
時系列基盤モデルを DGX Spark で動かして比べてみた
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
2025 年の秋から、時系列予測の基盤モデル(time-series foundation model)が立て続けにメジャー更新されました。Google の TimesFM 2.5、NVIDIA の NV-Tesseract(評価ライセンス段階)、AWS の Chronos-2 と、わずか 2 か月の間に 3 社の主力モデルが揃った形です。それぞれ需要予測や異常検知、製造業のセンサー監視など狙いどころが少しずつ違っていて、ベンチマークでもどれが頭一つ抜けているのか議論が続いている状況ですね。
本記事ではローカルで動かせる Chronos-2 と TimesFM 2.5 を実機ベンチして、現時点では DGX Cloud NIM 経由でしか触れない NV-Tesseract は公式情報と Cognite 社の事例を読み物として紹介する構成にしています。検証環境は手元の DGX Spark を使いました。
3 モデルの位置付けと比較表
3 モデルの開発元・配布形態・想定ユースをエコシステム単位で整理すると次のような形になります。AWS は SageMaker JumpStart と Bedrock Marketplace に乗せる形、Google は BigQuery の AI.FORECAST に乗せる形、NVIDIA は DGX Cloud の NIM として提供する形で、そのまま各社のプラットフォーム戦略が透けて見えていて面白いですね。
主要スペックを横に並べると、共通点と差異がはっきり見えます。
| 項目 | Chronos-2 | TimesFM 2.5 | NV-Tesseract |
|---|---|---|---|
| 提供元 | AWS(Amazon Science) | Google Research | NVIDIA |
| リリース | 2025-10-20 | 2025-09 | 2025(評価ライセンス) |
| アーキ | T5 encoder + Group Attention | Decoder-only + 量子化ヘッド | Transformer(詳細非公開) |
| パラメータ | 120M / 28M | 200M | 非公開 |
| Context 上限 | 8,192 | 16,384 | 非公開 |
| 多変量予測 | ネイティブ対応 | 対応 | 対応 |
| 異常検知 | -(予測中心) | AI.DETECT_ANOMALIES GA |
ネイティブ(NV-Tesseract-AD) |
| Fine-Tuning | 公開済み | 公開済み | NIM 経由のみ |
| ライセンス | Apache 2.0 | Apache 2.0 | 評価ライセンス |
| 入手性 | HF / GitHub | HF / JAX 版あり | DGX Cloud NIM のみ |
| 商用利用 | 可 | 可 | 評価期間中は条件付き |
Chronos-2 と TimesFM 2.5 はどちらも Apache 2.0 でローカル動作できる一方、NV-Tesseract は評価ライセンス段階で DGX Cloud NIM 経由でしか触れない、という入手性の差があります。一般公開時期は今のところアナウンスされていません。(2026年5月時点)
検証環境
