【Company Brain】 非構造化データにメダリオンアーキテクチャの考え方を適用してAI Readyなコンテキストレイヤーを構築する
リテールアプリ共創部 ビルドチームのるおんです。
最近、米国のデータ業界(Atlanなど)やVC(a16zなど)で、AIエージェント時代の最大級のボトルネックは「モデルの賢さ」ではなく「コンテキスト」だ という議論が急速に高まっています。
たとえばa16zは、こう指摘しています。
今日の企業データは依然として非常にばらばらで整理されていない状態にあります。そのため、構造化データと非構造化データを蓄積するさまざまなデータアーキテクチャを横断して、「前四半期の売上高の伸び率は?」といった基本的な質問に答えることさえ、データエージェントにとっては困難でした。
ここでの問題の核心は、エージェントが、最も基本的な質問にさえ答えるための適切な業務コンテキストを与えられていないという点にあります。(中略)企業の仕組みやデータシステムの構造を理解するだけでなく、それらをすべて結びつけるための「暗黙知」も維持した、最新かつ適切に管理されたコンテキストが必要とされているのです。
— a16z『Your Data Agents Need Context』(筆者訳)
モデルをいくら賢くしても、渡すコンテキストが整っていなければ、エージェントは基本的な問いにすら正しく答えられません。だからこそ、モデルとデータの間に挟まる 「コンテキストレイヤー(Context Layer)」 をどう設計するかが、次の主戦場として注目を集めています。Gartnerも2026年を 「the year of context」 と位置づけ、コンテキストが企業AIの基礎的なアーキテクチャ層になると予測しています。
そして実は、これはデータ基盤に限った話ではありません。私自身、プロジェクトのコンテキスト(議事録・課題・資料といった非構造化データ)をAIに扱わせる 中で、まったく同じ壁にぶつかっていました。
以前、プロジェクトの全情報を1つのリポジトリに集約する コンテキストエンジニアリング と、意思決定を時系列で蓄積する Decision Log について記事を書きました。
簡単に説明すると、MTGの文字起こしや議事録・課題管理ツール(Backlog等)のやり取り・共有資料(パワポ資料等)・ソースコードといった プロジェクトに関わる情報をAIフレンドリーな形式(Markdown)で扱えるようにする アプローチです。こうしておくと、Claude CodeなどのAIエージェントと協働しながら、要件定義から実装まであらゆる作業を進められる ようになります。「この機能の経緯は?」「この課題に返信して」といった依頼に対して、AIが過去の議事録や課題のやり取りを根拠に答えてくれる、という世界です。
あわせて、定例会やBacklogでのやり取りから生まれた意思決定を「何を・なぜ・どの議事録や課題を根拠に決めたか」とセットで追記していく Decision Log も導入しました。これらは一定の効果がありましたが、それでも 用語の揺れを揃える辞書・業務のルール・コンテキスト同士の関係 といった「AIが正しく文脈を辿るための土台」はまだ欠けたままでした。だから決定以外のことを聞かれると、AIは結局、生のコンテキストをGrepで総当たりするしかありませんでした。
コンテキストリポジトリは、議事録・課題のやり取り・共有資料といった生データをひたすら蓄積していきます。AIに何かを聞くと、AIはキーワードで全文検索し、ヒットしたファイルを片っ端から読み込んで答えます。プロジェクト初期はこれで十分機能するのですが、コンテキストが肥大化してくると 「その検索結果、本当に正しい根拠を引けているの?」 という不安がつきまといます。実際、コンテキストリポジトリの弱点として 「集約した生データから抽出される仕様が、本当に正しいか分からない」 という懸念が生じていました。そこで、なんらかの形で生データの前段にindexや圧縮された層の必要性をずっと感じていました。
そこで今回は、データ基盤の世界で生まれた メダリオンアーキテクチャ を 手法 として使い、非構造化なmdファイル群に対して AI Readyなコンテキストレイヤー を作ってみた、という話を書きます。
コンテキストレイヤーやメダリオンアーキテクチャは、構造化データ(DB・BI)を前提にしています。議事録や課題のやり取りのような 非構造化データに対するコンテキストレイヤーには、まだ世間の確立した答えがありません 。そのため、本ブログの内容は構造化データ向けの概念を非構造化データに当てはめる チャレンジ でもあります。
