
Amazon Athena で Apache Iceberg を試して内部構造を解剖してみた
はじめに
コンサルティング部のぐっさんです。
前回の記事では Athena を使って CSV と Parquet のスキャン量を比較し、Parquet の列指向フォーマットの効率性を確認しました。
今回は、Parquet などのデータファイルを束ねて管理するテーブルフォーマットである Apache Iceberg について、Athena で実際に触りながら学んでいきます。
一言まとめ
Apache Iceberg は Parquet などのファイル形式の上に構築されるテーブルフォーマットで、ACID トランザクション、タイムトラベル、スキーマ進化などの機能を提供します。データレイクを RDB のように操作できるようにするための技術です。
Apache Iceberg とは
ファイル形式 vs テーブルフォーマット
前回までの記事で扱った Parquet は「ファイル形式」です。1つ1つのファイルがどのようにデータを格納するかを定義しています。
一方、Iceberg は「テーブルフォーマット」です。複数のファイルをどのようにテーブルとして管理するかを定義しています。
なぜ Iceberg が必要なのか
S3 + Parquet だけでも分析は可能ですが、以下のような課題があります。Iceberg はこれらを解決します。
| 課題 | S3 + Parquet のみ | Iceberg |
|---|---|---|
| データ更新 | ファイル全体を書き換えが必要 | 行レベルで UPDATE/DELETE が可能 |
| 同時書き込み | 競合の可能性あり | ACID で整合性を保証 |
| スキーマ変更 | 全ファイル再作成が必要な場合も | スキーマ進化をサポート |
| 過去データ参照 | 別途バックアップが必要 | タイムトラベルで参照可能 |
Iceberg の内部構造
Iceberg は Metadata Layer と Data Layer の2層でデータを管理しています。
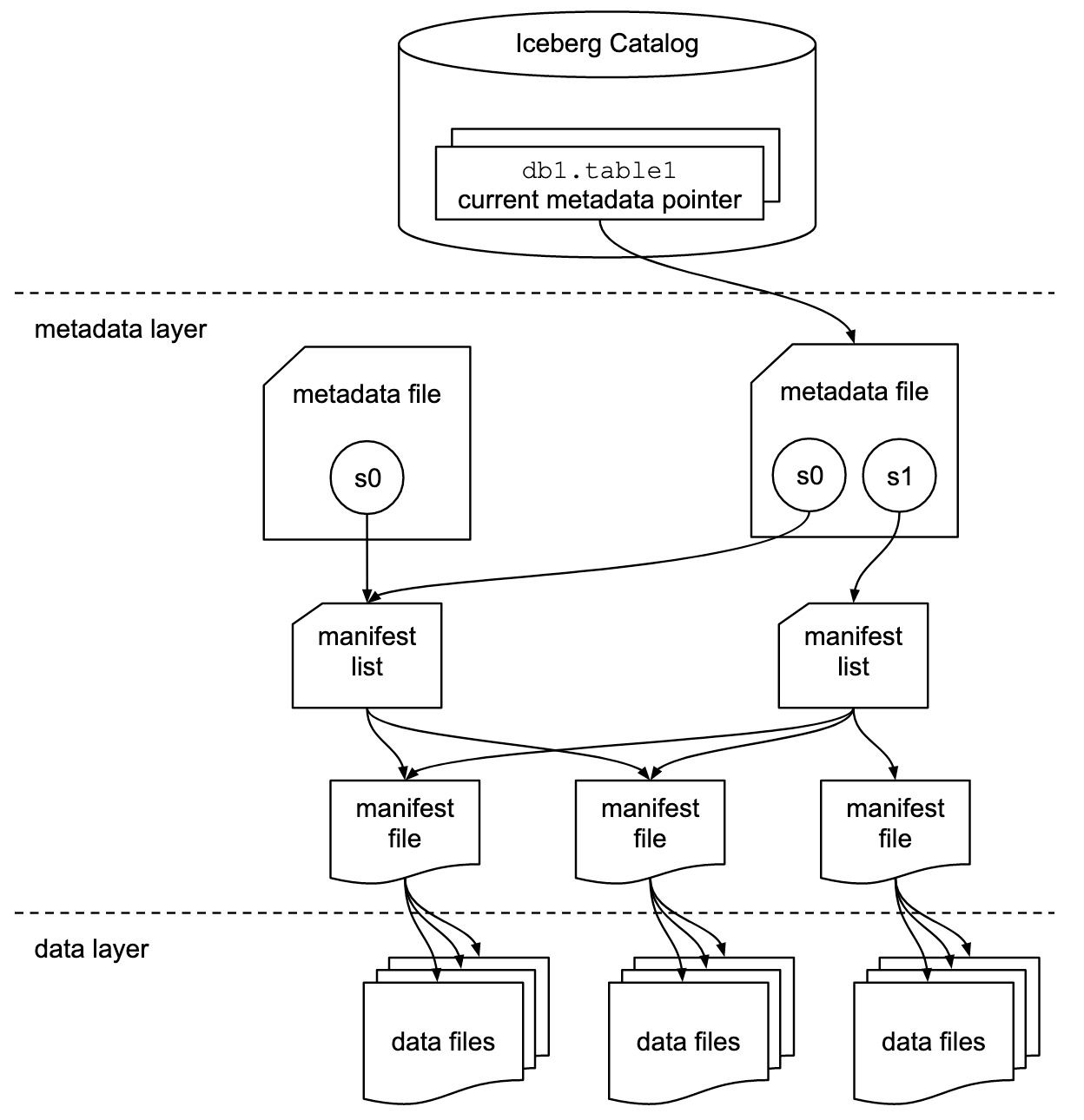
Iceberg Catalog
| 要素 | 役割 |
|---|---|
| Catalog | テーブル名と現在のメタデータファイルへのポインタを管理 |
Metadata Layer
| 要素 | 役割 |
|---|---|
| Metadata File | スキーマ、パーティション設定、スナップショット定義(ID、タイムスタンプ、Manifest List パス)を管理 |
| Manifest List | Manifest File のパス・サイズ・統計サマリーの一覧 |
| Manifest File | データファイルのパスとファイル単位の統計情報(min/max、行数、null数など) |
Data Layer
| 要素 | 役割 |
|---|---|
| Data Files | 実際のデータ(Parquet/ORC/Avro) |
この構造によって、データレイクにおいて以下のような機能を実現しています。
- スナップショット - Catalog のポインタを切り替えるだけで過去の状態を参照できる
- 効率的なクエリ - Manifest の統計情報でファイルをスキップできる
- ACID トランザクション - 新しい Metadata File を作成し、最後に Catalog を更新(アトミック)
- 効率的な書き込み - Manifest File はスナップショット間で再利用される
Iceberg の主要機能
- ACID トランザクション - 複数の書き込み操作が同時に発生しても整合性を保証
- タイムトラベル - 過去の任意の時点のデータを参照可能
- スキーマ進化 - カラムの追加・削除・名前変更が柔軟に可能
- パーティション進化 - パーティション構成を後から変更可能
- 隠しパーティショニング - ユーザーがパーティションを意識せずにクエリ可能
では実際にデータを投入して、これらの一部機能を試してみましょう。
検証の流れ
- テストデータ(NYC タクシー乗車データ)を Python で作成
- CSV を S3 にアップロード
- Athena で CSV の外部テーブルを作成
- Iceberg テーブルを作成し、CSV からデータを投入
- Iceberg の機能(UPDATE、DELETE、タイムトラベル)を試す
検証データ
Python の seaborn ライブラリに含まれる NYC タクシー乗車データ(6,433件)を使用します。
データ構造
| カラム | 説明 |
|---|---|
| pickup | 乗車日時 |
| dropoff | 降車日時 |
| passengers | 乗客数 |
| distance | 距離(マイル) |
| fare | 運賃 |
| tip | チップ |
| tolls | 通行料 |
| total | 合計金額 |
| color | タクシーの色(yellow/green) |
| payment | 支払方法(credit card/cash 等) |
| pickup_zone | 乗車ゾーン |
| dropoff_zone | 降車ゾーン |
| pickup_borough | 乗車区(Manhattan 等) |
| dropoff_borough | 降車区 |
データ生成
# 仮想環境の作成・有効化
python -m venv .venv
source .venv/bin/activate
# 依存ライブラリのインストール
pip install -r requirements.txt
# データ生成スクリプトを実行
python generate_taxi_data.py
requirements.txtの中身
seaborn>=0.12.0
出力例
データ生成完了: 6433件
カラム一覧:
- pickup: datetime64[ns]
- dropoff: datetime64[ns]
- passengers: int64
- distance: float64
- fare: float64
- tip: float64
- tolls: float64
- total: float64
- color: object
- payment: object
- pickup_zone: object
- dropoff_zone: object
- pickup_borough: object
- dropoff_borough: object
ファイルサイズ:
CSV: 869,349 bytes (849.0 KB)
先頭5件:
pickup dropoff passengers distance fare tip tolls total color payment pickup_zone dropoff_zone pickup_borough dropoff_borough
0 2019-03-23 20:21:09 2019-03-23 20:27:24 1 1.60 7.0 2.15 0.0 12.95 yellow credit card Lenox Hill West UN/Turtle Bay South Manhattan Manhattan
1 2019-03-04 16:11:55 2019-03-04 16:19:00 1 0.79 5.0 0.00 0.0 9.30 yellow cash Upper West Side South Upper West Side South Manhattan Manhattan
2 2019-03-27 17:53:01 2019-03-27 18:00:25 1 1.37 7.5 2.36 0.0 14.16 yellow credit card Alphabet City West Village Manhattan Manhattan
3 2019-03-10 01:23:59 2019-03-10 01:49:51 1 7.70 27.0 6.15 0.0 36.95 yellow credit card Hudson Sq Yorkville West Manhattan Manhattan
4 2019-03-30 13:27:42 2019-03-30 13:37:14 3 2.16 9.0 1.10 0.0 13.40 yellow credit card Midtown East Yorkville West Manhattan Manhattan
generate_taxi_data.pyの中身
データセットを読み込んでCSV化しているのみです!
import seaborn as sns
import os
# Taxi データセットを読み込み
df = sns.load_dataset('taxis')
# CSV で保存
df.to_csv('data/taxis.csv', index=False)
print(f"データ生成完了: {len(df)}件")
print(f"\nカラム一覧:")
for col in df.columns:
print(f" - {col}: {df[col].dtype}")
print(f"\nファイルサイズ:")
csv_size = os.path.getsize('data/taxis.csv')
print(f" CSV: {csv_size:,} bytes ({csv_size/1024:.1f} KB)")
print(f"\n先頭5件:")
print(df.head())
S3 にアップロード
バケット作成
# バケット作成(バケット名は適宜変更してください)
aws s3 mb s3://your-bucket-name --region ap-northeast-1
データアップロード
# CSV をアップロード
aws s3 cp data/taxis.csv s3://your-bucket-name/csv/
確認
aws s3 ls s3://your-bucket-name/ --recursive
Athena でテーブル作成
データベース作成
クエリエディタでSQL文を実行し、作成します。
CREATE DATABASE IF NOT EXISTS taxi_db;
CSV 外部テーブル作成
次に、CSV データを読み込むための外部テーブルを作成します。
CREATE EXTERNAL TABLE taxi_db.taxis_csv (
pickup STRING,
dropoff STRING,
passengers INT,
distance DOUBLE,
fare DOUBLE,
tip DOUBLE,
tolls DOUBLE,
total DOUBLE,
color STRING,
payment STRING,
pickup_zone STRING,
dropoff_zone STRING,
pickup_borough STRING,
dropoff_borough STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://your-bucket-name/csv/'
TBLPROPERTIES ('skip.header.line.count'='1');
データ確認
SELECT * FROM taxi_db.taxis_csv LIMIT 5;
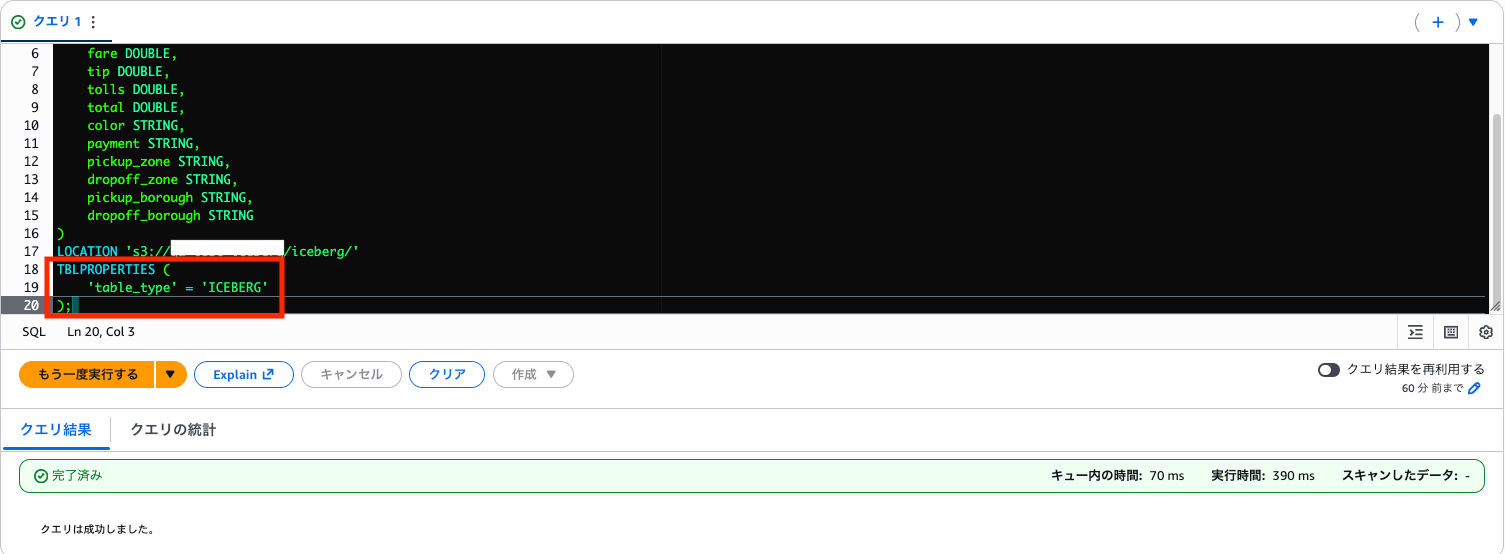
Iceberg テーブル作成
Icebergテーブルを作成します!