両モデルとも Python ライブラリ呼び出しで完結します。依存バージョンが噛み合わないので、uv venv は別建てにしました。
| 項目 | 値 |
|---|---|
| ハードウェア | DGX Spark(NVIDIA GB10、aarch64、128GB UMA) |
| OS / ドライバ | Ubuntu 24.04 / NVIDIA driver 580.142 |
| Python | 3.13.13 |
| PyTorch | 2.12.0+cu130(両 venv 共通) |
| Chronos-2 用 | chronos-forecasting==2.2.2, transformers==4.57.6 |
| TimesFM 2.5 用 | timesfm==2.0.0(git head d720daa6), safetensors==0.7.0 |
Chronos-2 を試す
chronos-forecasting>=2.1.0(2.1.0 以降は過去値共変量のバグ修正版)を pip で入れるだけ。PyTorch は ARM64 + Blackwell GB10 のために cu130 wheel index を明示しています。
uv pip install --index-url https://download.pytorch.org/whl/cu130 \
--extra-index-url https://pypi.org/simple/ torch
uv pip install "chronos-forecasting>=2.1.0"
最小サンプルは次のような感じです。BaseChronosPipeline.from_pretrained から predict_quantiles まで一気通貫で、ロード後の 1 推論で 21 種類の quantile を返してくれます。
import numpy as np
import torch
from chronos import BaseChronosPipeline
pipeline = BaseChronosPipeline.from_pretrained(
"amazon/chronos-2", device_map="cuda", dtype=torch.bfloat16
)
# 入力は (n_series, n_variates, history_length) の 3D tensor
context = torch.tensor(np.arange(512, dtype=np.float32)[None, None, :])
quantiles_list, mean_list = pipeline.predict_quantiles(
context, prediction_length=96, quantile_levels=[0.1, 0.5, 0.9]
)
print(quantiles_list[0].shape) # torch.Size([1, 96, 3])
chronos-forecasting>=2.2 で predict_quantiles の引数名・入力 shape・戻り値が一新されているので、過去記事や公式 example のコピペが効きにくくなっている点だけ気をつけたいですね。
TimesFM 2.5 を試す