先に結論
今回やったことを一言でいうと、プロジェクトのコンテキストに「コンテキストレイヤー」を作った ことです。その 手法(How) として、データ基盤の メダリオンアーキテクチャ を非構造化データ(mdファイル群)に応用しました。
全体像
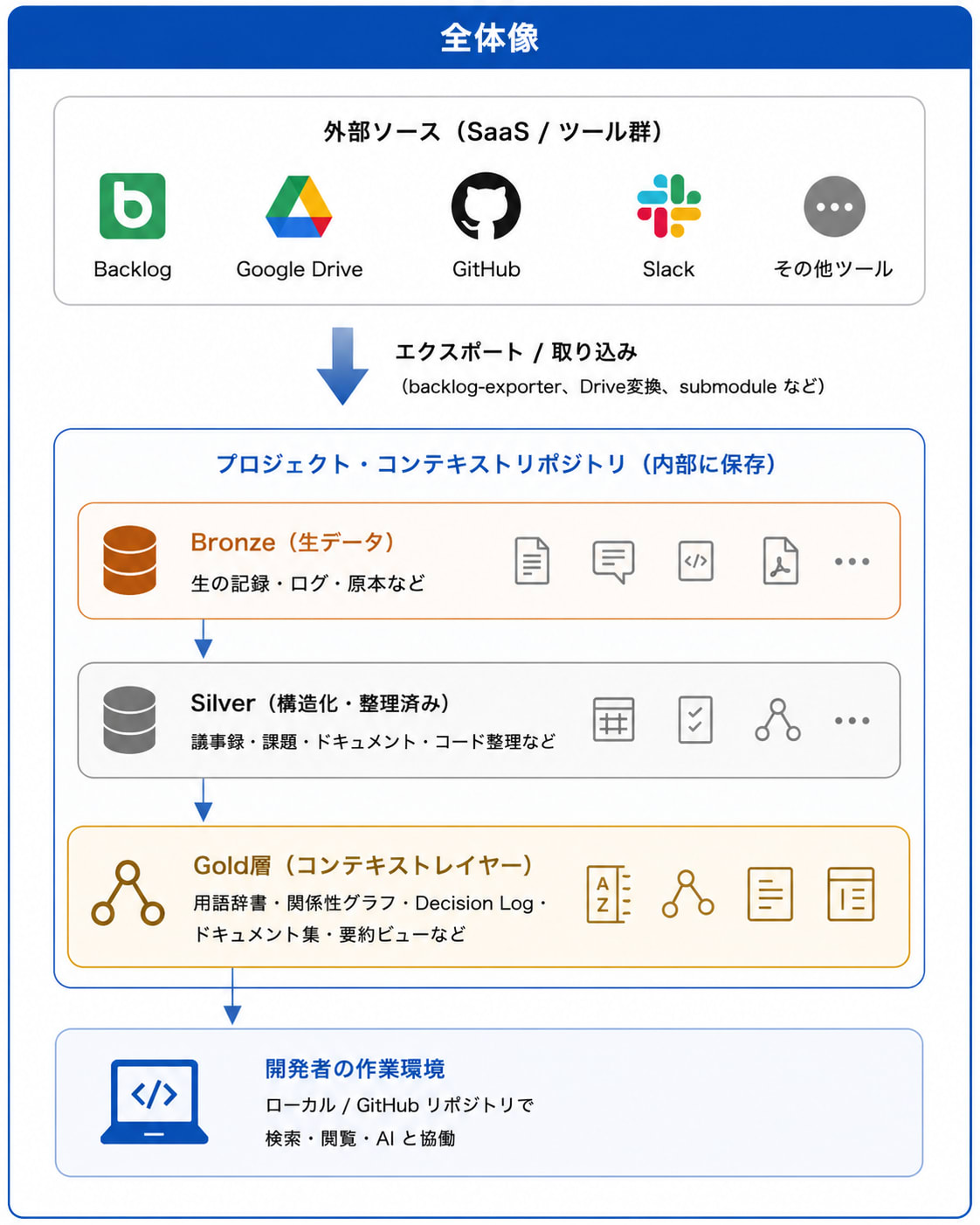
| コンテキストレイヤーなし(これまで) | コンテキストレイヤーあり(今回) | |
|---|---|---|
| AIの探し方 | 補助線が無いので、キーワードでGrep全文検索し、ヒットした生データを片っ端から読む | まずGold層を見る → 関係を辿って必要な生データだけ読む |
| データの捉え方 | 生データがフラットに同居 | Bronze / Silver / Gold の3階層で精製度を区別 |
| 根拠の確かさ | 撤回済み・古い情報も等しく「事実」として拾う | 精製済みの判断材料(Gold層)を起点にできる |
| トークン | 大量の生データを読み込んで消費 | indexとなるGold層を経由して節約 |
| ステークホルダーへの公開 | 生データに直接アクセスしてもらう | Gold層だけをWeb UI化して開放、それ以下はAI経由 |
ポイントは、Gold層が単なる「精製済みデータ置き場」ではなく、コンテキスト同士の関係をAIに伝える「コンテキストレイヤー」として機能する という点です。
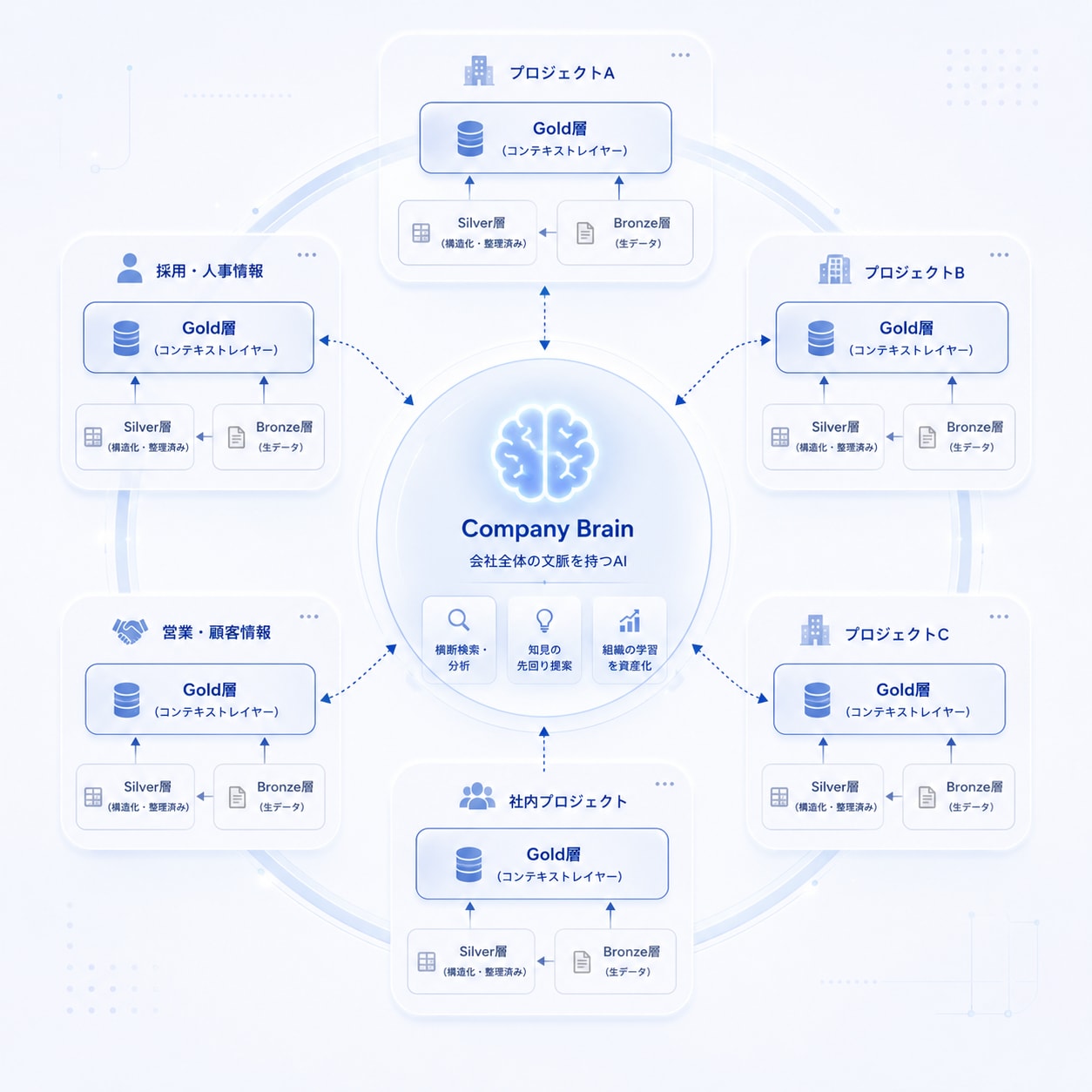
こうして案件ごとに精製したコンテキストレイヤーは、いずれ 複数の案件を横断して組織の知見を束ねる「Company Brain」(会社全体の文脈を理解したAI)の足場にもなっていきます。目の前の1案件を速くする仕組みが、そのまま組織の学習資産に積み上がっていきます。これについては、本記事の最後で改めて触れます。
順番に説明していきます。
コンテキストレイヤーとは
冒頭で、AIのボトルネックがモデルからコンテキストへ移りつつあり、その鍵が「コンテキストレイヤー」だ と触れました。先の結論でも「Gold層をそのままコンテキストレイヤーとして機能させる」と書いています。本題に入る前に、この コンテキストレイヤーが具体的に何を指す概念なのか を整理しておきます。(このあと、それを「作る手法」としてメダリオンアーキテクチャが登場し、両者は後ほど「Gold層=コンテキストレイヤー」として合流します。)
データカタログ企業のAtlanは、AIが知っていることと、人間が知っているが文書化していないことのギャップ を 「Context Gap」 と名づけ、それを埋める層がコンテキストレイヤーだと位置づけています。たとえば「先週の売上は?」に正しく答えるには、「売上」の定義(請求条件・返金ポリシー・収益認識のタイミング…)という業務コンテキストが要る。明示的に渡されなければ、LLMは もっともらしい数字を自信たっぷりに出してしまう 。このギャップを構造的に埋めるのがコンテキストレイヤーです。
| 構成要素 | 内容 |
|---|---|
| セマンティックレイヤー | 指標定義・業務用語の翻訳 |
| オントロジー | 企業内のエンティティ間の関係性 |
| オペレーショナルプレイブック | 業務手順・例外処理ルール |
| リネージ | データの来歴・依存関係 |
| アクティブメタデータ | 過去の意思決定の記憶 |
ポイントは、コンテキストレイヤーが 「生のコンテキストをただ集めたもの」ではない ということです。指標の意味、エンティティ同士の関係、データの来歴、過去の判断 — こうした 「AIが正しく推論するための補助線」を構造として束ねた層 が、コンテキストレイヤーです。
では、この「コンテキストレイヤー」が 無いと何が起きるのか、そして非構造化データでどう作るのかを見ていきます。
これまでの課題:コンテキストレイヤーが無い
まず、なぜこの仕組みが必要になったのかを整理します。
コンテキストエンジニアリングでプロジェクトの全情報をリポジトリに集約できても、その生データの上に 「コンテキストを整える層(=コンテキストレイヤー)」 が無いと、量が増えるにつれて問題が噴き出してきます。AIが生データをGrep(全文検索)で総当たりするしかない のも、突き詰めればこの層が無いことの症状の一つです。具体的には、次の2つが顕著でした。
