
dbt State を dbt platform + Snowflake で試してみた
はじめに
2026年6月のアップデートで、dbt の新機能 dbt State がプレビューとなりました。
dbt platform で試してみた内容を本記事でまとめてみます。
アップデートの概要
本機能については以下に記載があります。
dbt State は、モデルのビルド時に各ノードを評価し、最も効率的な方法を自動的に適用してくれる機能です。具体的には、以下の3つの方法でビルドを最適化します。
- Skip(Reuse)
- 対象スキーマに同一ロジックのオブジェクトが既に存在し、上流データも
lag_toleranceの範囲内で新しい場合、ビルドしない
- 対象スキーマに同一ロジックのオブジェクトが既に存在し、上流データも
- クローン
- 別スキーマ(prod など)に同一ロジック・新鮮なデータの同名オブジェクトがある場合、
CLONEで複製する
- 別スキーマ(prod など)に同一ロジック・新鮮なデータの同名オブジェクトがある場合、
- 通常ビルド
- 再利用できない場合は通常どおりビルドする。未選択の上流は prod へ自動的に defer する
従来のstate:modifiedや Slim CI と比べて、以下の点が異なります。
- セットアップがほぼ不要(
manifest.jsonの手動管理が不要) - 変更検知が意味ベース(空白・コメント・エイリアスの違いは無視される)
- 上流のデータ更新まで考慮する(
state:modifiedはファイル変更のみ)
また、dbt State はデプロイメント環境のジョブだけでなく、開発環境(dev)でも利用できる点も特徴です。
SAO(state-aware orchestration)では、ジョブの実行に閉じた機能で、開発実行には適用されませんでした。一方 dbt State は、ジョブに加えて開発実行(--manage-state)でも同じ最適化が働くため、日々の開発サイクルでも高速化やコスト削減が期待できます。
対応している DWH やバージョンは以下のとおりです。
