![[レポート]Amazon DataZoneでデータメッシュの構築とガバナンスを実現 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]Amazon DataZoneでデータメッシュの構築とガバナンスを実現 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS re:Invent2024に参加してきた、データ事業部の渡部です。
2日目のWorkshop【ANT308 | Build and govern your data mesh with Amazon DataZone】に参加してきたので、内容をまとめさせていただきます。
メタデータ管理はお客様からとりわけ問い合わせの多いデータマネジメントの一分野です。
そしてAmazon DataZoneはAWSのデータカタログです。
つまりは触らないといけないということで、何度か触ってはいるのですが使用がおぼつかないので、この機会に使用感に慣れたいという思いで参加をしてみました。
セッション概要
以下の環境を構築していくワークショップでした。
環境はAWSから用意してもらったものでやります。
イメージとしてはSkill Builderでのハンズオンが近いです。
会場の雰囲気がわかりやすいように画像を載せます。
基本的には一人で黙々と構築していくワークショップで、わからないことがあれば手を挙げて質問をします。
本ワークショップは大変人気で予約をしていなかった自分は30分ほど前に並んで、なんとか入ることができました。
以下は会場の様子です。

説明
A data mesh is a distributed, domain-driven architecture that defines responsibilities and coordination across separate domain teams and data products. A data mesh requires data governance to ensure data quality, consistency, security, and trust across domains. In this workshop, learn how to build with Amazon DataZone to help manage and govern your data mesh. Explore automating data discovery, cataloging, and sharing; analyzing data quality; visualizing data lineage; and governing data access to meet objectives. Through hands-on exercises, gain practical experience designing, deploying, and maintaining a well-governed data mesh solution using Amazon DataZone. You must bring your laptop to participate.
