
Amazon Bedrock: เปรียบเทียบระหว่าง "Kendra" และ "Bedrock Knowledge Bases" เมื่อใช้ RAG
สวัสดีครับ ผู้อ่านทุกท่าน ผมกาญจน์ครับ วันนี้เรากลับมาพบกันอีกครั้งกับบทความเกี่ยวกับบริการของ AWS ที่น่าสนใจอีกครั้ง คือ Bedrock ครับ ในโลกเทคโนโลยีทุกวันนี้ที่การใช้ AI เป็นที่แพร่หลายและเปลี่ยนแปลงการทำงานในหลายๆด้าน วันนี้เราจะมาเรียนรู้ร่วมกันว่า Bedrock สามารถช่วยเพิ่มประสิทธิภาพการทำงานของเราได้อย่างไรบ้างครับ
บทความนี้ได้มีการแปลและเรียบเรียงมาจากบทความภาษาญี่ปุ่นชื่อ [Amazon Bedrock] RAG利用時の選択肢「Kendra」と「Bedrock Knowledge Bases」を比較する โดยคุณ ฮิเดอากิ อาโอยางิ ครับ ท่านผู้อ่านสามารถอ่านบทความต้นฉบับ และบทความอื่นๆของคุณอาโอยางิตามลิงค์ได้เลยครับ
ในบทความนี้เราจะมีการพูดถึง RAG (Retrieval-Augmented Generation) ซึ่งเป็นเทคนิคของ AI ที่รวมความสามารถในการเข้าถึงข้อมูล (Information Retrieval) และการสร้างข้อความ (text generation) เพื่อให้ได้ข้อมูลที่ถูกต้อง, มีการอัปเดต และน่าเชื่อถือ ซึ่งหากเป็นโมเดลที่ไม่ได้ใช้ RAG จะมีโอกาสที่โมเดลภาษาขนาดใหญ่ (LLMs) จะไม่มีข้อมูลให้หรือตอบข้อมูลที่เป็นเท็จกลับมาได้ครับ
ท่านผู้อ่านที่อาจไม่คุ้นเคยกับ RAG สามารถอ่านรายละเอียดเพิ่มเติมได้ตามลิงค์ข้างล่างนี้ครับ
ในการใช้งาน RAG ใน Amazon Bedrock รูปแบบดังต่อไปนี้จะเป็นรูปแบบที่เราสามารถใช้ผสมผสานกับ Bedrock ได้ครับ
- ใช้ Amazon Kendra
- ใช้ Amazon Bedrock Knowledge Bases
- วิธีการอื่นๆ นอกเหนือจากวิธีข้างต้น
- ใช้ library อย่าง Langchain
- พัฒนาแบบกำหนดเอง
ในบรรดาตัวเลือกทั้งหมด "Kendra" และ "Bedrock Knowledge Bases" เป็นตัวเลือกที่ใช้งานบ่อยครับ
ตอนที่เปิดตัว Amazon Bedrock (GA) เต็มตัวสู่สาธารณะครั้งแรก[1] เรายังไม่มี Bedrock Knowledge Bases ให้ใช้ครับ Kendra จึงถูกใช้กันเป็นหลัก แต่หลังจาก Bedrock Knowledge Bases เปิดตัว อาจทำให้ผู้ใช้งานสับสนว่าเราควรใช้ "Kendra" หรือ "Bedrock Knowledge Bases" ดี
ด้วยเหตุนี้ ผมจึงได้เปรียบเทียบข้อแตกต่างระหว่าง "Kendra" และ "Bedrock Knowledge Bases" ให้ผู้อ่านได้เห็นภาพมากขึ้นครับ
ภาพรวม