| 項目 | 内容 |
|---|---|
| 対応 DWH | Snowflake / Databricks / BigQuery / Redshift |
| ネイティブ対応 | dbt Core 1.12+ / dbt Fusion / dbt platform |
| プラグイン対応 | dbt Core 1.7–1.11(pip install dbt-state) |
なお、dbt State は SAO(state-aware orchestration)の後継として位置づけられています。現在はプレビュー期間中なので、移行に強制的な期限はありませんが、dbt State が一般提供開始となったタイミングで移行のスケジュールが発表されるとドキュメントに記載されていました。
本機能については myshmeh さんの以下の記事でも詳しく紹介されています。
試してみる
前提条件
今回は dbt platform 上で dbt State を有効化し、基本的な動作を確認します。具体的な環境は以下の通りです。
- dbt:dbt platform
- 開発環境、デプロイメント環境いずれも Fusion Stable リリーストラック
- DWH:Snowflake
サンプルデータとして、公式のクイックスタートから利用できるjaffle_shopのデータを使用しています。
検証開始時点で、以下のリネージが構成されています。
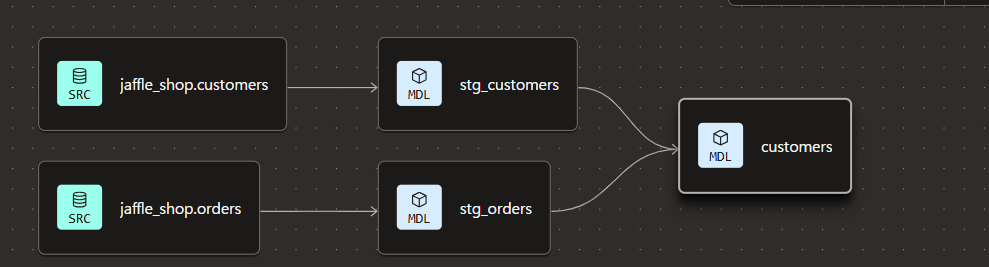
dbt State の有効化
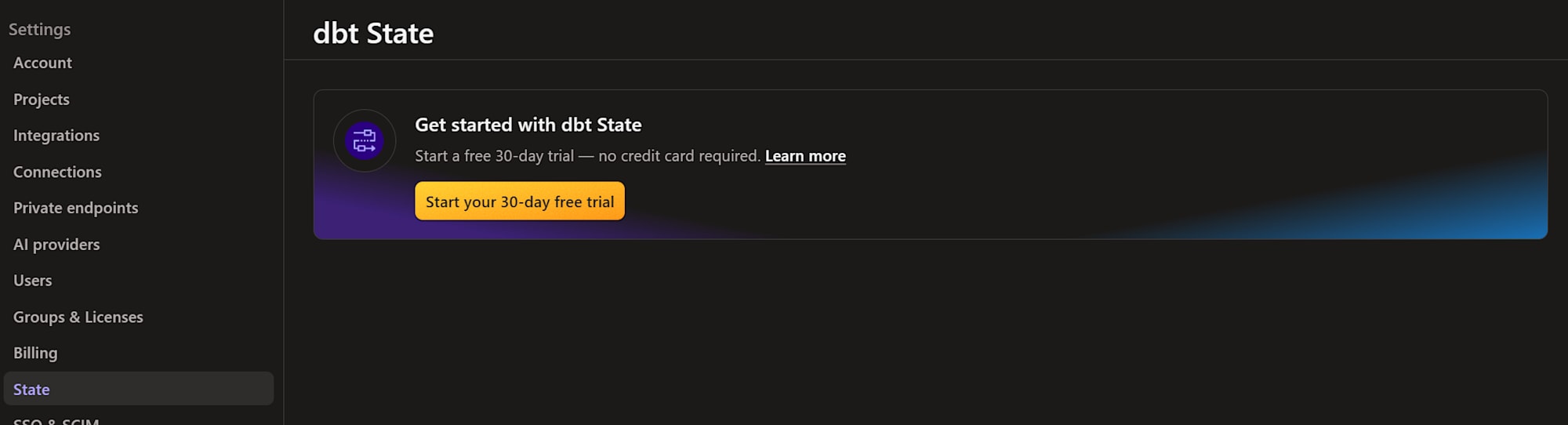
dbt platform にログインし、「Account settings > State」へ進みます。
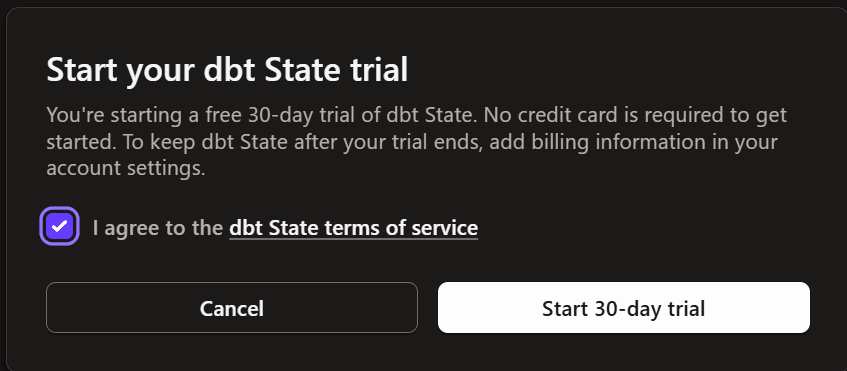
「Start your 30-day free trial」から規約に同意し、トライアルを開始します。
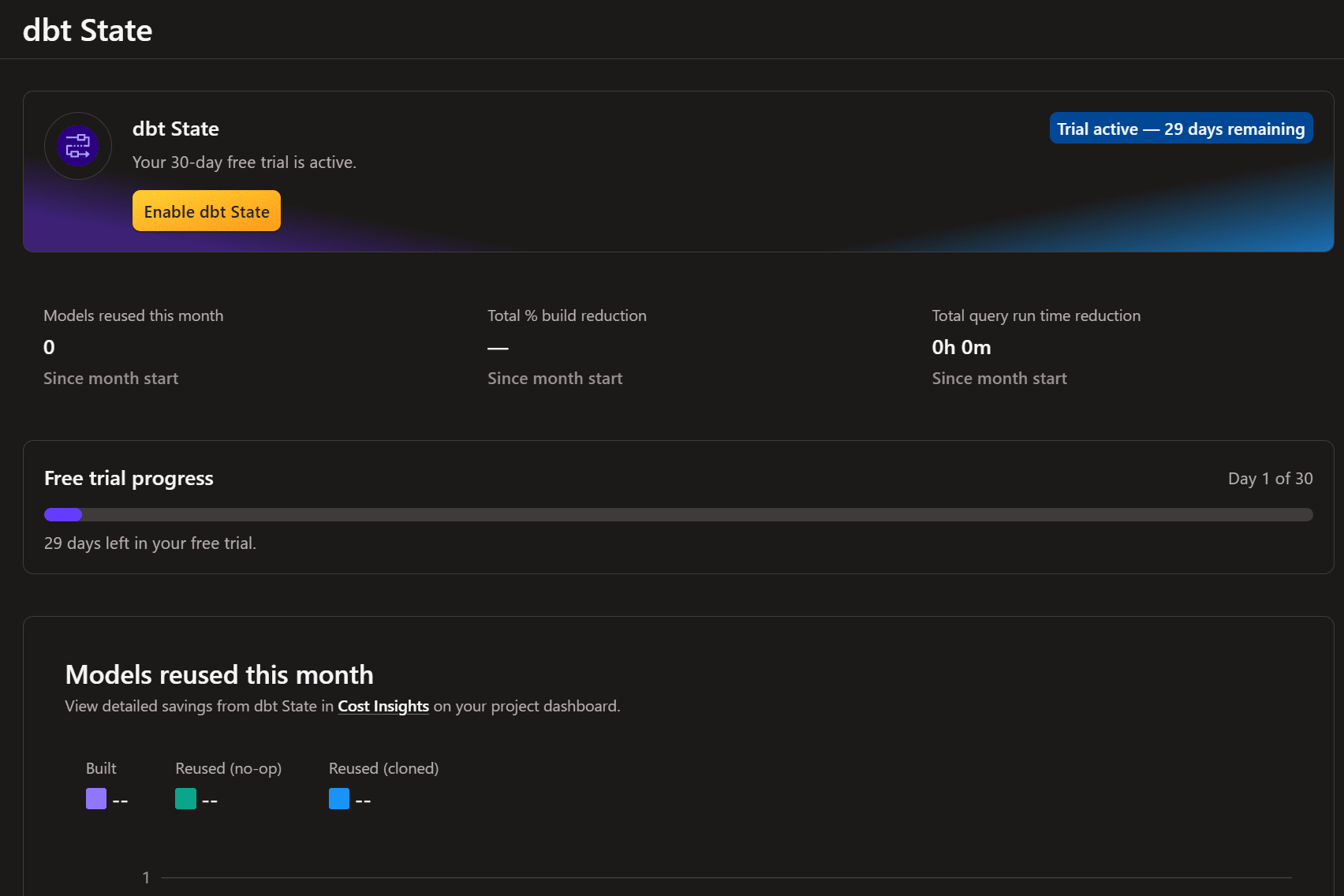
