
dbt platform の Advanced CI で event_time による最適化機能を試してみた
はじめに
dbt platform の Enterprise 以上のプランでは、CI ジョブの実行と合わせて、マージ先環境と PR 変更内容の差分を自動比較する機能として Advanced CI 機能が提供されています。
このうち event_time による最適化機能適用時の比較内容を確認した際の内容を記事としました。
Advanced CI の概要
本機能については以下に記載があります。
前提として、Advanced CI 機能は CI ジョブ内で実行される機能となります。そのため、プルリクエスト(PR)作成時に自動的に実行されます。
PR を通じて、マージ先環境に存在する既存モデルと、PR によって変更されたモデルとの差分を比較できます。確認できる項目の内、代表的な内容は以下のとおりです。
- 主キーを基準としたレコード差分(追加・削除・変更された行数)
- このためには、対象モデルのキーカラムに constraints または ユニークデータテスト が必要
- カラムの追加・削除・データ型の変更
- 新規モデルの追加および既存モデルの削除
本機能については、以下の記事も参考になると思います。
基本動作
Advanced CI の基本的な動作を確認してみます。
設定の有効化
Advanced CI の有効化は容易で、CI ジョブの「Execution settings」内の「dbt compare」にチェックを入れます。デフォルトで--select state:modifiedと入力されており、変更のあったモデルそのものが比較対象となるような設定となっています。(CI ジョブ自体は--select state:modified+となっており、変更のあったモデルとその下流のモデルが対象となっています。)