- 1. 矛盾する情報が共存する:3月のキックオフで「通知はメールとプッシュの両方」と決めたのに、3月後半に「プッシュのみに変更」となった場合、議事録にも課題にも 両方の記述が残ります 。AIがGrepで「通知」を引くと、撤回済みの古い決定も最新の決定も等しくヒットし、どちらを採用するかは保証されません。
- 2. 検索と読み込みのコスト:mdファイルが増え続けると、AIがGrepでヒットさせて読み込むファイル数が膨大になります。検索だけで時間がかかり、生データを大量に読むことで 推論に使えるトークンを圧迫 します。
1つ目の「最新の決定はどれか」という問題は、前回の記事で紹介した Decision Log である程度解決できました。
ただ、Decision Logは「意思決定」という一種類の精製データにすぎません。用語の揺れ、コンテキスト同士の関係、来歴 — こうした「生データを正しく読むための補助線」全体を、もっと体系立てて持ちたい。
そこで今回たどり着いたのが、メダリオンアーキテクチャで作った「Gold層」を、そのまま先ほどの「コンテキストレイヤー」として機能させる という合わせ技です。メダリオン が「精製度で階層を分けて、信頼できる起点(Gold層)を作る」役割を担い、その起点に用語・関係・来歴といった補助線を束ねるのが コンテキストレイヤー の役割でした。Decision Logだけでは足りなかった部分は、後者(コンテキストレイヤー)が埋めるわけです。
まずは土台となるメダリオンアーキテクチャから見ていきましょう。
メダリオンアーキテクチャとは
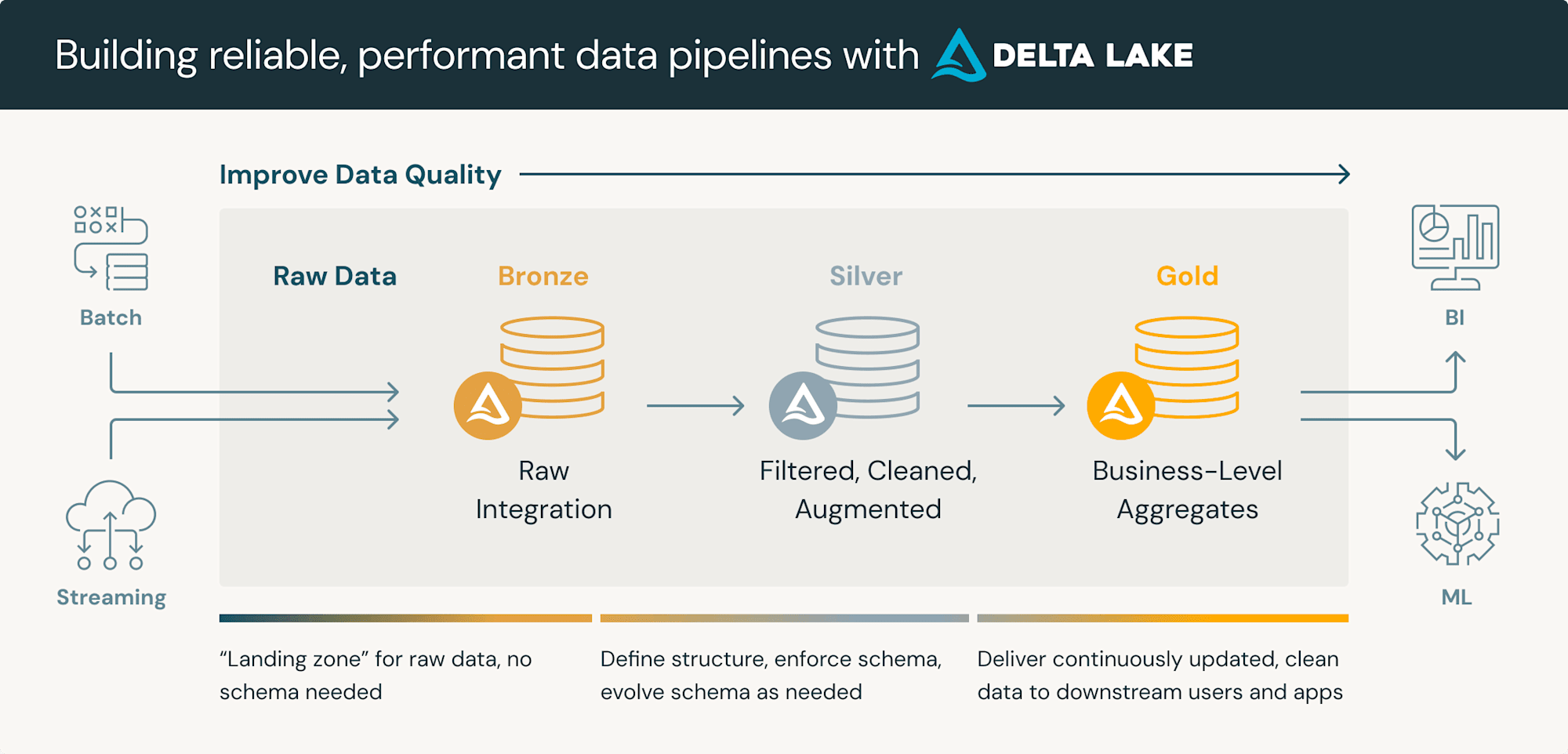
メダリオンアーキテクチャは、Databricksが提唱した、データを 精製度 によって3つの階層に分けて管理する設計パターンです。
| 層 | 一般的な定義 | データ基盤での例 |
|---|---|---|
| Bronze | 生データ。ソースからそのまま取り込んだ未加工の状態 | ログ、APIレスポンス、RAWファイル |
| Silver | クレンジング・結合された中間データ | 正規化済みテーブル |
| Gold | 集計・精製済みの、意思決定に使えるデータ | BIダッシュボード用の集計テーブル |
下流に行くほどデータが精製され、信頼して使える状態になっていく、という考え方です。
これは構造化データ(テーブル)の世界の話ですが、「精製度でデータを階層化し、下流ほど信頼できる」 という発想は、そのままコンテキストリポジトリにも当てはまるのではないか。これが今回のチャレンジの出発点です。
非構造化データにメダリオンを適用する
データ基盤のメダリオンを、我々のコンテキストリポジトリ(mdファイル群)に当てはめると、こうなります。
| 層 | 定義(精製度) | コンテキストリポジトリでの実体 |
|---|---|---|
| Bronze | 出来事の生記録 | 課題管理ツールのやり取り、MTGの文字起こし、資料の原本、ソースコード |
| Silver | 人間・AIが構造化した中間成果物(要メンテのドキュメント) | 議事録、Backlogドキュメント、GitHub Issue / Wiki |
| Gold | 最終精製済みの判断材料(積み上げ式の確定データ) | 決定事項、用語集、メンバー、ルール |
これまでのコンテキストリポジトリには、実は BronzeとSilverだけが同居 していました。生の文字起こしと、それを整えた議事録が、同じリポジトリにフラットに並んでいる状態です。
今回新たに追加したのが Gold層 です。「あとで判断のよりどころになる、精製済みの情報だけ」を1か所に集約しました。
ここで置くものの基準は 「時間が経っても正しい情報かどうか」 です。進行中の話題やその週限りの動きといった フロー情報は入れません 。いつ読んでも矛盾しない状態を保つためです。
実際のコンテキストリポジトリのディレクトリ構成としては以下のようになっています(+ が今回追加した部分)。
<案件>-context/
+├── Cortex/ # ★今回追加した Gold層(精製した判断材料だけを集約)
+│ ├── Home.md # 入口(案件の識別カード+このプロジェクトが目指すもの)
+│ ├── Decisions/ # 意思決定記録