TimesFM 2.5 で 1 つだけ気をつけたいのは、PyPI で配布されている timesfm==1.3.0 に TimesFM 2.5 用 API がまだ含まれていない点です。Hugging Face のモデルカードでも「pip install from PyPI coming soon. At this point, please git clone」と明記されていて、現時点では GitHub HEAD から source install するしかありません。--no-deps で入れるので safetensors だけ別途指定します。
uv pip install --index-url https://download.pytorch.org/whl/cu130 \
--extra-index-url https://pypi.org/simple/ torch safetensors
uv pip install --force-reinstall --no-deps \
"timesfm @ git+https://github.com/google-research/timesfm.git"
最小サンプルはこちらです。ForecastConfig で context と horizon の上限を決めて compile し、その後 forecast で実際の予測長を渡すパターンになっています。
import numpy as np
import timesfm
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch"
)
model.compile(timesfm.ForecastConfig(
max_context=2048, max_horizon=256,
normalize_inputs=True, use_continuous_quantile_head=True,
fix_quantile_crossing=True,
))
point_forecast, quantile_forecast = model.forecast(
horizon=96, inputs=[np.arange(512, dtype=np.float32)],
)
print(point_forecast.shape) # (1, 96)
ベンチマーク結果
ここからは ETTh1(電力データセット)を題材に、3 モデルをレイテンシ・精度・メモリ効率の 3 軸から並べて評価していきます。
題材には ETTh1(Electricity Transformer Temperature、Hourly、7 変数、17,420 行)の OT 列(オイル温度)を使いました。これは中国の電力会社が配電用変圧器を 2 年間(2016 年 7 月〜2018 年 7 月)監視したデータセットで、変圧器内部の油温(OT)と 6 種類の負荷変数(高・中・低の有効/無効電力)から過熱事故の予兆を予測することを狙ったものです。製造業の設備監視データと構造が近く、Informer 論文(AAAI 2021 Best Paper)以降は時系列予測の標準ベンチマークとして使われてきました。
評価は末尾から step=24 で 64 個の rolling-window split を取って計測しました。指標は MASE(Mean Absolute Scaled Error)と RMSE、推論レイテンシは cold-warm 分離で warm 中央値、ピーク GPU メモリは torch.cuda.max_memory_allocated() で取っています。
短期予測(horizon=96、context=512)
| モデル | warm 中央値 | warm p95 | Peak GPU mem | MASE | RMSE |
