
Snowflake Openflow Connector for PostgreSQL を AWS で動かしてみた
データ事業本部の笠原です。
今回はSnowflakeのOpenflow Connector for PostgreSQLを使って、RDS for PostgreSQLのデータをCDC (Change Data Capture) でSnowflakeに転送できるか、試してみました。
Openflow とは何か
Openflow は Snowflake が提供するデータ統合サービスで、Apache NiFi をベースにしています。各種データソースと Snowflake をつなぐマネージドなコネクタが用意されていて、画面上でパイプラインを組み立ててデータを取り込むことができます。
Openflowのデプロイモデルは2つあります。
- Snowflake Deployment (SPCS)
- Snowflake 側 (Snowpark Container Services) で動くフルマネージド型のデプロイモデル。AWS リソースを自分で用意する必要がなく、手軽に始められます。
- Snowflake Deploymentは、2026年6月現在、AWSもしくはAzureの商用リージョンの全てのアカウントで利用可能です。
- Bring Your Own Cloud (BYOC)
- 自分の AWS アカウントにて EKS 上で動かすデプロイモデル。ネットワークやデータの所在を自分でコントロールできます。
- Bring Your Own Cloudは、2026年6月現在、AWSの商用リージョンの全てのアカウントで利用可能です。
今回は AWS 環境上の RDS やオンプレ上の DB へのアクセスもできるようにしたいと思い、BYOC を選んで検証を行いました。
使うコネクタは PostgreSQL コネクタです。CDC (Change Data Capture) 方式で、最初に既存データをスナップショットし、その後は WAL (先行書き込みログ) から変更分を継続的に取り込みます。
今回の構成
今回の構成は以下の通りです。
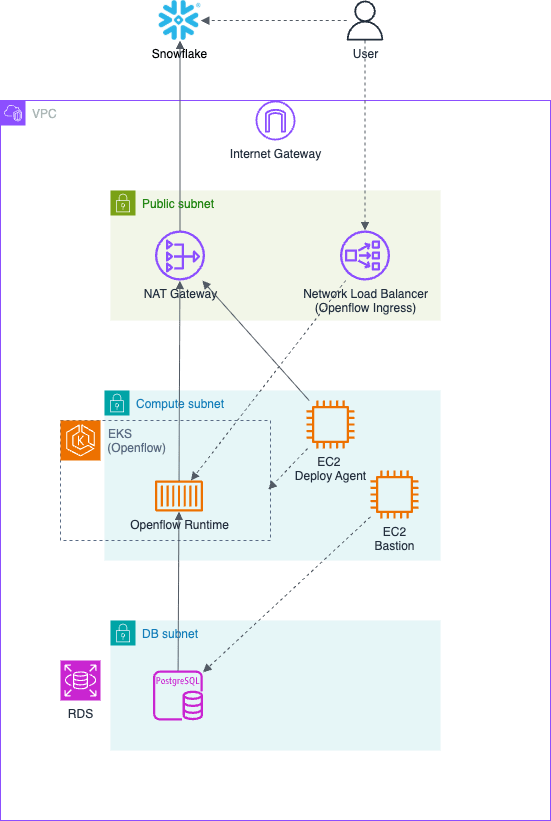
AWS上にOpenflowのランタイムが動作するような環境です。
ソースとなるDBは、RDS for PostgreSQLのインスタンスを起動して、テストデータを用意しておきます。
OpenflowランタイムからSnowflakeへのアクセス経路としては、パブリックサブネットにNAT Gatewayを設定しています。
あらかじめ作成しておくもの
今回は、VPC環境、RDSインスタンス、RDSへアクセスするための踏み台EC2インスタンスは作成しておきます。こちらについては、検証で利用したCloudFormationテンプレートを本ブログで公開していますので、ご参考ください。
Snowflake提供Cfnで作成されるもの
Openflowをデプロイする際に、SnowflakeからCloudformationテンプレートが提供されます。
このテンプレートをダウンロードしてデプロイすると、Openflowデプロイ用に動作するEC2インスタンスが起動します。(本ブログでは、「デプロイエージェントEC2」と呼んでいきます)
デプロイエージェントEC2が起動すると、UserDataに仕込まれたスクリプトによって、EKSやNLBが構築されます。
前提条件
今回の環境を構築するにあたり、以下の条件や環境を用意しました。
- Snowflake
- ORGADMIN(利用規約承諾)/ ACCOUNTADMIN が使えるアカウント
- AWSで稼働していること。今回は東京リージョンで試しています。
- AWS
- CloudFormation/VPC/EC2/EKS/IAM/RDS の管理者権限
- Snowflakeのリージョンと合わせています。今回は東京リージョン。
- ローカルPC
- AWS CLI /
session-manager-plugin/psql - 踏み台EC2経由でPostgreSQLへクエリを投入するために使用してます。
- AWS CLI /
構築手順
1. ネットワーク環境
BYOC は EKS 用の private サブネット と NLB/NAT 用の public サブネットを用意します。
public サブネットには kubernetes.io/role/elb=1 のタグを設定します。これは、EKSのNLB構築の際に自動探索するためです。
また、自己参照セキュリティグループ (デプロイエージェントEC2/EKS/EC2 Instance Connect Endpoint 共用) も用意しておきます。
ネットワーク環境構築Cfnテンプレート:01-network.yaml
AWSTemplateFormatVersion: "2010-09-09"
Parameters:
ProjectName:
Type: String
Default: openflow-pg
Description: リソース名・タグの接頭辞
VpcCidr:
Type: String
Default: 10.0.0.0/16
PublicSubnet1Cidr:
Type: String
Default: 10.0.101.0/24
Description: NLB / NAT 用パブリックサブネット (AZ #1)
PublicSubnet2Cidr:
Type: String
Default: 10.0.102.0/24
Description: NLB 用パブリックサブネット (AZ #2)
ComputeSubnet1Cidr:
Type: String
Default: 10.0.1.0/24
Description: EKS 用プライベートサブネット (AZ #1)
ComputeSubnet2Cidr:
Type: String
Default: 10.0.2.0/24
Description: EKS 用プライベートサブネット (AZ #2)
DbSubnet1Cidr:
Type: String
Default: 10.0.3.0/24
Description: RDS 用 DB サブネット (AZ #1)
DbSubnet2Cidr:
Type: String
Default: 10.0.4.0/24
Description: RDS 用 DB サブネット (AZ #2)
Resources:
Vpc:
Type: AWS::EC2::VPC
Properties:
CidrBlock: !Ref VpcCidr
EnableDnsSupport: true
EnableDnsHostnames: true
Tags:
- Key: Name
Value: !Sub "${ProjectName}-vpc"
InternetGateway:
Type: AWS::EC2::InternetGateway
Properties:
Tags:
- Key: Name
Value: !Sub "${ProjectName}-igw"
VpcGatewayAttachment:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
VpcId: !Ref Vpc
InternetGatewayId: !Ref InternetGateway
PublicSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref PublicSubnet1Cidr
AvailabilityZone: !Select [0, !GetAZs ""]
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub "${ProjectName}-public-1"
# AWS Load Balancer Controller が外部 NLB を作成するサブネットを探索するためのタグ
- Key: kubernetes.io/role/elb
Value: "1"
PublicSubnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref PublicSubnet2Cidr
AvailabilityZone: !Select [1, !GetAZs ""]
