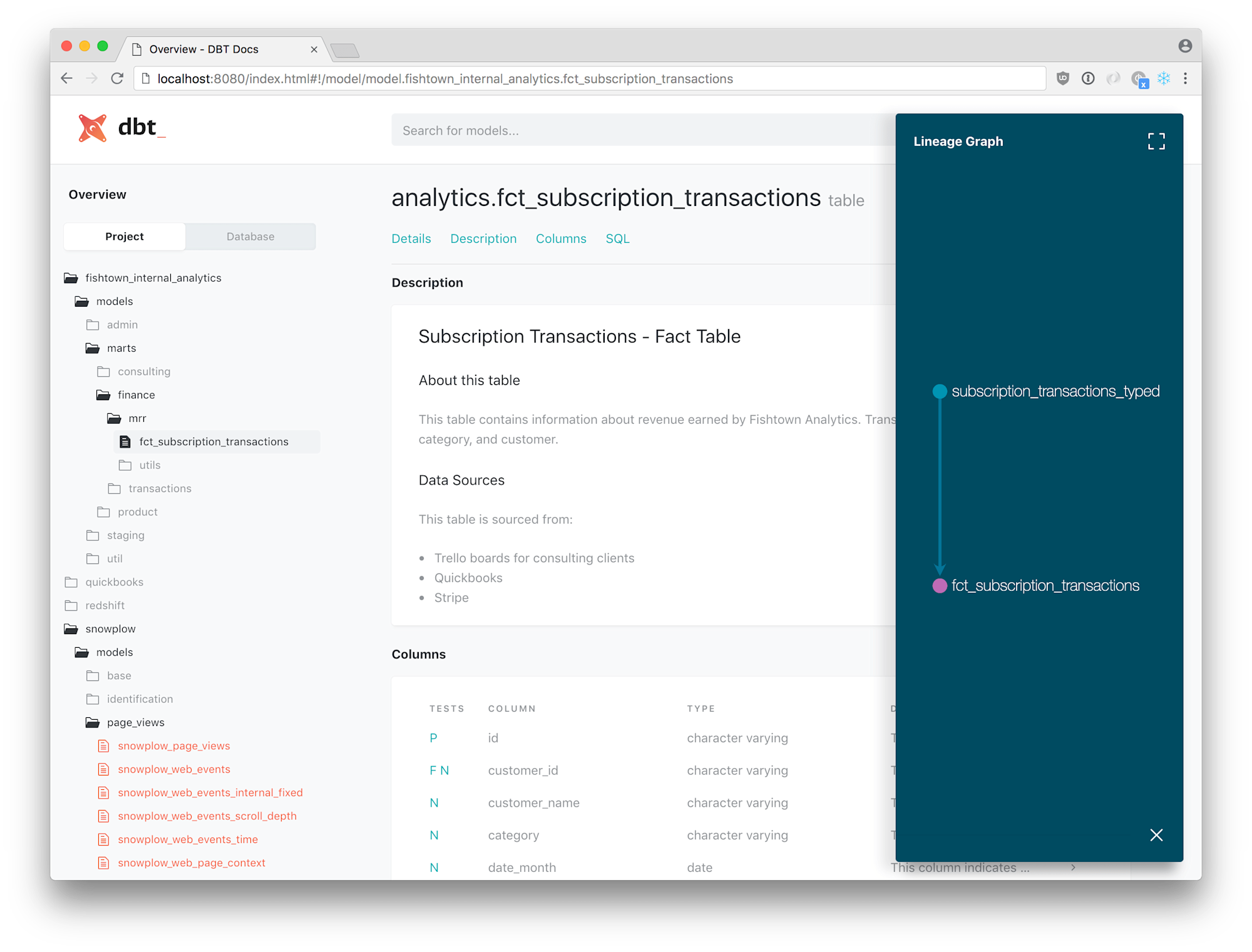
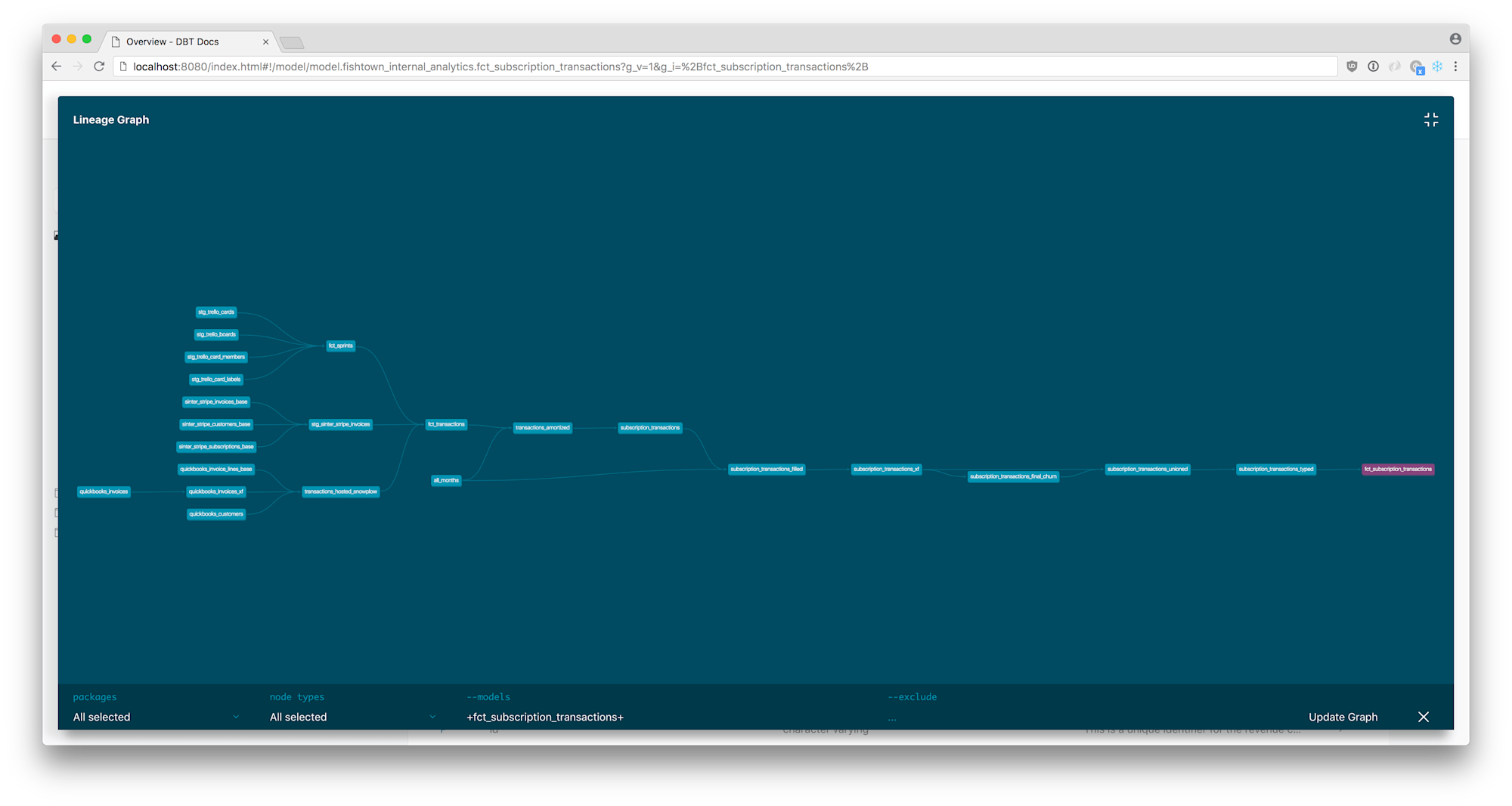
14.Commit your changes
この章では、dbt CloudのManaged Repositoryの利用を前提として、Gitのコミット~プッシュを行っています。しかし、今回はGit連携を対象外としているため、本章の内容はスキップします。
参考までに改めての記載となりますが、dbt Projects on SnowflakeにおけるGit連携については、以下のブログをご覧ください。
15.Deploy dbt
この章では、開発した内容を本番環境に反映することを行っていきます。dbt Projects on Snowflakeでは、dbt Cloudと全く異なる操作が必要となりますので、ご注意ください。
profiles.ymlに対して本番環境の情報を追記