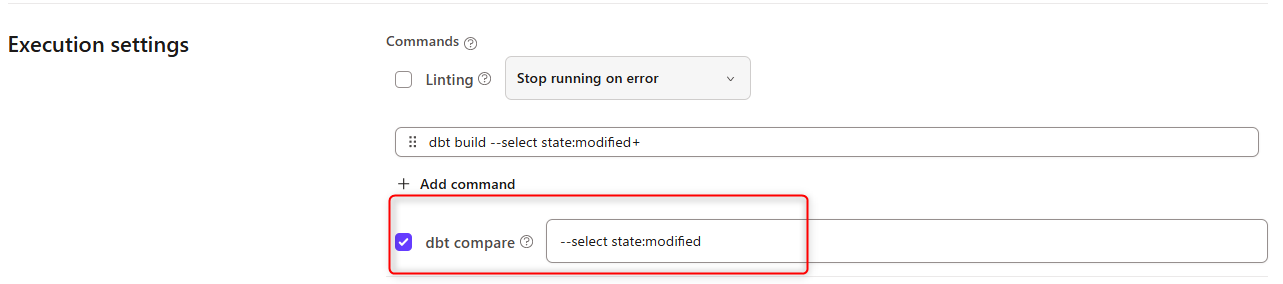
以降で、基本的な画面上の表示を見ていきます。
モデルの追加
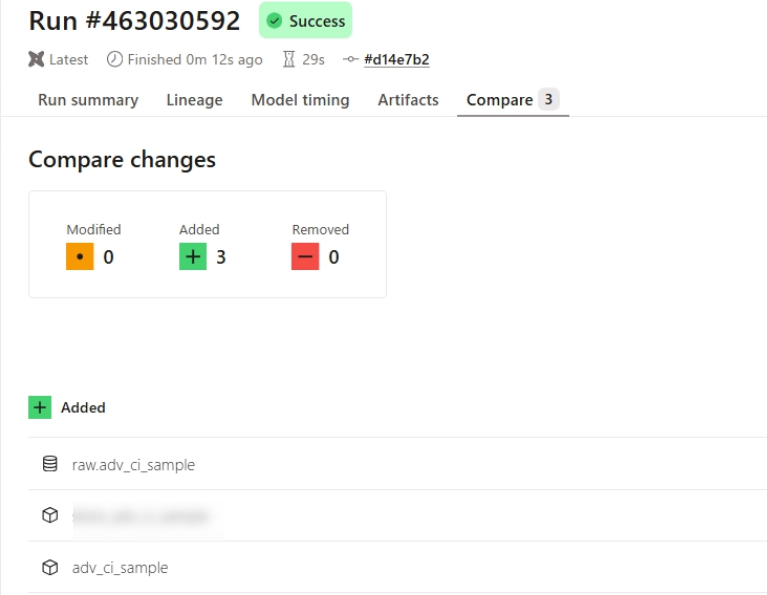
PR 発行時に新規モデルが追加されている場合は下図のように「Added」欄に対象のモデルが表示されます。Source 定義の追加やテストの追加もここに含まれるようです。
値の変更
下図のように既存のモデルを変更し、値が変わるような変更を行ったとします。
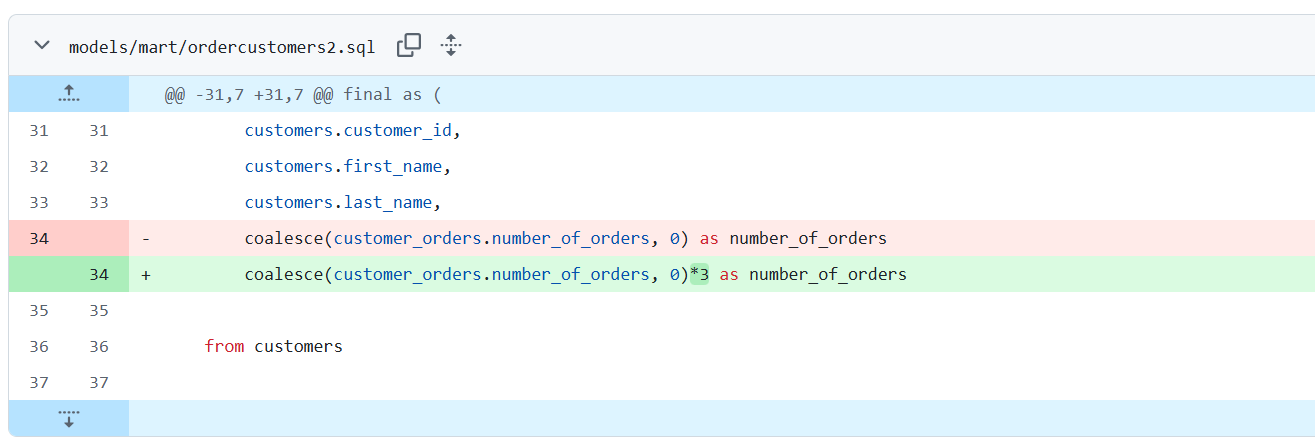
この場合、「Modified」としてどの程度変更があったかを示す割合とあわせて表示されます。(※新規追加したテストも下図ではあわせて表示されています。)
レコード数の変更
下図のようなフィルタを追加し既存のモデルからレコードが減少するような変更を加えてみます。
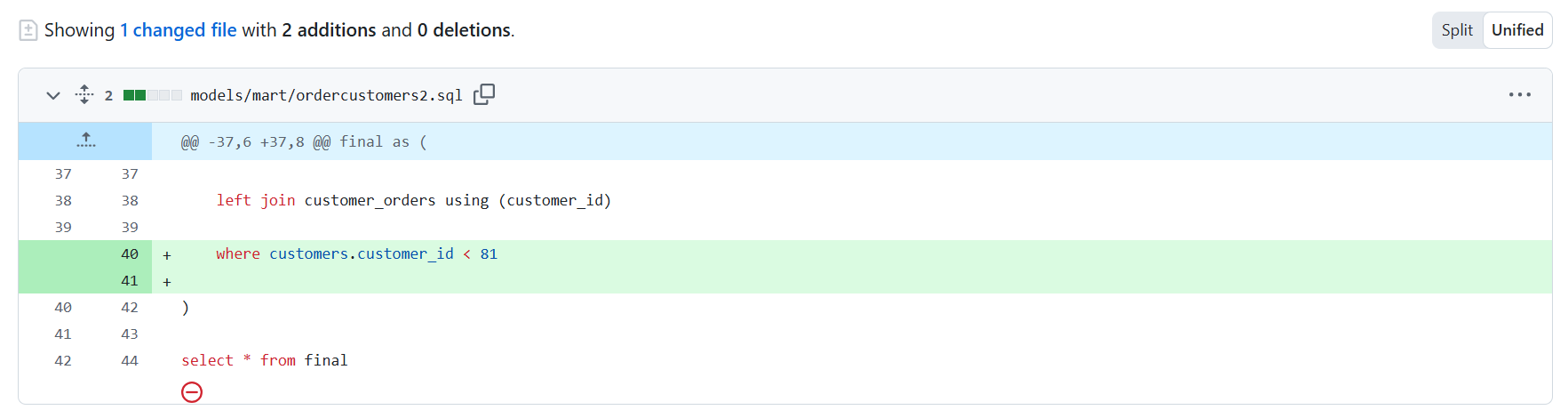
この場合、主キーを基準にレコードが減少したとして表示されます。
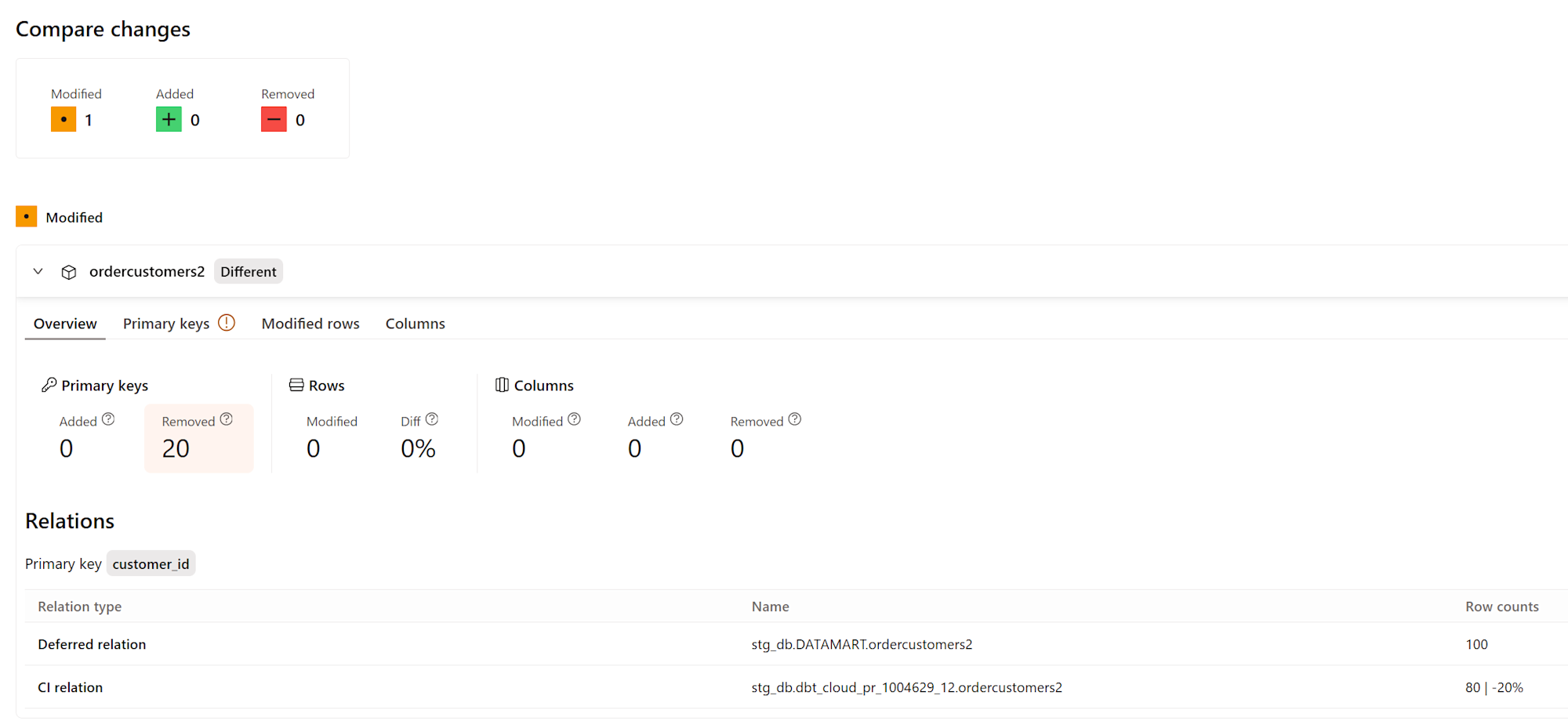
キーとなる項目がない場合
キーとして使用できる項目がわからない場合は、下図の表示となります。主キーを基準としたレコード差分(追加・削除・変更された行数)がわかる機能のため、このためには、対象モデルのキーカラムに constraints または ユニークデータテスト が必要です。
