Gemma 4 31B + S3 Vectors + AgentCore で低コストな RAG を構築してみた
はじめに
こんにちは、駐車が上手くなりたいコンサル部の神野です。
先日、suzuki.ryoさんが Gemma 4 31B の日本語性能と料金について記事を書いていました。
この記事にもある通り、Gemma 4 31B のトークン単価は入力 $0.14 / 1M tokens、出力 $0.40 / 1M tokens で、他のモデルと比較するとこんな感じです。
| モデル | 入力 (/ 1M tokens) | 出力 (/ 1M tokens) | Gemma 4 31B 比 |
|---|---|---|---|
| Gemma 4 31B | $0.14 | $0.40 | 1x |
| Claude Haiku 4.5 | $0.80 | $4.00 | 5.7〜10x |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 21〜37x |
| Claude Opus 4.8 | $5.00 | $25.00 | 35〜62x |
Gemma4 めちゃくちゃ安いですね・・・!!
そこそこ日本語が使えて、ツールコールもできるなら、AI エージェントとして RAG を組んだら面白いんじゃないか? と思い、Amazon Bedrock AgentCore + S3 Vectors を使って RAG を構築してみました。
せっかく LLM が安いなら、ベクトルストアも安くしたいですよね。S3 Vectors はストレージ課金と Query API 課金に加えてクエリ時に処理されるベクトル量に応じた料金が発生しますが、少量ドキュメントならかなりお安く済みます。Gemma 4 31B + S3 Vectors で、RAGってなんだか高そう・・・試しづらい・・・を払拭すべくテンプレートを作りました。今回のリポジトリはこちらです。
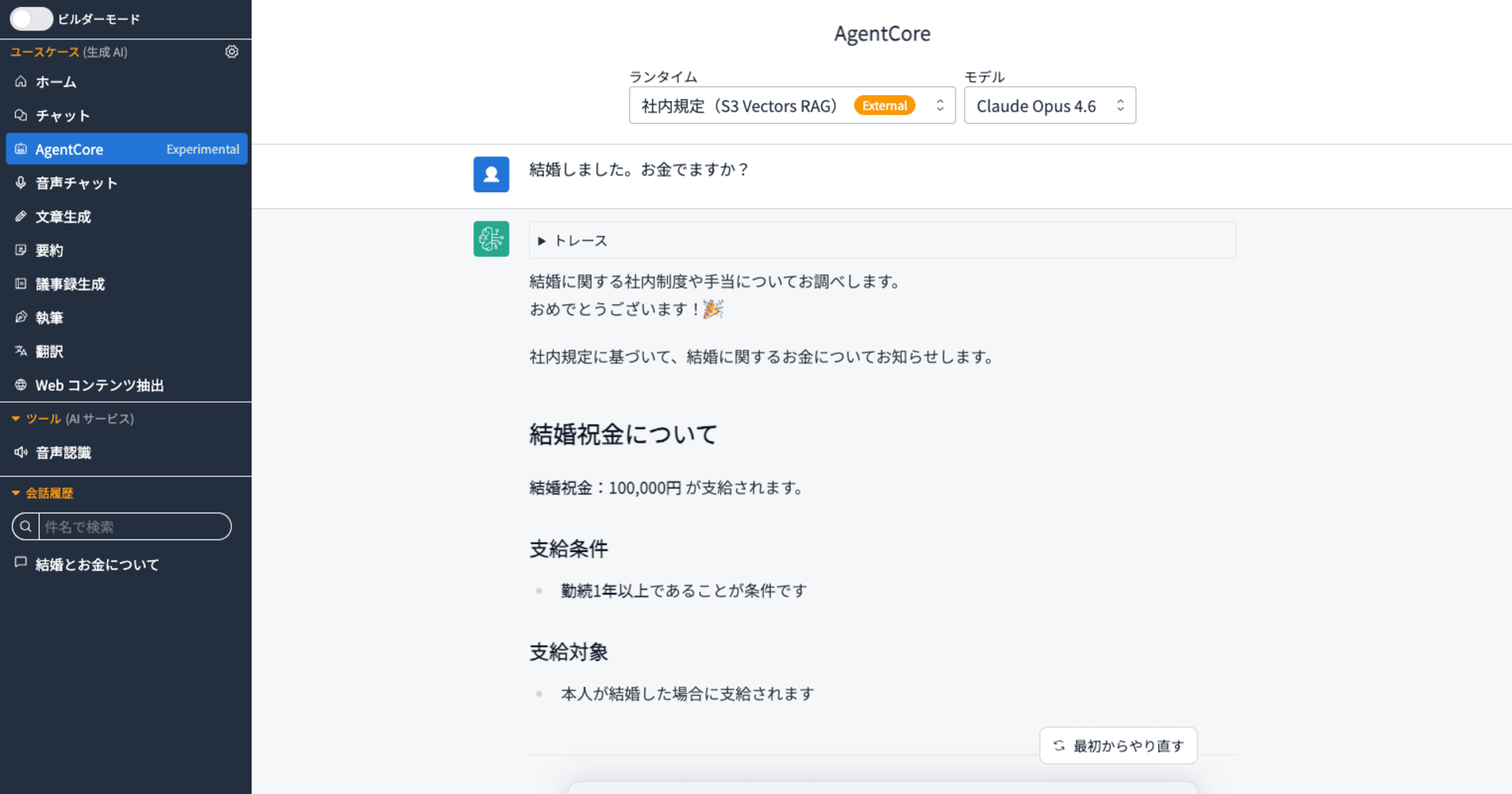
実際の動作はこんな感じです。
AIと協力しながら作りましたが良き感じに仕上がりました。
これを使ってみてRAGをためそう!と思っていただけると嬉しいです。まずは試すのが何よりも大事ですからね。
この記事では構成や実装の要所を紹介していきます。コード全体や細かい実装はリポジトリを参照してください。
前提
今回使った環境は下記の通りです。
- Node.js v24.16.0
- Python v3.13.11
- AWS CLI
- Docker(AgentCore Runtime のコンテナビルドに使用)
- bedrock-mantle で Gemma 4 31B を利用できること(2026-06-14 時点で us-east-1 等が利用可能、東京リージョンは使用できませんので注意です)
構成
Amplifyをフロントエンドに採用し、AgentCoreを中心としたアーキテクチャで構成しています。
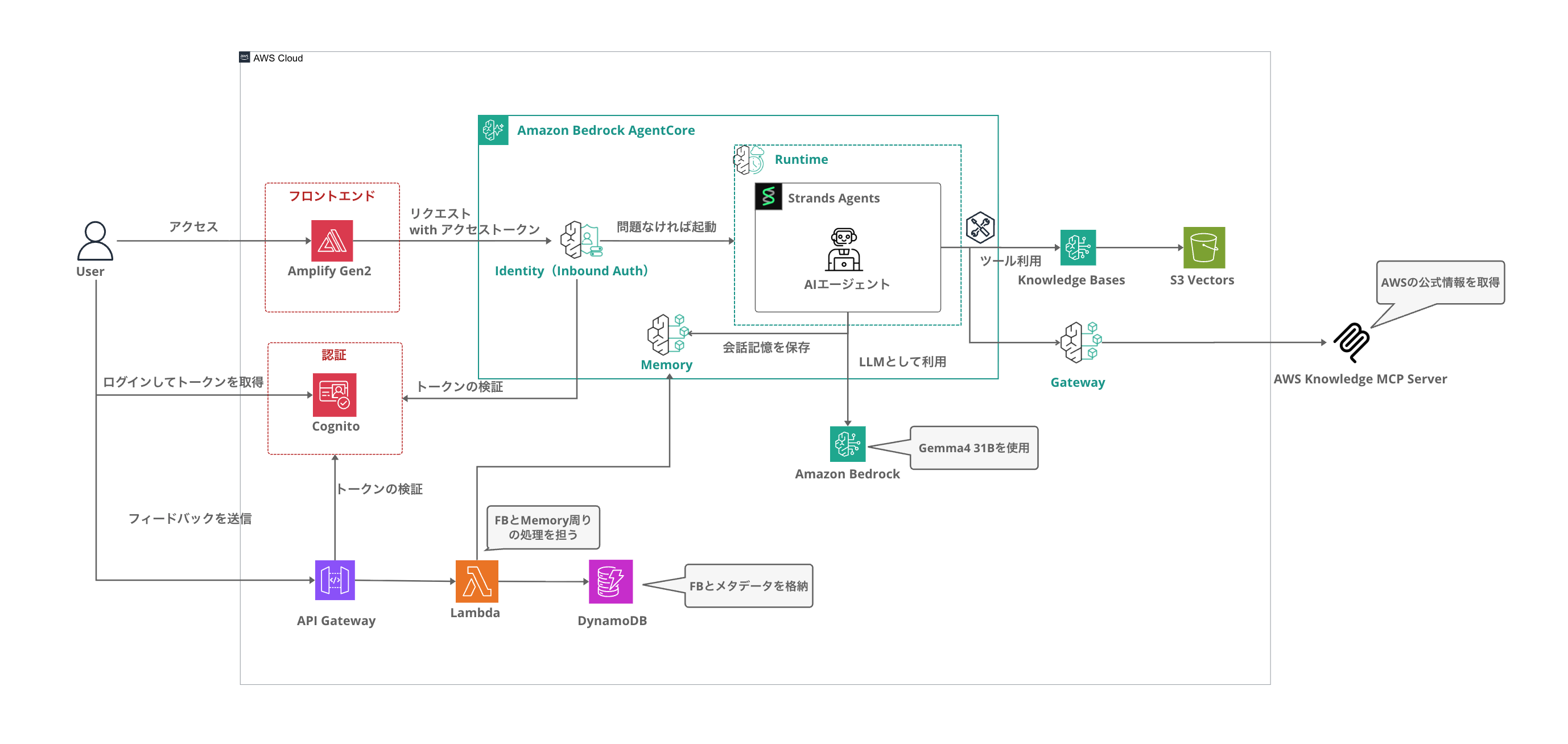
| 要素 | 技術 |
|---|---|
| LLM | Gemma 4 31B(bedrock-mantle の OpenAI 互換 API 経由) |
| エージェント | Strands Agents SDK |
| ナレッジベース | Bedrock Knowledge Bases + S3 データソース |
| ベクトルストア | S3 Vectors(Titan Embedding v2, 1024 dim, cosine) |
