
Quickstart for dbt and Snowflake試してみた
かわばたです。
dbtLabsが提供しているガイドのQuickstart for dbt and Snowflakeについて試していきます。
関連ページは下記となります。
dbtLabsが提供しているガイド
事前準備
下記がはじめるにあたり必要な要素となります。
- dbt Cloudのアカウント
- Snowflakeのアカウント
※かわばたはdbtについてはEnterprise版,SnowflakeトライアルアカウントのEnterprise版で試しています。
1.はじめに
このセクションでは、今回実践するクイックスタートガイドでどのようなことを行うか説明がありました。詳細は下記になります。
- 新しいSnowflakeワークシートの作成
- サンプルデータをSnowflakeアカウントにロード
- dbtをSnowflakeに接続
- サンプルクエリをdbtプロジェクトのモデルに変換
- dbtプロジェクトにソースを追加
- モデルにテストを追加
- モデルのドキュメント作成
- ジョブの実行をスケジュール
2.新しいSnowflakeワークシートの作成
- トライアル版のSnowflakeアカウントにログインします。
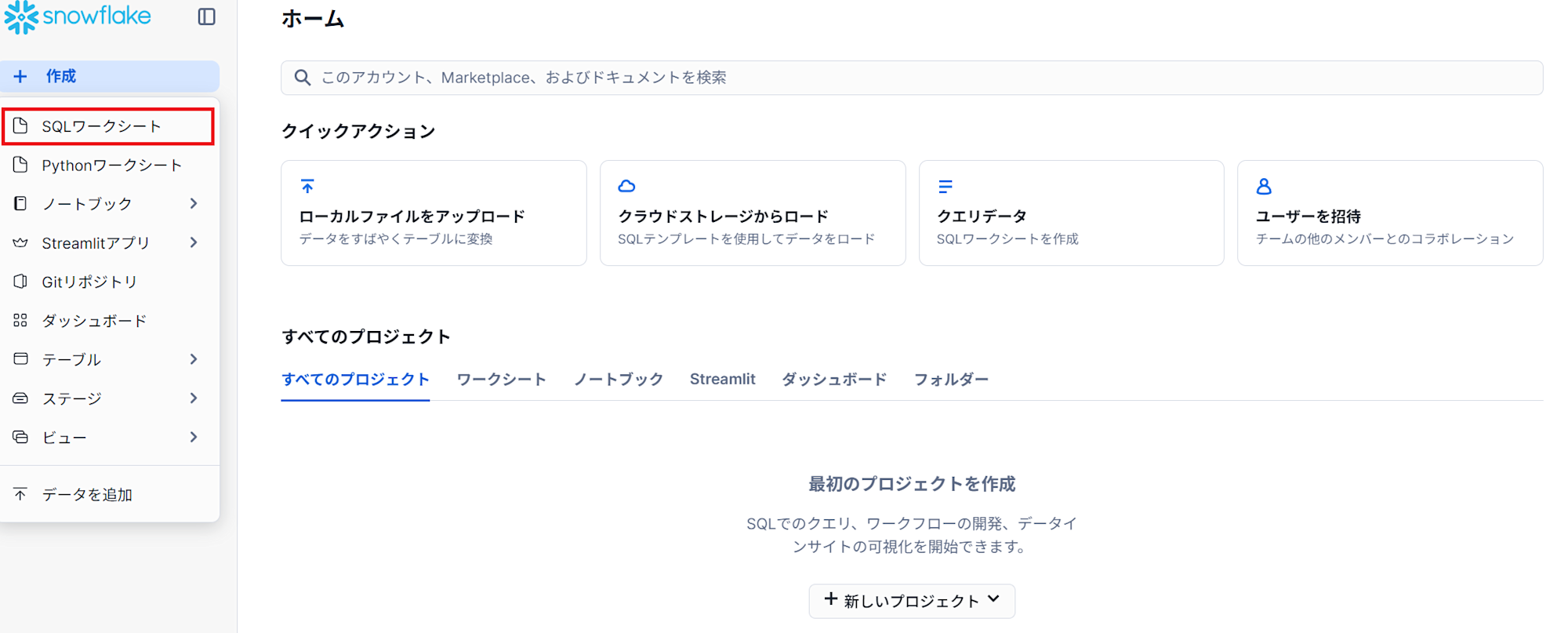
- SnowflakeUIで、Snowflakeロゴの下にある左隅の
+ 作成をクリックするとドロップダウンが開きます。最初のオプションSQLワークシートを選択します。
上記を行うと下記ページに遷移します。
3.データを読み込む
Snowflakeにデータを読み込み連携の準備を行います。
- 検証用に新しい仮想ウェアハウス、2つの新しいデータベース、2つの新しいスキーマを作成します。
先ほど開いたSQLワークシートのエディタに下記SQLコマンドを入力し、実行します。
create warehouse transforming;
create database raw;
create database analytics;
create schema raw.jaffle_shop;
create schema raw.stripe;
実行すると下記のような形で、ウェアハウス・データベース・スキーマが作成されていることが分かります。
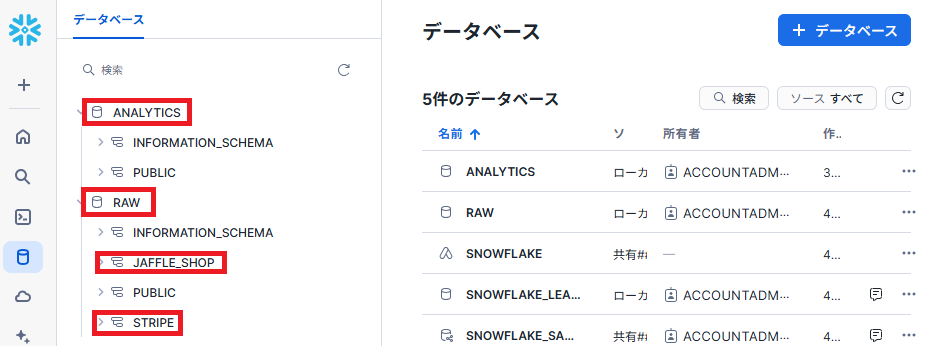
- 1で作成したrawデータベースに対して、関連するデータ(
customer,orders,payment)をCOPYコマンドを用いてロードしていきます。
