
Amazon Quick の Chat Agent のデータサイズの制限を整理してみた
クラウド事業本部の石川です。Amazon Quick(旧 Quick Suite)には、Chat Agentと呼ばれるエージェント型 AI チャット機能が搭載されており、トピックやデータセット、ダッシュボードを対象に自然言語で質問することができます。
ところが、いざ実運用に組み込もうとすると「データセットが大きすぎてチャット対象にならない」「ファイルをアップロードしたら謎の文字数エラーが出る」など、ドキュメントを読み込まないと気付きにくい制限事項に遭遇することが少なくありません。しかし、先日のアップデートでそれも過去のものとなりました。
本記事では、Chat Agent におけるデータソース・データセット周りの制限事項を、公式ドキュメントの最新情報をベースに整理します。実装前に「ハマりどころ」を把握しておくと、データの取り込み方針やトピック設計で迷うことが減るはずです。
Amazon Quick と Chat Agent とは
Amazon Quick は、AWS のビジネスインテリジェンス(BI)/エージェント型 AI プラットフォームです。従来からの BI ダッシュボード機能(Quick Sight)に加えて、自然言語チャット(Chat Agent)、ナレッジベース、Space(コラボレーション領域)といったエージェント型 AI 機能が統合されています。
Chat Agent はその中核機能で、SPICE データセットや一部の Direct Query データソース、トピック、ダッシュボード、ナレッジベース、アップロードしたファイルなどを対象に、自然言語で質問・分析を行うことができます。
データソース・データセットに関する制限
2026/5/4から、Chat Agent でデータセットの指定が可能になりました。従来のTopic Q&A(業務語彙を Topic としてキュレーション)、ダッシュボードQ&A(既存ダッシュボード内での Q&A)に加え、データセットへ直接自然言語で質問できる「Dataset Q&A」、いわゆる text-to-SQL 型のエージェント機能です。
Dataset Q&Aでは、いわゆる text-to-SQL 型のエージェント機能であるがゆえに格段に制限が緩和されています。Dataset Q&A の挙動はデータセットのモード(SPICE / Direct Query)で大きく変わります。
| 観点 | Direct Query データセット | SPICE データセット |
|---|---|---|
| 行数制限 | なし(データセット全体に対して集計) | SPICE 容量の範囲内 |
| Standard Edition の上限 | — | 25,000,000 行 / 25 GB |
| Enterprise Edition の上限 | — | 2,000,000,000 行 / 2 TB |
| ビジュアル生成タイムアウト | 2 分(Quick 側) | in-memory のため通常は高速 |
| 集計対象 | データソースの全データ | SPICE に取り込み済みの全行 |
AWS Machine Learning Blog および Amazon Quick ユーザーガイドの該当箇所に明記されている内容です。
"Dataset Q&A has no row limits for direct query datasets, so aggregations reflect the complete dataset."
(Introducing Dataset Q&A - AWS ML Blog)
"For SPICE datasets, the size limit of 2 TB and 2 billion rows applies when chatting with the dataset."
