![[レポート] Icebergとクロスプラットフォームなデータメッシュ #dbtCoalesceTokyo](https://images.ctfassets.net/ct0aopd36mqt/wp-refcat-img-a0f70de29a00d596aa50512303131e72/2fcbfee571e6db80cd904c3c64f7cecc/dbt-1200x630-1.jpg?w=3840&fm=webp)
[レポート] Icebergとクロスプラットフォームなデータメッシュ #dbtCoalesceTokyo
かわばたです。
2025年12月11日に、「Coalesce on the road Tokyo」が開催されました。
本記事はセッション「Icebergとクロスプラットフォームなデータメッシュ」のレポートです。
登壇者
-
伊藤俊廷氏
- dbt Labs スタッフソリューションアーキテクト
- dbt Labs スタッフソリューションアーキテクト
-
Lee Bond-Kennedy氏
- dbt Labs Director, Solutions Architecture
Icebergとクロスプラットフォームなデータメッシュ
本セッションでは、Apache Icebergとdbt Meshを活用したクロスプラットフォームのデータメッシュ構築について、DatabricksとSnowflakeを例に講演がありました。

アジェンダ

データプラットフォーム統制の理想的と現実

- 多くの企業では、拠点の違い、組織の独立性、歴史的背景などから、単一のデータプラットフォームに標準化することは難しく、複数のシステムが混在しているのが現実です。そうした環境でいかにしてデータを統合・活用するかを見ていきます。

Icebergの基礎
- Icebergは、表面に見えるのは氷山の一角で、水面下にある複雑なデータストレージの仕組みを抽象化するコンセプトです。

Icebergは主に3つのコンポーネントで構成

- オープンテーブルフォーマット:Parquetのようなデータファイル上に、メタデータレイヤーを追加するフォーマット。このメタデータがデータの保存場所などの情報を管理することで、クエリ性能、信頼性、再現性が向上し、データ損失のリスクも低減されます。

- データカタログ:Icebergテーブルの仕様を理解し、そのメタデータを管理するレイヤー。論理的なテーブル名を物理的なメタデータの場所にマッピングする役割を持ち、本日のデモでは、Databricksが提供するUnity Catalogをテクニカルカタログとして使用。

- RESTプロトコル:データカタログにアクセスするための、HTTPSベースの標準インターフェース。SnowflakeやDatabricks、BigQueryなどのコンピュートエンジンは、このプロトコルを通じてカタログにアクセスし、データをクエリします。

全体の構成

dbt Meshの価値
データ変換にdbtを利用していても、チームごとにワークフローが異なると、以下のような課題から組織がサイロ化してしまいます。

ワークフローが孤立すると難しくなる作業
-
ディスカバリー:参照すべき適切なモデルをリネージなしに見つけるのが困難。
-
所有権:チーム間でデータを受け渡す際の責任範囲が不明確。
-
デバッグ:システムごとにデバッグ方法が異なり、非効率。
-
メンテナンス:CI/CDが未整備だと変更に自信が持てず、上流の予期せぬ変更が下流に影響を及ぼす。

dbt Meshは、dbtプロジェクト間のモデル参照を可能にし、インターフェースや規約を明確にすることで、これらの課題を解決することができます。


オープンデータインフラストラクチャの基礎
- 複数のデータプラットフォーム間でdbtプロジェクトを連携させる
- データをコピーまたは複製することなく、任意のコンピュートエンジンによって作成されたオブジェクトを参照する
- エンタープライズ全体で統一されたデータガバナンスと発見により、組織のサイロを解消する
- ベンダー非依存のアーキテクチャをサポートする