- customerテーブルの作成
create table raw.jaffle_shop.customers
( id integer,
first_name varchar,
last_name varchar);
- COPYコマンドを実行してcustomerテーブルにデータをロード
```sql
copy into raw.jaffle_shop.customers (id, first_name, last_name)
from 's3://dbt-tutorial-public/jaffle_shop_customers.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1);
同様に、orders,paymentについても作成していきます。
- ordersテーブルの作成
create table raw.jaffle_shop.orders
( id integer,
user_id integer,
order_date date,
status varchar,
_etl_loaded_at timestamp default current_timestamp);
- COPYコマンドを実行してordersテーブルにデータをロード
copy into raw.jaffle_shop.orders (id, user_id, order_date, status)
from 's3://dbt-tutorial-public/jaffle_shop_orders.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1);
- paymentテーブルの作成
create table raw.stripe.payment
( id integer,
orderid integer,
paymentmethod varchar,
status varchar,
amount integer,
created date,
_batched_at timestamp default current_timestamp);
- COPYコマンドを実行してordersテーブルにデータをロード
copy into raw.stripe.payment (id, orderid, paymentmethod, status, amount, created)
from 's3://dbt-tutorial-public/stripe_payments.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1);
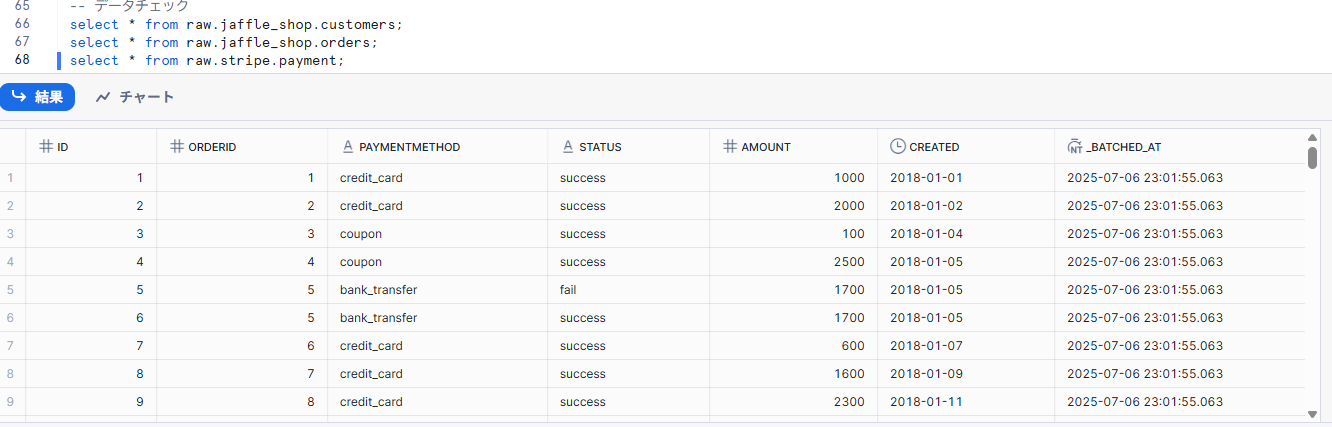
3.最後に作成したテーブルにデータがロードされているか確認します。
select * from raw.jaffle_shop.customers;
select * from raw.jaffle_shop.orders;
select * from raw.stripe.payment;
下記のようにデータが表示されていることが確認できました。
※このセクションで使用したSQLコマンドの公式ドキュメントを残します。
4.dbtをSnowflakeに接続する
Snowflakeにdbtを接続する方法は主に2つあります。
- Partner Connect
- 手動でセットアップ
今回は手動でセットアップしていきます。
-
dbtで新しいプロジェクトを作成します。左側下部のアカウント名をクリックし、
Account settingsを選択、Projectを開き右側上部の+New projectをクリックします。
-
任意のプロジェクト名を記載し、
Continueをクリックします。
-
2を実行すると、下記画面に遷移するので、
Connectionを設定します。
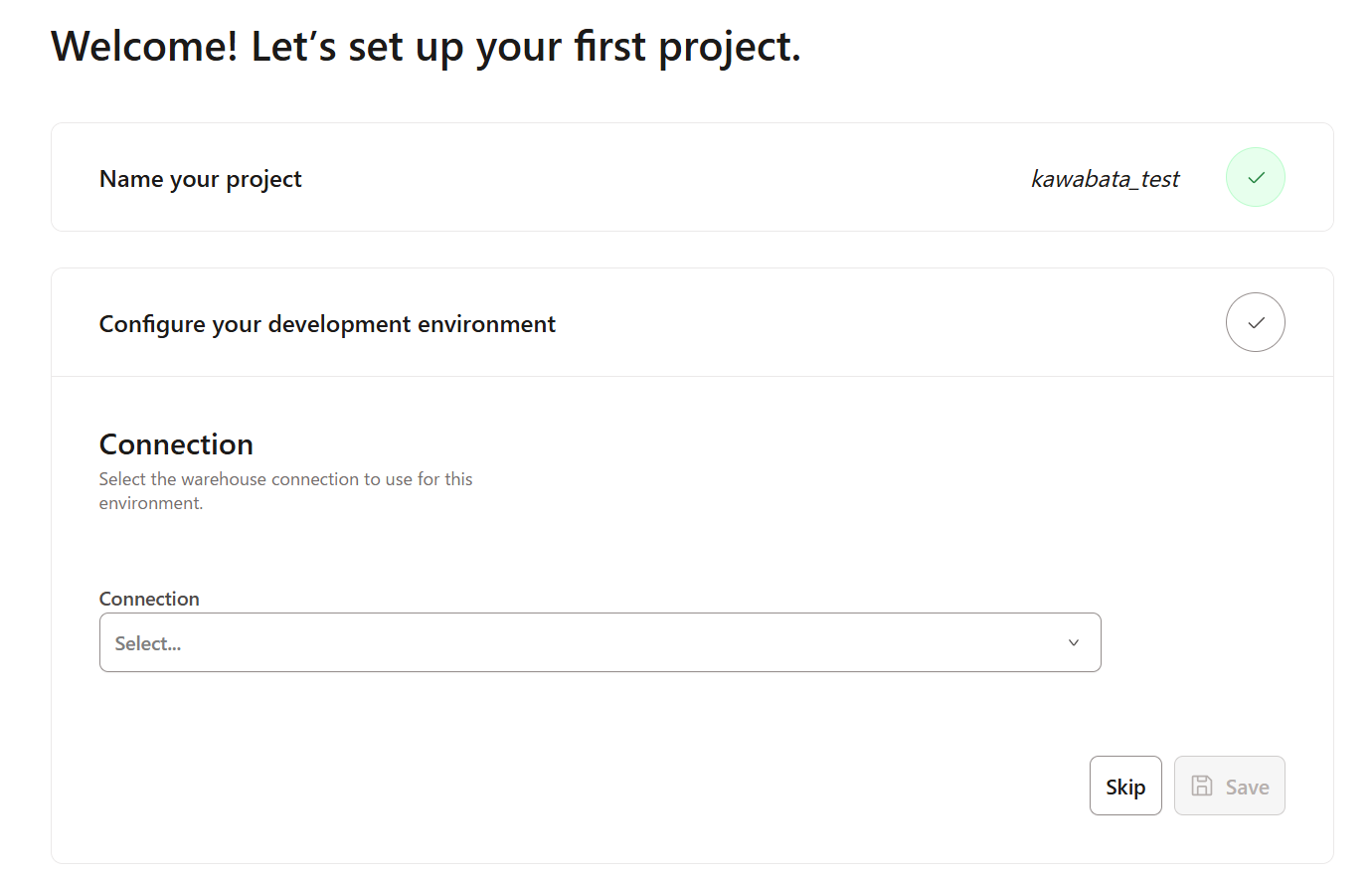
-
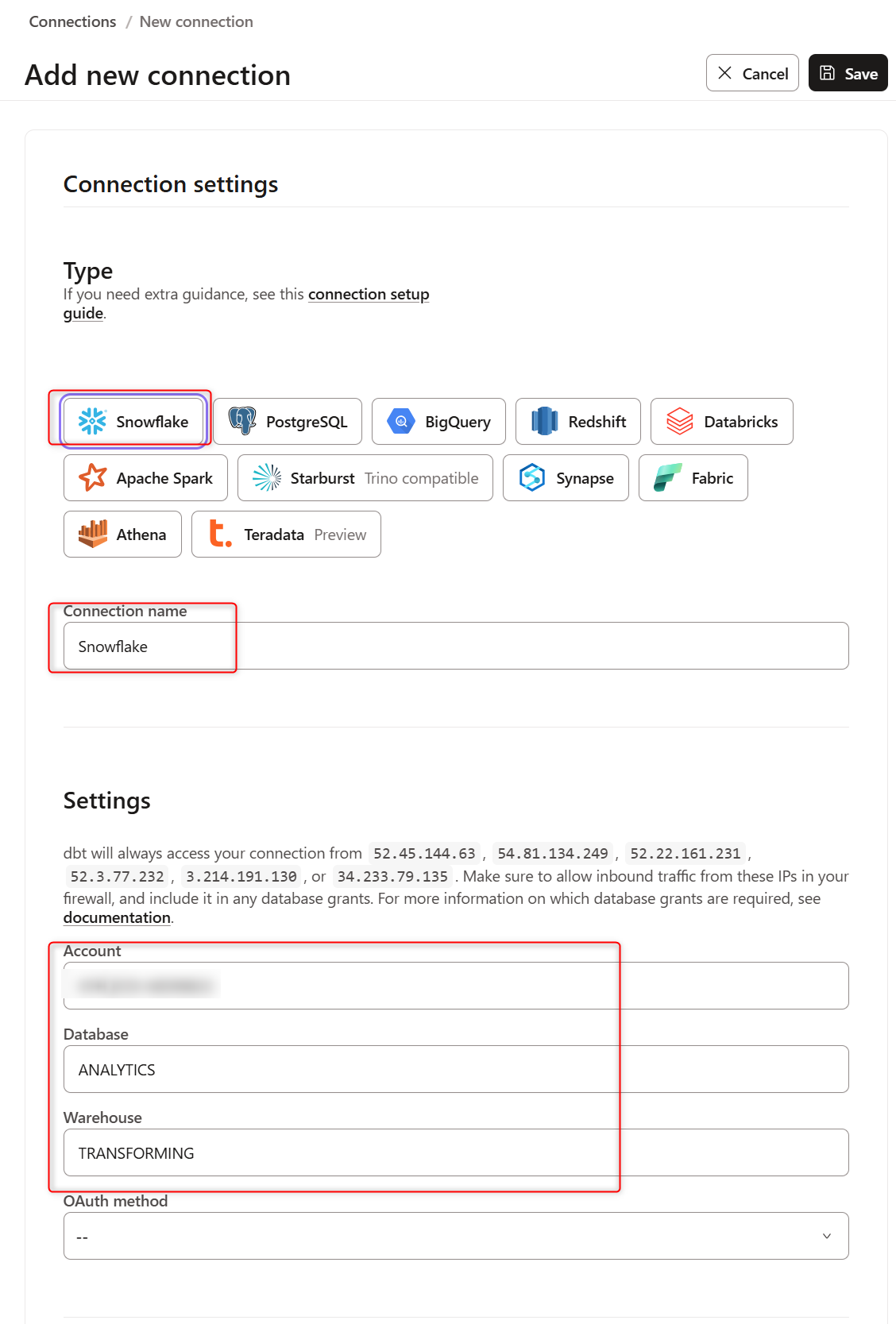
プルダウンを開き
Add new connectionをクリックすると下記画面に遷移します。TypeをSnowflakeと設定、Connection nameは任意の名前で登録し、Settingsを設定したデータベース・ウェアハウス名に変更し保存します。
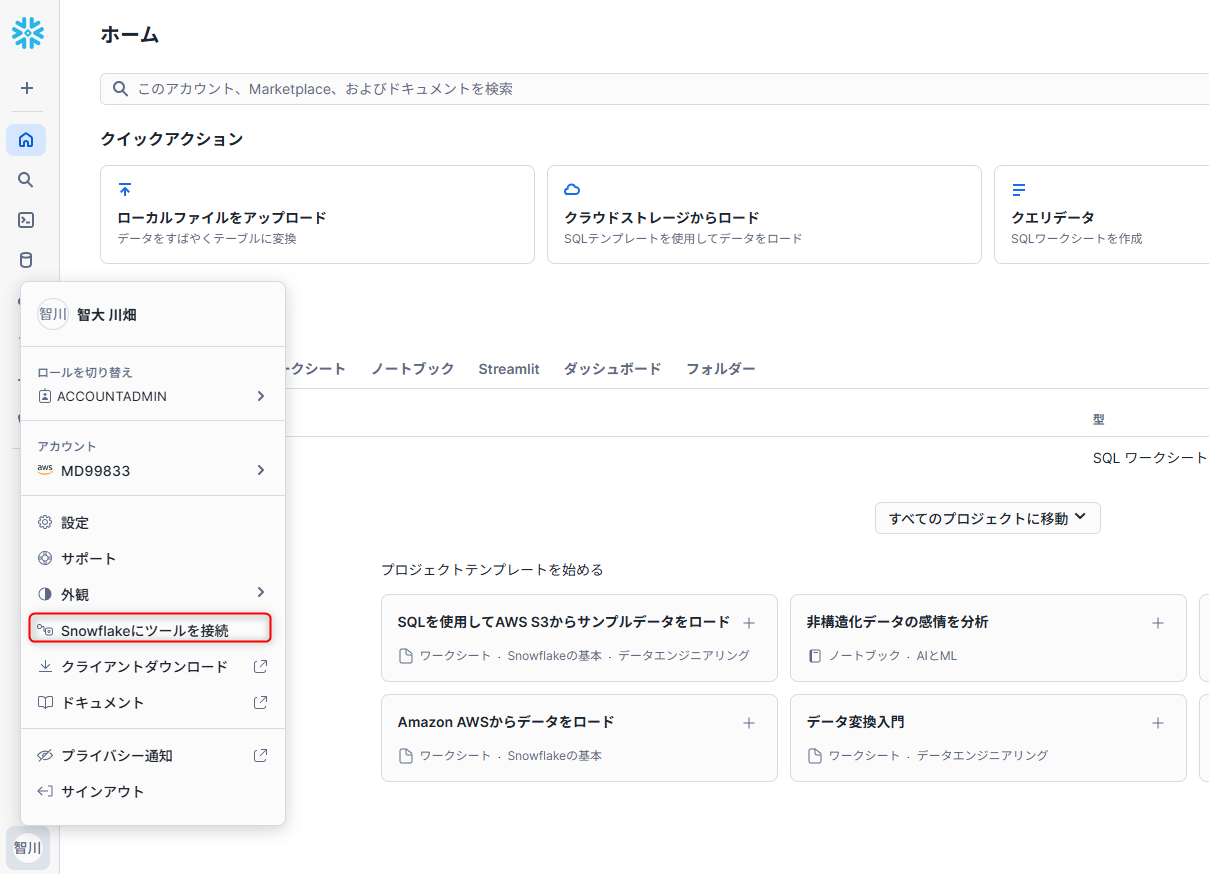
アカウント名はSnowflakeのUIで確認します。SnowflakeのUIに戻り、左下のメニューからアカウント名をクリックし、アカウント識別子をコピーします。
-
4まで完了したら、再度
Account settingsを選択、Projectを開き作成したProjectをクリックします。下記画面に遷移するので、Configure development environment and add a connectionをクリックします。
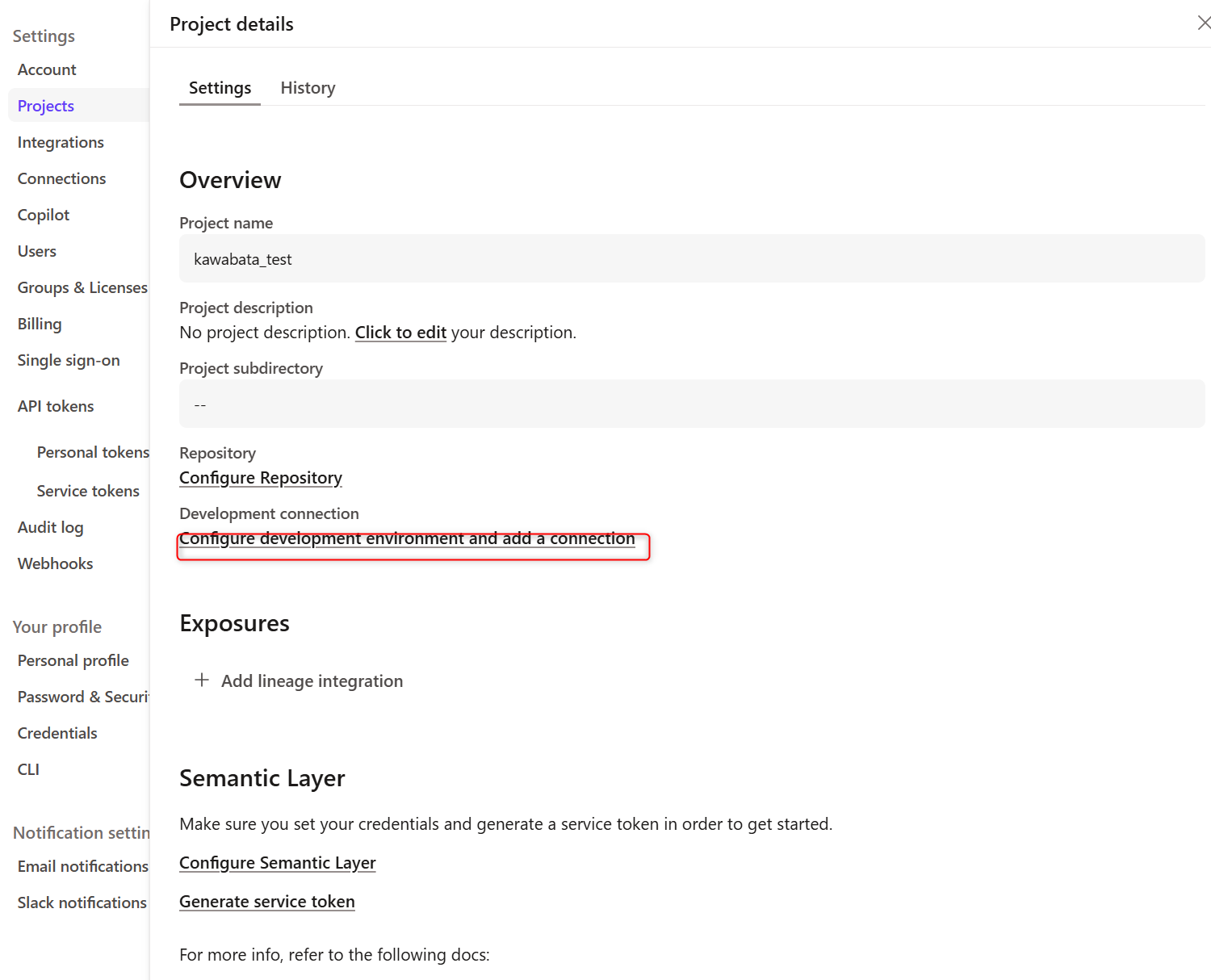
-
すると