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub "${ProjectName}-public-2"
- Key: kubernetes.io/role/elb
Value: "1"
ComputeSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref ComputeSubnet1Cidr
AvailabilityZone: !Select [0, !GetAZs ""]
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: !Sub "${ProjectName}-compute-1"
# 内部 LB 用サブネットの探索タグ
- Key: kubernetes.io/role/internal-elb
Value: "1"
ComputeSubnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref ComputeSubnet2Cidr
AvailabilityZone: !Select [1, !GetAZs ""]
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: !Sub "${ProjectName}-compute-2"
- Key: kubernetes.io/role/internal-elb
Value: "1"
DbSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref DbSubnet1Cidr
AvailabilityZone: !Select [0, !GetAZs ""]
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: !Sub "${ProjectName}-db-1"
DbSubnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref Vpc
CidrBlock: !Ref DbSubnet2Cidr
AvailabilityZone: !Select [1, !GetAZs ""]
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: !Sub "${ProjectName}-db-2"
NatEip:
Type: AWS::EC2::EIP
DependsOn: VpcGatewayAttachment
Properties:
Domain: vpc
Tags:
- Key: Name
Value: !Sub "${ProjectName}-nat-eip"
NatGateway:
Type: AWS::EC2::NatGateway
Properties:
AllocationId: !GetAtt NatEip.AllocationId
SubnetId: !Ref PublicSubnet1
Tags:
- Key: Name
Value: !Sub "${ProjectName}-nat"
PublicRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref Vpc
Tags:
- Key: Name
Value: !Sub "${ProjectName}-public-rt"
PublicDefaultRoute:
Type: AWS::EC2::Route
DependsOn: VpcGatewayAttachment
Properties:
RouteTableId: !Ref PublicRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref InternetGateway
PublicSubnet1RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref PublicRouteTable
SubnetId: !Ref PublicSubnet1
PublicSubnet2RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref PublicRouteTable
SubnetId: !Ref PublicSubnet2
PrivateRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref Vpc
Tags:
- Key: Name
Value: !Sub "${ProjectName}-private-rt"
PrivateDefaultRoute:
Type: AWS::EC2::Route
Properties:
RouteTableId: !Ref PrivateRouteTable
DestinationCidrBlock: 0.0.0.0/0
NatGatewayId: !Ref NatGateway
ComputeSubnet1RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref PrivateRouteTable
SubnetId: !Ref ComputeSubnet1
ComputeSubnet2RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref PrivateRouteTable
SubnetId: !Ref ComputeSubnet2
DbRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref Vpc
Tags:
- Key: Name
Value: !Sub "${ProjectName}-db-rt"
DbSubnet1RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref DbRouteTable
SubnetId: !Ref DbSubnet1
DbSubnet2RouteAssoc:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref DbRouteTable
SubnetId: !Ref DbSubnet2
OpenflowPrivateSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: !Sub "${ProjectName} Openflow BYOC private SG (self ingress, all egress)"
VpcId: !Ref Vpc
SecurityGroupEgress:
- IpProtocol: "-1"
CidrIp: 0.0.0.0/0
Description: allow all outbound
Tags:
- Key: Name
Value: !Sub "${ProjectName}-openflow-private-sg"
OpenflowPrivateSgSelfIngress:
Type: AWS::EC2::SecurityGroupIngress
Properties:
GroupId: !Ref OpenflowPrivateSecurityGroup
IpProtocol: "-1"
SourceSecurityGroupId: !Ref OpenflowPrivateSecurityGroup
Description: allow all inbound from itself
Outputs:
VpcId:
Description: Snowflake BYOC テンプレート (BYO-VPC) で選択する VPC
Value: !Ref Vpc
Export:
Name: !Sub "${ProjectName}-VpcId"
VpcCidr:
Value: !Ref VpcCidr
Export:
Name: !Sub "${ProjectName}-VpcCidr"
ComputeSubnetIds:
Description: Snowflake BYOC テンプレートで選択する EKS 用プライベートサブネット (2つ)