| 会話メモリ | AgentCore Memory |
| エージェント実行環境 | AgentCore Runtime |
| MCP Gateway(オプション) | AgentCore Gateway + AWS Knowledge MCP Server |
| 認証 | Cognito |
| 履歴 API | API Gateway REST API + Cognito User Pool Authorizer + Lambda + AgentCore Memory + DynamoDB |
| フィードバック | API Gateway REST API + Cognito User Pool Authorizer + Lambda + DynamoDB |
| フロントエンド | React + Vite + Tailwind CSS v4 |
| IaC | Amplify Gen 2 + CDK |
できることとしてはざっと下記の通りです。チャットで検索するのに最低限必要な機能を実装しています。
- チャット形式でナレッジベースを検索・回答
- カテゴリ(人事・経理・セキュリティ・開発・運用)で検索対象を絞り込み
- AgentCore Memory による会話履歴の保持
- Gateway 経由で AWS 公式ドキュメントも MCP ツールとして検索(オプション)
- 回答に対するフィードバック(いいね / 改善 / コメント)を DynamoDB に記録
- LLM-as-a-Judge による回答品質の評価スクリプト(15問テストセット付き)
デプロイ
リポジトリをクローンして npm install → npx ampx sandbox --once で、以下のリソースがまとめて作成されます。
- Cognito(認証)
- Bedrock Knowledge Base + S3 Vectors
- S3 へのサンプルドキュメントアップロードと KB 同期
- AgentCore Runtime(Gemma 4 31B エージェント)
- AgentCore Memory
- 会話履歴取得用 REST API + Lambda + DynamoDB
- フィードバック用 REST API + Lambda + DynamoDB
git clone https://github.com/yuu551/gemma4-31b-agentcore-sample.git
cd gemma4-31b-agentcore-sample
npm install
npx ampx sandbox --once
デプロイが完了すると amplify_outputs.json が生成されます。フロントエンドはこのファイルから Runtime ARN や Memory ID を自動的に読み取るので、環境変数の設定は不要です。
npm run dev
ブラウザで開くと Cognito の認証画面が表示されます。サインアップ後、チャット画面からナレッジ検索を試せます。
AgentCore Gateway を有効にしたい場合は、環境変数を付けてデプロイします。
ENABLE_GATEWAY=true npx ampx sandbox --once
有効/無効は amplify/parameters.ts で管理しています。
sandboxコマンドで、フロントはローカルでホストしていますが、実際にAmplifyにホストすることもできるので詳しくはGitHubのReadmeをご参照ください。
S3 Vectorsの採用理由
RAG のベクトルストアとしてよくある選択肢と比較してみます。