+│ ├── Glossary/ # 用語の定義
+│ ├── Members/ # 関係者の名簿(人名の表記ゆれの解決も兼ねる)
+│ └── Rules/ # この案件で継続的に守る約束事
├── 課題管理/ # 課題管理ツール(Backlog等)の同期ミラー
│ ├── issues/ # 課題のやり取り(Bronze)
│ ├── documents/ # 要件定義書・仕様書(Silver)
│ └── wiki/
├── 会議/ # 文字起こし(Bronze)と議事録(Silver)が同居
├── 開発/ # GitHub の同期ミラー
│ ├── issues/
│ ├── src/ # ソースコード(Bronze)
│ └── wiki/ # 設計ドキュメント(Silver)
├── 共有資料/ # 提案資料・PDF等をMarkdown化(Bronze/Silver)
└── デザイン/ # 画面インベントリ(Figma同期)
├── inventory/
└── resources/
*実際のディレクトリ構造
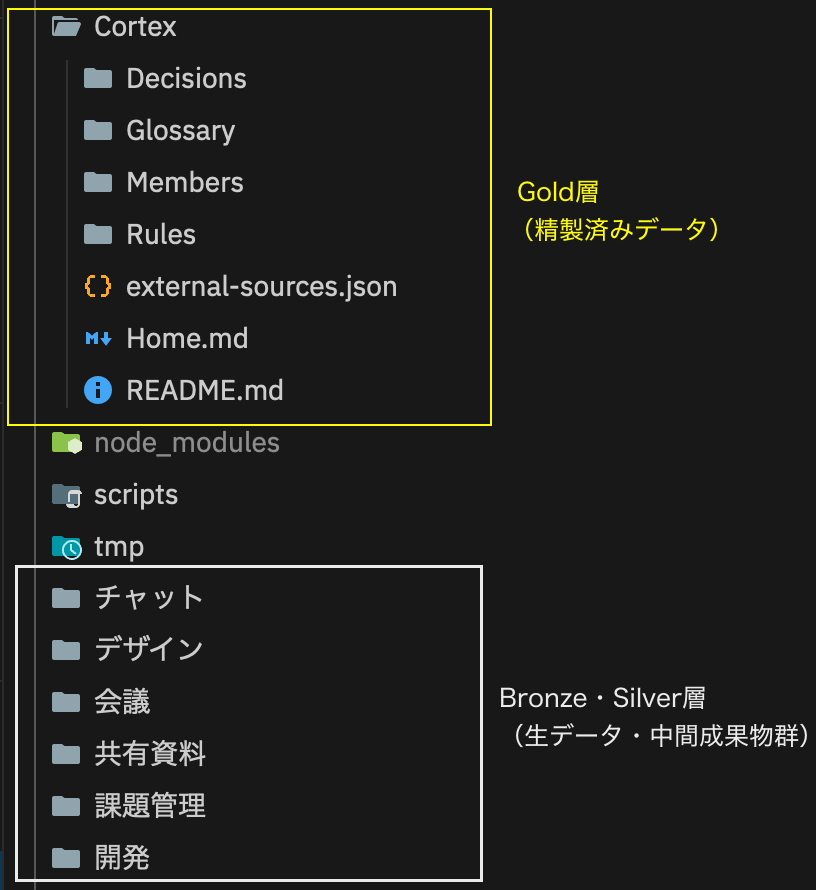
Gold層は Cortex/ という1つのフォルダに集約しています(決定事項・用語集・メンバー・ルール)。生データ(Bronze/Silver)はソース別の元の場所(わかりやすいように日本語名でのディレクトリ)に置いたまま、精製した判断材料だけを Cortex/ に集めている、という形です。(Cortexは本プロジェクトにおけるGold層を表す造語で、いまはこの仕組み全体の名前としても使っています)
そして Cortex/Home.md には、識別カード(後述)とあわせて 「このプロジェクトが目指すもの」 を書いています。「解きたいこと(誰の・何の課題を・どう解くか)」と「達成した状態(どうなったら成功と言えるか)」の2項目です。AIは現在地(決定・用語・ルール)だけでは動けず、目的地との差分 があって初めて「次に何をすべきか」を導けます(ループエンジニアリング)。
Gold層の中身・生成方式については後ほど詳しく解説します。
Gold層を「コンテキストレイヤー」にする
ここからが今回の肝です。
前述のコンテキストレイヤーの議論は、主に 構造化データ(データベース・BI) の世界の話でした。今回のチャレンジは、これを 非構造化なmdファイル群 で実現することです。そしてその担い手になるのが、メダリオンで切り出した Gold層 です。
つまりGold層は、単なる「精製済みデータ置き場」ではなく、プロジェクトにおける 「コンテキストレイヤー」 として機能させます。
実体としては、Gold層は 1レコード = 1ファイル(1つの決定・1つの用語・1人のメンバー・1つのルールを、それぞれ独立したmdファイル)として持っています。そして、各ファイルのfrontmatter(先頭に置くメタデータ)に「関係性のタグ」 が付いていて、これが生のコンテキストへの参照になっています。
Cortex/
├── Decisions/
│ └── records/
│ ├── 20260610-001-プロジェクトの全コンテキストを本リポジトリに集約する.md
│ └── 20260610-002-コンテキストをオントロジーで構造化する.md
├── Glossary/
│ └── records/
│ ├── コンテキスト.md
│ └── クラスメソッド.md
├── Members/
│ └── records/
│ └── 山田太郎.md
└── Rules/
└── records/
└── 本番リリースは金曜を避ける.md
各レコードには、以下のようなfrontmatterが貼られています。
---
type: decision # エンティティ型
id: "20260610-001" # 安定ID(YYYYMMDD-NNN)
relations: # 機械向け:型付きの関係(安定IDで張る)
- rel: based_on # 根拠
target: "minute:定例会:20260604" # 6/4の定例会の議事録
- rel: supersedes # 古い決定を置き換える
target: "20260320-005" # 3/20の決定を上書き
references: # 人間向け:自由記述リンク
- "会議/Ph.1/20260604/minutes.md"
---