|---|---|---|---|---|---|
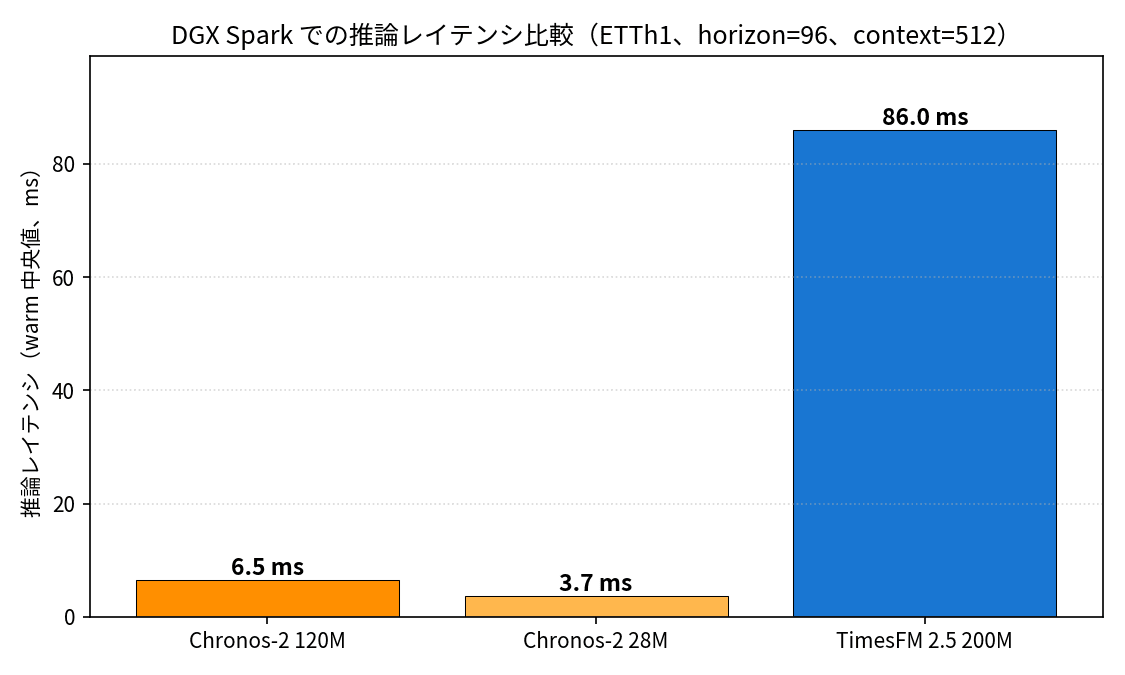
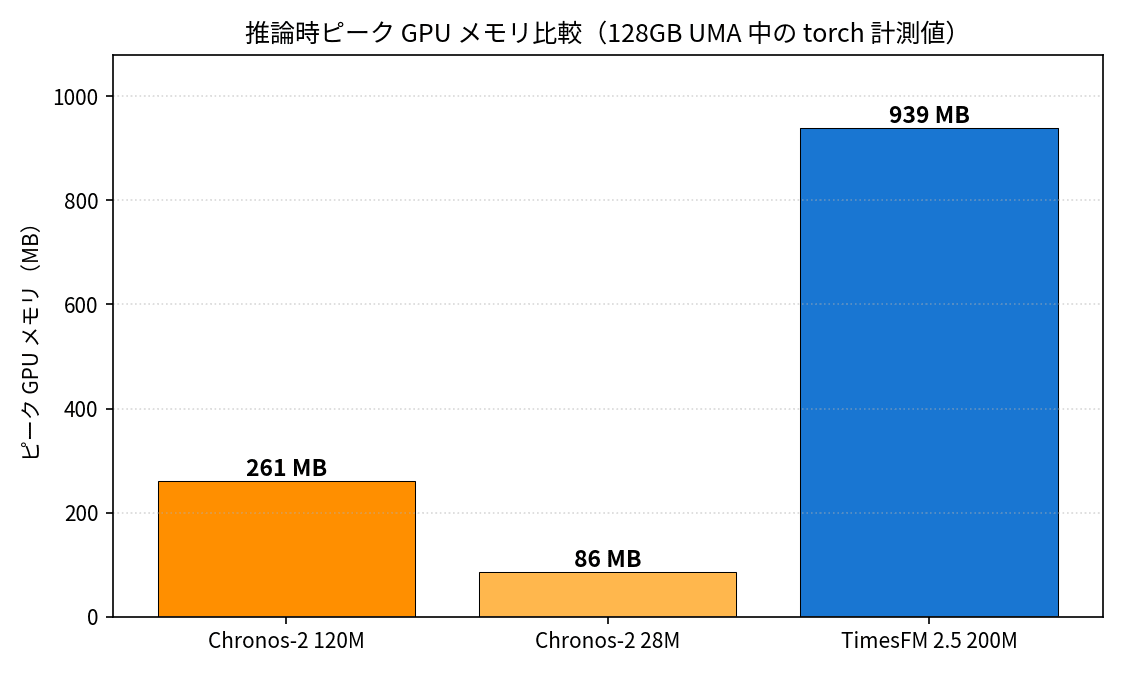
| Chronos-2 120M | 6.5 ms | 6.7 ms | 0.255 GB | 1.149 | 2.228 |
| Chronos-2 28M | 3.7 ms | 3.9 ms | 0.084 GB | 1.154 | 2.263 |
| TimesFM 2.5 200M | 86.0 ms | 89.3 ms | 0.917 GB | 1.106 | 2.169 |
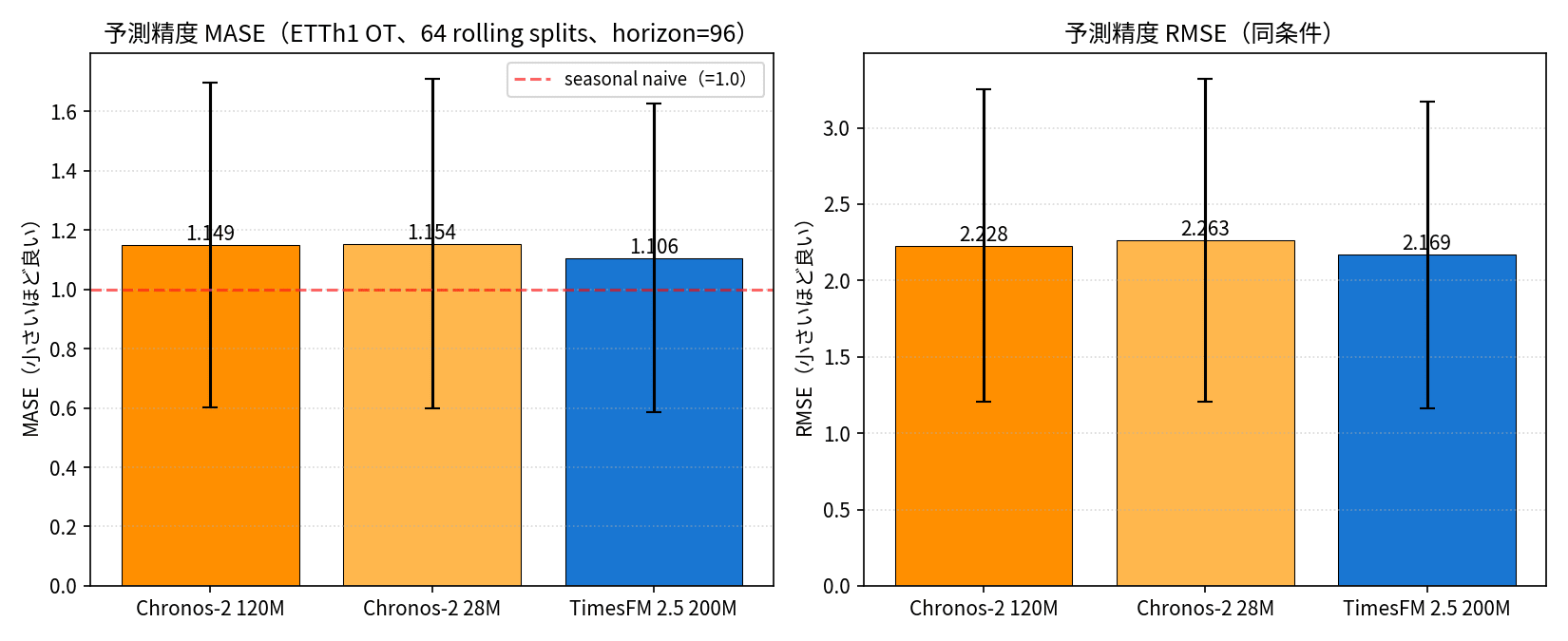
精度は TimesFM 2.5 が MASE / RMSE ともに最良で、3 モデル全部が seasonal naive(MASE=1.0、24 時間前と同じ値を返すだけのナイーブ予測)をわずかに上回る程度の差です。ETTh1 OT は強い日周期を持つので、ゼロショット基盤モデルといえども seasonal baseline はそれなりに手強い相手ですね。
レイテンシ差はかなり際立っていて、Chronos-2 28M (3.7ms) と Chronos-2 120M (6.5ms) は TimesFM 2.5 200M (86ms) より 13〜23 倍速い、という結果になりました。これは encoder-only で quantile を 1 forward pass で吐く Chronos-2 と、decoder-only で autoregressive 生成する TimesFM 2.5 の構造差がそのままレイテンシに出ています。
GPU メモリで見ると 28M は 120M の 1/3、TimesFM 2.5 の 1/11 で、それでいて精度はほぼ同等です。
horizon を伸ばすとどうなるか
予測対象を 96 時間(4 日)から 720 時間(30 日)まで伸ばして、レイテンシと精度がどう変わるかを見ました。
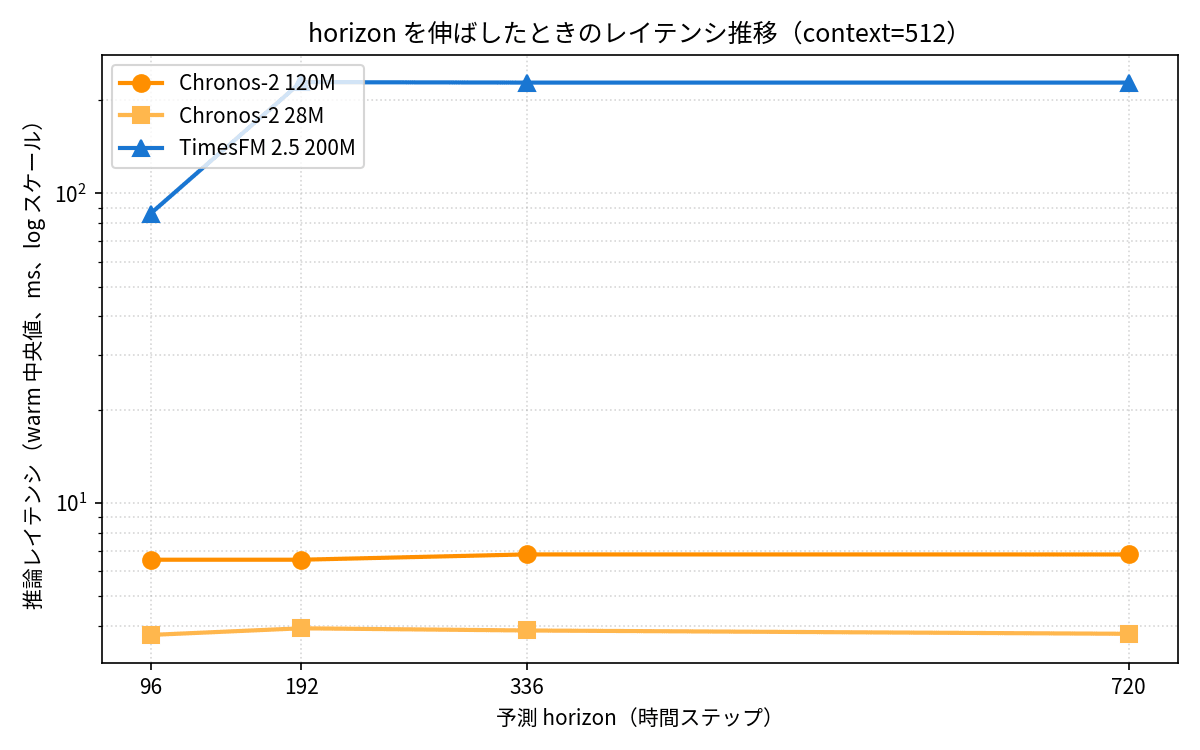
| horizon | Chronos-2 120M | Chronos-2 28M | TimesFM 2.5 200M |
|---|---|---|---|
| 96 | 6.5 ms / MASE 1.149 | 3.7 ms / MASE 1.154 | 86 ms / MASE 1.106 |
| 192 | 6.7 ms / 1.196 | 3.8 ms / 1.221 | 229 ms / 1.241 |
| 336 | 6.8 ms / 1.259 | 3.9 ms / 1.330 | 228 ms / 1.214 |
| 720 | 6.8 ms / 1.453 | 3.8 ms / 1.543 | 228 ms / 1.411 |
Chronos-2 のレイテンシは horizon=96 と horizon=720 でほぼ同じ(6.5ms → 6.8ms)で、地味にすごいですね。TimesFM 2.5 は h=96 → h=192 で 2.7 倍に増えて、それ以降は内部 horizon_len が頭打ちになって横ばい、という挙動でした。