"Amazon Kendra" (ต่อไปในบทความนี้จะเรียกแค่ "Kendra" ครับ) เป็นบริการค้นหาข้อมูลภายในองค์กร (Enterprise Search) ที่แยกออกมาต่างหาก ซึ่งมีมาก่อนจะเปิดตัว Bedrock อีกครับ
ถึงแม้ว่ารายละเอียดของขั้นตอนการค้นหาจะไม่ได้เปิดเผย แต่ก็มีการอธิบายว่า "ใช้การประมวลผลภาษาธรรมชาติและ deep learning ขั้นสูง" (natural language processing and advanced deep learning model) โดยให้บริการ สืบค้นข้อมูลเชิงความหมาย (Semantic-based search) มากกว่าจะเป็นการ สืบค้นแบบอิงคำสำคัญ (keyword-based search)
กล่าวคือ กรณีค้นหาคำว่า "รถยนต์" การสืบค้นคำสำคัญจะหาเฉพาะข้อมูลที่มีคำว่า "รถยนต์" เขียนอยู่เท่านั้น แต่บริการสืบค้นข้อมูลเชิงความหมายจะมีการตีความหมายของรถยนต์ และนำไปหาข้อมูลที่มีความเกี่ยวข้อง เช่น ศูนย์จำหน่ายรถยนต์, ประกันรถยนต์ หรือข้อมูลอื่นๆที่เกี่ยวข้องกับรถยนต์
เรียกได้ว่าเป็นบริการแบบครบเครื่อง หรือ "all-in-one" ที่รวมองค์ประกอบหลายส่วนเข้าด้วยกัน (ระบบจัดเก็บเวกเตอร์[2], ครอว์เลอร์ของแหล่งข้อมูล[3], เสิร์ชเอนจินท์, ฯลฯ)
ข้อมูลเกี่ยวกับ Kendra (ภาษาอังกฤษ)
"Amazon Bedrock Knowledge Bases" (ต่อไปในบทความนี้จะเรียกแค่ "Bedrock Knowledge Bases" ครับ)
※ ในอดีตบริการนี้เคยถูกเรียกว่า "Knowledge Bases for Amazon Bedrock" แต่ได้เปลี่ยนมาเป็นชื่อปัจจุบันประมาณช่วง กันยายน ค.ศ.2024
Amazon Bedrock Knowledge Bases ถูกกำหนดให้เป็น "ฟังก์ชันการค้นหา" Bedrock สำหรับสร้าง RAG โดยใช้ embedded model ของ generative AI ของ Bedrock ตอนสร้างหรือค้นหา index ทึ่สร้างไว้ ซึ่งจะคล้ายคลึงกับการเก็บข้อมูลแบบเวกเตอร์ของ Kendra ตรงที่ผู้ใช้งานสามารถค้นหาข้อมูลจากความหมายที่ใกล้เคียงกัน แทนการค้นหาแบบคำสำคัญ (keyword) ซึ่งจะหาเฉพาะข้อมูลที่คำตรงกันเท่านั้น
โดย Bedrock Knowledge Bases ให้ API สำหรับใช้งาน ซึ่งไม่ได้มีทำแค่ค้นหา (Retrieve) ซึ่งจะแสดงผลแค่ข้อมูลที่หาเจอเท่านั้น แต่ยังสร้างคำตอบจากผลการค้นหา (Retrieval-Augmented Generation) ให้ครบจบในครั้งเดียว
เวกเตอร์สโตร์ (Vector Store)[2:1]
● Kendra
รวมอยู่ในบริการแล้ว จึงไม่สามารถเลือกประเภทของเวกเตอร์สโตร์ได้ครับ
● Bedrock Knowledge Bases
สามารถเลือกเวกเตอร์สโตร์ได้ดังนี้
- Amazon OpenSearch Serverless
- Amazon Aurora (PostgreSQL)
