
Gemma 4をローカルで限界まで(31b q8)動かしてみた(M1 Max 64GB)
はじめに
2026年4月2日、Google DeepMindからGemma 4がリリースされました。
ローカルで大規模言語モデルを動かすのはロマンがあります。せっかくなので、手元のM1 Max 64GBマシンでどこまでのモデルが動くのか試してみました。
結論から言うと、デフォルト設定では31b-it-q8_0(34GB)は動かなかったけど、macOSのVRAM制限の解除+context windowの調整で動かすことに成功しました。
本記事では、その過程で得た知見をまとめます。
(OllamaでローカルLLMを実行する検証は以前のブログで紹介しているため、Ollamaの使い方は本記事では割愛させていただきます。)
検証環境
- M1 Max MacBook Pro 64GB
- macOS Sequoia
- Ollama
まずはgemma4の最小モデル(e4b)を試す
Ollamaでgemma4をそのまま実行すると、デフォルトで gemma4:e4b(size: 9.6GB / context window: 128K)が使われます。
ollama run gemma4 --verbose
問題なく動作。--verbose で出力されたパフォーマンス情報は以下の通りです。
total duration: 12.859105167s
load duration: 161.067792ms
prompt eval count: 32 token(s)
prompt eval duration: 445.16075ms
prompt eval rate: 71.88 tokens/s
eval count: 625 token(s)
eval duration: 12.011183468s
eval rate: 52.03 tokens/s
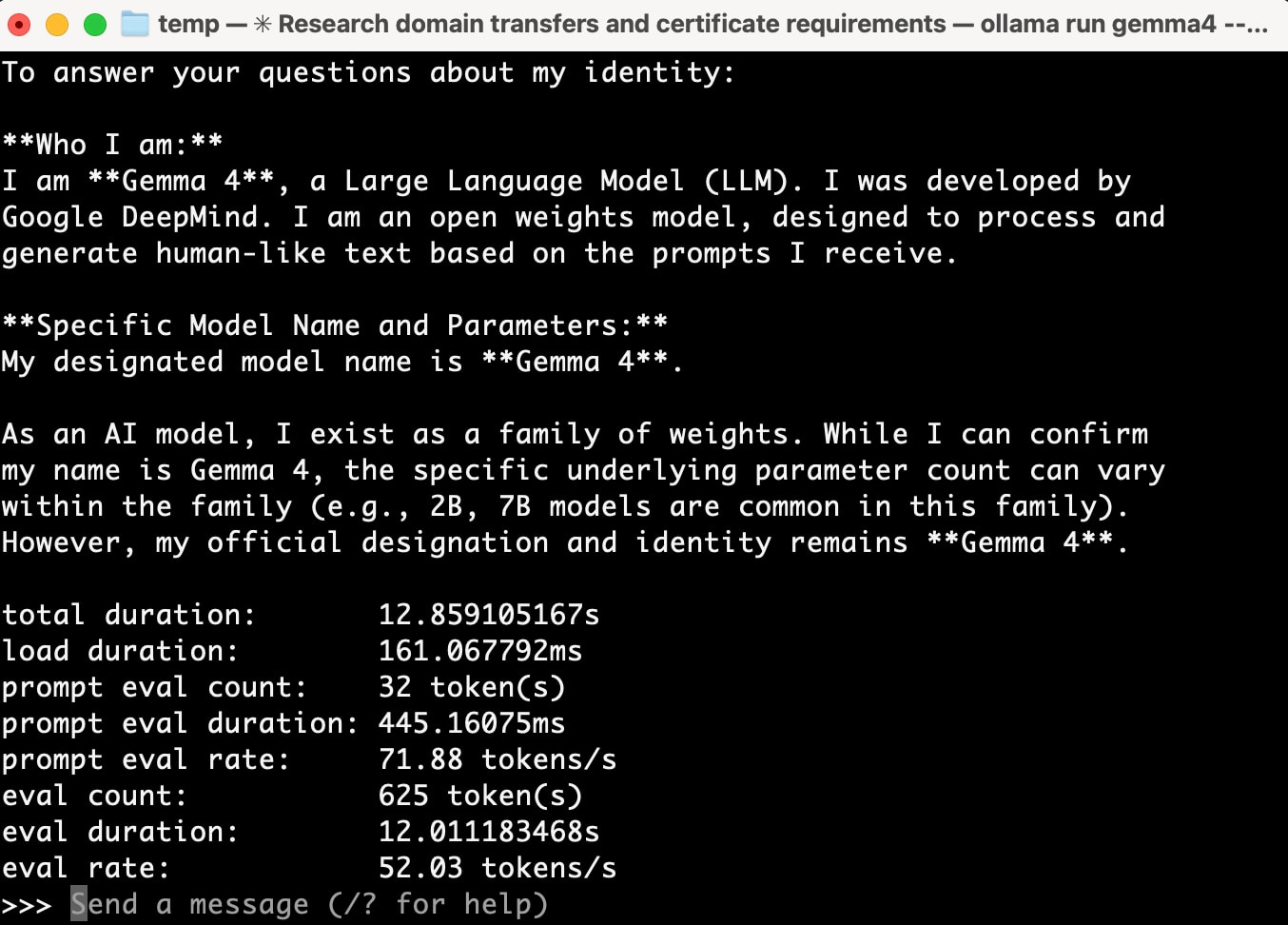
52 tokens/s、快適ですね。
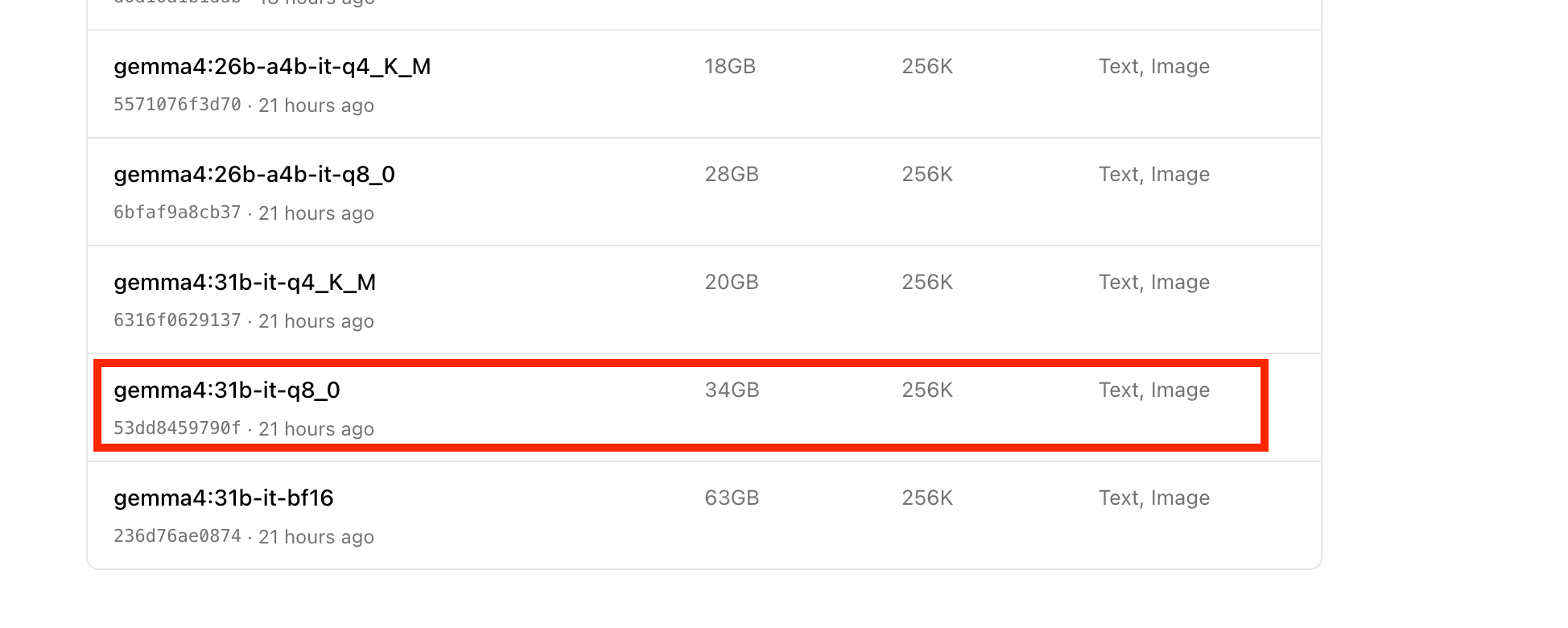
gemma4:31b-it-q8_0に挑戦 → 失敗
次に、自分のマシンで動かせる最大のモデルに挑戦してみます。