(Ask questions, explore data, and get insights with chat - Amazon Quick User Guide)
つまり、Dataset Q&A 専用の独自上限が新設されたわけではなく、既存の SPICE/Direct Query のクォータがそのまま適用される という理解で問題ありません。
Chat Agent 対象の SPICE データセットサイズ
公式ドキュメントによると、SPICE データセットを Chat Agent で対象にする場合、1 データセットあたり 2 TB および 20 億行 のサイズ制限が適用されます。
Direct Query データソースの Chat Agent 対応状況
Chat Agent における Direct Query 対応は、データソース種別ごとに異なります。公式ドキュメントでは、Chat Agent で利用可能な Direct Query データソースとして次の 4 種類が明記されています。
- Amazon Redshift
- Amazon Athena
- Aurora PostgreSQL
- Amazon S3 Tables
それ以外のデータソース(一般的な RDB やサードパーティ製 SaaS など)に対する Direct Query データセットは、現時点では Chat Agent の対象外です。「Direct Query なら一律で使えない」ではなく、「対応データソースが限定されている」というのが正確な理解になります。
オンプレミスや MySQL・SQL Server などを Direct Query で繋いでいるケースでは、Chat Agent を前提とするなら SPICE へのインポートを検討する必要があります。
ファイルアップロードに関する制限
チャットウィンドウにファイルをドラッグして質問する場合の制限は、公式ドキュメントに明示されています。
| 項目 | 制限値 |
|---|---|
| 1 回あたりの最大ファイル数 | 20 ファイル |
| 画像(.jpeg, .png) | 10 MB |
| スプレッドシート(.csv, .xls, .xlsx) | 10 MB |
| その他のサポート形式(PDF, Word, PowerPoint など) | 50 MB |
| パース後の総文字数 | 665,000 文字未満 |
| 音声・動画ファイル | 非対応 |
| 会話の保持期間 | 非アクティブ 90 日後に削除(添付ファイルも同時削除) |
665,000 文字制限という最大の落とし穴
このうち実務で最も引っかかりやすいのが、パース後の総文字数 665,000 文字 の制限です。5 MB 以下のファイルでもアップロードに失敗し、exceeds the 665,000 character count limit. Try uploading to a Space. というエラーが出ることがあります。
ファイル容量自体は小さくても、テキスト密度が高い CSV や JSON などはパース後の文字数で先にリミットに到達します。容量制限より文字数制限の方が先に効く という認識を持っておくとよいでしょう。
その他、アップロードしたファイルは個別削除ができず、会話全体を消すしかない点にも注意が必要です。
ファイル + 構造化データに対する精度の限界
これは「エラーになる」系の制限ではないですが、実運用上は最も重要な落とし穴です。
ファイルアップロード + チャット体験は、探索と要約を意図したものであり、決定論的・行単位の正確なクエリ用ではない。「このメールアドレスで購入された製品は?」 のような質問では、ファイルサイズや複雑さが増すにつれて、レコードの取りこぼし、部分一致、推論された詳細が発生するのが一般的。これは構造化データに対するドキュメントベース RAG クエリの本質的な限界です。