TBLPROPERTIES で 'table_type'='ICEBERG' を指定します。
CREATE TABLE taxi_db.taxis_iceberg (
pickup STRING,
dropoff STRING,
passengers INT,
distance DOUBLE,
fare DOUBLE,
tip DOUBLE,
tolls DOUBLE,
total DOUBLE,
color STRING,
payment STRING,
pickup_zone STRING,
dropoff_zone STRING,
pickup_borough STRING,
dropoff_borough STRING
)
LOCATION 's3://your-bucket-name/iceberg/'
TBLPROPERTIES (
'table_type' = 'ICEBERG'
);
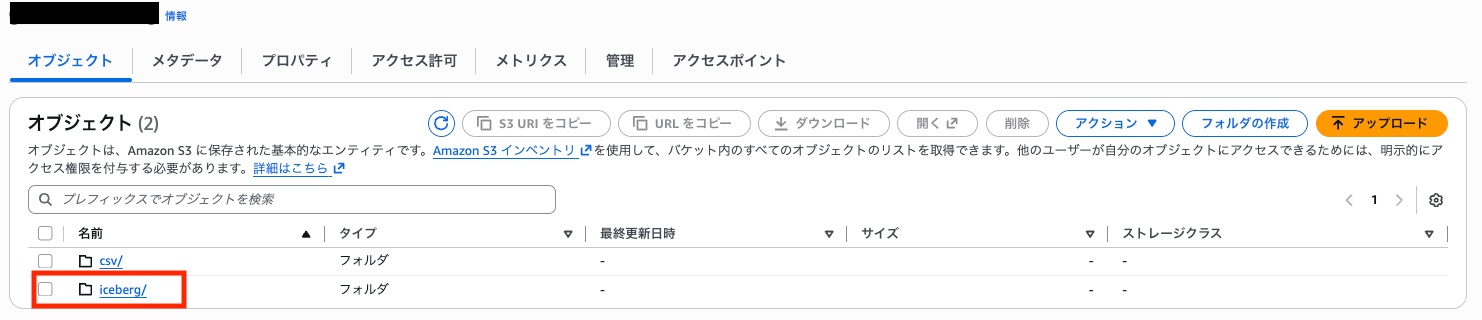
作成直後に、S3を見るとメタデータファイルが自動で格納されていました。
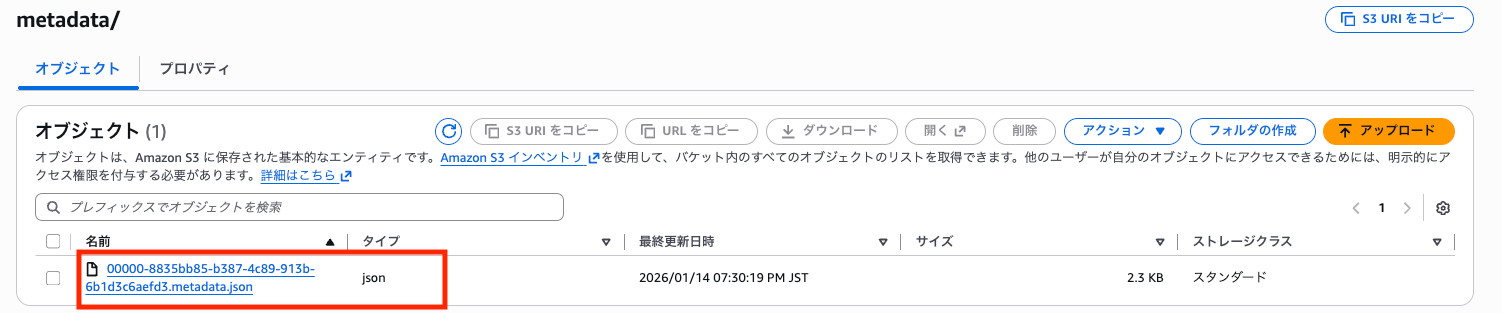
テーブル作成直後のメタデータファイル(metadata.json)の中身を確認してみました。
{
"format-version" : 2,
"table-uuid" : "002bd9f3-4026-4f4b-a47f-ada7fd579281",
"location" : "s3://your-bucket-name/iceberg",
"last-sequence-number" : 0,
"last-updated-ms" : 1768386618442,
"last-column-id" : 14,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "pickup",
"required" : false,
"type" : "string"
}, {
"id" : 2,
"name" : "dropoff",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "passengers",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "distance",
"required" : false,