たとえば「この意思決定は、6/4の定例会の議事録を根拠にしている」という関係が、based_on という関係タグと安定ID(minute:...)で表現されます。どの決定が、どのコンテキストから来たのか を機械的に辿れるわけです。
ポイントは2つです。1つは、関係を ファイルパスではなく安定ID で張ること(生データは同期で上書き・改名されるため、パスだとすぐ切れる)。もう1つは supersedes で 古い決定を「置き換えた」と宣言できる こと。冒頭で挙げた「通知はメール+プッシュ → プッシュのみ」のような矛盾も、最新の決定が古い決定を上書きするので、AIは関係を辿るだけで現行版にたどり着けます。
先ほど挙げたコンテキストレイヤーの5つの構成要素に、我々のGold層のデータを当てはめてみると、こうなります。
| 構成要素 | 内容 | 我々のGold層での実体 |
|---|---|---|
| セマンティックレイヤー | 業務用語・指標の定義と翻訳 | Glossary(用語集)(プロジェクト固有のユビキタス辞書) |
| オントロジー | エンティティ間の関係性の定義 | ontology.md + frontmatter規約(型・安定ID・関係型を定義) |
| オペレーショナルプレイブック | 業務手順・例外処理ルール | Rules(ルール) + 各種Skill |
| リネージ | データの来歴・依存関係 | frontmatterの relations / references / source が張る来歴グラフ |
| アクティブメタデータ | 過去の意思決定の記憶 | Decisions(決定事項) |
構造化データの世界で語られていた5つの要素が、mdファイル群でもそっくり再現できる。コンテキスト同士がどういう関係で繋がっているかを、AIに明確に伝える — このGold層こそが、非構造化データに対するコンテキストレイヤーの実体です。
特に オントロジー では、エンティティ型(decision / minute / issue / term …)、安定IDの規則、関係型(based_on / derived_from / supersedes / relates_to)を定義しています。これにより「どの意思決定が、どのコンテキストから来たのか」を型として辿れるようになります。
そして、これらのGoldレコードは GitHub Actionsで毎晩自動生成・追記 されます。cronで起動したActionsがBacklog等を最新化し、Claude Code(CLI)をヘッドレス実行 して 前回実行以降のGit差分(直近約25時間)だけ を走査、新しいレコードを1ファイルずつ追記します。
| ワークフロー | スケジュール | 生成先 |
|---|---|---|
| Gold昇格 | 毎日 22:00 JST | Cortex/Decisions/ Cortex/Glossary/ Cortex/Members/ Cortex/Rules/(AI生成分は status: draft) |
ここで効くのが、push前に必ず検証を通す ことです。いまは3種類のガードレールが走ります。
- スキーマ検証:オントロジー規約に違反したレコードはCIで弾き、壊れたコミットをpushしない
- 参照lint:実在しないスキル名や、撤去済みのディレクトリへの参照を検出する。ドキュメントの陳腐化は「AIに存在しないものを読ませる」ことになるので、放置すると初動が狂う
- 矛盾検知:新しく抽出した決定を「新規/重複/矛盾」の3択で判定し、既存の決定と食い違う場合は
supersedesを張って置き換える
「AIが自動で書くが、関係を辿れる形式は機械的に保証される」状態を作れます。
また、Gold層だけをViewerでUI化 し、メンバーがUIからこれまでの確定事項(Gold)を読めるようにしています。各レコードから該当mdのGitHub編集画面へ1クリックで飛べるようにして、「AIが下書きを書き、人間がUIから承認・修正する」 Human-in-the-loopを回しています。
さらに 「AIで編集」「AIで登録」 ボタンも用意しています。押すとプロンプトが入った状態でClaude Codeが開くので、Gitやターミナルを触ったことがない人でも 、Gold層のレコードを直したり新しく登録したりできます。Viewerが表示するのはGold層だけなので、このUIを開くこと自体が「本体はここです」という説明 にもなっています。