event_time による最適化機能
Advanced CI では、モデルに event_time カラムを設定することで、比較先の環境と CI 環境間で重複している期間のみを比較対象にするような設定が可能です。
公式ドキュメント記載の例ですが、以下のようなケースでは期間を絞らずに比較を行うと、差分の誤検知が発生する可能性があります。
- CI 環境では直近 7 日間など、期間を限定してモデルをビルドする場合、比較先環境に存在するそれ以前のデータが「削除された行」と解釈されてしまう
- CI ジョブは実行時点の最新データを含むため、比較先環境よりも新しいデータが含まれることがあります。その結果、本来は単に処理時点が異なるだけであるにもかかわらず、「新規追加行」としてフラグ付けされてしまう
このようなケースに対応するため、モデルに event_time を設定することができます。
event_time を設定することで、比較先環境と CI 環境の共通する時間範囲のみを比較対象とするようになり、削除・新規追加の誤判定を防止できます。あわせて、不要な期間のデータを比較対象から除外できるため、比較処理の高速化や計算コストの削減も期待できます。
試してみる
検証用のサンプルデータとして以下のテーブルとレコードを追加し、Source 定義で参照できるようにしておきます。
CREATE OR REPLACE TABLE ADV_CI_SAMPLE (
ID NUMBER,
USER_ID NUMBER,
AMOUNT NUMBER(10,2),
STATUS STRING,
EVENT_TIME TIMESTAMP_NTZ,
UPDATED_AT TIMESTAMP_NTZ
);