- ผลิตภัณฑ์ของเจ้าอื่น (Third Party Products)
- MongoDB Atlas
- Pinecone
- Redis Enterprise Cloud
※ เฉพาะเมื่อเราเลือก OpenSearch Serverless เท่านั้น เวกเตอร์สโตร์ถึงจะถูกสร้างอัตโนมัติใน Wizard Screen ของ Kendra ส่วนเวกเตอร์สโตร์อื่นต้องสร้างก่อนล่วงหน้า
ความแตกต่างในการจัดการเวกเตอร์สโตร์ระหว่าง Kendra และ Bedrock จะอยู่ในภาพด้านล่างครับ
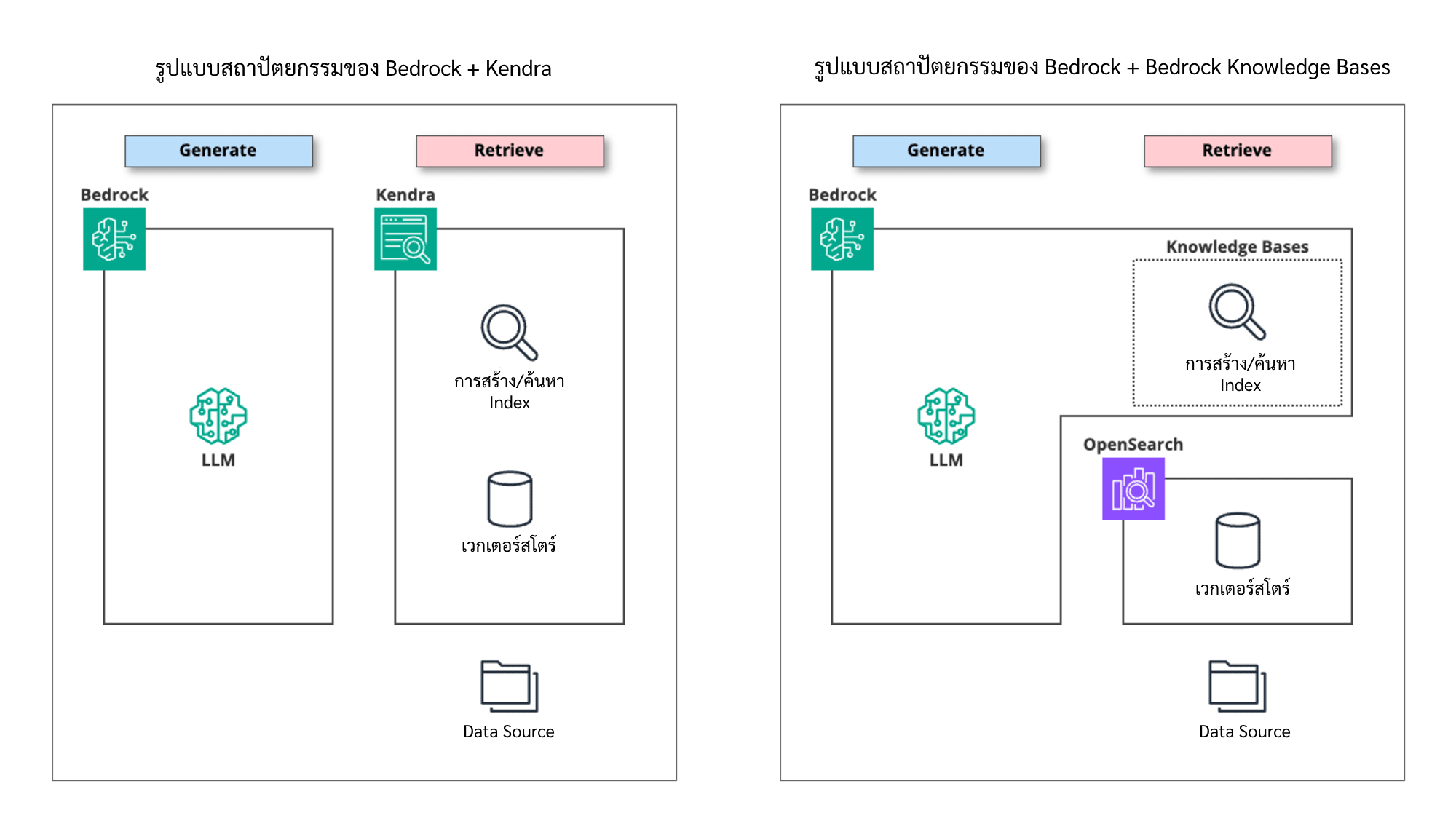
แหล่งข้อมูล (Data source)
ประเภทของ Data source ที่รองรับ
● Kendra
สามารถรองรับ Data source ได้สูงถึง 30 ประเภท
※ สามารถอ่านเพิ่มเติมเกี่ยวกับ datasource ที่รองรับได้ตามลิงค์นี้ครับ Data source connectors
● Bedrock Knowledge Bases
สามารถรองรับ Data source ได้ดังนี้
- Amazon S3
- Atlassian Confluence - Preview
- Microsoft SharePoint - Preview
- Salesforce - Preview
- Web Crawler - Preview
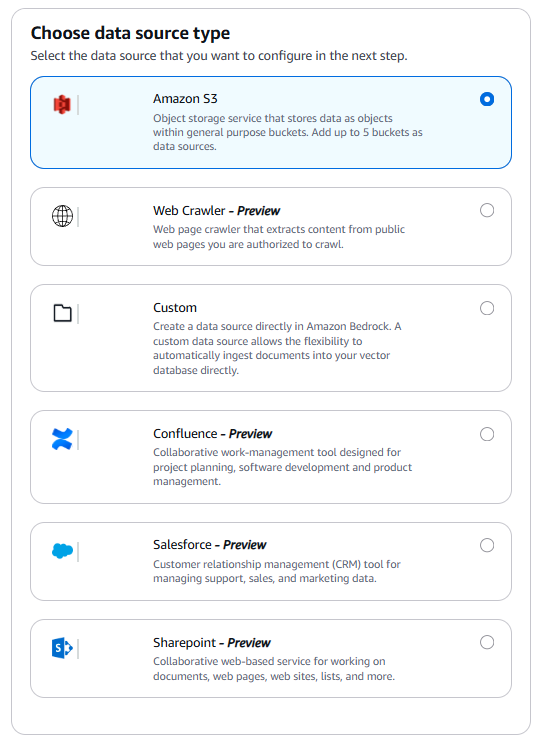
Note: ข้อมูลเกี่ยวกับ Data Source ที่ Bedrock Knowledge Bases รับรอง เป็นข้อมูล ณ วันที่ 8 กรกฎาคม ค.ศ.2025 ท่านผู้อ่านสามารถตรวตสอบรายการ Data Source ได้โดยไปที่ AWS Bedrock -> Knowledge Bases -> Create ได้เลยครับ
รูปแบบไฟล์ข้อมูลที่รองรับ
● Kendra / Bedrock Knowledge Bases
| รูปแบบไฟล์ข้อมูลที่รองรับ | Kendra | Bedrock Knowledge Bases |
|---|---|---|
| Plain text (.txt) | รองรับ | รองรับ (ASCII เท่านั้น) |
| comma-separated text (.csv) | รองรับ | รองรับ |
| Markdown (.md) | รองรับ | รองรับ |
| HTML (.html) | รองรับ | รองรับ |
| XML (.xml) | รองรับ | ー |
| XSL transformation (.xslt) | รองรับ | ー |
| JSON (.json) | รองรับ | ー |
| rich text format (.rtf) | รองรับ | ー |
| Microsoft Word (.doc/.docx) | รองรับ | รองรับ |
| Microsoft Excel (.xls/.xlsx) | รองรับ | รองรับ |
| Microsoft PowerPoint (.ppt/.pptx) | รองรับ | ー |
| PDF (.pdf) | รองรับ | รองรับ |
อ้างอิงข้อมูลจาก
※ Bedrock Knowledge Bases จะรองรับไฟล์ที่ขนาดไม่เกิน 50 MB และจะรับรองเฉพาะ "ไฟล์ pdf" กรณีตั้งค่าเป็น "Advanced Analysis Options"
ขนาดไฟล์ข้อมูลที่รองรับ
● Kendra / Bedrock Knowledge Bases
ขนาดใหญ่สุดที่ทั้งคู่รองรับคือ 50 MB