まず、本番環境として出力したいスキーマの情報をprofiles.ymlに追記します。
profiles.ymlを開き、以下のように変更します。prodという新しいtargetを追加し、schema: PRODとしていることがポイントとなります。
※注意点:このコードを丸ごとコピペして書き換えると、dev:のschema:がDBT_SSAGARAとなりますので、ご注意ください。
dbt_quickstart:
target: dev
outputs:
dev:
type: snowflake
role: ACCOUNTADMIN
warehouse: TRANSFORMING
database: ANALYTICS
schema: DBT_SSAGARA
prod:
type: snowflake
role: ACCOUNTADMIN
warehouse: TRANSFORMING
database: ANALYTICS
schema: PROD
入力後は下図のようになります。

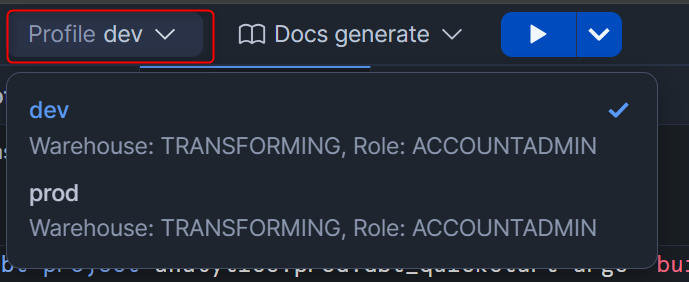
参考までに、profiles.ymlで新しいtargetを追加すると、Workspaceの上部からGUI操作で出力先を変更することも可能です。(今回のハンズオンにおいては、変更不要です。)
指定したスキーマにdbt Projectをデプロイ
dbt Projects on Snowflakeはタスクとして定期実行できるのですが、このためには指定したスキーマにdbt Projectをデプロイする必要があります。
Workspaceの画面右上のdbt project名が書かれた箇所を押して、Disconnectを押します。これは、デプロイ先がデフォルトで登録されているため、この登録情報を削除するためです。(2026/1/19追記)
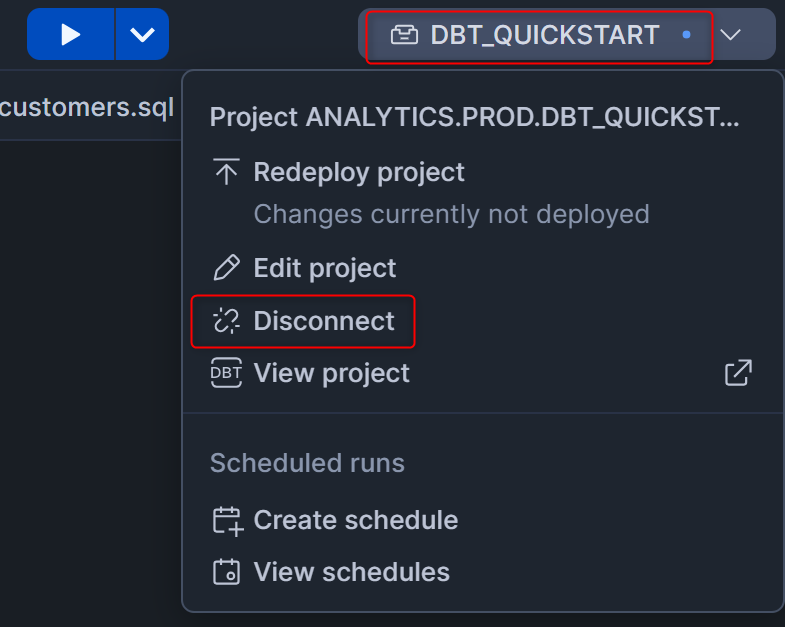
改めて、Workspaceの画面右上のConnectを押して、Deploy dbt projectを押します。
