![[アップデート] AWS Glue の Interactive Session の Spark Connect 対応を VS Code からノートブックで試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-545ba5dfbc8fa4c7760dd9872ef835f9/665944e579f487b4434cb289305767b3/aws-glue?w=3840&fm=webp)
[アップデート] AWS Glue の Interactive Session の Spark Connect 対応を VS Code からノートブックで試してみた
クラウド事業本部の石川です。AWS Glue の Interactive Session が Apache Spark Connect に対応し、SageMaker Unified Studio のノートブックや手元のIDEから直接 PySpark を実行できるようになりましたので、VS Code のノートブックから実際に接続して試してみました。
AWS Glue のインタラクティブセッションは、ジョブ化する前の PySpark コードを対話的に実行・デバッグするためのサーバーレスな仕組みです。これまではノートブックカーネル(SparkMagic)や Livy ベースの Statement API を介してセッションとやり取りしていました。
今回のアップデートにより、AWS Glue のインタラクティブセッションが Apache Spark Connect をネイティブにサポートしました。Spark Connect はクライアントとSparkの実行環境を分離する軽量なクライアント・サーバー型アーキテクチャで、これによって SageMaker Unified Studio のノートブックや、VS Code・PyCharm といった Python インタプリタを持つIDE、あるいは任意の Python スクリプトから、AWS Glue のサーバーレス Spark に直接接続できるようになりました。アドホックなデータ探索、ステップバイステップのデバッグ、本番投入前の段階的な PySpark ジョブ開発を、普段使っているツールのまま行える点が特徴です。
Spark Connect とは
Apache Spark Connect は Spark 3.4 で導入された、クライアントとSparkドライバプロセスを分離するアーキテクチャです。クライアントは論理実行プランを gRPC でサーバーに送り、結果は Apache Arrow でストリーミングされます。クライアント側はフルの Spark ランタイムを持つ必要がなく、PySpark の remote() API に対応した環境であれば接続できます。
AWS Glue では Glue バージョン 5.1 以降のインタラクティブセッションで Spark Connect がサポートされます。従来の Livy セッションとの違いは以下のとおりです。
| 項目 | Livy | Spark Connect |
|---|---|---|
| プロトコル | REST | gRPC(論理実行プラン)+ Apache Arrow(結果ストリーミング) |
| 接続方法 | Statement API(RunStatement / GetStatement 等) | エンドポイントURLへ PySpark remote() で直接接続 |
| クライアント要件 | aws-glue-sessions パッケージ or AWS SDK | Spark Connect 対応の PySpark |