การซิงโครไนซ์ Data Source
● Kendra
สามารถเลือกได้ระหว่าง "Manual" (ตั้งค่าเอง) หรือ "Automatic (Scheduled)" (อัตโนมัติ/กำหนดไว้)
Bedrock Knowledge Bases
ในฟีเจอร์มาตรฐานสามารถทำได้เฉพาะ "Manual" เท่านั้น แต่ว่าสามารถใช้ร่วมกับ EventBridge Scheduler เพื่อให้สามารถรันอัตโนมัติตามตารางเวลาได้
สามารถดูการใช้ EventBridge Scheduler เพื่อตั้งค่าการรันอัตโนมัติได้ที่นี่ครับ
โมเดลที่ใช้
โมเดล Embedding (การสร้าง/ค้นหา Search Index)
● Kendra
(เนื่องจากวิธีการประมวลผลไม่ได้ใช้ Generative AI ในการสร้าง/ค้นหา Search Index จึงไม่เกี่ยวข้องกับหัวข้อนี้)
● Bedrock Knowledge Bases
เลือกใช้โมเดล Embedding ที่สามารถใช้งานได้ใน Bedrock
- Amazon Titan Embeddings G1 - Text (※)
- Amazon Titan Text Embeddings V2
- Cohere Embed English
- Cohere Embed Multilingual
※ สามารถใช้งานได้เฉพาะกับเวกเตอร์สโตร์ที่สร้างไว้แล้วก่อนหน้านี้เท่านั้น ไม่สามารถใช้งานแบบใหม่ได้
โมเดลที่ใช้ในการสร้างคำตอบ
● Kendra
Kendra เองไม่มีฟังก์ชันการสร้างคำตอบเฉพาะครับ เราจึงสามารถเลือกใช้ LLM ที่จะผสมผสานได้อย่างอิสระเพื่อสร้างคำตอบ
● Bedrock Knowledge Bases
"Retrieve API" จะทำเฉพาะการค้นหาใน Knowledge Base ในขณะที่ "RetrieveAndGenerate API" จะใช้ผลลัพธ์จากการค้นหาเพื่อสร้างคำตอบ และโมเดลที่สามารถใช้ได้สำหรับแต่ละ API นั้นแตกต่างกัน
สำหรับกรณีแรก (Retrieve API) การสร้างคำตอบไม่ขึ้นอยู่กับ Bedrock Knowledge Bases เราจึงสามารถใช้โมเดลใดก็ได้ที่มีใน Bedrock ครับ
กรณีหลัง (RetrieveAndGenerate API) จำเป็นต้องเลือกจากโมเดลที่เตรียมไว้ให้ (ดังต่อไปนี้)
- AI21 Labs
- Jamba 1.5 Mini
- Jamba 1.5 Large
- Jamba-Instruct
- Amazon
- Titan Text G1 - Premier
- Anthropic
- Claude 3.5 Haiku
- Claude 3.5 Sonnet v2
- Claude 3.5 Sonnet
- Claude 3 Haiku
- Claude 3 Sonnet
- Claude 2.1
- Claude 2
- Cohere
- Command R+
- Command R
- Meta
- Llama 3.2 11B Instruct
- Llama 3.2 90B Instruct
- Llama 3.1 405B Instruct
- Llama 3.1 70B Instruct
- Llama 3.1 8B Instruct
- Llama 3 70B Instruct
- Llama 3 8B Instruct
- Mistral AI
- Mistral Large (24.07)
- Mistral Large (24.02)