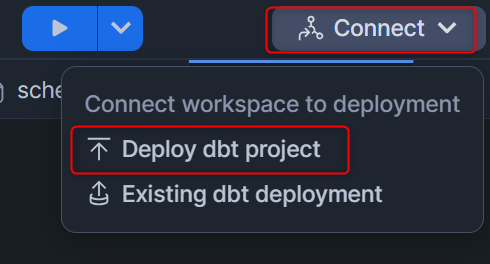
以下の内容を入力します。
Select location- データベース:ANALYTICS
- スキーマ:PROD ※今回は
profiles.ymlで指定したデータの出力先と同じスキーマにしていますが、dbt Projectのオブジェクト用に違うスキーマを作成してそのスキーマを指定しても問題ありません。
- Select or create dbt project
+ Create dbt projectを押します。
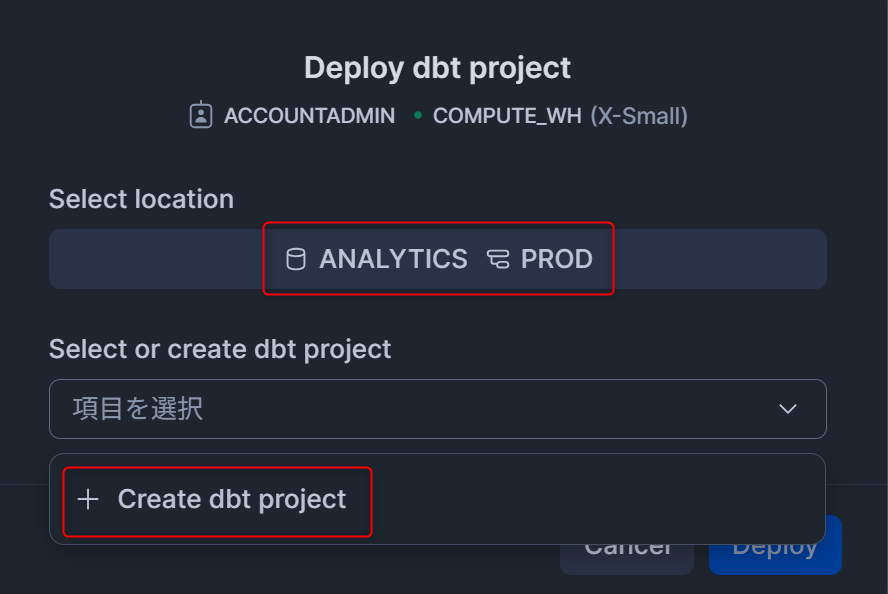
拡張された設定画面において、以下のように入力したあと右下のDeployを押します。
Enter Name:dbt_quickstart- この名称で、dbt Projectがスキーマオブジェクトとして作られます。