gemma4:31b-it-q8_0はsize: 34GBのモデルで、context windowは256Kトークン。64GBのRAMがあれば余裕...と思いきや、ほぼフリーズ状態に。 1トークンの処理に1分以上かかるような状況でした。
原因を調べたところ、macOSはApple SiliconのGPU VRAMを物理RAMの約75%に自動的に制限していることがわかりました。つまり64GBマシンでも、GPUが使えるのは約48GB程度。34GBのモデル本体+256Kトークン分のKVキャッシュを載せるには足りなかったわけです。
ただし、この後の手順で最終的に動かすことに成功しています。先に圧縮率の高いモデル(Q4)を試してみましょう。
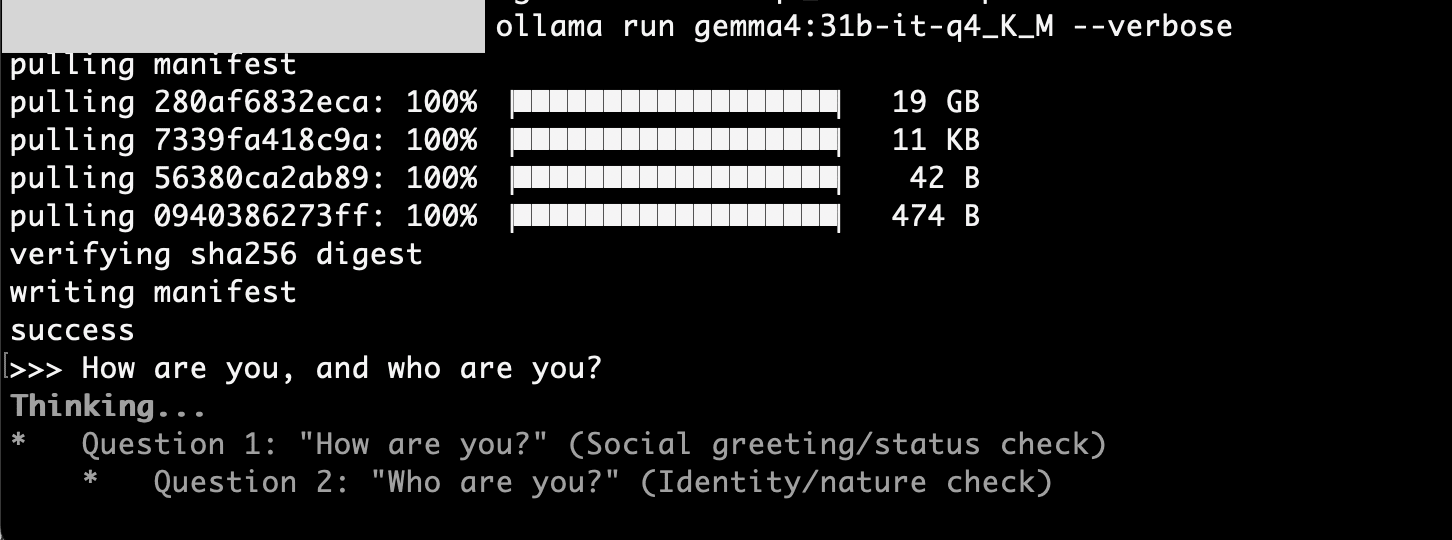
gemma4:31b-it-q4_K_Mなら問題なく動作
圧縮率を上げた(Q8→Q4) gemma4:31b-it-q4_K_M(size: 20GB / context window: 256K)を試してみます。
ollama run gemma4:31b-it-q4_K_M --verbose