| 対応環境 | SparkMagic カーネルの Jupyter | SageMaker Unified Studio のノートブック、VS Code・PyCharm 等のIDE |
接続の全体像は以下のようになります。
なお Spark Connect は AWS Glue Studio では利用できません。インタラクティブ開発には SageMaker Unified Studio のノートブックか、Python インタプリタを持つIDEを利用します。
やってみた
今回は SageMaker Unified Studio を使わず、普段の開発環境である VS Code のノートブック(Jupyter拡張)から、AWS Glue の Spark Connect セッションに接続して PySpark を実行してみます。
前提条件
- 検証リージョン: ap-northeast-1 / 東京
- AWS Glue インタラクティブセッション用のIAMロール(本検証では Glue Data Catalog と S3 を参照できる
AWSGlueServiceRoleDefaultを使用) - 呼び出し元プリンシパルに必要な権限:
glue:CreateSession/glue:GetSession/glue:GetSessionEndpoint/glue:DeleteSessionと、ロールを Glue に渡すためのiam:PassRole - VS Code(Python 拡張・Jupyter 拡張を導入済み)
- ローカルの Python 3.11 環境
Spark Connect のエンドポイントはパブリックな gRPC エンドポイント(443/TLS)で、トークン認証を用います。VPC内に置く必要はなく、手元のPCからインターネット経由で接続できます。
クライアント環境とカーネルの準備
ローカルに Spark Connect クライアントを用意します。フルの Spark や Java は不要で、PySpark の Spark Connect クライアント(純Pythonの gRPC クライアント)だけで接続できます。接続先の Glue 5.1 が Spark 3.5 系のため、クライアントの PySpark もバージョンを合わせます。あわせて、VS Code から選択するための Jupyter カーネルを登録します。
python3.11 -m venv .venv
source .venv/bin/activate
pip install boto3 "pyspark[connect]==3.5.6" pandas pyarrow grpcio grpcio-status ipykernel
python -m ipykernel install --user --name sparkconnect-glue --display-name "Python 3.11 (Glue Spark Connect)"
私の環境の場合、VS Code でノートブック(.ipynb)を開き、右上の「カーネルの選択」から Python 3.11 (Python 3.11.13) を選びます(venv のインタプリタを直接選択しても構いません)。あとは従来のように専用の Spark カーネル(SparkMagic)を用意する必要はなく、通常の Python カーネルからそのまま Glue に接続できます。
0. ライブラリの読み込みとセッション情報の準備
実行アカウントから Glue セッション用のロール ARN を組み立てます(ハードコードを避けるため sts で取得)。セッションIDは毎回ユニークにします。
import time, uuid, urllib.parse