すると、現在選択中のプロジェクトに関するジョブが表示されます。環境単位・ジョブ単位で設定を制御できます。
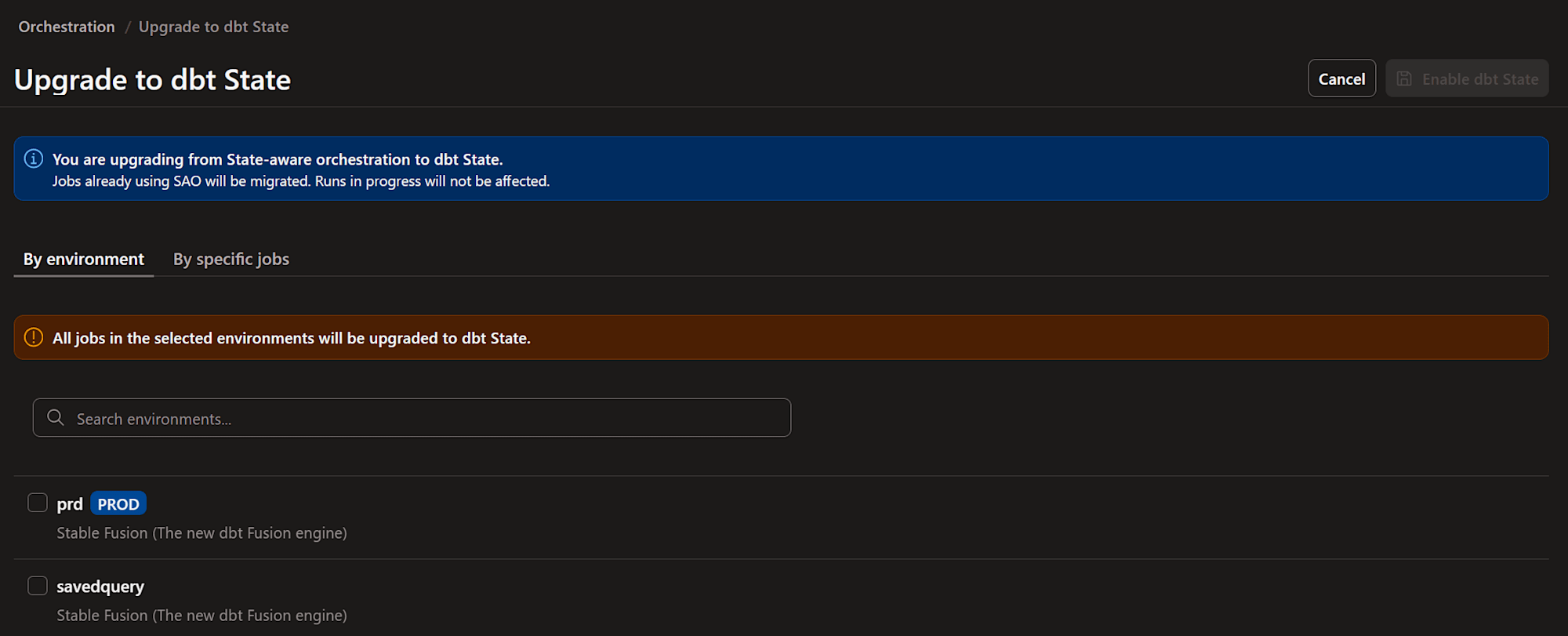
ここでは本番環境(prd)にチェックを入れて「Enable dbt State」をクリックしました。
prod state の用意
クローンや defer の比較対象とするため、prod 環境のジョブ(prd job)で一度フルビルドを実行し、state を確定させておきます。
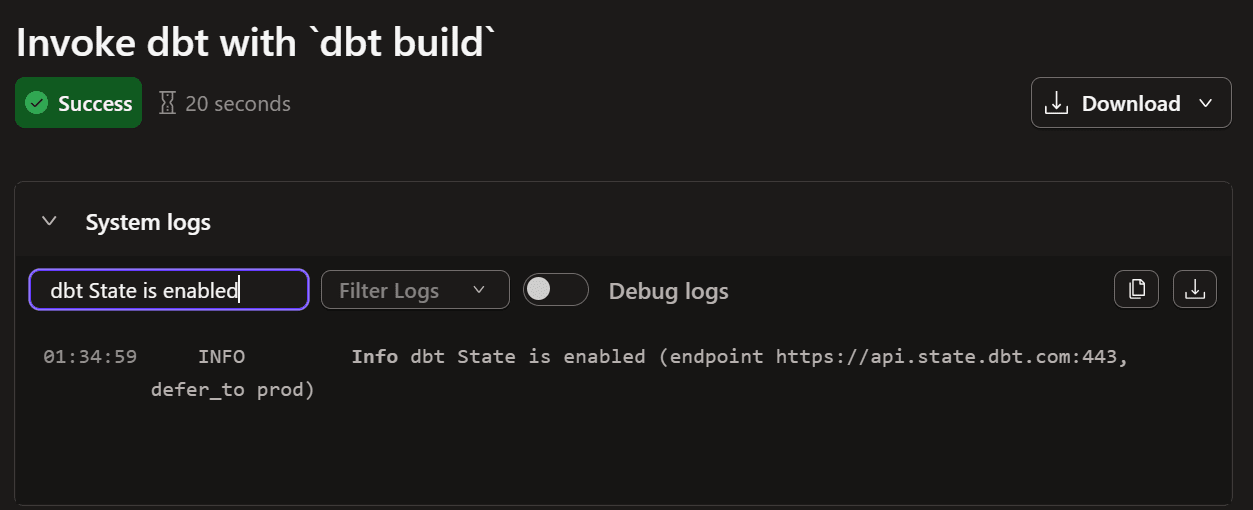
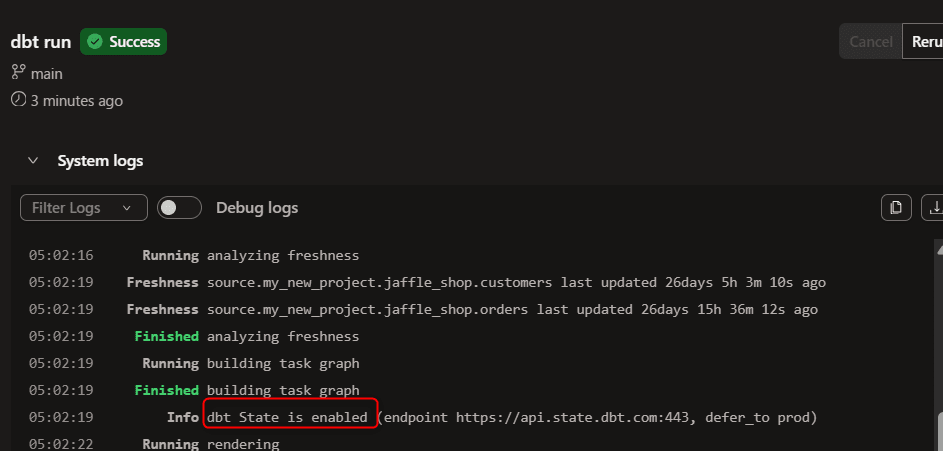
ログを確認すると、この時点で dbt State が有効化されていることが確認できます。
Skip(再利用)の確認
デプロイメント環境のジョブを前回から何も変更せずにそのままprd jobを再実行します。
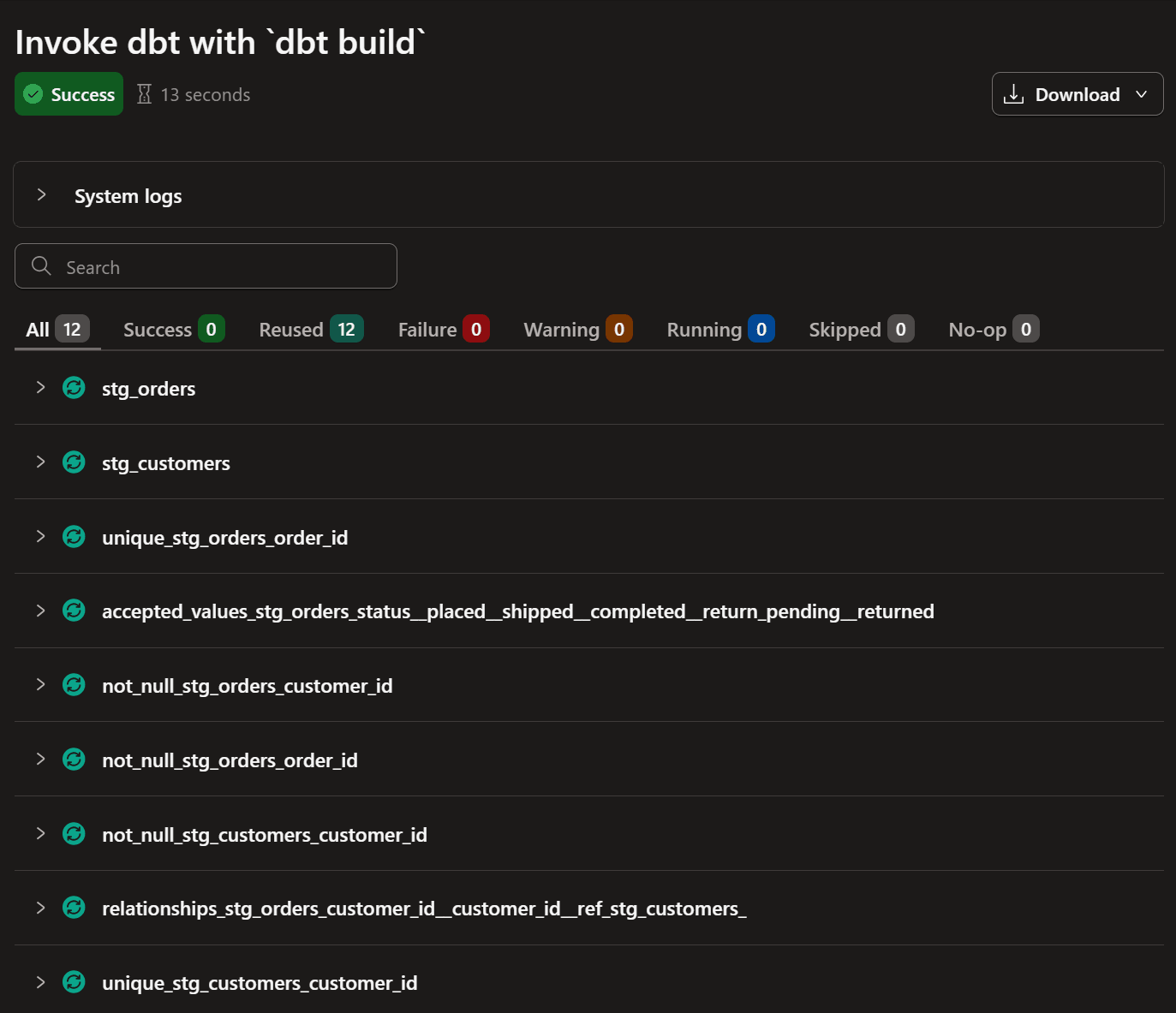
ログの一部:
01:54:57
INFO Info dbt State is enabled (endpoint https://api.state.dbt.com:443, defer_to prod)
・・・
01:55:07
============================ Execution Summary ============================
INFO Invocation 019e8b30-dac8-7d42-bb5a-0c57b62f132d build successfully for target prd [12.66s]
Processed 3 models | 9 data tests
Summary 12 total | 12 reused
結果は上記の通り、全ノードがreusedとなり、dbt State による再利用が動作していることが確認できました。
なお、この時点では従来の SAO(state-aware orchestration)と区別できません。無変更なので、いずれであっても「ビルド不要」と判断するためです。