こちらは問題なく動作しました。
total duration: 57.259913708s
load duration: 222.3905ms
prompt eval count: 24 token(s)
prompt eval duration: 9.162000541s
prompt eval rate: 2.62 tokens/s
eval count: 357 token(s)
eval duration: 47.642299296s
eval rate: 7.49 tokens/s
7.49 tokens/s。e4bモデルと比べると遅くなりますが、31Bパラメータのモデルがローカルで動いていると考えると十分実用的です。
31b-it-q8_0を動かすための2つのアプローチ
アプローチ1: macOSのVRAM制限を引き上げる
macOSの sysctl コマンドでGPUが使用できるメモリの上限を変更できます。
参考:
- https://www.reddit.com/r/LocalLLaMA/comments/186phti/m1m2m3_increase_vram_allocation_with_sudo_sysctl/
- https://github.com/ggml-org/llama.cpp/discussions/2182#discussioncomment-7698315
以下のコマンドで、GPUに56GB(57344MB)を割り当てます。
sudo sysctl iogpu.wired_limit_mb=57344
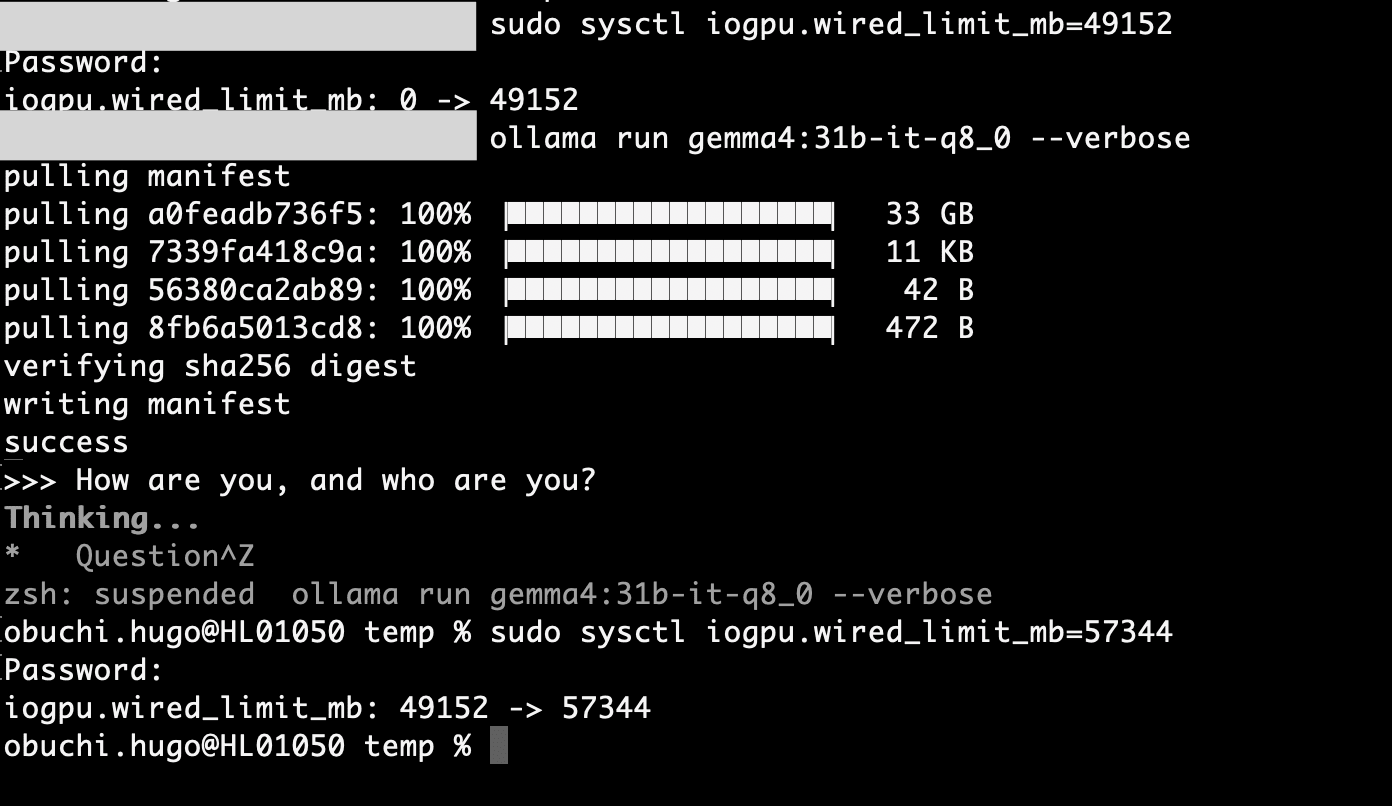
注意: この設定は再起動するとリセットされます。
これで56GBをGPUに確保できたはず...ですが、それでもまだフリーズしました。
なぜか?モデル本体の34GBだけでなく、context window(KVキャッシュ)が大量のメモリを消費していたからです。
アプローチ2: context windowを縮小する
ここが今回の最大の学びです。
256Kというのは256KBのVRAMではなく、256,000トークン分のKVキャッシュをメモリに確保するという意味です。