| ベクトルストア | 最低月額 | 課金モデル |
|---|---|---|
| OpenSearch Serverless(Classic) | $350〜 | OCU 時間課金(最低 2 OCU) |
| S3 Vectors | $0〜 | 完全従量課金 |
Knowledge Basesに対応している OpenSearch Serverless (Classic、NextGenではないです)では最低 OCU 分の時間課金が発生し、検証用途では月数百ドル規模になりやすいです。S3 Vectors は使った分だけ課金なので、ドキュメント数が少ない PoC や社内ツールにはぴったりです。ただハイブリッド検索ができない、OpenSearchに比べてレイテンシーが発生するなどは理解する必要がありますが、まずサクッと試す段階ならそこまで神経質にならなくても良いです。
今回は S3 Vectors を Bedrock Knowledge Bases のバックエンドとして使っています。Retrieve API 経由でクエリするので、ドキュメント同期してベクトル変換などマネージド機能を活用しつつ、ベクトルストアのコストは S3 Vectors の従量課金に抑えられます。
Knowledge Base + S3 Vectors を CDK で構築する
CDK では L1 コンストラクトで S3 Vectors と Knowledge Base を構築しています。CfnVectorBucket / CfnIndex でベクトルストアを作り、CfnKnowledgeBase の storageConfiguration で S3_VECTORS を指定して紐づけます。
import * as s3vectors from "aws-cdk-lib/aws-s3vectors";
import * as bedrock from "aws-cdk-lib/aws-bedrock";
const vectorBucket = new s3vectors.CfnVectorBucket(ragStack, "VectorBucket", {});
const vectorIndex = new s3vectors.CfnIndex(ragStack, "VectorIndex", {
vectorBucketArn: vectorBucket.attrVectorBucketArn,
indexName: "company-docs",
dataType: "float32",
dimension: 1024,
distanceMetric: "cosine",
metadataConfiguration: {
nonFilterableMetadataKeys: [
"AMAZON_BEDROCK_TEXT", "AMAZON_BEDROCK_METADATA",
"x-amz-bedrock-kb-source-uri", "x-amz-bedrock-kb-chunk-id",
"x-amz-bedrock-kb-data-source-id",
],
},
});
const kb = new bedrock.CfnKnowledgeBase(ragStack, "KnowledgeBase", {
name: "agentic-rag-kb",
roleArn: kbRole.roleArn,
knowledgeBaseConfiguration: {
type: "VECTOR",
vectorKnowledgeBaseConfiguration: {