Connectionのプルダウン内に、4で作成したConnection nameが選択できるのでクリックします。※かわばたはSnowflakeと登録したので、Snowflakeを選択しました。
Username,PasswordにSnowflakeにサインインする際のUsername,Passwordを記載します。
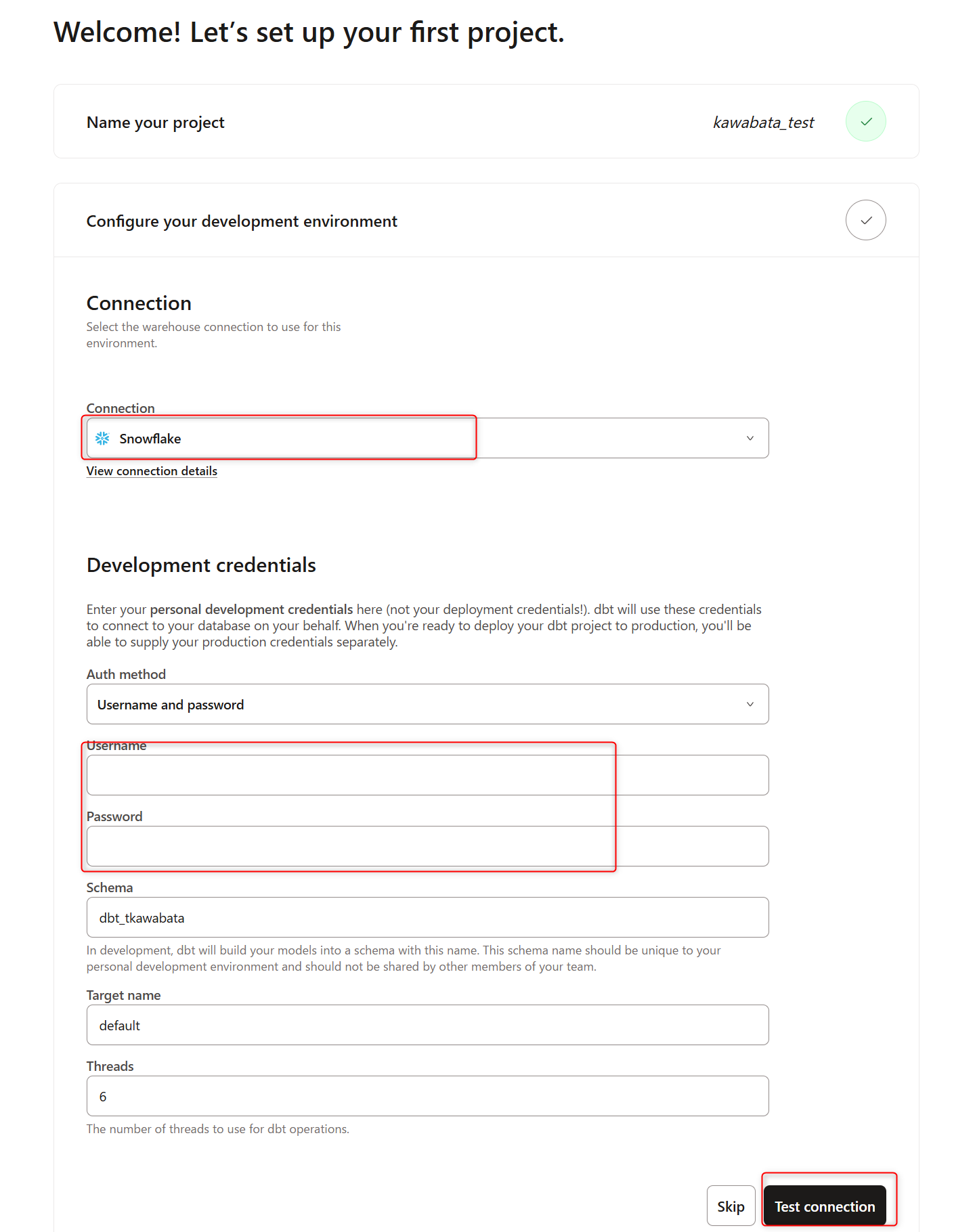
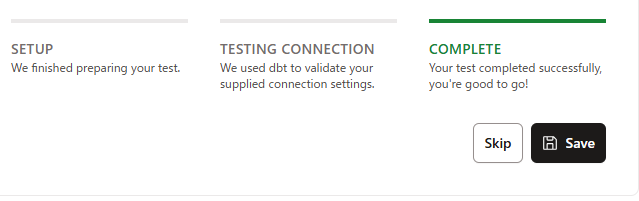
入力後、Test Connectionをクリックし、下記のようにConnection test successfulと表示されれば接続できています。
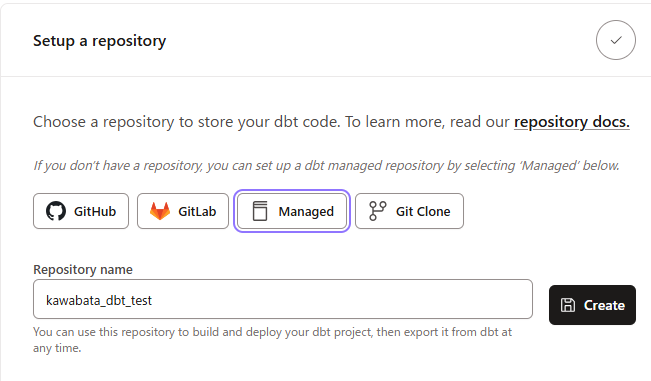
- 6完了後、
Setup a repositoryを設定する画面に遷移します。今回はManagedを選択し任意のRepository nameを記載します。
Your project is ready!となりましたので、準備完了です。
5.dbt管理リポジトリを設定
先ほどの4-7で設定できているのでskipします。
6.dbtプロジェクトを初期化して開発
Studio IDEをクリックし起動させます。- 左側のファイルツリーの上にある
Initialize your projectをクリックすると下記画面のようになります。
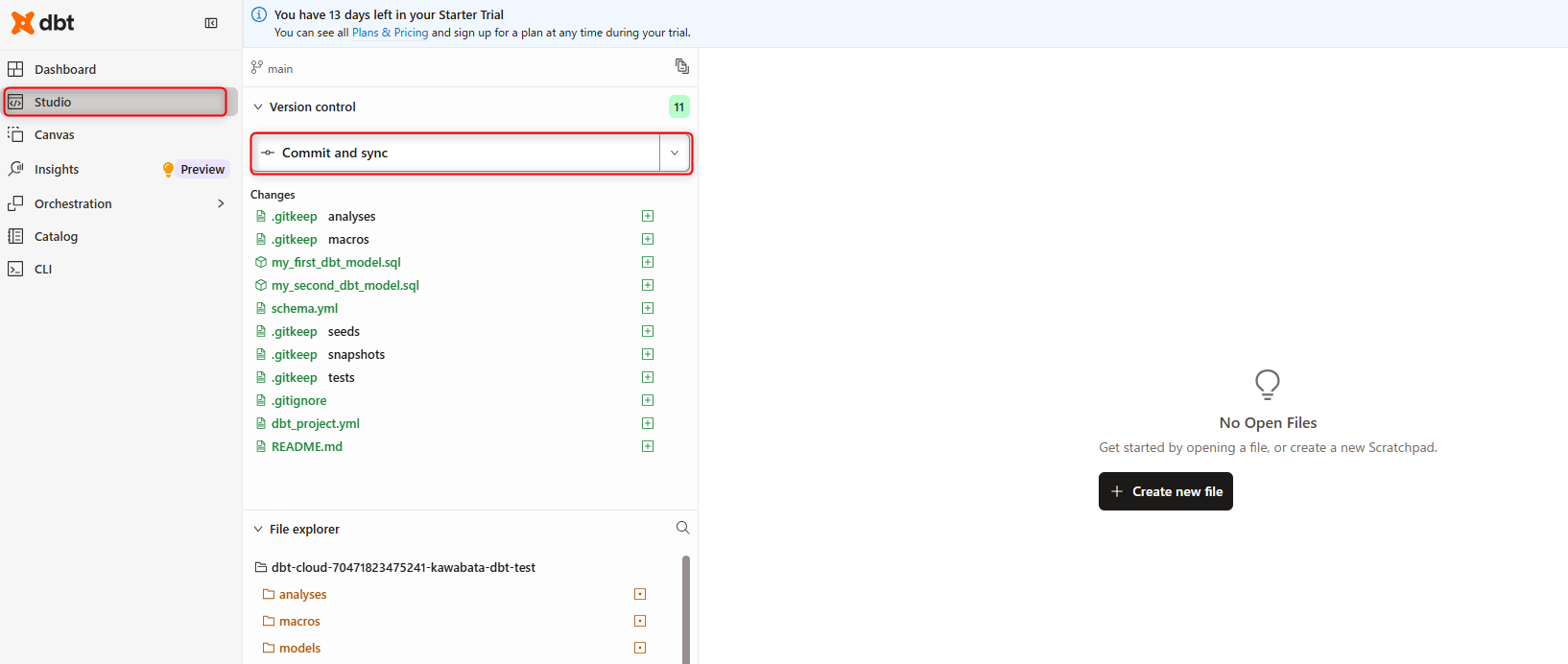
Commit and syncをクリックして、最初のコミットを行います。- ここまでの状況を踏まえた環境で初めてのdbtコマンド実行を試してみます。下記のように画面下部でdbtコマンド
dbt runを入力し実行する事が可能です。
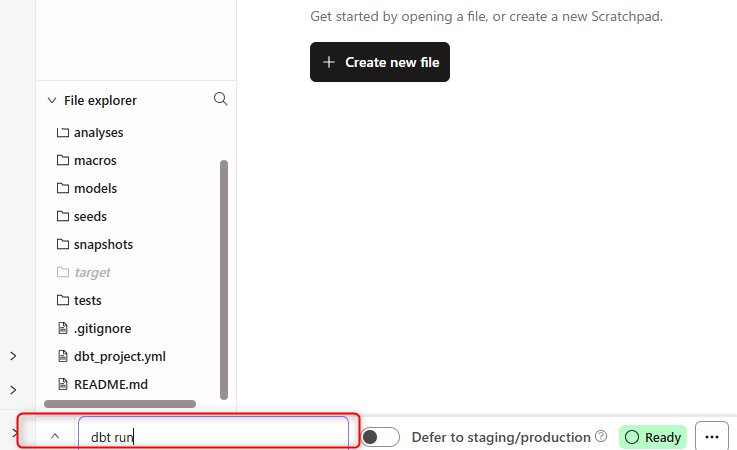
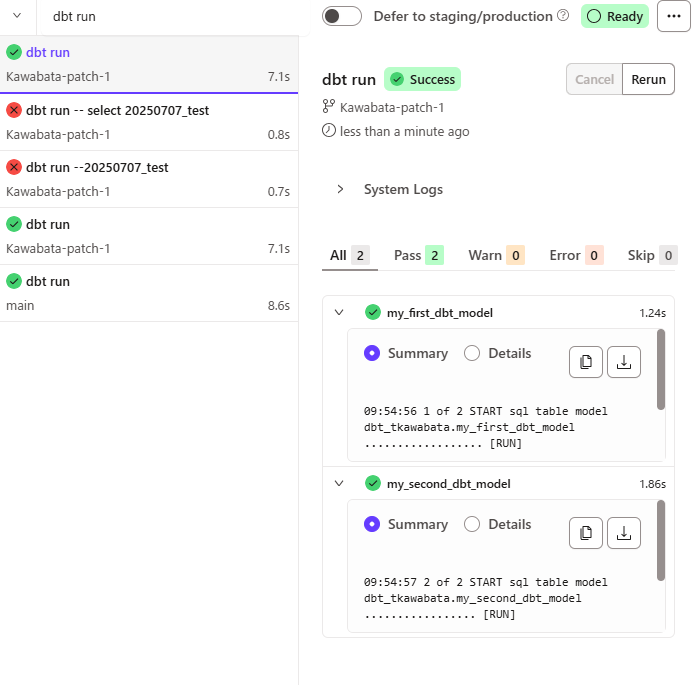
実行すると下記のような形で処理されました。
7.はじめてのモデル開発
実際にモデルの開発を行っていきます。
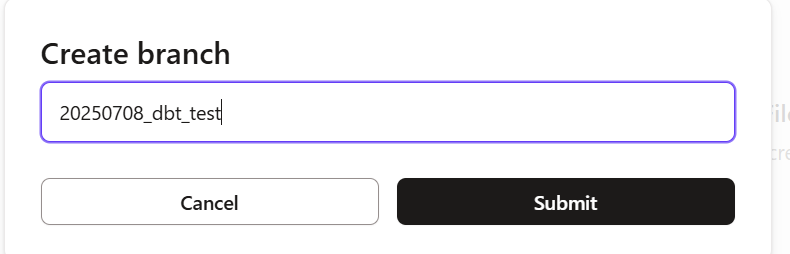
新しいブランチを作成するため、下記のようにCreate branchをクリックします。
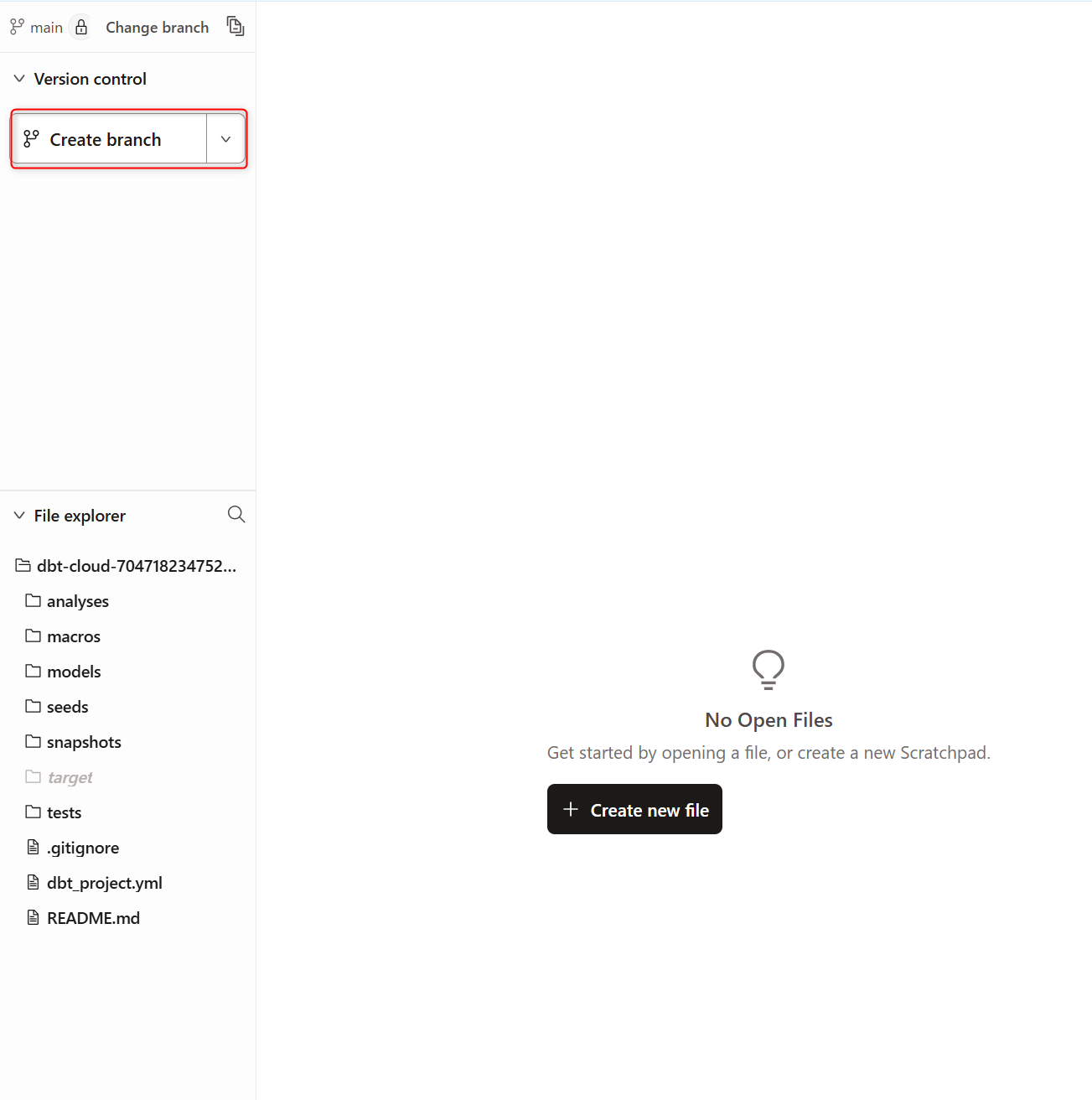
任意のブランチ名を記載しsubmitします。
下記順序でクエリを記載したファイルを保存していきます。
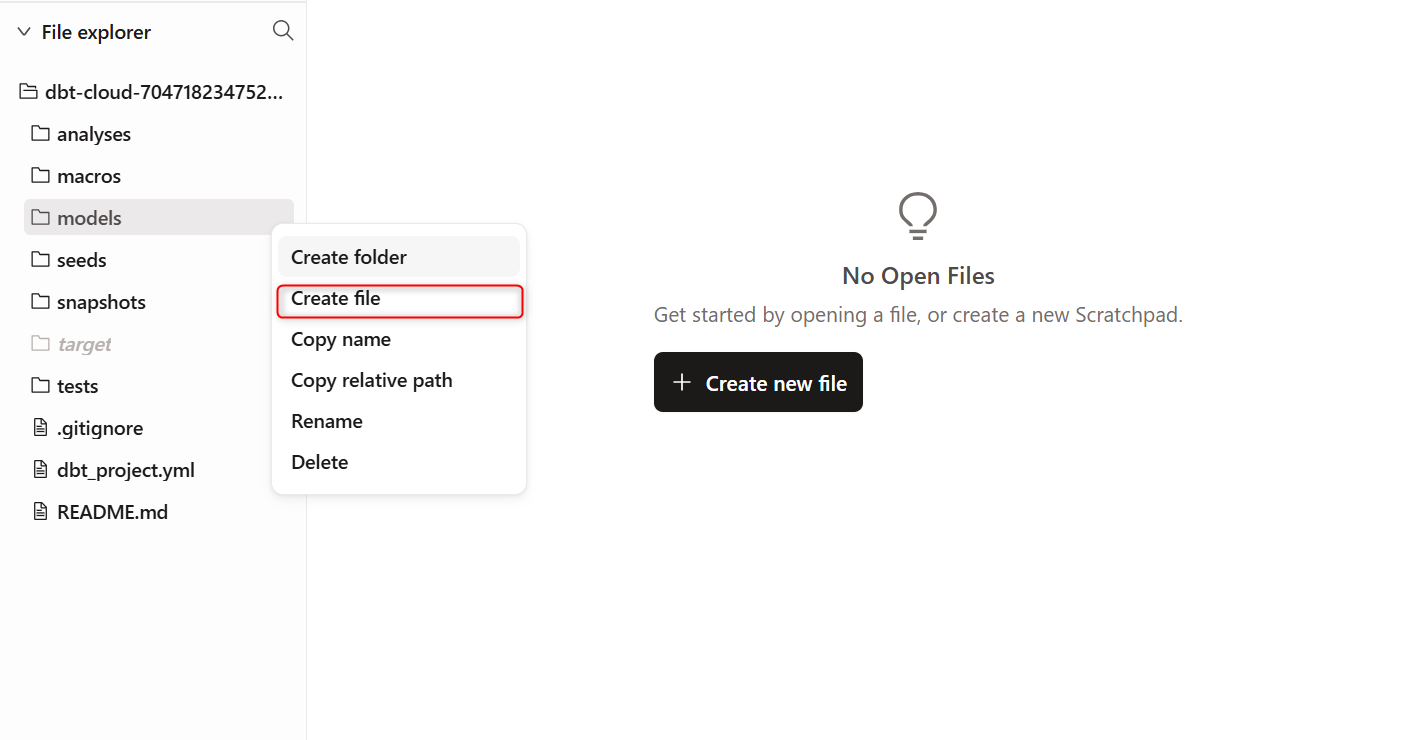