- Mistral Small (24.02)
ผู้อ่านสามารถตรวจสอบโมเดลเพิ่มเติมได้ที่นี่ครับ
Chunking
Chunking คือการแบ่งชิ้นข้อมูลที่มีขนาดใหญ่เป็นส่วนเล็กลงเพื่อให้สามารถจัดการได้ครับ
● Kendra
Chunking ที่เหมาะสมจะดำเนินการโดยอัตโนมัติ จึงไม่มี parameter สำหรับการตั้งค่า Chunking ใน Kendra ครับ
● Bedrock Knowledge Bases
สามารถเลือกตัวเลือกการ chunking ดังต่อไปนี้:
- Default chunking: ปรับขนาดชิ้นไฟล์โดยอัตโนมัติ
- การ chunking ขนาดคงที่: กำหนดขนาดชิ้นไฟล์
- การ chunking แบบลำดับชั้น: ใช้ขนาดชิ้นไฟล์แยกกันสำหรับ "เวลาค้นหา" และ "เวลาสร้างคำตอบ"
- การ chunking แบบ semantic: แบ่งชิ้นไฟล์ตามจุดแบ่งที่มีความหมายผ่านการประมวลผลภาษาธรรมชาติ
- ไม่มี chunking: ไม่แบ่งชิ้น 1 ไฟล์เป็น 1 ชิ้น (คาดว่าจะใช้ร่วมกับการประมวลผลเอกสารล่วงหน้า)
RAG ขั้นสูง
● Bedrock Knowledge Bases เท่านั้น
ในเดือนกรกฎาคม ค.ศ. 2024 การอัปเดตของ Bedrock Knowledge Bases ได้เพิ่มฟีเจอร์หลายอย่างเพื่อสร้าง "Advanced RAG"
Advanced RAG หมายถึงเทคนิค RAG ขั้นสูงที่ถูกคิดค้นขึ้นเพื่อเพิ่มความแม่นยำของ RAG แบบดั้งเดิม (ที่เรียกว่า "Naive RAG") (ไม่ใช่ฟีเจอร์เฉพาะของ Bedrock แต่เป็นแนวคิดทั่วไปของ Generative AI ครับ)
ตัวเลือกการวิเคราะห์ขั้นสูง
เมื่อแหล่งข้อมูลเป็นไฟล์ PDF หรือรูปแบบอื่นที่มี "ตาราง" และ "รูปภาพ" RAG แบบดั้งเดิมไม่สามารถระบุข้อความที่เขียนอยู่ในตารางหรือรูปภาพได้ ทำให้เนื้อหาเหล่านี้ไม่ถูกนำมาสร้าง Index
ตัวเลือกการวิเคราะห์ขั้นสูง (Advanced Parsing) ใช้โมเดลพื้นฐาน (Claude 3 Sonnet, Claude 3 Haiku) เพื่อวิเคราะห์ตารางและรูปภาพที่อยู่ในไฟล์ PDF เป็นต้น และสามารถนำข้อความเหล่านั้นมาใช้ได้
การเพิ่มกลยุทธ์ chunking
เพิ่มตัวเลือกกลยุทธ์ chunking ขั้นสูงคือ "การ chunking แบบลำดับชั้น" และ "การ chunking แบบ semantic"
(อธิบายแล้วในหัวข้อ "Chunking")
การ chunking แบบกำหนดเอง
ใน Bedrock Knowledge Bases เราสามารถใช้ฟังก์ชัน Lambda เพื่อดำเนินการ chunking แบบกำหนดเองแทนการใช้กลยุทธ์ chunking ที่เตรียมไว้ให้ครับ
โดยเราสามารถใช้ที่มีอยู่ในเฟรมเวิร์ก OSS เช่น LangChain หรือ LlamaIndex หรือพัฒนาขึ้นเองได้เช่นกัน