embeddingModelArn: `arn:aws:bedrock:${cdk.Aws.REGION}::foundation-model/amazon.titan-embed-text-v2:0`,
},
},
storageConfiguration: {
type: "S3_VECTORS",
s3VectorsConfiguration: {
vectorBucketArn: vectorBucket.attrVectorBucketArn,
indexName: "company-docs",
},
},
});
storageConfiguration の type に S3_VECTORS を指定し、s3VectorsConfiguration で VectorBucket と Index を紐づけています。S3 データソースから KB への取り込みは、CDK のカスタムリソースでデプロイ時に自動でドキュメント取り込みジョブを実行するようにしています。
metadataConfiguration の nonFilterableMetadataKeys には、Knowledge Bases が内部的に使うメタデータキーを指定しています。S3 Vectors のメタデータにはサイズ上限があり、これらのキーをフィルタ可能として登録しようとすると上限を超えてドキュメント取り込みがエラーになります。フィルタに使わないメタデータキーは nonFilterableMetadataKeys に入れておく必要があるので注意です。
Gemma 4 31B を Strands Agentで動かす
Gemma 4 31B は bedrock-mantle の OpenAI 互換 API 経由で呼び出します。
Strands Agents SDK の OpenAIResponsesModel を使えば、ツール実行できるエージェントとして動きます。
from strands import Agent, tool
from strands.models.openai_responses import OpenAIResponsesModel
from aws_bedrock_token_generator import provide_token
BASE_URL = f"https://bedrock-mantle.{REGION}.api.aws/openai/v1"
model = OpenAIResponsesModel(
model_id="google.gemma-4-31b",
client_args={
"api_key": provide_token(region=REGION),
"base_url": BASE_URL,
},
)
agent = Agent(
model=model,
tools=[knowledge_search, list_categories],
system_prompt=SYSTEM_PROMPT,
)
bedrock-mantle は通常の Bedrock(Converse API)とはエンドポイントが異なり、aws-bedrock-token-generatorでベアラートークンを取得して渡す形になります。aws-bedrock-token-generator は AWS の認証情報から bedrock-mantle 用の短期トークンを生成してくれるライブラリで、provide_token(region=REGION) を呼ぶだけで使えます。
Strands から bedrock-mantle を呼び出す方法は下記の記事でも紹介されていて参考になります!