Value: !Sub "${ComputeSubnet1},${ComputeSubnet2}"
Export:
Name: !Sub "${ProjectName}-ComputeSubnetIds"
ComputeSubnet1Id:
Value: !Ref ComputeSubnet1
ComputeSubnet2Id:
Value: !Ref ComputeSubnet2
PublicSubnetIds:
Description: NLB ingress 用パブリックサブネット (2つ)
Value: !Sub "${PublicSubnet1},${PublicSubnet2}"
Export:
Name: !Sub "${ProjectName}-PublicSubnetIds"
DbSubnetIds:
Description: RDS DB Subnet Group に渡す DB サブネット (2つ)
Value: !Sub "${DbSubnet1},${DbSubnet2}"
Export:
Name: !Sub "${ProjectName}-DbSubnetIds"
ComputeSubnetCidrs:
Description: RDS セキュリティグループの許可元に使う compute サブネット CIDR
Value: !Sub "${ComputeSubnet1Cidr},${ComputeSubnet2Cidr}"
Export:
Name: !Sub "${ProjectName}-ComputeSubnetCidrs"
OpenflowPrivateSecurityGroupId:
Description: Snowflake BYOC テンプレートの PrivateSecurityGroup に渡す SG ID
Value: !Ref OpenflowPrivateSecurityGroup
Export:
Name: !Sub "${ProjectName}-OpenflowPrivateSgId"
2. データベース (RDS for PostgreSQL) 環境
今回のデータソースとなるDBを構築します。RDS for PostgreSQLのシングルインスタンスをDB Subnetに起動します。
設定のポイントは以下の通りです。
- rds.logical_replication = 1
- これにより wal_level=logical になります。
- 新規作成インスタンスには作成時から適用されますが、念のため
SHOW wal_level;で確認しましょう。
- PubliclyAccessible = false
- EKS(同一 VPC) 内の Openflow ランタイムからプライベート接続のみとし、5432 ポートを VPC CIDR からのみ許可するため、パブリックアクセスはしない設定にします。
DB環境構築Cfnテンプレート:02-rds-postgres.yaml
AWSTemplateFormatVersion: "2010-09-09"
Parameters:
ProjectName:
Type: String
Default: openflow-pg
Description: 01-network.yaml と同一の接頭辞 (Export 参照に使用)
DBName:
Type: String
Default: appdb
Description: 初期データベース名 (コネクタの接続先 DB)
MasterUsername:
Type: String
Default: pgadmin
Description: RDS マスタユーザ名
ParameterGroupFamily:
Type: String
Default: postgres16
Description: DB パラメータグループのファミリ (EngineVersion と整合させること)
EngineVersion:
Type: String
Default: "16.13"
Description: >-
PostgreSQL エンジンバージョン (ParameterGroupFamily と整合させること)
DBInstanceClass:
Type: String
Default: db.t3.small
Description: サンプル用なので、小さめのインスタンスクラスにします
AllocatedStorage:
Type: Number
Default: 20
Description: ストレージ(GB)
Resources:
# DB認証情報格納用のSecrets Manager
DBSecret:
Type: AWS::SecretsManager::Secret
# サンプル環境のためスタック削除時にシークレットも削除する
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
Name: !Sub "${ProjectName}/rds/master"
Description: RDS for PostgreSQL master credentials
GenerateSecretString:
SecretStringTemplate: !Sub '{"username":"${MasterUsername}"}'
GenerateStringKey: password
PasswordLength: 24
# JDBC URL / シェルで問題になりやすい文字を除外
ExcludeCharacters: '"@/\ ''`'
Tags:
- Key: Name
Value: !Sub "${ProjectName}-rds-master-secret"
DBSubnetGroup:
Type: AWS::RDS::DBSubnetGroup
Properties:
DBSubnetGroupDescription: !Sub "${ProjectName} DB subnet group"
SubnetIds: !Split
- ","
- !ImportValue
"Fn::Sub": "${ProjectName}-DbSubnetIds"
Tags:
- Key: Name
Value: !Sub "${ProjectName}-db-subnet-group"
DBSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: !Sub "${ProjectName} RDS PostgreSQL access (VPC internal only)"
VpcId: !ImportValue
"Fn::Sub": "${ProjectName}-VpcId"
SecurityGroupIngress:
# 今回はVPC CIDRからのアクセスを許可
- IpProtocol: tcp
FromPort: 5432
ToPort: 5432
CidrIp: !ImportValue
"Fn::Sub": "${ProjectName}-VpcCidr"
Description: PostgreSQL from within VPC (EKS/Openflow runtime)
Tags:
- Key: Name
Value: !Sub "${ProjectName}-rds-sg"
DBParameterGroup:
Type: AWS::RDS::DBParameterGroup
Properties:
Description: !Sub "${ProjectName} PostgreSQL params with logical replication"
Family: !Ref ParameterGroupFamily
Parameters:
# wal_level=logical を有効にする RDS 固有パラメータ
rds.logical_replication: "1"
# コネクタ 1 台あたり最低 1 スロット / 2 WAL sender
max_replication_slots: "10"
max_wal_senders: "10"
Tags:
- Key: Name
Value: !Sub "${ProjectName}-pg-params"
DBInstance:
Type: AWS::RDS::DBInstance