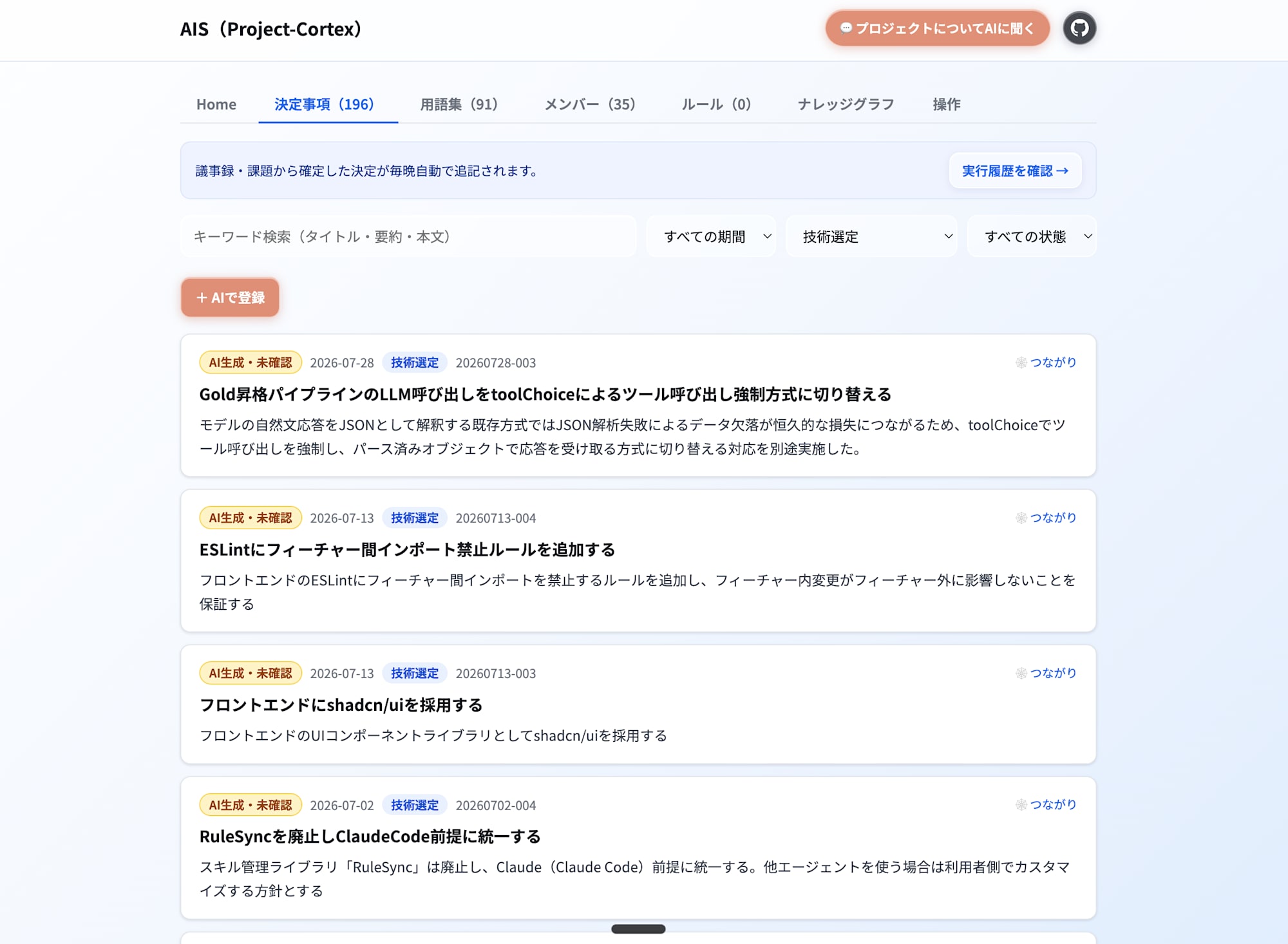
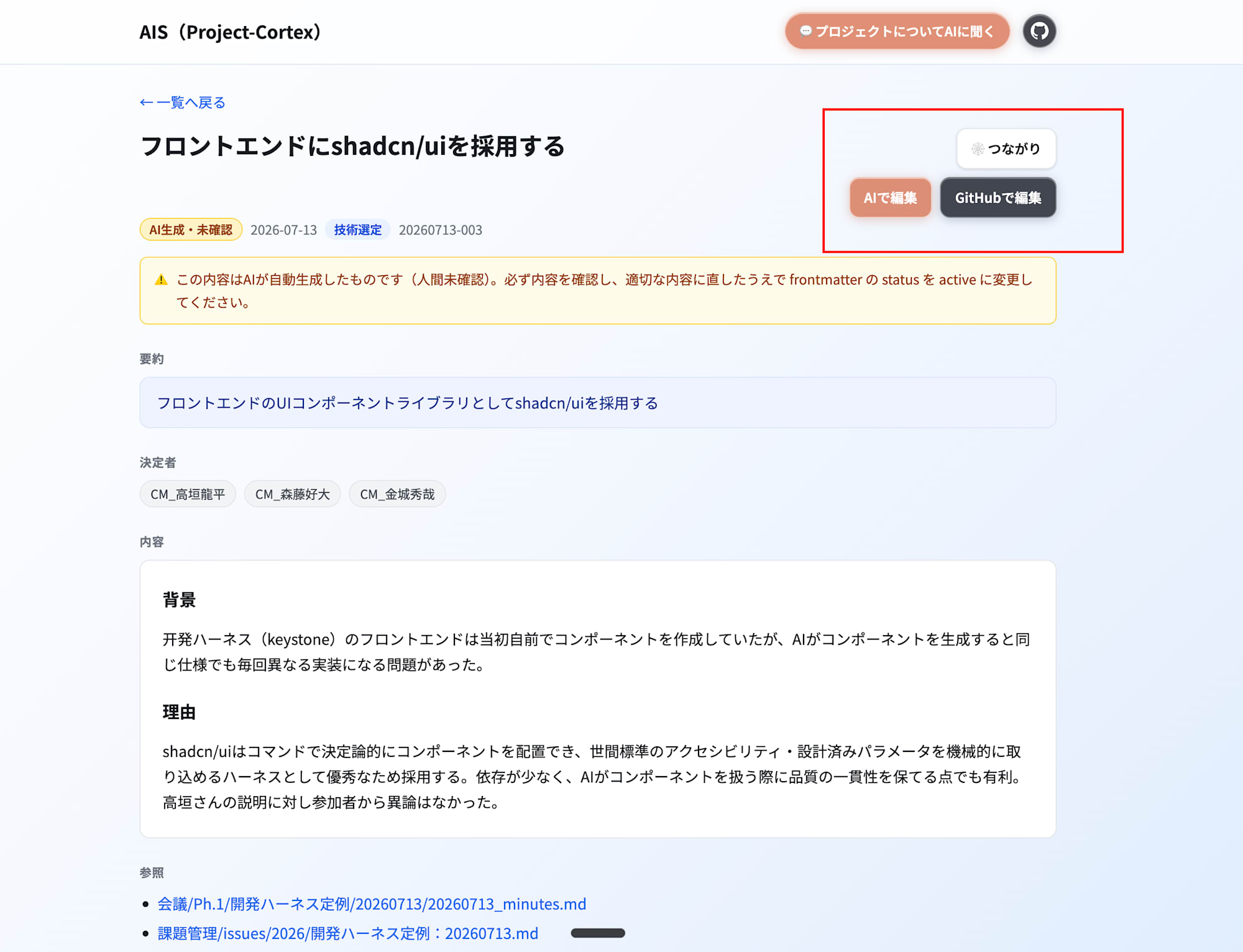
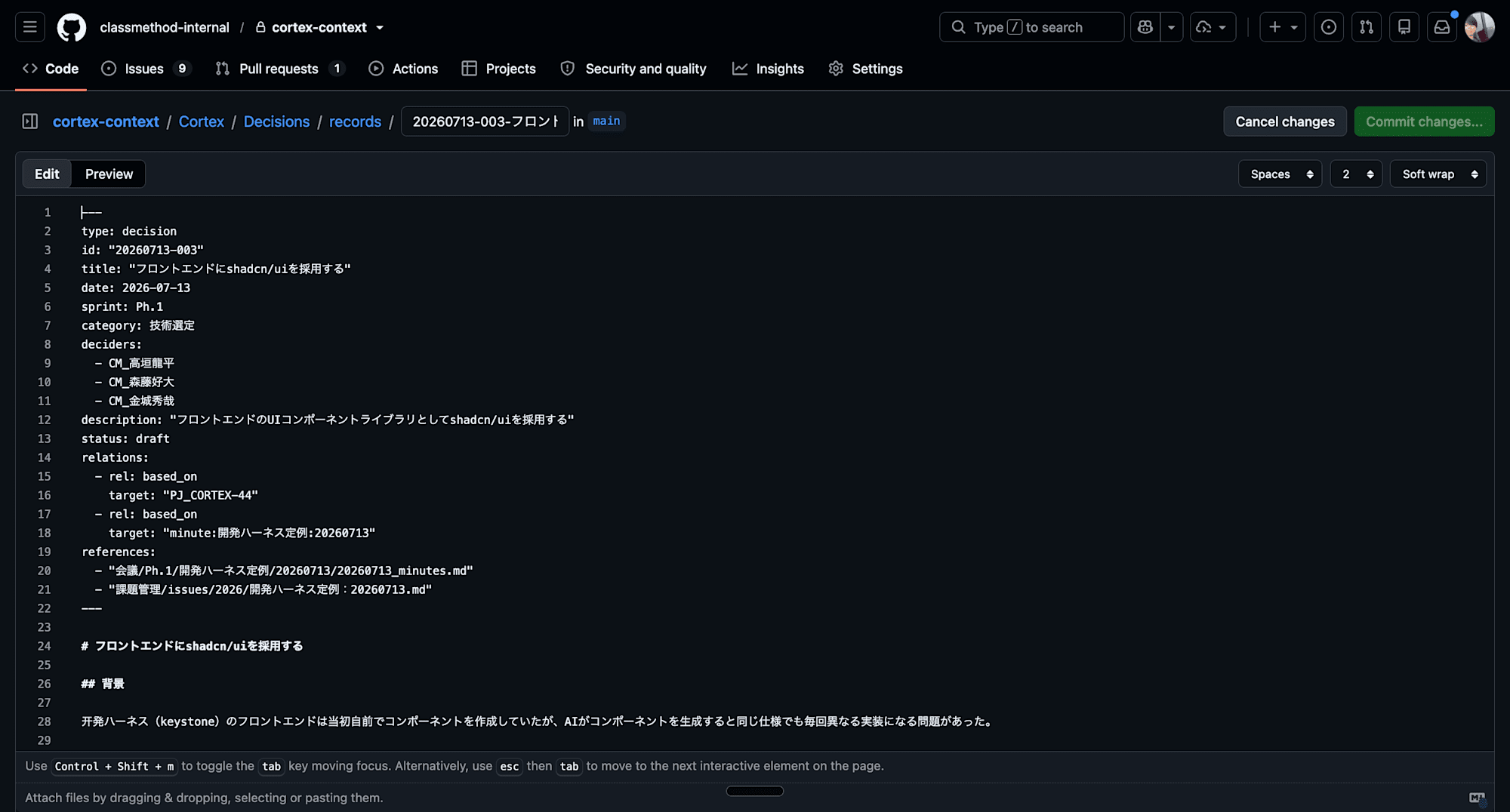
AIの「探し方」の変化
このコンテキストレイヤーを追加すると、AIの動きが 「特定の単語でGrep検索」から「まずGold層を見る → 関係するコンテキストだけを辿って読む」 に変わります。
たとえば「クーポン機能の仕様を教えて」とAIに聞いたとき、
- 従来:「クーポン」でリポジトリ全体を全文検索し、ヒットした生データを片っ端から読む。撤回済みの古い決定も拾う
- 今回:まずGold層からクーポンに関連するレコード(用語の定義・最新の決定)を見る。そこから関係付けられた生のコンテキスト群(Bronze・Silver)にだけアクセスして答える
Grep時代と比べて、ハルシネーションを減らし、トークンを節約しながら、正しい根拠にアクセスできる ようになります。全案件を横断走査するような巡回エージェントを作る場合も、入口がGold層に揃っているので同じ恩恵を受けられます。
ちなみに、この「まずGold層、次に関係を辿って生データ」という動き方は、AIの気まぐれに任せているわけではありません。リポジトリの ルールファイル(CLAUDE.md 等)に探索戦略として明文化 して、毎回この順序を守らせています。
### 探索戦略: Gold起点の二段構え
- 第一段: まず Cortex/(Gold層)を読む(Home → Glossary → Decisions → Rules)
- 第二段: Gold層のfrontmatterが指す安定ID(課題キー・議事録ID等)を辿り、
必要な生データだけをピンポイントで開く
- フォールバック: Goldに手がかりが無いときだけ、生データをGrep検索する
(最初からリポジトリ全体をGrep全文検索するアプローチは取らない)
コンテキストレイヤーを「作る」ことと、AIに「まずそこを読め」と指示すること は、セットで初めて効きます。
そして、これをViewerとして ナレッジグラフ で表示してみました。Gold層を中心に据え、frontmatterから「どのSilver・Bronzeコンテキストとどう関連しているか」をプログラム的に紐づけることで、AIが実際にコンテキストを参照していく順番 を可視化したものです。つまりこれは、AIが読み込むコンテキストの順番(リネージ) を、そのまま絵にしたものだと言えます。
下のGIFでは、中央のGoldレコード(決定・用語)を起点に、frontmatterの関係タグが指す議事録・課題のノードへと線が伸びていく様子が見えます。各ノードはリンクになっていて、クリックすると根拠となるBacklogやGitHubなどの実物に飛べます。コンテキストレイヤーの「リネージ」が、そのまま可視化UIになっている形です。
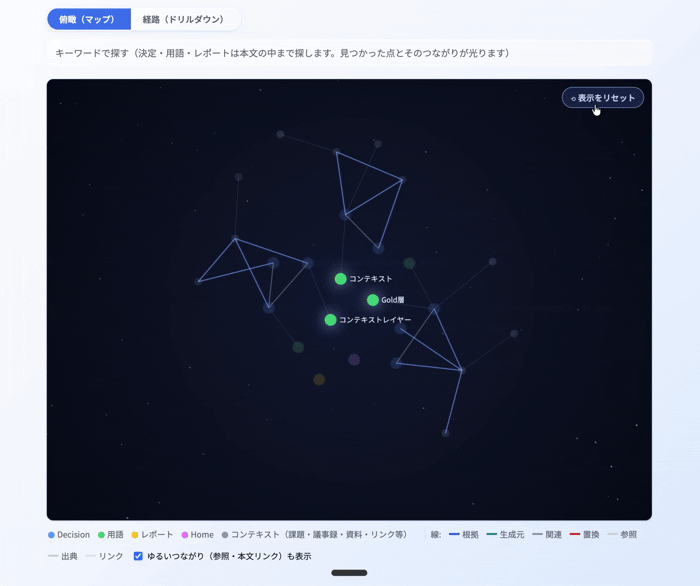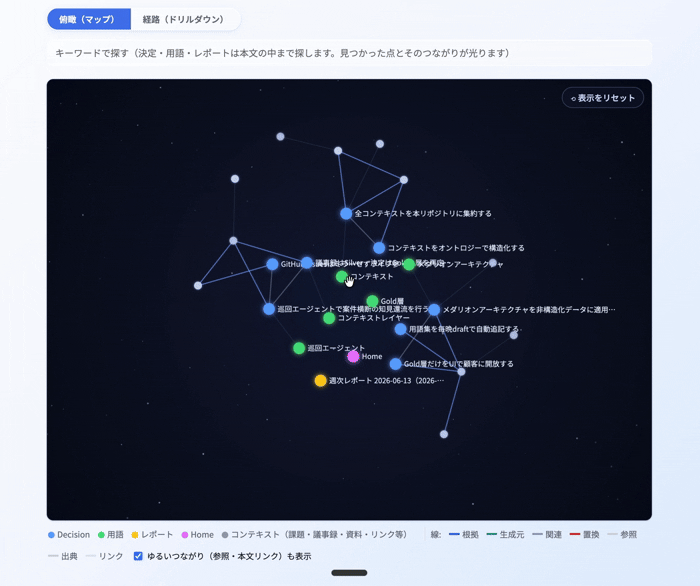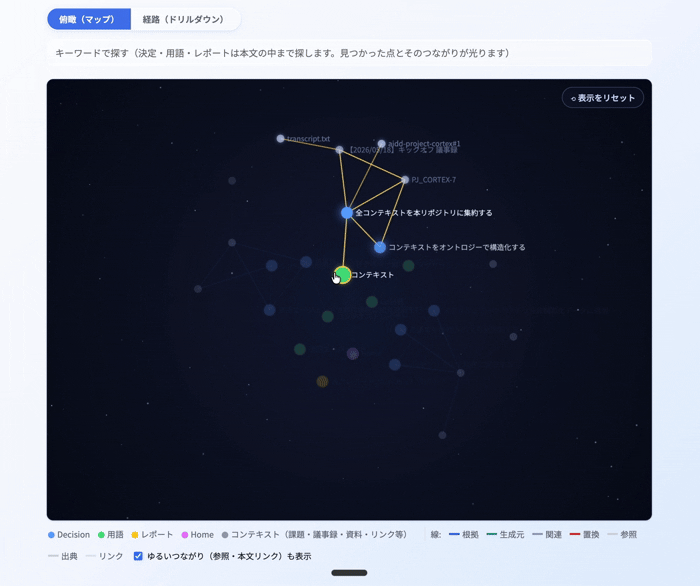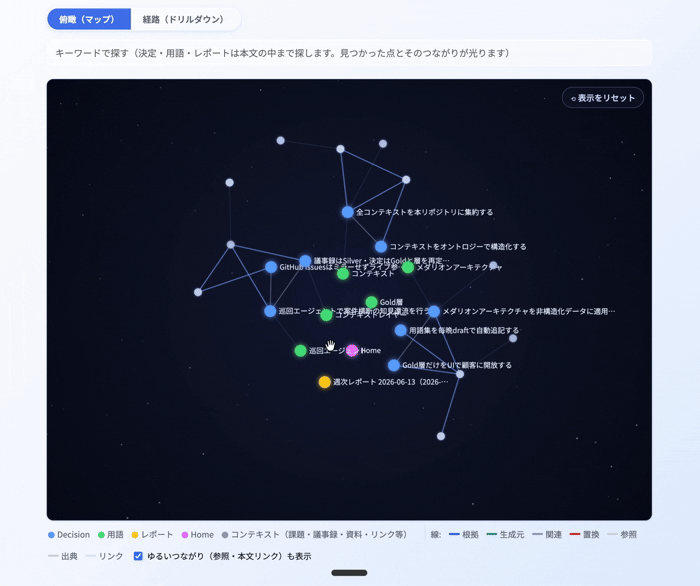
また、ドリルダウン形式でも同じようにGoldレイヤーからSilver・Bronzeコンテキストにも辿れるようにViewer化してみました。
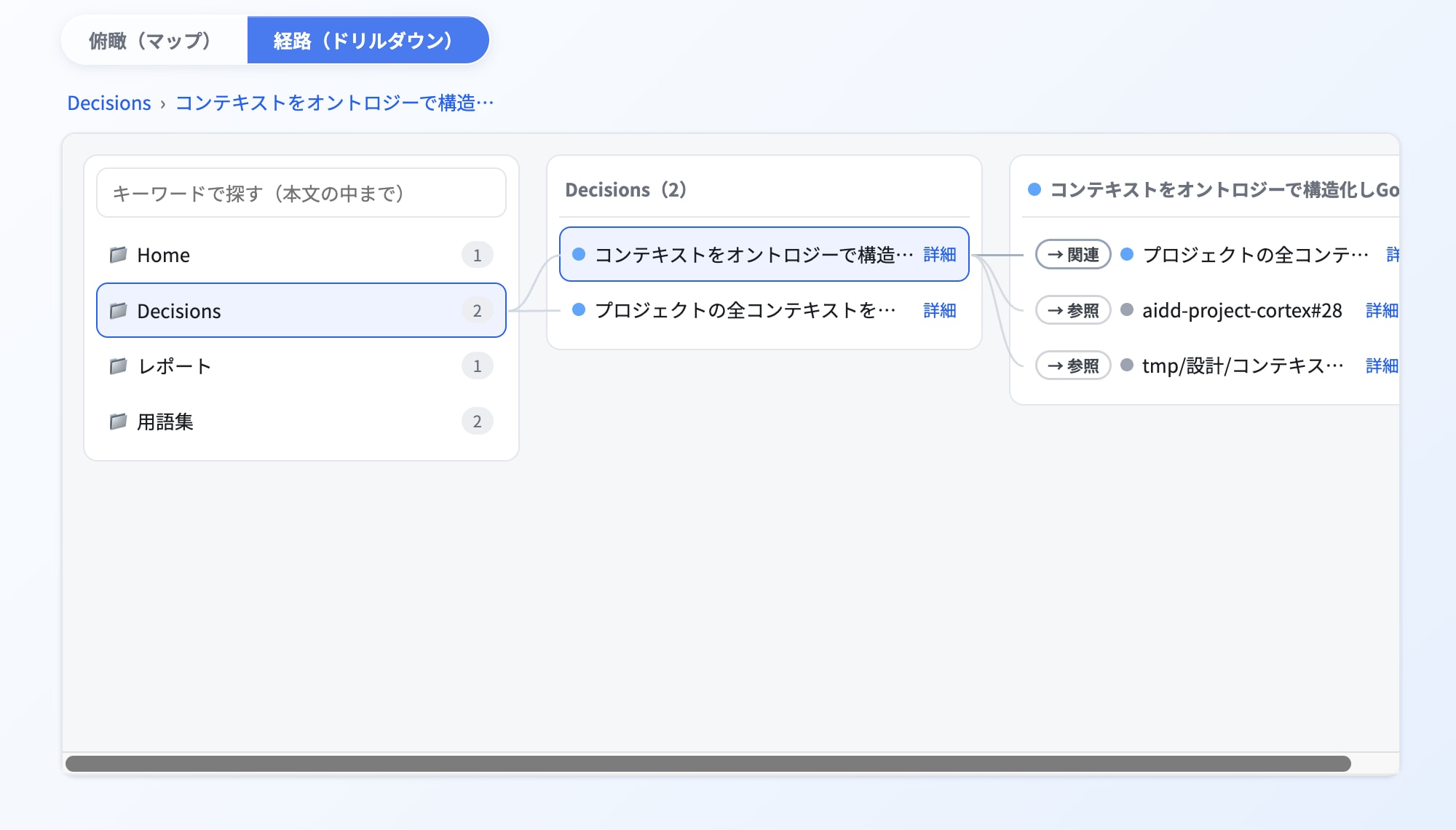
取り込みアプローチの懸念と、コンテキストレイヤーの普遍性
ここまで、Bronze/Silverなどの生コンテキストを backlog-exporter やsubmodule、Google Driveからの変換などで GitHubリポジトリに取り込む 前提で書いてきました。
ただ、ツールごとにカスタムな取り込み配管を作るのは大変で、組織である程度ツールが固定化されている必要があり、あまりスケールしません。一方で、MCPやコネクタが各SaaSから提供され、機能が強化されていけば、わざわざ手元に取り込まなくても、必要なときに外側へライブで取りに行く ほうが筋がよくなるはずです。世間の流れも明らかにそちらを向いています。