精度はどのモデルも horizon を伸ばすと自然に劣化しますが、TimesFM 2.5 は h=720 でも MASE 1.411 で Chronos-2 120M(1.453)をわずかに上回っています。長期予測でも精度の優位を保てるのは TimesFM 2.5 の強みですね。
TimesFM 2.5 は context を伸ばすと精度が劇的に改善する
TimesFM 2.5 が「16K context」を打ち出している以上、context を伸ばしたときに本当に精度が改善するのかは試してみたい論点でした。Chronos-2 は context 上限が 8,192 なので、ここは TimesFM 2.5 単独で評価しています。
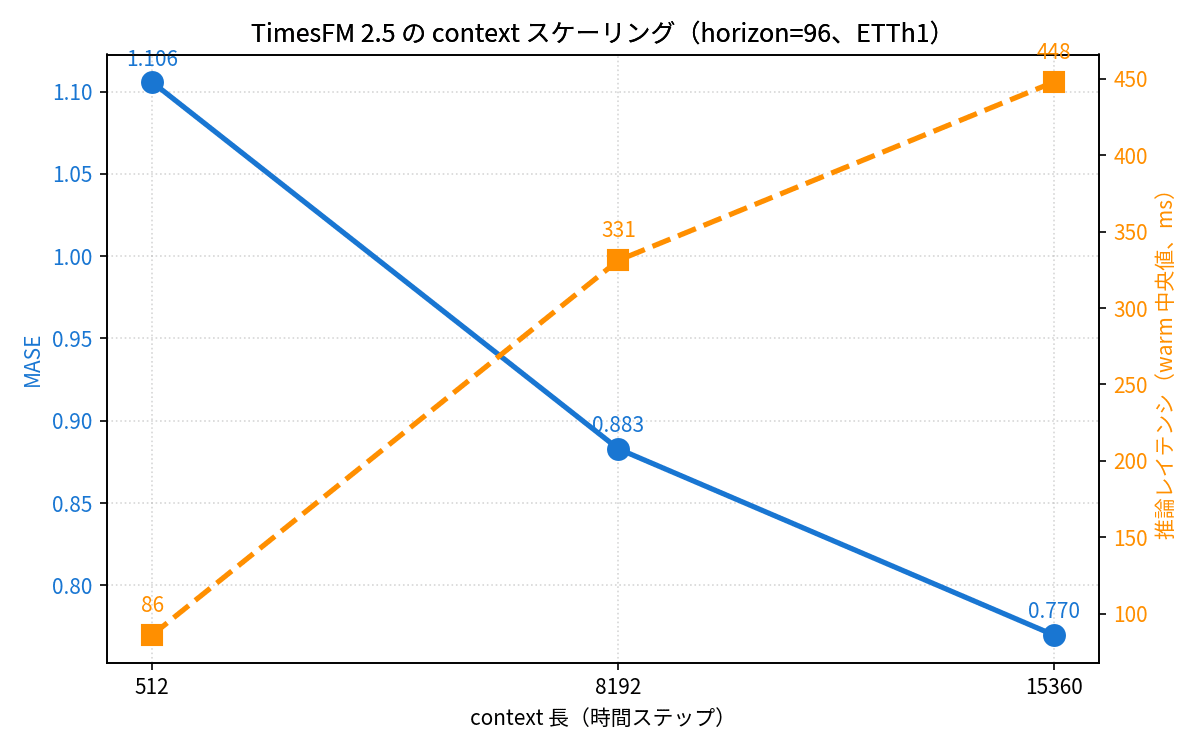
| context | warm 中央値 | Peak GPU | MASE | c=512 比 |
|---|---|---|---|---|
| 512 | 86.0 ms | 0.917 GB | 1.106 | baseline |
| 8,192 | 331.2 ms | 0.993 GB | 0.883 | 20% 改善 |
| 15,360 | 447.8 ms | 1.074 GB | 0.770 | 30% 改善 |
c=15,360 で MASE 0.770、これは seasonal naive を 23% 上回る精度です。「16K context」の効能が数値ではっきり出ていて、本当に長 context が活きるモデルだなと再認識しました。注意したいのは context をモデル上限の 16,384 まで使い切ることはできない点で、max_context + max_horizon ≤ 16384 という architecture 制約があるので、horizon=1024 を確保すると実用上限は context=15,360 までです。
多変量予測でも見てみた
ETTh1 は OT 以外に HUFL / HULL / MUFL / MULL / LUFL / LULL の 6 種類の電力 Load 列を持っているので、Chronos-2 で 7 変数を multivariate で同時予測すると OT 単独精度がどう変わるかを試しました。
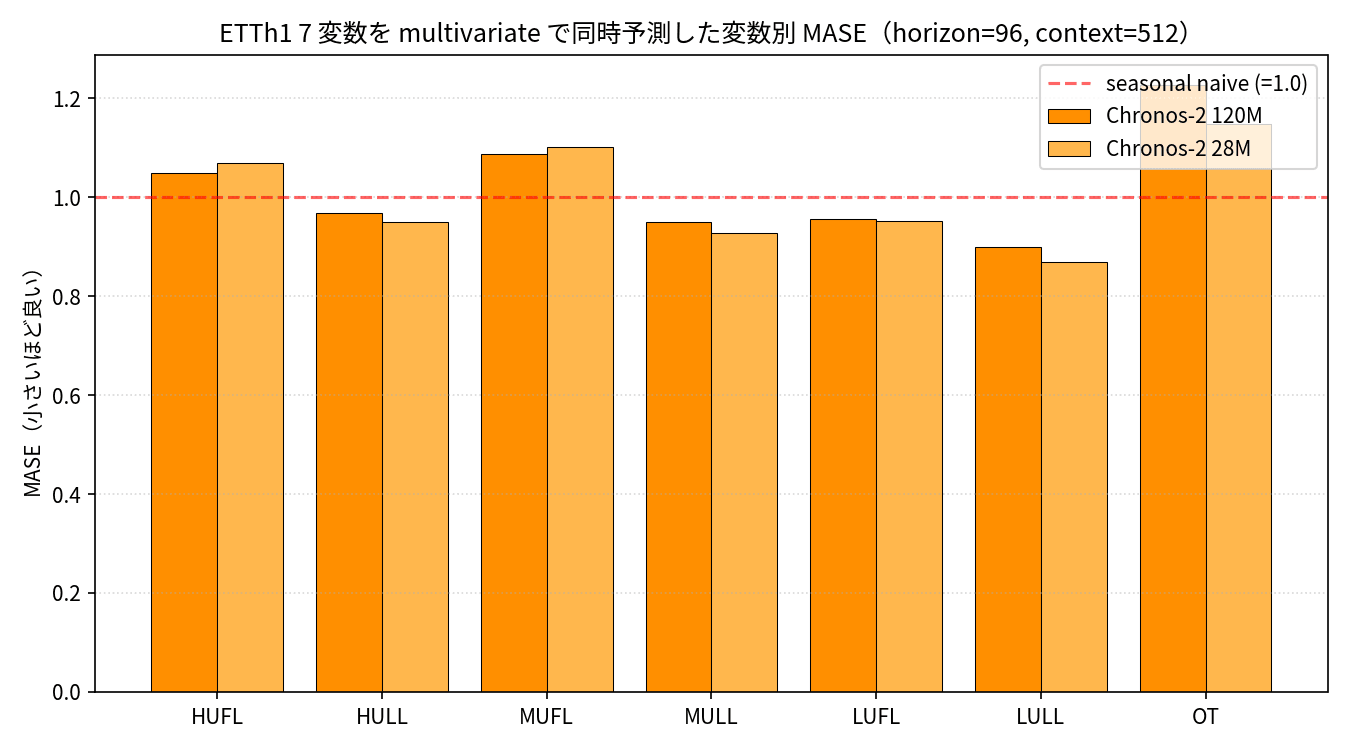
結果として、Chronos-2 120M で OT 精度を見ると単変量の MASE 1.149 から多変量内では 1.226 へ 7% 悪化していました。一方で他の 6 変数は MASE 0.87〜1.09 で良好に予測できていて、特に LULL は 0.90 と seasonal naive を 10% 上回っています。
おそらく「target と相関の弱い covariate を混ぜると逆効果になることがある」という、機械学習でよく言われる現象がそのまま出ていますね。Chronos-2 28M で同じことを試すと OT MASE が 1.149 でほぼ変わらず、こちらは「複数指標を 1 forward pass で全部返す」効率を活かしてダッシュボード用途には向きそうな印象です。
別ドメインでも順位は保たれるか
ETTh1(電力データ)で出した順位が他ドメインでも保たれるのか、UCI Air Quality dataset の T 列(ローマの室温)でも同条件で計測してみました。
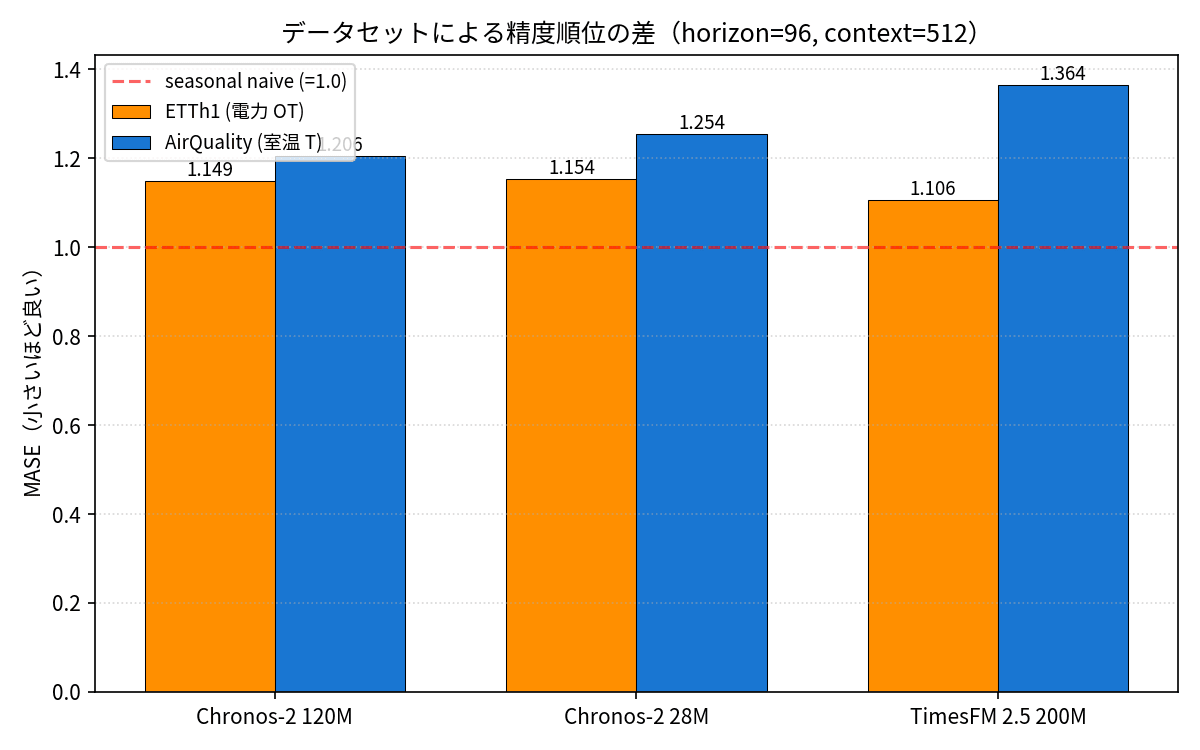
| Dataset | 1 位 | 2 位 | 3 位 |
|---|---|---|---|