INSERT INTO ADV_CI_SAMPLE
SELECT
SEQ4() + 1 AS ID,
UNIFORM(1, 1000, RANDOM()) AS USER_ID,
UNIFORM(100, 10000, RANDOM()) / 100 AS AMOUNT,
'completed' AS STATUS,
DATEADD(
day,
- UNIFORM(0, 29, RANDOM()),
CURRENT_TIMESTAMP()
) AS EVENT_TIME,
CURRENT_TIMESTAMP() AS UPDATED_AT
FROM TABLE(GENERATOR(ROWCOUNT => 1000));
このテーブルを参照するモデルを作成します。間に一つレイヤを挟んでいますが、下図のような内容としました。
with adv_ci_sample as (
select * from {{ ref('store_adv_ci_sample') }}
),
final as (
select
id,
user_id,
amount,
status,
event_time,
updated_at
from adv_ci_sample
)
select * from final
キー項目での比較のため、モデルのプロパティを設定するYAMLファイルにユニークテストを追加しておきます。この時点ではevent_time は未設定です。
version: 2
models:
- name: adv_ci_sample
columns:
- name: id
data_tests:
- unique
- not_null
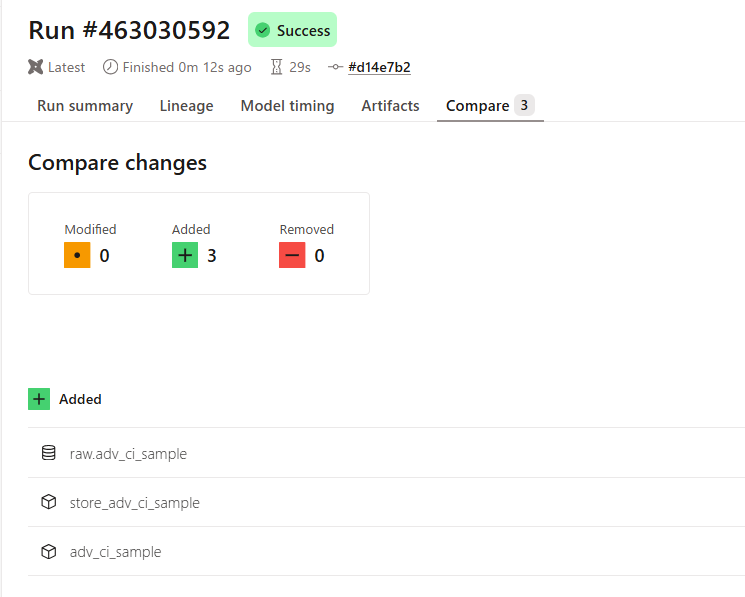