エージェントの検索ツール
エージェントのツールとして、Bedrock Knowledge Bases の Retrieve API を呼び出す検索を実装しています。
@tool
def knowledge_search(query: str, category: str = "") -> str:
"""社内ドキュメントをナレッジベースから検索します。"""
kwargs = {
"knowledgeBaseId": KNOWLEDGE_BASE_ID,
"retrievalQuery": {"text": query},
"retrievalConfiguration": {
"vectorSearchConfiguration": {"numberOfResults": 5}
},
}
if category and category in CATEGORIES:
kwargs["retrievalConfiguration"]["vectorSearchConfiguration"]["filter"] = {
"equals": {"key": "category", "value": category}
}
response = bedrock_agent.retrieve(**kwargs)
# 結果を整形して返す
S3 Vectors を直接クエリするのではなく、Knowledge Bases の Retrieve API 経由で検索しています。Embedding 変換は Knowledge Bases 側が自動でやってくれるので、エージェント側ではクエリ文字列を渡すだけです。メタデータフィルタリングにも対応しているので、カテゴリ(人事・経理・セキュリティ・開発・運用)で検索対象を絞り込みたい場合は実現可能です。
SPAから AgentCore Runtime にリクエスト
AgentCore Runtime は JWT認証に対応しているので、フロントエンドから直接呼び出せます。
const runtime = new agentcore.Runtime(ragStack, "AgenticRagRuntime", {
runtimeName: "agentic_rag_gemma4",
agentRuntimeArtifact: agentArtifact,
authorizerConfiguration: agentcore.RuntimeAuthorizerConfiguration.usingCognito(
backend.auth.resources.userPool,
[backend.auth.resources.userPoolClient],
),
});
Runtime の authorizerConfiguration に Cognito を指定するだけで、フロントエンドからは Authorization: Bearer <accessToken> でリクエストを送れます。
const session = await fetchAuthSession();
const accessToken = session.tokens?.accessToken?.toString();
const response = await fetch(
`https://bedrock-agentcore.${REGION}.amazonaws.com/runtimes/${runtimeArn}/invocations?qualifier=DEFAULT`,
{
method: "POST",
headers: {
Authorization: `Bearer ${accessToken}`,
"Content-Type": "application/json",
Accept: "text/event-stream",
"X-Amzn-Bedrock-AgentCore-Runtime-Session-Id": sessionId,
},
body: JSON.stringify({ prompt, sessionId, userId }),
},
);
Runtime ARN は amplify_outputs.json から読み取れます。CDK 側で backend.addOutput({ custom: { runtime_arn: runtime.agentRuntimeArn } }) として出力しておけば、フロントエンドでインポートするだけです。
フロントエンド
Amplify Gen 2 は CDK ベースなので、Cognito の設定も amplify/auth/resource.ts に数行書くだけです。フロントエンド側は @aws-amplify/ui-react の Authenticator コンポーネントでアプリ全体をラップするだけで、サインアップ・ログイン・トークン管理が完成します。
import { Authenticator } from "@aws-amplify/ui-react";
function App() {
return (
<Authenticator>
{({ user }) => <ChatApp user={user} />}
</Authenticator>
);
}
検証フェーズで認証付きの画面がこのように簡単に作れるのはありがたいですね。
チャットの回答表示には Streamdown を使っています。
Streamdown は SSE で流れてくるマークダウンをリアルタイムにレンダリングしてくれるライブラリで、ストリーミング中のちらつきやレイアウトジャンプを抑えてくれます。コードブロックのシンタックスハイライトにも対応していて、導入もシンプルでした。