- 左側ツリー下部にある
File explorer配下のmodelsの三点リーダー(︙)をクリックし、Create fileでファイルを作成します。
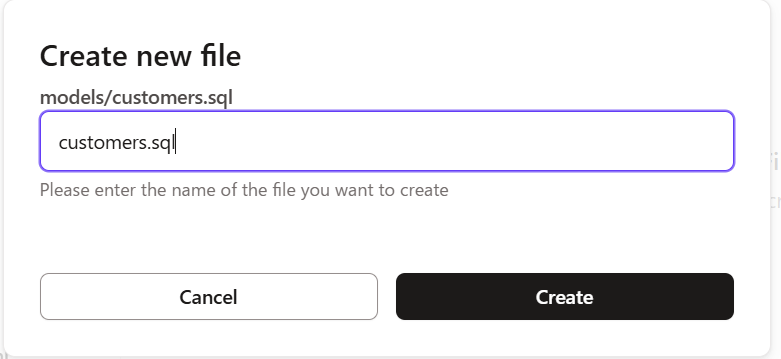
- 1を行うと下記画面がポップアップするので
customers.sqlと記載し、Createをクリックします。
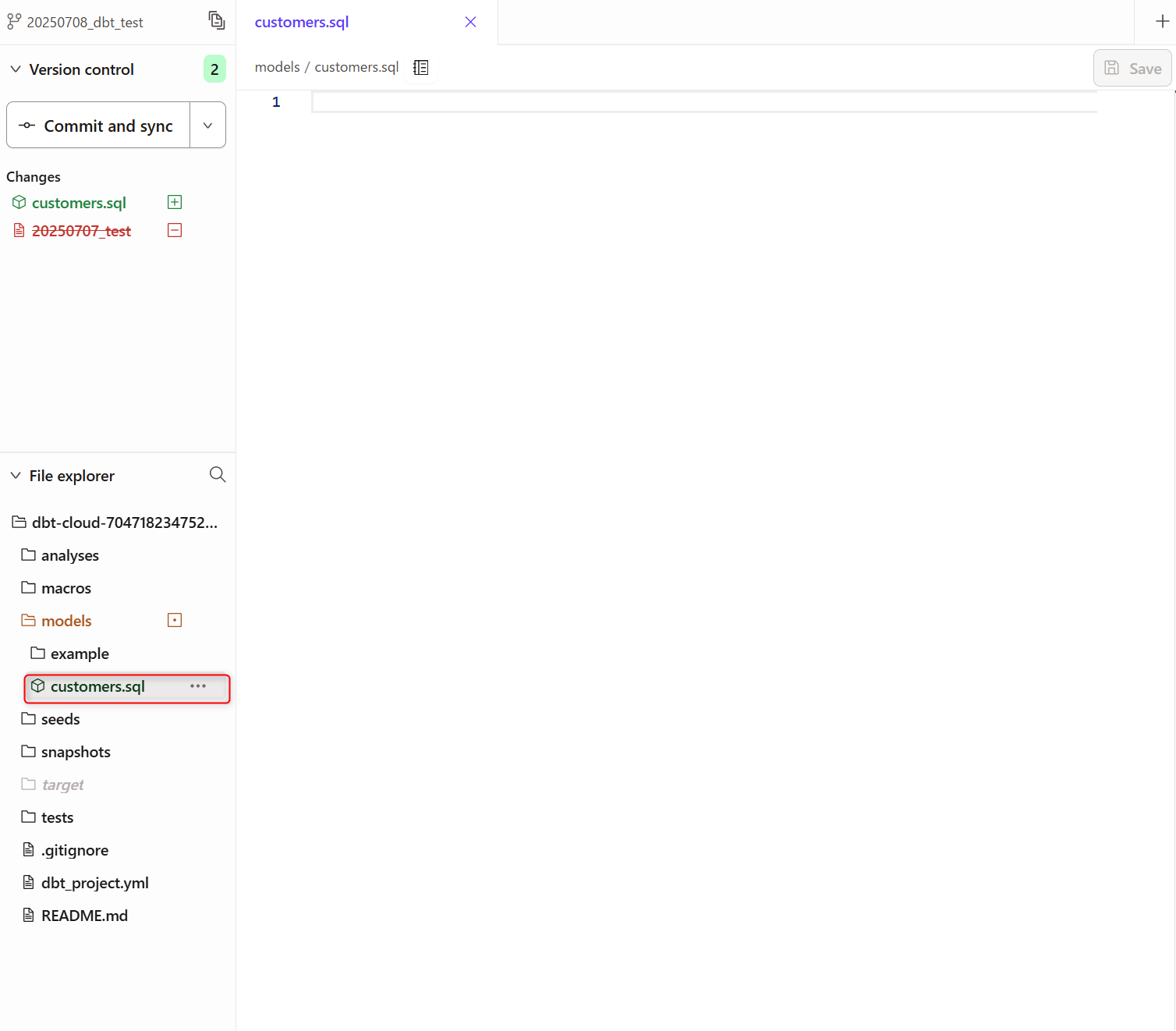
- 下記のように
modelsの配下にcustomers.sqlとモデルが生成されました。
customers.sqlをクリックしエディタに下記クエリを貼り付け保存します。
with customers as (
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
dbt runと実行してみると、下記のように作成したcustomers.sqlモデルも実行されていることが分かります。
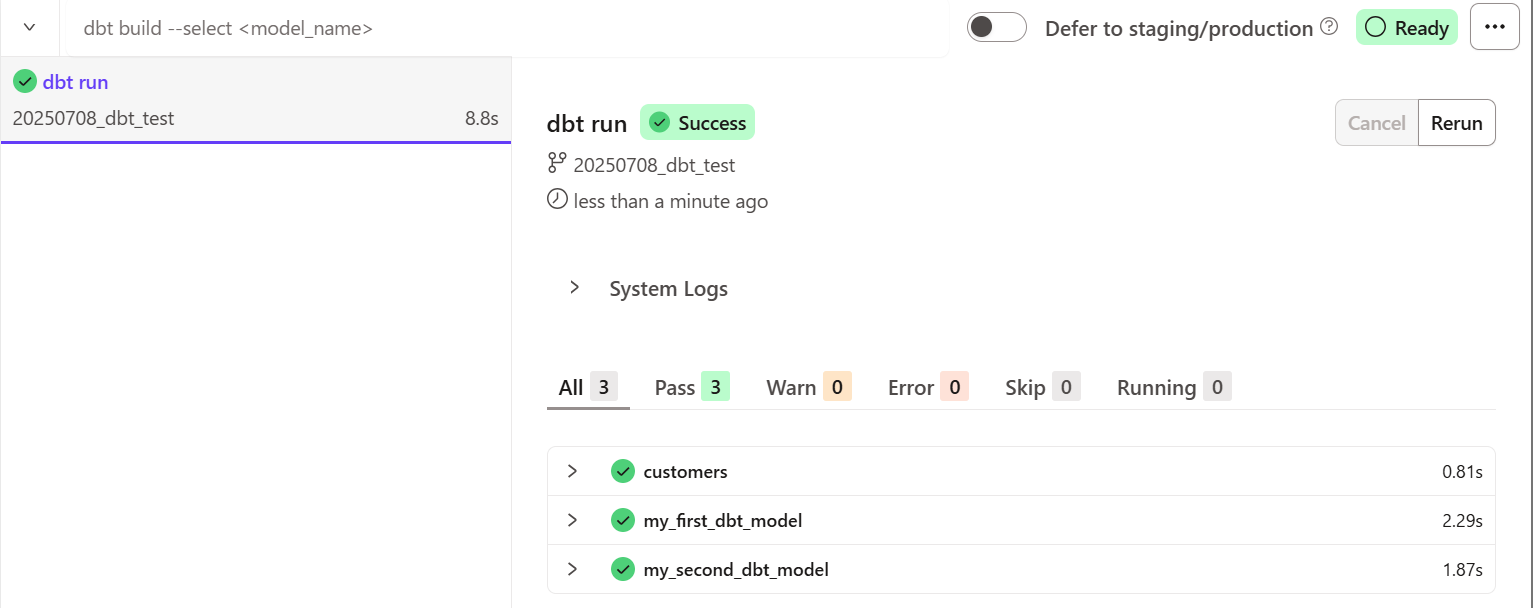
8.モデルのマテリアライズ方法を変更
dbtの最も強力な機能の一つは、設定値を変更するだけで、モデルがウェアハウス内でどのようにマテリアライズされるかを変更できることです。裏側でDDL(データ定義言語)を記述する代わりに、キーワードを変更するだけで、テーブルとビューを切り替えることができます。
デフォルトでは、すべてがビューとして作成されます。しかし、ディレクトリレベルでこの設定を上書きすることができ、そのディレクトリ内のすべてのモデルが異なるマテリアライゼーションで作成されるようになります。
実際に試していきます。
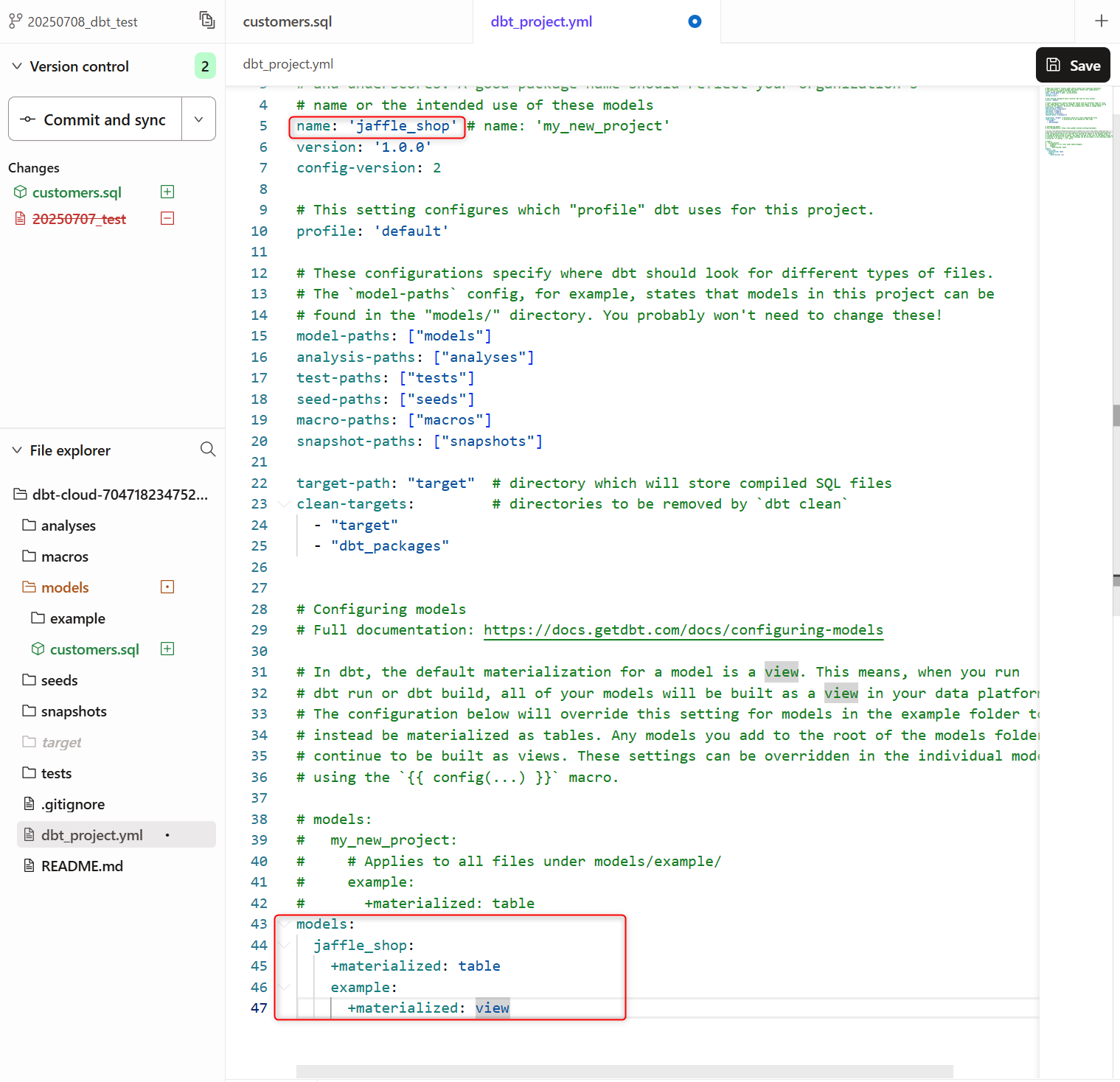
dbt_project.ymlのファイルを編集します。- プロジェクトの
nameを下記のように更新します。
name: 'jaffle_shop'
- 設定ブロックを下記のように更新しテーブルとしてマテリアライズされるよう設定します。
models:
jaffle_shop:
+materialized: table
example:
+materialized: view
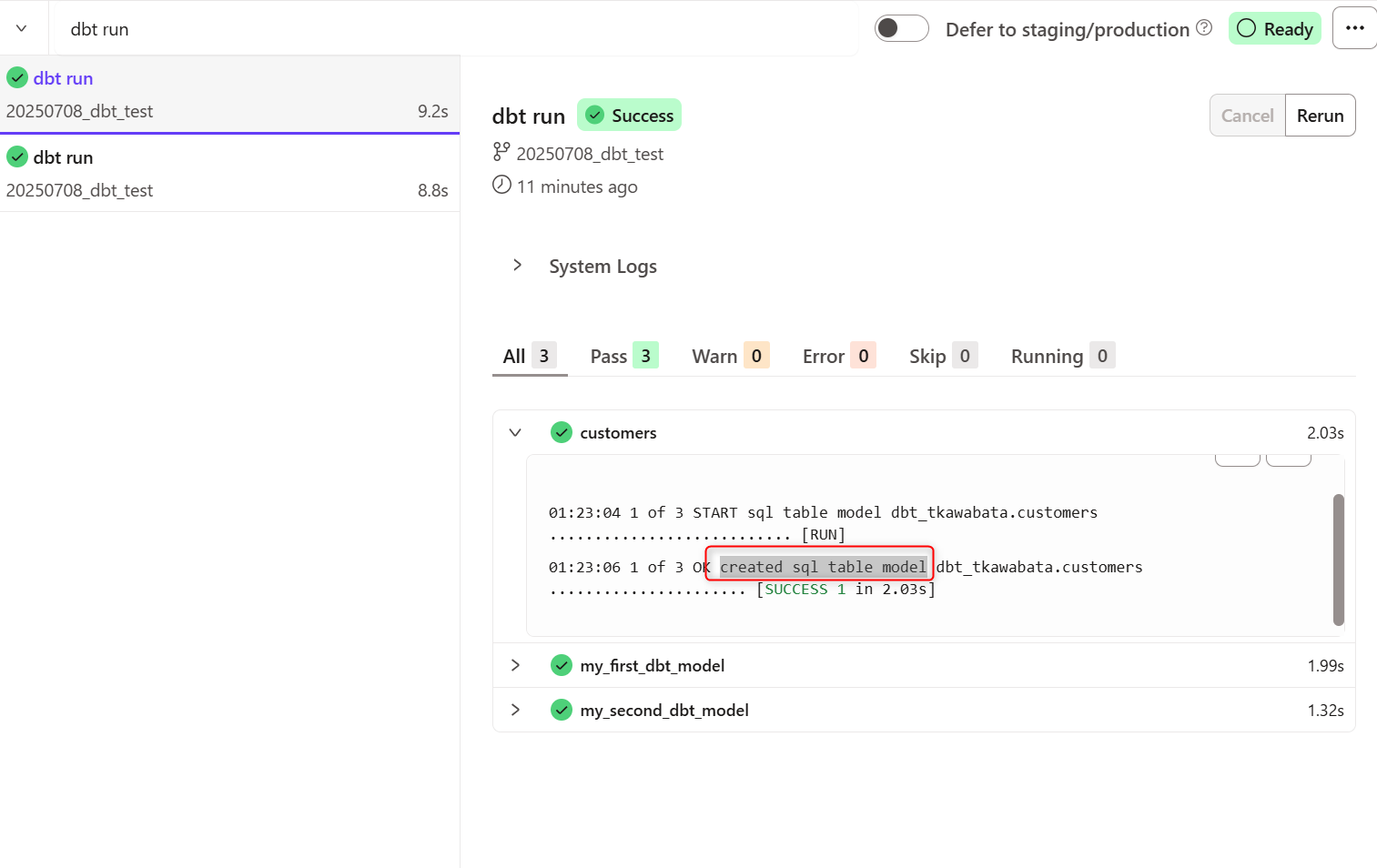
実際にdbt runで実行してみると、ログにcreated sql table modelと表示され、テーブルとして更新されていることが分かりました。
9.サンプルモデルの削除