上記の内容でモデルを追加します。PR 発行時の比較結果は下図となり新規モデルとして認識されます。
モデルを変更
モデルを以下のように変更し、CI 環境では直近7日間のレコードのみを使用する設定とします。
with adv_ci_sample as (
select * from {{ ref('store_adv_ci_sample') }}
{% if target.name in ['ci', 'dev'] %}
where event_time >= dateadd(day, -7, current_timestamp())
{% endif %}
),
final as (
select
id,
user_id,
amount,
status,
event_time,
updated_at
from adv_ci_sample
)
select * from final
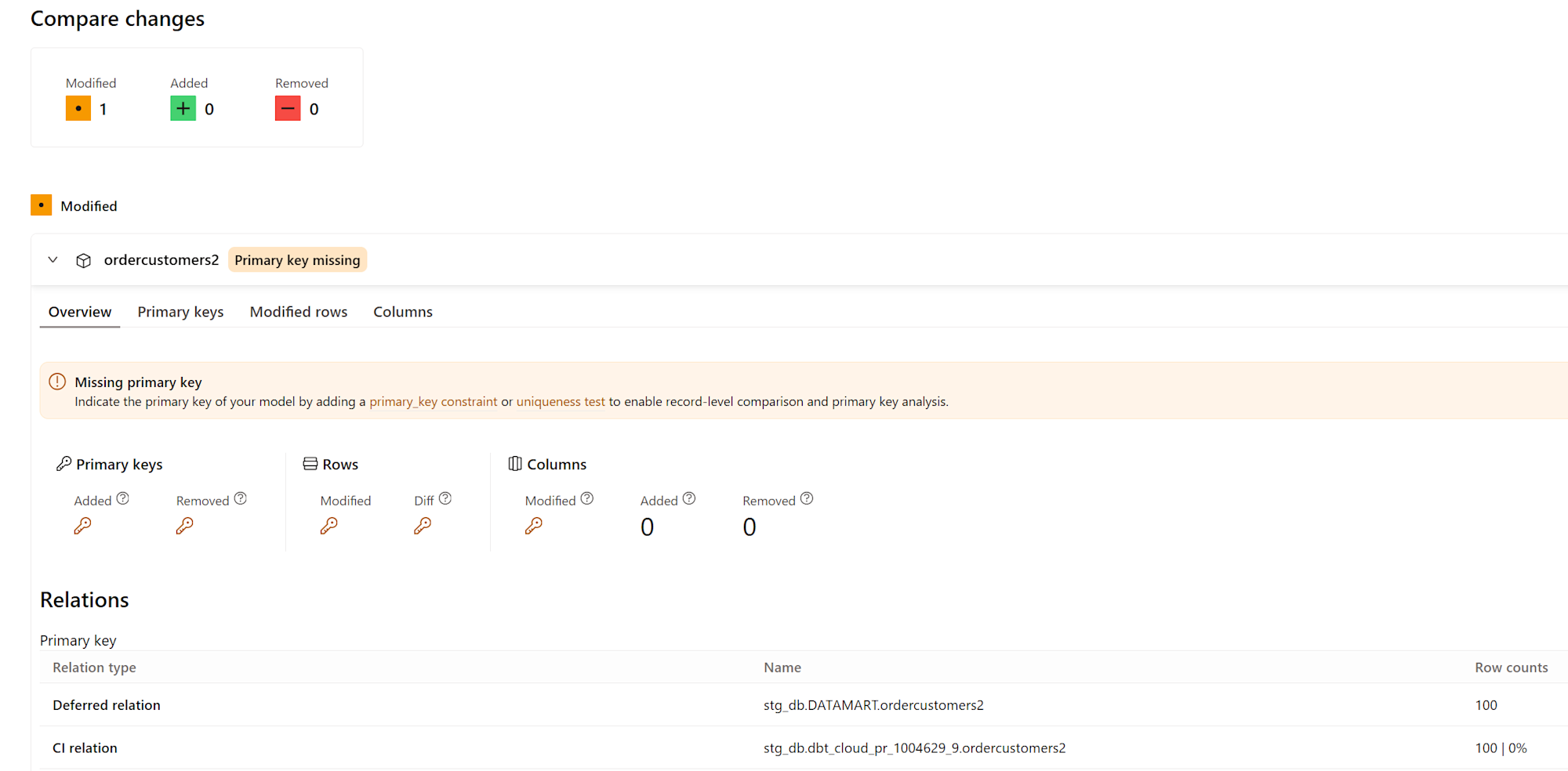
この状態で再度 PR を作成すると、下図のようになり、フィルタしたレコードが削除されたとして扱われます。
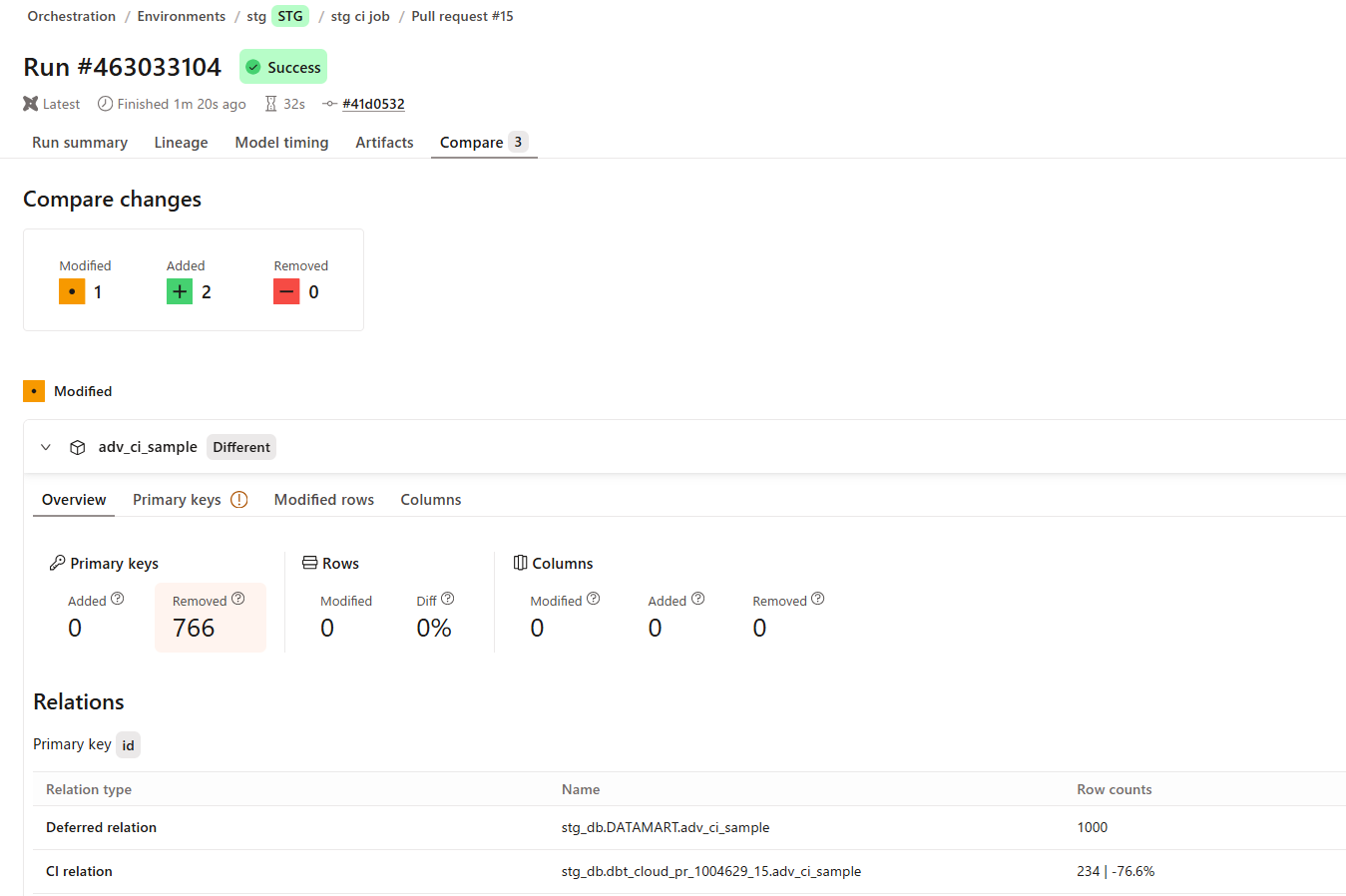
そこで、対象のモデルの YAML ファイルを変更しevent_timeプロパティをイベント発生時刻を表すカラムに設定します。
version: 2
models:
- name: adv_ci_sample
columns:
- name: id
data_tests:
- unique
- not_null
config:
event_time: event_time