<Streamdown isAnimating={!!message.isStreaming}>
{processedContent}
</Streamdown>
フロントエンドの実装詳細はリポジトリの src/ 配下を参照してください。
AgentCore Memory で会話履歴を保持する
AgentCore Memory と Strands を連携させて、セッション間で会話履歴を保持しています。
from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfig
from bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager
config = AgentCoreMemoryConfig(
memory_id=MEMORY_ID,
actor_id=user_id,
session_id=session_id,
)
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=config,
region_name=REGION,
)
agent = Agent(
model=model,
tools=tools,
system_prompt=SYSTEM_PROMPT,
session_manager=session_manager,
)
Strands の session_manager に AgentCoreMemorySessionManager を渡すだけで、会話の保存・復元が自動化されます。ユーザーごと・セッションごとに会話が分離されるので、マルチユーザー環境でも安心ですね。
履歴一覧の管理
会話本文は AgentCore Memory に保存し、履歴の復元時は API Gateway + Cognito User Pool Authorizer + Lambda 経由で ListEvents API を呼び出しています。JWT の sub クレームを actor_id として使う構成にしました。これにより、ログイン中のユーザー自身の履歴しか表示されません。
また、サイドバーに表示するセッションタイトルや最終更新時刻は DynamoDB にメタデータとして保存しています。会話の送信後にタイトルや最終メッセージを更新し、サイドバーではこのメタデータを参照します。
AgentCore Gateway で AWS ドキュメント検索(オプション)
AgentCore Gateway を通じて AWS 公式ドキュメントを MCP ツールとして検索できるようにしました。ENABLE_GATEWAY=true でデプロイすると有効になります。
const gateway = new agentcore.Gateway(ragStack, "KnowledgeGateway", {
gatewayName: "agentic-rag-gateway",
authorizerConfiguration: agentcore.GatewayAuthorizer.usingAwsIam(),
});
new agentcore.CfnGatewayTarget(ragStack, "AWSKnowledgeTarget", {
gatewayIdentifier: gateway.gatewayId,
name: "aws-knowledge",
targetConfiguration: {
mcp: { mcpServer: { endpoint: "https://knowledge-mcp.global.api.aws" } },
},
});
エージェント側からは mcp-proxy-for-aws を使って IAM 認証付きで Gateway に接続しています。
from mcp_proxy_for_aws.client import aws_iam_streamablehttp_client
from strands.tools.mcp import MCPClient
mcp_factory = lambda: aws_iam_streamablehttp_client(
endpoint=GATEWAY_URL,
aws_region=REGION,
aws_service="bedrock-agentcore",
)
tools.append(MCPClient(mcp_factory))
AWS Knowledge MCP Server は AWS がホストしている MCP サーバーで、Gateway のターゲットとして追加するだけで使えます。社内ドキュメントだけでなく AWS の公式ドキュメントも横断的に検索できるので、もしここに技術的な質問にも対応できるようにしたい場合の参考にしていただけると良いです。あくまでGatewayをどう使うかのサンプル的な意味合いもあります。無理に使う必要もございません。
Gateway 経由で IAM 認証を使う構成については、下記の記事も必要に応じてご参照ください。
Gateway を拡張する
今回は AWS Knowledge MCP Server だけを Gateway のターゲットに追加していますが、AgentCore Gateway には Lambda や独自の MCP Server、さらには AgentCore Runtime 自体もターゲットとして接続できます。たとえば社内 API の呼び出し、外部サービスとの連携、独自の処理などをツールとして追加できます。
たとえば別の AgentCore Runtime を Gateway 経由でツールとして呼び出す場合は、Runtime の invocations エンドポイントをターゲットに指定し、IAM 認証を設定します。
