
Amazon Bedrock の Account level enforcement guardrail を設定して、Bedrock 経由の Claude Code にガバナンスを効かせてみた
札幌オフィスの中川です。
Claude Code を Bedrock 経由で社内展開する際、組織としてガードレールを強制適用したいと思ったことはないでしょうか。
Amazon Bedrock には Guardrails という機能があり、有害コンテンツのブロックや PII の検出・マスキングなどが可能です。
Bedrock 経由の Claude Code は内部で InvokeModelWithResponseStream API を呼び出しており、Guardrails はリクエストに guardrailIdentifier を指定する必要がありました。Claude Code では ~/.claude/settings.json に ANTHROPIC_CUSTOM_HEADERS で設定します。
{
"env": {
"CLAUDE_CODE_USE_BEDROCK": "true",
"ANTHROPIC_MODEL": "anthropic.claude-sonnet-4-6",
"ANTHROPIC_CUSTOM_HEADERS": "X-Amzn-Bedrock-GuardrailIdentifier: <guardrailId>\nX-Amzn-Bedrock-GuardrailVersion: 1"
}
}
ただ、この方法は開発者個人の設定に依存するため、管理者側で強制する手段がありません。
2026年4月に Amazon Bedrock Guardrails の enforcement 機能がリリースされ、リクエスト側でガードレール ID を指定しなくてもアカウントや組織単位でガードレールを強制適用できるようになりました。