意味ベースの変更検知の確認
dbt State の変更検知は意味ベースで、コメントや空白などの変更は無視され、出力に影響するロジック変更だけが rebuild の対象になります。これを2パターンで試してみます。
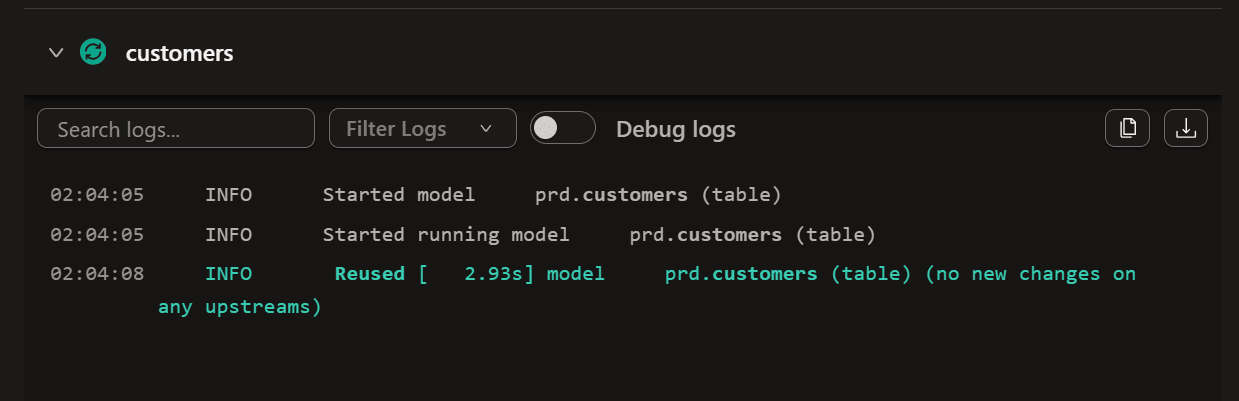
コメントのみ追加
mart/customers.sqlの先頭にコメント1行だけを追加(ロジック変更なし)してジョブを実行します。
-- dbt State 意味ベース変更検知の検証用コメント(ロジック変更なし)
with customers as (
select * from {{ ref('stg_customers') }}
他は特に変更せずにジョブを実行すると下図のように reuse となりました。コメントなどは「意味のある変更ではない」と判定され、rebuild されませんでした。
ロジック変更
mart/customers.sqlにカラムを1つ追加してジョブを実行してみます。
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders,
current_date() as dbt_state_logic_test -- dbt State ロジック変更検知の検証用カラム
from customers
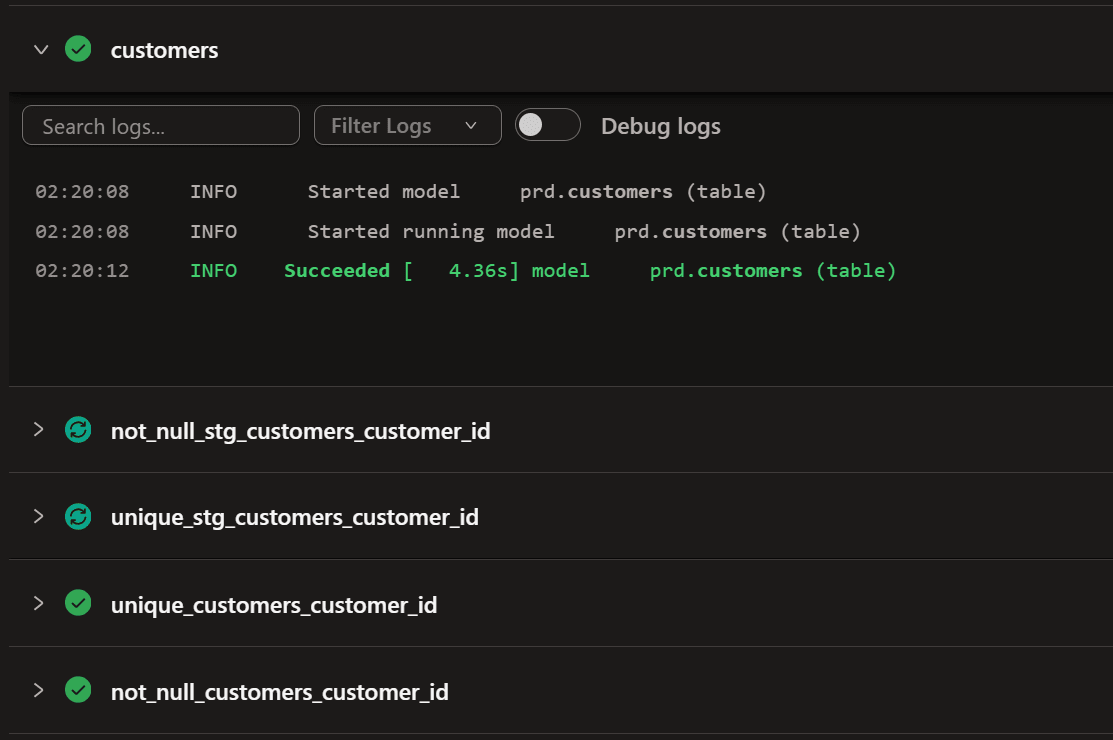
今度は対象のモデルが rebuild されました。出力列が変わる意味のあるロジック変更は dbt State が検知し、reuse せずに rebuild します。
開発環境(dev)での有効化
ここからはクローン / defer を確認するため、開発環境(dev)でも dbt State を有効化してみます。
先の「Account settings > State」の有効化 UI は ジョブ / 環境の一覧であり、開発環境(development)はそこに表示されませんでした。