Default Target:prodprofiles.ymlで設定されたターゲットのうち、デフォルトで利用したいターゲットを選択します。今回は本番実行用のため、prodを指定します。
Run dbt deps;有効化しない- もし、dbt_utilsなど外部のdbtパッケージを利用する場合はこちらを有効化してください。
デプロイに成功したら、下図のように表示されます。prodスキーマを見ると、dbt Projectがデプロイされていることがわかります。
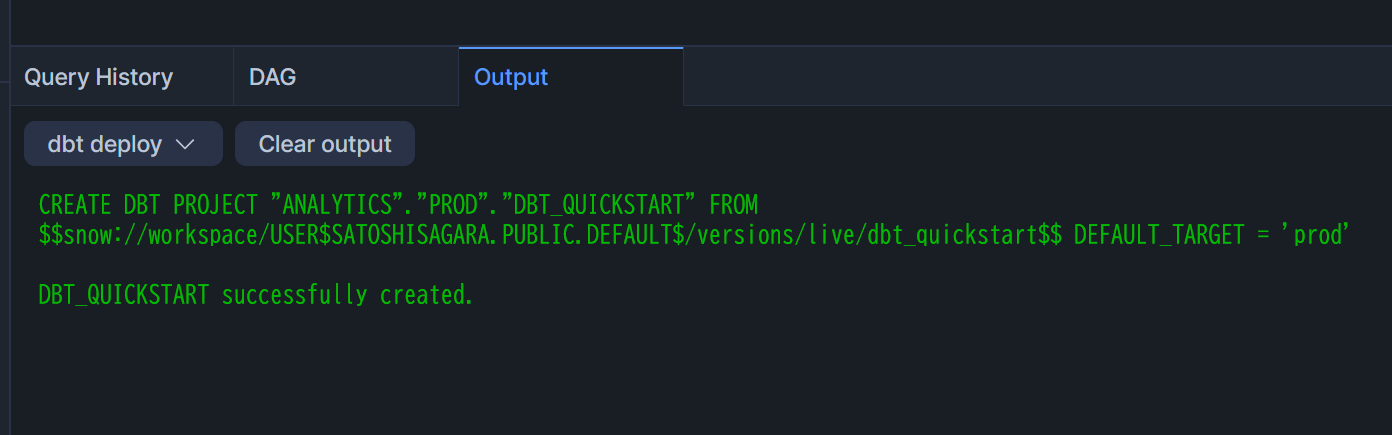

この後、タスク設定用のクエリを実行するため、新しい.sqlファイルを作成します。
左上のファイル一覧から+ Add newを押してSQL Fileを選択し、define_task.sqlとします。

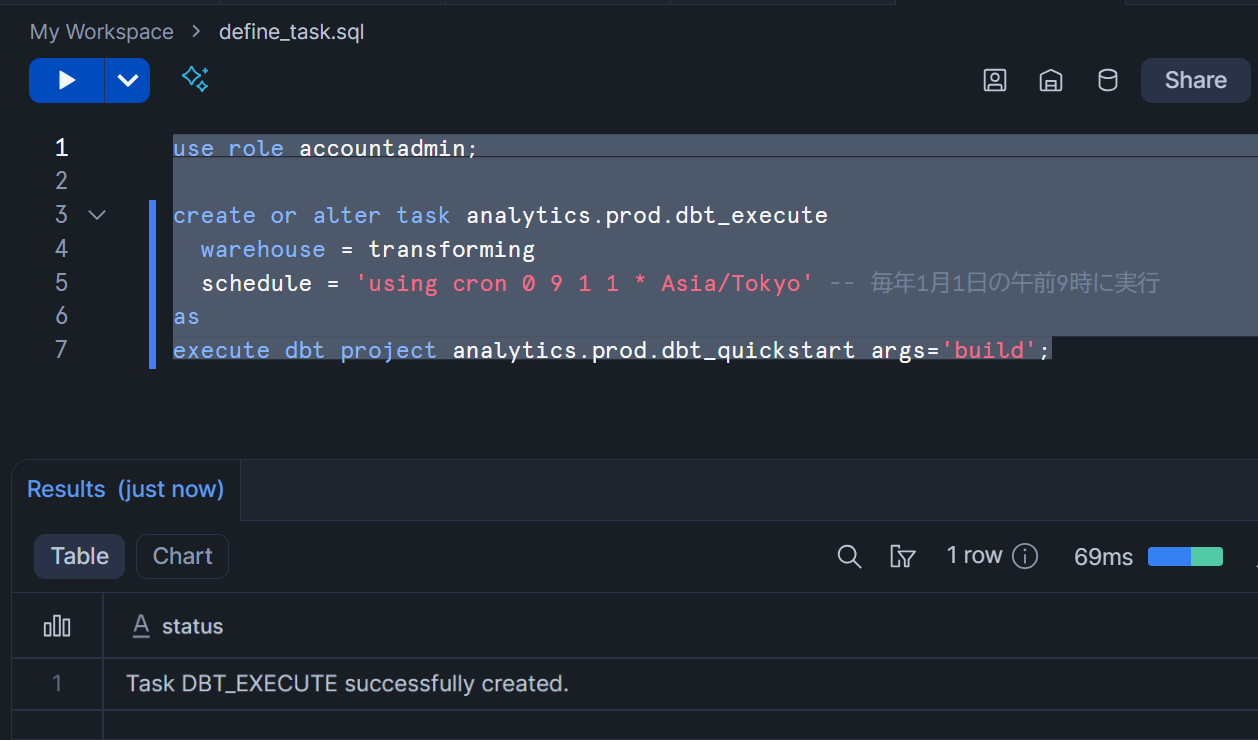