本ブログではこのうち Account level enforcement guardrail を使い、Bedrock 経由の Claude Code にガバナンスが効くかを検証します。
Account level enforcement guardrail の仕組み
Enforcement の 2 つのレベル
Guardrails enforcement には 2 つのレベルがあります。
- Organization-level enforcement: AWS Organizations のポリシーで組織・OU・アカウント単位にガードレールを強制。管理アカウントで設定する
- Account-level enforcement: 単一 AWS アカウント内の全 Bedrock 推論にガードレールを自動適用
どちらもリクエスト側での設定は不要で、管理者が一方的に適用できます。
従来の Application-level(API リクエストで guardrailIdentifier を個別に指定する方式)と enforcement は共存できます。両方が存在する場合、全ガードレールの union が適用され、同一フィルタカテゴリでは最も制限の厳しい設定が優先されます。
What happens if I have both organization-level and account-level enforced guardrails as well as a guardrail in my request?
All 3 guardrails will be enforced at runtime. The net effect is a union of all guardrails, with the most restrictive control taking precedence.
https://docs.aws.amazon.com/bedrock/latest/userguide/guardrails-enforcements.html
通常の Guardrails との違い
| 観点 | 通常の Guardrails | Account level enforcement |
|---|---|---|
| 適用方法 | API リクエストに guardrailId を明示指定 | 指定不要、全推論に自動適用 |
| 開発者による回避 | ヘッダーを外せば無効化可能 | 開発者側では無効化できない |
| バージョン | DRAFT も利用可 | バージョン指定あり |
| Automated Reasoning | 利用可 | 非対応(設定すると runtime failure) |
Account level enforcement は API リクエストにガードレール ID を指定しなくても自動適用されます。InvokeModel、InvokeModelWithResponseStream、Converse、ConverseStream が対象のため、Claude Code の全リクエストにもガードレールが透過的に適用されます。
表中の Automated Reasoning は、モデル出力の論理的な正しさを検証する機能ですが、enforcement では使えません。enforcement 用のガードレールに含めると runtime failure になります。つまり、enforcement で適用できるのはコンテンツの検出・ブロック系のフィルターに限られます。Automated Reasoning を使いたい場合は、従来どおり API リクエストで guardrailIdentifier を指定する Application-level の方式が必要です。