import boto3
from pyspark.sql import SparkSession
REGION = "ap-northeast-1"
glue = boto3.client("glue", region_name=REGION)
account_id = boto3.client("sts", region_name=REGION).get_caller_identity()["Account"]
role_arn = f"arn:aws:iam::{account_id}:role/AWSGlueServiceRoleDefault"
session_id = "blog-vscode-sc-" + uuid.uuid4().hex[:8]
print("session_id:", session_id)
print("role_arn :", role_arn)

1. Spark Connect セッションを作成
SessionType="SPARK_CONNECT" と GlueVersion="5.1" を指定します。コストを抑えるため、ワーカーは最小構成(G.1X × 2)、アイドルタイムアウトも短めにしています。
resp = glue.create_session(
Id=session_id,
Role=role_arn,
Command={"Name": "glueetl"},
GlueVersion="5.1",
SessionType="SPARK_CONNECT",
NumberOfWorkers=2,
WorkerType="G.1X",
IdleTimeout=15,
Timeout=30,
DefaultArguments={"--language": "python", "--enable-glue-datacatalog": "true"},
)
s = resp["Session"]
print("Status :", s["Status"])
print("SessionType :", s["SessionType"])
print("GlueVersion :", s["GlueVersion"])
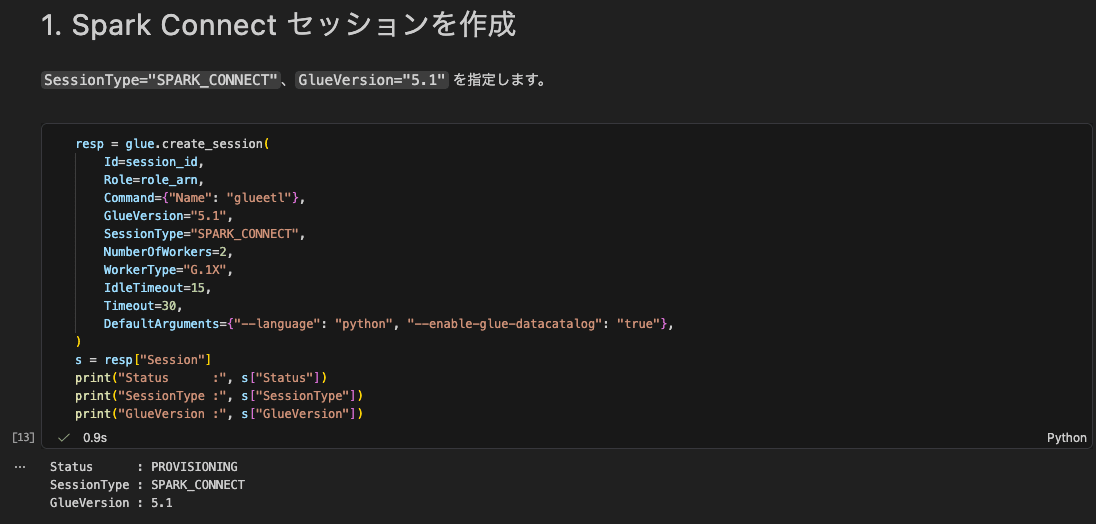
SessionType が SPARK_CONNECT で作成できました。Intaractive Serssionが作成され、マネジメントコンソールからProvisioningであることが確認できます。
2. READY になるまで待機
セッションが READY になるまでポーリングします。今回は数十秒で READY に到達しました。
while True:
status = glue.get_session(Id=session_id)["Session"]["Status"]
print(status)
if status in ("READY", "FAILED", "STOPPED", "TIMEOUT"):
break
time.sleep(10)
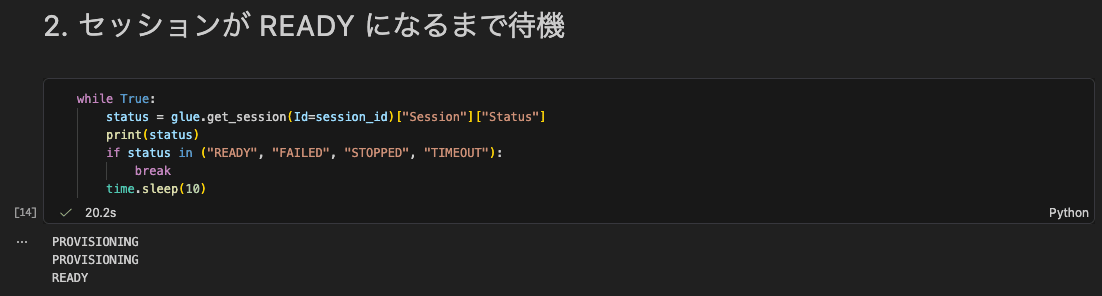
Intaractive SerssionがReadyであることが確認できます。

3. エンドポイントとトークンを取得
get_session_endpoint(新しいAPI)で Spark Connect の接続先URLと認証トークンを取得し、remote() に渡す接続文字列を組み立てます。トークンは機密のため、表示はマスクしています。
ep = glue.get_session_endpoint(SessionId=session_id)["SparkConnect"]