デモ:Icebergとdbt Meshによるクロスプラットフォーム実装
- Iceberg、Databricks、Snowflake、dbt Meshを組み合わせたクロスプラットフォームのデータメッシュを構築
構成の概要
- ストレージ:S3にIcebergフォーマットでデータを保存。
- カタログ:Databricks Unity Catalogでメタデータを一元管理。
- dbtプロジェクト:上流にDatabricksプロジェクト、下流にSnowflakeプロジェクトを配置。
-
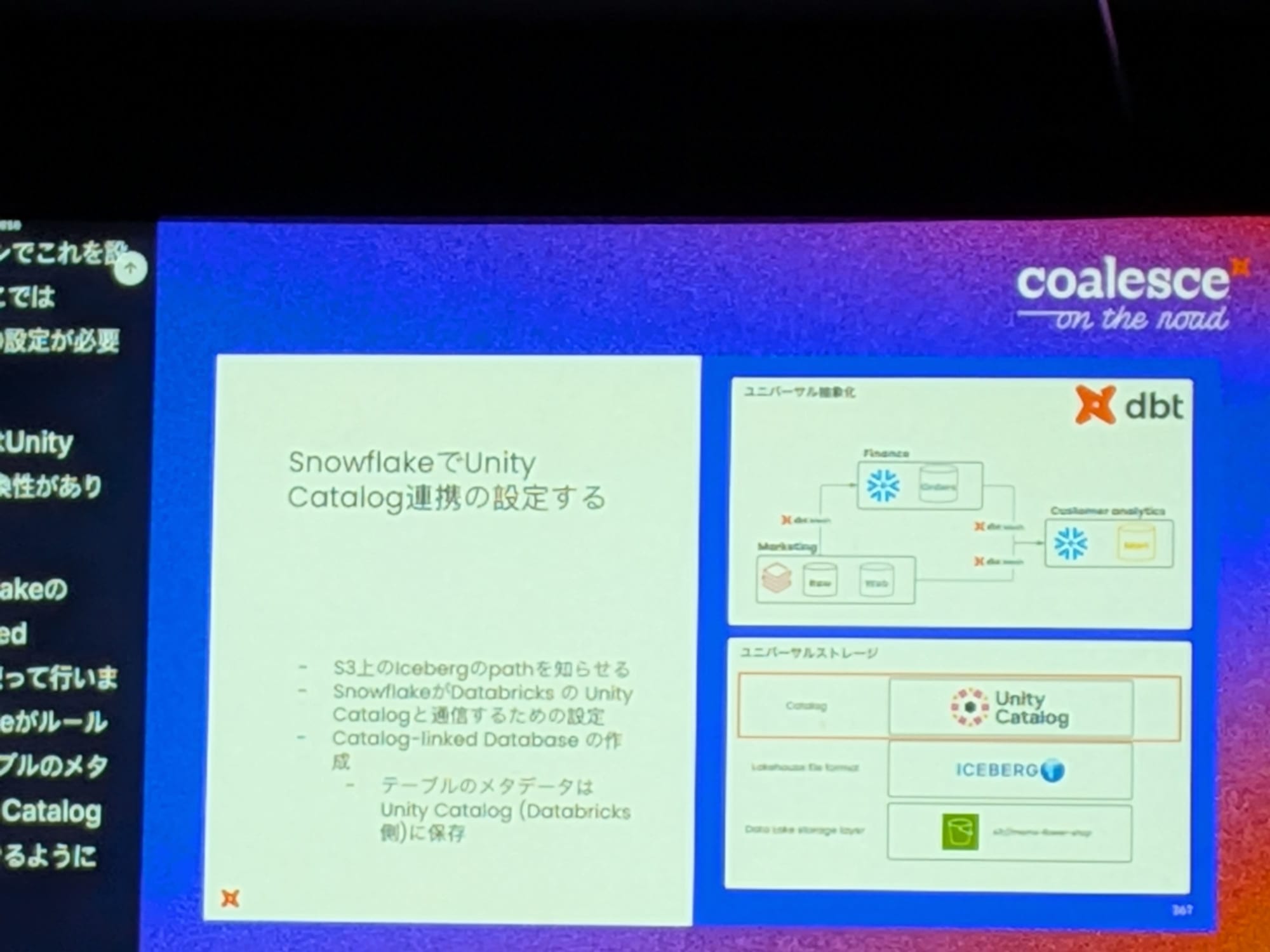
S3バケットをストレージとして定義し、Databricks Unity CatalogをIcebergのメタデータを保存する技術カタログとして設定

-
Databricks側で、S3を外部ロケーションとして設定し、Unity Catalogを定義

-
Snowflake側では「カタログ連携 (Catalog Integration)」機能を使用し、Unity Catalogを指すリンクされたデータベースを作成
これにより、メタデータが両プラットフォームでリアルタイムに同期され、どちらかで作成したテーブルがもう一方からも即座に参照・読み書き可能
-
dbt Meshにより、異なるdbtプロジェクト(DatabricksとSnowflake)間の可視性が確保


- 下流のSnowflakeプロジェクトから、ref('upstream_project_name', 'model_name') という構文で、上流のDatabricksプロジェクトのモデルを直接参照できます。
- このモデルをdbt runで実行すると、Icebergフォーマットを介して、SnowflakeとDatabricksで生成されたデータが統合された新しいテーブルがSnowflake上に作成されます。
- Snowflakeで作成されたテーブルは、メタデータが同期されているため、Databricks側からも即座にクエリ可能です。
導入時の注意点と推奨パターン
アーキテクチャは非常に強力ですが、進化の速い分野であるため、導入には以下の点を考慮する必要があります。
推奨パターン
現時点では、多くのプラットフォームがIcebergに完全対応しているわけではないため、Databricks Unity CatalogをハブとしてSnowflakeと連携するパターンが最も安定している。
考慮すべき課題
-
設定の複雑さ:Snowflake, Databricks, dbt, Icebergの各レイヤーで設定が必要となり、準備が煩雑。
-
機能の制約:プラットフォーム間で共通して利用できる機能(最大公約数)のみを選択する必要があり、命名規則などに制約がある。
-
プレビュー機能:連携アーキテクチャの多くはまだプレビュー段階であり、本番利用には注意が必要。
-
権限管理:各プラットフォームの権限ポリシーが異なるため、一貫した権限管理が複雑になる可能性がある。
-
パフォーマンス:RESTプロトコル経由のアクセスはネットワークレイテンシの影響を大きく受けるため、関連リソースはすべて同じクラウドリージョン内に配置することが強く推奨。

最後に
最近のトレンドとしてマルチプラットフォームとしてSnowflake、Databricksをはじめ複数のDWHを使用している組織は多くなってきている印象です。特にセッションの中で話されていたように組織内の部署ごとにツールが異なるパターンはケースとして多いのではないかと感じました。
このようにdbtとApache Icebergを組み合わせることで実装できると分かり大変参考になりました。
ただ、実装には考慮すべき点も多いのでスモールスタートで始めていくのが良さそうです。
私も実際に試してみたいと思います。
この記事が何かの参考になれば幸いです!