"type" : "double"
}, {
"id" : 5,
"name" : "fare",
"required" : false,
"type" : "double"
}, {
"id" : 6,
"name" : "tip",
"required" : false,
"type" : "double"
}, {
"id" : 7,
"name" : "tolls",
"required" : false,
"type" : "double"
}, {
"id" : 8,
"name" : "total",
"required" : false,
"type" : "double"
}, {
"id" : 9,
"name" : "color",
"required" : false,
"type" : "string"
}, {
"id" : 10,
"name" : "payment",
"required" : false,
"type" : "string"
}, {
"id" : 11,
"name" : "pickup_zone",
"required" : false,
"type" : "string"
}, {
"id" : 12,
"name" : "dropoff_zone",
"required" : false,
"type" : "string"
}, {
"id" : 13,
"name" : "pickup_borough",
"required" : false,
"type" : "string"
}, {
"id" : 14,
"name" : "dropoff_borough",
"required" : false,
"type" : "string"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.object-storage.enabled" : "true",
"write.object-storage.path" : "s3://your-bucket-name/iceberg/data",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"statistics" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}
ポイント
format-version: 2- Iceberg v2 フォーマットschemas- カラム定義(DDL で指定した内容)current-snapshot-id: -1- まだデータがない状態snapshots: []- スナップショットも空write.parquet.compression-codec: zstd- データは Zstandard 圧縮で保存される
CSV から Iceberg へデータ投入
INSERT INTO taxi_db.taxis_iceberg
SELECT * FROM taxi_db.taxis_csv;
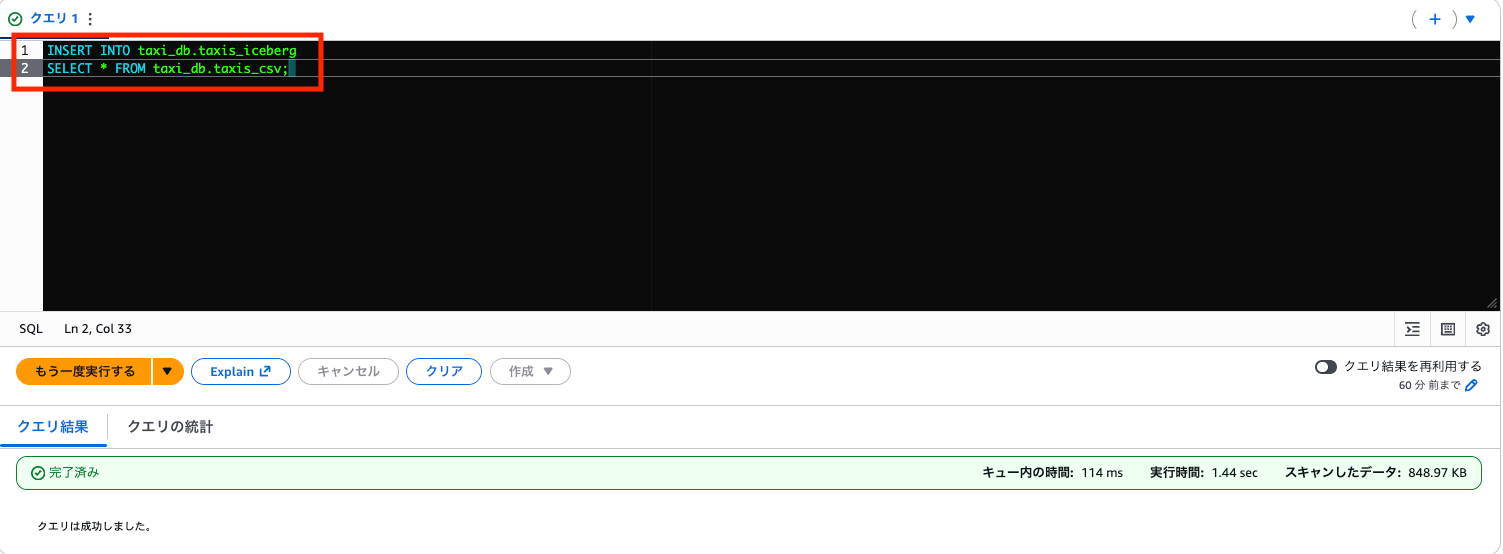
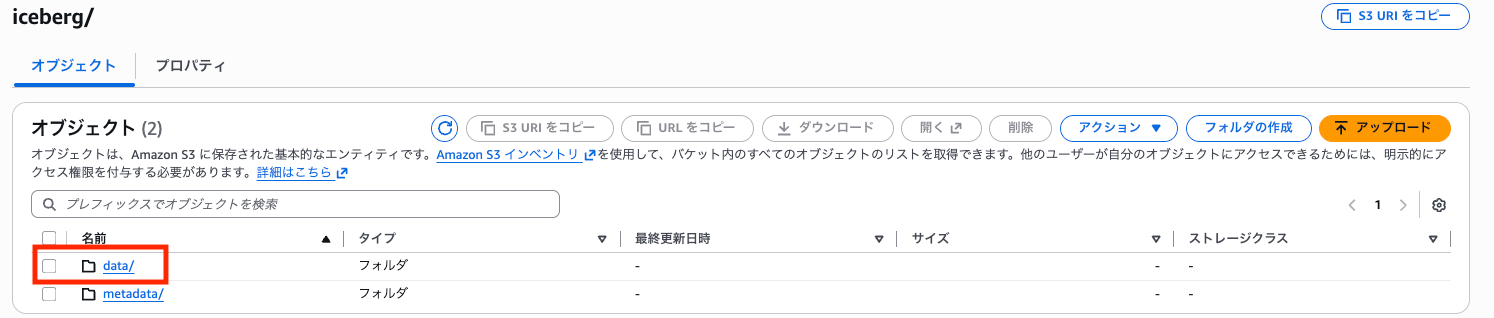
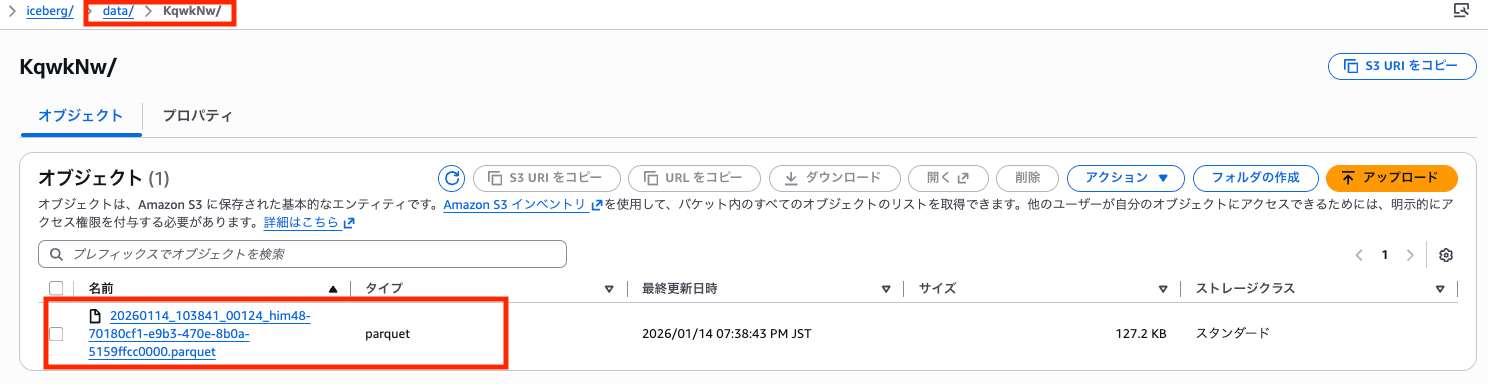
S3 を確認すると、data フォルダが作成され、その中に Parquet ファイルが自動生成されています。元データは CSV でしたが、Iceberg テーブルに INSERT されると内部的には Parquet 形式で保存されます。
データ確認
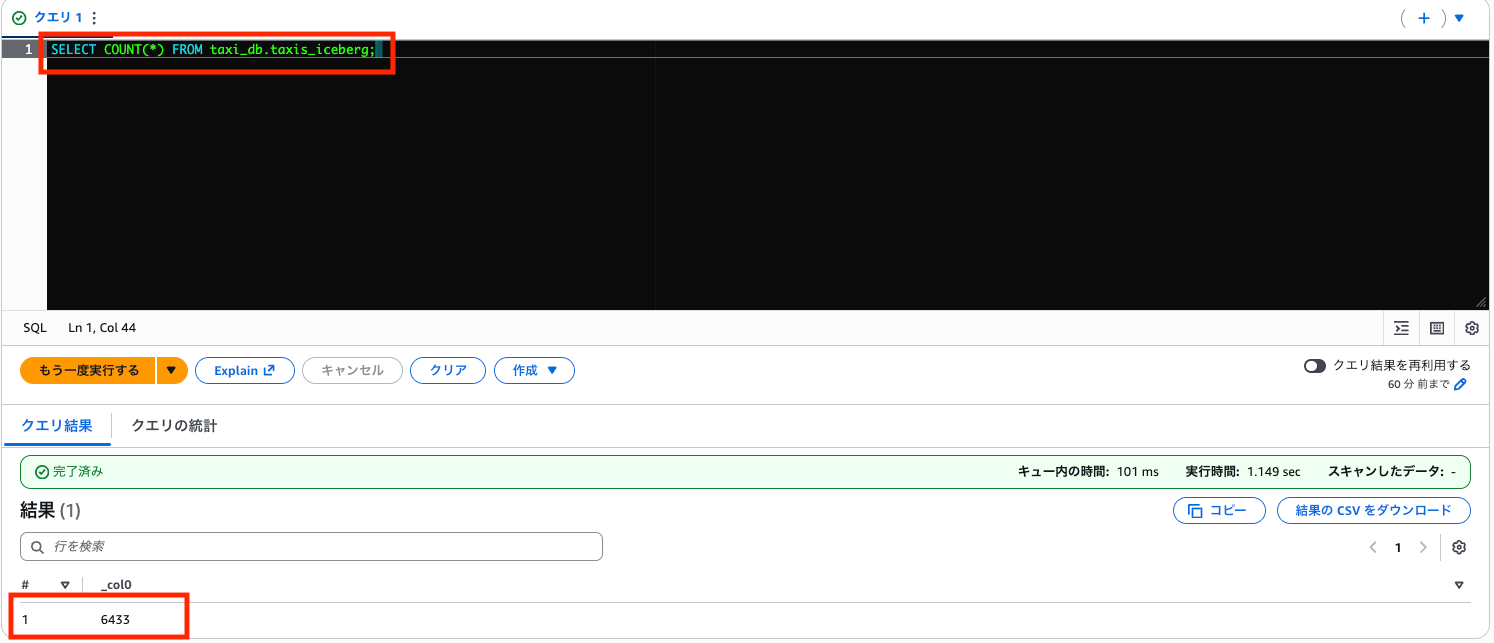
件数を確認します(CSV と同じ 6,433 件であれば OK)。
SELECT COUNT(*) FROM taxi_db.taxis_iceberg;
データの中身も確認してみましょう。
SELECT * FROM taxi_db.taxis_iceberg LIMIT 5;
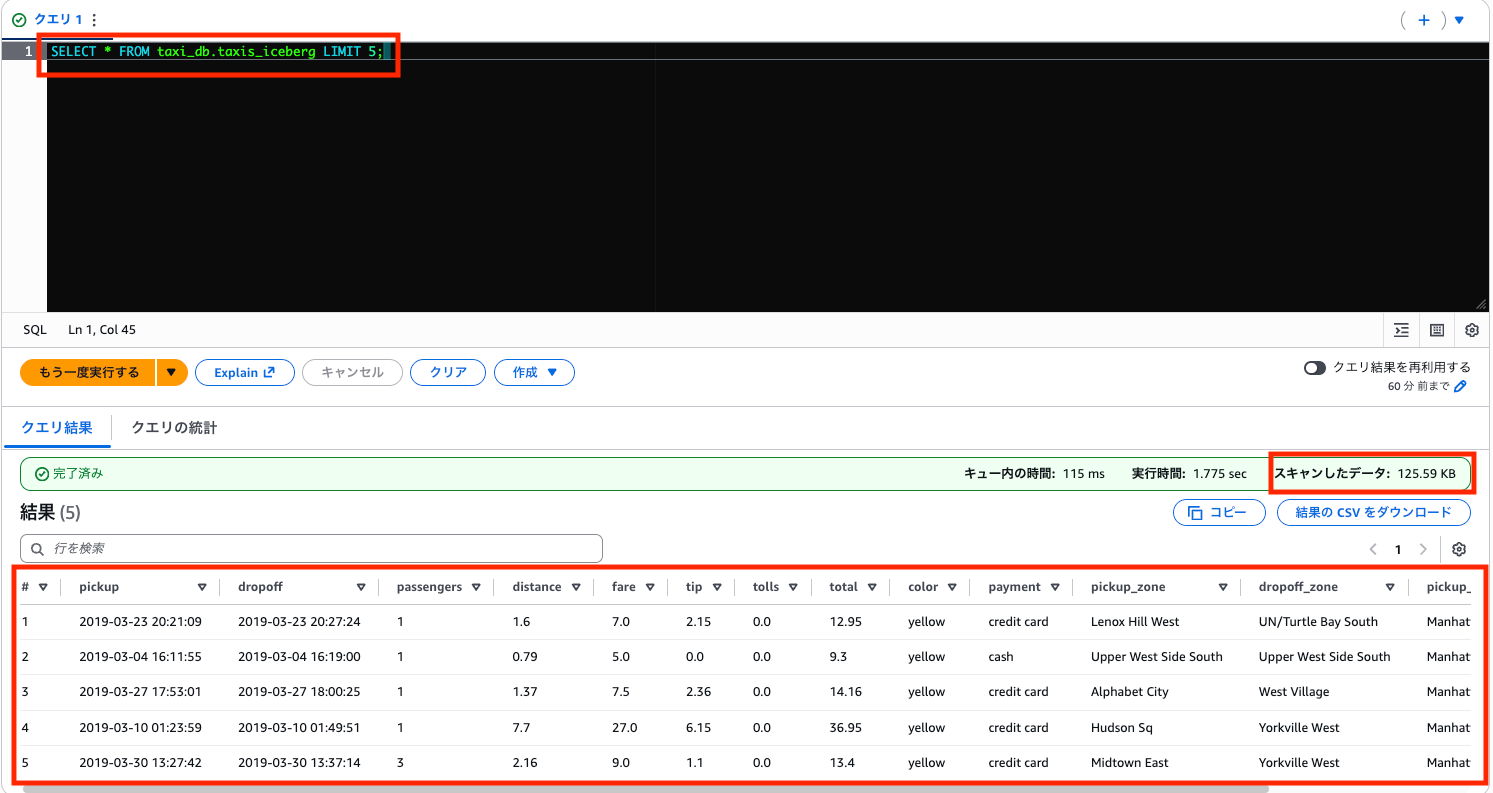
Iceberg テーブルは内部的に Parquet で保存されているため、CSV テーブルに比べてスキャン量が削減されています。前回の記事で検証した通り、列指向フォーマットの恩恵を受けられます。
Iceberg の機能を試す
1. UPDATE(行レベル更新)
通常の Parquet 外部テーブルでは UPDATE ができませんが、Iceberg では可能です。
例:cash 支払いを「cash」から「Cash」に統一
まず現在の支払方法を確認します。
SELECT DISTINCT payment FROM taxi_db.taxis_iceberg;
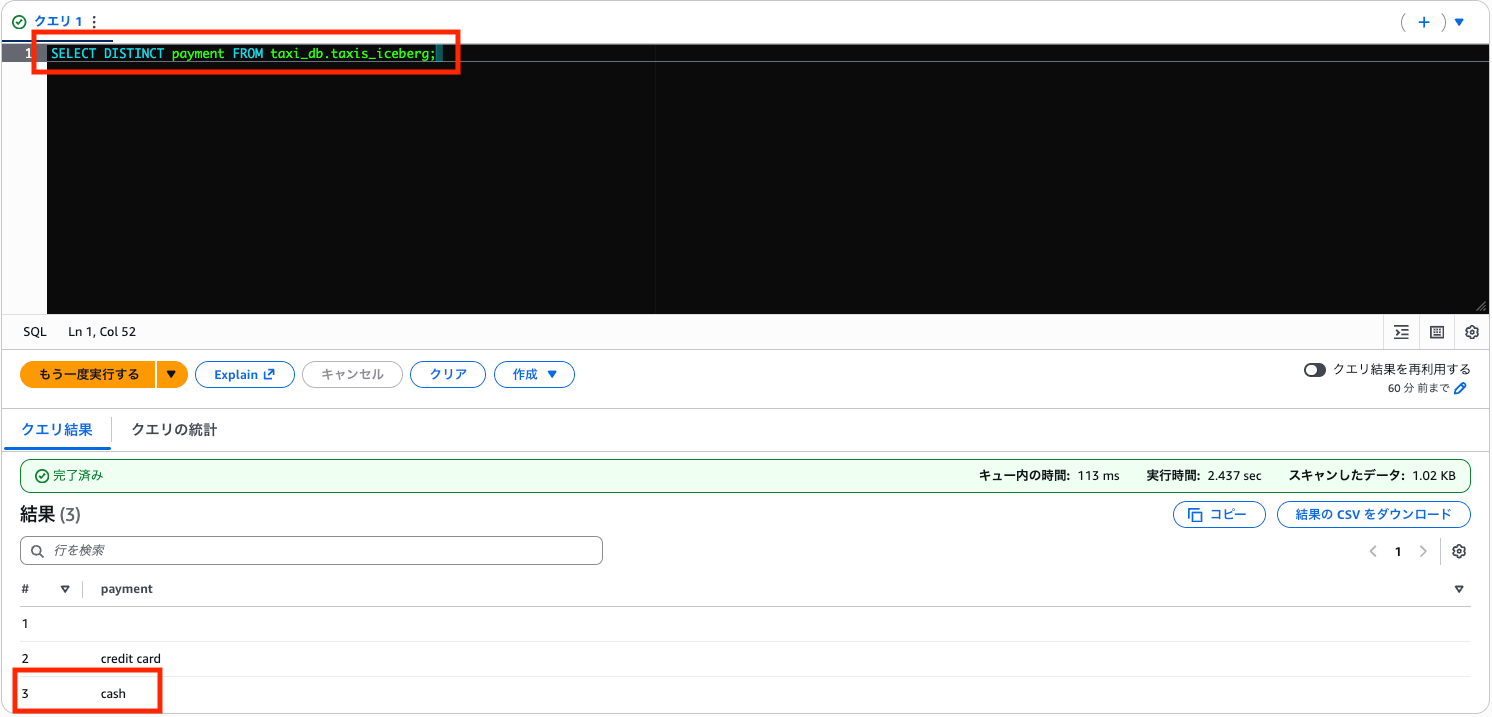