| ETTh1(電力 OT) | TimesFM 2.5 (1.106) | Chronos-2 120M (1.149) | Chronos-2 28M (1.154) |
| AirQuality(室温 T) | Chronos-2 120M (1.206) | Chronos-2 28M (1.254) | TimesFM 2.5 (1.364) |
順位が逆転しました。AirQuality は ETTh1 より時系列としてノイズが多く、ETTh1 ほど強い日周期がない(昼夜差はあるが季節変動も大きい)ためか、短 context (c=512) では TimesFM 2.5 の長 context の強みが活きていないようです。「TimesFM 2.5 がいつも最良」とは言えない結果で、本番ドメインで実際に比較するのは大事だなと再認識しました。
異常検知シミュレーション
NV-Tesseract が異常検知に強いと聞くと、Chronos-2 / TimesFM 2.5 の予測ベース異常検知はどの程度使えるのか気になりますね。ETTh1 の test 区間にスパイク・レベルシフト・ノイズバーストの 3 種類の異常を人工注入して、予測残差の絶対値を異常スコアとして per-step ROC AUC を計算しました。
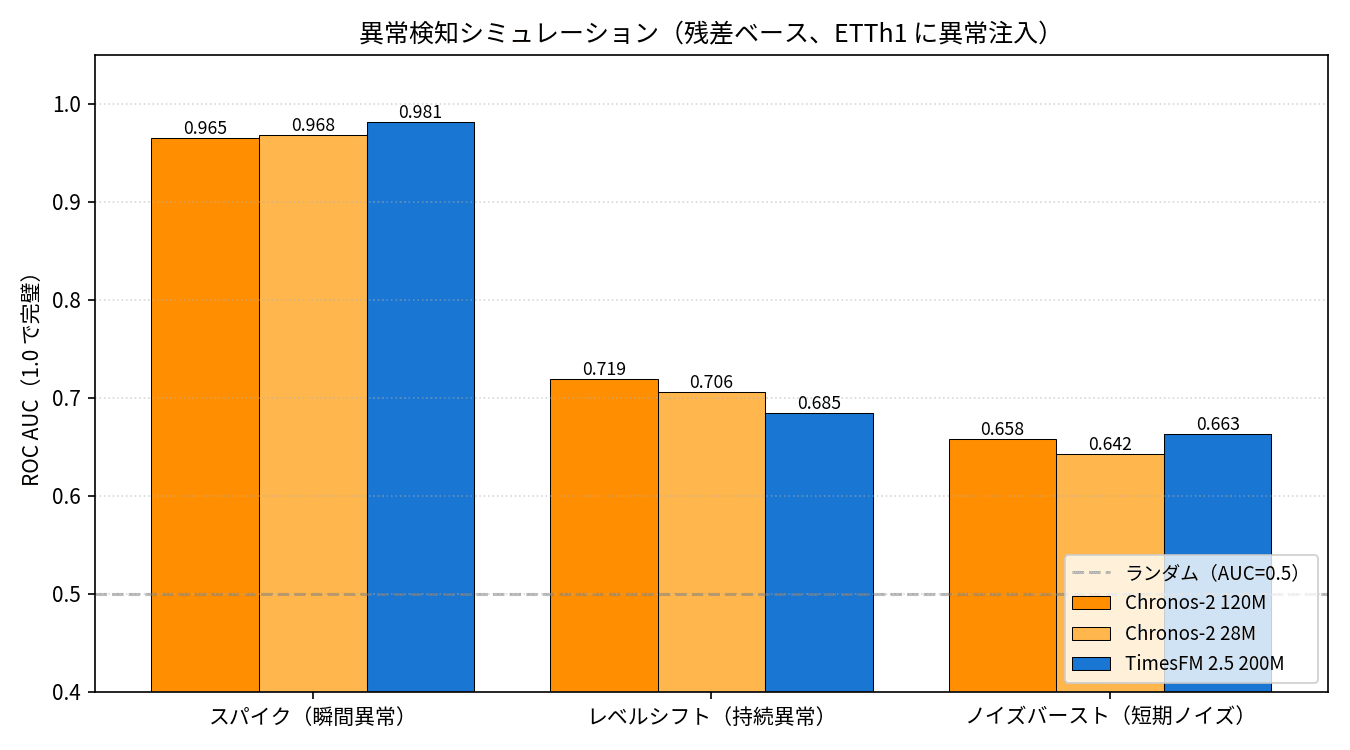
| Pattern | Chronos-2 120M | Chronos-2 28M | TimesFM 2.5 200M |
|---|---|---|---|
| スパイク(瞬間異常) | 0.965 | 0.968 | 0.981 |
| レベルシフト(持続異常) | 0.719 | 0.706 | 0.685 |
| ノイズバースト(短期) | 0.658 | 0.642 | 0.663 |
スパイクは 3 モデルとも AUC 0.96 以上で、瞬間的な外れ値はほぼ確実に拾えています。下のチャートが定性例で、注入したスパイク(赤丸)でだけ予測残差が大きく跳ねていて、視覚的にも分かりやすいですね。
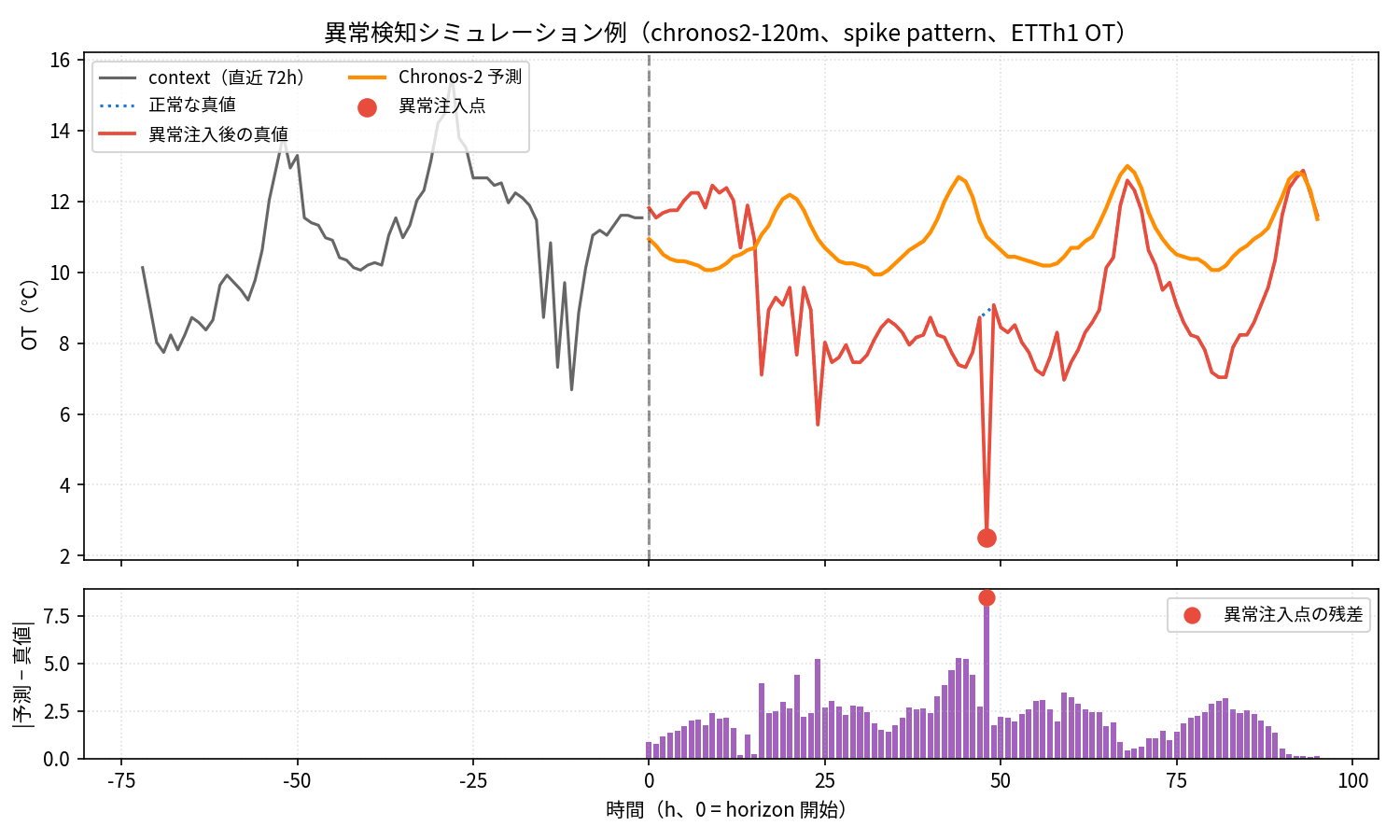
レベルシフトは AUC 0.69〜0.72 で中程度。設備の段階的なドリフトに当たるような異常はそれなりに検出できる、というレベルです。ノイズバーストは AUC 0.64〜0.67 と低めで、短期高周波のノイズは予測 FM だけだと見逃しやすそうです。NV-Tesseract のような専用異常検知モデルはこのあたりが本領になるはずで、公開後に改めて比較してみたいところですね。
NV-Tesseract
公式の NVIDIA Developer Blog(New NVIDIA NV-Tesseract Time-Series Models と Advancing Anomaly Detection for Industry Applications)によれば、NV-Tesseract は予測・異常検知・分類の 3 タスクに対応した Transformer ベースのモデルです。とくに異常検知(NV-Tesseract-AD)は segmented / multi-scale adaptive thresholding と呼ぶ機構で、産業用センサーの細かな外れ値検出を狙った設計になっているようです。