モデルの作成ができるようになったため、デフォルトで用意されているモデルを削除していきます。
対象は 左側ツリー下部にあるFile explorer配下のmodels/example配下のファイルです。
下記のようにexampleフォルダのメニューからDeleteをクリックします。
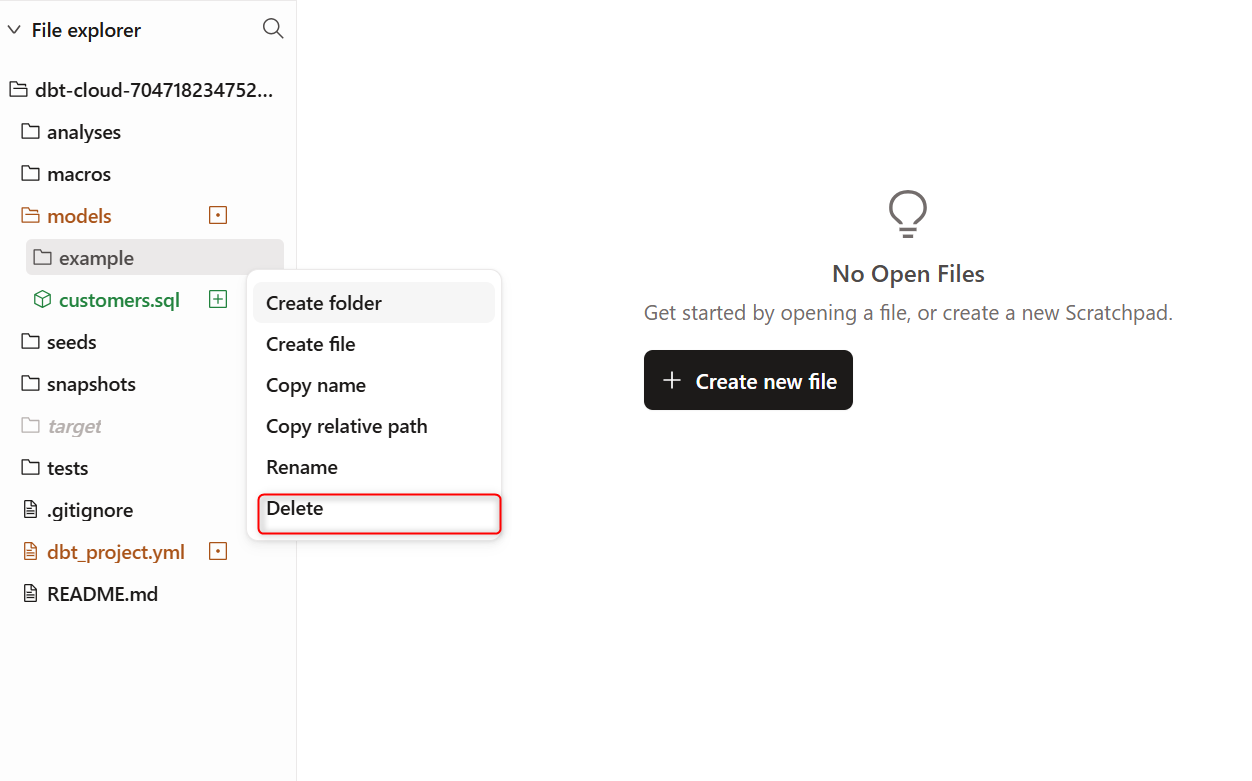
models配下を確認すると、exampleフォルダが削除されていることが確認できました。
10.他のモデルの上にモデルを構築する
既存のクエリでは、共通テーブル式(CTE)を使うことで、対応していました。SQLのベストプラクティスとして、「データをクリーンアップするロジック」と「データを変換するロジック」は分離すべきです。
下記イメージ
-- 1つのSQLファイル内での分離 (CTEを使用)
WITH source_data AS (
SELECT * FROM raw_data
),
-- ① クリーンアップのロジック
cleaned_data AS (
SELECT
id AS order_id,
user_id AS customer_id,
amount
FROM source_data
),
-- ② 変換のロジック
customer_orders AS (
SELECT
customer_id,
COUNT(order_id) AS number_of_orders,
SUM(amount) AS total_amount
FROM cleaned_data
GROUP BY 1
)
SELECT * FROM customer_orders
上記の①クリーンアップのロジックと②変換ロジックは分離することがベストプラクティスです。
各ロジックを別々のモデルに分離し、ref関数を使ってモデルの上に別のモデルを構築する(=モデルを連携させる)方法を試すことができます。
ref関数のドキュメントは下記になります。
実際にやってみましょう。
modelsフォルダ配下に下記sqlファイルを2ファイル作成します。
- stg_customers.sql
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
2. stg_orders.sql
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
- 作成していたmodels/customers.sqlを下記のように更新します。
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