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
DBInstanceIdentifier: !Sub "${ProjectName}-postgres"
Engine: postgres
EngineVersion: !Ref EngineVersion
DBName: !Ref DBName
DBInstanceClass: !Ref DBInstanceClass
AllocatedStorage: !Ref AllocatedStorage
StorageType: gp3
StorageEncrypted: true
MultiAZ: false
PubliclyAccessible: false
DeletionProtection: false
BackupRetentionPeriod: 1
AutoMinorVersionUpgrade: true
MasterUsername: !Ref MasterUsername
MasterUserPassword: !Sub "{{resolve:secretsmanager:${DBSecret}:SecretString:password}}"
DBParameterGroupName: !Ref DBParameterGroup
DBSubnetGroupName: !Ref DBSubnetGroup
VPCSecurityGroups:
- !Ref DBSecurityGroup
Tags:
- Key: Name
Value: !Sub "${ProjectName}-postgres"
Outputs:
DBEndpointAddress:
Description: RDS エンドポイント (コネクタの JDBC URL に使用)
Value: !GetAtt DBInstance.Endpoint.Address
Export:
Name: !Sub "${ProjectName}-RdsEndpoint"
DBEndpointPort:
Value: !GetAtt DBInstance.Endpoint.Port
DBName:
Value: !Ref DBName
JdbcUrl:
Description: そのままコネクタに設定できる JDBC URL
Value: !Sub
- "jdbc:postgresql://${Addr}:${Port}/${Db}"
- Addr: !GetAtt DBInstance.Endpoint.Address
Port: !GetAtt DBInstance.Endpoint.Port
Db: !Ref DBName
MasterSecretArn:
Description: マスタ認証情報の Secrets Manager ARN
Value: !Ref DBSecret
MasterUsername:
Value: !Ref MasterUsername
3. 踏み台EC2 (SQL投入用)
今回RDS for PostgreSQLインスタンスに対してSQLを実行するために、Systems Manager セッションマネージャーのポートフォワーディングを使ってローカルPCからクエリ実行しようと思います。そのための踏み台となるEC2を用意しました。
Compute Subnetに配置してます。
また、念の為UserDataにてpostgresqlをインストールしてpsqlコマンドが使えるようにしています。
踏み台EC2環境構築Cfnテンプレート 03-bastion.yaml
AWSTemplateFormatVersion: "2010-09-09"
Parameters:
ProjectName:
Type: String
Default: openflow-pg
Description: 01-network.yaml と同一の接頭辞 (Export 参照に使用)
InstanceType:
Type: String
Default: t3.micro
LatestAmiId:
Type: AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>
Default: /aws/service/ami-amazon-linux-latest/al2023-ami-kernel-default-x86_64
Description: 最新 Amazon Linux 2023 AMI を SSM パブリックパラメータから自動解決
Resources:
BastionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${ProjectName}-bastion-role"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
Tags:
- Key: Name
Value: !Sub "${ProjectName}-bastion-role"
BastionInstanceProfile:
Type: AWS::IAM::InstanceProfile
Properties:
InstanceProfileName: !Sub "${ProjectName}-bastion-profile"
Roles:
- !Ref BastionRole
BastionSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: !Sub "${ProjectName} bastion (SSM only, no inbound)"
VpcId: !ImportValue
"Fn::Sub": "${ProjectName}-VpcId"
SecurityGroupEgress:
- IpProtocol: "-1"
CidrIp: 0.0.0.0/0
Description: allow all outbound
Tags:
- Key: Name
Value: !Sub "${ProjectName}-bastion-sg"
BastionInstance:
Type: AWS::EC2::Instance
Properties:
InstanceType: !Ref InstanceType
ImageId: !Ref LatestAmiId
IamInstanceProfile: !Ref BastionInstanceProfile
SubnetId: !Select
- 0
- !Split
- ","
- !ImportValue
"Fn::Sub": "${ProjectName}-ComputeSubnetIds"
SecurityGroupIds:
- !Ref BastionSecurityGroup
UserData:
Fn::Base64: |
#!/bin/bash
# psql クライアントを導入 (Amazon Linux 2023)
dnf install -y postgresql16 || dnf install -y postgresql15
Tags:
- Key: Name
Value: !Sub "${ProjectName}-bastion"
Outputs:
BastionInstanceId:
Description: 踏み台のインスタンス ID
Value: !Ref BastionInstance
SsmStartSessionCommand:
Description: SSM セッション開始コマンド
Value: !Sub "aws ssm start-session --target ${BastionInstance} --region ${AWS::Region}"
4. PostgreSQL側設定
PostgreSQL側には、まずデータソースとなるデータベース・スキーマ・テーブルをサンプル用に作成しておきます。
今回はSSMセッションマネージャーのポートフォワーディングを使って、ローカルPCから psql コマンドを実行します。ターミナルでまず以下のコマンドを実行します。
export BASTION_ID=<踏み台EC2のインスタンスID>
export RDS_ENDPOINT=<DBエンドポイント>