token = urllib.parse.quote(ep["AuthToken"], safe="")
remote = f"{ep['Url']}:443/;use_ssl=true;x-aws-proxy-auth={token}"
print("Url :", ep["Url"])
print("AuthToken (len) :", len(ep["AuthToken"]), "chars (masked)")
print("AuthTokenExpirationTime:", ep["AuthTokenExpirationTime"])

レスポンスの SparkConnect には Url、AuthToken、AuthTokenExpirationTime(トークンの有効期限)が含まれます。
4. Spark Connect で接続
組み立てた接続文字列を SparkSession.builder.remote(...) に渡して接続します。VS Code のカーネル(手元のPC)はあくまで薄いクライアントとして振る舞い、処理は Glue 側の Spark で実行されます。
spark = SparkSession.builder.remote(remote).getOrCreate()
spark.version
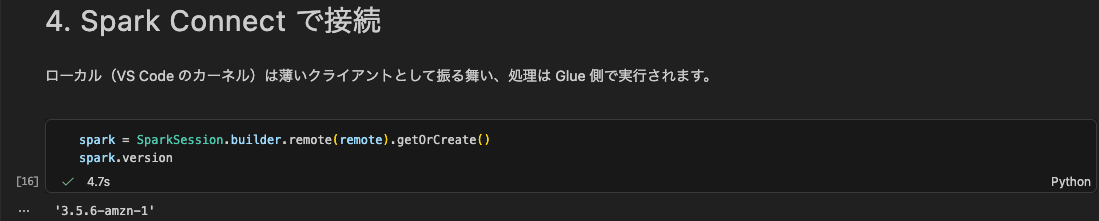
接続先の Spark バージョンは 3.5.6-amzn-1 でした。
5. PySpark / Spark SQL を実行
DataFrame API と Spark SQL をセルから実行します。
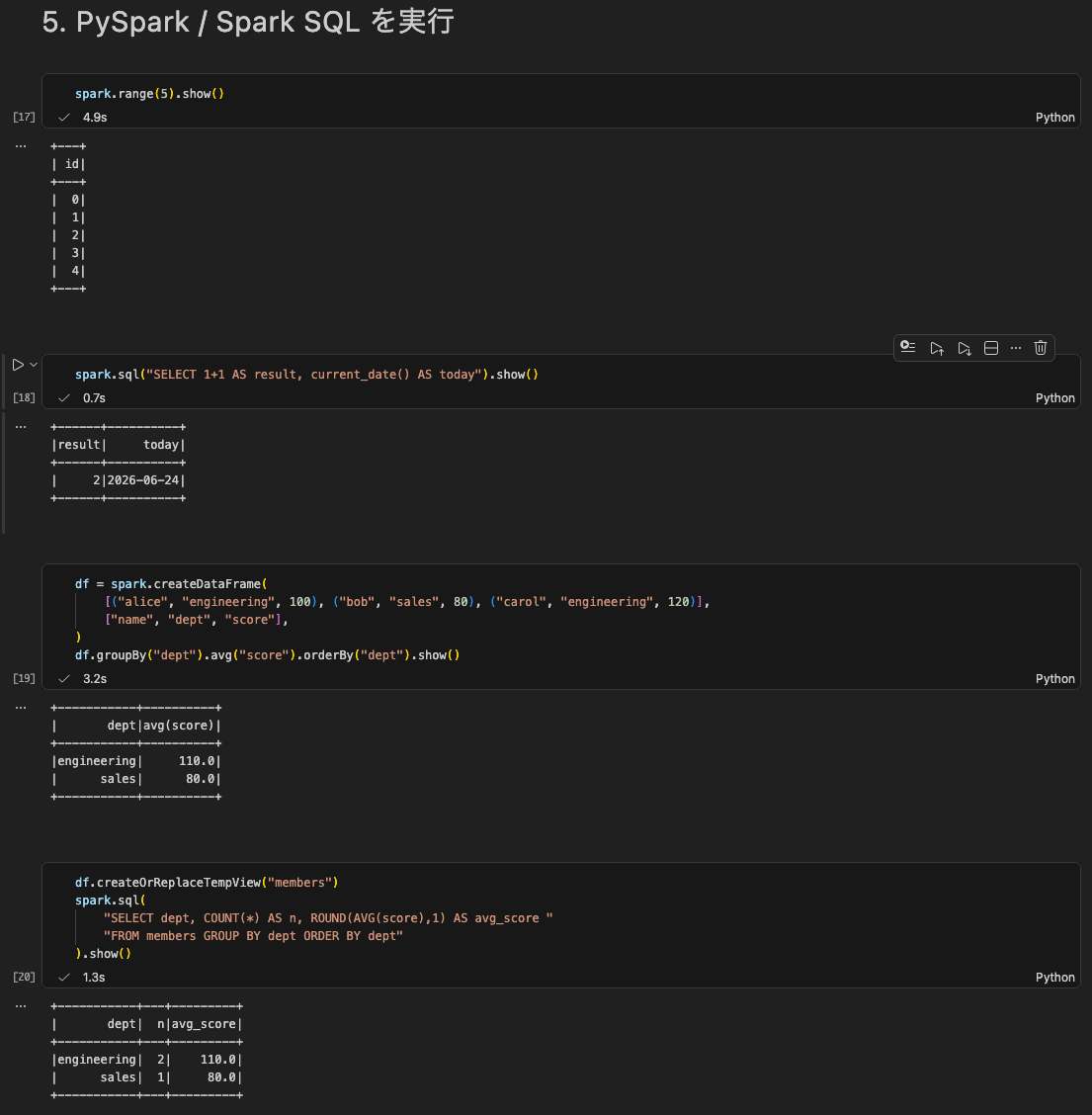
DataFrame API、Spark SQL、Temp View を使った集計まで、VS Code のセルから問題なく実行できました。結果の収集(show)は Apache Arrow 経由で行われます。
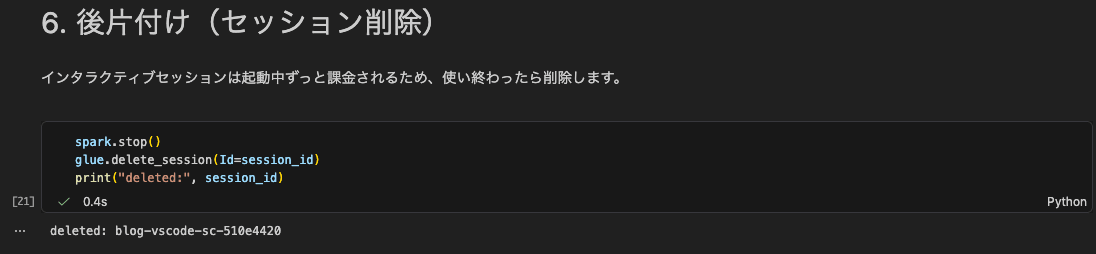
セル7: 後片付け(セッション削除)
インタラクティブセッションは起動中ずっと課金されるため、使い終わったらセッションを削除します。アイドルタイムアウト任せにせず、ノートブックの最後のセルで明示的に削除しておくと安全です。
spark.stop()
glue.delete_session(Id=session_id)
print("deleted:", session_id)
考察
実際に VS Code のノートブックから試してみて得られた知見と注意点を整理します。
- 手元のPCにフルの Spark や Java を用意しなくても、
pyspark[connect]だけで Glue のサーバーレス Spark に対話的に接続できました。従来のように専用の Spark カーネル(SparkMagic)を用意する必要はなく、通常の Python カーネルからそのまま接続できる手軽さがあります。 - 接続はパブリックな gRPC エンドポイント(443/TLS)+トークン認証で、VPCのセットアップは不要でした。普段使いの VS Code からそのまま接続できるのは実務上ありがたいポイントです。
- 認証トークンには有効期限(
AuthTokenExpirationTime)があります。長時間のセッションでは、公式ドキュメントのサンプルにあるようにget_session_endpointでトークンを取り直して再接続する仕組みを入れておくと安心です。
制限事項として、以下は押さえておくとよいです。