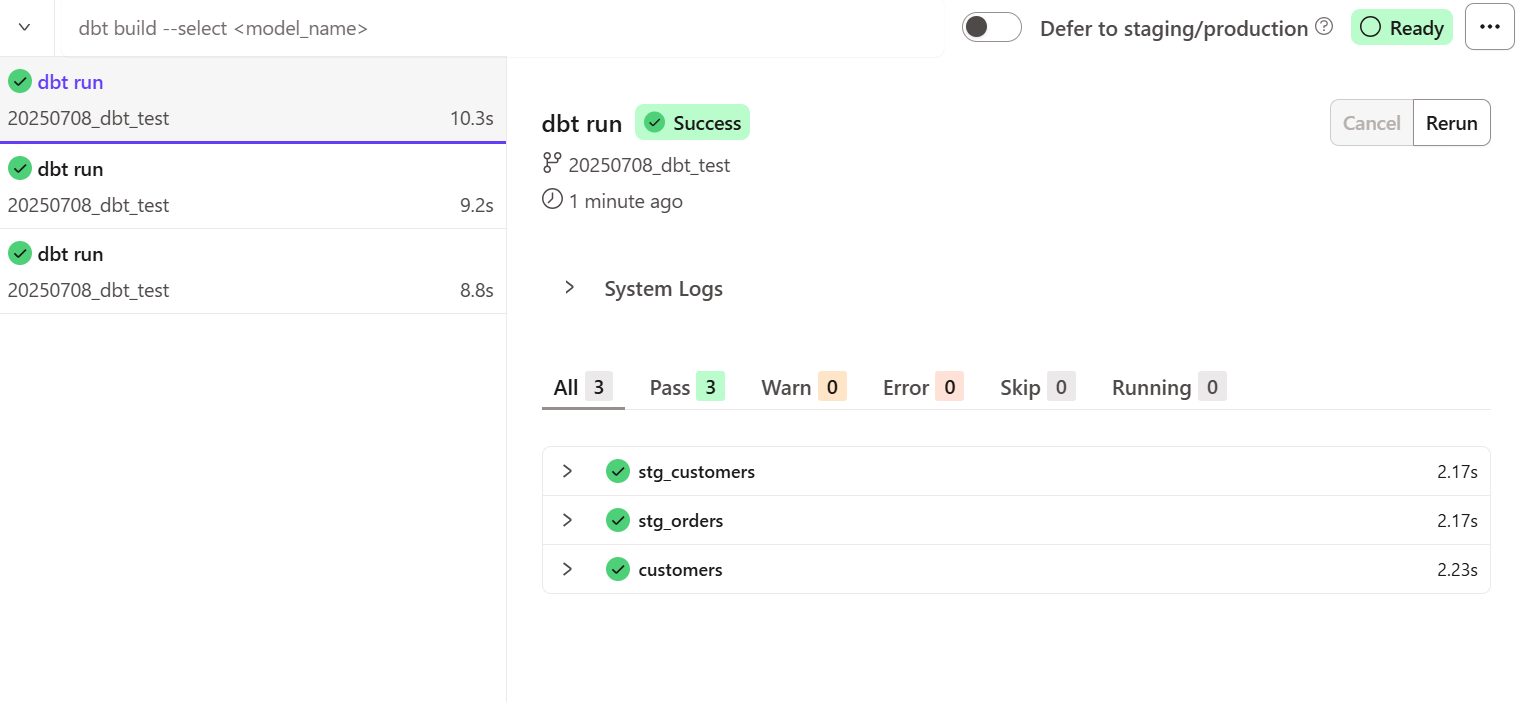
実際に実行してみると下記のようになりました。
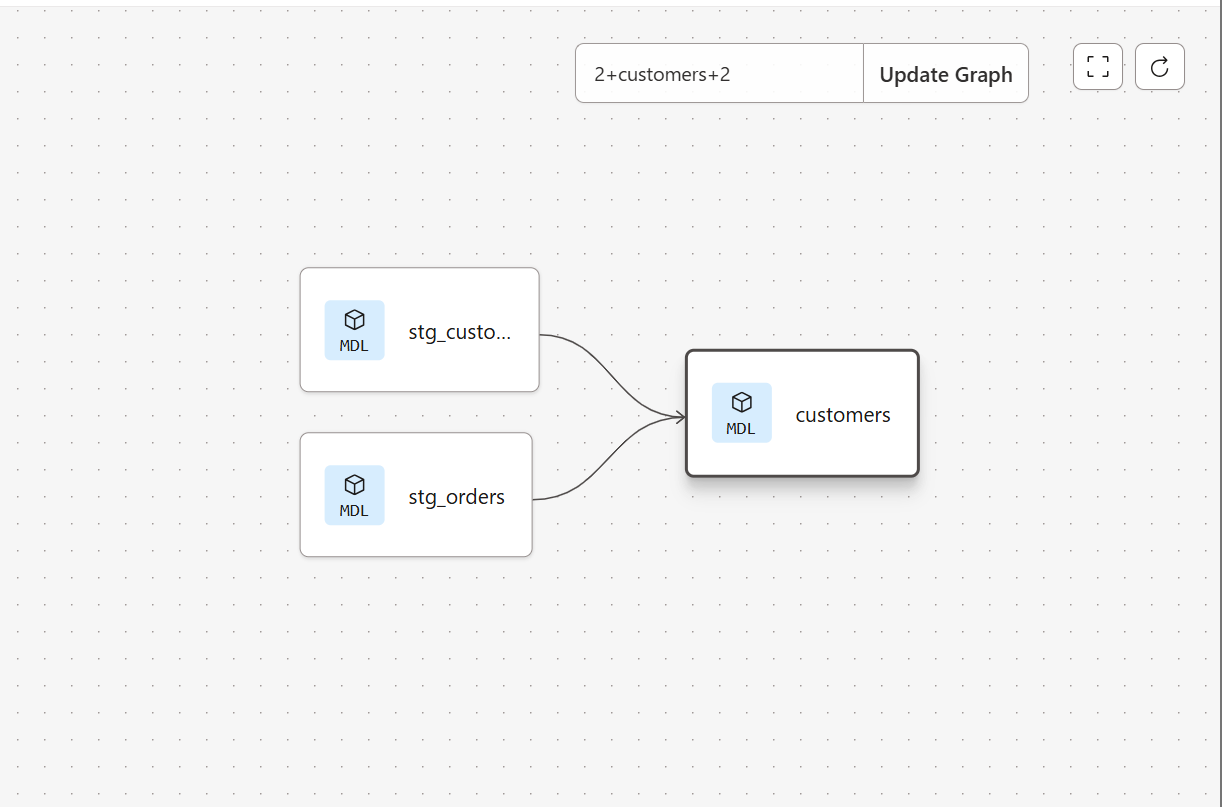
依存関係としては下記のようになっています。
11.モデルに対してテストを追加
dbtではプロジェクトにテストを実装することで、作成したモデルが意図通りに機能しているかを確認することができます。
modelsフォルダ配下にschema.ymlというYAMLファイルを作成し、下記コードを記載し保存してください。
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
下記のように保存します。
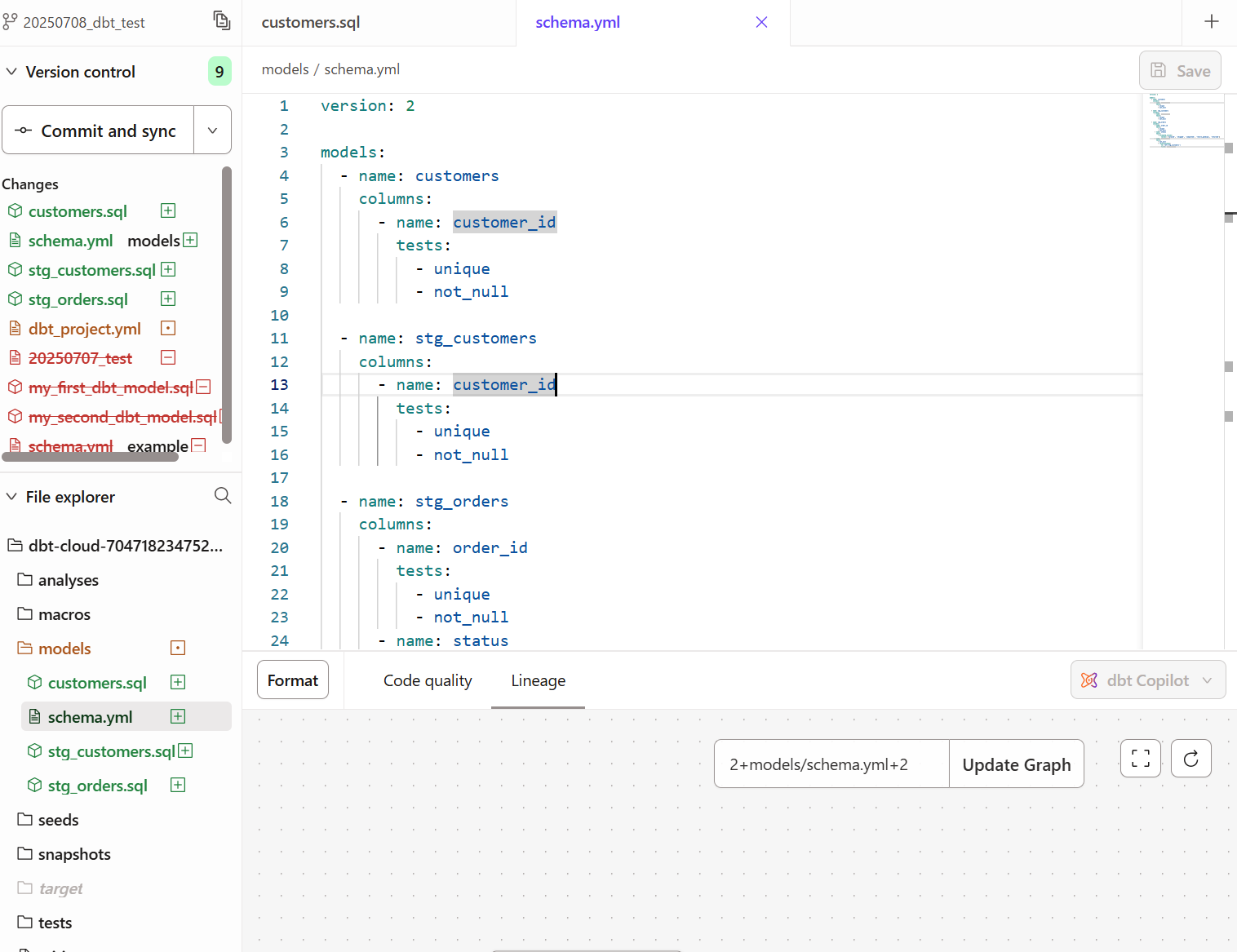
dbt testを実行し、下記の通りすべてのテストが成功したことを確認しました。
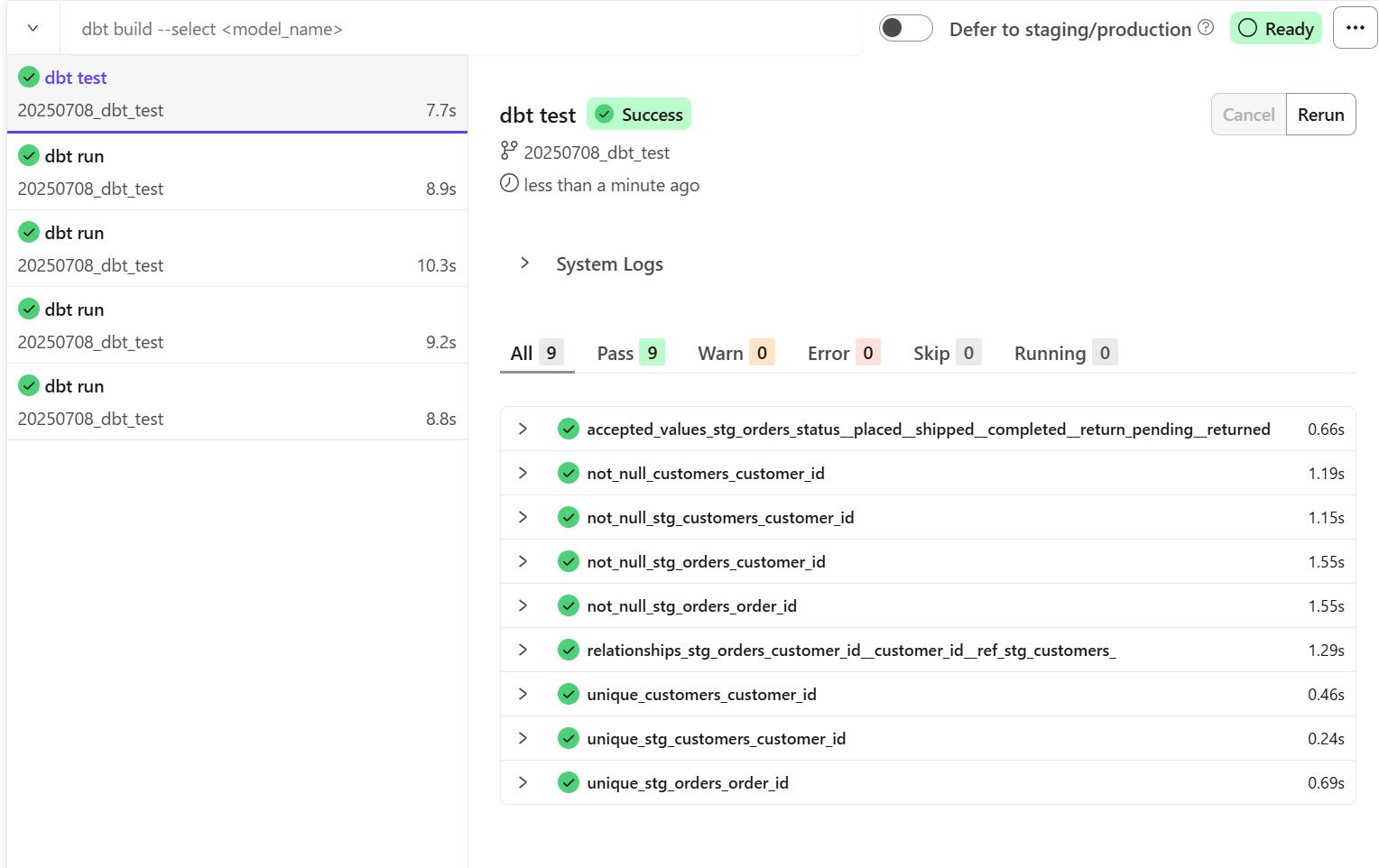
dbtはYAMLファイルを反復処理し、各テストにクエリを作成します。各クエリは、テストに失敗したレコードの数を返します。この数が 0 の場合、テストは成功です。
12.モデルに対してドキュメントを生成
プロジェクトにドキュメントを追加することで、モデルについて詳細に記述し、その情報をチームで共有することができます。ここでは、プロジェクトにいくつかの基本的なドキュメントを追加していきます。
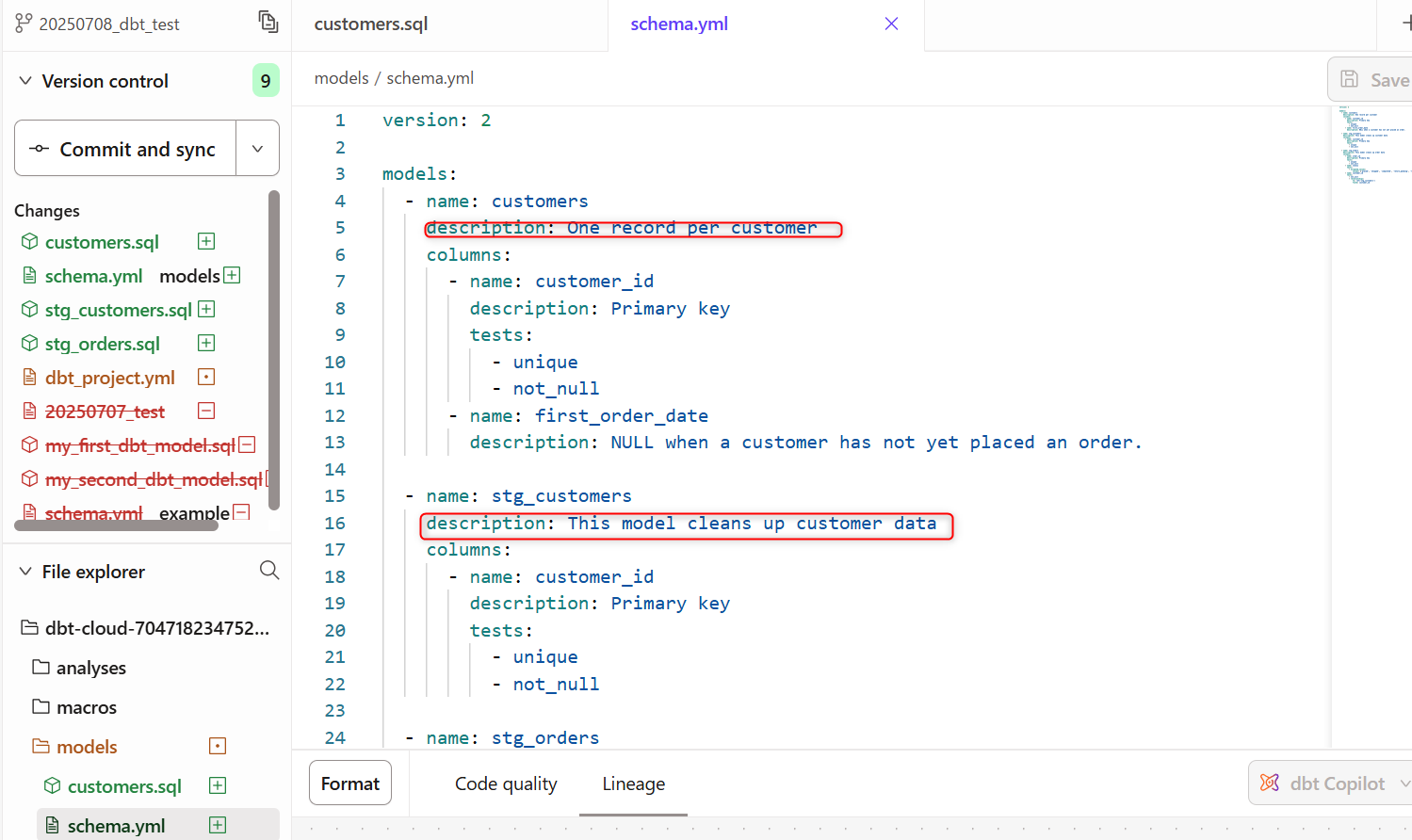
先程テスト実行時に作成したschema.ymlの内容を以下の形に修正します。各種要素にdescriptionの項目が追加された形です。
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
dbt docs generateを実行すると、ドキュメントが生成されます。
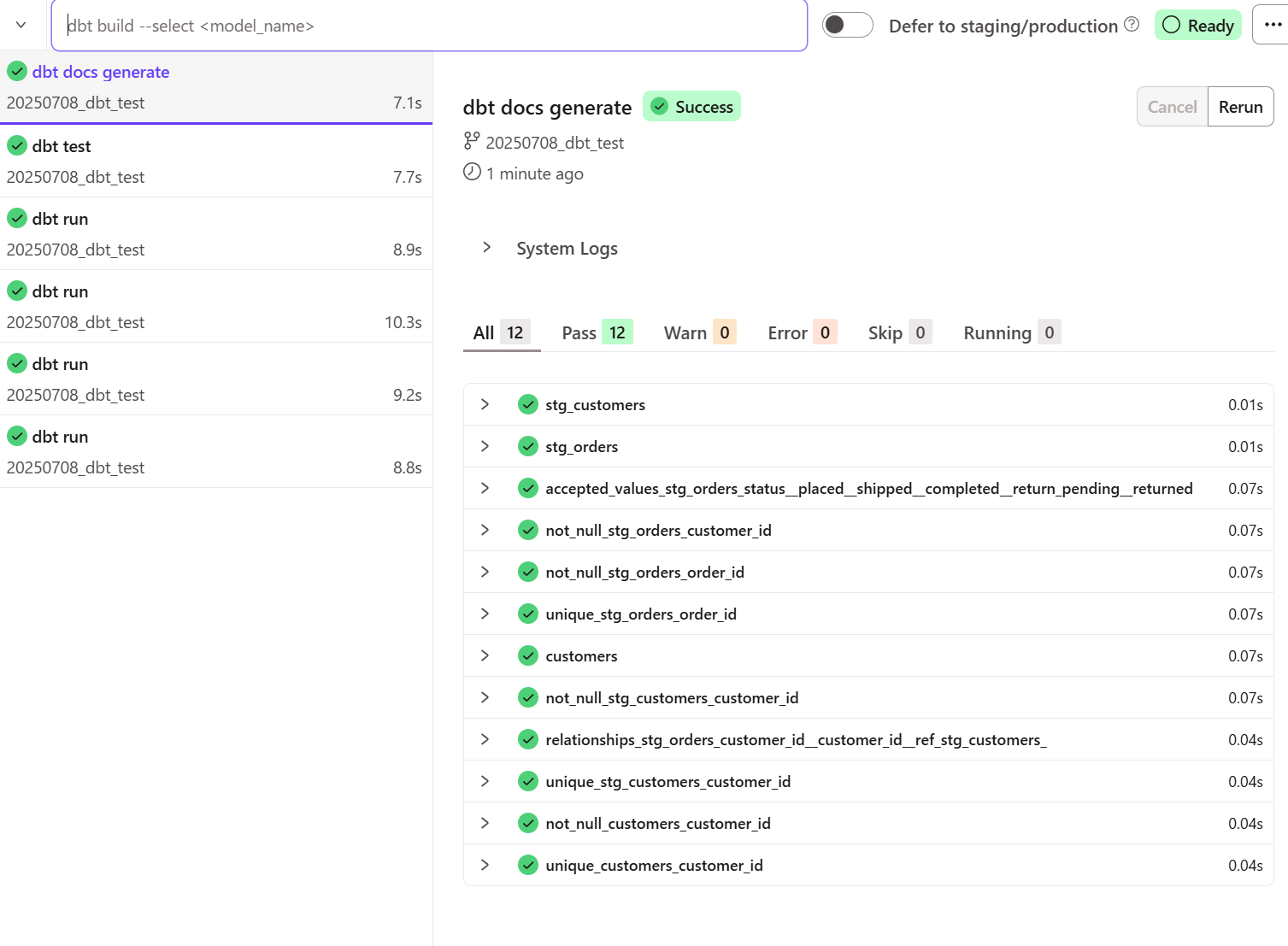
下記赤枠部分をクリックします。
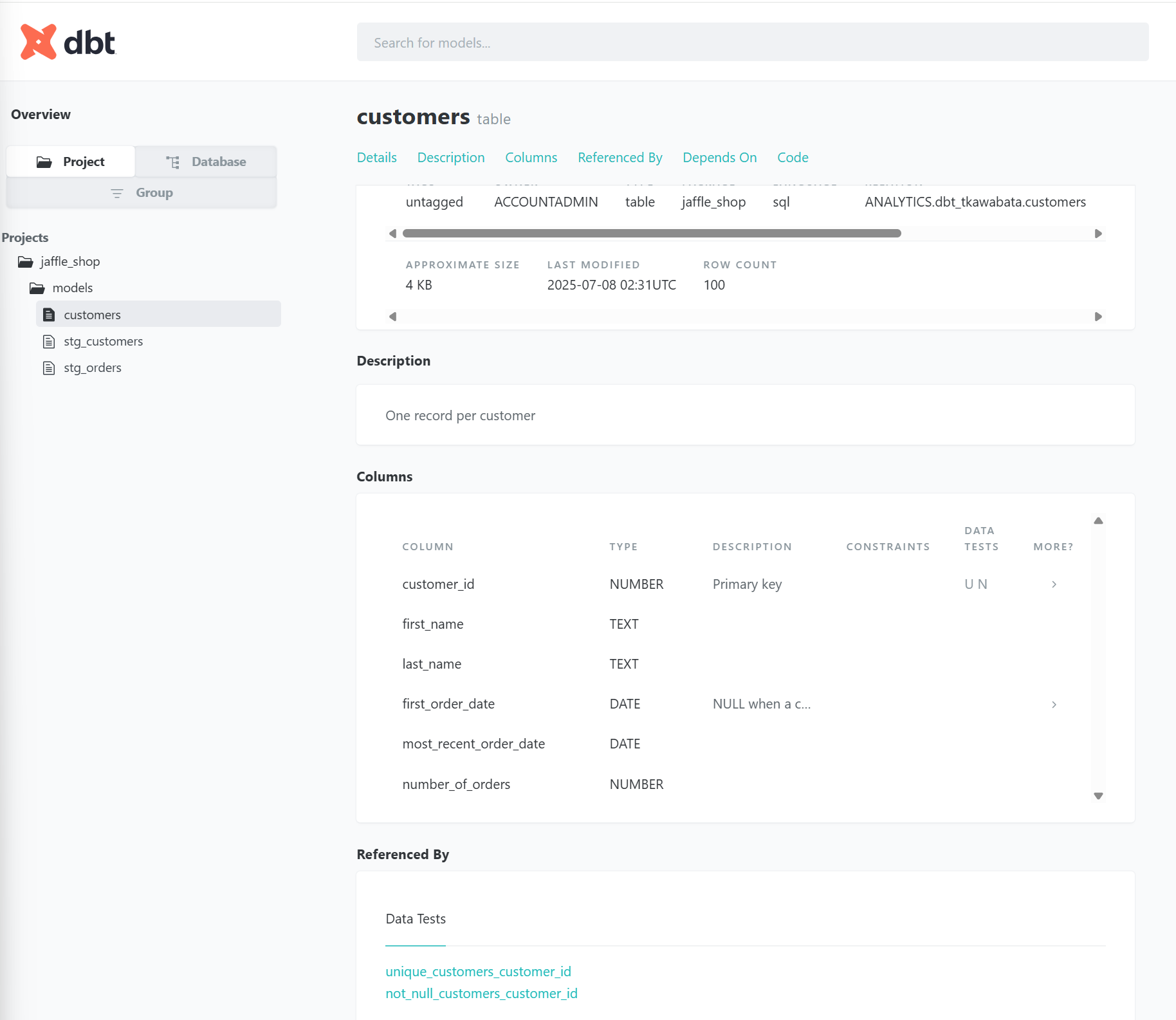
作成されたドキュメント画面に遷移し、下記のように確認することができます。
13.変更した内容をコミットする
ここまで作業した内容をコミットしていきます。
Commit and syncをクリックします。
コミットメッセージを入力して、Submitクリックします。
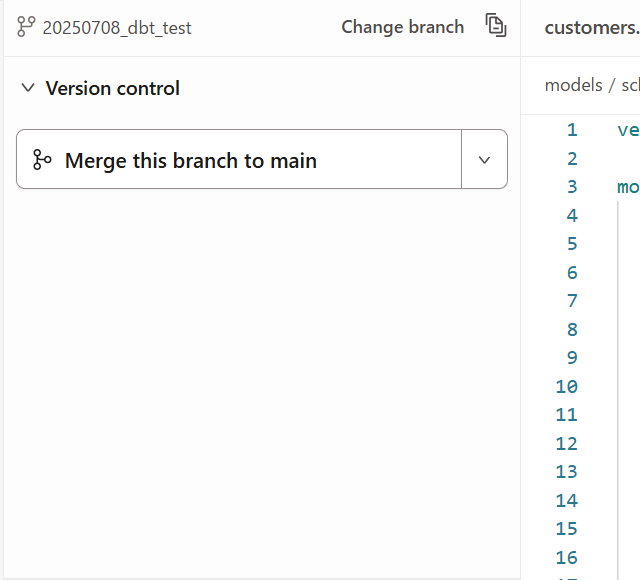