aws ssm start-session --region "ap-northeast-1" --target "$BASTION_ID" \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters "{\"host\":[\"$RDS_ENDPOINT\"],\"portNumber\":[\"5432\"],\"localPortNumber\":[\"55432\"]}"
上記コマンド実行しているターミナルは閉じずに、別のターミナルを立ち上げて、以下のコマンドを実行します。
psql "host=localhost port=55432 dbname=appdb user=pgadmin sslmode=require" \
-f postgres/01-test-data.sql
-f オプションで、SQLファイルを指定して実行します。
実行するSQLファイルの中身は以下の通りです。
このSQLファイルを実行することで、テストデータを投入しています。
テストデータ投入SQL 01-test-data.sql
-- Schema
CREATE SCHEMA IF NOT EXISTS app;
-- Tables
CREATE TABLE app.customers (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(200) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT now()
);
CREATE TABLE app.products (
product_id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price NUMERIC(10,2) NOT NULL,
in_stock BOOLEAN NOT NULL DEFAULT true
);
CREATE TABLE app.orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER NOT NULL REFERENCES app.customers(customer_id),
product_id INTEGER NOT NULL REFERENCES app.products(product_id),
quantity INTEGER NOT NULL DEFAULT 1,
status VARCHAR(20) NOT NULL DEFAULT 'pending',
order_date TIMESTAMP NOT NULL DEFAULT now()
);
-- Initial data
INSERT INTO app.customers (name, email) VALUES
('Taro Yamada', 'taro@example.com'),
('Hanako Suzuki', 'hanako@example.com'),
('Jiro Tanaka', 'jiro@example.com');
INSERT INTO app.products (name, price, in_stock) VALUES
('Keyboard', 3980.00, true),
('Mouse', 1980.00, true),
('Monitor', 29800.00, false);
INSERT INTO app.orders (customer_id, product_id, quantity, status) VALUES
(1, 1, 2, 'confirmed'),
(2, 2, 1, 'pending'),
(3, 3, 1, 'shipped');
-- check data
SELECT 'customers' AS t, count(*) FROM app.customers
UNION ALL SELECT 'products', count(*) FROM app.products
UNION ALL SELECT 'orders', count(*) FROM app.orders;
次に、CDCを行うための論理レプリケーション設定の確認等を行います。
psql "host=localhost port=55432 dbname=appdb user=pgadmin sslmode=require" \
-f postgres/02-logical-reprecation-setup.sql
実行するSQLファイルの中身は以下の通りです。
以下の内容を行っています。
- 論理レプリケーション設定確認
SHOW wal_level;を実行して、値がlogicalと返ることを確認logicalでない場合、DBパラメータグループのrds.logical_replicationを1に変更してDBインスタンス再起動を行ってください。
- Openflowコネクタ用ユーザ作成と権限付与
- SQLクエリ内の
<CONNECTOR_PASSWORD>の値は適宜変更して実行してください。
- SQLクエリ内の
- Publicationの作成
論理レプリケーション設定確認、パブリケーション設定 02-logical-replication-setup.sql
-- Check logical replication
SHOW wal_level; -- 期待値: logical
SHOW max_replication_slots;
SHOW max_wal_senders;
-- user for openflow connector
CREATE USER openflow_user WITH PASSWORD '<CONNECTOR_PASSWORD>';
-- RDS では非スーパーユーザに REPLICATION 属性を直接付けられないため、
-- 代わりに rds_replication ロールを付与して論理レプリケーションを許可する。
GRANT rds_replication TO openflow_user;
-- Grant for Snapshot / CDC
-- データソースとしてテストデータを作成したデータベースやスキーマ等へ読み取り権限を付与
GRANT CONNECT ON DATABASE appdb TO openflow_user;
GRANT USAGE ON SCHEMA app TO openflow_user;
GRANT SELECT ON ALL TABLES IN SCHEMA app TO openflow_user;
ALTER DEFAULT PRIVILEGES IN SCHEMA app GRANT SELECT ON TABLES TO openflow_user;
-- PUBLICATION
CREATE PUBLICATION openflow_pub
FOR TABLE app.customers, app.products, app.orders
WITH (publish_via_partition_root = true);
-- Check
SELECT pubname, puballtables FROM pg_publication WHERE pubname = 'openflow_pub';
SELECT schemaname, tablename FROM pg_publication_tables WHERE pubname = 'openflow_pub';
5. Snowflake側設定
続いて、Snowflake側の設定に移ります。
最初に利用規約に承諾します。
ORGADMIN権限を持つユーザでSnowflakeにログインし、
Snowsight上の左メニューから「取り込み」>「Openflow」をクリックします。
初回はOpenflowの利用規約が表示されるので、許諾します。
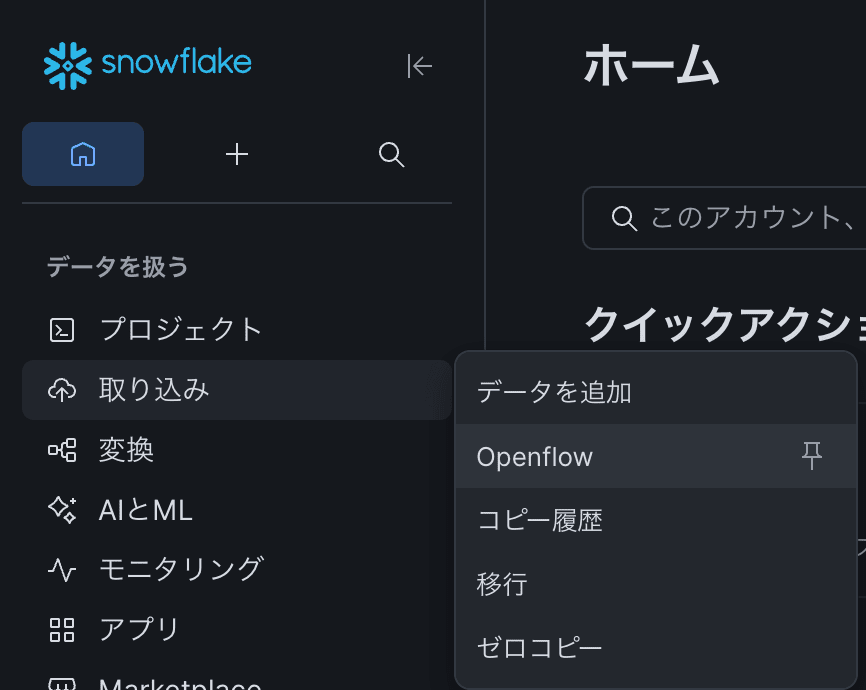
続いて、Snowsight上からSQLクエリを実行します。
なお、クエリ内の <your_user> は、実際にSnowflakeを作業するユーザ名に置き換えてください。
Openflow有効化 03-openflow-deployment-setup.sql
-- Create Openflow Admin Role
USE ROLE ACCOUNTADMIN;
CREATE ROLE IF NOT EXISTS OPENFLOW_ADMIN