credit card、cash、そして空欄(NULL)の 3 種類があることがわかります。実データには欠損もあるんですね。
UPDATE を実行します。
UPDATE taxi_db.taxis_iceberg
SET payment = 'Cash'
WHERE payment = 'cash';
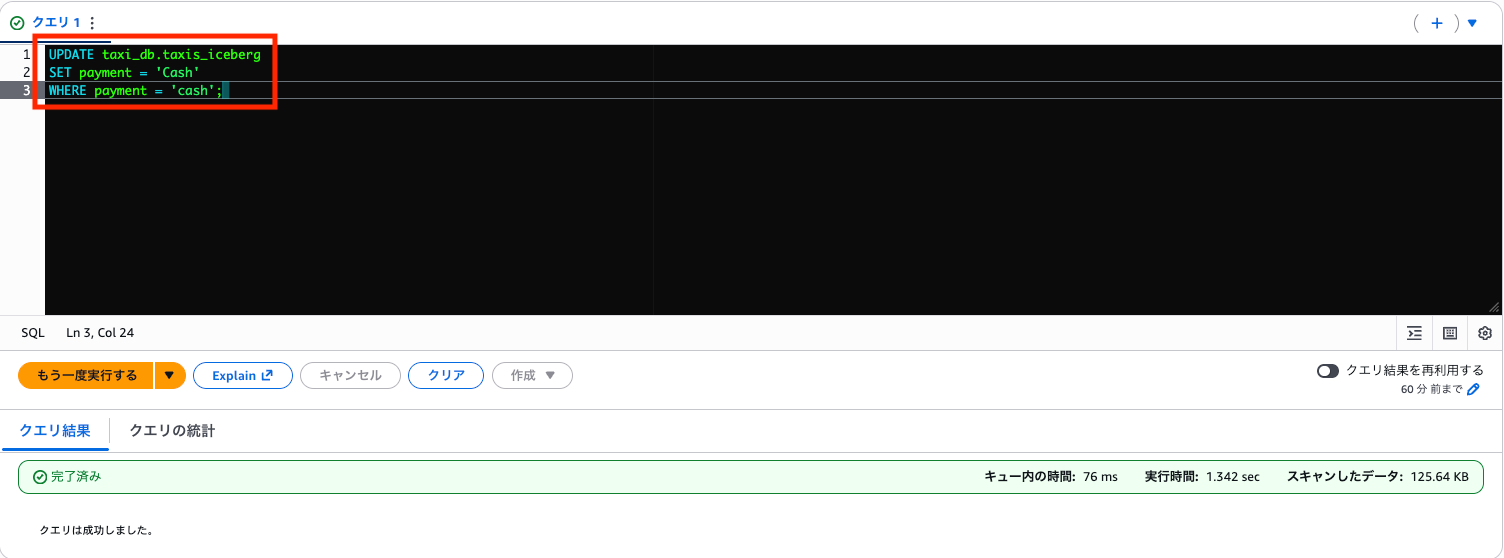
再度確認すると、cash が Cash に変わっています。
SELECT DISTINCT payment FROM taxi_db.taxis_iceberg;
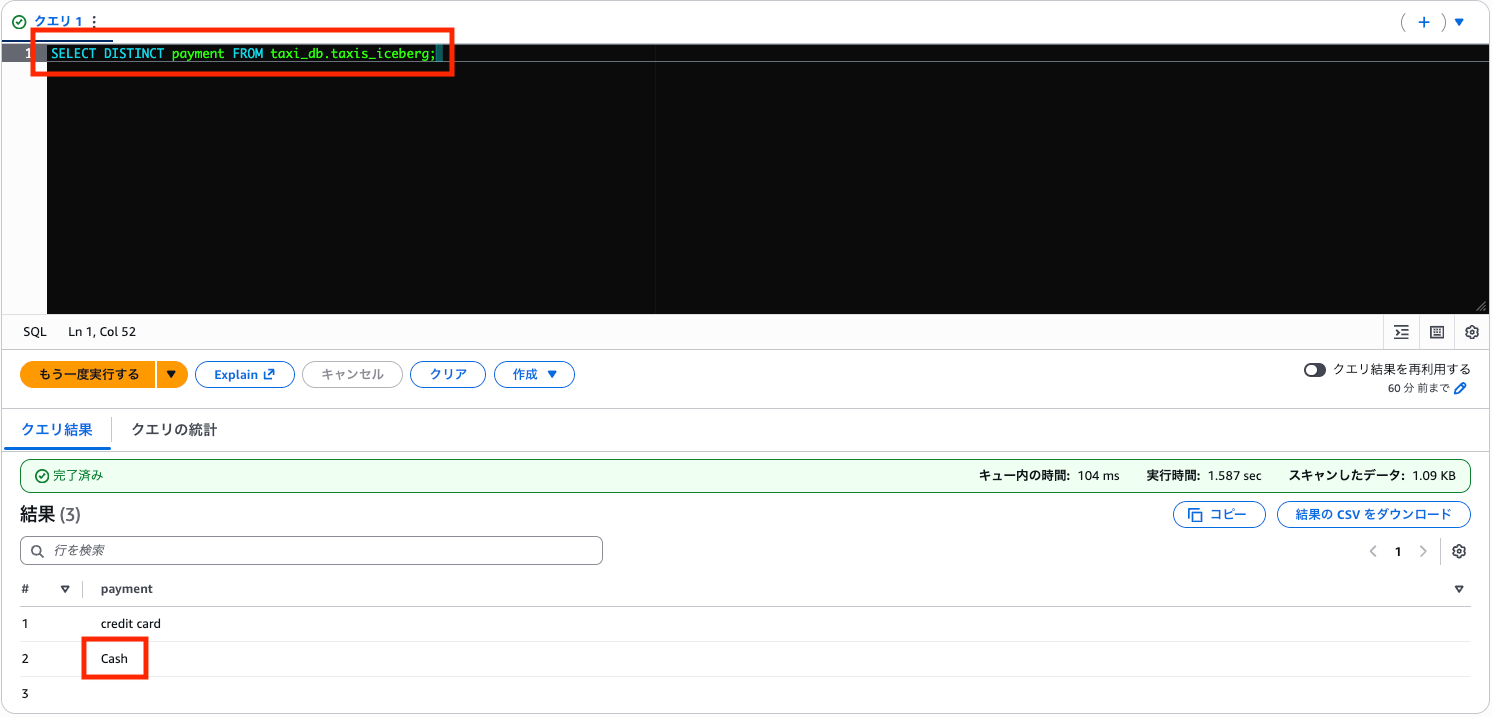
データの中身も確認してみましょう。Cash に更新されたデータを表示します。
SELECT * FROM taxi_db.taxis_iceberg
WHERE payment = 'Cash'
LIMIT 5;
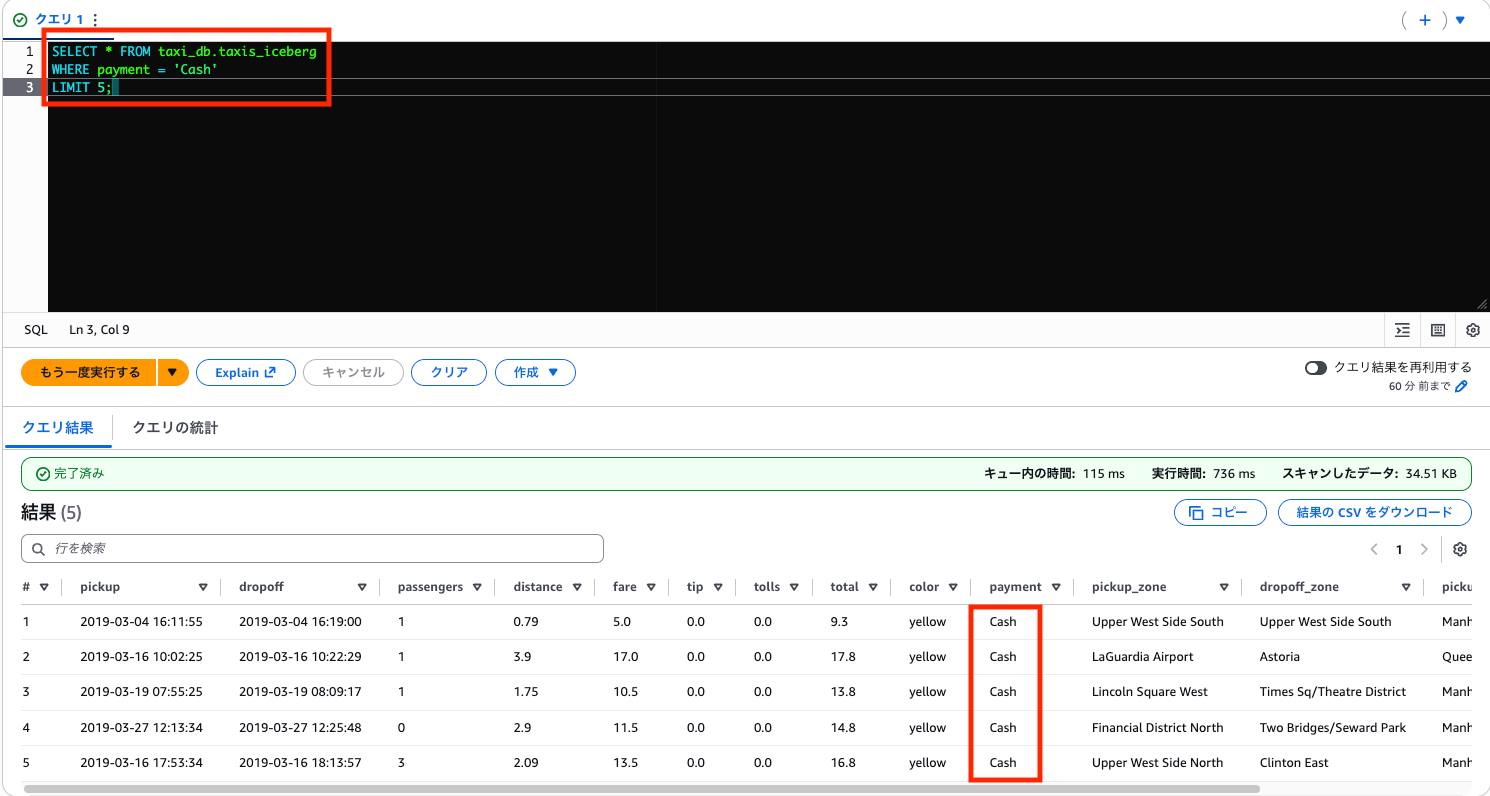
2. DELETE(行レベル削除)
特定の条件に合うデータを削除できます。
例:乗客数が 0 人のデータを削除(データ不備として)
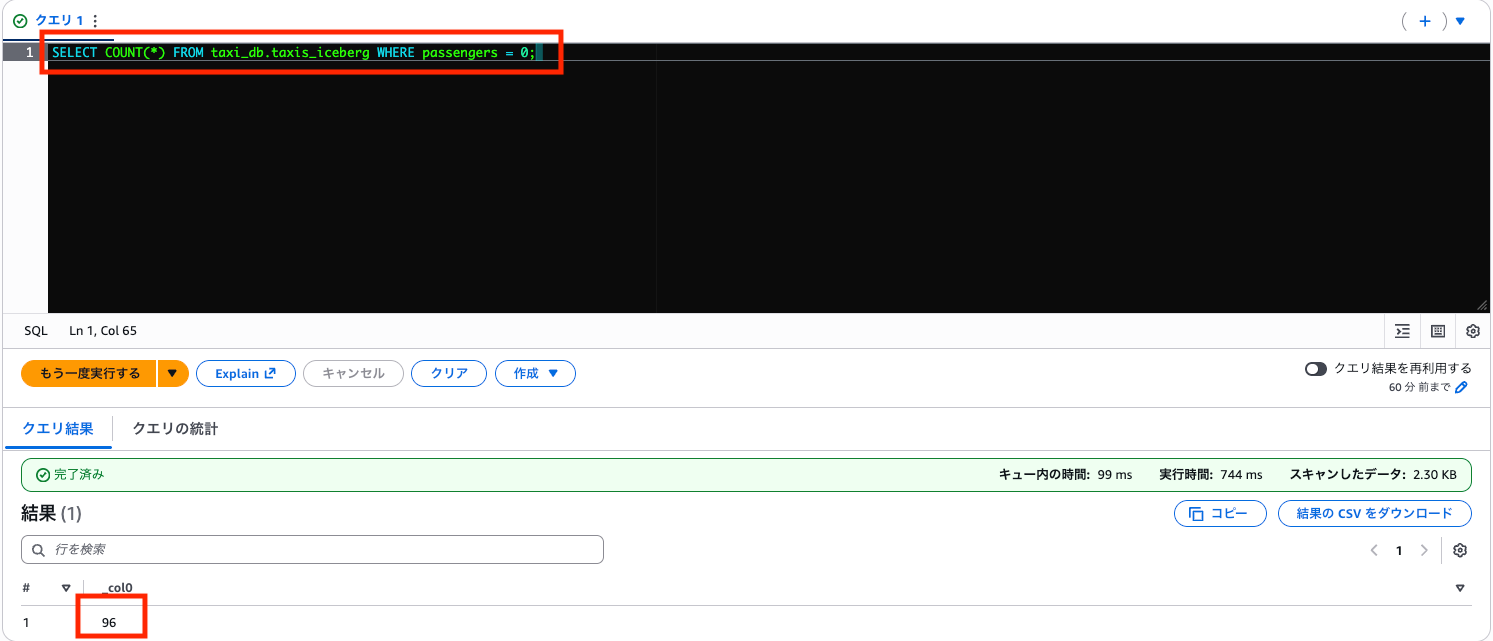
まず件数を確認します。
SELECT COUNT(*) FROM taxi_db.taxis_iceberg WHERE passengers = 0;
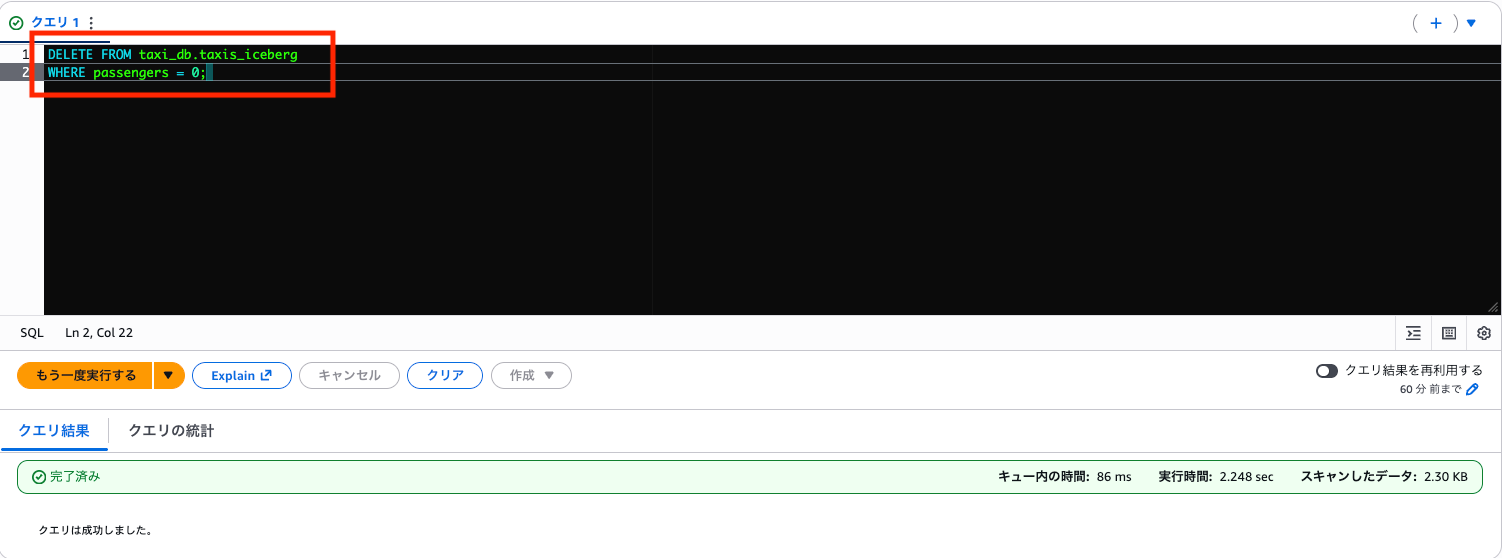
削除実行
DELETE FROM taxi_db.taxis_iceberg
WHERE passengers = 0;
削除後の件数を確認します。
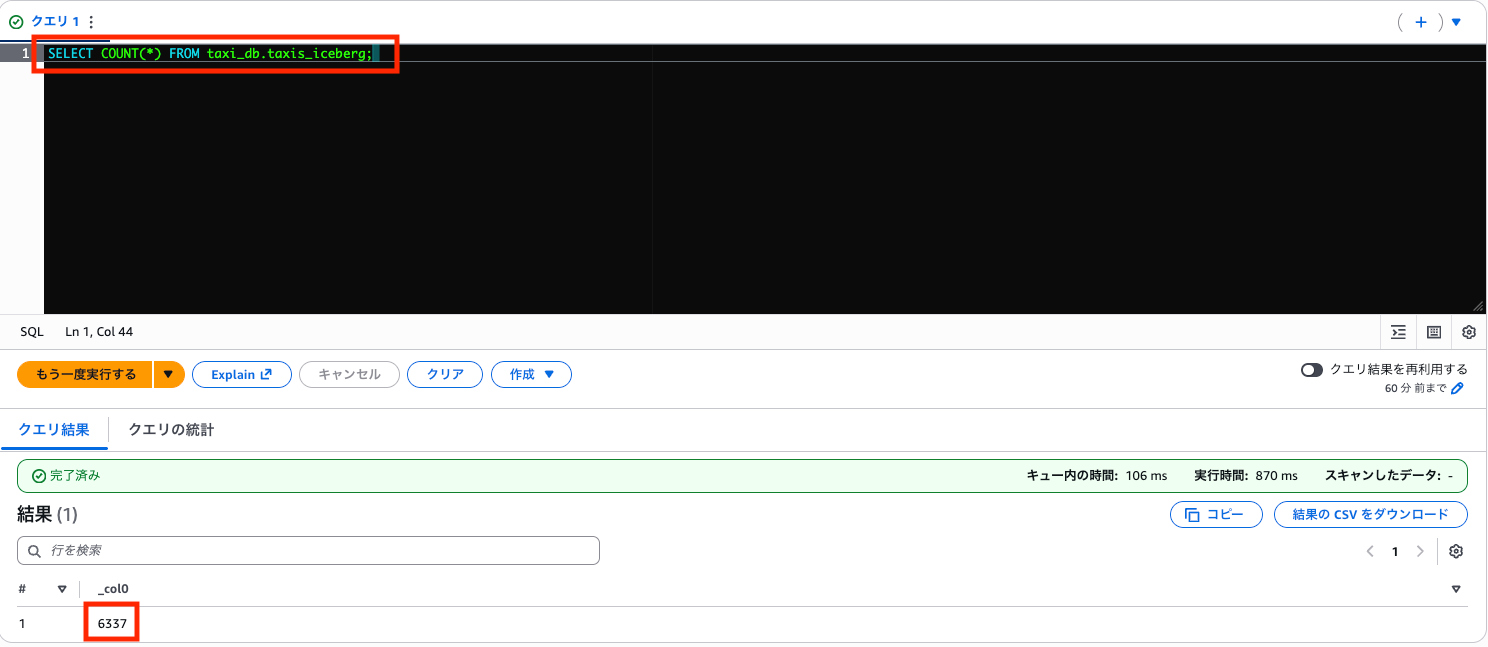
SELECT COUNT(*) FROM taxi_db.taxis_iceberg;
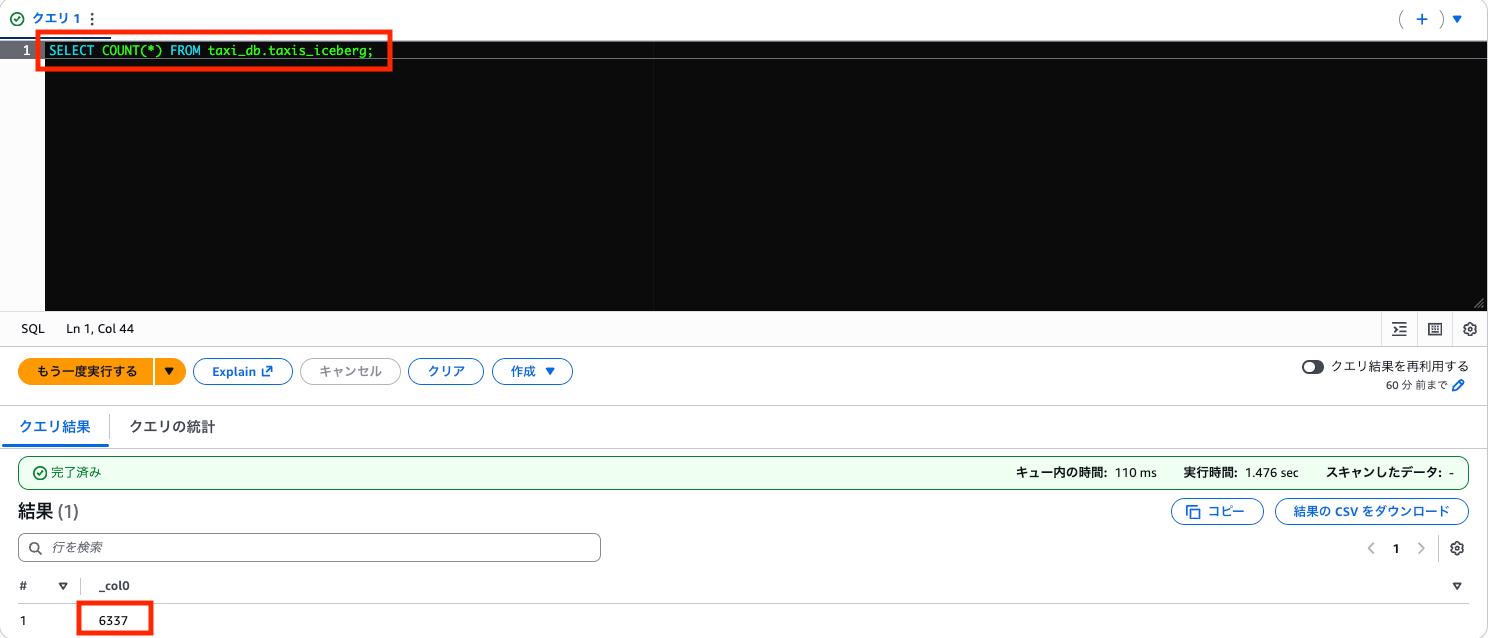
6,337 件に減りました(6,433 - 96 = 6,337)。乗客数 0 人のデータが正常に削除されています。
3. タイムトラベル
Iceberg はすべての変更履歴をスナップショットとして保持しているため、過去の時点のデータを参照できます。
スナップショット一覧の確認
SELECT * FROM "taxi_db"."taxis_iceberg$snapshots"
ORDER BY committed_at;