AI翻訳
データメッシュは、個別のドメインチームとデータプロダクト間の責任と連携を定義する、分散型のドメイン駆動アーキテクチャです。データメッシュには、ドメイン全体でデータの品質、一貫性、セキュリティ、信頼性を確保するためのデータガバナンスが必要です。このワークショップでは、Amazon DataZoneを使用してデータメッシュを管理・統制する方法を学びます。データの発見、カタログ化、共有の自動化、データ品質の分析、データ系統の可視化、目標達成のためのデータアクセスの管理について探求します。ハンズオン演習を通じて、Amazon DataZoneを使用した適切に管理されたデータメッシュソリューションの設計、デプロイ、維持に関する実践的な経験を得ることができます。参加にはラップトップの持参が必要です。
スピーカー
- Deepmala Agarwal, Sr Data Specialist, AWS
- Diego Ortiz, Data Strategy Solutions Architect, Amazon Web Services
セッション内容
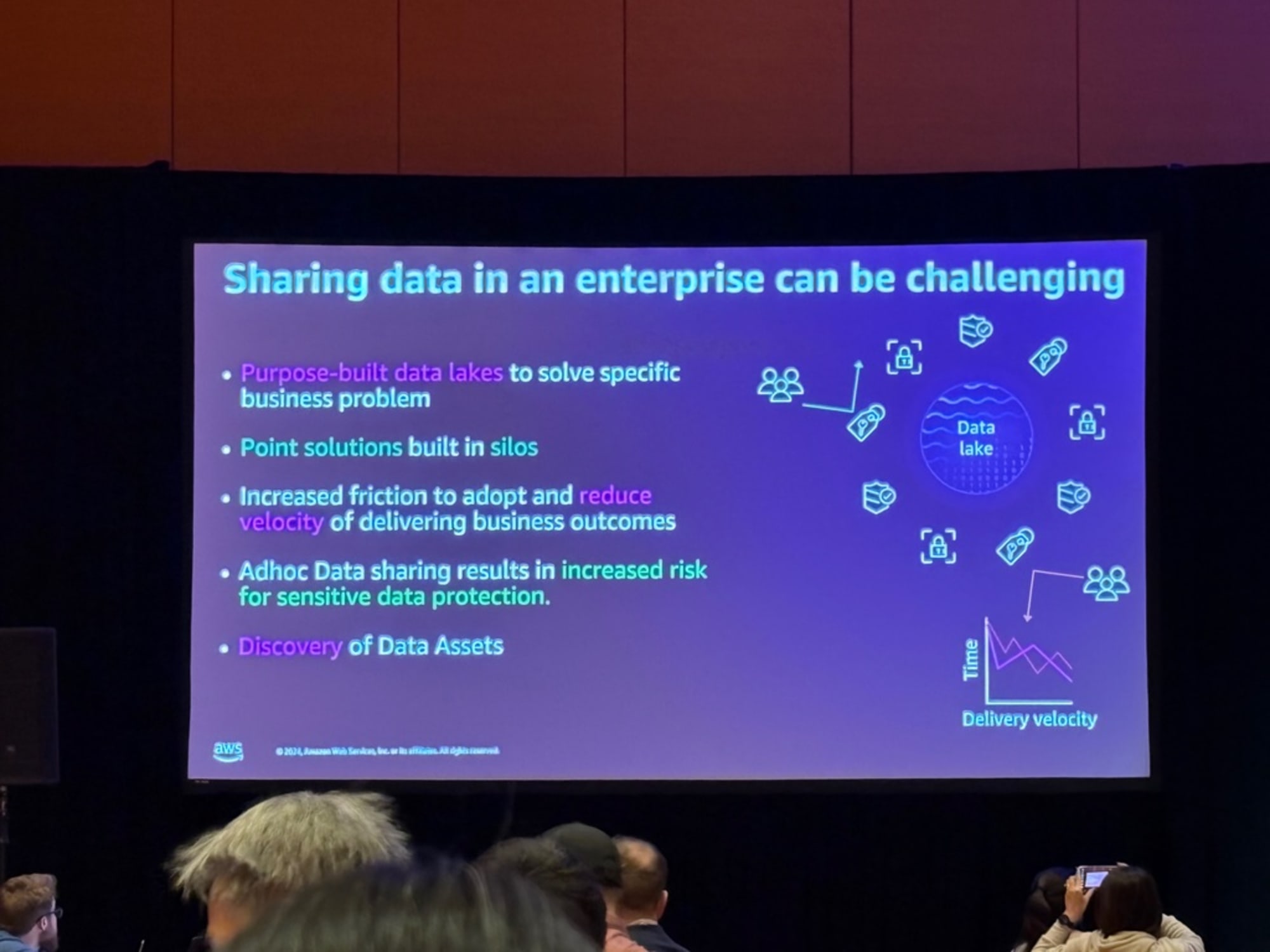
まず初めにデータ共有についての課題について語られました。
以下は抜粋です。
- 断片化されたデータ環境で、データの発見が困難
- 部門ごとに最適化されたソリューションで、データ相乗効果が下がること
- 機密データ保護とのバランス
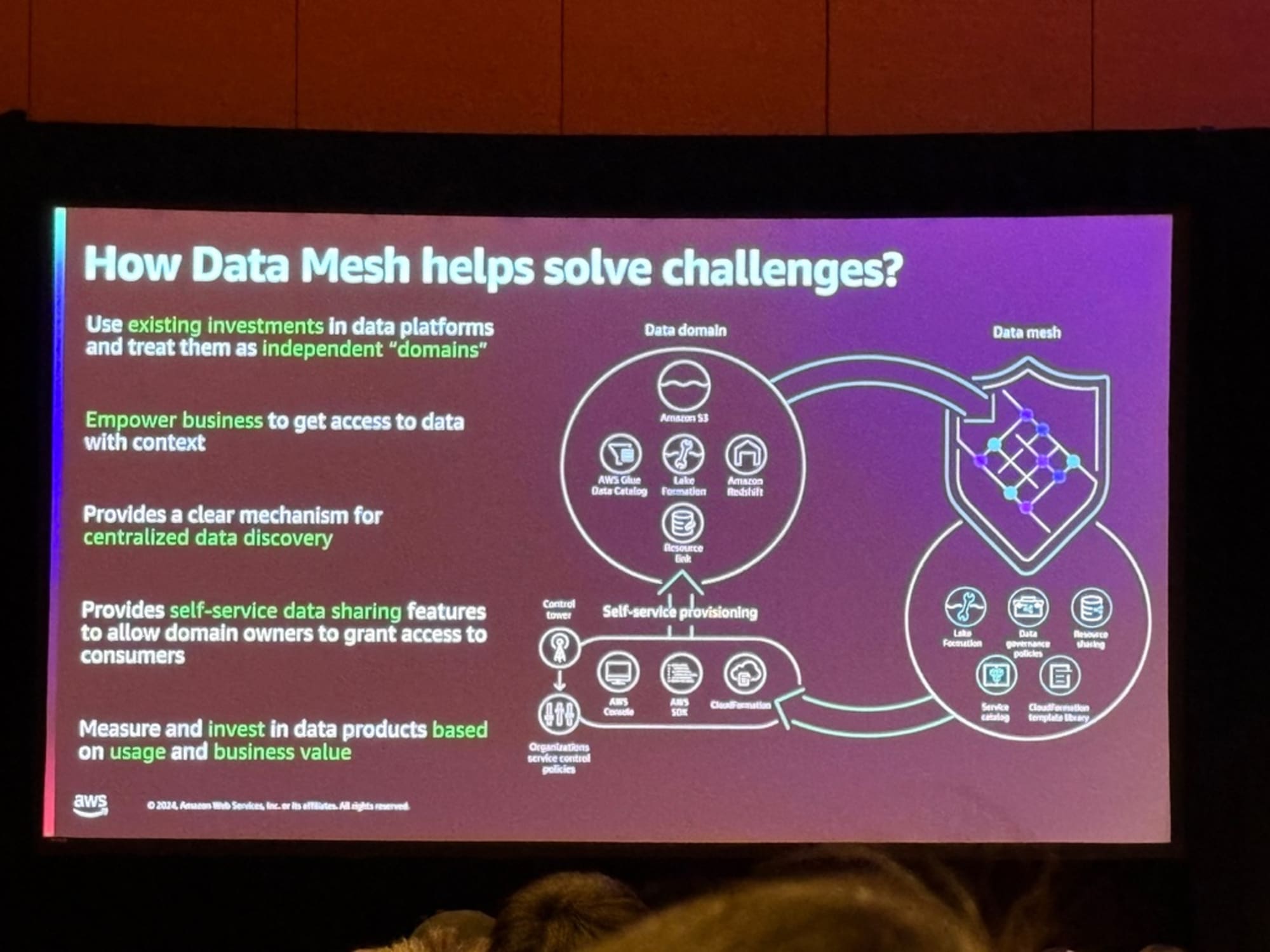