COMMENT = 'Openflow デプロイ/ランタイムを管理するロール';
-- 自分の作業ユーザに付与
GRANT ROLE OPENFLOW_ADMIN TO USER <your_user>;
-- Grant for Openflow
GRANT CREATE OPENFLOW DATA PLANE INTEGRATION ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
GRANT CREATE OPENFLOW RUNTIME INTEGRATION ON ACCOUNT TO ROLE OPENFLOW_ADMIN;
-- ランタイム/コネクタへの OAuth ログインは、作業ユーザの DEFAULT_ROLE を使う。
-- 作業ユーザのロールを `OPENFLOW_ADMIN` に変更していたとしても、
-- DEFAULT_ROLEが ACCOUNTADMIN / ORGADMIN / GLOBALORGADMIN / SECURITYADMIN だと
-- Openflowにアクセス拒否される
-- (`The role requiested has been explicity blocked ...` エラーが返る)
-- そのため、DEFAULT_ROLEを非特権のOPENFLOW_ADMINに変更して、セカンダリロールをALLにする
-- 変更後は一度サインアウト→再サインインしてからOpenflowを操作すること
ALTER USER <your_user> SET DEFAULT_ROLE = OPENFLOW_ADMIN;
ALTER USER <your_user> SET DEFAULT_SECONDARY_ROLES = ('ALL');
-- Create Event Table
-- Openflowランタイムのログ/メトリクスを記録するテーブル
CREATE DATABASE IF NOT EXISTS OPENFLOW;
CREATE SCHEMA IF NOT EXISTS OPENFLOW.TELEMETRY;
CREATE EVENT TABLE IF NOT EXISTS OPENFLOW.TELEMETRY.EVENTS;
GRANT USAGE ON DATABASE OPENFLOW TO ROLE OPENFLOW_ADMIN;
GRANT USAGE ON SCHEMA OPENFLOW.TELEMETRY TO ROLE OPENFLOW_ADMIN;
6. Openflow Deploy設定 (エージェントEC2/EKS/NLB)
次に、Snowsight上からOpenflowデプロイメントの設定を行います。
作業ユーザを OPENFLOW_ADMIN ロールに切り替えて実施します。
Snowsight上の左メニューから「取り込み」>「Openflow」をクリックし、「Openflowを起動」をクリックします。

Openflowの画面が表示されたら、「Create a deployment」をクリックします。
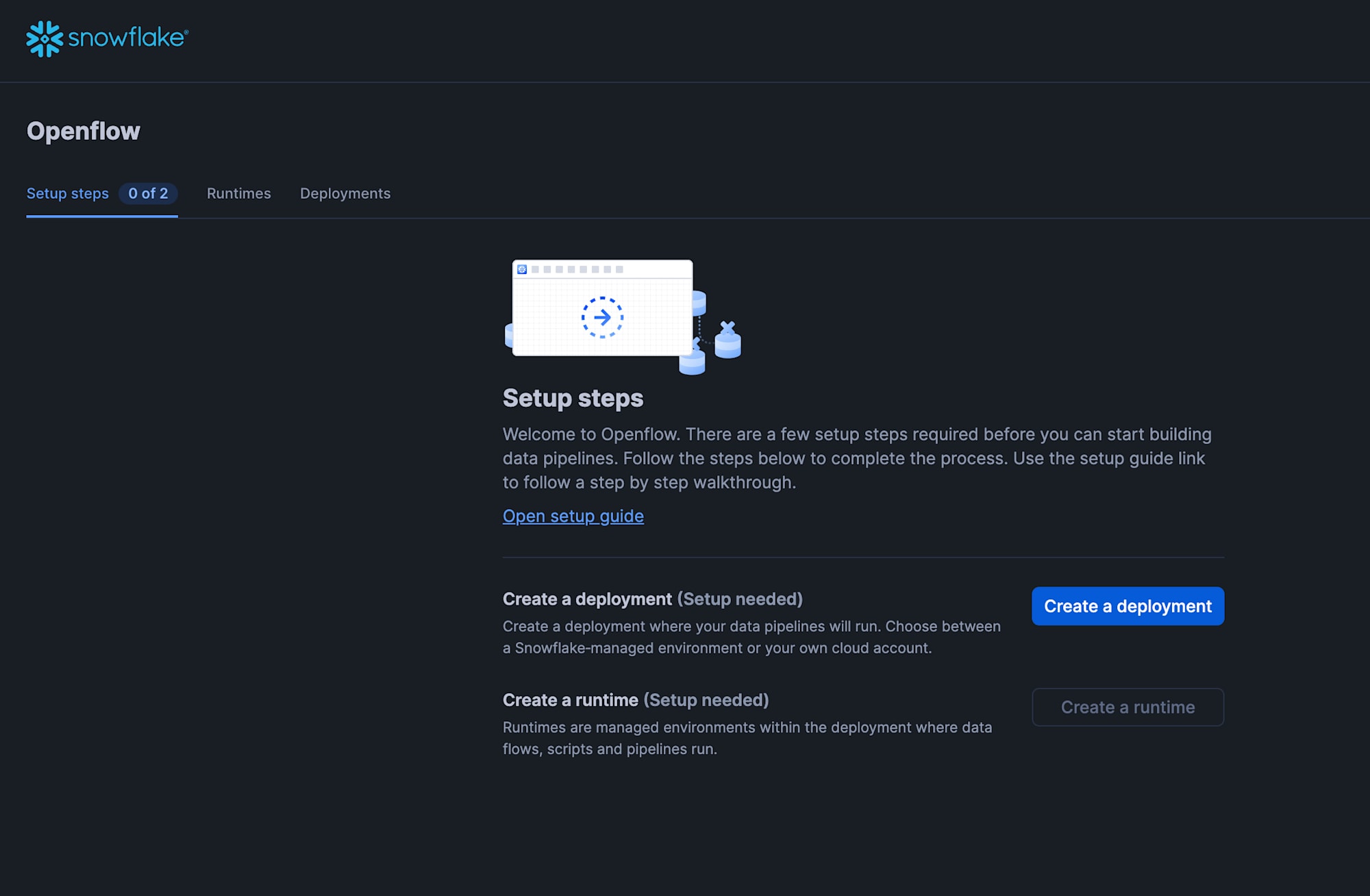
「Prerequesites」の画面では「Next」をクリックし、
「Deployment location」の画面では「Amazon Web Services」を選択して、
「Name」欄に適宜デプロイメント名を入力し、「Next」をクリックします。
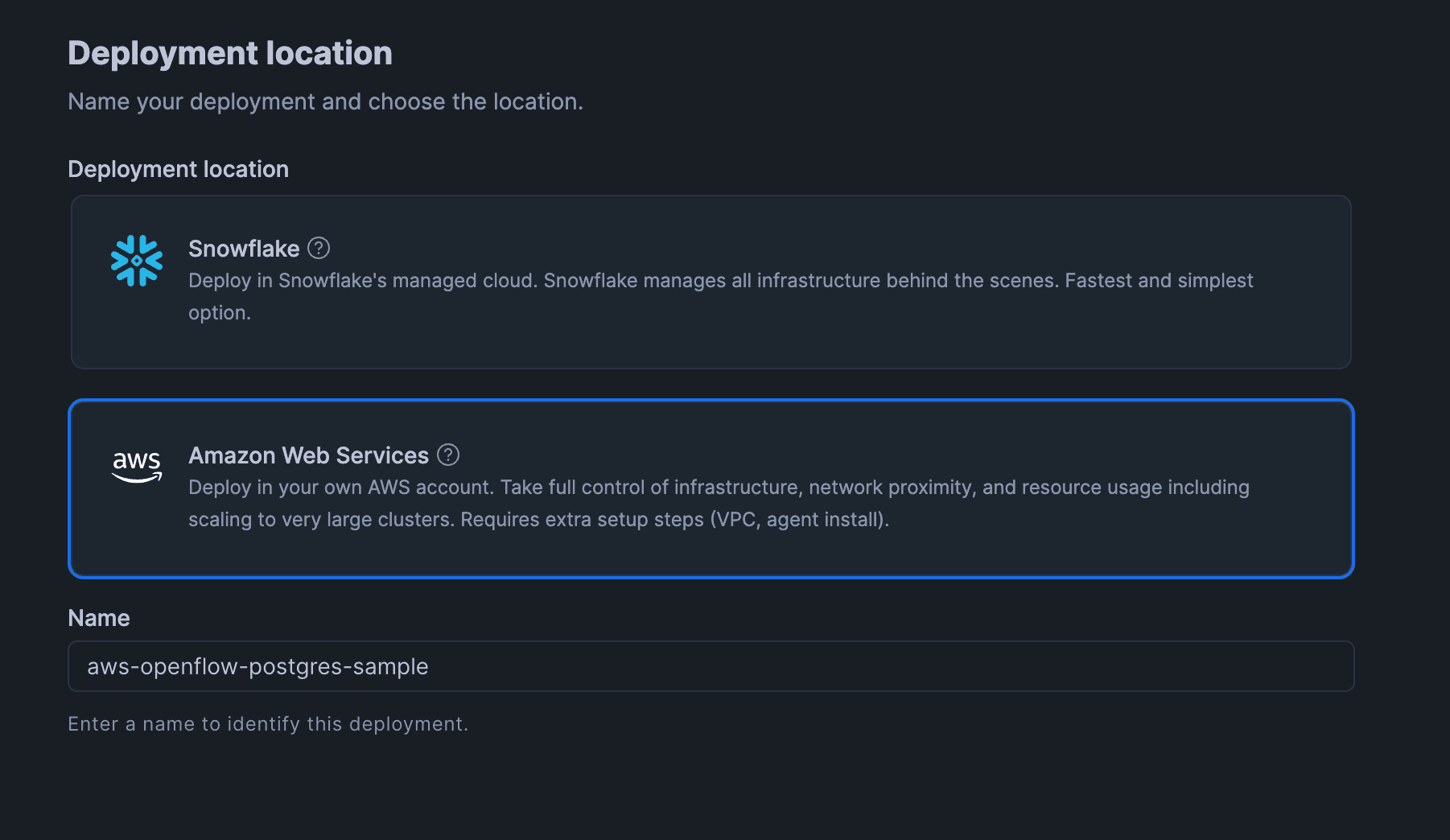
「Deployment configuration」の画面で、「Select a VPC option」で「Bring Your Own VPC」を選択して「Create deployment」をクリックします。
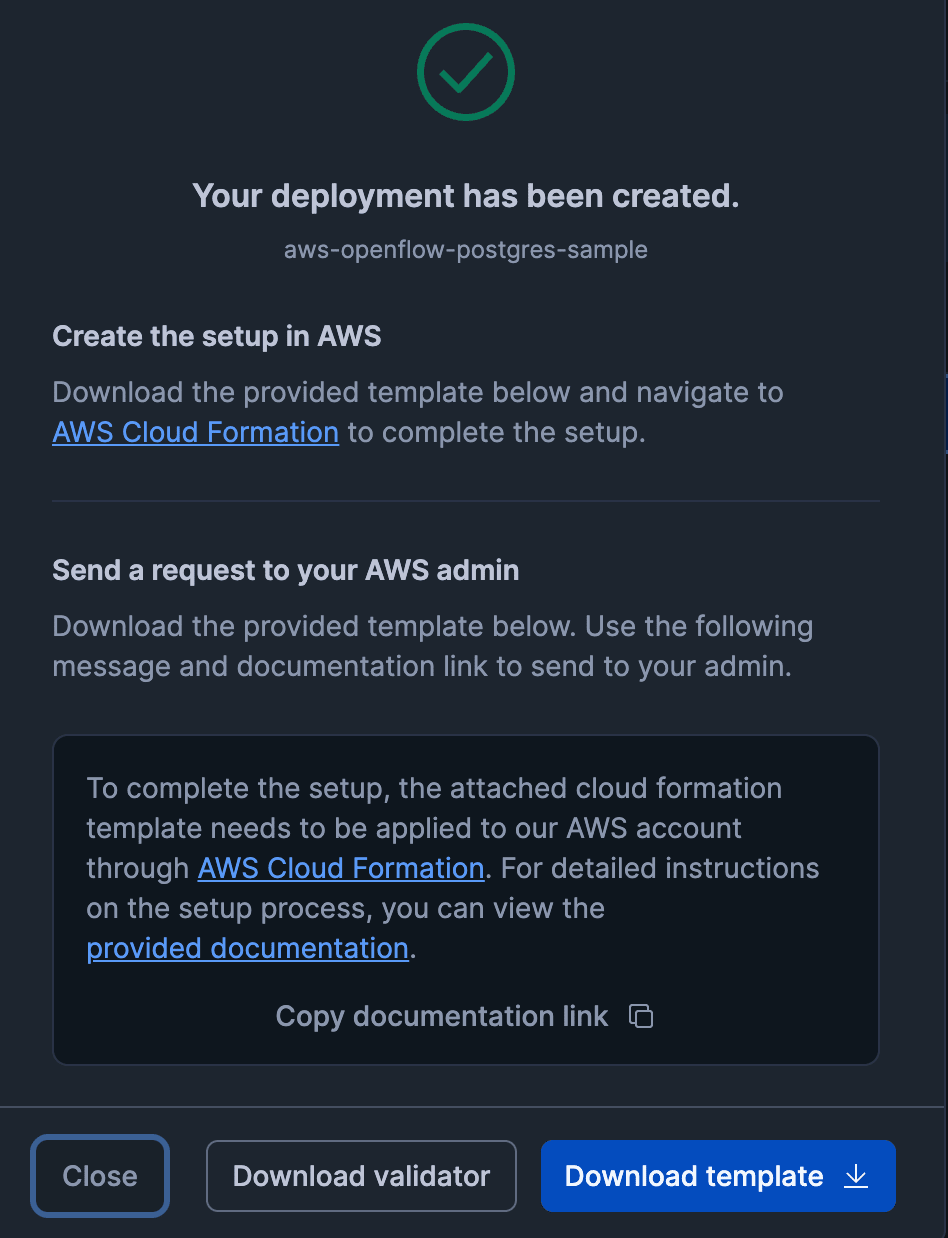
すると、「Your deployment has been created」の画面が表示されます。
「Download template」をクリックして、Cloudformationテンプレートをダウンロードします。
このテンプレートを使用して、Openflowの稼働に必要なEKSやNLBを構築するデプロイエージェントEC2を作成します。
ダウンロードしたCloudFormationテンプレートを用いてスタック作成を実施します。
パラメータには以下を設定し、他はデフォルトのままにしました。
InfraVPC01-network.yamlで作成した VPC の Id を指定
PrivateSecurityGroup01-network.yamlで作成したOpenflowPrivateSecurityGroupの Id を指定
PrivateSubnet101-network.yamlで作成したComputeSubnet1の Id を指定
PrivateSubnet201-network.yamlで作成したComputeSubnet2の Id を指定
スタック作成が完了すると、デプロイエージェントEC2が起動します。
デプロイエージェントEC2起動時に、Openflowのデプロイ環境となるEKSノードグループやランタイム環境、NLB等が構築されます。
このOpenflowのデプロイ環境構築には約60分程度かかりました。
Snowflake上のOpenflowデプロイメントのステータスが「Inactive」から「Active」になるまで、しばらく待ちます。
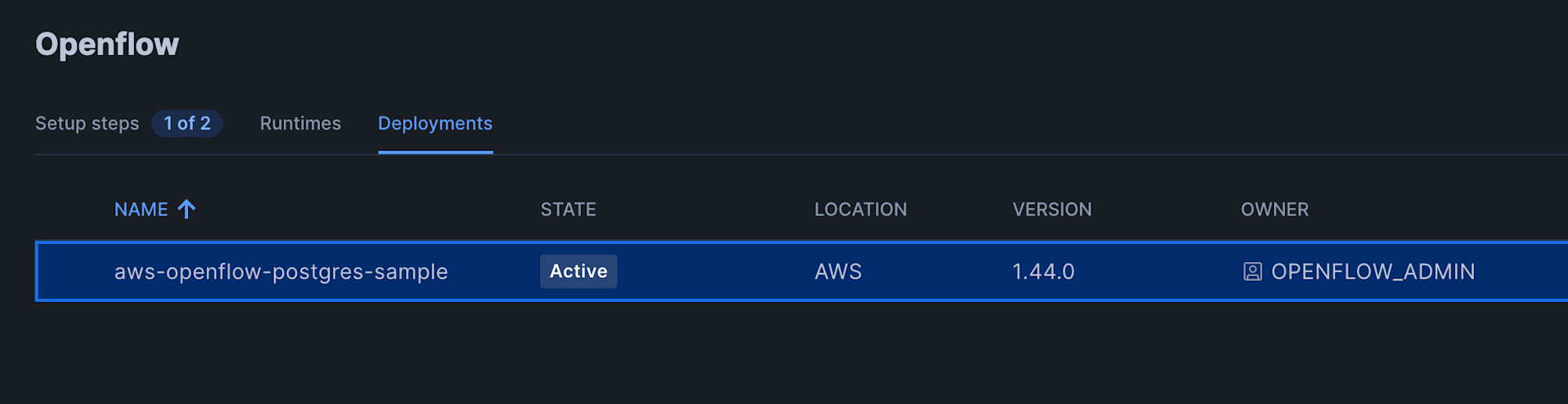
また、デプロイエージェントEC2にログインして、以下のコマンドを実行することで進捗確認することも可能です。
journalctl -xe -f -n 100 -u docker
画面上に All resources applied successfully が表示されていれば必要なリソースは作成されています。
ちなみに、デプロイエージェントEC2作成のスタックの中にEC2 Instance Connect Endpointも作成されていますので、作成されたEC2 Instance Connect Endpointからの22番ポート通信をデプロイエージェントEC2のセキュリティグループで許可すれば、EC2 Instance Connect経由でログインできます。
OpenflowデプロイメントのステータスがActiveになったら、Snowsightにて以下のSQLを実行します。
<deployment_name> は、作成したOpenflowデプロイメント名を指定してください。
(この例でのOpenflowデプロイメント名は aws-openflow-postgres-sample です)
イベントテーブルをデータプレーン統合に紐付け 04-openflow-deployment-telemetry-events-setup.sql
SHOW OPENFLOW DATA PLANE INTEGRATIONS;
ALTER OPENFLOW DATA PLANE INTEGRATION <deployment_name>
SET EVENT_TABLE = 'OPENFLOW.TELEMETRY.EVENTS';
7. コネクタ操作用Snowflakeオブジェクト作成
Openflow Runtime作成の前に、宛先となるSnowflakeデータベース等、
Openflow Connectorが操作するSnowflakeオブジェクトを作成しておきます。
Snowsightにて、以下のSQLを実行します。
SQL内の <your_user> は、作業ユーザ名に置き換えてください。
コネクタ操作用Snowflakeオブジェクト作成 05-openflow-destination-objects-setup.sql
USE ROLE ACCOUNTADMIN;
-- Create database and role for destination
CREATE DATABASE IF NOT EXISTS OPENFLOW_PG_DB
COMMENT = 'Openflow PostgreSQL コネクタの宛先 DB';
CREATE ROLE IF NOT EXISTS OPENFLOW_PG_CONNECTOR_ROLE