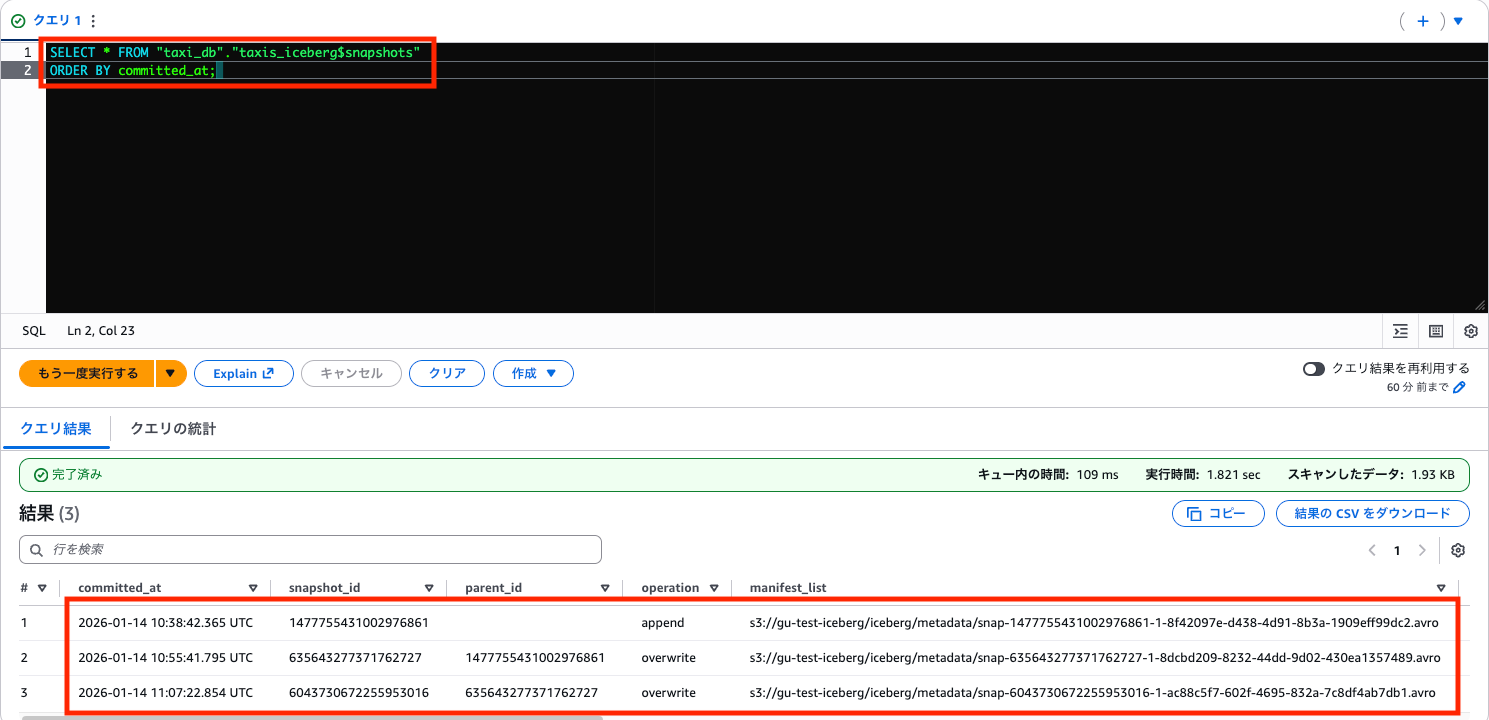
特定のスナップショットを参照
2番目のスナップショット(UPDATE 後・DELETE 前)を指定して、削除前のデータを参照してみます。
-- 2番目のスナップショット ID を指定して、DELETE 前のデータを参照
SELECT COUNT(*)
FROM taxi_db.taxis_iceberg
FOR VERSION AS OF <snapshot_id>;
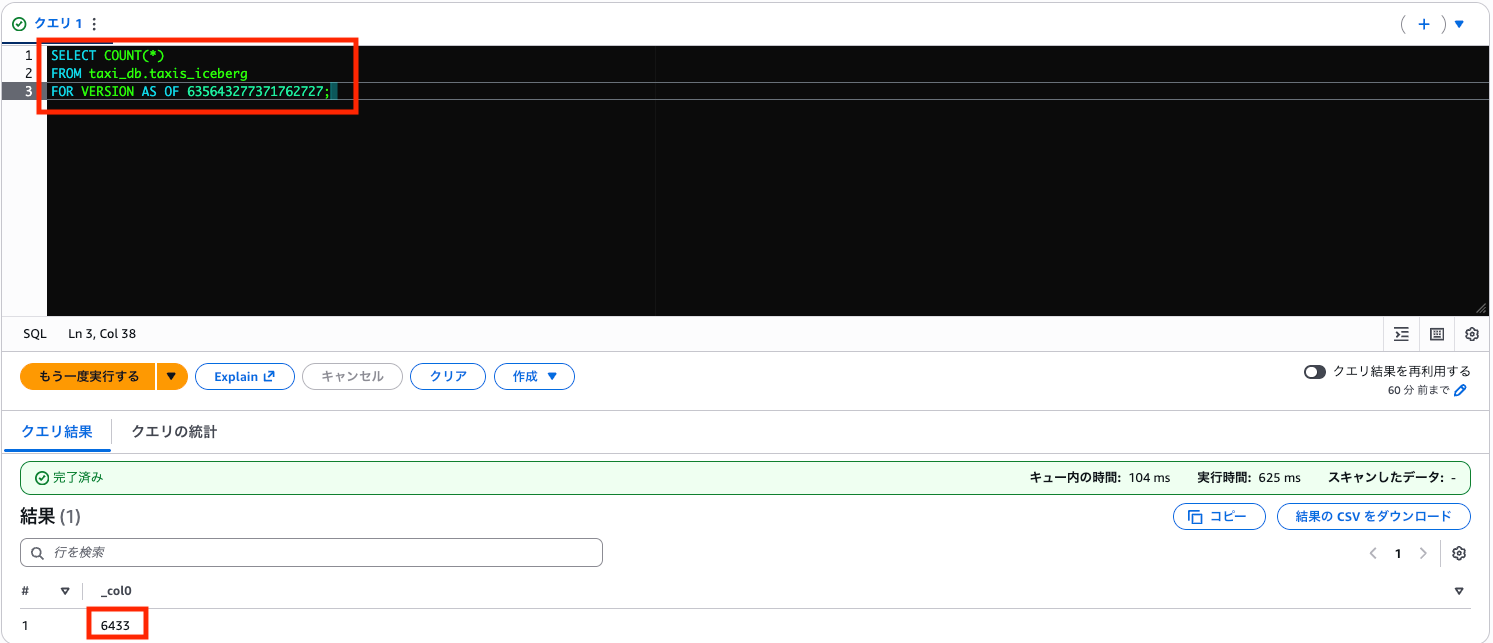
6,433 件が返ってくれば、DELETE 前の状態を参照できたことが確認できます。なお、これは過去データを「見ている」だけで、実際のテーブルは現在の状態(6,337件)のままです。
-- 現在のテーブルは変わっていない
SELECT COUNT(*) FROM taxi_db.taxis_iceberg;
4. スキーマ進化
新しいカラムを追加してみます。まず現在のカラムを確認します。
DESCRIBE taxi_db.taxis_iceberg;
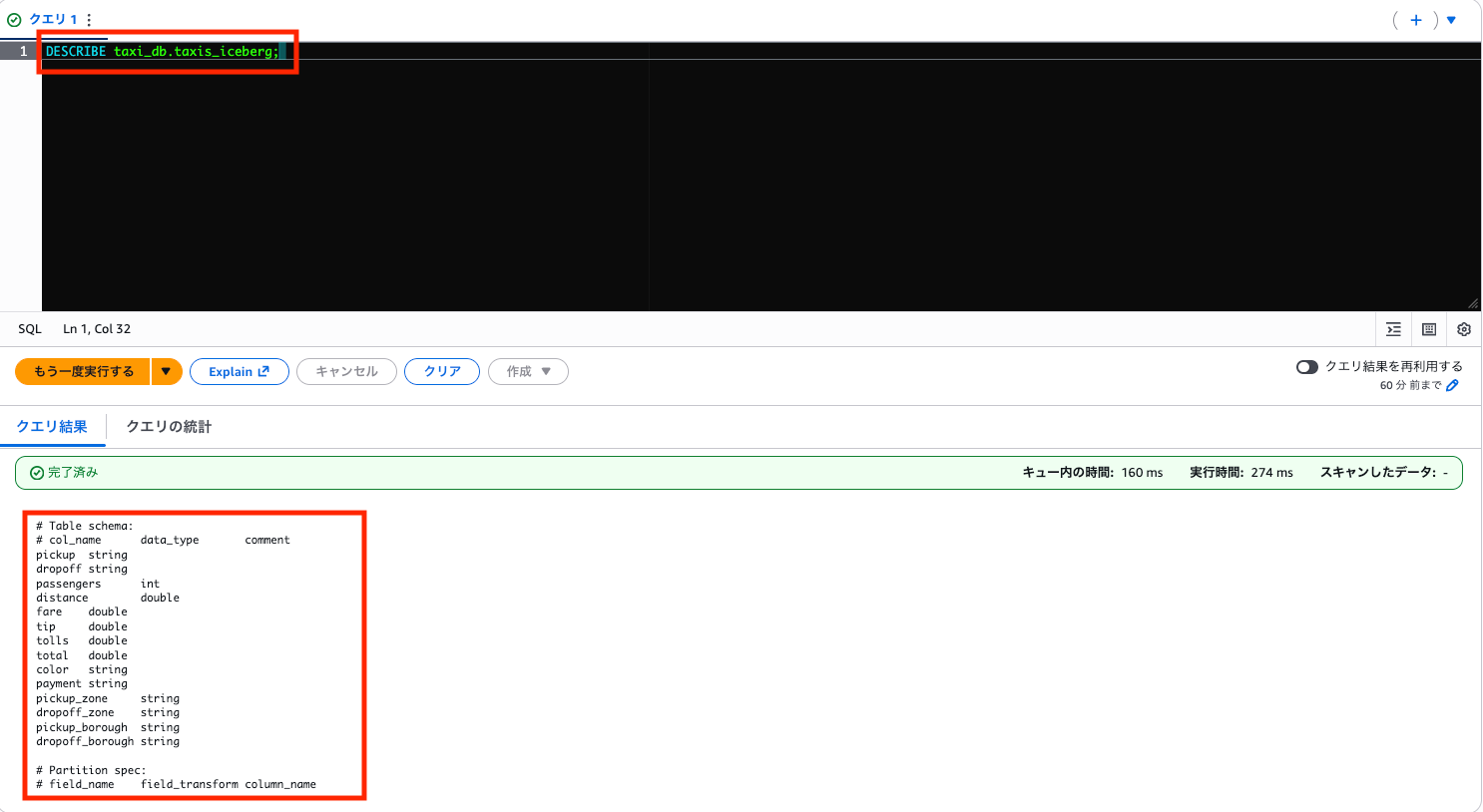
中身はこんなかんじですね。
# Table schema:
# col_name data_type comment
pickup string
dropoff string
passengers int
distance double
fare double
tip double
tolls double
total double
color string
payment string
pickup_zone string
dropoff_zone string
pickup_borough string
dropoff_borough string
# Partition spec:
# field_name field_transform column_name
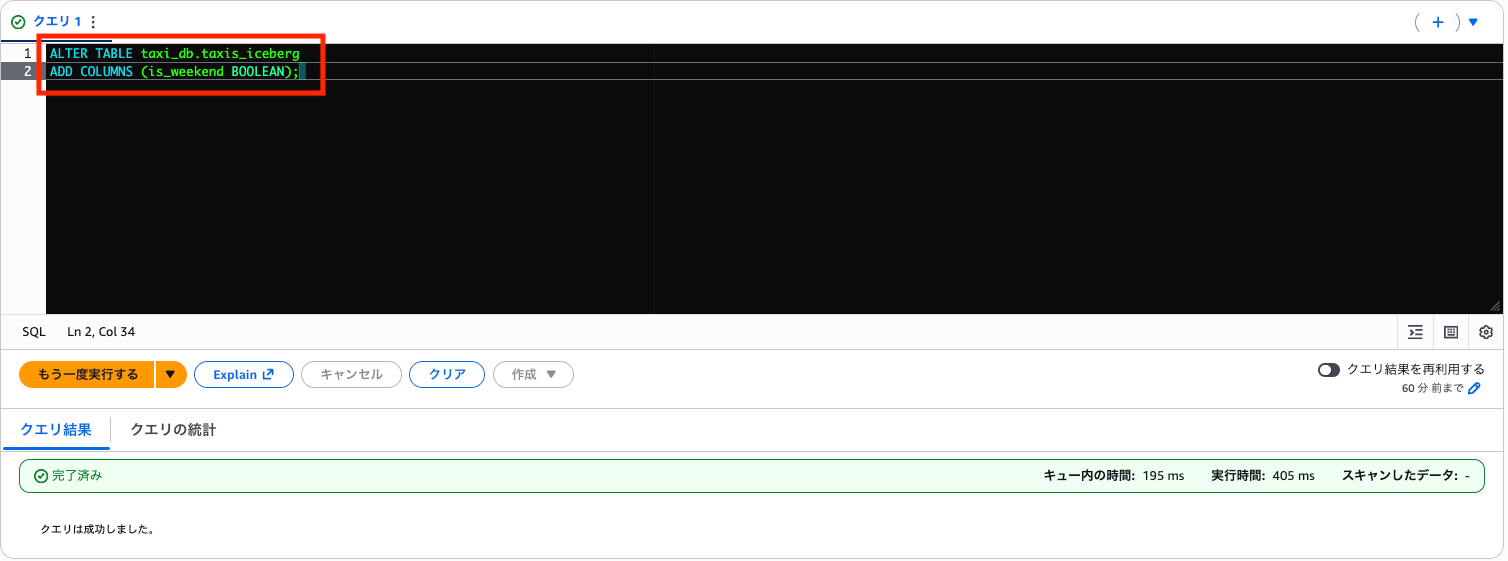
カラムを追加します。
ALTER TABLE taxi_db.taxis_iceberg
ADD COLUMNS (is_weekend BOOLEAN);
再度確認します。
DESCRIBE taxi_db.taxis_iceberg;
is_weekendが仲間入りしていますね!