製造業の実事例として印象的なのが、GTC 2026 の初日(2026 年 3 月 16 日)に合わせて発表された Cognite 社との提携です。テキサス州 Clear Lake にある Celanese の化学工場で、反応槽の水位センサーから状態予測を NV-Tesseract NIM で動かしている事例が公開されています。Celanese 側の課題感は「手動サンプリングが入るたびに従来の予測モデルが bias jumps(バイアスの段差)を起こして連続運用が崩れていた」というもので、NV-Tesseract のリアルタイム予測でこのギャップを埋める狙いがあるそうです。
提供形態として面白いのは、Cognite の Industrial Knowledge Graph(設備・センサー・運用知識のグラフ DB)に NV-Tesseract NIM を接続する形で、データの文脈とモデルがセットで提供されるパッケージになっている点です。対象セクターは化学だけでなくエネルギー、製造業、電力と再生可能エネルギー、重工業まで広げて謳っていて、産業 OT データのプラットフォーマー側を窓口にして産業ライン全体の最適化に投入される方向が透けて見えますね。VSS や Cosmos のような映像系基盤モデルと組み合わせると、「センサー時系列+映像」の両軸で工場の可視化が進みそうな気配です。
ローカル DGX Spark や Jetson で動かせるようになる時期は今のところ未定のようですが、楽しみですね。
エコシステムと運用面の比較
章 6 のベンチ結果はなぜこうなったのでしょうか。3 モデルの内部構造を並べてみると、設計思想の差がそのまま運用特性に出ていることが見えてきます。
Chronos-2 は encoder + quantile head の 1 forward pass で全 horizon を一括出力するので、horizon を伸ばしてもレイテンシが伸びにくい。TimesFM 2.5 は decoder で autoregressive にパッチ単位を生成していくので、horizon が伸びるほどレイテンシが伸びるが、その代わり長 context を活かせる、という設計になっています。
ユースケース別のおすすめは次のような形でしょうか。
| 想定ユース | 向きそうな選択肢 |
|---|---|
| AWS 中心の需要予測(共変量豊富) | Chronos-2 + SageMaker JumpStart / Bedrock Marketplace |
| GoogleCloud のデータレイク上で SQL 一発予測 | TimesFM 2.5 + BigQuery AI.FORECAST |
| IoT センサーの異常検知(高精度要件) | NV-Tesseract |
| エッジ寄りで軽量に動かしたい | Chronos-2 28M |
| 長期トレンド予測(数千ステップ) | TimesFM 2.5(long context モード) |
| 短期予測を大量に並列処理 | Chronos-2 120M |
| 金融など確率予測重視 | Chronos-2 |
実プロジェクトでの応用検討
実際に関わっているプロジェクトで考えているのは、PLC(製造現場のセンサーや設定値を制御する産業用コントローラ)から取得したリアルタイムデータを時系列モデルに流して、「今の運転条件で従来通りの製品ができそうか」「設定値が変わって失敗に向かう兆候が出ていないか」を逐次判定する使い方です。設定値を future covariate として渡せば品質指標の未来値が予測できますし、予測残差を見れば異常スコアにもなります。本記事のベンチで Chronos-2 28M は warm 3.7ms と PLC スキャンサイクル(100ms〜1 秒)に余裕で間に合うので、エッジ寄りの構成でリアルタイム連携が現実的に組めそうですね。前段で触れた Cognite × Celanese の事例もまさに同じ構図で、OT 系プラットフォーマーと NIM をつなぐ形でこれを実装しています。実機の PLC データを流す技術検証は改めて別記事で扱いたいと考えています。