リポジトリや手元のローカルにためておくと、Grep検索を活用し、APIの遅延を感じずにコンテキストを参照させ、mdプレビューを確認しながらClaude Codeと協働して全ての作業を完結できる体験が非常によかったので、当初はこのアプローチをとっていました。しかし、外側のコンテキストを取りにいくという世間の流れとの乖離を感じる時がありました。
そこで気づいたのが、Gold層(コンテキストレイヤー)さえ自分たちで生成しておけば、その下のBronze/Silverを「内側に取り込む」か「外側に取りに行く」かに関わらず、 コンテキストレイヤーとしての価値は失われない ということです。もし外側にコンテキストを拾いにいく姿に変わっていったとしても、Gold層さえ今のうちに作っておけば、そこだけ取り外して適用可能ということです。
実際、いまはソースによって使い分けています(変換が必要な共有資料や課題管理は内側に、MCPが成熟しているSlackやGitHubのIssue / PRは外から)。
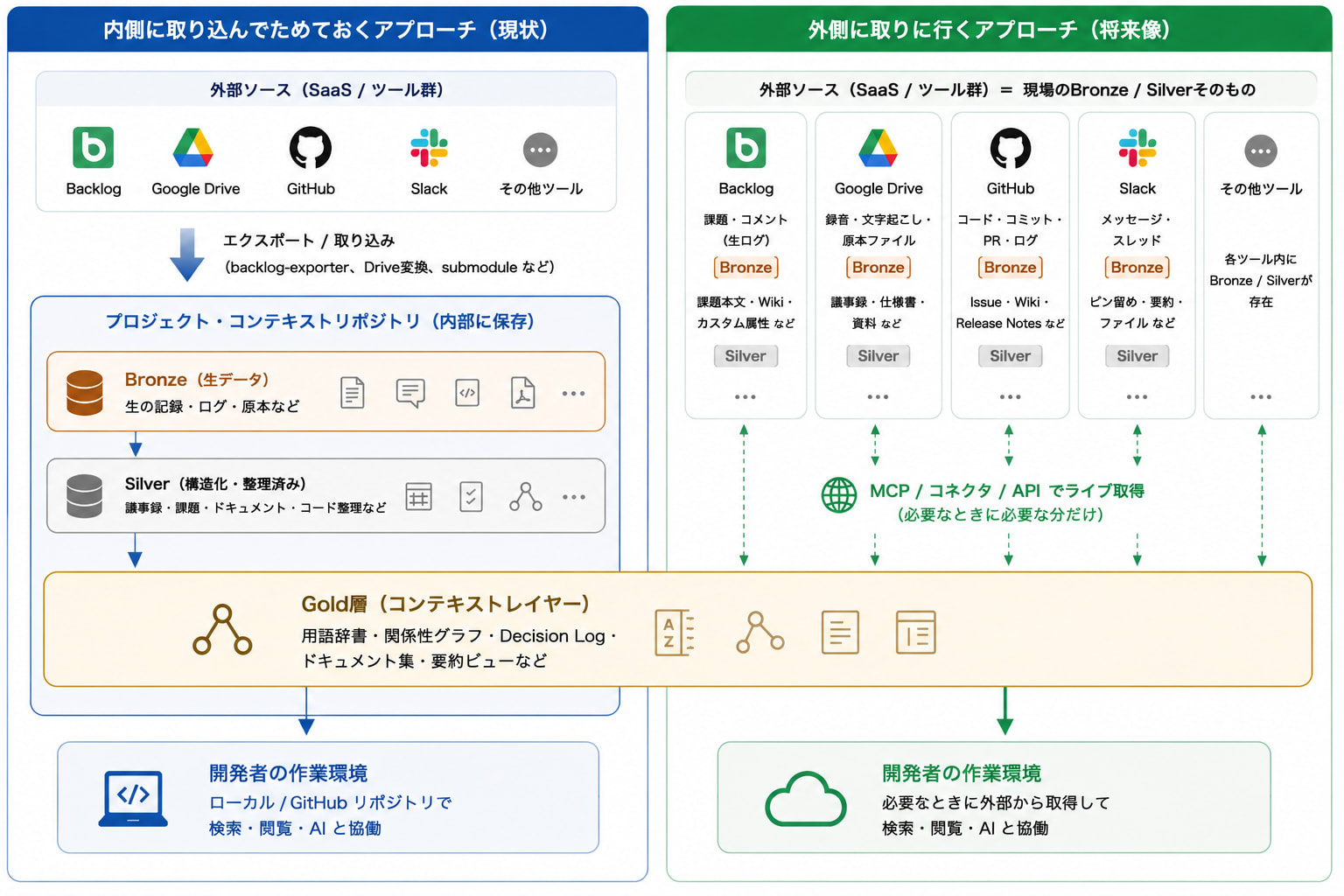
むしろ、transport(経路)がMCPでコモディティ化するほど、精製した文脈(Gold)を握っていることの価値は上がる と考えています。
Company Brainに向けて
ここまでは1つの案件の中の話でしたが、この設計の本当の狙いは、もう少し先にあります。それは、複数の案件を横断するエージェント — いわば会社全体の知見を束ねる Company Brain のような存在を見据えている、ということです。
Company Brain とは、会社の中に散らばったあらゆる情報 — 案件のやり取りはもちろん、社内プロジェクト・営業や採用の記録・社内ドキュメント・各種ナレッジなど — を横断的に理解し、「会社全体の文脈」を持ったAI として振る舞う存在を指す概念です。個々の人間が抱える属人的な知識や、組織のあちこちにバラバラに眠っている知見を1つの知能に束ね、「会社の誰が・どんな問いを投げても、全社的な蓄積を根拠に答えられる」状態を目指すものです。冒頭で触れた、データ基盤の文脈で語られる「コンテキストレイヤー」を 組織全体のスケールに引き上げたもの 、と捉えるとイメージしやすいかもしれません。
受託開発をやっていると、別の案件で得た「この業界ではこの要件が落とし穴になりやすい」「この機能はこう設計するのが定石」といった知見が、次の案件でそのまま効くことがよくあります。これを人の記憶や口伝えに頼るのではなく、全案件のコンテキストリポジトリを横断走査して、過去の知見を新しい案件に先回りで届ける — そういうエージェントを作れたら、組織の学習そのものが資産になります。また、この仕組みは企業案件にとどまらず、社内のあらゆる非構造化データに対して適用可能です。
実は、今回のメダリオン+コンテキストレイヤーは、単一プロジェクトで見ると"あると便利"ですが、この横断エージェントから見ると"無いと成立しない"前提条件 になっています。
- Gold層が横断走査の入口になる:何十ものリポジトリを毎回全文走査するのは非現実的です。圧縮済み・型付きのGold層があれば、エージェントは「この案件を深く読むべきか」をまず軽量に判断できます
- 共通オントロジーで案件をまたいでJOINできる:すべての案件が同じ型(
decision/term…)と安定IDを使っていれば、「全リテール案件の"会員証"に関する決定を集める」といった 横断クエリ が成立します。案件ごとにスキーマがバラバラだと、これは原理的に不可能です - リネージで根拠を示せる:横断するほど「なぜそう言えるのか」の説明責任が重くなります。来歴をたどれれば、「この示唆はA案件のこの決定が根拠」と出典付きで提示できます
そして、この横断を意識した仕掛けが、各案件の入口である Home.md の frontmatter(識別カード) です。本文を読まなくても、frontmatterだけで案件を分類・ルーティングできるようにしてあります。
---
type: overview
id: "overview:home"
kind: 案件 # 案件 | 社内プロジェクト
org: 〇〇部 # 所有部署
client: 〇〇株式会社 # 顧客(案件のみ)
lifecycle: active # active | archived
domains: [retail, 会員証] # 業務ドメイン(類似案件の発見に使う)
platforms: [Web, LINE miniapp] # 技術(横断検索に使う)