# Table schema:
# col_name data_type comment
pickup string
dropoff string
passengers int
distance double
fare double
tip double
tolls double
total double
color string
payment string
pickup_zone string
dropoff_zone string
pickup_borough string
dropoff_borough string
is_weekend boolean
# Partition spec:
# field_name field_transform column_name
S3 上のファイル構造
せっかくなのでIceberg テーブルが S3 上でどのように管理されているか確認してみましょう。
ここまでの検証でどれくらいファイルが溜まっているか・・・
aws s3 ls s3://your-bucket-name/iceberg/ --recursive
2026-01-14 19:38:43 130255 iceberg/data/KqwkNw/20260114_103841_00124_him48-70180cf1-e9b3-470e-8b0a-5159ffcc0000.parquet
2026-01-14 19:55:42 3059 iceberg/data/NAwi7w/20260114_105540_00124_az5k7-a69af1ba-1d5c-40dc-8cdd-236b6c4936aa.parquet
2026-01-14 20:07:23 996 iceberg/data/_WNpKQ/20260114_110721_00043_k64c9-a1506c5c-239a-4736-9e0a-b85195b4d97a.parquet
2026-01-14 19:55:42 36924 iceberg/data/umF6Hw/20260114_105540_00124_az5k7-6adc69b9-54fc-4a93-811a-cf135bfd5cf2.parquet
2026-01-14 20:07:23 1099 iceberg/data/va5F1g/20260114_110721_00043_k64c9-bc0ad815-ad87-4ac8-9964-19d5d36aca70.parquet
2026-01-14 19:30:19 2314 iceberg/metadata/00000-8835bb85-b387-4c89-913b-6b1d3c6aefd3.metadata.json
2026-01-14 19:38:43 3387 iceberg/metadata/00001-3871af6f-0782-4419-8aa6-6cfd9e045fcc.metadata.json
2026-01-14 19:55:42 4522 iceberg/metadata/00002-99054ad3-7e8f-4252-b77c-dc6e566e03ec.metadata.json
2026-01-14 20:07:24 5596 iceberg/metadata/00003-3c7634c0-24e6-4904-9e6d-e8154a097d3e.metadata.json
2026-01-14 20:34:12 7363 iceberg/metadata/00004-8ca813ca-ad86-43f9-b17a-5c0f715ae8e4.metadata.json
2026-01-14 19:55:42 7673 iceberg/metadata/8dcbd209-8232-44dd-9d02-430ea1357489-m0.avro
2026-01-14 19:55:42 7487 iceberg/metadata/8dcbd209-8232-44dd-9d02-430ea1357489-m1.avro
2026-01-14 19:38:43 7691 iceberg/metadata/8f42097e-d438-4d91-8b3a-1909eff99dc2-m0.avro
2026-01-14 20:07:23 7610 iceberg/metadata/ac88c5f7-602f-4695-832a-7c8df4ab7db1-m0.avro
2026-01-14 19:38:43 4247 iceberg/metadata/snap-1477755431002976861-1-8f42097e-d438-4d91-8b3a-1909eff99dc2.avro
2026-01-14 20:07:23 4394 iceberg/metadata/snap-6043730672255953016-1-ac88c5f7-602f-4695-832a-7c8df4ab7db1.avro
2026-01-14 19:55:42 4335 iceberg/metadata/snap-635643277371762727-1-8dcbd209-8232-44dd-9d02-430ea1357489.avro
ファイル名が長くてわかりにくいですが、整理すると以下のような構造になっているようです。
iceberg/
├── data/
│ ├── KqwkNw/*.parquet ← INSERT 時の元データ
│ ├── NAwi7w/*.parquet ← UPDATE で追加(更新後の行)
│ ├── umF6Hw/*.parquet ← UPDATE で追加(更新後の行)
│ ├── _WNpKQ/*.parquet ← DELETE で追加(Position Delete File)
│ └── va5F1g/*.parquet ← DELETE で追加(Position Delete File)
└── metadata/
├── 00000-*.metadata.json ← テーブル作成時
├── 00001-*.metadata.json ← INSERT 後
├── 00002-*.metadata.json ← UPDATE 後
├── 00003-*.metadata.json ← DELETE 後
├── 00004-*.metadata.json ← スキーマ変更後
├── *-m0.avro ← Manifest File
└── snap-*.avro ← Manifest List
data/- 実際のデータ(CSV で INSERT しても Parquet で保存される)metadata/- テーブルのメタデータ、スナップショット情報
Iceberg ファイルの中身を読み取る
Iceberg のメタデータは JSON(metadata.json)と Avro(Manifest List、Manifest File)、データは Parquet で保存されています。Avro が採用されているのは、スキーマをファイル内に埋め込めて、かつコンパクトに保存できるためです。
バイナリ形式のファイル(Avro、Parquet)はテキストエディタでは開けないため、ここでは Python ライブラリ(fastavro、pyarrow)を使って読み取り、整形して表示しています。各ファイルの役割は後述のまとめで整理しています。
Python スクリプトの使い方
# Avro / Parquet 読み取り用ライブラリをインストール
pip install fastavro pyarrow
# S3 からファイルをダウンロード
aws s3 cp s3://your-bucket-name/iceberg/metadata/00004-xxx.metadata.json ./
aws s3 cp s3://your-bucket-name/iceberg/metadata/snap-xxx.avro ./
aws s3 cp s3://your-bucket-name/iceberg/metadata/xxx-m0.avro ./
aws s3 cp s3://your-bucket-name/iceberg/data/xxx/xxx.parquet ./
# 読み取りスクリプトの使い方
python read_iceberg_files.py snapshot <path> # Manifest List (snap-*.avro)
python read_iceberg_files.py manifest <path> # Manifest File (*-m0.avro)
python read_iceberg_files.py parquet <path> # Data / Delete File (*.parquet)
read_iceberg_files.py(クリックで展開)
"""
Iceberg ファイル読み取りスクリプト
使い方:
python read_iceberg_files.py snapshot <path> # Manifest List (snap-*.avro)
python read_iceberg_files.py manifest <path> # Manifest File (*-m0.avro)
python read_iceberg_files.py parquet <path> # Data File (*.parquet)
"""
import sys
def read_snapshot(path):
"""Manifest List (snap-*.avro) を読む"""
import fastavro
print(f"=== Manifest List: {path} ===\n")
with open(path, 'rb') as f:
reader = fastavro.reader(f)
print("--- Records ---")
for i, record in enumerate(reader):
print(f"\n[Manifest {i}]")
print(f" manifest_path: {record.get('manifest_path', 'N/A')}")
print(f" manifest_length: {record.get('manifest_length', 'N/A')} bytes")
print(f" partition_spec_id: {record.get('partition_spec_id', 'N/A')}")
print(f" content: {record.get('content', 'N/A')} (0=data, 1=deletes)")
print(f" added_snapshot_id: {record.get('added_snapshot_id', 'N/A')}")
print(f" added_rows_count: {record.get('added_rows_count', 'N/A')}")
print(f" existing_rows_count: {record.get('existing_rows_count', 'N/A')}")
print(f" deleted_rows_count: {record.get('deleted_rows_count', 'N/A')}")
def read_manifest(path):
"""Manifest File (*-m0.avro) を読む"""
import fastavro
print(f"=== Manifest File: {path} ===\n")
with open(path, 'rb') as f:
reader = fastavro.reader(f)
print("--- Records ---")
for i, record in enumerate(reader):
data_file = record.get('data_file', {})
content = data_file.get('content', 0)
content_type = {0: 'data', 1: 'position deletes', 2: 'equality deletes'}.get(content, 'unknown')
print(f"\n[Entry {i}]")
print(f" status: {record.get('status', 'N/A')} (1=added, 2=existing, 3=deleted)")
print(f" snapshot_id: {record.get('snapshot_id', 'N/A')}")
print(f" content: {content} ({content_type})")
print(f" file_path: {data_file.get('file_path', 'N/A')}")
print(f" file_format: {data_file.get('file_format', 'N/A')}")
print(f" record_count: {data_file.get('record_count', 'N/A')}")
print(f" file_size_in_bytes: {data_file.get('file_size_in_bytes', 'N/A')}")
if i >= 9:
print(f"\n... (以降省略、全 {i+1}+ 件)")
break
def read_parquet(path):
"""Parquet ファイルを読む"""
import pyarrow.parquet as pq
print(f"=== Parquet File: {path} ===\n")
parquet_file = pq.ParquetFile(path)
metadata = parquet_file.metadata
print("--- Metadata ---")
print(f" num_rows: {metadata.num_rows}")
print(f" num_columns: {metadata.num_columns}")
print("\n--- Schema ---")
schema = parquet_file.schema_arrow
for field in schema:
print(f" {field.name}: {field.type}")
print("\n--- Data Preview (先頭10行) ---")
table = parquet_file.read()
df = table.to_pandas()
print(df.head(10).to_string())
def main():
if len(sys.argv) < 3:
print(__doc__)
sys.exit(1)
file_type = sys.argv[1]
path = sys.argv[2]
if file_type == 'snapshot':
read_snapshot(path)
elif file_type == 'manifest':
read_manifest(path)
elif file_type == 'parquet':
read_parquet(path)
else:
print(f"Unknown file type: {file_type}")
sys.exit(1)
if __name__ == '__main__':
main()
metadata.json の中身を覗いてみる
最新の metadata.json(00004-*.metadata.json)を見ると、Iceberg がどのように変更履歴を管理しているかがわかります。まず全体を見てから、各部分を解説します。
metadata.json 全体(クリックで展開)
{
"format-version" : 2,
"table-uuid" : "002bd9f3-4026-4f4b-a47f-ada7fd579281",
"location" : "s3://your-bucket-name/iceberg",
"last-sequence-number" : 3,
"last-updated-ms" : 1768390451352,
"last-column-id" : 15,
"current-schema-id" : 1,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [
{ "id" : 1, "name" : "pickup", "required" : false, "type" : "string" },
{ "id" : 2, "name" : "dropoff", "required" : false, "type" : "string" },
{ "id" : 3, "name" : "passengers", "required" : false, "type" : "int" },
{ "id" : 4, "name" : "distance", "required" : false, "type" : "double" },
{ "id" : 5, "name" : "fare", "required" : false, "type" : "double" },
{ "id" : 6, "name" : "tip", "required" : false, "type" : "double" },
{ "id" : 7, "name" : "tolls", "required" : false, "type" : "double" },
{ "id" : 8, "name" : "total", "required" : false, "type" : "double" },
{ "id" : 9, "name" : "color", "required" : false, "type" : "string" },
{ "id" : 10, "name" : "payment", "required" : false, "type" : "string" },
{ "id" : 11, "name" : "pickup_zone", "required" : false, "type" : "string" },
{ "id" : 12, "name" : "dropoff_zone", "required" : false, "type" : "string" },
{ "id" : 13, "name" : "pickup_borough", "required" : false, "type" : "string" },
{ "id" : 14, "name" : "dropoff_borough", "required" : false, "type" : "string" }
]
}, {
"type" : "struct",
"schema-id" : 1,
"fields" : [
{ "id" : 1, "name" : "pickup", "required" : false, "type" : "string" },
{ "id" : 2, "name" : "dropoff", "required" : false, "type" : "string" },
{ "id" : 3, "name" : "passengers", "required" : false, "type" : "int" },
{ "id" : 4, "name" : "distance", "required" : false, "type" : "double" },
{ "id" : 5, "name" : "fare", "required" : false, "type" : "double" },
{ "id" : 6, "name" : "tip", "required" : false, "type" : "double" },
{ "id" : 7, "name" : "tolls", "required" : false, "type" : "double" },
{ "id" : 8, "name" : "total", "required" : false, "type" : "double" },
{ "id" : 9, "name" : "color", "required" : false, "type" : "string" },
{ "id" : 10, "name" : "payment", "required" : false, "type" : "string" },
{ "id" : 11, "name" : "pickup_zone", "required" : false, "type" : "string" },
{ "id" : 12, "name" : "dropoff_zone", "required" : false, "type" : "string" },
{ "id" : 13, "name" : "pickup_borough", "required" : false, "type" : "string" },
{ "id" : 14, "name" : "dropoff_borough", "required" : false, "type" : "string" },
{ "id" : 15, "name" : "is_weekend", "required" : false, "type" : "boolean" }
]
} ],
"default-spec-id" : 0,
"partition-specs" : [ { "spec-id" : 0, "fields" : [ ] } ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ { "order-id" : 0, "fields" : [ ] } ],
"properties" : {
"write.object-storage.enabled" : "true",
"write.object-storage.path" : "s3://your-bucket-name/iceberg/data",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : 6043730672255953016,
"refs" : { "main" : { "snapshot-id" : 6043730672255953016, "type" : "branch" } },
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 1477755431002976861,
"timestamp-ms" : 1768387122365,
"summary" : {
"operation" : "append",
"added-data-files" : "1",
"added-records" : "6433",
"total-records" : "6433",
"total-data-files" : "1",
"total-delete-files" : "0"
},
"manifest-list" : "s3://your-bucket-name/iceberg/metadata/snap-1477755431002976861-1-8f42097e-d438-4d91-8b3a-1909eff99dc2.avro",
"schema-id" : 0
}, {
"sequence-number" : 2,
"snapshot-id" : 635643277371762727,
"parent-snapshot-id" : 1477755431002976861,
"timestamp-ms" : 1768388141795,
"summary" : {
"operation" : "overwrite",
"added-data-files" : "1",
"added-position-delete-files" : "1",
"added-delete-files" : "1",
"added-records" : "1812",
"added-position-deletes" : "1812",
"total-records" : "8245",
"total-data-files" : "2",
"total-delete-files" : "1",
"total-position-deletes" : "1812"
},
"manifest-list" : "s3://your-bucket-name/iceberg/metadata/snap-635643277371762727-1-8dcbd209-8232-44dd-9d02-430ea1357489.avro",
"schema-id" : 0
}, {
"sequence-number" : 3,
"snapshot-id" : 6043730672255953016,
"parent-snapshot-id" : 635643277371762727,
"timestamp-ms" : 1768388842854,
"summary" : {
"operation" : "overwrite",
"added-position-delete-files" : "2",
"added-delete-files" : "2",
"added-position-deletes" : "96",
"total-records" : "8245",
"total-data-files" : "2",
"total-delete-files" : "3",
"total-position-deletes" : "1908"
},
"manifest-list" : "s3://your-bucket-name/iceberg/metadata/snap-6043730672255953016-1-ac88c5f7-602f-4695-832a-7c8df4ab7db1.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"snapshot-log" : [
{ "timestamp-ms" : 1768387122365, "snapshot-id" : 1477755431002976861 },
{ "timestamp-ms" : 1768388141795, "snapshot-id" : 635643277371762727 },
{ "timestamp-ms" : 1768388842854, "snapshot-id" : 6043730672255953016 }
],
"metadata-log" : [
{ "timestamp-ms" : 1768386618442, "metadata-file" : "s3://your-bucket-name/iceberg/metadata/00000-8835bb85-b387-4c89-913b-6b1d3c6aefd3.metadata.json" },
{ "timestamp-ms" : 1768387122365, "metadata-file" : "s3://your-bucket-name/iceberg/metadata/00001-3871af6f-0782-4419-8aa6-6cfd9e045fcc.metadata.json" },
{ "timestamp-ms" : 1768388141795, "metadata-file" : "s3://your-bucket-name/iceberg/metadata/00002-99054ad3-7e8f-4252-b77c-dc6e566e03ec.metadata.json" },
{ "timestamp-ms" : 1768388842854, "metadata-file" : "s3://your-bucket-name/iceberg/metadata/00003-3c7634c0-24e6-4904-9e6d-e8154a097d3e.metadata.json" }
]
}
トップレベルの主要フィールド
| フィールド | 値 | 説明 |
|---|---|---|
format-version |
2 | Iceberg v2 フォーマット |
current-schema-id |
1 | 現在使用しているスキーマ ID |
current-snapshot-id |
6043730672255953016 | 現在参照しているスナップショット |
schemas |
[...] | スキーマの履歴(schema-id: 0, 1) |
snapshots |
[...] | スナップショットの履歴 |
スキーマ進化(schemas)
| schema-id | カラム数 | 変更点 |
|---|---|---|
| 0 | 14 | 初期スキーマ(pickup 〜 dropoff_borough) |
| 1 | 15 | is_weekend カラムを追加 |
テーブルの current-schema-id は 1 ですが、既存の全スナップショットは schema-id: 0 で作成されています。スキーマ進化後にデータを書き込むと、新しいスナップショットは schema-id: 1 を参照します。
スナップショット履歴(snapshots)
| # | operation | schema-id | 内容 |
|---|---|---|---|
| 1 | append | 0 | INSERT: 6,433件追加 |
| 2 | overwrite | 0 | UPDATE: 1,812件更新 |
| 3 | overwrite | 0 | DELETE: 96件削除 |
UPDATE の仕組み
UPDATE(sequence-number: 2)の summary の項目を整理しましょう。
| フィールド | 値 | 意味 |
|---|---|---|
added-records |
1812 | 更新後の新しいデータ行(payment = 'Cash') |
added-position-deletes |
1812 | 削除対象としてマークされた古い行(payment = 'cash') |
added-delete-files |
1 | この操作で追加された Position Delete File の数 |
total-delete-files |
1 | テーブル全体の Position Delete File 数 |
UPDATE = 古い行の位置を Position Delete File に記録 + 新しい行を追加 するという動作になっています。
書き込み方式の詳細は以下のブログを参照ください!
