
データパイプラインサービス「Fivetran」でSalesforceのデータをBigQueryにまるっと同期する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。
データアナリティクス事業本部ソリューション部プリセールススペシャリストの兼本です。
当エントリは『クラスメソッド BigQuery Advent Calendar 2020』4日目のエントリです。 本アドベントカレンダーでは、12月01日から12月25日までの25日間、弊社DA(データアナリィクス)事業本部のメンバーがBigQueryに関連するブログを公開していきます。
- クラスメソッド BigQuery Advent Calendar 2020 の記事一覧 | Developers.IO
- クラスメソッド BigQuery Advent Calendar 2020 - Qiita
このエントリでは、データパイプラインサービス「Fivetran」を使用してノーコードでSalesforceのデータをBigQueryに同期する手順をご紹介します。
Fivetranとは?
Fivetranは様々なデータソースからデータを抽出し、データウェアハウスへロードを自動化するサービスです。 SalesforceやSAPなど様々なアプリケーションやデータベース、イベント、ファイルから抽出したデータをデータウェアハウスにロードすることができます。 また、BIツールで可視化するにあたって、変換/加工処理をデータウェアハウス内で行うことができることも主な特徴です。
関連エントリ:
やってみた
以下、Salesforceのデータを同期する手順をステップバイステップでご紹介します。
事前準備として、Fivetranがデータを同期する先となるBigQueryのプロジェクトを作成しておきます。データセットやテーブルはFivetranから動的に作成するため、事前に用意しておく必要はありません。

FivetranからBigQueryへの接続設定
BigQueryへの接続に限らず、Fivetranでは最初にデータのDestination(宛先)を指定します。Destinationを追加するにはFivetranアカウントのOwnerロールを所有している必要があります。
任意のDestination名を入力して「ADD DESTINATION」を押下します。

データの宛先となるDestination(今回の場合はBigQuery)を選択します。

BigQueryに接続するために必要な情報を入力します。設定画面の右側にSetup Guideが表示され、それぞれの項目で設定すべき内容と(可能な場合は)その情報を確認できるサイトへのリンクが表示されますので、基本的にはSetup Guideの手順に従うことで簡単に接続の設定が完了します。

注意点として、FivetranからBigQueryへのアクセスを許可するためにFivetranのサービスアカウントに対してBigQueryへのアクセス権限を付与しておく必要があります。具体的にはGoogle Platform ConsoleでBigQueryのプロジェクトを開き、「IAMと管理>IAM」ページでSetupページに記載されているFivetranサービスアカウントをメンバーとして追加します。アクセス権限として「BigQueryユーザ」を付与します。

設定が完了したら「SAVE & TEST」を押下して接続を確認します。接続が正常に行えると以下のような表示になります。

ちなみに、適切な権限を付与していない場合は以下のようなエラーが表示されます。

FivetranからSalesforceへの接続設定
データソースとしてSalesforceを登録します。データソースの追加は「Connectors」ページから「+CONNECTOR」もしくは「CREATE YOUR FIRST CONNECTOR」(初回のみ)を押下します。

データソースとして使用可能なサービス・データベースの一覧が表示されます。結構たくさんありますが、名前でフィルタすると目的のデータソースを見つけやすいです。

選択したサービスにアクセスするための認証情報を設定します。「AUTHORIZE」を押下するとSalesforceのログイン認証が求められますので、必要な情報を入力します。
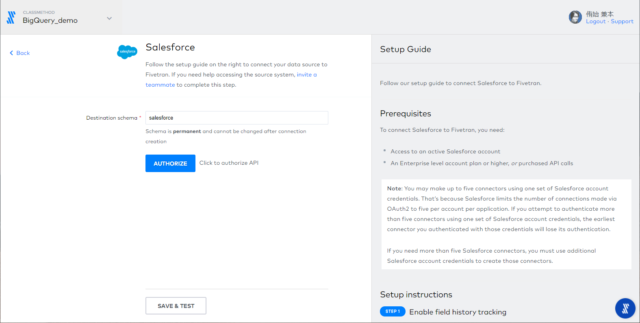
正常に認証できると以下のような画面が表示されますので、そのまま同期の設定を行う場合は「VIEW CONNECTOR」を押下します。

Connectorが接続するサービスのスキーマ情報を取得するために「Review Schema」を押下します。Fivetranの便利なところは同期するサービスのスキーマ情報を取得し、宛先のデータソースに対して同じスキーマを再現してくれるところです。
これはデータソースとしてRDBMSのような正規化されたデータを使う場合だけではなく、SalesforceやGoogle AnalyticsのようにREST API経由でデータを取得する場合も同様です。例えば、Salesforceのスキーマはこちらからご確認いただけます。

Review Schemaが完了すると同期するテーブルやカラム(フィールド)を選択します。稼働環境なので一部テーブルはモザイク処理していますが、毎回洗い替えが必要になるテーブルやデータのないテーブルに対しては同期非推奨であることを示す「!」がリストの右に表示されています。 同期したいテーブルやフィールドを選択したら「SAVE AND CONTINUE」を押下して設定を完了します。

Connectorのステータス画面に戻ると「Start Initial Sync」というボタンが表示されていますので、このボタンを押下して最初の同期を実行します。Fivetranは同期するレコードのアクティブ行に対してライセンス費がかかりますが、最初の同期は無料で実行できます。

同期実行中の状態はダッシュボードで確認することができます。

こちらは最初の同期が完了して定期的な同期を実行している状態です。

一方そのころBigQueryでは・・・
データの同期先となるBigQueryの状態を確認します。Salesforceというデータセットが作成され、その配下にはFivetran側で同期対象として選択したテーブルが複数作成されていることが確認できます。各テーブルのカラムもデータの特性に合わせたデータ型が設定されています。

まとめ
今回はSalesforceを例として利用しましたが、Fivetranはほかにも様々なサービスやデータベースに対するConnectorを用意しています。データパイプライン処理は独自に開発をするかETLツールを利用することが多いと思いますが、Fivetranは同期したDestinationに対してELT処理をスケジュール実行するトランスフォーム機能や、スキーマの変更を検知して動的にDestinationのスキーマを更新する機能を用意しています。
特にBigQuery、Redshift、Snowflakeなどのクラウドデータウェアハウスとの親和性が高いデータパイプラインサービスですので、データ連携の個別対応に疲れた貴方の参考になれば幸いです。
以上、最後までお付き合いいただきありがとうございました。