開発環境では、実行時フラグ--manage-stateや後述するdbt_project.ymlの設定追加で dbt State を有効化できました。
dbt build --manage-state # 実行ごとに有効化
dbt build --no-manage-state # 無効化
試しに開発環境(Studio IDE)でdbt run --manage-stateを実行してみます。
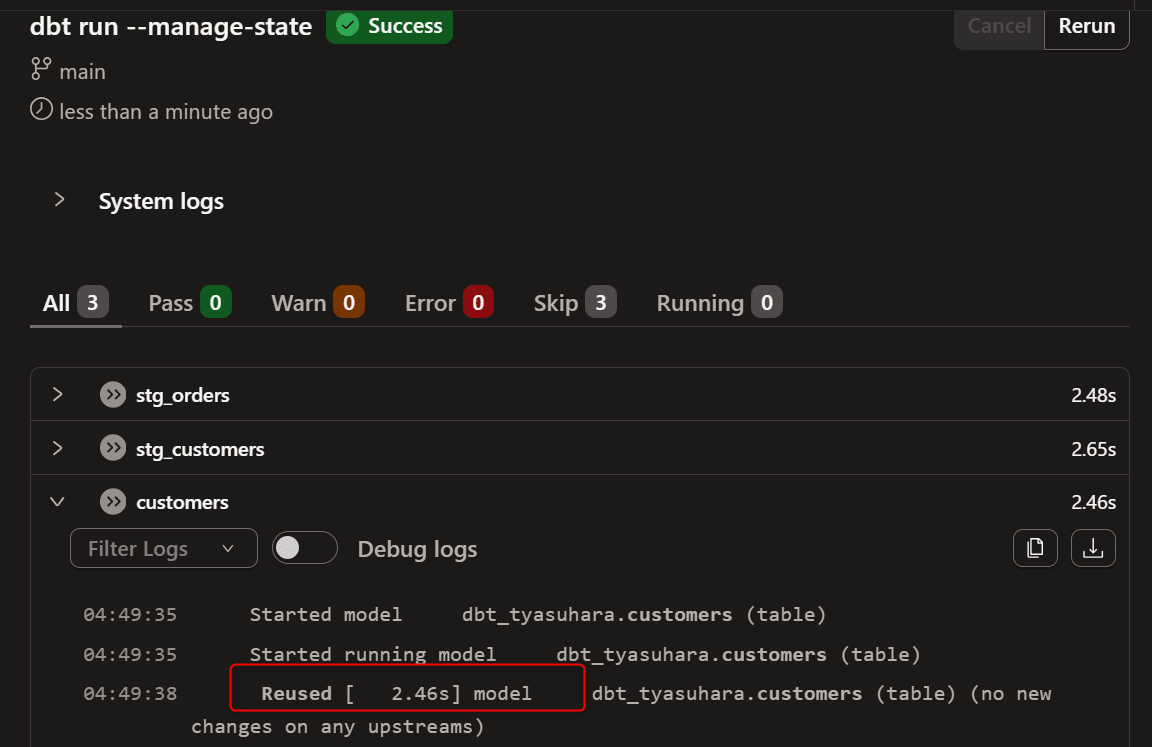
上記のように--manage-stateを付ければ dbt State が有効化され、Reused(no new changes on any upstreams)となることが確認できました。
毎回フラグを付けたくない場合は、dbt_project.ymlに以下を記述することでプロジェクト全体でデフォルト有効化できます。
name: 'my_new_project'
version: '1.0.0'
config-version: 2
profile: 'default'
# dbt State をプロジェクト全体でデフォルト有効化(毎回 --manage-state を付けなくてよい)
# 個別実行で外す場合は --no-manage-state で上書き
flags:
manage_state: true
クローンの確認
dbt State のクローンは、DWH ネイティブの zero-copy クローン(Snowflake であればCREATE TABLE ... CLONE)を使い、SQL を実行せずに既存テーブルの複製を作る仕組みです。
「対象スキーマ(dev)にテーブルが無く、別スキーマ(prod)に同一ロジック・新鮮な table がある」場合に、SQL を流す代わりに prod からクローンして dev に用意してくれます。クローンは SAO には存在しない dbt State 固有の挙動です。
クローンの挙動を確認するため、開発スキーマdbt_tyasuharaのテーブルを削除して空にしておきます。

dbt State が有効な状態で開発環境でモデルをビルドします。