---
## このプロジェクトが目指すもの
**解きたいこと**: 紙の会員証を運用している店舗スタッフと会員の手間をなくし、提示・確認を数秒で終わらせる
**達成した状態**: 全店舗でミニアプリの会員証が使われ、紙の発行を停止できている
横断エージェントは、まずこの識別カードだけを読んで「進行中(lifecycle: active)のリテール案件(domains に retail)」を絞り込み、そこからGold層に降りていけばいい。1案件のGold層が、そのまま横断知能の1ノードになる という設計です。
この横断エージェントは、 Loop Engineering を用いて、組織全体を巡回させます。
もちろん、ここから先には課題もあります。全案件で同じ規約を守り続けるガバナンス、記号的なID一致だけでは拾えない 意味的なマッチング(埋め込み等の層)、そして案件をまたぐときの 顧客ごとの情報境界(entitlement) — このあたりは、横断の規模が大きくなるほど効いてきます。ただ、これらに取り組むにしても、足場となるGold層と共通オントロジーが各案件に揃っていること が大前提です。案件がまだ少ない今のうちに、この規約を固めておくこと自体が布石になる、と考えています。
おわりに
今回は、データ基盤の世界の メダリオンアーキテクチャ という概念を、非構造化なmdファイル群に適用し、AI Readyなコンテキストレイヤー を作ってみた話を紹介しました。
要点を振り返ります。
- 生データをGrepで探させる前提には、矛盾する情報の共存 と 根拠の不確かさ という弱点があった
- データを精製度で Bronze / Silver / Gold の3層に捉え、精製済みの判断材料を Gold層 として集約した
- Gold層は単なるデータ置き場ではなく、frontmatterの関係タグによって コンテキスト同士の関係をAIに伝える「コンテキストレイヤー」 として機能する
- これにより、AIの動きが 「Grep全文検索」から「Gold層起点 → 関係を辿る」 に変わり、ハルシネーション削減・トークン節約・正しい根拠へのアクセスが実現できる
- Goldレコードは 1レコード1ファイル で、GitHub Actionsが毎晩自動で追記 し、push前の スキーマ検証・参照lint・矛盾検知 で形式と整合を保証する。
- Gold層自体の信頼は、一次ソースへのリネージ と CI・人間レビューのガードレール(Viewerから1クリックで編集) で担保する。リネージはそのまま ナレッジグラフ/ドリルダウンのViewer として可視化できる
- 生コンテキストの取り込みは 「内側に取り込む」か「外側へライブで取りに行く」かを問わず差し替え可能 。
「コンテキストを大量に集めたはいいが、そこから本当に正しい情報を引けているのか分からない」 — これはコンテキストエンジニアリングを実践する誰もがぶつかる壁だと思います。構造化データの世界で培われた メダリオンアーキテクチャ で「Gold層」を切り出し、それを コンテキストレイヤー として機能させる。この合わせ技を非構造化データに持ち込むことが、その壁を越える一つの手がかりになるのではないか、と感じています。
そして、こうして1つずつ整えたGold層は、いずれ案件にとどまらず 社内のあらゆる文脈を横断するCompany Brain の足場になります。目の前の1プロジェクトを速く正確にするための仕組みが、そのまま組織全体の学習資産に積み上がっていく — そこまで見据えて、コンテキストの持ち方を設計していきたいと思っています。
また、我々リテールアプリ共創部では、コンテキストレイヤーだけでなく、組織ハーネス、Company Brainを実現するための巡回エージェント等を構築し、AI時代にやればやるほど勝てる組織づくりを始めています。FDEが顧客に最も価値を発揮できるような環境を目指し準備を進めていきます。
以上、どなたかの参考になれば幸いです。
お知らせ
クラスメソッドのリテールアプリ共創部 ビルドチーム ではエンジニアを募集しています。
Claude Code や Cursor などの AI エージェントを業務に組み込み、プロジェクトの立ち上げから本番開発までを高速に回しているチームです。AI 駆動開発・プリセールス・顧客折衝・要件定義までフルスタックに踏み込んでみたい方は、ぜひ以下をご覧ください。
参考