次にデータメッシュの利点について語られます。
- 既存のデータ環境を活用可能
- コンテキストを含めたビジネス部門へのデータアクセス権限付与
- 集中型データ発見メカニズムの提供
- セルフサービスでのデータ共有機能
- データ製品への投資判断
ビジネス部門が一番データに詳しく、その部門がアクセス権限付与ができること。集中させたデータカタログでパブリッシャが自分のデータを定義し、コンシューマがどうデータを利用するかの設定が可能であること。部門同士の調整なしに、コンシューマが簡単にデータ利活用できること。
以上が利点として挙げられました。
なおデータメッシュについては、こちらの記事がわかりやすいです。
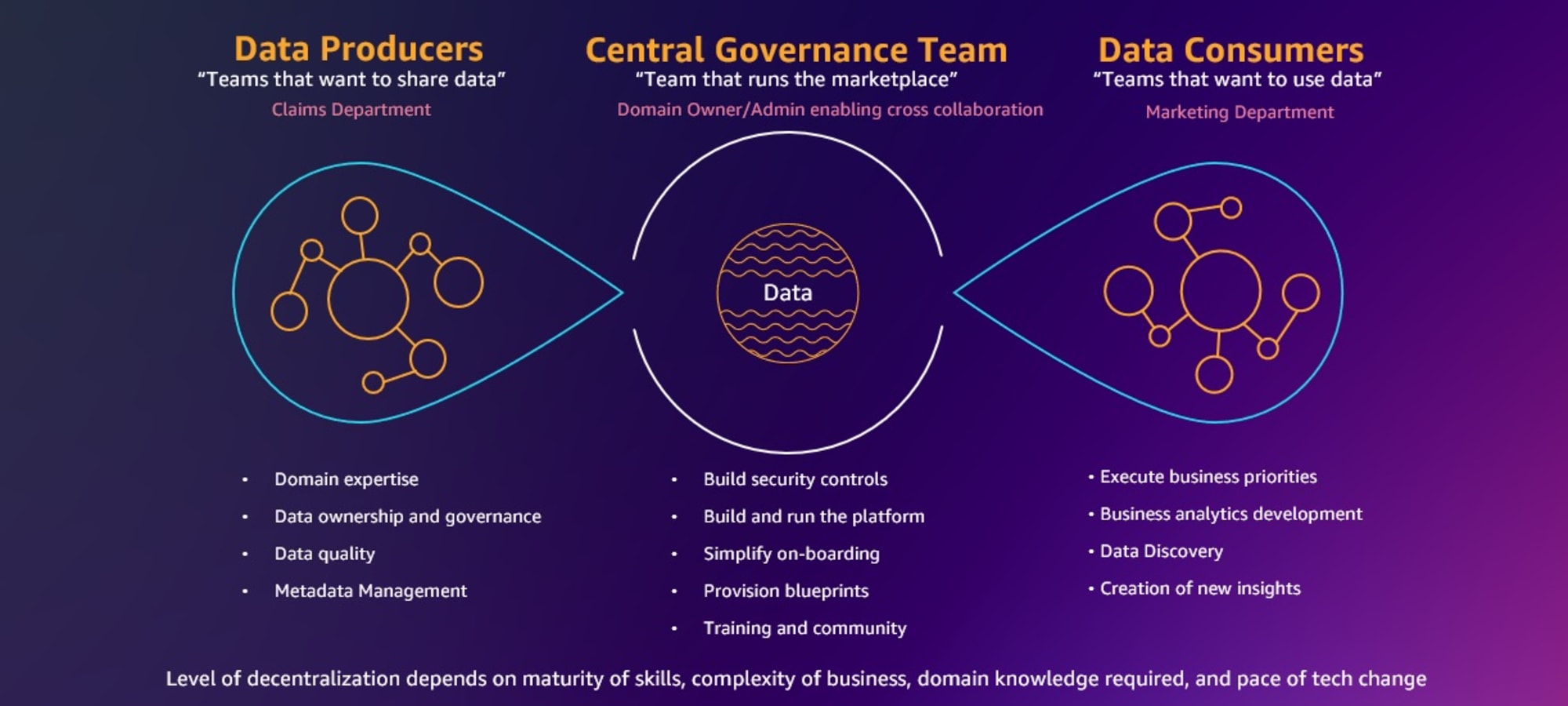
次にデータメッシュの4つの核が紹介されます。
- データオーナー:データの所有権
- データスチュワード:データ共有のガバナンス
- データプロデューサー:データプロダクトの定義
- データコンシューマー:セルフサービスによるデータ発見
データプロダクトの共有方法を定めて共通ガイドラインを策定するデータスチュワードは、この中でも特にデータメッシュでの重要な枠割を担います。

データ共有やメッシュの話が繰り広げられたあと、DataZoneではこれらを実現できると紹介されました。
DataZoneのコンポーネントについて、概要図があげられました。

続いてそのDataZoneを触るワークショップの紹介に移り、
データカタログの準備、プロデューサーによるデータプロダクトの提供、データコンシューマーによるデータ発見と消費までがワークショップの対象となることが説明されました。