การแยกแยะคำถาม (Query Decomposition)
ใน RAG แบบดั้งเดิม ในขั้นตอน "Retrieve" จะใช้ข้อความที่ผู้ใช้ป้อนเข้ามาโดยตรงในการสืบค้น Index แต่หากข้อความที่ป้อนเข้ามายาวหรือซับซ้อน อาจไม่ได้ผลการค้นหาตามที่ต้องการได้
ดังนั้น การแยกข้อความที่ป้อนเข้ามาอย่างเหมาะสมและสร้างคำสืบค้นหลายๆ คำสืบค้น จึงสามารถเพิ่มความแม่นยำของการค้นหาได้ครับ
อ้างอิงจากบทความภาษาญี่ปุ่น: Bedrock Knowledge BasesのAdvanced RAGに関する機能についての解説
Metadata Filtering
● Kendra
การกำหนด Metadata
ข้อมูลที่ถูกนำเข้าจาก data source ไปยัง index จะมีการกำหนด attribute (metadata) มาตรฐานให้โดยอัตโนมัติ เช่น "Title", "Data Source URI" เป็นต้นครับ
ถ้าผู้ใช้ต้องการเพิ่ม metadata ที่ไม่ใช่รูปแบบมาตรฐาน เราจะต้องสร้าง "metadata file" (~.metadata.json) ที่บรรยายความสัมพันธ์ระหว่างไฟล์และข้อมูล metadata แล้ววางไว้ใน data source และตั้งค่าให้อ้างอิงไฟล์ดังกล่าว
Contents Document Enrichment (CDE)
Amazon Kendra ยังสามารถทำการสร้าง metadata แบบอัตโนมัติได้โดยใช้ CDE (Custom Document Enrichment) เช่นกันครับโดยเมื่อค่า attribute ของไฟล์ตรงตามเงื่อนไขที่กำหนด จะสามารถกำหนด tag (metadata) ที่ระบุไว้ได้
ตัวอย่างเช่น สามารถทำการ tag ได้ตามเงื่อนไขต่างๆ เช่น "เมื่อ creator เป็น member ที่กำหนด" หรือ "เมื่อ update date อยู่ในช่วงเวลาที่กำหนด" เป็นต้น
การ filter ผลการค้นหาโดยใช้ metadata
เมื่อทำการค้นหา index (Retrieve) เราสามารถระบุเงื่อนไขของ attribute เพื่อทำการ filter ผลการค้นหาได้
ตัวอย่างเช่น สามารถทำการ filter ได้ดังนี้ครับ:
- ระบุการ filter สำหรับ data source URI เพื่อให้ค้นหาเฉพาะข้อมูลใน folder hierarchy ที่กำหนด
- กำหนด custom metadata ที่แสดงถึง category ไว้ล่วงหน้า เพื่อให้ค้นหาเฉพาะข้อมูลใน category ที่กำหนด
- กำหนด custom metadata ที่แสดงถึงข้อมูลลับไว้ล่วงหน้า เพื่อให้ค้นหาเฉพาะข้อมูลที่ไม่ได้ตั้งค่าเป็นข้อมูลลับเท่านั้น
● Bedrock Knowledge Bases
การกำหนด Metadata
ข้อมูลที่ถูกนำเข้าจาก data source ไปยัง index จะมีการกำหนด attribute (metadata) มาตรฐานให้โดยอัตโนมัติ เช่น "title" และ "data source URI" เป็นต้น เหมือนกับ Kendra ครับ