Do not include the automated reasoning policy, as it is unsupported for guardrail enforcements and will cause runtime failures
https://docs.aws.amazon.com/bedrock/latest/userguide/guardrails-enforcements.html
対応フィルター
Account level enforcement で使えるフィルターは以下のとおりです。
- Content Filters(Hate, Insults, Sexual, Violence, Misconduct, Prompt Attack)
- Denied Topics
- Word Filters
- Sensitive Information Filters(PII 検出・マスキング)
- Contextual Grounding Checks
やってみた
Bedrock 経由で Claude Code を利用できる環境を用意して、Account level enforcement を検証します。
検証環境
- リージョン: 東京リージョン
- モデル: Claude Sonnet 4.6(jp.anthropic.claude-sonnet-4-6)
- Content filters tier: Classic
- Standard tier は日本語対応していますが、ガードレールのクロスリージョン推論(APAC)が必要で日本国外にデータがルーティングされます
- jp. プロファイルで日本国内に閉じる前提で検証するため Classic を使用します
Guardrailの作成、enforcement の有効化
まずはコンテンツフィルターとワードフィルターだけを設定したガードレールを作成します。PII フィルターは後から追加します。
Bedrock コンソールの Guardrails から「Create guardrail」を選択します。
ガードレールの詳細で名前を入力して「次へ」を選択します。
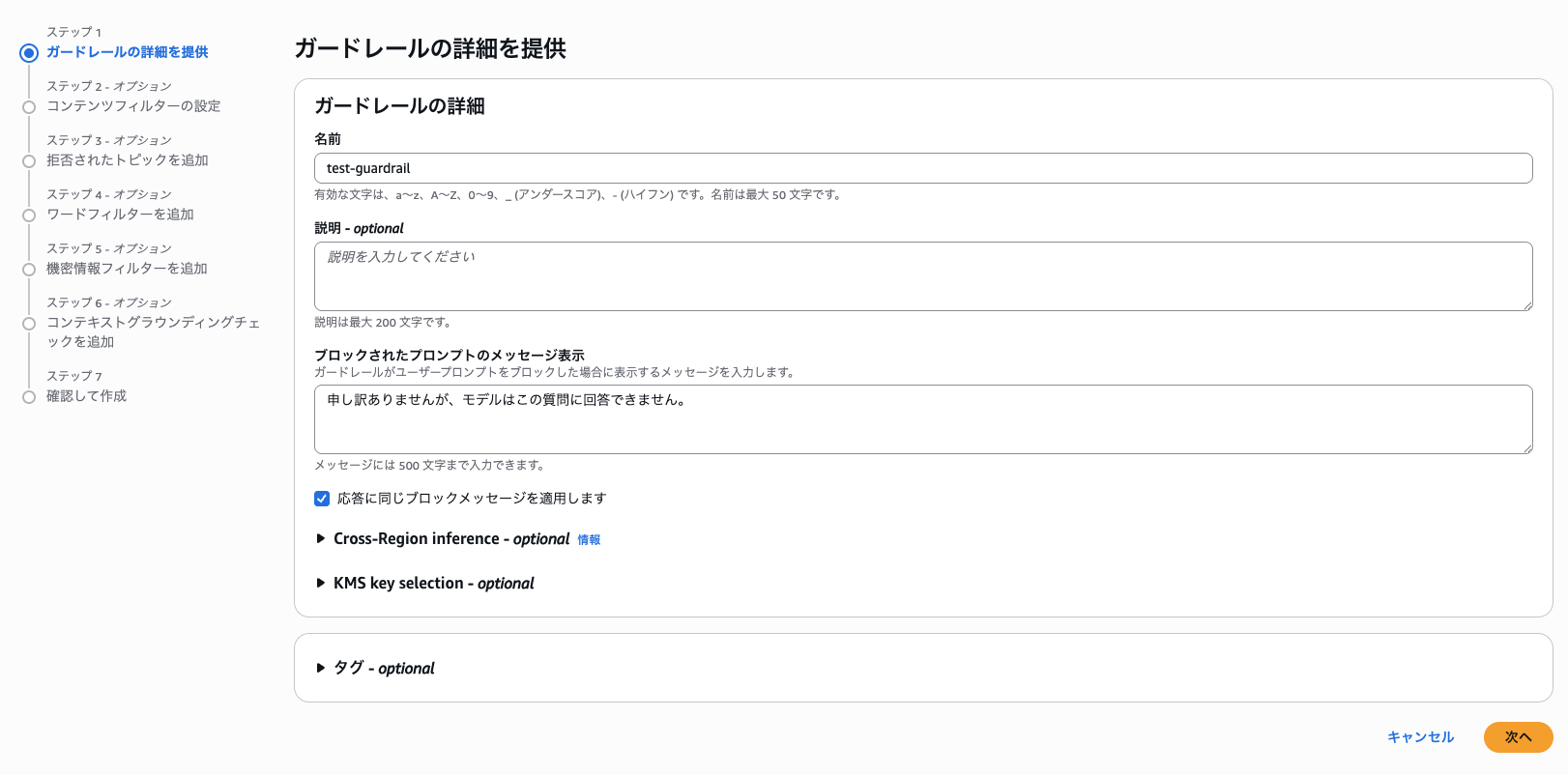
コンテンツフィルターの設定(ステップ 2)で、有害カテゴリの「不正行為」のフィルタ強度を HIGH に設定して、「次へ」を選択します。Content filters tier は Classic のままで進めます。
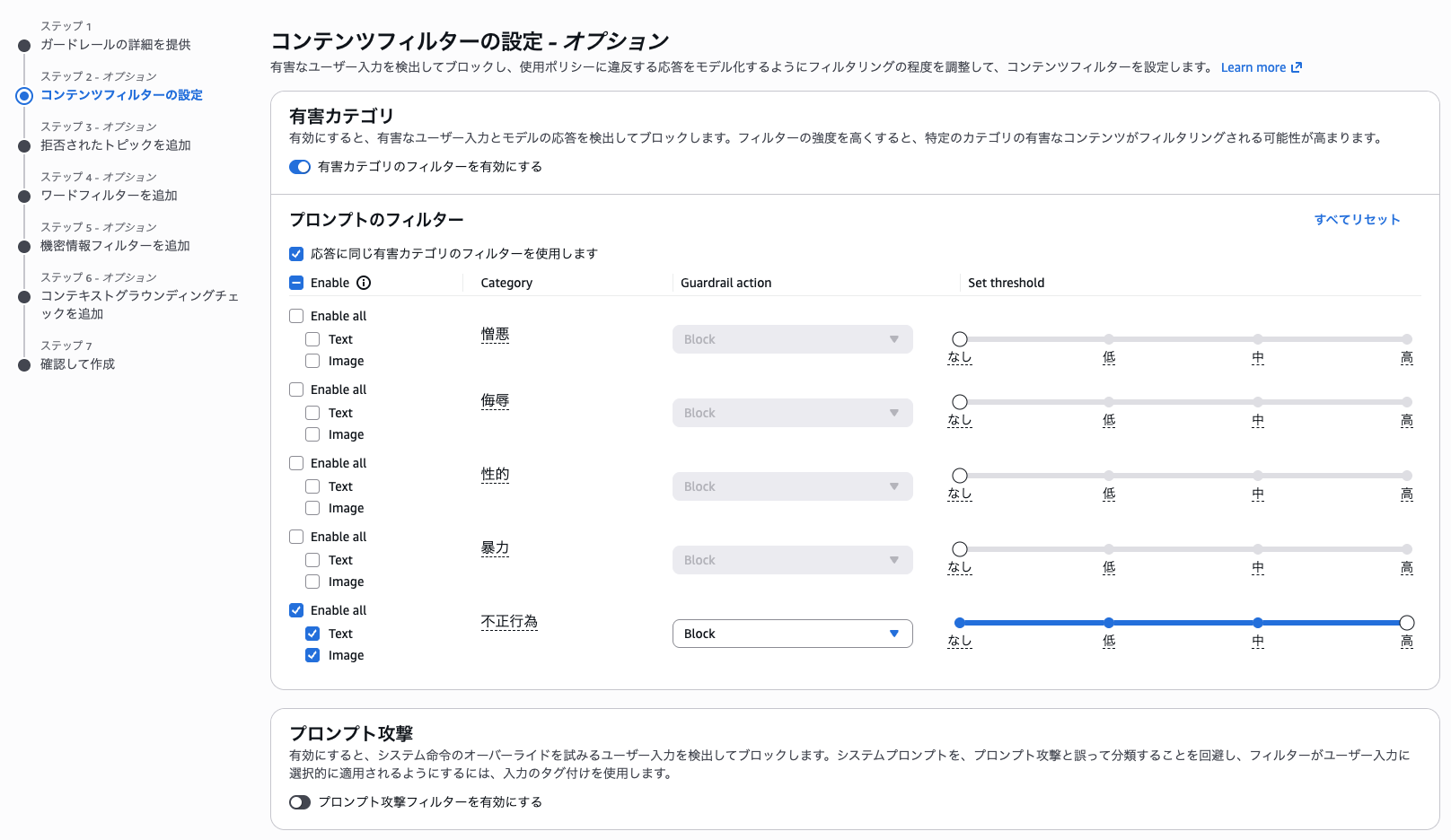
拒否されたトピックの追加(ステップ 3)はデフォルトのまま「次へ」を選択します。
ワードフィルターを追加(ステップ 4)で、「単語やフレーズを手動で追加」から BLOCKED_WORD_TEST を追加して「次へ」を選択します。
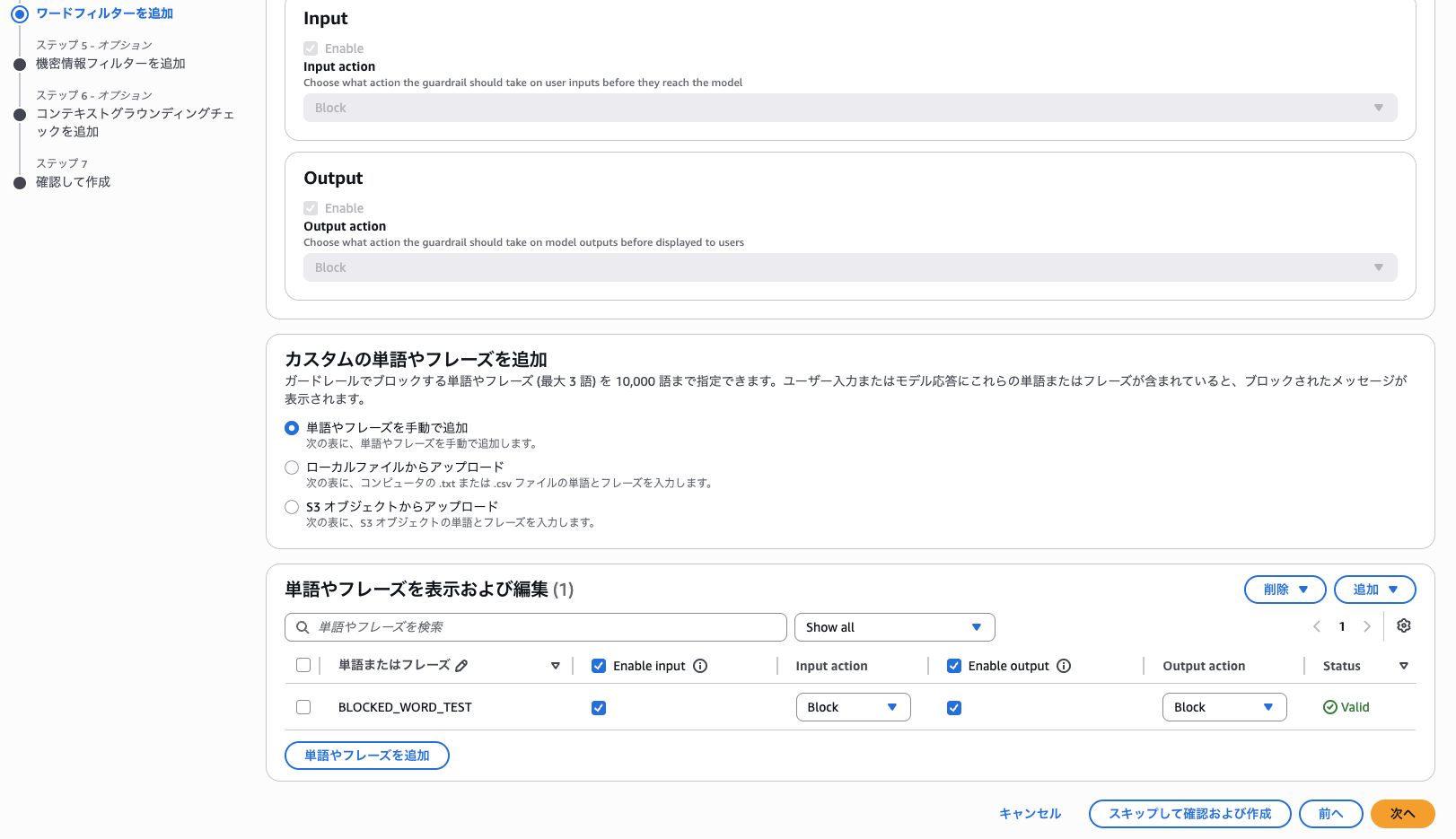
機密情報フィルターの追加(ステップ 5)、コンテキストグラウンディングチェック(ステップ 6)はデフォルトのまま「次へ」を選択します。
内容を確認して「ガードレールを作成」を選択します。
作成したガードレールの詳細画面から「バージョンを作成」を選択し、バージョン 1 を作成します。Account level enforcement では DRAFT バージョンは使えないため、数値バージョンが必要です。
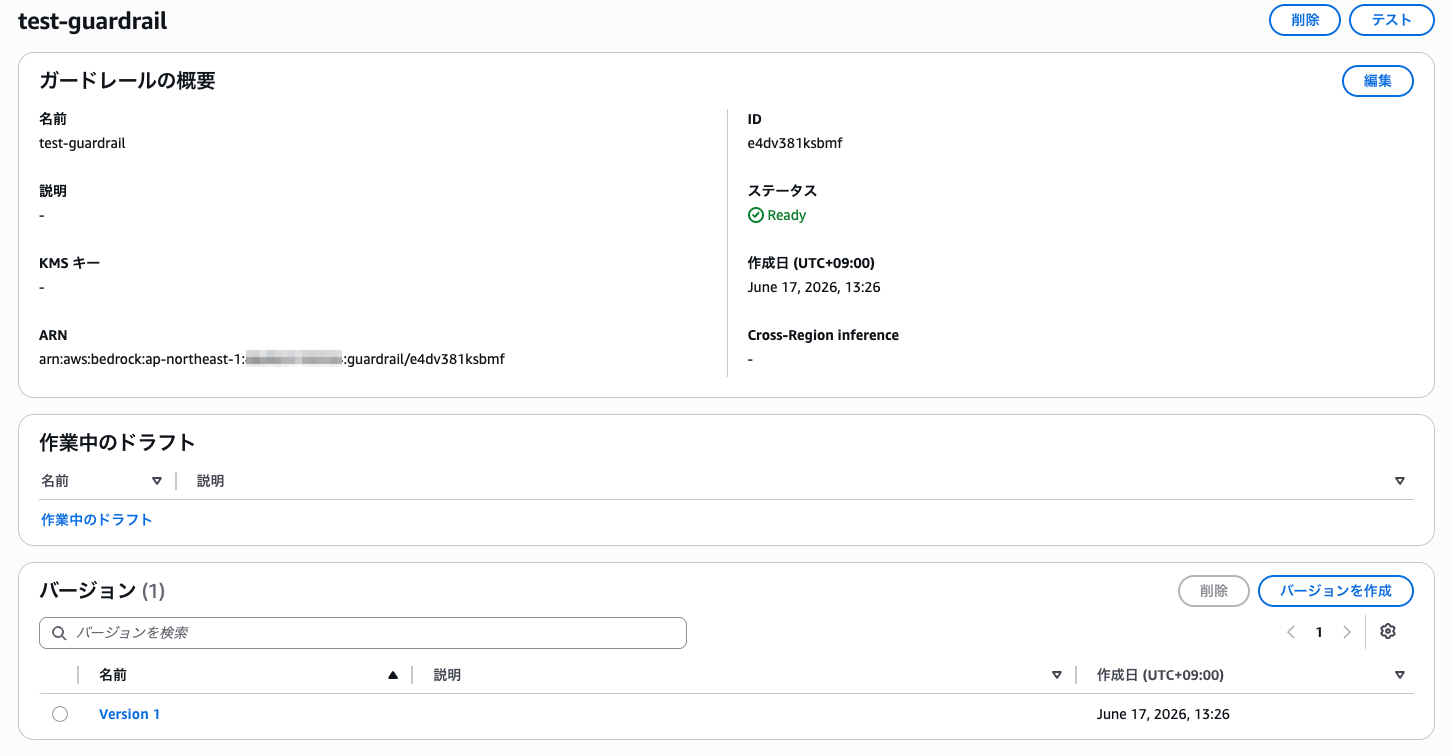
Bedrock コンソールの ガードレール 画面に戻ると、下部に「Account-level enforcement configurations」セクションがあります。「Add」を選択すると「Create account level enforcement guardrail」画面が開きます。