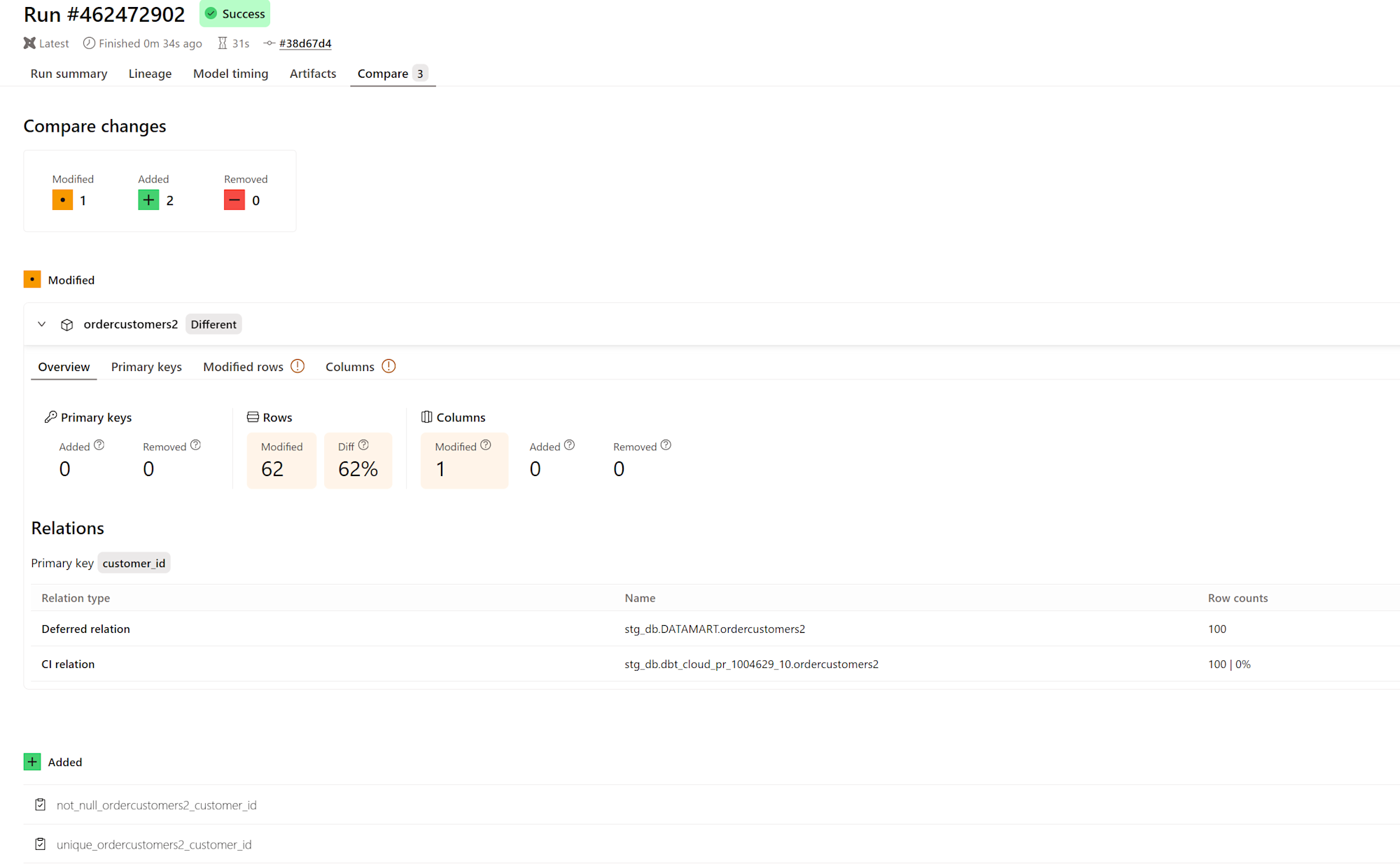
この状態で PR を作成すると、今度は下図のようになりキー項目の削除として認識されることはありませんでした(CI環境では比較先と比べてレコード数が少ないことは Relation メニューから確認できる。)
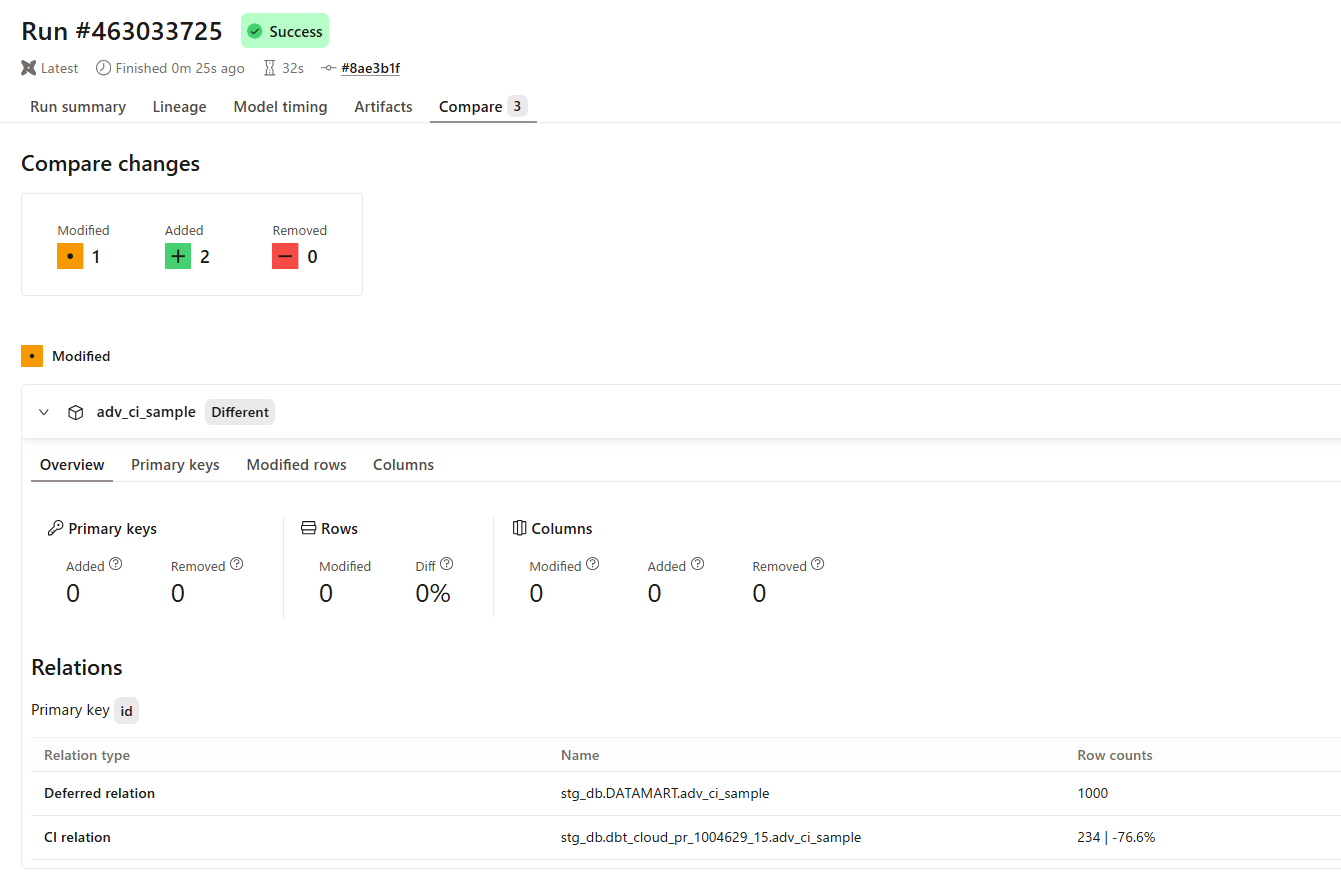
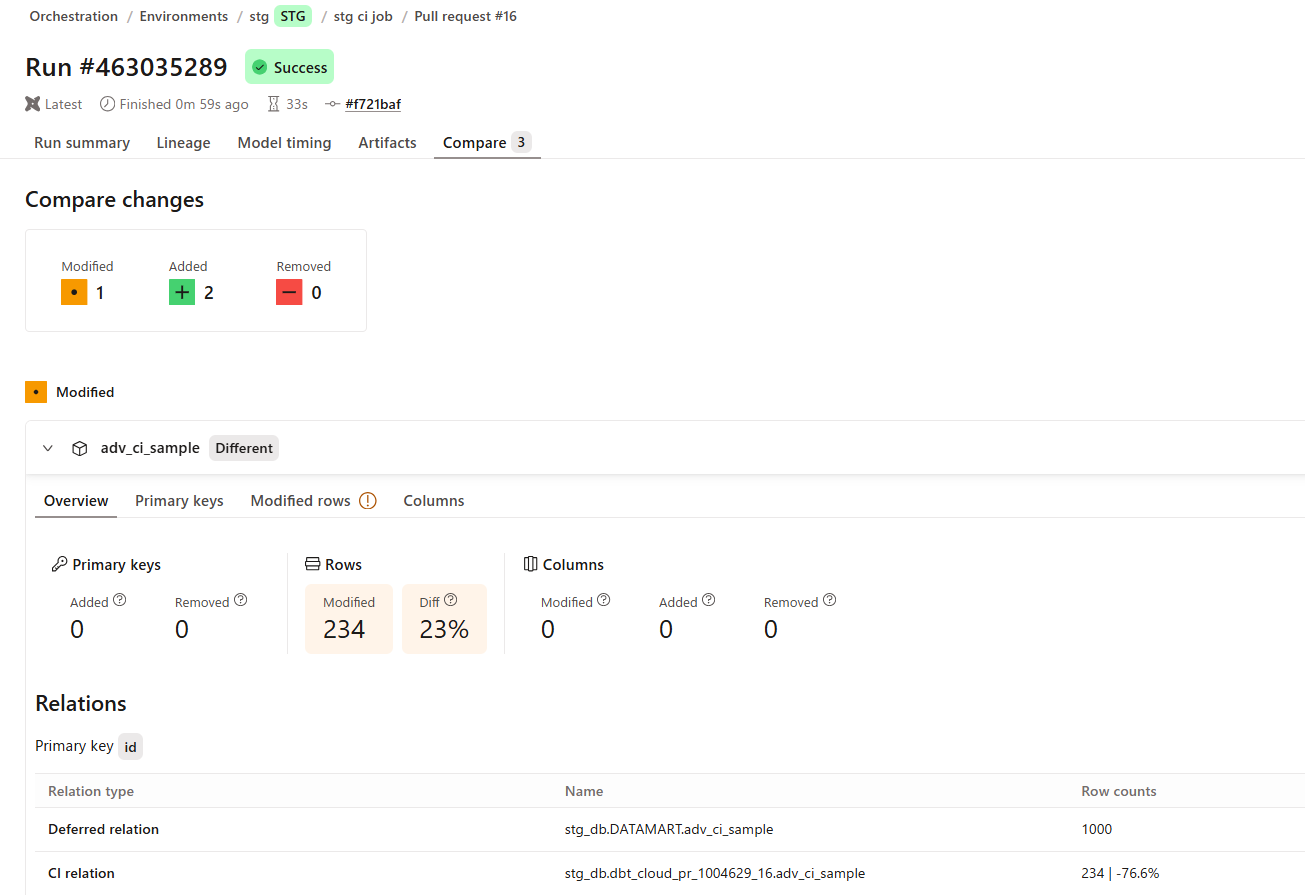
続けて実際に値を変更するような設定で PR を作成します。
amount * 2 as amount,
この場合、CI 環境と比較先の重複期間にあるレコードについて、違いとして検出されました。
event_time プロパティを設定時に発行される SQL を確認
一通り動作を確認できたので、さいごに実際にevent_timeプロパティ追加した際に発行される SQL を確認します。
はじめに以下のような SQL が発行されていました。
with min_maxes as (
select min(event_time) as min_event_time, max(event_time) as max_event_time
from (select * from stg_db.DATAMART.adv_ci_sample) a_subq
union all
select min(event_time) as min_event_time, max(event_time) as max_event_time
from (select * from stg_db.dbt_cloud_pr_1004629_15.adv_ci_sample) b_subq
)