หากต้องการกำหนด metadata ที่ไม่มีในมาตรฐาน จะต้องสร้าง "metadata file" (~.metadata.json) ที่บรรยายความสัมพันธ์ระหว่างไฟล์และข้อมูล metadata ไว้ใน data source แล้วตั้งค่าให้อ้างอิงไฟล์นี้
การ filter ผลการค้นหาโดยใช้ metadata
เมื่อทำการค้นหา index (Retrieve) เราสามารถระบุเงื่อนไขของ attribute เพื่อทำการ filter ผลการค้นหาได้
ตัวอย่างเช่น สามารถทำการ filter ได้ดังนี้ครับ:
- ระบุการ filter สำหรับ data source URI เพื่อให้ค้นหาเฉพาะข้อมูลใน folder hierarchy ที่กำหนด
- กำหนด custom metadata ที่แสดงถึง category ไว้ล่วงหน้า เพื่อให้ค้นหาเฉพาะข้อมูลใน category ที่กำหนด
- กำหนด custom metadata ที่แสดงถึงข้อมูลลับไว้ล่วงหน้า เพื่อให้ค้นหาเฉพาะข้อมูลที่ไม่ได้ตั้งค่าเป็นข้อมูลลับเท่านั้น
การ filter ตามสิทธิ์การเข้าถึง (Access Control)
● Kendra เท่านั้น
ใน Kendra เราสามารถทำการ filter ผลการค้นหาตาม user ได้โดยอิงจากสิทธิ์การเข้าถึง (ACL) ที่ตั้งค่าไว้ใน data source ครับ
การนำเข้าข้อมูล ACL จาก data source
สำหรับ data source ที่รองรับการนำเข้า ACL จะมีการนำเข้าข้อมูล ACL โดยอัตโนมัติระหว่างการ crawl (sync) data source และจัดเก็บไว้ใน index ครับ
แต่มีข้อจำกัดบางอย่างที่ควรระวังดังนี้ครับ:
- ข้อมูล ACL ที่ตั้งค่าไว้ในไฟล์หนึ่งๆ มีจำนวนที่สามารถนำเข้าได้จำกัด (รวม user และ group ได้สูงสุด 200 entry)
- ไม่มีวิธีการตรวจสอบรายการข้อมูล ACL ที่ถูกนำเข้า (แต่จะมีการบันทึกใน sync log จึงสามารถค้นหาไฟล์เป้าหมายเพื่อตรวจสอบข้อมูล ACL ที่ถูกนำเข้าได้)
การ filter ผลการค้นหาตาม user เมื่อทำการค้นหา
เมื่อเราทำการค้นหา สามารถส่ง "ข้อมูล user ที่ใช้งาน" เป็น parameter ผ่าน API/SDK เพื่อให้ผลการค้นหาแสดงเฉพาะข้อมูลที่ user นั้นมีสิทธิ์เข้าถึงตามข้อมูล ACL ที่เก็บไว้ใน index ครับ (ข้อมูลที่ไม่มีสิทธิ์เข้าถึงจะไม่ปรากฏในผลการค้นหา)
มีวิธีการส่งข้อมูล user 2 แบบ:
- ส่ง user ID โดยตรง
- ส่งในรูปแบบ user token
ซึ่งวิธีส่งในรูป user token จะรับ token จาก authentication infrastructure ที่ application ใช้สำหรับ user authentication แล้วส่งเป็น parameter ใน Kendra API/SDK