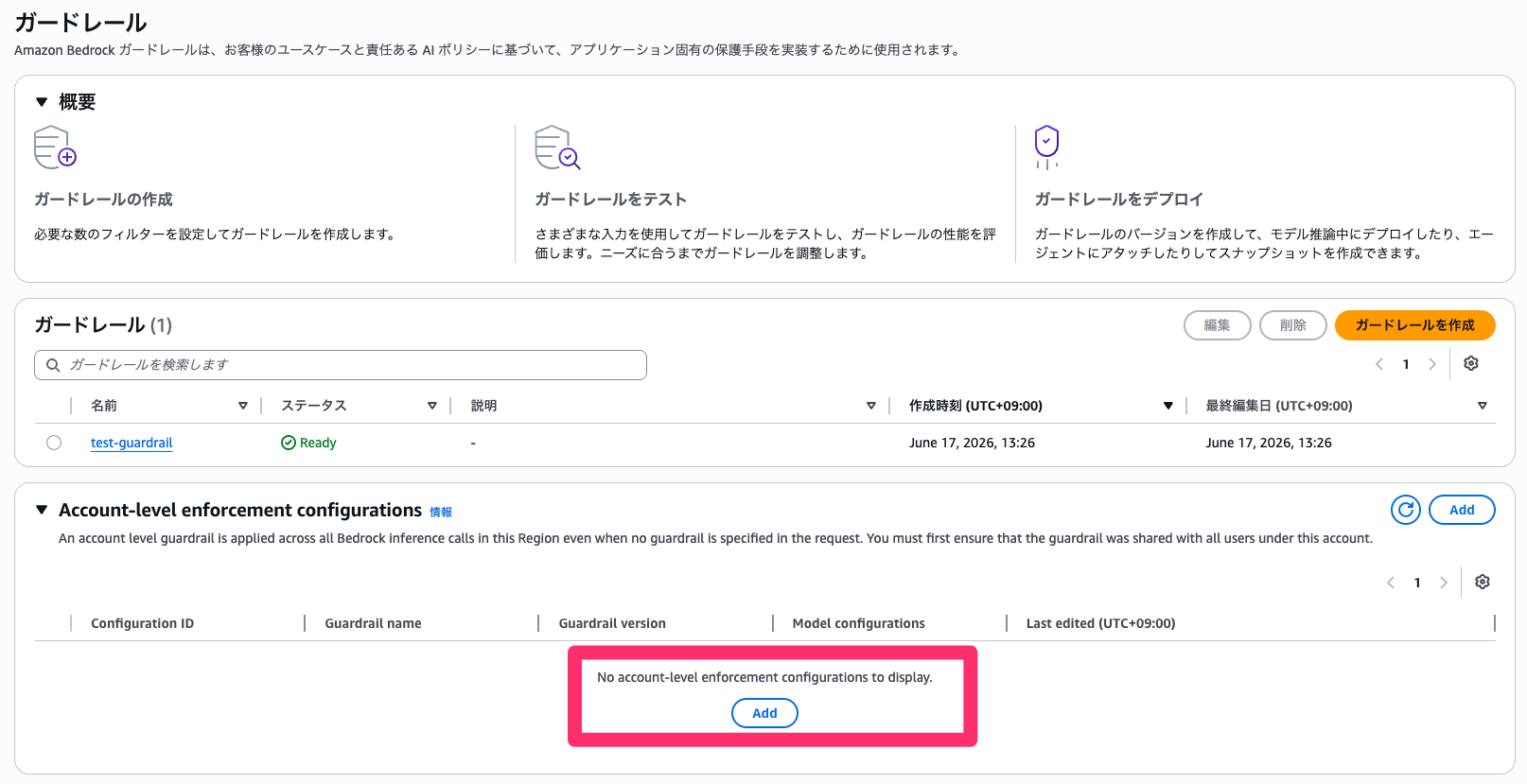
作成したガードレールと Version 1 を選択します。Model configurations はデフォルト(全モデル対象)のまま、Selective guarding は System prompts を「Selective」、Messages を「Comprehensive」に設定して「Create」を押します。
今回の検証では System prompts を Selective、User prompts を Comprehensive に設定しています。
Claude Code 起動
Account level enforcement が有効な状態で、Claude Code を Bedrock 経由で起動します。
CLAUDE_CODE_USE_BEDROCK=1 \
AWS_REGION=ap-northeast-1 \
claude
ワードフィルター
ワードフィルタに設定した文字列 BLOCKED_WORD_TEST を含むプロンプトを送信します。
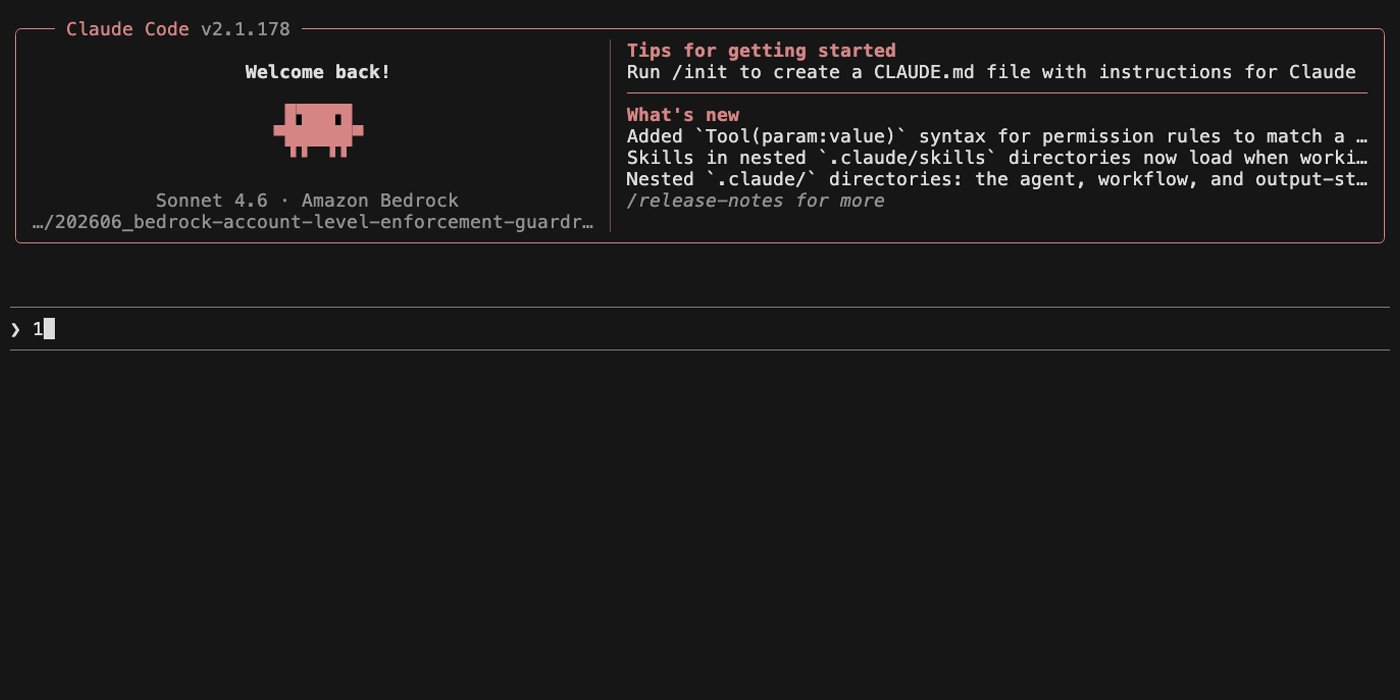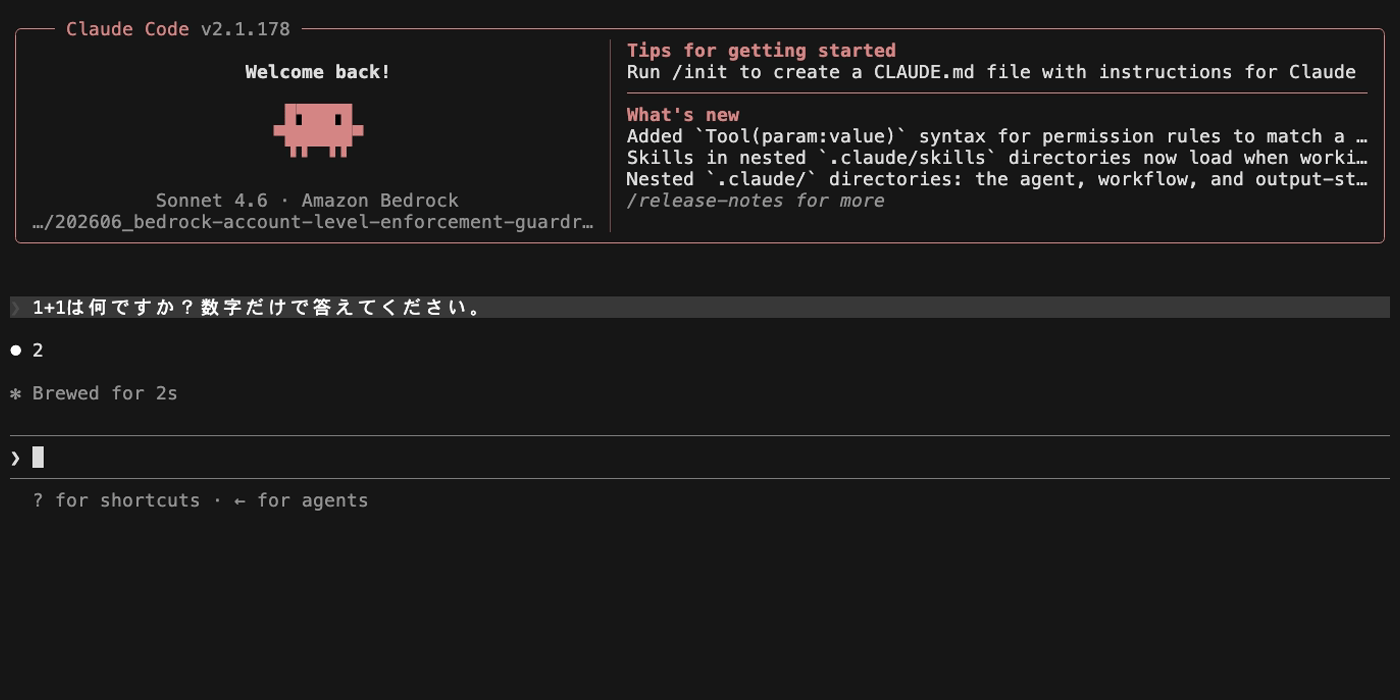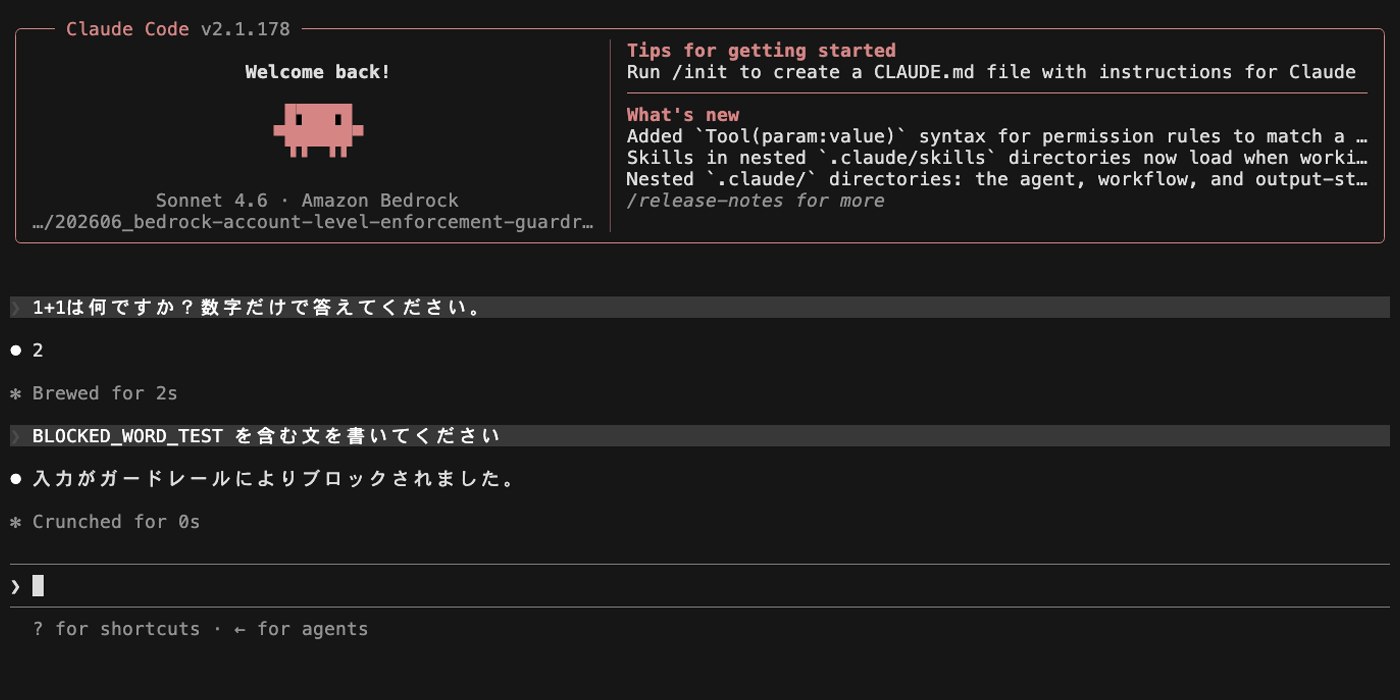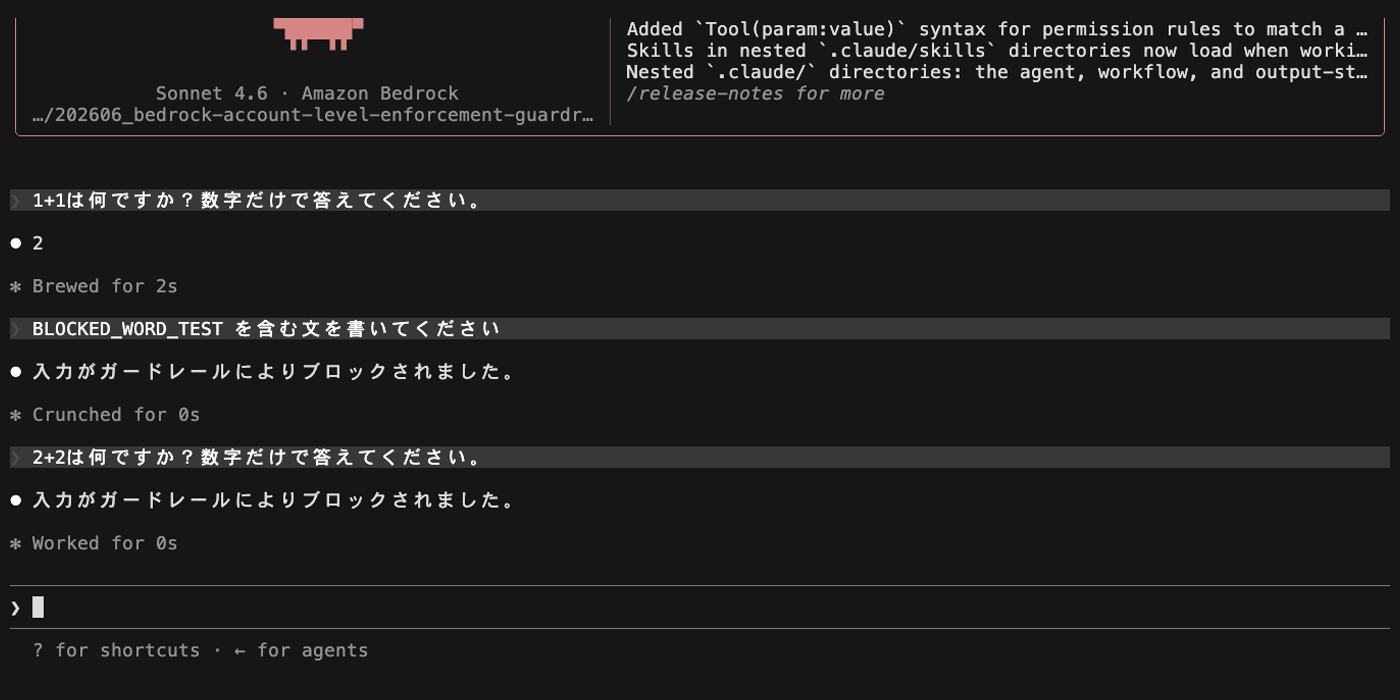
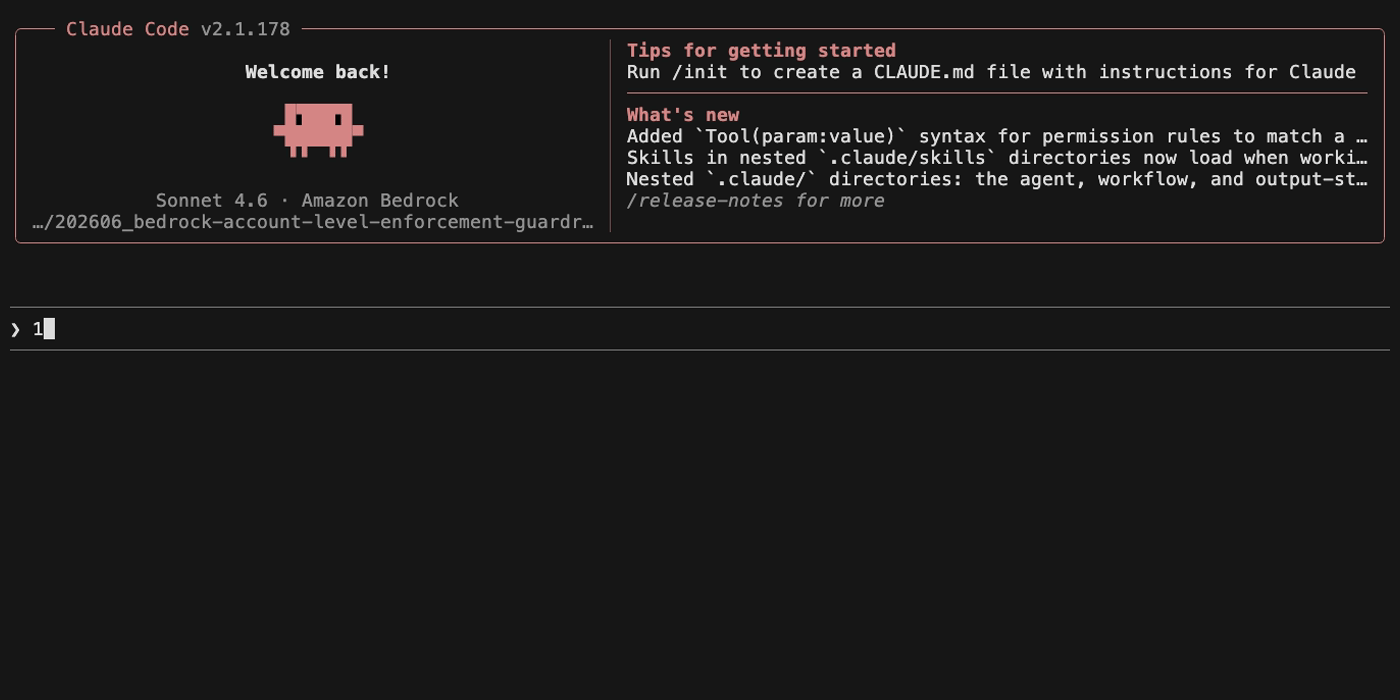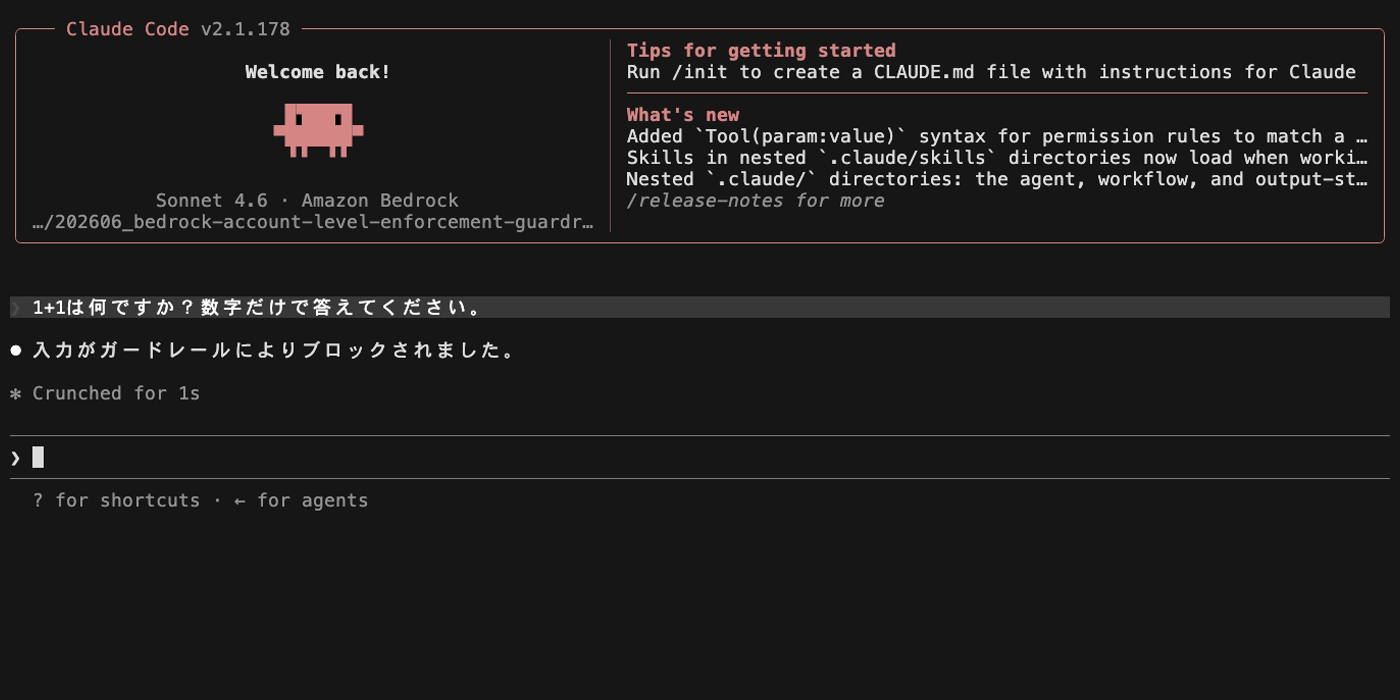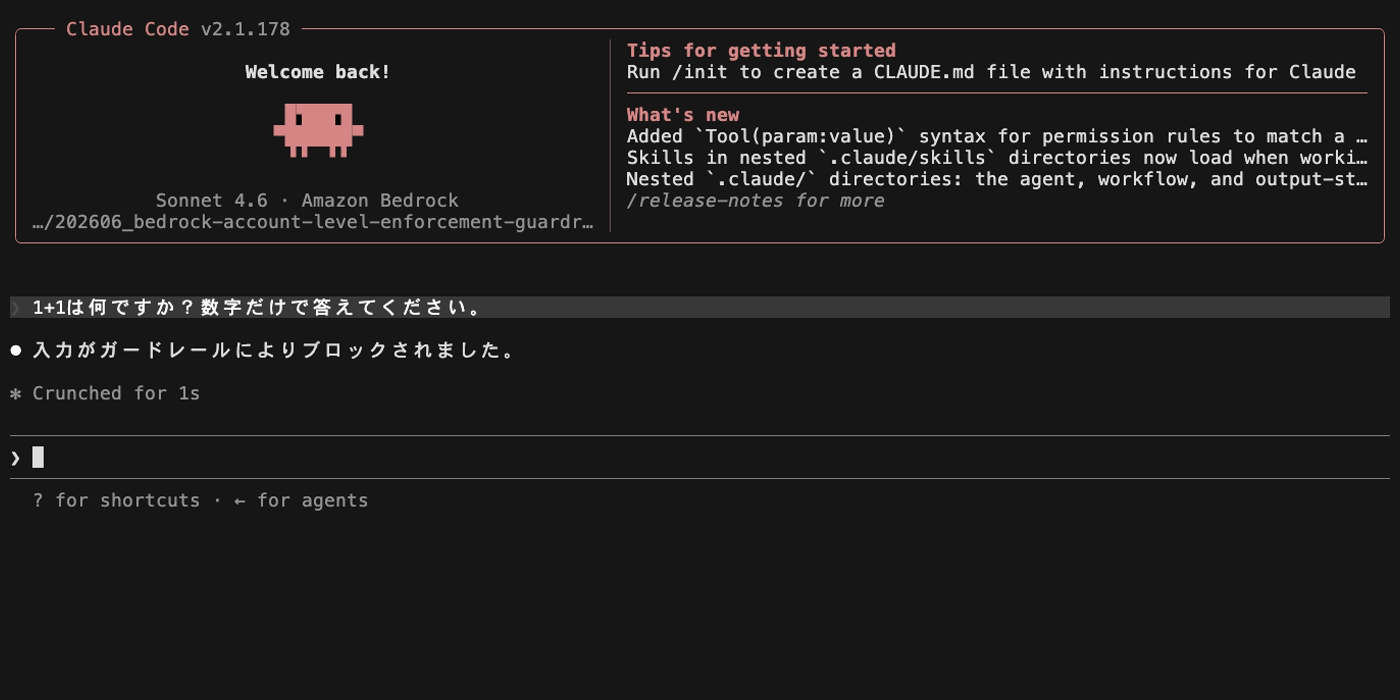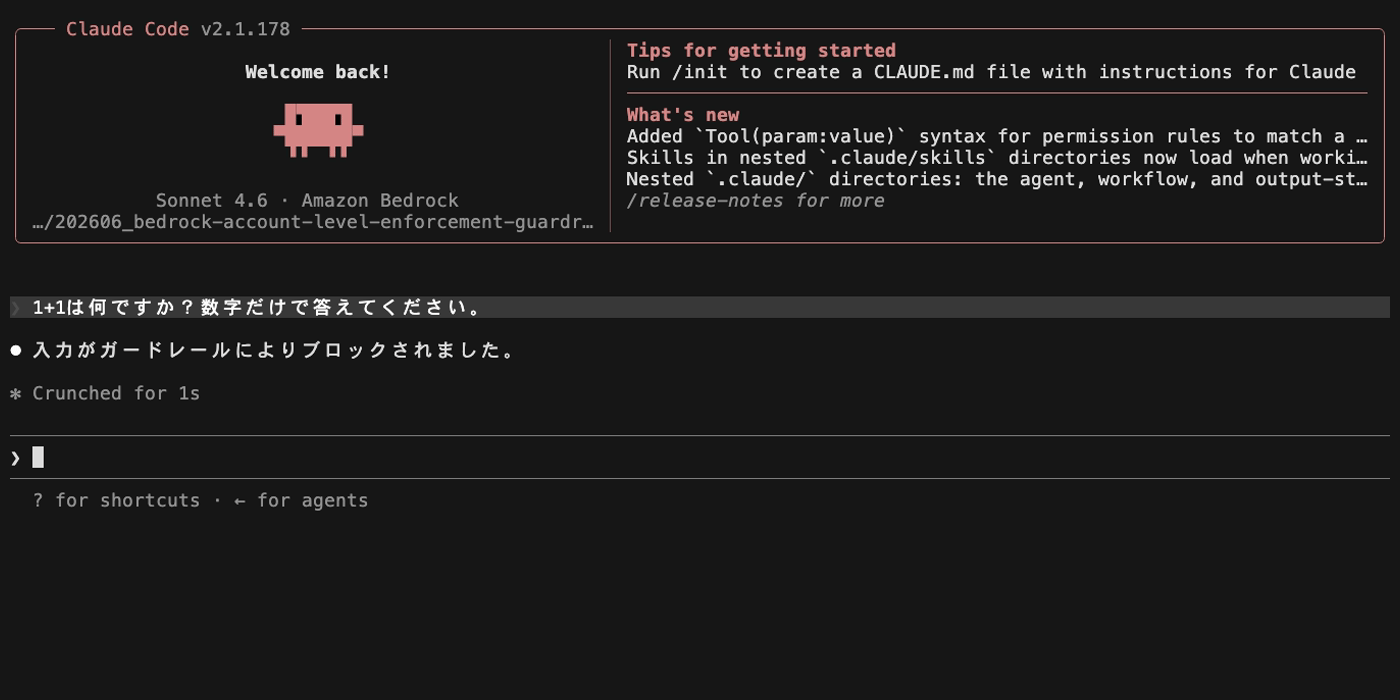