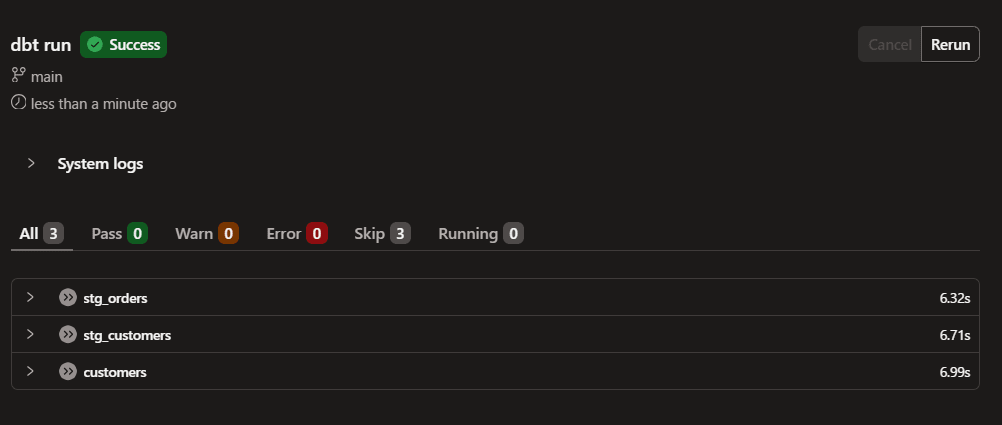
ログの一部:
05:15:13
Started running model dbt_tyasuhara.customers (table)
05:15:20
Reused [ 6.99s] model dbt_tyasuhara.customers (table) (cloned from cached relation)
実際に実行されたクエリを確認すると、prod からクローンしていることがわかります。
05:15:17
Query executed on node: model.my_new_project.customers:
CREATE OR REPLACE TRANSIENT TABLE "ANALYTICS"."DBT_TYASUHARA"."CUSTOMERS"
CLONE "ANALYTICS"."PRD"."CUSTOMERS"
dev にテーブルが無く、prod に同一ロジック・新鮮なテーブルがある状態で、customersが prod からクローンされることが確認できました。
ビューの扱い
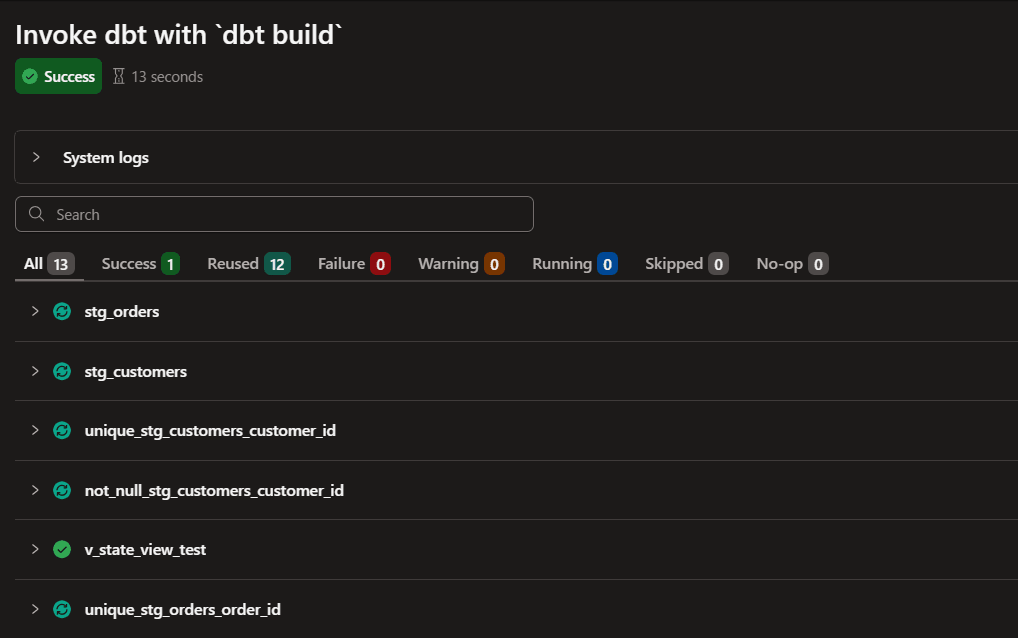
dbt State の最適化はテーブルのみでビューが対象外であることも確認します。検証用にビューを1つ追加します。
{{ config(materialized='view') }}
select * from {{ ref('stg_customers') }}
prod に push してジョブを実行し、その後に変更せず再実行すると、ビューはそのまま再作成されました。
開発環境でも試したところ、同様にクローンされませんでした。
defer の確認
defer は、今ビルドしないモデルの参照を別環境の成果物で代替解決する仕組みです。dev に無い上流は prod のテーブルを参照してくれるので、上流を dev で作り直さずに目的のモデルだけを開発・テストできます。
クローンと区別するため、対象モデル(customers)を dev で簡単にロジックを変更します(一致するとクローンされてしまうため)。