COMMENT = 'PostgreSQL コネクタが宛先 DB へ書き込むためのロール';
-- コネクタはスキーマ/テーブルを自動生成するため、DB への USAGE と CREATE SCHEMA を付与
GRANT USAGE ON DATABASE OPENFLOW_PG_DB TO ROLE OPENFLOW_PG_CONNECTOR_ROLE;
GRANT CREATE SCHEMA ON DATABASE OPENFLOW_PG_DB TO ROLE OPENFLOW_PG_CONNECTOR_ROLE;
-- Create warehouse
CREATE WAREHOUSE IF NOT EXISTS OPENFLOW_PG_WH
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE
COMMENT = 'Openflow PostgreSQL コネクタ用ウェアハウス';
GRANT USAGE, OPERATE ON WAREHOUSE OPENFLOW_PG_WH TO ROLE OPENFLOW_PG_CONNECTOR_ROLE;
-- Openflow Runtimeを作成する作業ユーザに対してGrantすることで、
-- ランタイム作成時の画面上のドロップダウンリストに表示させる
GRANT ROLE OPENFLOW_PG_CONNECTOR_ROLE TO USER <your_user>;
8. Openflow Runtime設定
次にOpenflow Runtimeを設定します。
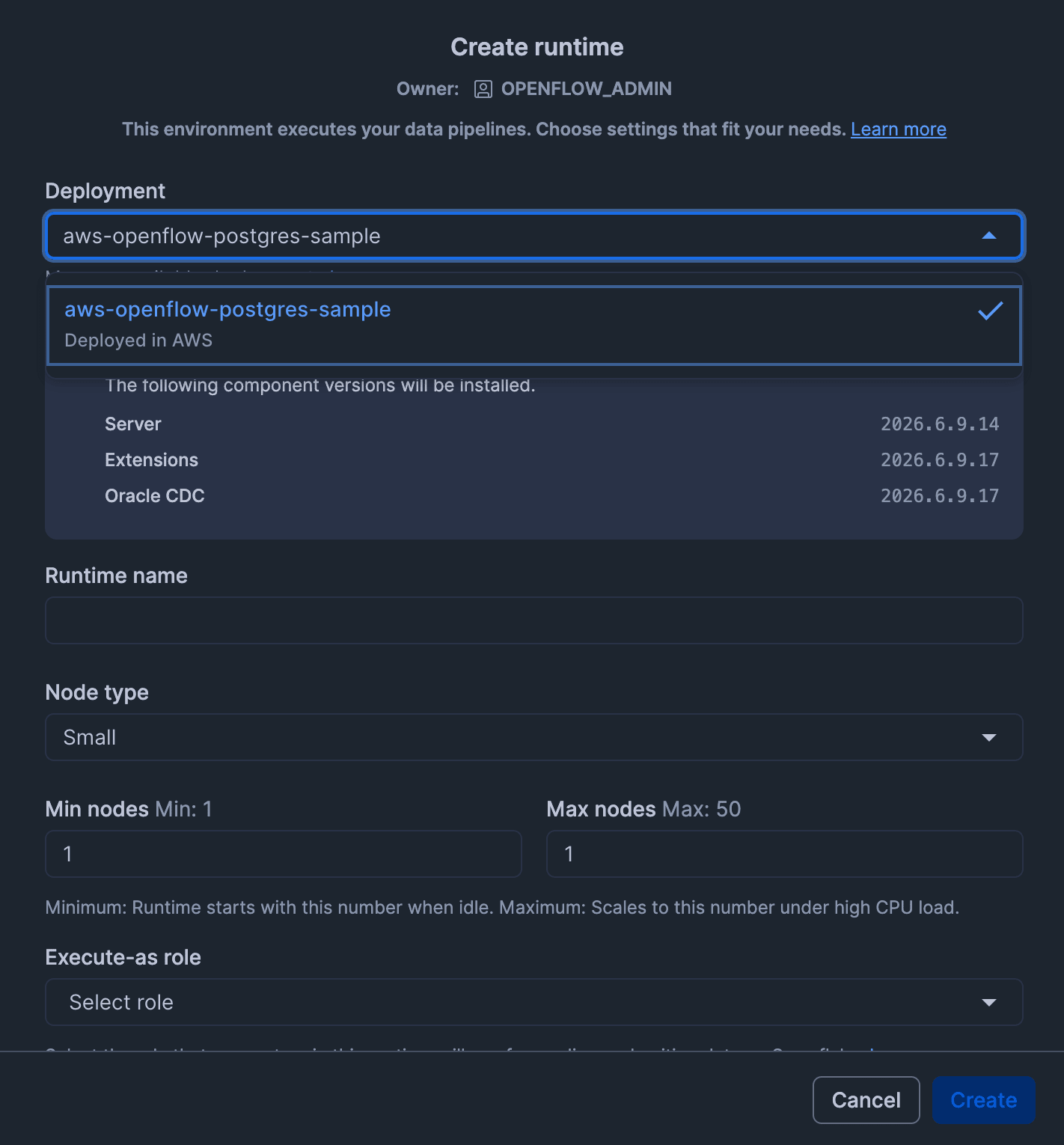
Openflowの画面から「Create a runtime」をクリックします。
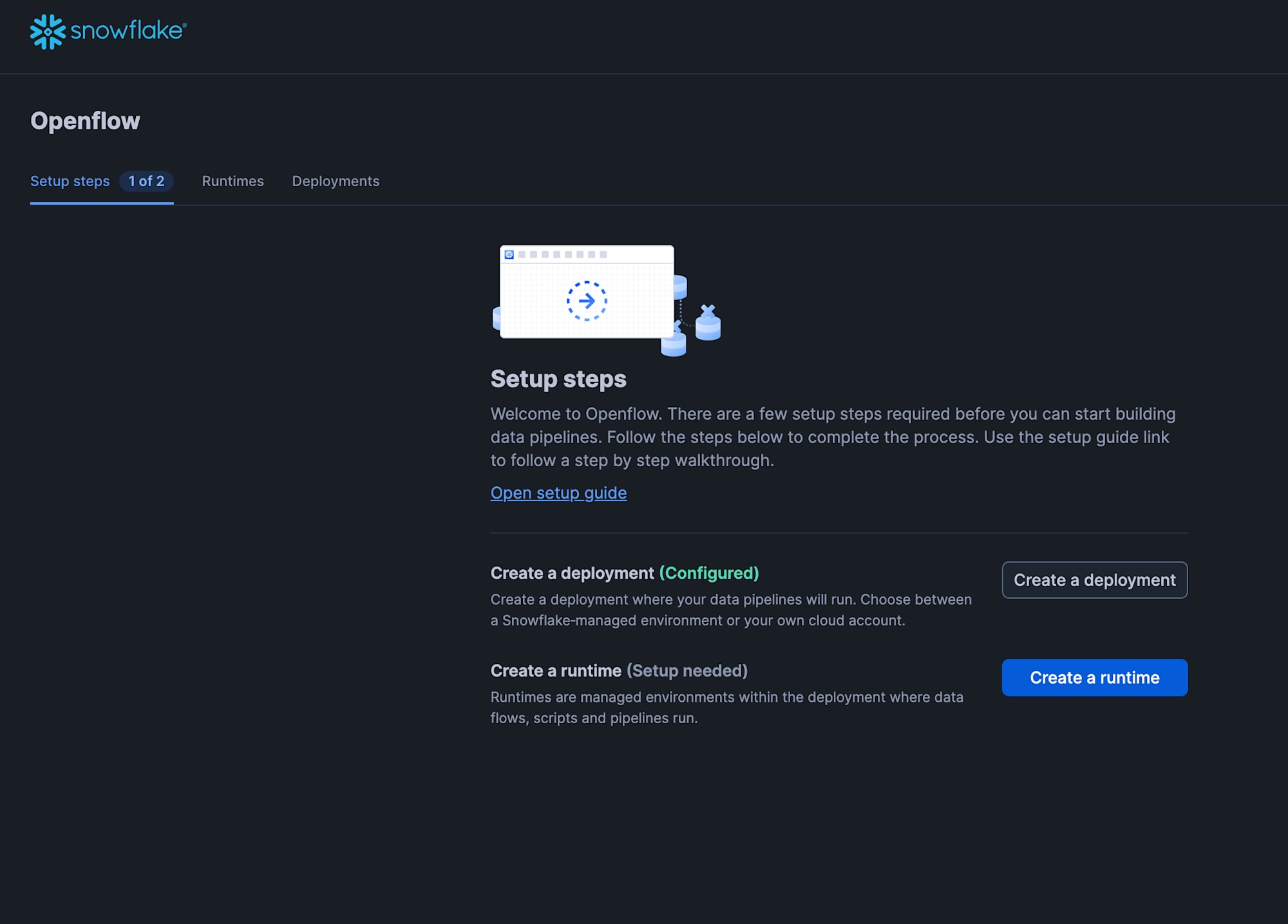
「Create runtime」の画面では以下の設定を行い、「Create」をクリックします。
- Deployment
- 作成したOpenflowデプロイメント名を選択
- Runtime Name
- 適宜入力する
- ここでは
openflow_pg_rtとした
- Node size
- Medium 以上を選択
- ここでは
Mediumを選択した
- Min nodes
- 1
- Max nodes
- 1
- PostgreSQLコネクタ要件により、マルチノードをサポートしていないため、単一ノードとなるようMin nodes/Max nodesとも
1を指定します- 参考: Openflow要件
- Execute-as role
OPENFLOW_PG_CONNECTOR_ROLEを選択
これでランタイムが作成されます。
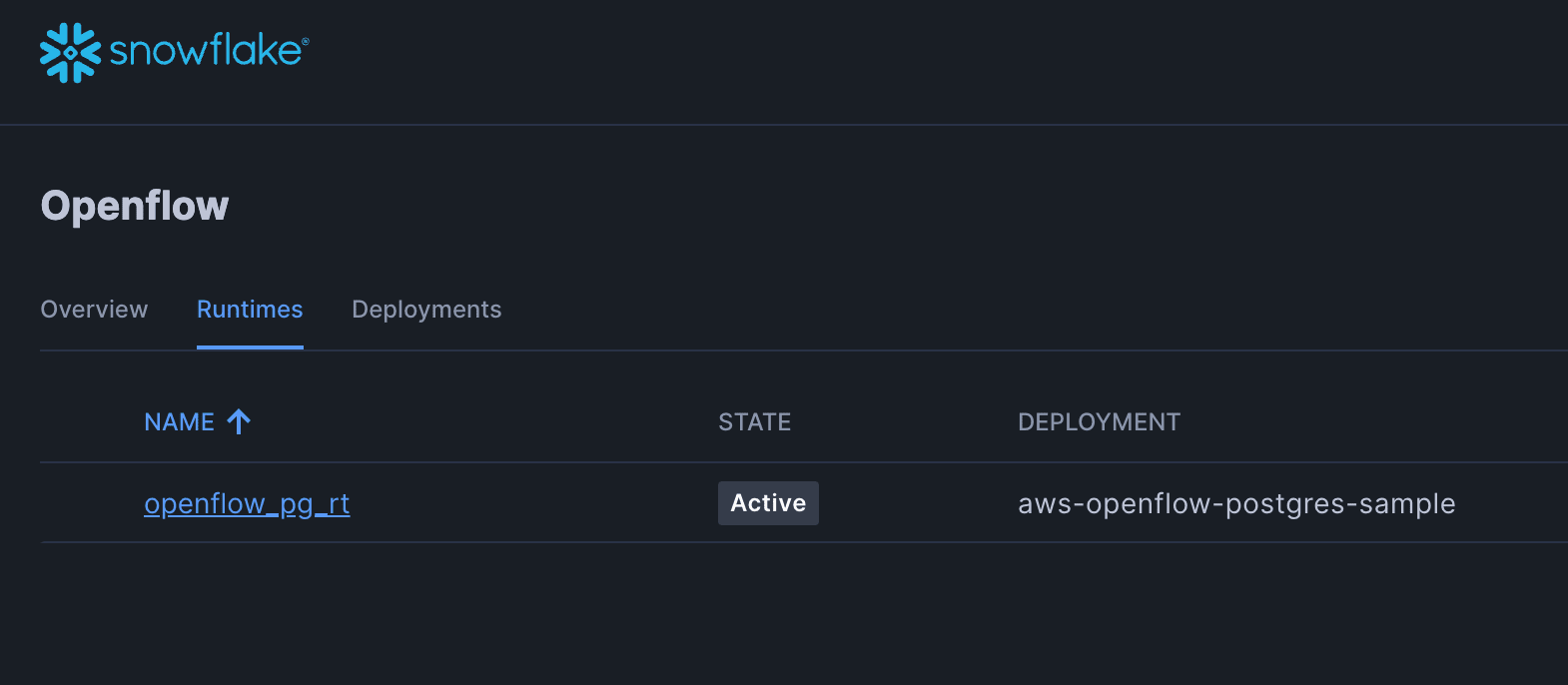
作成には2分程度かかります。ランタイムのステータスが「Active」になるまで待ちましょう。
9. Openflowコネクタ導入
Openflow Runtimeが作成されたら、PostgreSQL用のコネクタを導入します。
Openflowのoverview画面内にある「Featured connectors」に「PostgreSQL」が表示されていれば、そのPostgreSQLパネルの「Install」をクリックします。
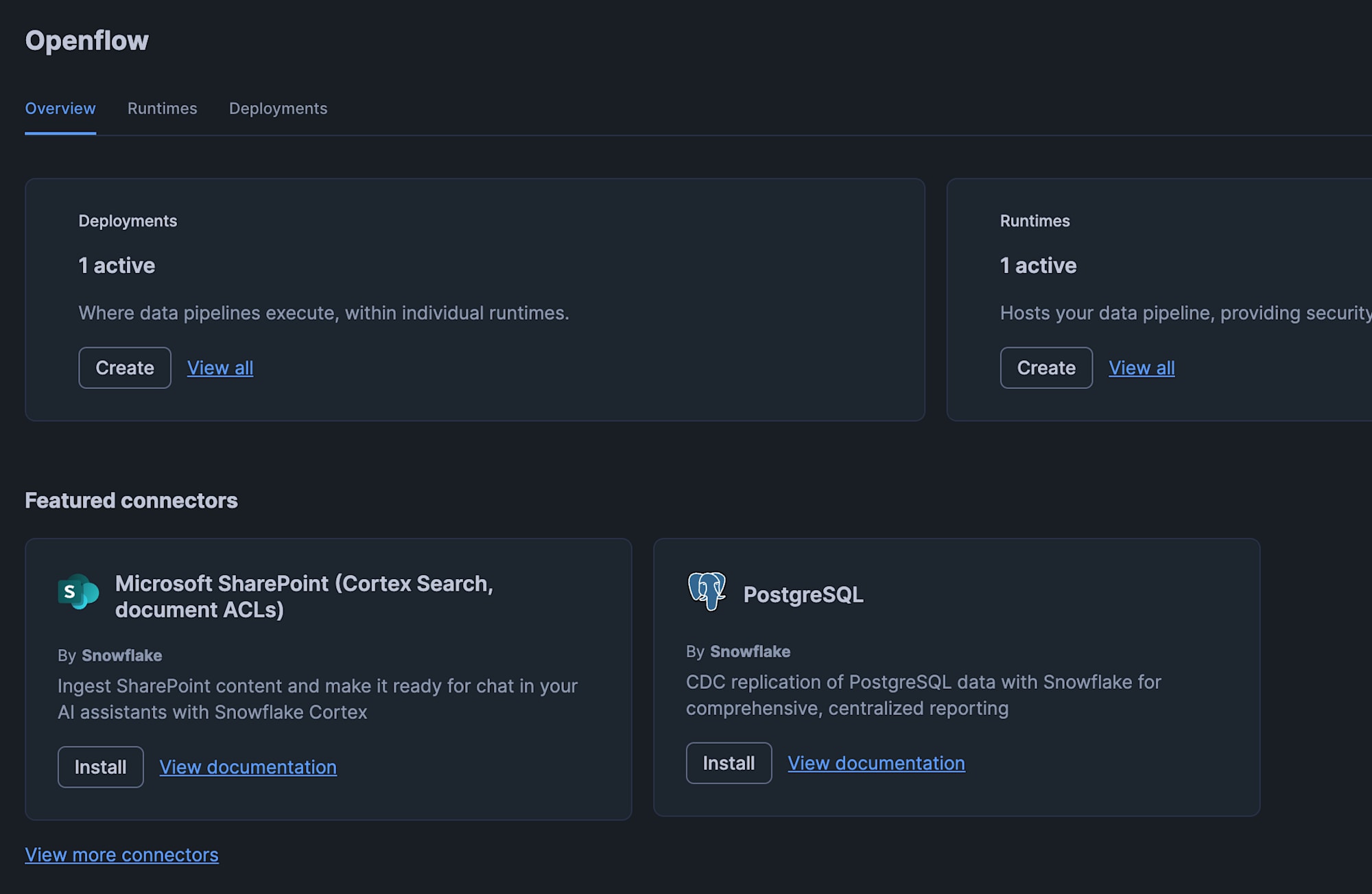
もし表示されていなければ、「View more connectors」リンクをクリックし、コネクタ一覧の中から「PostgreSQL」を検索して同様に「Install」をクリックします。
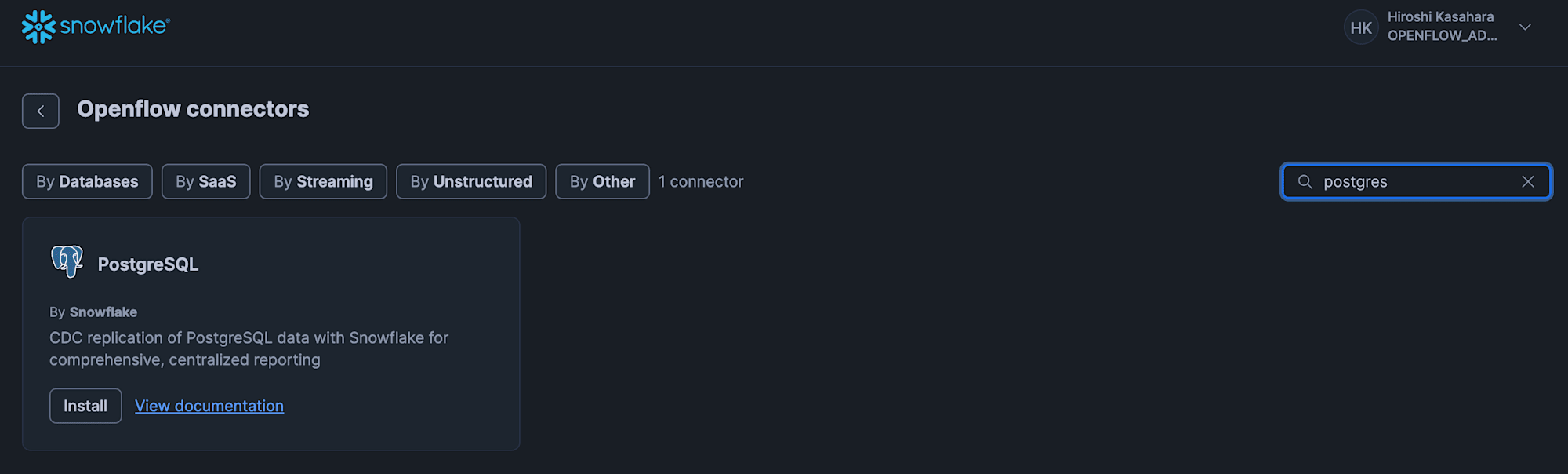
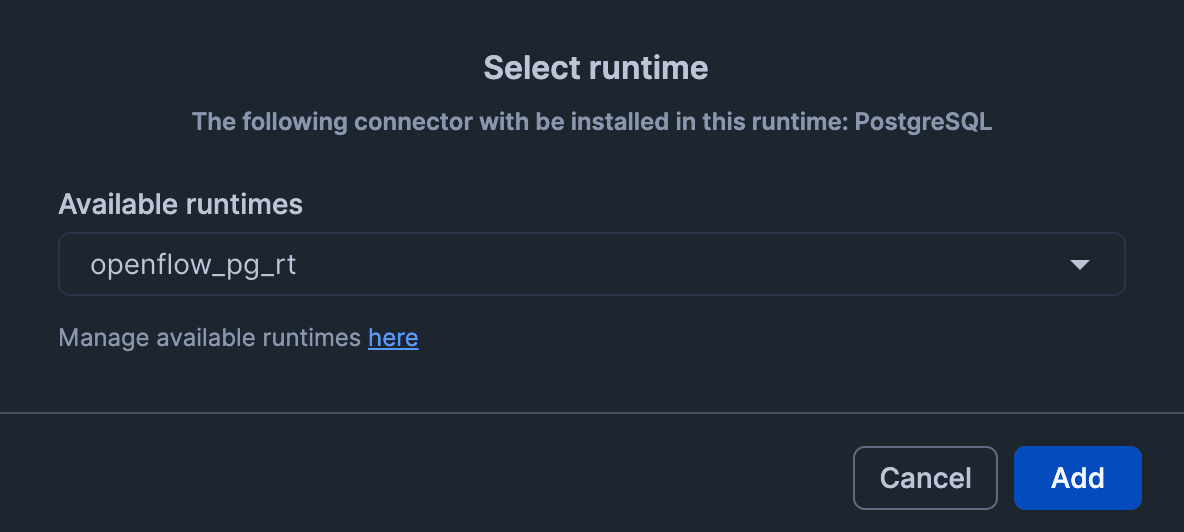
PostgreSQLコネクタインストール先となるOpenflow Runtimeを選択します。
ここでは先ほど作成したOpenflow Runtimeを選択しましょう。
「Add」ボタンをクリックすると、ランタイムにPostgreSQLコネクタが導入されます。
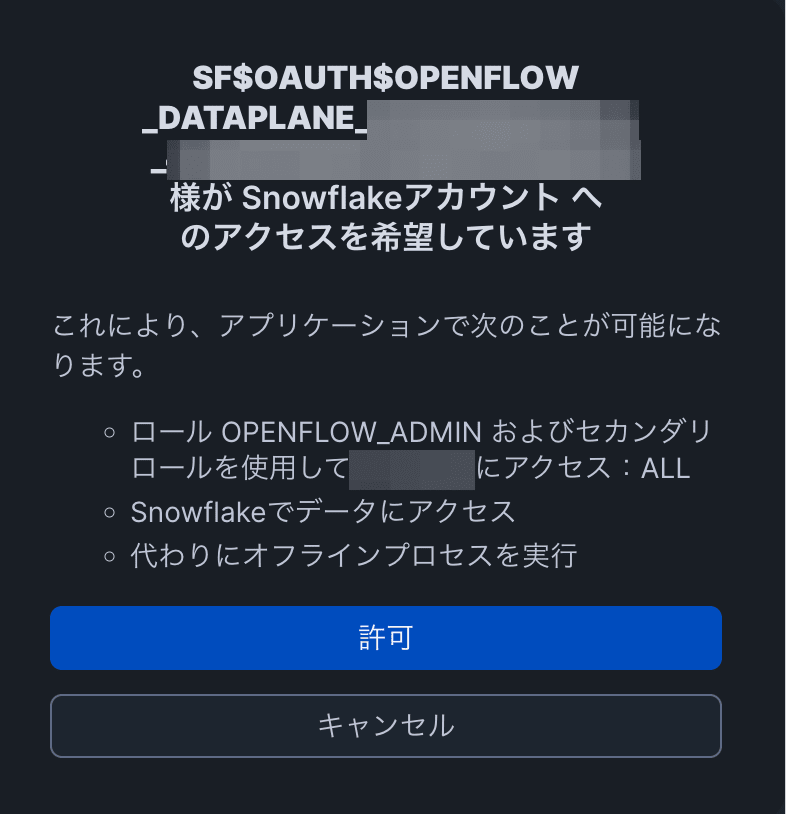
Snowflake 資格情報で認証し、ランタイムのアクセスを許可します。
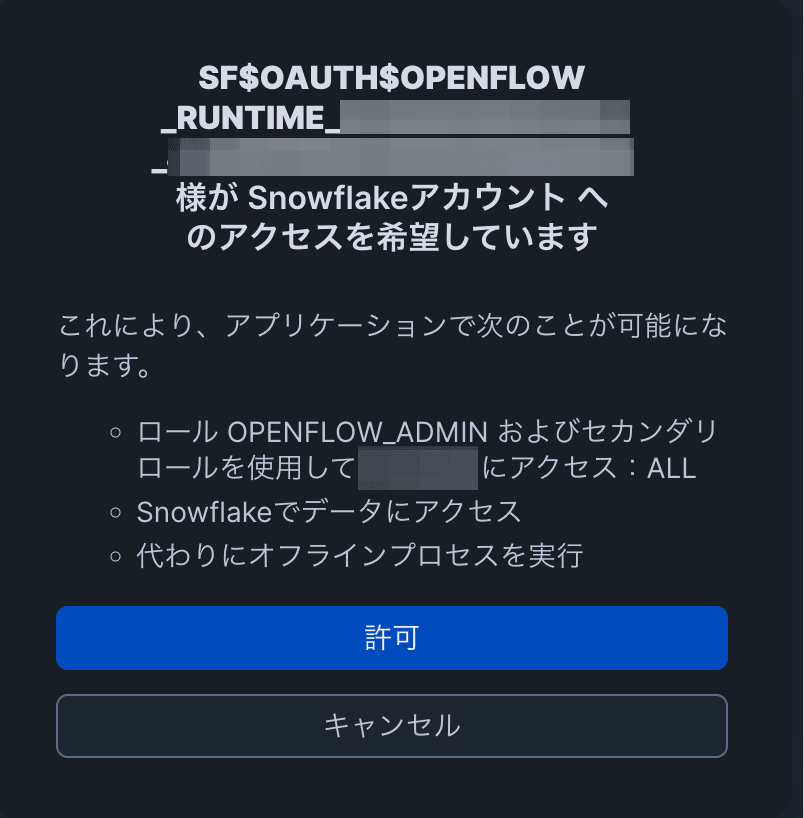
成功すると、キャンバスにコネクタのプロセスグループが表示されます。
なお、ランタイムへのアクセス時に「The role requested has been explicitly blocked for use with this application」と表示されて、ログイン画面に遷移される場合、認証する作業ユーザの DEFAULT_ROLE の設定を変更する必要があります。
03-openflow-deployment-setup.sql の中で設定していますが、この部分の適用がまだの場合は再度設定をしてください。
ALTER USER <your_user> SET DEFAULT_ROLE = OPENFLOW_ADMIN;
ALTER USER <your_user> SET DEFAULT_SECONDARY_ROLES = ('ALL');
10. Openflowコネクタ設定
キャンバス上では、以下の設定を行います。
まず、PostgreSQLと書かれたボックスを右クリックして「Parameters」をクリックします。
Source / Destination / Ingestion の各値を以下のようにし、Source / Destination / Ingestion 毎に「Apply」をクリックして適用します。
「Parameters」クリック時には、Source / Destination / Ingestion パラメータ設定画面のいずれかがポップアップ表示されますので、適宜設定したら別のパラメータ設定に移りましょう。
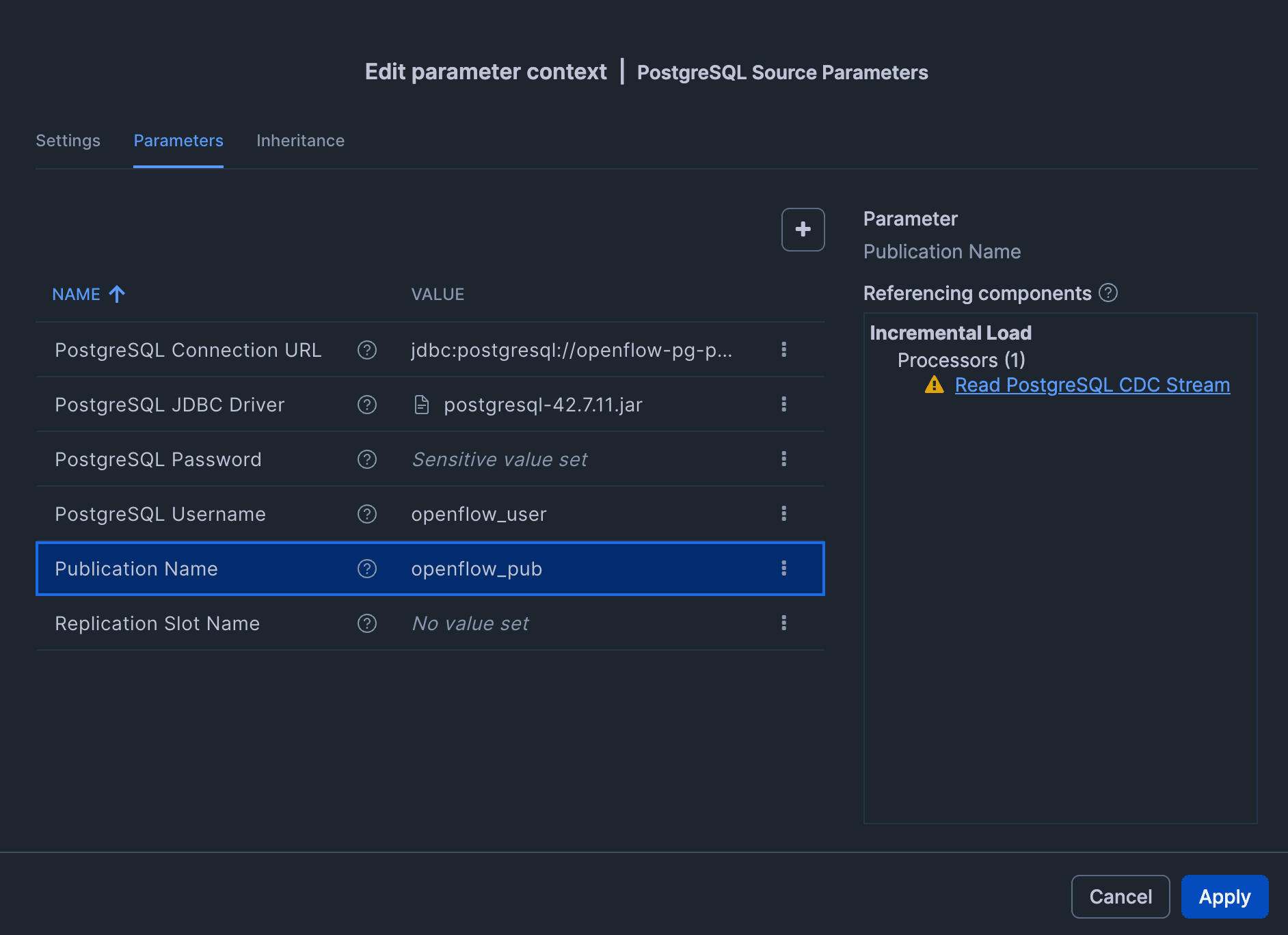
Source (RDS for PostgreSQLへの接続設定)
| パラメータ | 値 |
|---|---|
| PostgreSQL Connection URL | jdbc:postgresql://<RDS endpoint>:5432/appdb |
| PostgreSQL JDBC Driver | postgresql.org の JDBC jar をアップロードして指定 (「Reference asset」にもチェック) |
| PostgreSQL Username | openflow_user |
| PostgreSQL Password | 手順 4. で設定した openflow_user のパスワード |
| Publication Name | openflow_pub |
| Replication Slot Name | 空欄可 (未指定ならコネクタが自動作成) |
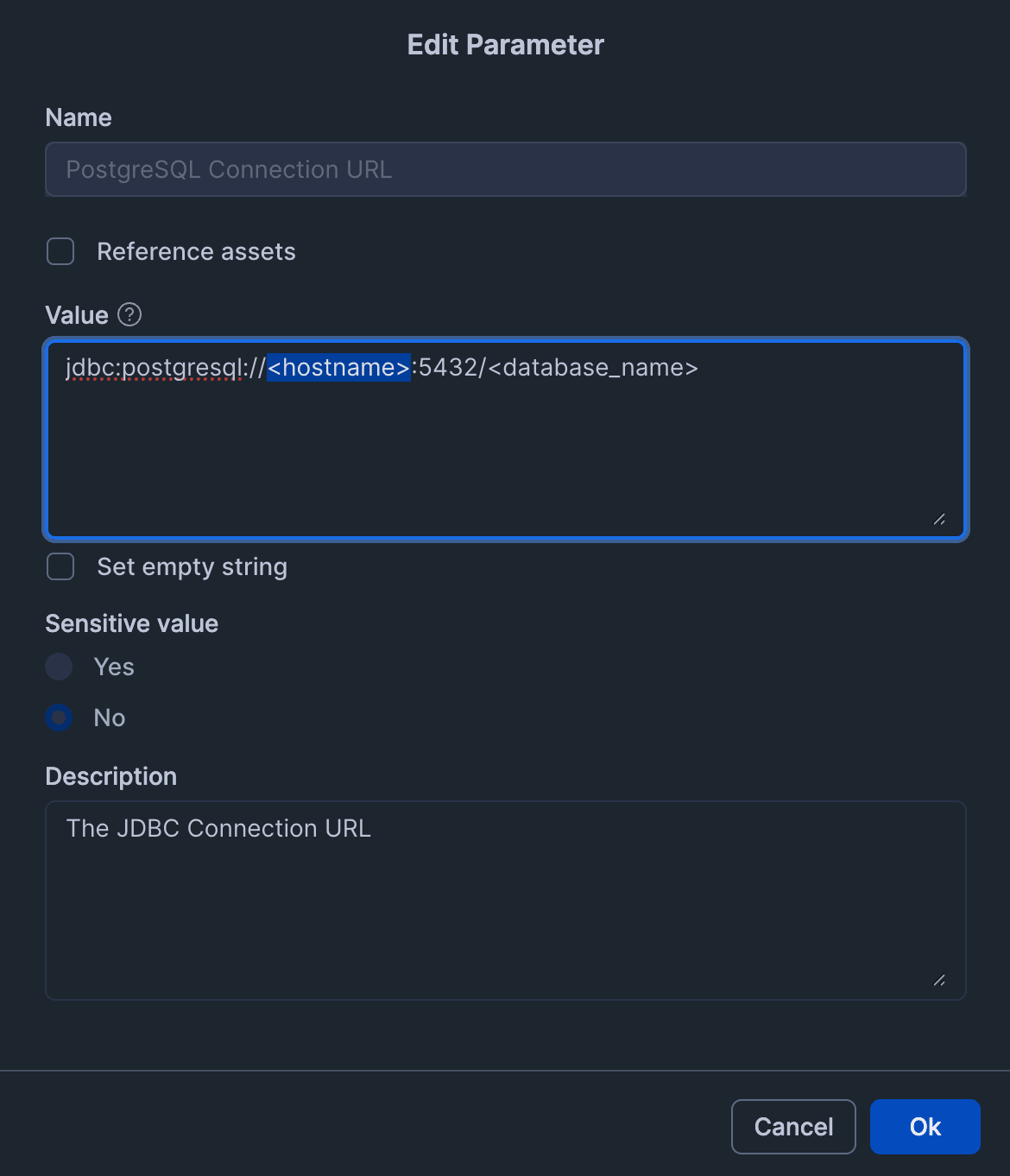
PostgreSQL Connection URL は JDBC の接続文字列を設定します。RDSのエンドポイントがホスト名になりますので、適宜設定しましょう。
PostgreSQL JDBC Driver は、 postgresql.org のWebサイトから JDBC の jar ファイルを取得し、その jar ファイルをアップロードして設定しました。
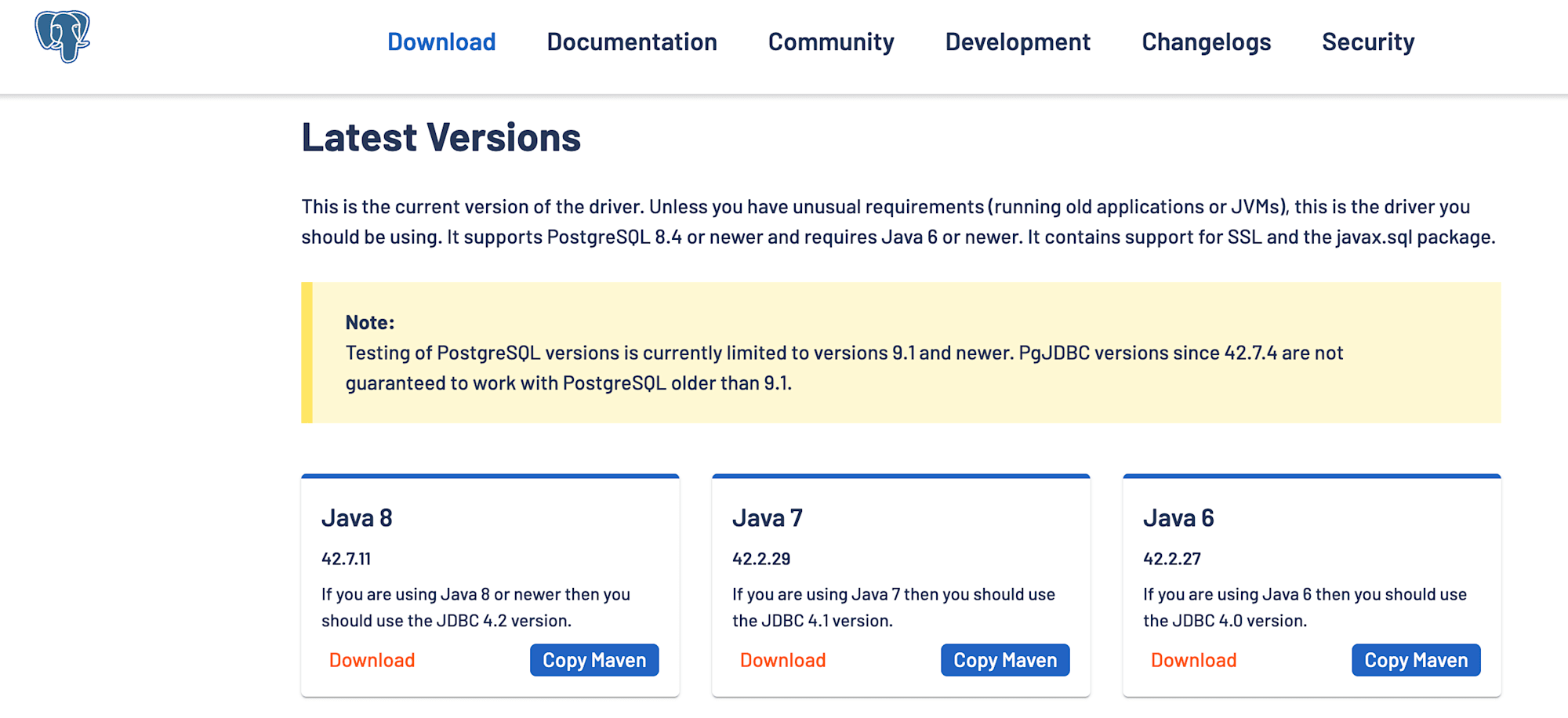
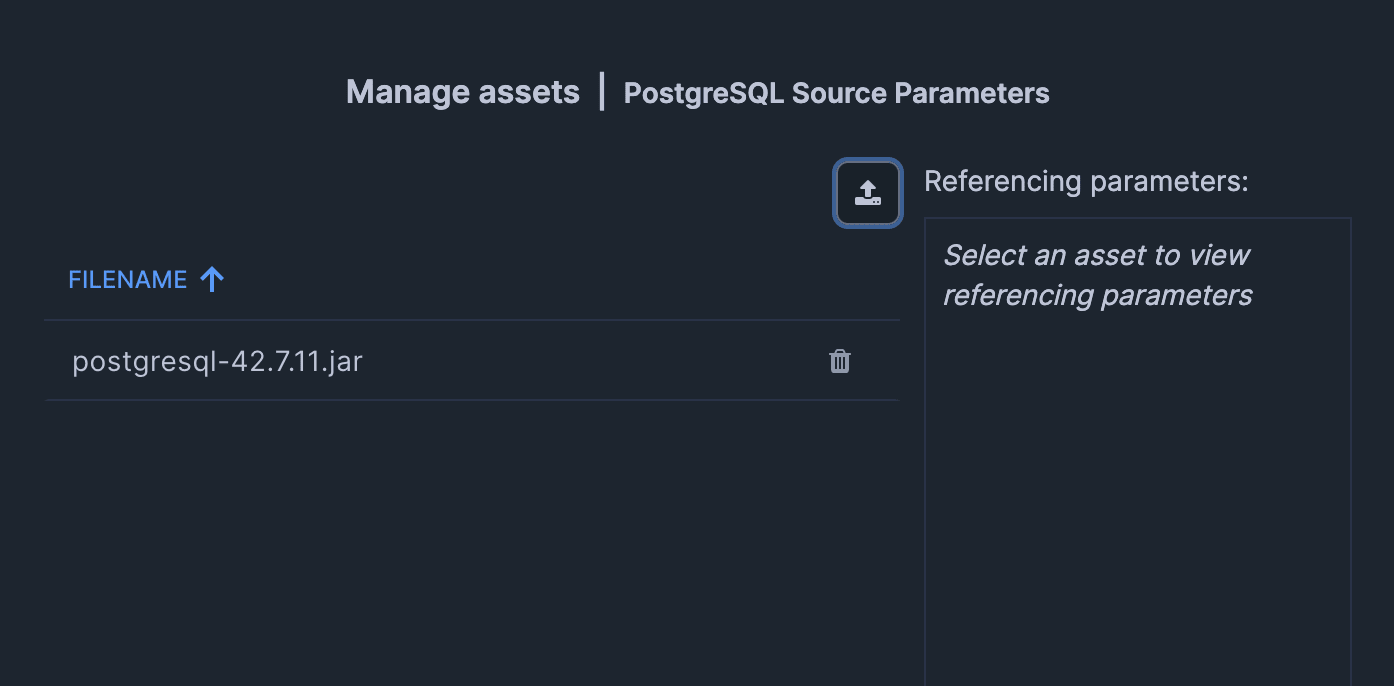
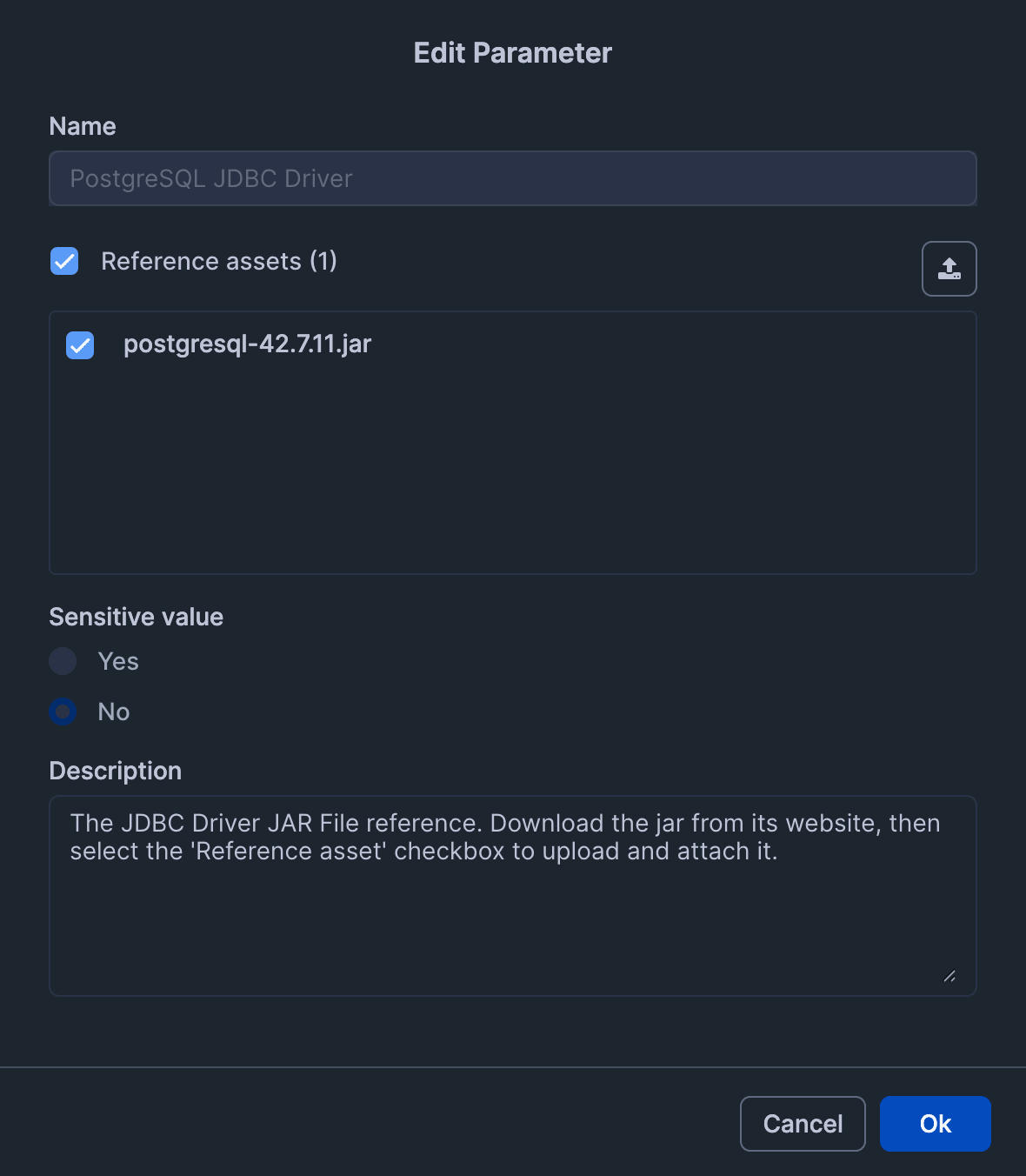
「Reference asset」にもチェックを入れます。
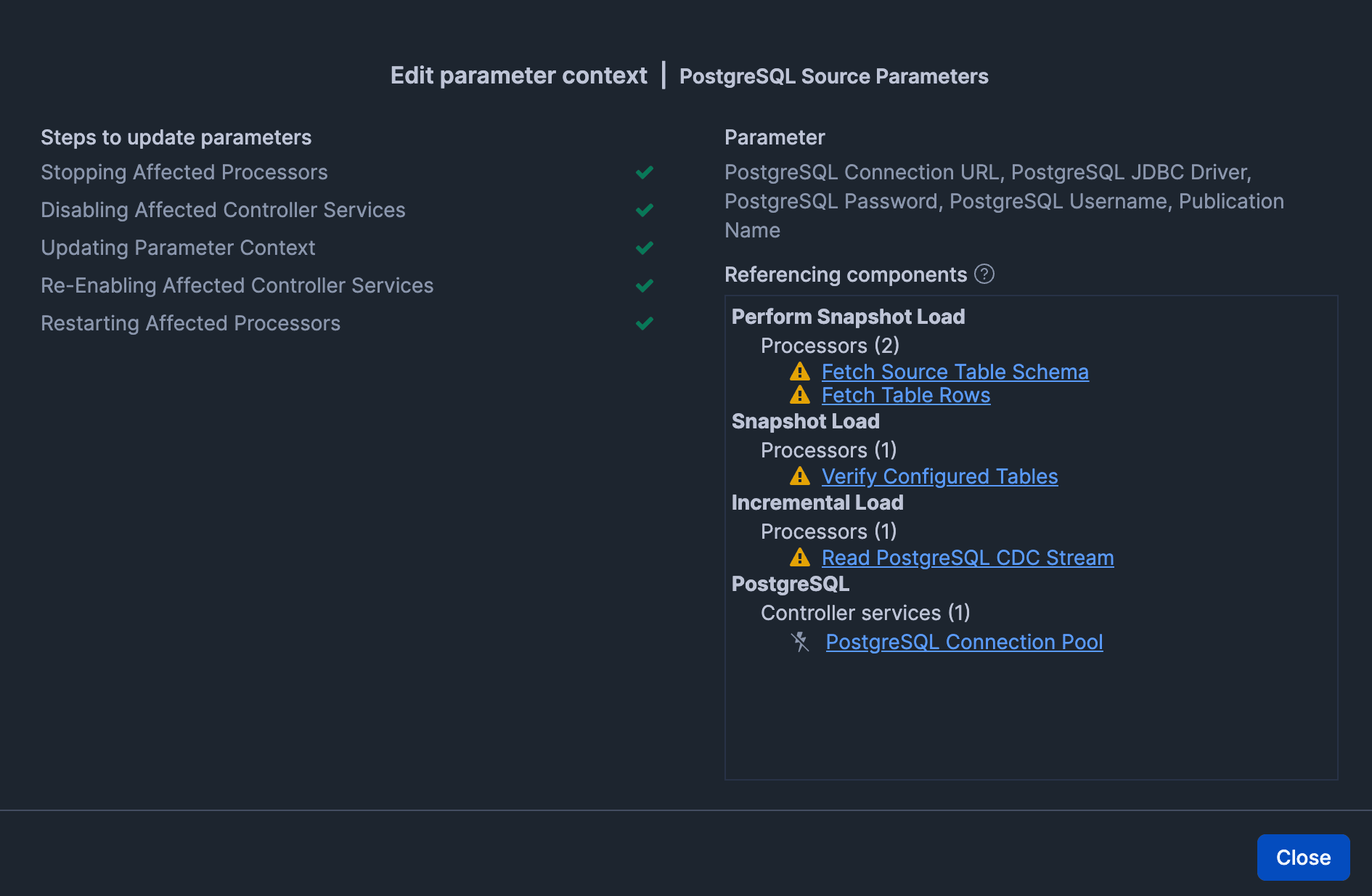
「Apply」後、問題ないことを確認します。
Destination (Snowflakeへの接続設定)
| パラメータ | 値 |
|---|---|
| Destination Database | OPENFLOW_PG_DB |
| Destination Schema Pattern | 例: ${source.schema.name} (ソース側PostgreSQLの app スキーマを再現) |