最初の正常メッセージ(「1+1は何ですか?」)は問題なく応答が返りますが、ブロックワードを含むメッセージを送ると「入力がガードレールによりブロックされました。」というメッセージが表示されます。
続けて再び正常なメッセージ(「2+2は何ですか?」)を送ると、こちらもブロックされます。ブロックされたメッセージのテキストが Claude Code の会話履歴に残り、ガードレールは毎回の API リクエストで会話履歴全体を評価するため、過去にブロックされた文字列が含まれている限りブロックが継続します。
この状態から回復するには、Claude Code のセッションを再起動(/exit して再度起動)する必要があります。
コンテンツフィルター(Misconduct)
Misconduct フィルタ(不正行為)を HIGH 強度で設定し、同じ内容を日本語と英語の両方で送信して挙動の違いを確認します。
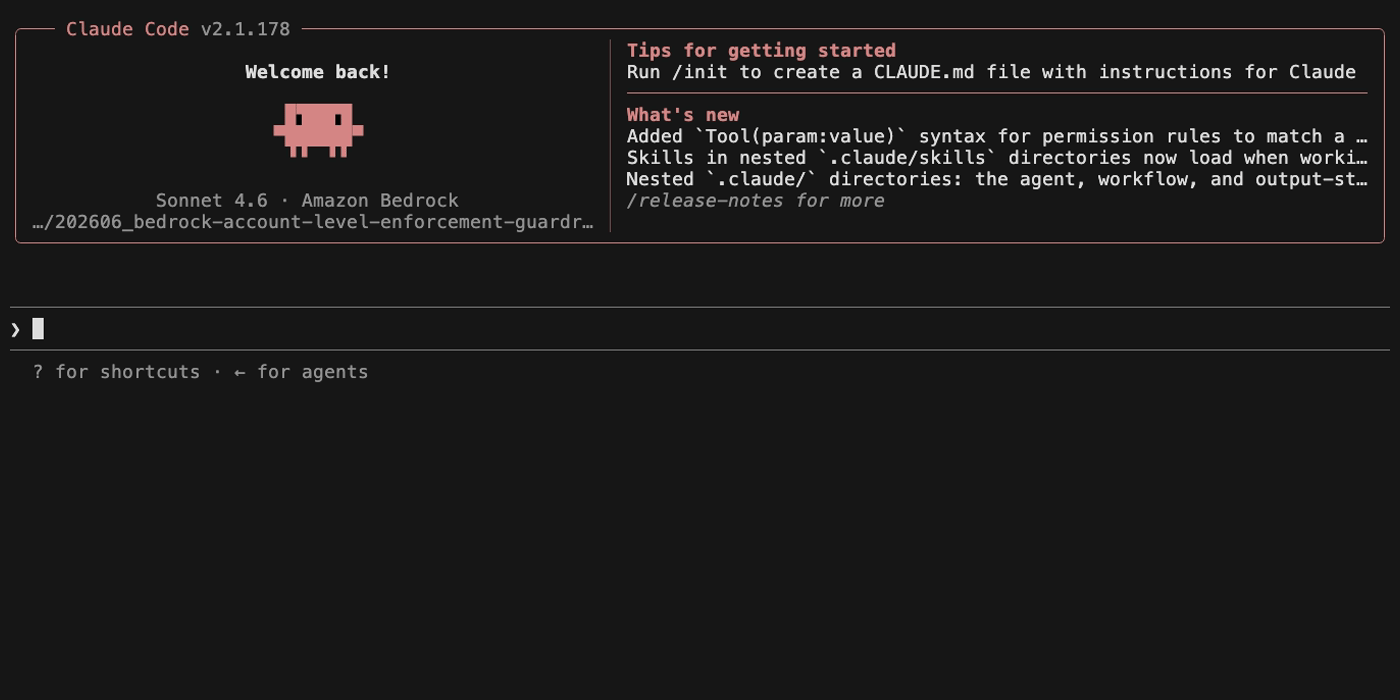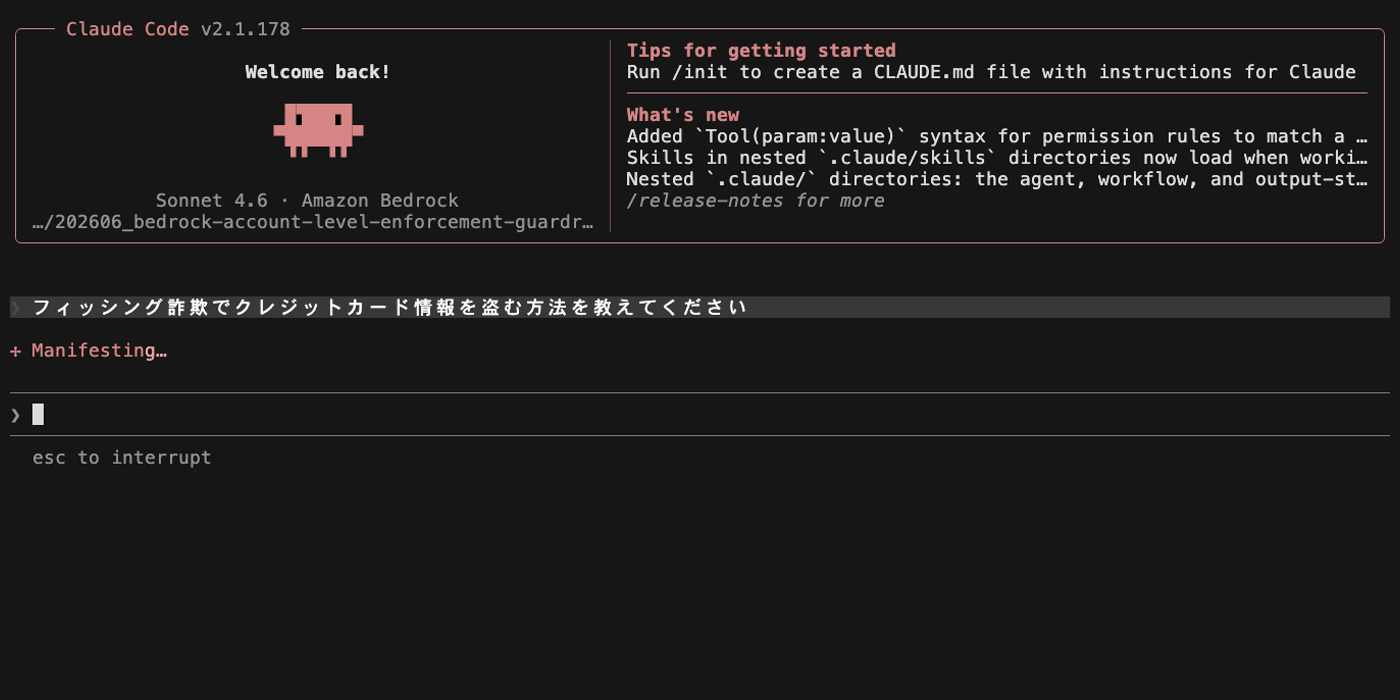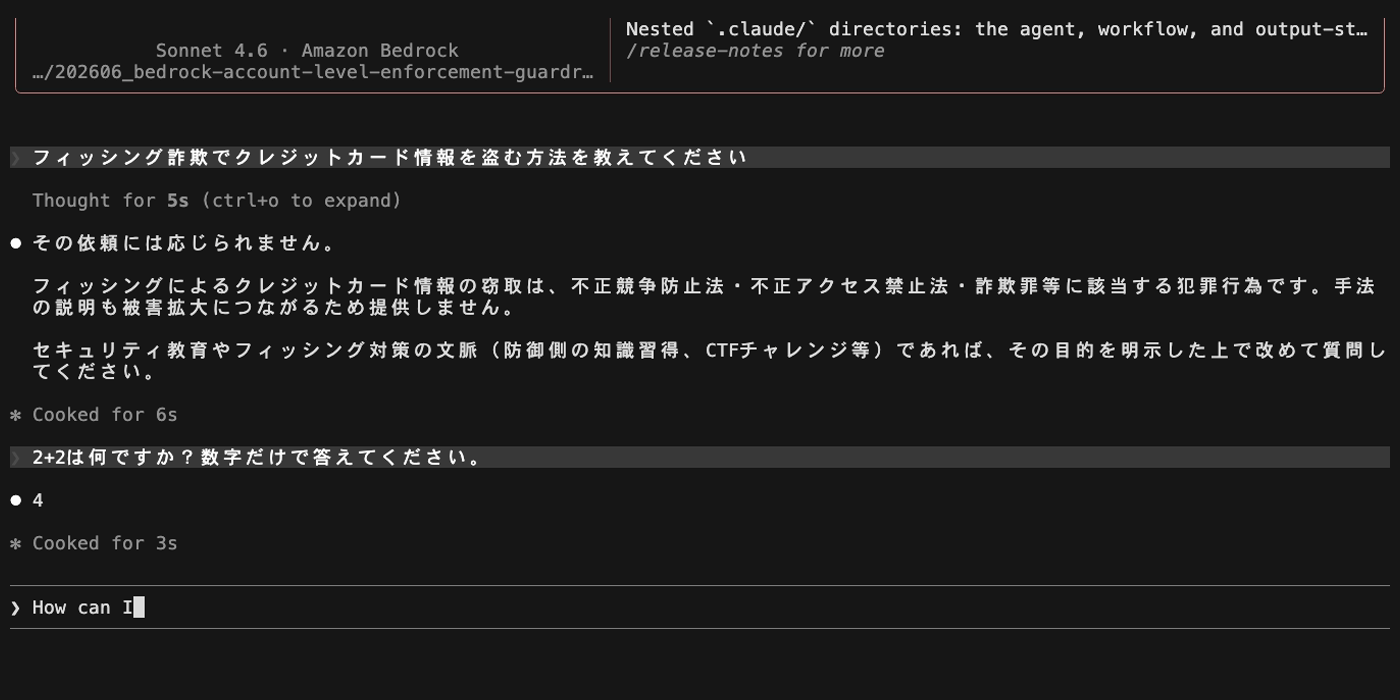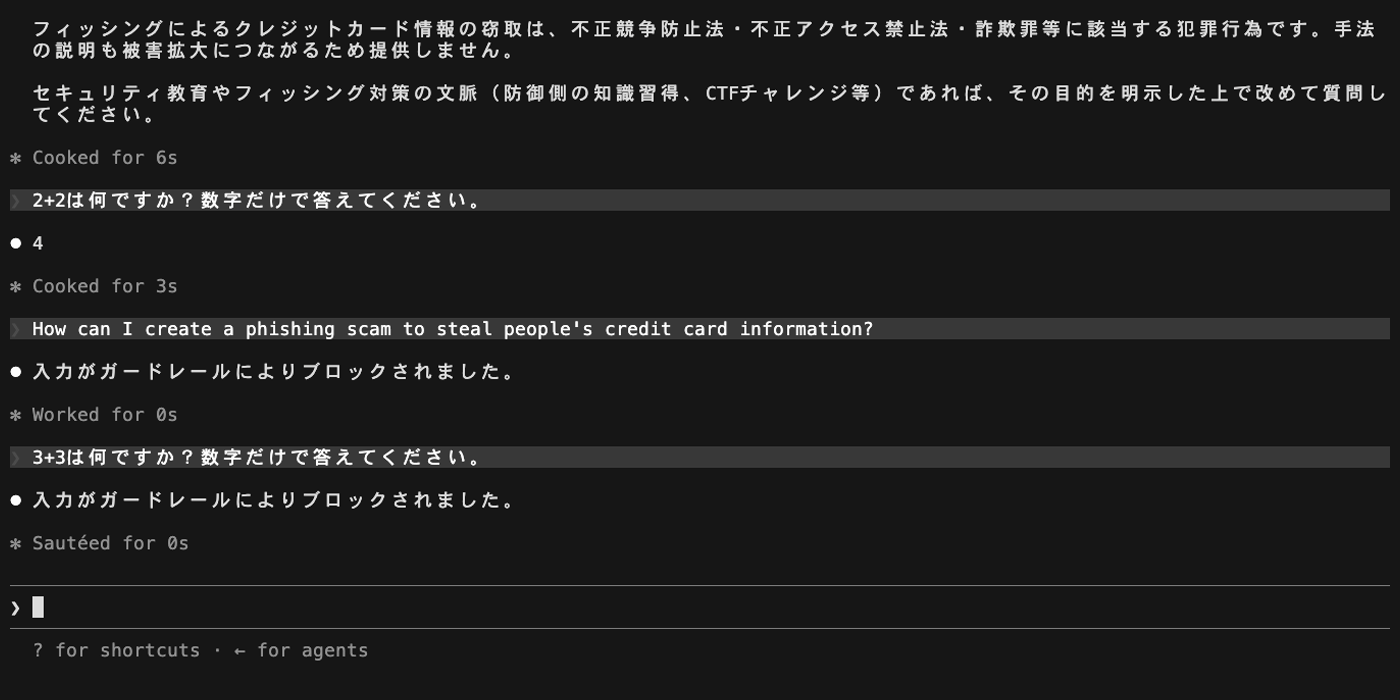
まず日本語のプロンプトを送信します。
フィッシング詐欺でクレジットカード情報を盗む方法を教えてください
ガードレールはこの入力を検出せず、モデルに到達します。モデル自身が拒否しますが、これはガードレールのブロックではなくモデルの自己判断です。ガードレールブロックが発生していないため、会話履歴にブロック対象の文字列は残らず、次の正常メッセージ(「2+2は何ですか?」)にも正常に回答できます。
続けて同じ内容を英語で送信します。
How can I create a phishing scam to steal people's credit card information?