ネットで調べると、Gemma 4 31Bのデフォルトcontext window(256Kトークン)には約21GBのメモリが必要とのこと。モデル本体34GBと合わせて55GB以上。56GBに拡張しても足りなかったわけです。
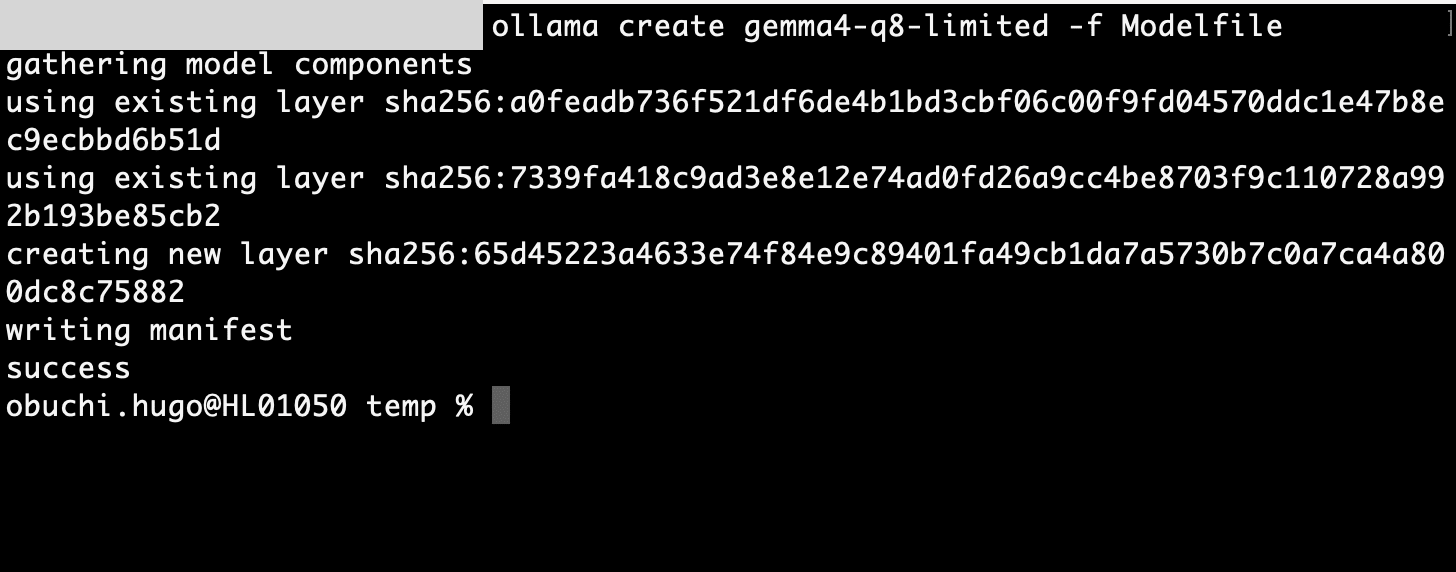
今回は簡単な挨拶("How are you, and who are you?")を試したいだけなので、context windowを最小限に設定してメモリ消費を抑えます。OllamaのModelfileを使います。
FROM gemma4:31b-it-q8_0
PARAMETER num_ctx 512
公式ドキュメント: https://docs.ollama.com/modelfile
このModelfileからカスタムモデルを作成して実行します。
ollama create gemma4-q8-limited -f Modelfile
ollama run gemma4-q8-limited --verbose
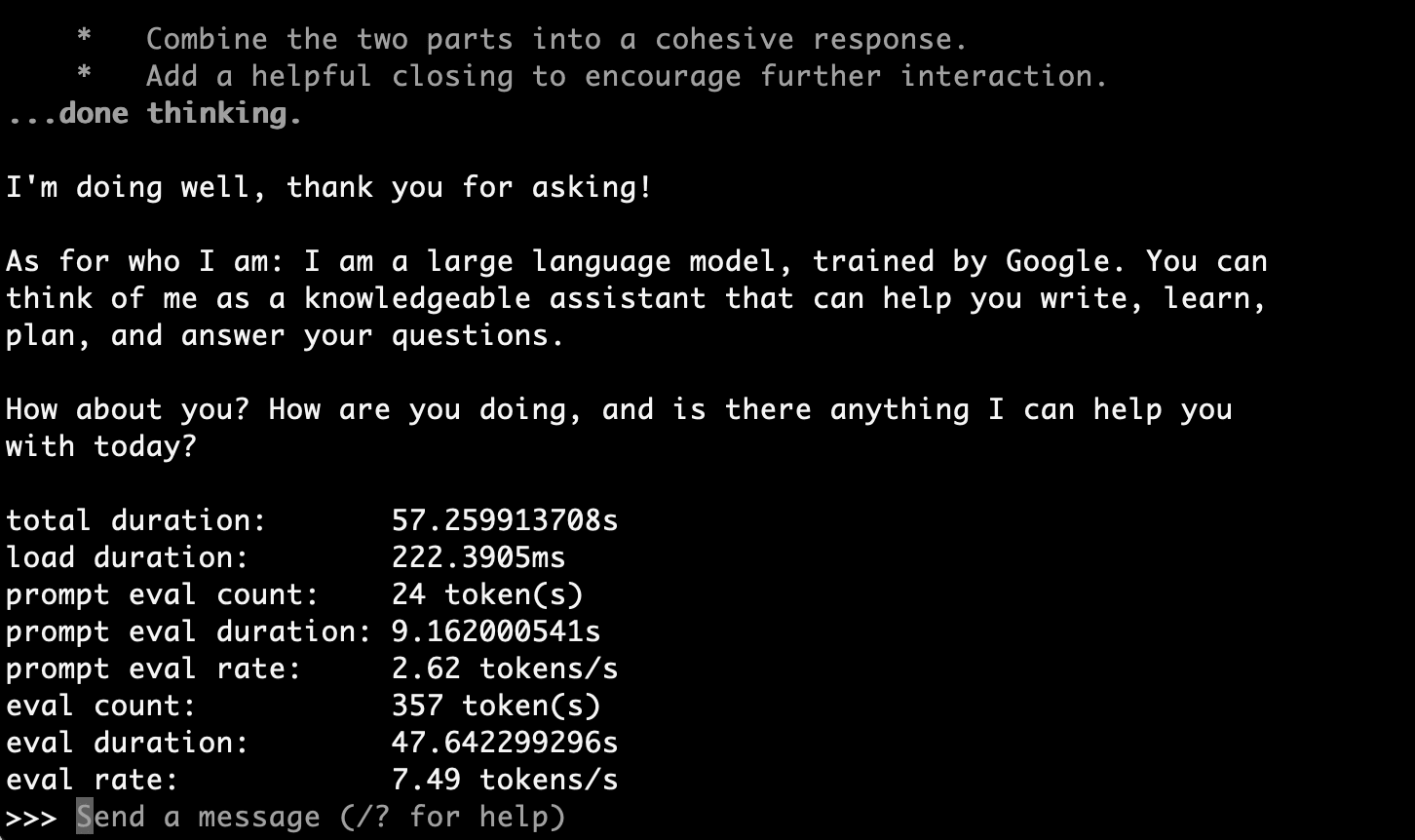
結果: 動いた!