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders,
'defer_test' as dbt_state_defer_marker -- defer 検証用
from customers
left join customer_orders using (customer_id)
)
dbt platform では下図の箇所で defer 先を確認できます。

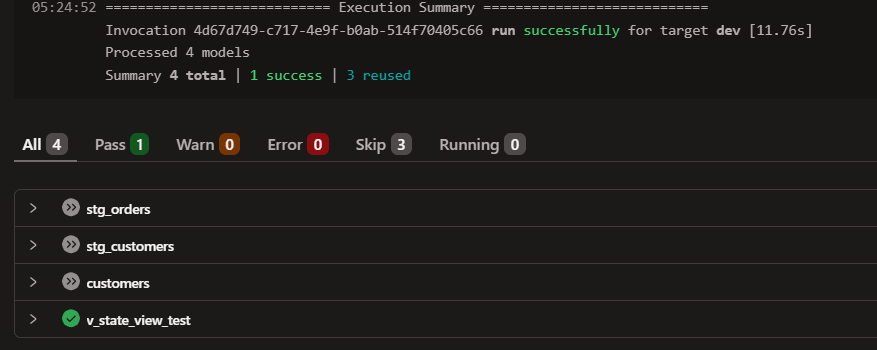
再度 dev の出力先スキーマを空にした上で、上流のモデルは含めずに対象のモデルだけを実行します。
dbt build --select customers
その結果customersの上流参照が prod(ANALYTICS.PRD.*)に解決され、defer が期待どおり成立しました。
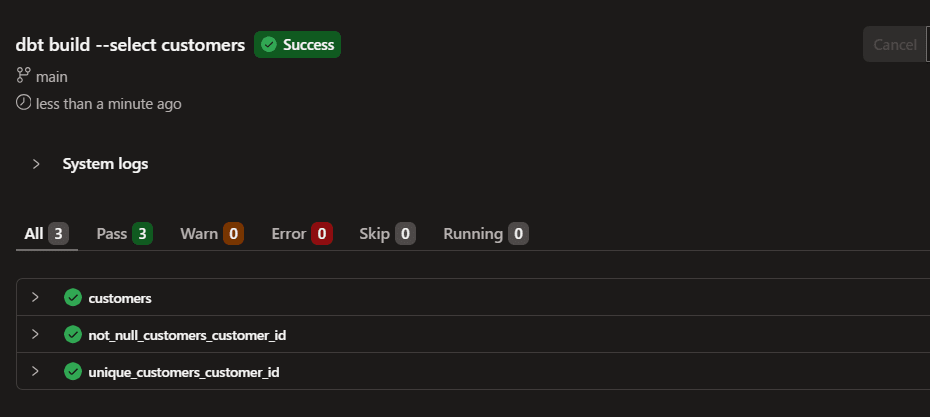
実際にコンパイルされた SQL を確認すると、上流の参照先が prd になっていることがわかります。
create or replace transient table analytics.dbt_tyasuhara.customers
as (with customers as (
select * from analytics.prd.stg_customers
),
orders as (
select * from analytics.prd.stg_orders
),
lag_tolerance の挙動
最後に、dbt state の設定の一つの上流データの鮮度の許容差を決めるlag_toleranceを試します。
これは「上流データの最終更新からどれだけ経過したら rebuild 対象にするか」を決める設定で、既定は45m(45分)です。その他も含めたオプションは以下にまとまっています。
検証用に、ここでは以下のようにdbt_project.ymlに設定しました。注意点として、stg レイヤーもテーブルとしてます。