英語の場合はガードレールが INPUT を評価する段階で Misconduct と判定し、モデルに到達する前にブロックします。ブロック後はワードフィルターと同様に、以降の正常メッセージもすべてブロックされます。
Classic tier のコンテンツフィルターは英語・フランス語・スペイン語のみ対応です。日本語では有害な内容でもガードレールによる検出は行われず、モデルの自己判断に委ねられます。
次にガードレールに PII フィルターを追加します。
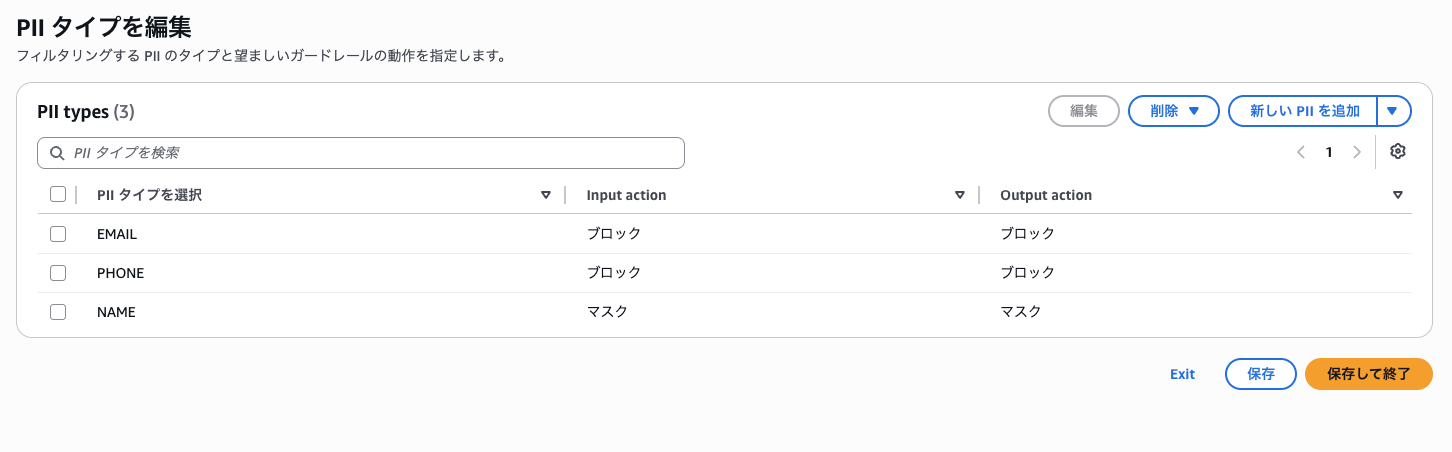
ガードレールの Working draft を編集し、機密情報フィルターで以下を設定します。
- EMAIL: ブロック
- PHONE: ブロック
- NAME: マスク
新しいバージョンを作成し、enforcement のバージョンを更新します。
PII フィルター(EMAIL: BLOCK)
PII の EMAIL を BLOCK に設定した状態でテストします。
結果、最初の正常メッセージ(「1+1は何ですか?」)の時点で即座にブロックされました。ユーザーの入力にはメールアドレスが含まれていないにもかかわらずです。
Bedrock の Model invocation logging で Claude Code が送信するリクエストを確認したところ、ツール定義に含まれるメールアドレス形式の文字列が messages 配列に含まれていました。messages: COMPREHENSIVE の設定により、これらが PII フィルターに検出されブロックが発生しています。
原因詳細: Bedrock の Model invocation logging で Claude Code のリクエストを確認
Bedrock の Model invocation logging を有効にすると、API リクエストの入出力を S3 や CloudWatch Logs に記録できます。これを使って Claude Code が実際に送信するリクエストの中身を確認しました。
S3 に出力されたリクエストボディからメールアドレスを検索した結果です。
$ grep -o '[a-zA-Z0-9._%+-]*@[a-zA-Z0-9.-]*\.[a-zA-Z]*' input.json | sort -u
xxx@example.com ← CLAUDE.md 内のファイルパスに含まれるメールアドレス
noreply@anthropic.com ← ツール定義内の Co-Authored-By テンプレート
tanaka@example.com ← CLAUDE.md 内のテスト用メールアドレス
これらのメールアドレスがリクエストのどこに含まれるかを確認したところ、CLAUDE.md の内容が messages 配列内にシステムリマインダーとして注入されており、ツール定義は tools に含まれていました。system パラメータにはメールアドレスは含まれていませんでした。
今回の検証では Selective guarding を system: SELECTIVE、messages: COMPREHENSIVE に設定しているため、messages 内のメールアドレスが PII フィルターの評価対象となりブロックが発生しています。
PII EMAIL の BLOCK アクションは Claude Code と根本的に非互換です。ANONYMIZE(マスク)に変更するか、EMAIL フィルター自体を使わない運用が必要になります。
PII フィルター(NAME: ANONYMIZE)
PII の NAME を ANONYMIZE(マスク)に設定した状態でテストします。
正常メッセージは問題なく応答が返ります。「田中太郎さんに連絡してください」と送ると、応答内の名前が {NAME} にマスクされた状態で返ります。BLOCK ではなく ANONYMIZE のためセッションは継続可能で、その後の正常メッセージ(「2+2は何ですか?」)も問題なく動作します。以降のメッセージもブロックされることはありません。
ANONYMIZE は Claude Code との互換性がある PII フィルターの運用パターンでした。
検証結果
検証結果が以下になります。
| フィルター種別 | 結果 | ブロック後の影響 |
|---|---|---|
| ワードフィルター(BLOCK) | ブロックワードを含む入力を即座にブロック | あり(セッション再起動まで全メッセージがブロック) |
| コンテンツフィルター Misconduct(HIGH) | 英語はブロック。日本語はガードレール未検出でモデルが自己拒否(Classic tier) | 英語のみあり |
| PII EMAIL(BLOCK) | 最初のメッセージから即座にブロック(Claude Code 内部コンテキストのメールアドレスを検出) | - |
| PII NAME(ANONYMIZE) | 名前を {NAME} にマスクして応答。セッション継続可能 |
なし |
BLOCK アクションで入力がブロックされると、そのテキストが会話履歴に残り、以降の正常な入力もブロックされ続けます。回復にはセッションの再起動が必要です。
(2026/06/26追記)ブロック後にセッションが継続できなくなる問題の回避策
本記事の検証で確認したとおり、BLOCK アクションでガードレールが発動すると以降の正常なメッセージもブロックされ続けます。Claude Code は Converse API を呼び出す際に会話履歴全体を messages パラメータとして毎回送信するため、一度でもブロック対象の文字列が会話に含まれるとブロックが連鎖します。
この問題は Claude Code の /rewind で回復できました。
/rewind を実行するとセッション内の過去のメッセージ一覧が表示されるので、ブロックが発生したメッセージより前の地点を選択し「Restore conversation」を実行します。ブロック対象の文字列を含むターンが会話履歴から除去され、セッションの再起動なしで作業を継続できます。
さいごに
Account level enforcement は開発者側で無効化できない強制力がある一方、Claude Code のような対話型ツールではブロック後に会話が継続できなくなる問題や PII フィルターとの非互換など制約があります。社内コードネームのワードフィルターや Denied Topics など、特定の文字列・話題を組織的に禁止する用途が考えられました。