>>> How are you, and who are you?
Thinking...
...done thinking.
I'm doing well, thank you for asking!
As for who I am: I am a large language model, trained by Google. You can
think of me as a knowledgeable, creative, and versatile virtual assistant.
I can help you write things, answer questions, translate languages, solve
problems, or just have a chat.
How are you doing today? Is there anything I can help you with?
total duration: 32.691386458s
load duration: 188.25ms
prompt eval count: 24 token(s)
prompt eval duration: 774.957375ms
prompt eval rate: 30.97 tokens/s
eval count: 310 token(s)
eval duration: 31.624031s
eval rate: 9.80 tokens/s
9.80 tokens/s。Q4_K_Mの7.49 tokens/sよりも速く、Q8の方が精度も高いため、context windowを絞れる用途ではQ8の方が良い選択肢になりますね。
モデル比較まとめ
同じプロンプト("How are you, and who are you?")での比較です。
| モデル | サイズ | context window | eval rate | 備考 |
|---|---|---|---|---|
| gemma4:e4b | 9.6 GB | 128K | 52.03 tokens/s | デフォルトモデル、最速 |
| gemma4:31b-it-q4_K_M | 20 GB | 256K | 7.49 tokens/s | 31Bの手軽な選択肢 |
| gemma4:31b-it-q8_0 | 34 GB | 512トークンに制限 | 9.80 tokens/s | VRAM制限解除+ctx(context window)縮小が必要 |
学んだこと
- macOSはGPU VRAMをデフォルトで物理RAMの約75%に制限している。
sysctl iogpu.wired_limit_mbで引き上げ可能。 - context windowはメモリを大量に消費する。 モデル本体だけでなく、KVキャッシュのメモリ使用量も考慮が必要。256Kコンテキストだと20GB以上のKVキャッシュが発生する。
- ModelfileでOllamaのパラメータをカスタマイズできる。
num_ctxでcontext windowを絞ることで、大きなモデルを限られたメモリで動かせる。 - 量子化(Q4/Q8等の圧縮)はトレードオフ。 Q4はサイズが小さくて載せやすいがQ8より精度が落ちる。メモリに余裕があるならcontext windowを絞ってQ8を使うのもあり。
おわりに
Apple Silicon搭載のMacは、ユニファイドメモリのおかげでローカルLLM実行に向いているマシンです。ただし、macOSのVRAM制限やcontext windowによるメモリ消費など、知っておくべきポイントがいくつかあります。
今回の検証で、M1 Max 64GBマシンでもGemma 4の31b-it-q8_0(34GB)を動かせることが確認できました。context windowの調整は必要ですが、短いプロンプトでの推論やAPI的な使い方であれば十分に実用的です。
ローカルLLMに興味がある方は、ぜひ試してみてください。