以下のクエリをコピーして実行し、dbt Projectを用いたタスクを定義します。ポイントはargs='buildで、dbt runとdbt testをModelごとに交互に実行できるdbt buildコマンドが実行することを指定しています。
use role accountadmin;
create or alter task analytics.prod.dbt_execute
warehouse = transforming
schedule = 'using cron 0 9 1 1 * Asia/Tokyo' -- 毎年1月1日の午前9時に実行
as
execute dbt project analytics.prod.dbt_quickstart args='build';
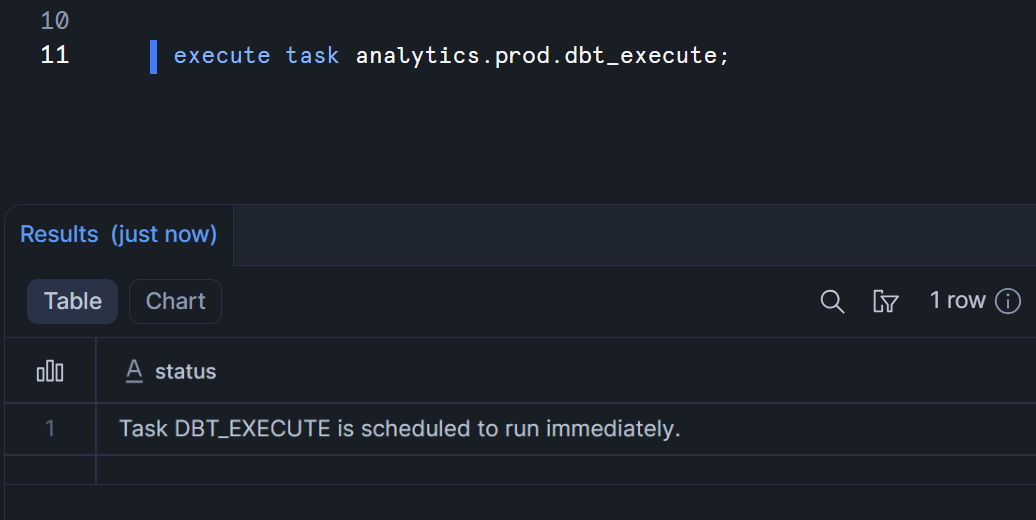
この後、以下のコマンドを実行して手動でタスクを実行してみます。
execute task analytics.prod.dbt_execute;