const runtimeEndpoint =
`https://bedrock-agentcore.${cdk.Aws.REGION}.amazonaws.com/runtimes/` +
encodeURIComponent(anotherRuntime.agentRuntimeArn) +
"/invocations";
new agentcore.CfnGatewayTarget(ragStack, "MyAgentTarget", {
gatewayIdentifier: gateway.gatewayId,
name: "my-agent",
description: "社内データ分析エージェント",
targetConfiguration: {
mcp: {
mcpServer: {
endpoint: runtimeEndpoint,
},
},
},
credentialProviderConfigurations: [
{
credentialProviderType: "GATEWAY_IAM_ROLE",
credentialProvider: {
iamCredentialProvider: {
service: "bedrock-agentcore",
},
},
},
],
});
エンドポイントは https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{URLエンコードされたARN}/invocations の形式です。credentialProviderConfigurations で IAM ロールを指定すると、Gateway がリクエスト時に SigV4 署名を付与してくれます。
エージェント自体のコードを変えなくてもこのようにターゲットを追加することで、できることの幅を広げることを可能にします。
Gateway の MCP Server ターゲットで IAM 認証を使う構成については、下記の記事で詳しく紹介しているので、こちらも必要に応じてご参照ください。
フィードバック収集
RAG を運用していく上で、ユーザーからのフィードバックは回答品質の改善に欠かせません。今回は回答ごとに「いいね / 改善が必要」やコメントを送れる仕組みを入れています。
フィードバックの送信先には API Gateway REST API + Cognito User Pool Authorizer + Lambda + DynamoDB を使っています。
const feedbackApi = new apigateway.RestApi(ragStack, "FeedbackApi", {
restApiName: "agentic-rag-feedback",
deployOptions: { stageName: "prod" },
});
const feedbackAuthorizer = new apigateway.CognitoUserPoolsAuthorizer(ragStack, "FeedbackAuthorizer", {
cognitoUserPools: [backend.auth.resources.userPool],
});
feedbackResource.addMethod("POST", new apigateway.LambdaIntegration(feedbackFn), {
authorizer: feedbackAuthorizer,
authorizationType: apigateway.AuthorizationType.COGNITO,
});
Cognito の ID トークンで認証するので、誰がどの回答にフィードバックしたかを紐づけられます。DynamoDB に保存されたフィードバックは集計・CSV エクスポート用のスクリプトで確認できるようにしています。
npm run feedback:summary -- --table <TABLE_NAME>
npm run feedback:export -- --table <TABLE_NAME> -o feedback.csv
LLM-as-a-Judge の自動評価に加えて、実際のユーザーからのフィードバックも収集しておくと、プロンプト改善やドキュメント追加の判断材料になりますね。
LLM-as-a-Judge で RAG 品質評価
RAG を作ったら精度が気になりますよね。Gemma 4 31B 自身を審査用のLLMとして使い、15問のテスト質問に対する回答品質を3つの観点で自動評価してみました。評価スクリプトは eval/evaluate.py に用意しています。
npm run eval -- \
--runtime-arn <RUNTIME_ARN> \
--region us-east-1
Runtime ARN はデプロイ後に生成される amplify_outputs.json の custom.runtime_arn に記載されているのでそちらを参照します。実行すると15問すべてに対して RAG の回答を取得し、Gemma 4 31B が審査員として Faithfulness / Relevancy / Completeness の3軸で1〜5のスコアを付けます。
[1/15] q01: リモートワークは週何日まで可能ですか?...
RAG応答: 289文字, 1ツール呼出, 6.9秒
評価: F=5 R=5 C=5 (6.9秒)
理由: 正解に含まれる「週3日まで」「HRシステムから前日17時までに申請」という情報を完全に網羅し、正しいドキュメントを参照している
[2/15] q02: タクシー代の経費精算で事前承認が必要なのは...