実装で気をつけたい点
時系列モデル自体ではなく、ライブラリ側の過渡期事情で詰まりやすかったポイントを 2 つだけ。
Chronos-2 の predict_quantiles API が 2.2 系で一新されているので、過去記事や公式 example のコピペがそのままだと動きません。引数は inputs=tensor、入力は 3 次元 (n_series, n_variates, history_length) 必須(univariate でも tensor[None, None, :])、戻り値は tuple[list[Tensor], list[Tensor]] で quantiles_list[0] の shape は (n_variates, horizon, num_quantiles) です。
TimesFM 2.5 の context 上限は実質 15,360 までです。max_context + max_horizon ≤ 16384 のアーキ制約があるので、horizon=1024 を確保すると context は 15,360 までしか取れません。本記事の長 context 検証も c=15,360 で計測しています。
まとめ
今回は 2025 年秋から続いている時系列基盤モデルのメジャー更新を整理して、AWS Chronos-2 / Google TimesFM 2.5 を実機ベンチし、NV-Tesseract は公式情報と Cognite 事例ベースで紹介する構成にしました。
ざっくり言うと、レイテンシ重視で大量並列処理なら Chronos-2、長 context で精度を稼ぎたいなら TimesFM 2.5、製造業の異常検知に専用モデルを使いたいなら NV-Tesseract、という棲み分けかなと思っています。Chronos-2 28M はメモリも推論時間も軽量で精度はほぼ 120M 並み、エッジに近い場所にデプロイする選択肢としても面白い存在ですね。
参考リンク
Chronos-2
- Amazon Science Blog - Introducing Chronos-2
- GitHub - amazon-science/chronos-forecasting
- arXiv 2510.15821 - Chronos-2: From Univariate to Universal Forecasting
TimesFM 2.5
- HuggingFace - google/timesfm-2.5-200m-pytorch
- GitHub - google-research/timesfm
- BigQuery AI.FORECAST documentation
NV-Tesseract
- NVIDIA Developer Blog - NV-Tesseract Time-Series Models
- NVIDIA Developer Blog - NV-Tesseract-AD for Industry Applications
- Cognite × NVIDIA Partnership