参考までに、dbt project自体の実行状況は、画面左のTransformationから、dbt projectsを押すことで確認可能です。

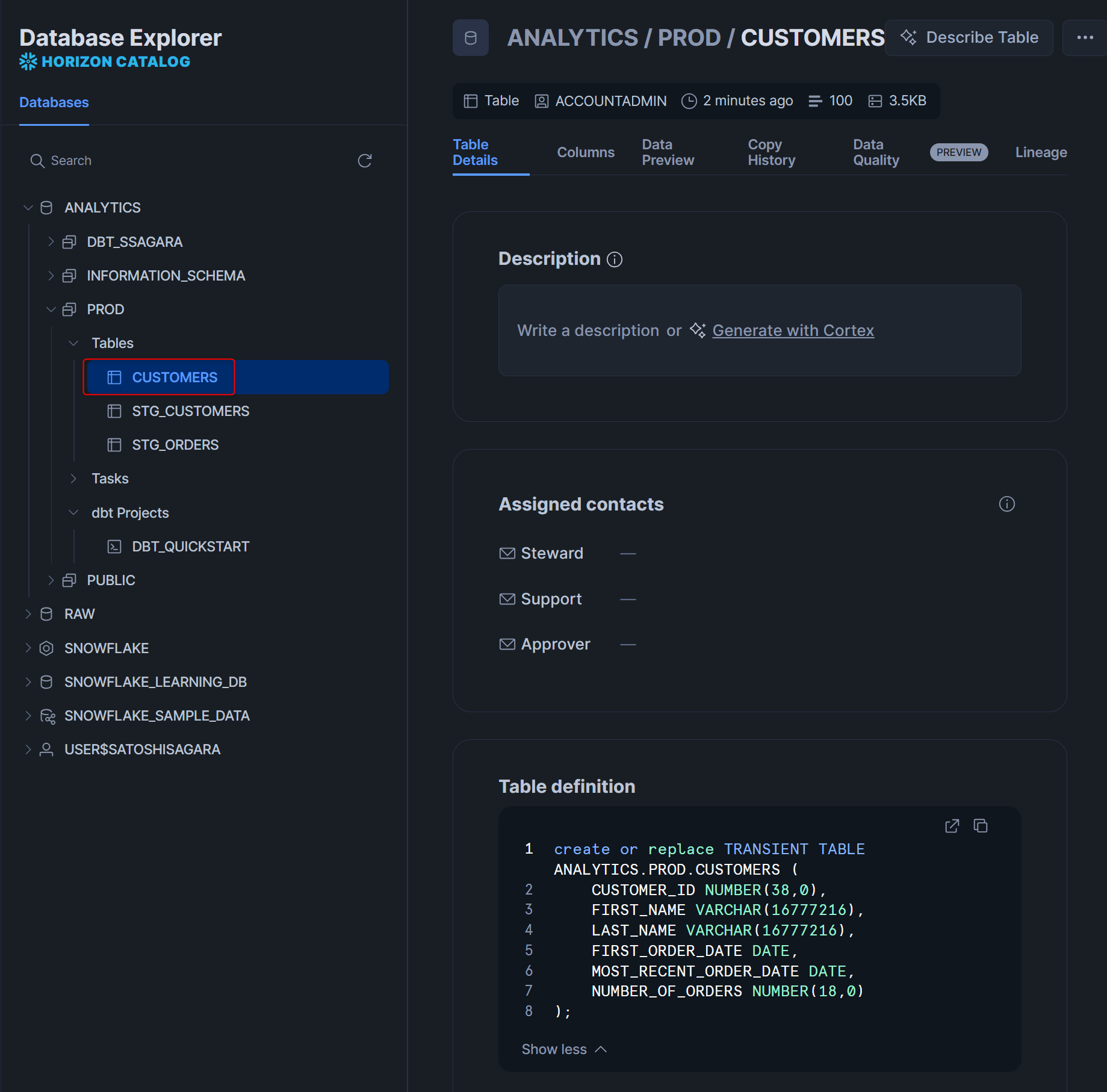
タスクの成功を確認した後にprodスキーマの中を見ると、無事にテーブルが作成されていました!これで、Workspace上で個人用のスキーマに対して開発を行って問題なかったデータ変換処理が、本番用のスキーマに対して反映されました。この開発と本番の切り分けがスムーズに行えるのがdbtの強みです。
最後に
「Quickstart for dbt and Snowflake」のチュートリアルをdbt Projects on Snowflakeでやってみました。
dbt自体を学びながらdbt Projects on Snowflakeを試していくにはちょうどよい内容だと思います!ぜひお試しください。