Manifest List の中身を覗いてみる
snap-*.avro は Manifest List ファイルです。ファイル名に snap- とスナップショット ID が含まれていますが、中身はスナップショットのデータではなく、Manifest File の一覧です。スナップショットの定義自体は metadata.json 内にあり、そこから Manifest List が参照されます。
なぜこの構造なのか?
スナップショットを復元するには「どのデータファイルが有効か」を知る必要がありますが、Iceberg はデータファイルを直接管理せず、Manifest File を経由します。そのため、Manifest List には「このスナップショット時点で参照すべき Manifest File の一覧」が格納されています。この間接参照により、新しい操作に対応する Manifest File だけ追加し、既存の Manifest File は再利用できるため効率的です(階層構造の詳細は後述のまとめを参照)。
Manifest List の主要フィールド(Avro スキーマより)
| フィールド | 説明 |
|---|---|
| manifest_path | Manifest File のパス |
| content | 内容種別(0=data, 1=position deletes) |
| added_snapshot_id | この Manifest が追加されたスナップショット ID |
| added_rows_count | この Manifest が管理するファイル内の行数 |
Manifest List の中身(クリックで展開)
[Manifest 0]
manifest_path: s3://.../8dcbd209-...-m0.avro
manifest_length: 7673 bytes
partition_spec_id: 0
content: 0 (0=data, 1=deletes)
added_snapshot_id: 635643277371762727
added_rows_count: 1812
existing_rows_count: 0
deleted_rows_count: 0
[Manifest 1]
manifest_path: s3://.../8f42097e-...-m0.avro
manifest_length: 7691 bytes
partition_spec_id: 0
content: 0 (0=data, 1=deletes)
added_snapshot_id: 1477755431002976861
added_rows_count: 6433
existing_rows_count: 0
deleted_rows_count: 0
[Manifest 2]
manifest_path: s3://.../ac88c5f7-...-m0.avro
manifest_length: 7610 bytes
partition_spec_id: 0
content: 1 (0=data, 1=deletes)
added_snapshot_id: 6043730672255953016
added_rows_count: 96
existing_rows_count: 0
deleted_rows_count: 0
[Manifest 3]
manifest_path: s3://.../8dcbd209-...-m1.avro
manifest_length: 7487 bytes
partition_spec_id: 0
content: 1 (0=data, 1=deletes)
added_snapshot_id: 635643277371762727
added_rows_count: 1812
existing_rows_count: 0
deleted_rows_count: 0
| Manifest | content | 説明 | 行数 |
|---|---|---|---|
| Manifest 0 | 0 (data) | UPDATE で追加された新しい行(payment = 'Cash') |
1,812 |
| Manifest 1 | 0 (data) | INSERT で追加された元データ | 6,433 |
| Manifest 2 | 1 (deletes) | DELETE で削除マークされた行(passengers = 0) |
96 |
| Manifest 3 | 1 (deletes) | UPDATE で削除マークされた古い行(payment = 'cash') |
1,812 |
現在のスナップショットは 4つの Manifest File を参照しており、それぞれがデータファイルまたは Delete File を管理しています。タイムトラベル時は、過去のスナップショットが参照する Manifest File のセットを使ってデータを再構築します。
Manifest File の中身を覗いてみる
Manifest File(*-m0.avro)は、データファイルや Delete File のリストを管理しています。
DELETE 操作後の Manifest File を見ると、Position Delete File が登録されていることがわかります。
Manifest File の中身(クリックで展開)
[Entry 0]
status: 1 (1=added, 2=existing, 3=deleted)
snapshot_id: 6043730672255953016
content: 1 (position deletes)
file_path: s3://your-bucket-name/iceberg/data/va5F1g/20260114_110721_00043_k64c9-bc0ad815-ad87-4ac8-9964-19d5d36aca70.parquet
file_format: PARQUET
record_count: 83
file_size_in_bytes: 1099
[Entry 1]
status: 1 (1=added, 2=existing, 3=deleted)
snapshot_id: 6043730672255953016
content: 1 (position deletes)
file_path: s3://your-bucket-name/iceberg/data/_WNpKQ/20260114_110721_00043_k64c9-a1506c5c-239a-4736-9e0a-b85195b4d97a.parquet
file_format: PARQUET
record_count: 13
file_size_in_bytes: 996
ポイント
record_count: 83と13の合計 96件が、DELETE で削除した件数と一致- Position Delete File も Parquet 形式で保存されている
Iceberg の削除動作
UPDATE の仕組みでも触れましたが、Iceberg は Merge-on-Read 方式を採用しており、既存のデータファイルを直接変更しません。DELETE も同様に、「どの行を削除するか」を Position Delete File に記録します。
この仕組みにより、元データを保持したまま論理削除を実現しています。物理削除しないことで、タイムトラベルや障害復旧が可能になります。
ただし、Delete File が増えるとクエリ時のマージ処理が重くなります。運用では定期的に Compaction(データファイルの統合)や Expire Snapshots(古いスナップショットの削除)を実行して、不要なファイルを物理削除することが推奨されます。
参考: Apache Iceberg Spec - Position Delete Files
Apache Iceberg - Maintenance
Position Delete File の中身を覗いてみる
Position Delete File の Parquet ファイルを実際に開いてみると、その正体がわかります。
Position Delete File の中身(クリックで展開)
--- Metadata ---
num_rows: 83
num_columns: 2
--- Schema ---
file_path: string
pos: int64
--- Data Preview (先頭10行) ---
file_path pos
0 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 7
1 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 92
2 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 117
3 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 278
4 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 389
5 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 417
6 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 420
7 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 529
8 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 641
9 s3://.../KqwkNw/20260114_103841_00124_him48-....parquet 695
Position Delete File の構造
file_path- 削除対象のデータファイルのパスpos- そのファイル内の削除対象の行番号(0-indexed)
つまり「KqwkNw/... の Parquet ファイルの 7行目、92行目、117行目、... を削除する」という情報が記録されています。クエリ実行時にこの情報を参照して、該当行をスキップすることで論理削除を実現しています。
もう1つの Position Delete File(Entry 1)も見てみると、参照先のデータファイルが異なることがわかります。
Entry 1 の Position Delete File(クリックで展開)
--- Metadata ---
num_rows: 13
num_columns: 2
--- Schema ---
file_path: string
pos: int64
--- Data Preview (先頭10行) ---
file_path pos
0 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 3
1 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 11
2 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 60
3 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 184
4 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 290
5 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 499
6 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 534
7 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 559
8 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 604
9 s3://.../umF6Hw/20260114_105540_00124_az5k7-....parquet 624
| Position Delete File | 参照先データファイル | 削除件数 |
|---|---|---|
| Entry 0 | KqwkNw/...(INSERT 時のデータ) | 83件 |
| Entry 1 | umF6Hw/...(UPDATE 時のデータ) | 13件 |
DELETE 対象の行が複数のデータファイルに分散していたため、それぞれに対応する Position Delete File が作成されています。合計 83 + 13 = 96件で、DELETE した件数と一致します。
Iceberg の階層構造まとめ
ここまで見てきた内容を整理すると、Iceberg は「リストのリスト」といった階層構造になっています。
| ファイル | 形式 | 役割 |
|---|---|---|
| metadata.json | JSON | スナップショットのリスト(+ スキーマ、設定など) |
| Manifest List(snap-*.avro) | Avro | Manifest File のリスト |
| Manifest File(*-m0.avro 等) | Avro | データファイルのリスト |
| Data Files(*.parquet) | Parquet | 実データ / Position Delete File |
metadata.json
└── snapshots[]
└── snapshot → Manifest List(snap-*.avro)
└── Manifest File(*-m0.avro)
└── Data File(*.parquet)
この階層構造により、スナップショットごとに「どのデータファイルが有効か」を効率的に追跡でき、タイムトラベルや ACID トランザクションが実現されています。
お片付け
Athena テーブル・データベースの削除
DROP TABLE IF EXISTS taxi_db.taxis_iceberg;
DROP TABLE IF EXISTS taxi_db.taxis_csv;
DROP DATABASE IF EXISTS taxi_db;
S3 データの削除
aws s3 rm s3://your-bucket-name/ --recursive
aws s3 rb s3://your-bucket-name
まとめ
| 機能 | S3 + Parquet のみ | Iceberg テーブル |
|---|---|---|
| UPDATE/DELETE | 不可 | 行レベルで可能 |
| トランザクション | なし | ACID 保証 |
| タイムトラベル | 不可 | スナップショットで可能 |
| スキーマ変更 | テーブル再作成が必要 | ALTER TABLE で柔軟に変更可能 |
Apache Iceberg を使うことで、S3 上のデータレイクでもデータベースのような操作性を実現できます。
なお、今回はパーティションなしで検証しましたが、パーティションを活用するとクエリ時に不要なファイルをスキップでき、さらに効率的なデータ管理が可能です。
今後は AWS の新サービス S3 Tables(Iceberg をマネージドで扱える)についても触ってみたいと思います。
最後までお読みいただきありがとうございました!