CSV や Excel をチャットに直接投げると、内部的には RAG として扱われます。件数集計や合計値のような正確性が必要な用途では、データセットとして正規に取り込む べき、というのが結論です。
Space にアップロードした場合の制限
チャットのファイルアップロード制限に引っかかった場合の代替手段として、ファイルを Space にアップロードする方法があります。Space は資料・データを保管してチャット対象にできるコラボレーション領域です。
Space のファイルアップロード制限は次のとおりです。
| 項目 | 制限値 |
|---|---|
| PDF / Word / PowerPoint | 500 MB |
| その他のサポート形式 | 50 MB |
| 1 Space あたりの最大ファイル数 | 10,000 ファイル |
| 1 Space あたりの合計ストレージ | 10 GB |
| 1 Space あたりの各リソース(dashboard / topic / knowledge base / action) | 各 20 件まで |
PDF・Word・PowerPoint は 500 MB まで対応するなど、チャットへの直接アップロードよりも上限が大きく設計されています。一方、合計ストレージは 10 GB までというキャップがあるため、大量のファイルを扱う場合は分割や整理が必要です。
なお、インデックスデータストレージ容量が満杯になっていると、Space へのファイルアップロード自体が拒否されます。実際に Failed to start upload for XXX.pdf: Index is full. Please request index capacity increase or contact your administrator というエラーが日本のコミュニティでも報告されています。
Dataset Q&A を大規模データで試してみた
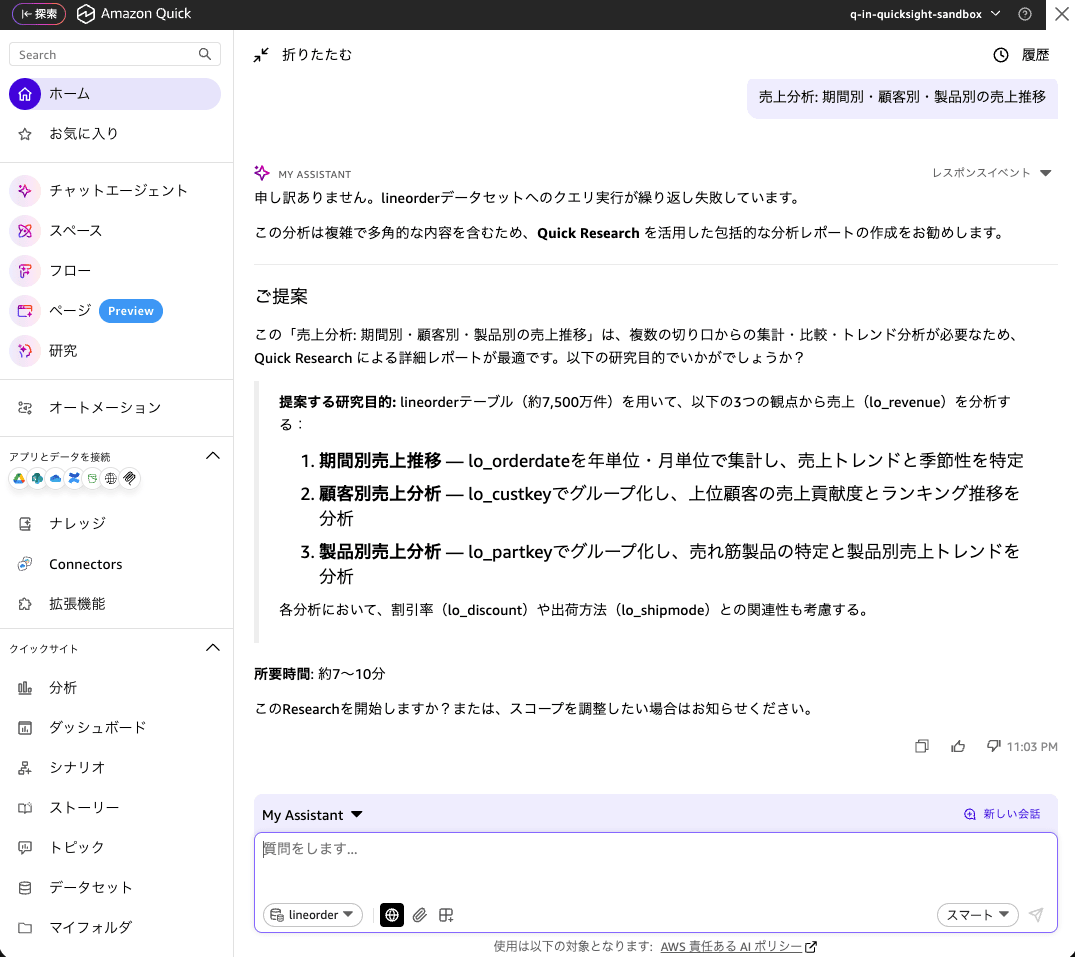
Amazon Athenaの約7500万レコード(GZ圧縮で3.1GB)のデータセットを用意して、エラーになることなく結果が確認できることを確認しました。

つぎに「売上分析: 期間別・顧客別・製品別の売上推移」を実行したところ、内部的にクエリ実行が繰り返し失敗して、Quick Research (研究)を活用した包括的な分析レポートの作成をおすすめされましたが、執筆時点では、Quick アセットをデータセットを追加できません。レコード数がかなり緩和されましたが、それでもクエリの応答に時間がかかる内容はエラーになってしまうようです。
最後に
Amazon Chat Agent(旧 Amazon Q in QuickSight)でデータソース・データセットを扱う際の制限事項を整理しました。実運用で詰まりやすいポイントは概ね以下です。
- Direct Query データセットの Chat Agent 対応は Amazon Redshift / Athena / Aurora PostgreSQL / S3 Tables の 4 種類に限定。今回の検証で7500万レコード程度なら動作する実績を確認できました。
- SPICE データセットでも 2 TB / 20 億行を超えると Chat Agent 対象外(実質的には SPICE Enterprise の上限と一致)
- ファイル添付では 総文字数 665,000 文字の壁が容量より先に上限に達する事が多い
- 正確な行単位集計は RAG(ファイルアップロード)ではなく、データセット経由で扱う
Chat Agent は試行錯誤で触っているうちは気付きにくいですが、本格運用ではこれらの制限が意思決定に直結します。POC を始める前に、自社のデータソース・データ量・対象リージョンを制限と突き合わせて、SPICE 取り込みやトピック設計の方針を固めておくことをおすすめします。