RAG応答: 152文字, 1ツール呼出, 6.1秒
評価: F=5 R=5 C=5 (4.5秒)
理由: 回答は正解の内容と完全に一致しており、正しいドキュメントを参照して正確に回答している
サンプルドキュメントに対する評価結果です。
| 観点 | 内容 | スコア |
|---|---|---|
| Faithfulness | KB の内容に基づいているか(ハルシネーションの有無) | 5.00 / 5.00 |
| Relevancy | 正しいドキュメントを参照して回答しているか | 5.00 / 5.00 |
| Completeness | 期待される情報を網羅しているか | 4.47 / 5.00 |
| Overall | - | 4.82 / 5.00 |
15問すべてで正しいドキュメントを検索・回答できました。Completeness が若干低いのは、RPO(目標復旧時点)や MFA 必須といった補足情報を省略する傾向がありました。メインの回答は正確に返ってくるので、この価格帯のモデルとしては十分な精度だと思います。
あくまで一問一答のシンプルな質問セットおよびシンプルな評価基準での結果で高くなりがちかと思うので、参考値としてご覧ください。自分たちのドキュメントに差し替えたら eval/questions.json のテスト質問も書き換えて、同じスクリプトで評価できます。フィードバック収集の仕組みと合わせて、改善サイクルを回していく使い方を想定しています。
評価に使った質問の例
- リモートワークは週何日まで可能ですか? 申請方法も教えてください。
- タクシー代の経費精算で事前承認が必要なのはいくらからですか?
- セキュリティインシデントを発見したらどこに連絡すればいいですか?
- 本番デプロイが禁止されている曜日はありますか?
- 500万円以上の調達に必要な承認レベルを教えてください。
自分たちのドキュメントを使う
このサンプルには架空の業務ドキュメントが 20件入っていますが、seed/docs/ の中身を差し替えるだけで自分たちのドキュメントに切り替えられます。
テキストファイルとメタデータファイルをペアで配置します。
seed/docs/
├── my-document.txt # ドキュメント本文
├── my-document.txt.metadata.json # メタデータ(カテゴリ・タイトル)
{
"metadataAttributes": {
"category": {
"value": { "type": "STRING", "stringValue": "hr" }
},
"title": {
"value": { "type": "STRING", "stringValue": "リモートワーク規程" }
}
}
}
再デプロイすると BucketDeployment が S3 にアップロードし、カスタムリソースがドキュメント取り込みジョブを自動実行します。ドキュメントを差し替えたら eval/questions.json のテスト質問も書き換えると、LLM-as-a-Judge で新しいドキュメントに対する評価もできますね。
コスト感
月1000回の質問で運用した場合の目安です。あくまで目安で実際には使用した分かかるので注意してください。
前提としてus-east-1、Gateway 有効、LLM-as-a-Judge は未実行、サンプル文書のみ、シンプルな問い合わせ(1問1答レベル)を前提としています。
| 項目 | 月額目安 |
|---|---|
| Gemma 4 31B(推論) | 約 $0.34 ~ $1.00 |
| Embedding + S3 Vectors | 約 $0.05〜$0.20 |
| AgentCore Runtime | 約 $0.50〜$2 |
| AgentCore Memory + Gateway | 約 $0.50〜$1 |
| Cognito | $0(1万 MAU 以内) |
| Amplify Hosting | 約 $0.50〜$3 |
| API Gateway + Lambda + DynamoDB | 約 $0.01〜$0.10 |
| 合計 | 約 $3〜$7 / 月 |
LLM 推論と AgentCore Runtime が主な課金要素です。OpenSearch Serverless の最低料金(月 $350〜)と比較すると、S3 Vectors を使うことでベクトルストアのコストはほぼゼロに近くなります。PoC や社内ツールのように「まず動かしてみたい」というフェーズでは、かなり魅力的な構成だと思います。
おわりに
RAG って構築コストが高そう、試しづらい・・・というイメージを持っている方は多いんじゃないかと思います。
ただ今回紹介した構成例であれば、そこまでコストもかけずサクッと挙動や感触を掴んでいただけるのではないかと思います。
ここで導入の可能性を見いだせれば、このリポジトリをベースに機能を追加するのもアリですし、チューニングするのも良いと思います。Claude などのフロンティアモデルと精度比較するのも面白いですね。
実装の詳細はリポジトリを参照していただければと思います。フィードバックがあれば Issue 経由でお気軽にお寄せください!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!!