models:
my_new_project:
+materialized: view # models/ 直下など、意図しない場所にモデルが置かれた場合のデフォルト
stg:
+database: analytics
+materialized: table
+state:
lag_tolerance: 1m # dbt State 検証用(既定 45m)。鮮度許容差を短くして挙動を観察
mart:
+database: analytics
+materialized: table
+state:
lag_tolerance: 45m # dbt State 検証用(既定 45m)
以下の設定イメージです。
- 短い設定(1m):変化が 1分経てば rebuild 対象(早く追従)
- 長い設定(45m):変化が 45分経つまで reuse(鮮度より安定/コスト優先)
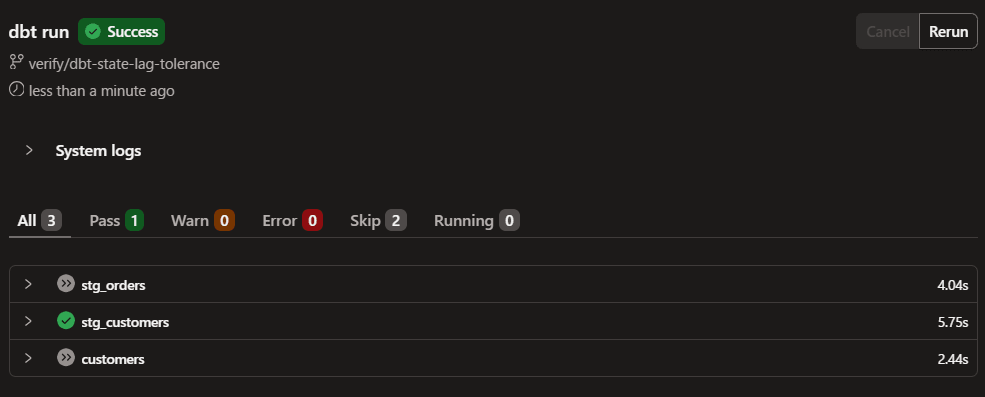
この状態で、ソーステーブルのjaffle_shop.customersにデータを INSERT します。
INSERT INTO RAW.JAFFLE_SHOP.CUSTOMERS (ID, FIRST_NAME, LAST_NAME)
VALUES (100001, 'dbt_state', 'lag_test');
INSERT 後すぐに再実行すると、stg_customers(1m)は rebuild、customers(45m)は reuse となりました。lag_toleranceにより、レイヤーごとなどでも鮮度とビルドコストを調整する際に使用できることがわかります。
さいごに
dbt State を dbt platform・Snowflake 環境で試してみました。
開発環境でも最適化の恩恵を受けられるのは嬉しいポイントと思いました。dbt State は現時点ではプレビューで、SAO の後継として位置づけられています。一般提供時には正式な移行タイムラインが告知される見込みです。
こちらの内容がどなたかの参考になれば幸いです。