ワークショップで構築するアーキテクチャです。
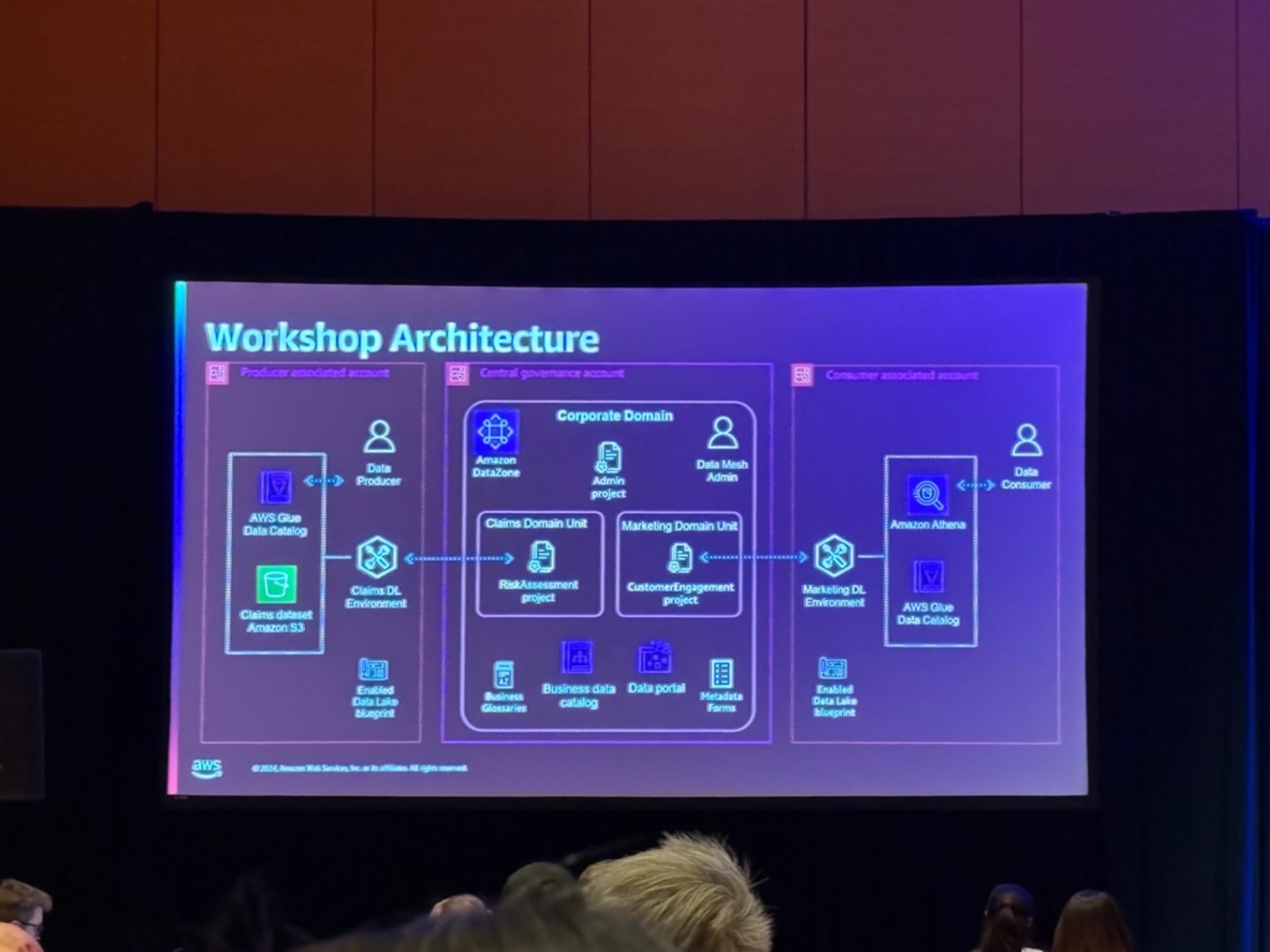
ここから各自ワークショップに移りました。
ワークショップの内容としては、以下で公開されているワークショップの内容とほぼ同じとなります。
内容のとおり進めていくと、DataZoneでの前準備、データ提供・消費をどうやるのかが確認できると思います。
特にはじめはドメインに対してアカウントを紐づけたり、プロジェクト作成の権限を付与したりと、カタログの準備・設定作業がかなり多く使い始めるまでが大変という印象です。
特にAWSアカウントやロールの考えが出てくるためです。
データスチュワードとDataZoneの有識者がともに、何が企業にとってカタログやデータ共有機能に対して必要な機能かを棚卸して、DataZoneではそれをどう実現するのか考えていくのがストーリーとしてはいいのかなと思いました。
さいごに
DataZoneにはプロジェクトや環境など、聞き慣れない用語があります。
最初は理解が難しく、私も完全に把握できているとは言えないのですが、AWS謹製のデータカタログということで、今後もAWSサービスとの親和性が深まってくるでしょう。
また最近はユーザーごとの課金から使用量に対する従量課金と料金体系が一新されました。
これでよりDataZoneを試して使用してみることが簡単になったのではないでしょうか。
データメッシュを実現するAWSのデータカタログ・アクセス管理サービス、ぜひ一度触ってみてください。