ข้อดีของการใช้ token คือสามารถ offload การตรวจสอบ token ให้ Kendra ทำ จึงสามารถเขียน code ได้ง่ายและทำ access control ได้อย่างปลอดภัยครับ
ลิงค์อ้างอิง:
สุดท้ายนี้
ท่านผู้อ่านคงเห็นแล้วว่า หลังจากลองเปรียบเทียบข้อแตกต่างระหว่าง Kendra และ Bedrock Knowledge Bases ไม่ได้มีตัวเลือกไหนเหนือกว่าอย่างชัดเจน แต่ละตัวมีข้อเด่นและข้อจำกัดแตกต่างกันไป ซึ่งการนำไปใช้ก็ขึ้นอยู่กับความต้องการใช้งานของแต่ละท่านครับ
Kendra มีจุดเด่นที่มี data source connector ที่หลากหลาย ส่วน Bedrock Knowledge Bases น่าสนใจตรงที่มีการเพิ่มฟีเจอร์ใหม่ๆ อย่างต่อเนื่อง ทำให้ความสะดวกในการใช้งานและความแม่นยำในการค้นหาดีขึ้นเรื่อยๆครับ
เทคโนโลยีของ Generative AI มีการเปลี่ยนแปลงในทุกๆวัน ในวันข้างหน้าอาจจะมีฟังก์ชันหรือความสามารถใหม่ๆเพิ่มเข้ามา นอกเหนือจากที่กล่าวไว้ในบทความนี้ครับ เพื่อข้อมูลที่อัปเดตใหม่ การอ่านข้อมูลเพิ่มเติมจาก Documentation และเว็บไซต์ทางการของ AWS จะทำให้ได้ข้อมูลที่อัปเดตที่สุดครับ
จบไปแล้วนะครับกับบทความ เปรียบเทียบระหว่าง "Kendra" และ "Bedrock Knowledge Bases" เมื่อใช้ RAG หวังว่าผู้อ่านทุกท่านจะได้ประโยชน์ไปไม่มากก็น้อยครับ แล้วพบกันใหม่บทความหน้าครับ
Amazon Bedrock เปิดตัว GA (General Availability) ในเดือนกันยายน 2023 - General Availability หมายถึงการที่บริการของ cloud เปิดตัวสู่สาธารณชน ↩︎
การเก็บข้อมูลแบบเวกเตอร์ (Vector Storage) เป็นระบบจัดเก็บข้อมูลแบบตัวเลข โดยไม่ว่าจะเป็นข้อมูลข้อความหรือภาพก็ตามจะถูกแปลงอยู่ในกลุ่มของตัวเลข เวลาเราทำการสืบค้นข้อมูลเชิงความหมาย (Semantic-based search) ข้อความที่เราพิมพ์ก็จะถูกแปลงเป็นตัวเลขเช่นกัน และนำไปเทียบกับเลขเวคเตอร์ของข้อมูล ซึ่งถ้าเลขเวคเตอร์ของข้อมูลมีความคล้ายกับเลขของเรา ข้อมูลเหล่านั้นก็จะถูกนำมาแสดง ↩︎ ↩︎
ครอว์เลอร์ของแหล่งข้อมูล (Data source Crawler) หลายท่านอาจคุ้นเคยกับคำว่า web crawler ซึ่งเป็นซอฟท์แวร์ที่ไปรวบรวมข้อมูลบนเว็บไซต์ต่างๆ ตาม url ที่กำหนด แต่ Datasource Crawler มีความหมายกว้างกว่า คือสามารถไปรวบรวมข้อมูลในแหล่งข้อมูลต่างๆ ซึ่งของ AWS จะมี crawler ใน AWS Glue สามารถอ่านเพิ่มเติมเกี่ยวกับ resource ที่สามารถใช้ crawler รวบรวมข้อมูลได้ที่ AWS Glue Crawler Data Stores ↩︎