Merge this branch to mainをクリックで変更をメインブランチにマージします。
14.dbtのデプロイ
最後のセクションとなりました。
dbtのスケジューラを使用して、本番環境ジョブを確実にデプロイし、プロセスに可観測性を組み込みます。
この部分が公式で書かれている部分と差異があり、下記のように対応しました。
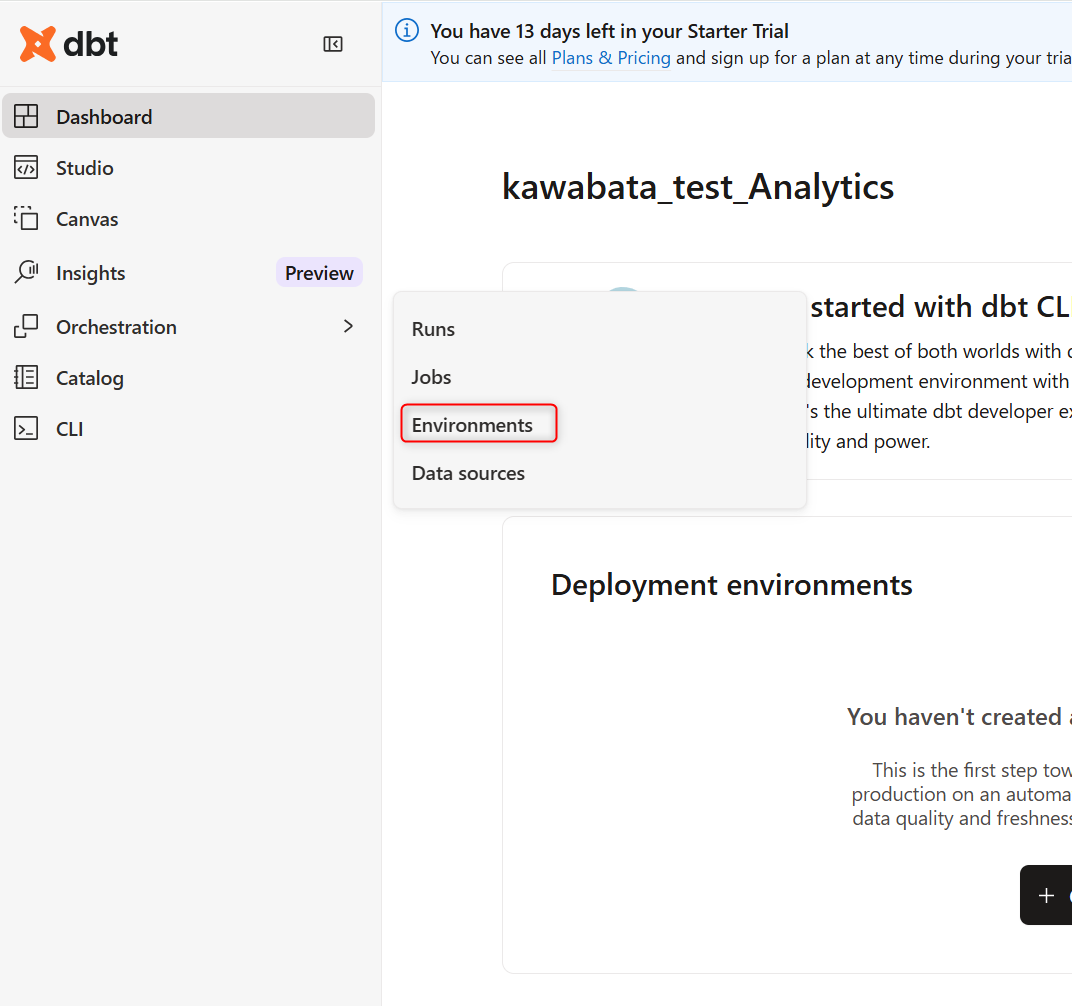
Orchestration配下のEnvironmentsをクリックします。
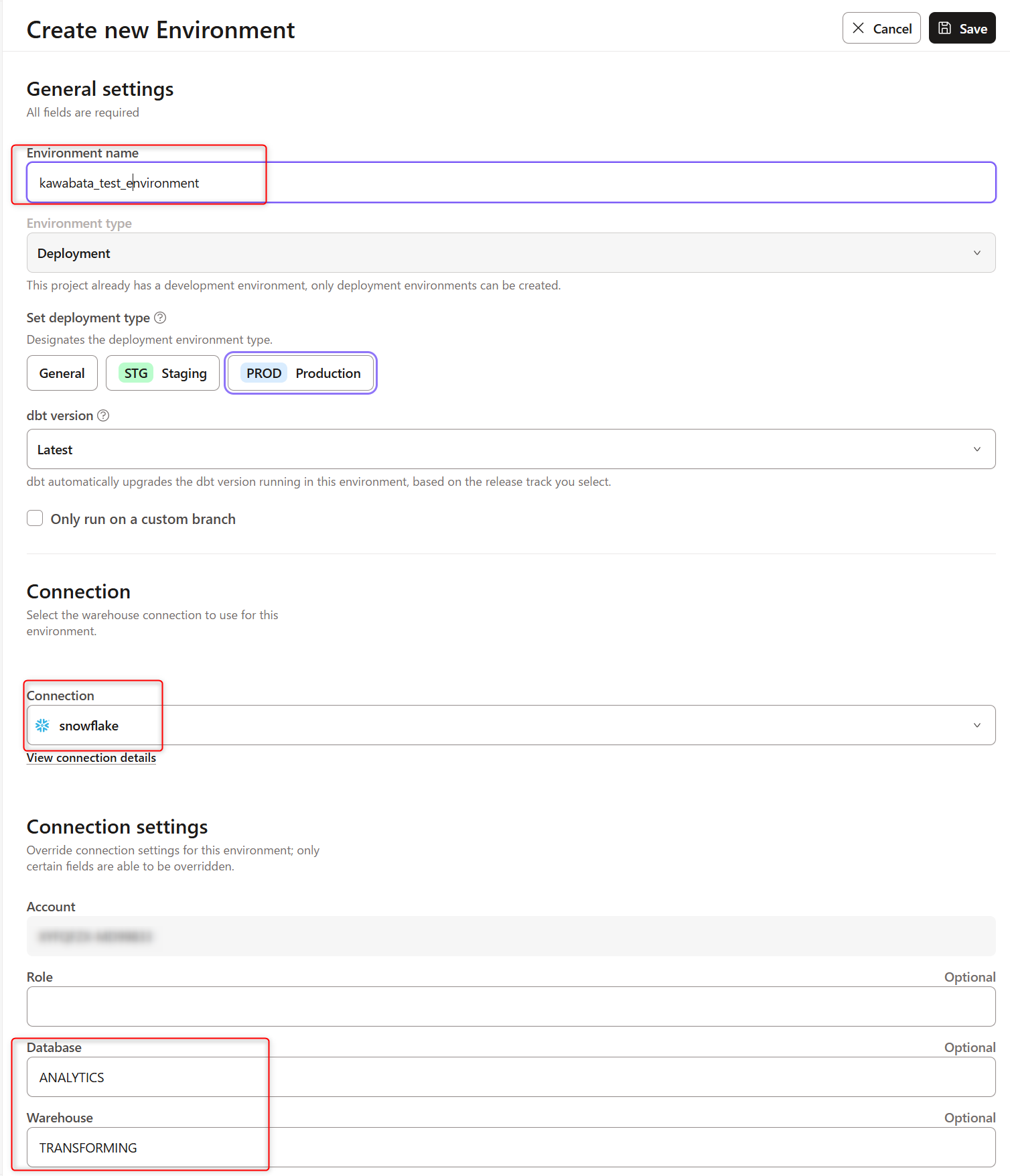
Create Environmentをクリックすると下記画面に遷移するので、任意のEnvironment nameを設定します。
ConnectionはSnowflakeを選択し、Connection settingsは最初に設定したものを記載します。
DatabaseはANALYTICS,WarehouseはTRANSFORMINGと記載します。
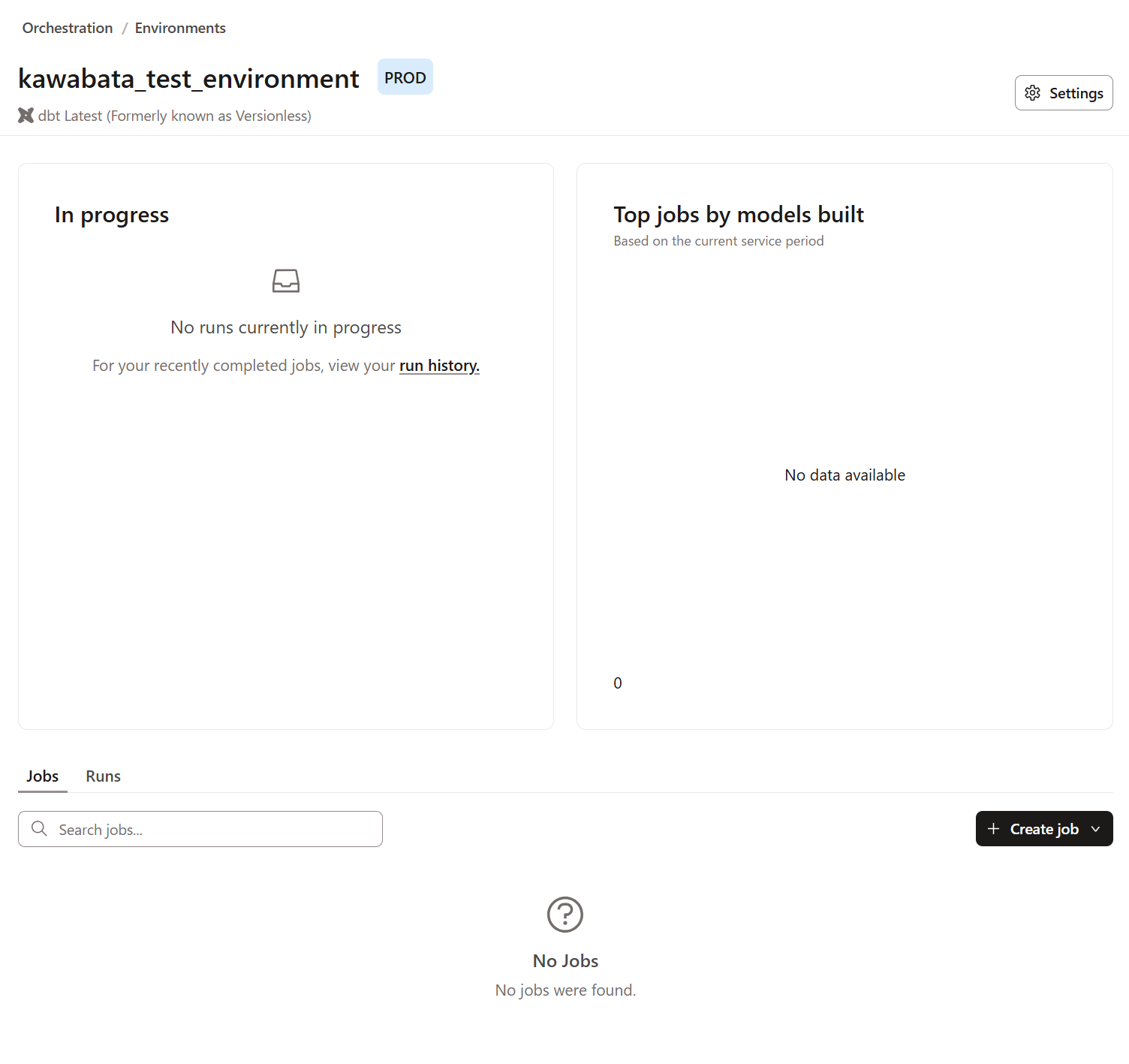
保存すると下記画面のようにPROD環境が作成されます。
Create jobをクリックし、配下のDeploy jobを選択します。
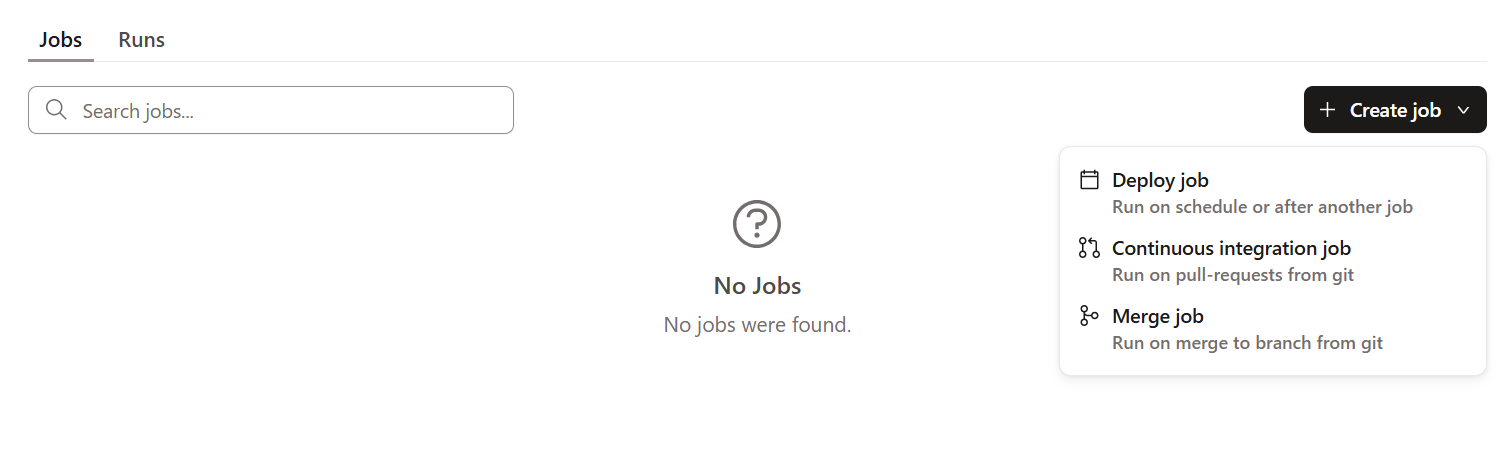
すると、下記の画面に遷移します。任意のJob Nameを設定し保存します。
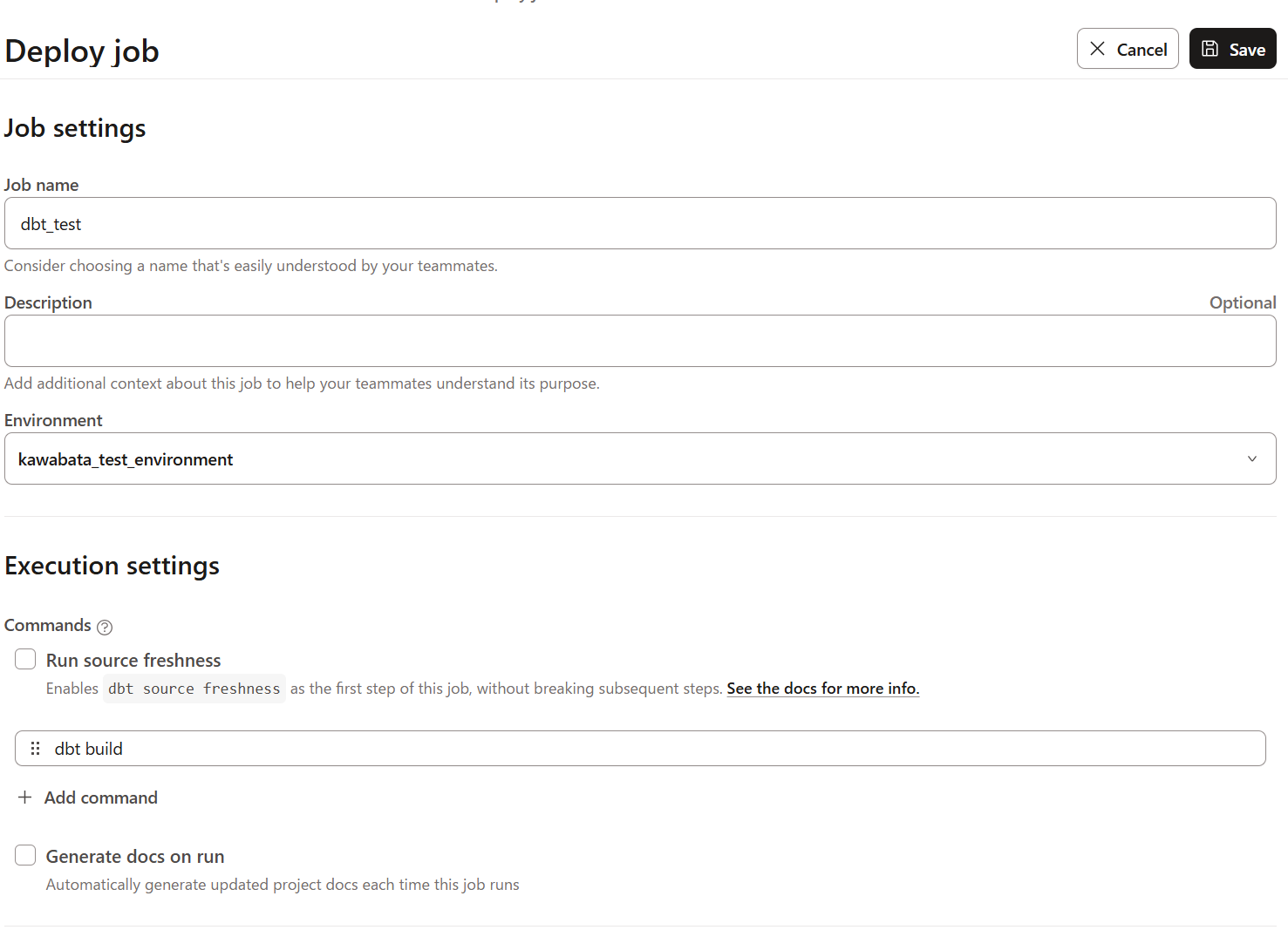
これでジョブの実行準備ができたので、右側上部にある`Run Now'をクリックします。
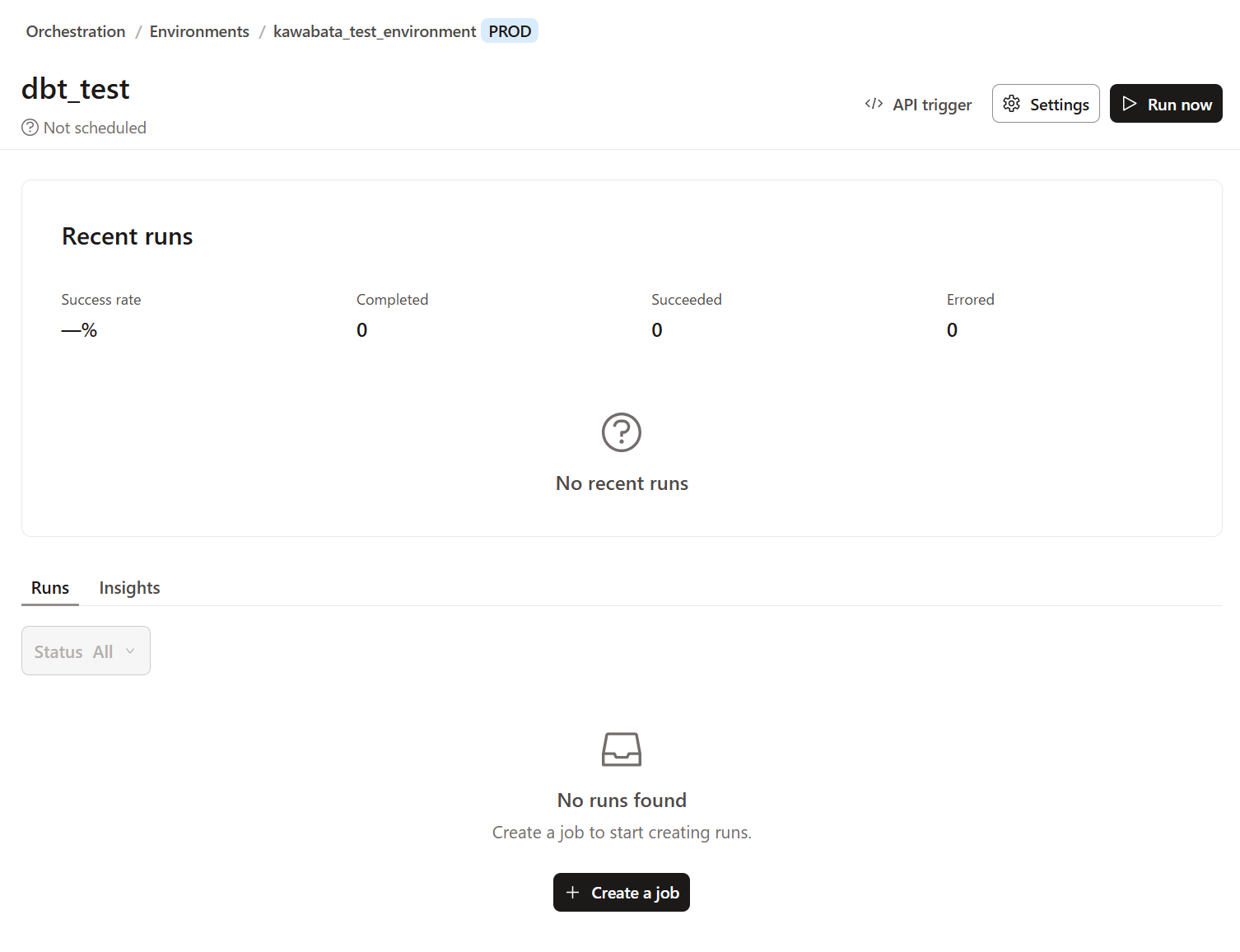
実行すると、ジョブの実行状況を下記のように確認できます。
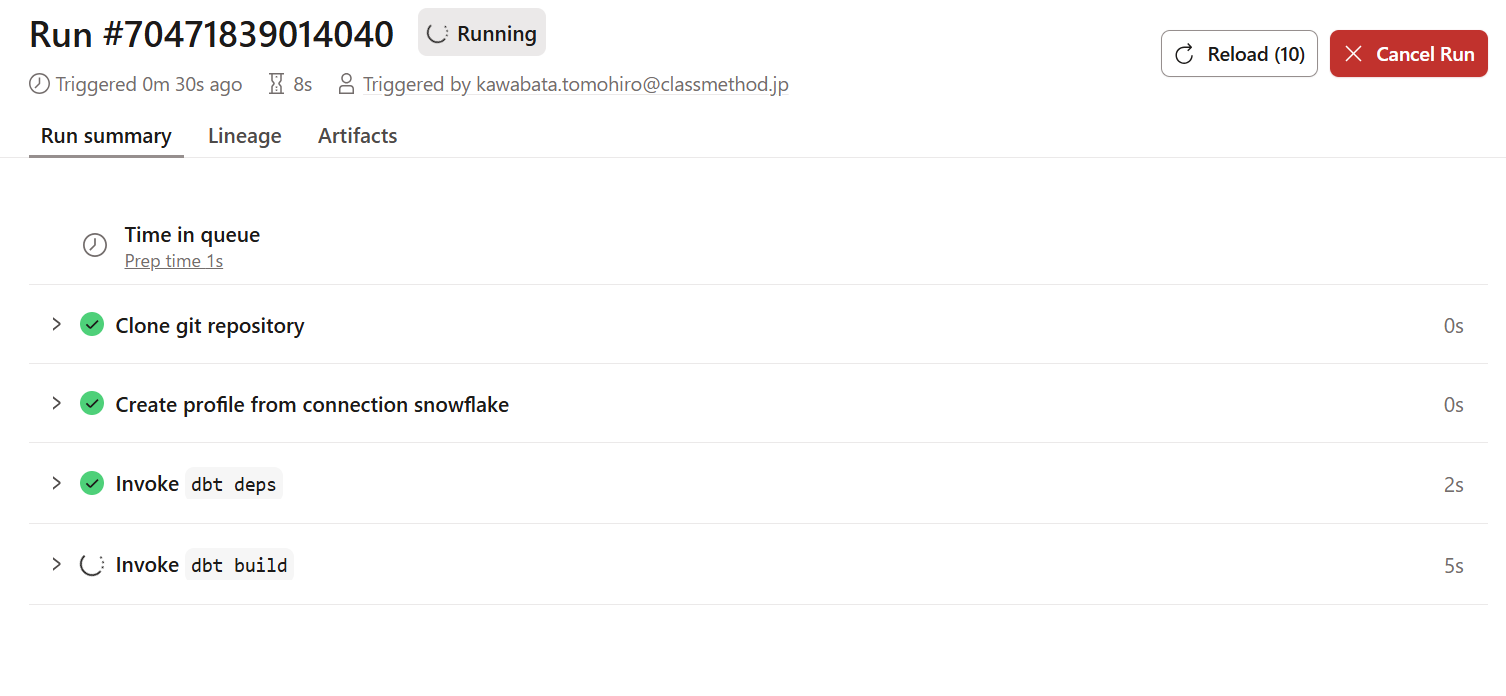
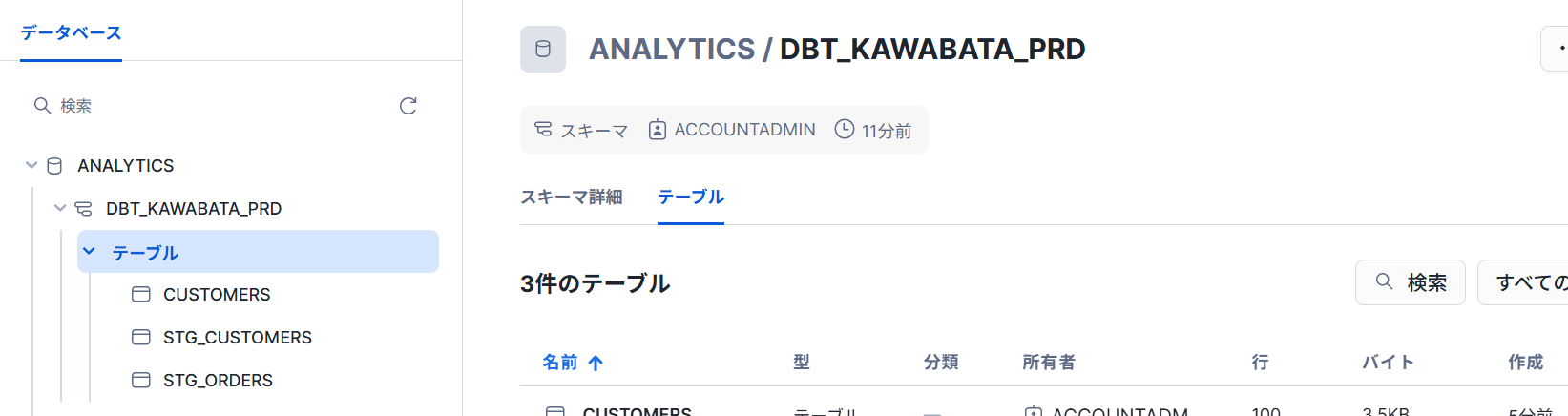
実行が完了し、Snowflake側のデータベースANALYTICSを確認すると下記のように反映されていました。
最後に
いかがでしたでしょうか。dbtとSnowflakeを接続し、デプロイまで体験できるこのガイド(チュートリアル)を通して、私自身も実際に触ることでイメージが格段に上がりました。
弊社過去エントリもありますが、dbtのバージョンが上がったからか変更されている部分もありましたので、
2025年版ということで参考になれば幸いです。