- セッションタイプ(Livy / Spark Connect)は作成後に変更できません。
- Spark Connect セッションでは Statement API(RunStatement 等)は使えません。クライアントから直接やり取りします。
- Lake Formation によるきめ細かなアクセス制御(FGAC)は非対応で、フルテーブルアクセスのみです。実際、別途
SHOW DATABASESを試したところ、Lake Formation 管理下のカタログでは権限不足(Required Describe on default)でアクセスが拒否されました。Glue Data Catalog 上のテーブルを扱う場合は、セッションロールに対する Lake Formation の権限設計が必要であることを示しています。 - Spark Connect は AWS Glue Studio では利用できません。SageMaker Unified Studio のノートブックか、Python インタプリタを持つIDEから利用します。
SageMaker Unified Studio のノートブックから使う場合は、sagemaker-studio ライブラリの Spark ユーティリティを使うと、エンドポイントの取得や接続文字列の組み立てを意識せずに接続できます。
from sagemaker_studio import sparkutils
spark = sparkutils.init(connection_name="my-glue-spark-connection")
コスト面では、1回の検証(セッション作成→PySpark実行→削除)あたりの課金は、計測した例で DPUSeconds=331.892(約0.092 DPU時間)でした。東京リージョンの単価($0.44/DPU時間)換算で約 $0.04 程度です。インタラクティブセッションには分単位の最小課金がある点と、起動中は継続課金される点に注意し、使い終わったら削除する運用が安全です(料金単価はリージョンや時期により変動するため、最新は公式の料金ページでご確認ください)。
最後に
AWS Glue のインタラクティブセッションが Spark Connect に対応したことで、SageMaker Unified Studio のノートブックや手元のIDE・Pythonスクリプトから、サーバーレスな Glue Spark へ直接接続して対話的に PySpark を開発できるようになりました。今回は VS Code のノートブックから pyspark[connect] で接続し、DataFrame API・Spark SQL を実行できることを確認できました。
近年、Apache SparkはApache Icebergテーブルのサポートが充実してきており、テーブル作成の際にはSparkが必要となるケースが増えています。 Interactive Sessionの作成から、Spark SQLの実行、Sessionの削除までの一連の流れを、IaC(Infrastructure as Code)ではなく標準的なノートブックファイルで記述できるため、Gitを用いたコード管理に組み込みやすいという利点があります。
クラスタ管理を意識せず、普段の開発環境のまま Glue 上で段階的に PySpark ジョブを組み立てられるのは、本番ジョブ化前の試行錯誤フェーズで効いてきそうです。Glue Data Catalog 上のテーブルを扱う場合は Lake Formation の権限設計(およびFGAC非対応の制約)に留意しつつ、まずは手元の VS Code から接続して触ってみるのがおすすめです。