| Snowflake Authentication Strategy | SNOWFLAKE_MANAGED |
| Snowflake Warehouse | OPENFLOW_PG_WH |
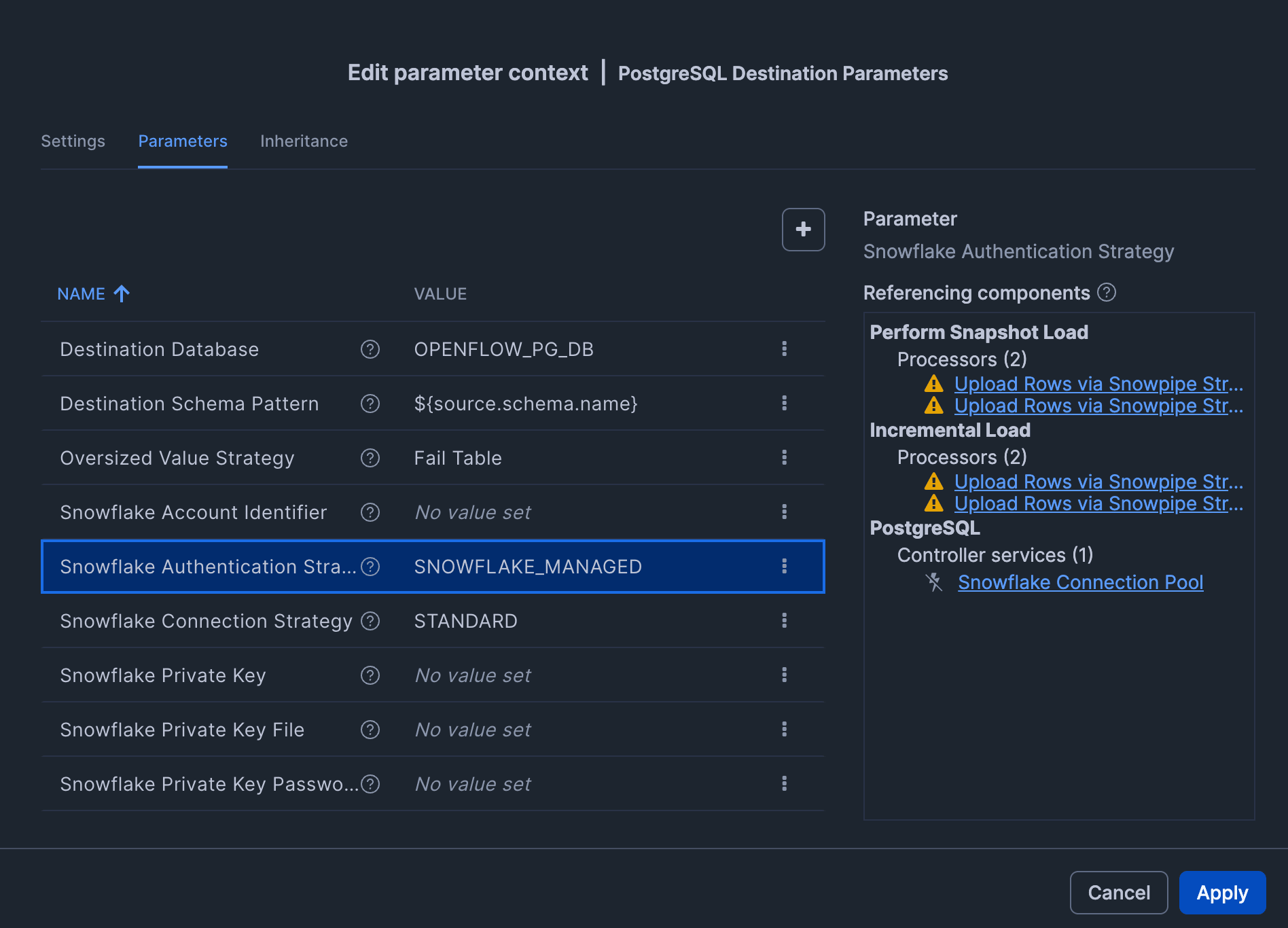
「Snowflake Authentication Strategy」を SNOWFLAKE_MANAGED に設定することで、Openflow Runtime設定の Execute-as role で指定されたロール ( OPENFLOW_PG_CONNECTOR_ROLE ) が認証主体となって動作します。
Ingestion (取り込み設定)
| パラメータ | 値 |
|---|---|
| Included Table Names | app.customers, app.products, app.orders |
| Merge Task Schedule CRON | 例: 0 * * * * ? (今回は検証用なので、毎分取り込みをするように設定しています) |
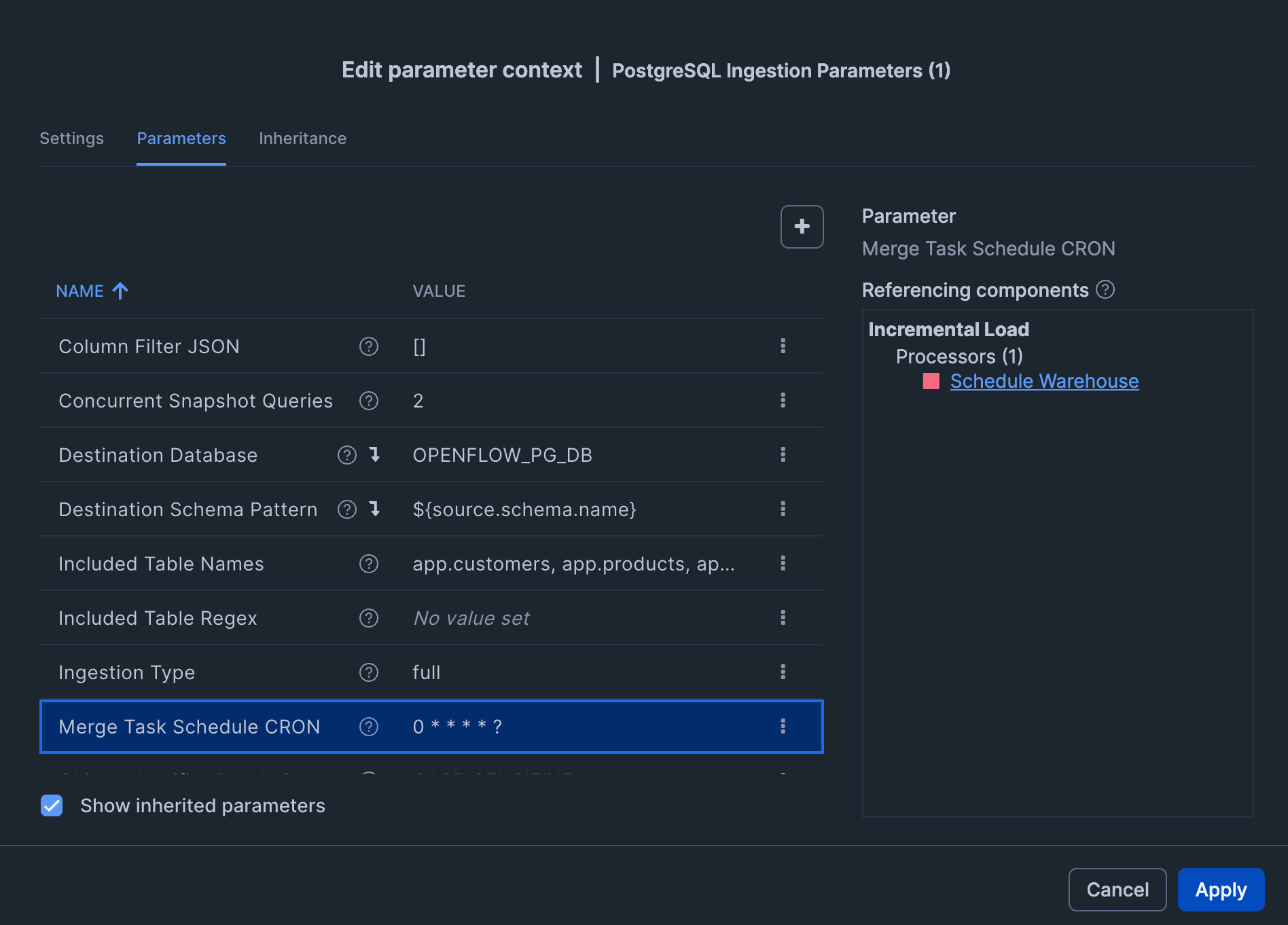
なお、取り込み開始後に「Destination Schema Pattern」「Object Identifier Resolution」を変更しないようにしましょう。
11. フローの開始
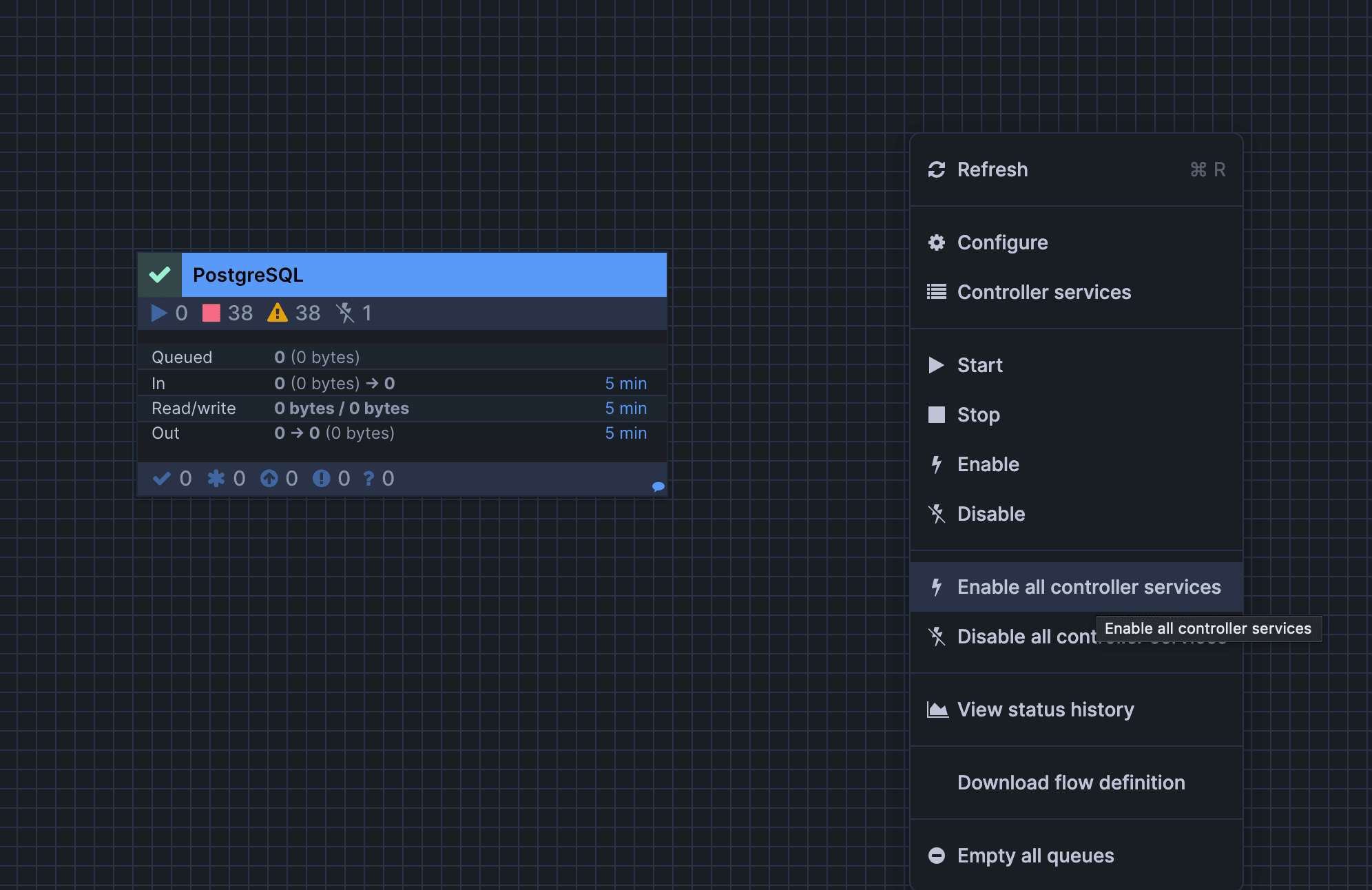
キャンバスのボックスでない部分を右クリックし、「Enable all Controller Services」をクリックします
続いて、キャンバスのボックスを右クリックし、「Start」をクリックします。
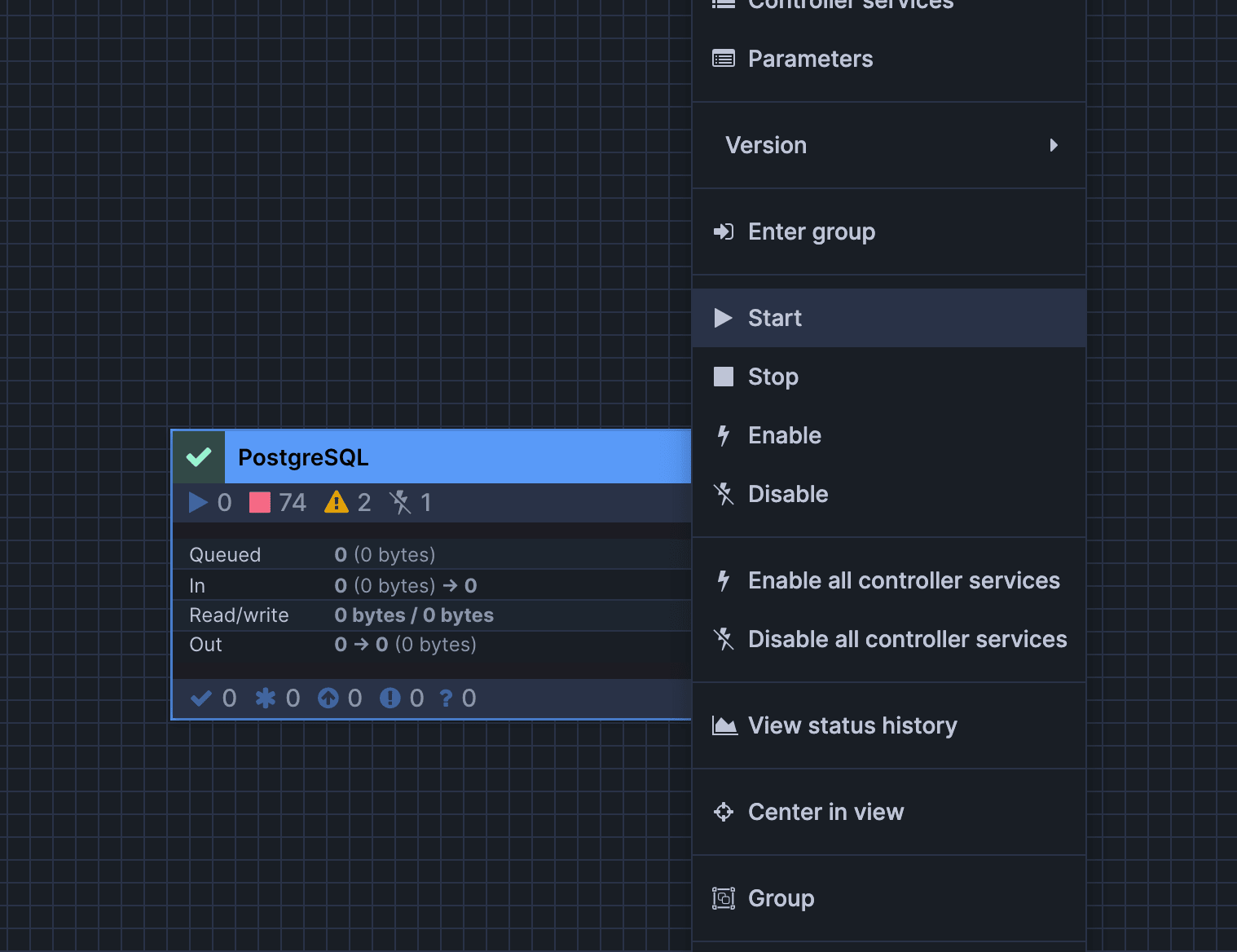
上記の順に実行するとコネクタが起動し、初回スナップショット → 増分(CDC)の順で取り込みを開始します。
動作確認
コネクタが起動したら、動作確認をします。
初回スナップショット
まずは初回スナップショットが成功している確認しましょう。
初回スナップショットが完了すると、PostgreSQLでpublication設定した対象スキーマ app と各テーブルがSnowflake上に反映されていることがわかります。
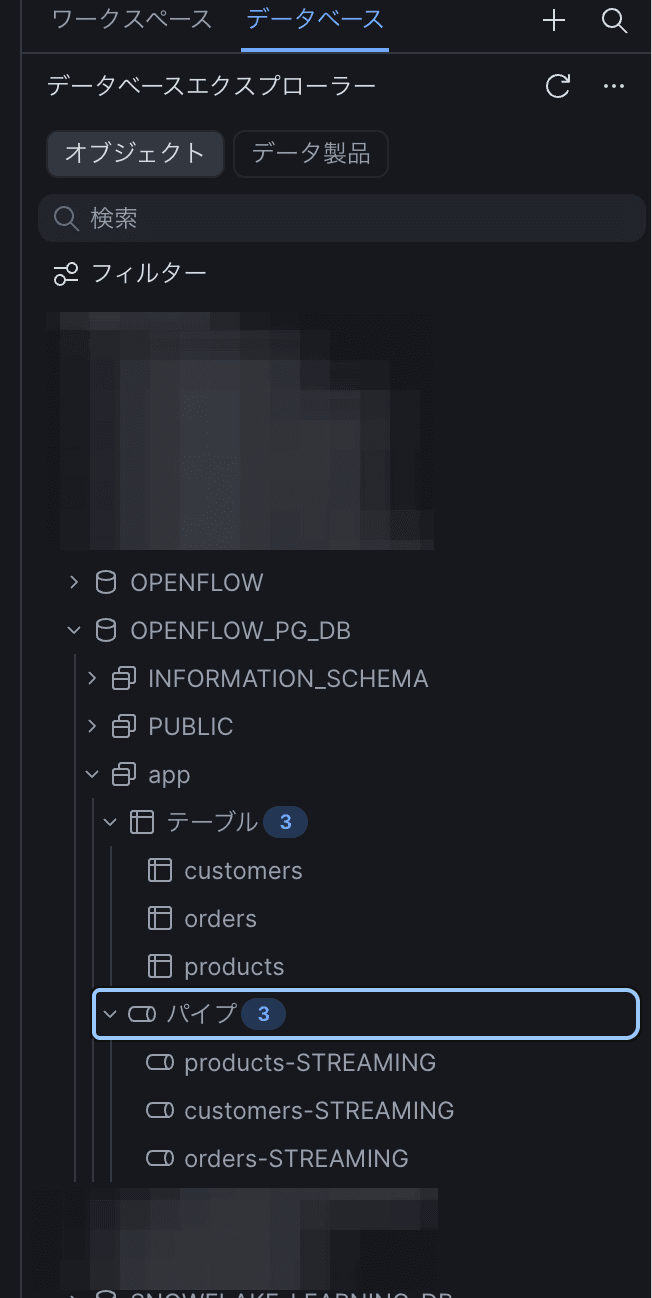
Snowsight上から、以下のSQLを実行してデータ件数を確認しましょう。
初回スナップショット確認
SELECT 'customers' AS t, COUNT(*) FROM OPENFLOW_PG_DB."app"."customers"
UNION ALL SELECT 'products', COUNT(*) FROM OPENFLOW_PG_DB."app"."products"
UNION ALL SELECT 'orders', COUNT(*) FROM OPENFLOW_PG_DB."app"."orders"
ORDER BY t;
PostgreSQLに格納されているデータ件数と一致しているはずです。
ちなみに、コネクタの取り込み設定の一つである「Object Identifier Resolution」のデフォルト設定が CASE_SENSITIVE であるため、今回はPostgreSQLから取り込まれたSnowflakeのスキーマ名やテーブル名は大文字小文字を区別します。そのため、小文字をダブルクォート " で括っています。
CDC (差分転送)
次に、ソース側のPostgreSQLにてデータ更新を行い、その内容がSnowflakeへ反映されているか確認します。
PostgreSQLへ以下のSQLクエリを実行して、データの変更を行いました。
データ変更
-- insert
INSERT INTO app.customers (name, email) VALUES
('Saburo Sato', 'saburo@example.com');
INSERT INTO app.orders (customer_id, product_id, quantity, status) VALUES
(4, 1, 5, 'pending'); -- 上で追加した customer_id=4 を参照
-- update
UPDATE app.products
SET in_stock = true, price = 27800.00
WHERE name = 'Monitor';
UPDATE app.orders
SET status = 'shipped'
WHERE order_id = 2;
-- delete
DELETE FROM app.orders
WHERE order_id = 3;
-- check count
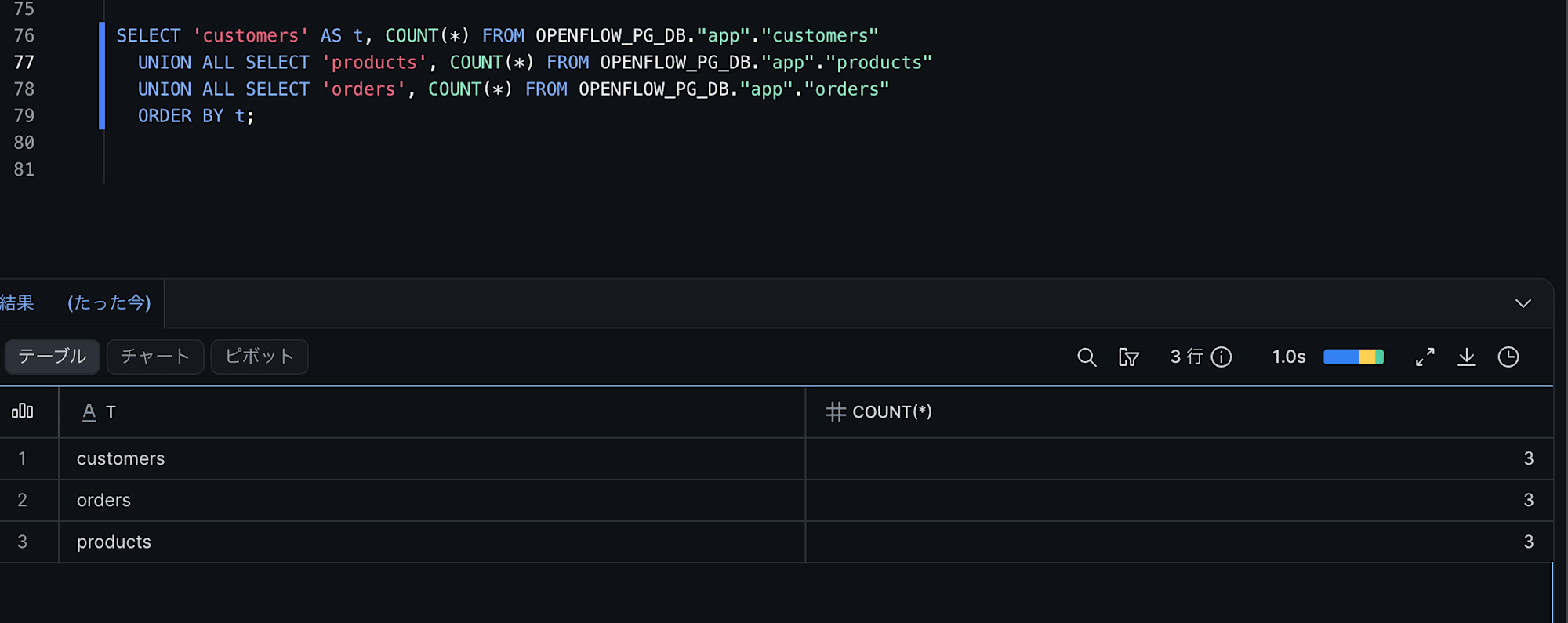
SELECT 'customers' AS t, count(*) FROM app.customers
UNION ALL SELECT 'products', count(*) FROM app.products
UNION ALL SELECT 'orders', count(*) FROM app.orders;
そして、Openflowコネクタの「Merge Task Schedule」のcronで設定した間隔 (今回は毎分連携なので約1分) だけ待ってから Snowflake に反映されているか確認しましょう。
データ変更反映確認
-- 件数の変化確認 (insert / delete)
SELECT 'customers' AS t, COUNT(*) FROM OPENFLOW_PG_DB."app"."customers" -- 3 -> 4 (INSERT)
UNION ALL SELECT 'orders', COUNT(*) FROM OPENFLOW_PG_DB."app"."orders" -- INSERT 1, DELETE 1
ORDER BY t;
-- 更新の変化確認 (update)
SELECT "product_id", "name", "price", "in_stock"
FROM OPENFLOW_PG_DB."app"."products"
WHERE "name" = 'Monitor'; -- price=27800.00, in_stock=TRUE になっていること
-- メタデータ列確認
SELECT "order_id", "status",
"_SNOWFLAKE_INSERTED_AT",
"_SNOWFLAKE_UPDATED_AT",
"_SNOWFLAKE_DELETED"
FROM OPENFLOW_PG_DB."app"."orders"
ORDER BY "order_id";
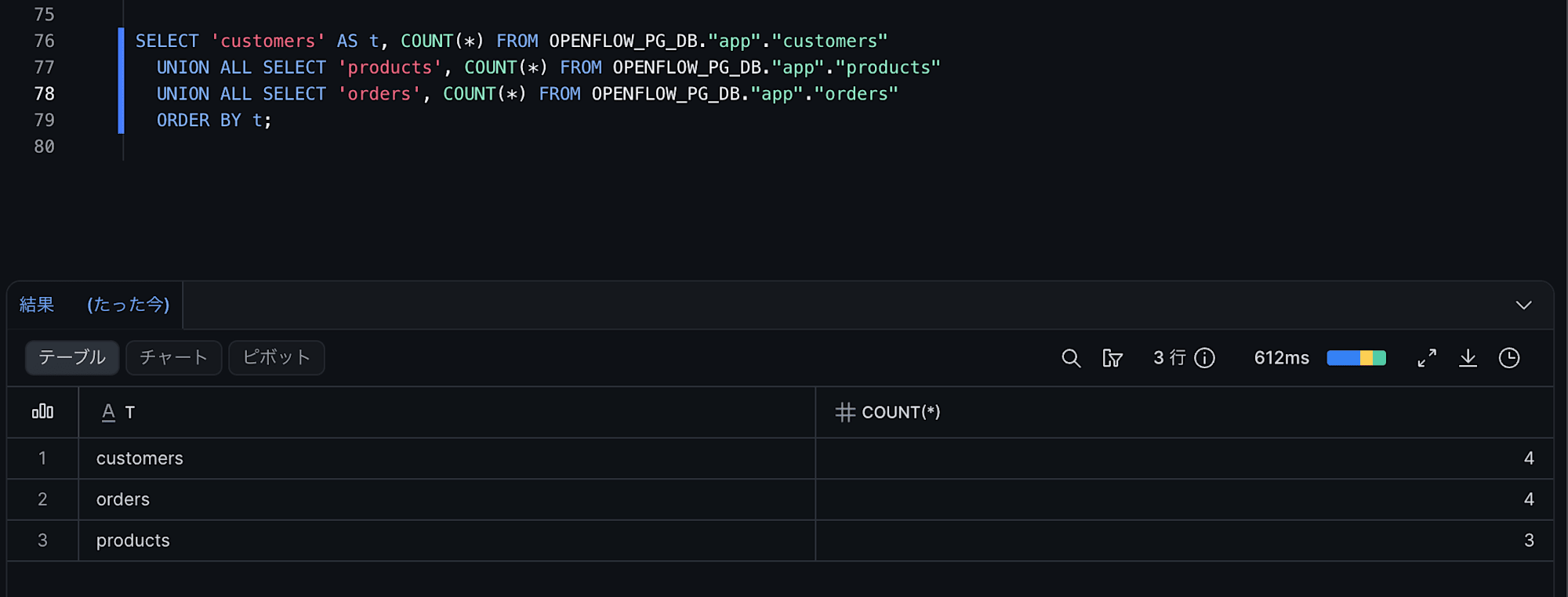
各行にはメタデータ列が設定されているので、以下の内容が反映されているはずです。
order_id=2status='shipped'に更新され_SNOWFLAKE_UPDATED_ATが入る
order_id=3- DELETE が反映され
_SNOWFLAKE_DELETEDが TRUE(論理削除)
- DELETE が反映され
- 新規
order_id(order_id=4)- INSERT され
_SNOWFLAKE_INSERTED_ATが入る
- INSERT され
まとめ
いかがでしたが。
Snowflake Openflow Connector for PostgreSQLをAWS上にBYOCで導入してみました。
事前の設定に思いのほか苦労しましたが、まずは何とか動くところまでは確認できました。
OpenflowのRuntimeからはSnowflakeへのOutbound通信だけでなく、Connector設定のためにInbound通信も必要という点は注意が必要そうです。
デフォルトではパブリックサブネット上にIngress用のNLBが構築されますが、公式ドキュメントにはプライベートサブネット上にIngress用のNLBが構築できる設定も記載されていますので、いずれこちらの動作も確認したいと思います。
この記事がお役に立てれば幸いです。