select max(min_event_time) as min_event_time, min(max_event_time) as max_event_time
from min_maxes
内容を確認すると、CI 環境(stg_db.dbt_cloud_pr_1004629_15.adv_ci_sample)と比較先の環境(ここではマージ先のstg_db.DATAMART.adv_ci_sample)で、それぞれの event_time の最小値・最大値を取得し、その重複期間を算出していることが分かります。
具体的には、以下の処理により、両環境に共通する期間を算出しています。
max(min_event_time)(開始日の遅い方)min(max_event_time)(終了日の早い方)
このようにして算出された重複期間をもとに、続いて発行される SQL では、実際のレコード差分比較処理が実行されていました。以下は一部分のみの抜粋ですが、比較先と CI 環境のデータからなる CTE が定義され、行全体のハッシュ化などが行われています。
with
a as (
select
ID,
USER_ID,
AMOUNT,
STATUS,
EVENT_TIME,
UPDATED_AT,
md5(cast(coalesce(cast(id as TEXT), '_dbt_dbt_compare_macros_surrogate_key_null_') as TEXT)) as dbt_audit_surrogate_key,
row_number() over (partition by dbt_audit_surrogate_key order by dbt_audit_surrogate_key ) as dbt_audit_pk_row_num,
hash(ID, USER_ID, AMOUNT, STATUS, EVENT_TIME, UPDATED_AT, dbt_audit_pk_row_num) as dbt_audit_row_hash
from (select * from stg_db.DATAMART.adv_ci_sample)
where event_time >= '2026-02-09 16:47:29.990000'
and event_time <= '2026-02-15 16:47:29.990000'
),
b as (
select
ID,
USER_ID,
AMOUNT,
STATUS,
EVENT_TIME,
UPDATED_AT,
md5(cast(coalesce(cast(id as TEXT), '_dbt_dbt_compare_macros_surrogate_key_null_') as TEXT)) as dbt_audit_surrogate_key,
row_number() over (partition by dbt_audit_surrogate_key order by dbt_audit_surrogate_key ) as dbt_audit_pk_row_num,
hash(ID, USER_ID, AMOUNT, STATUS, EVENT_TIME, UPDATED_AT, dbt_audit_pk_row_num) as dbt_audit_row_hash
from (select * from stg_db.dbt_cloud_pr_1004629_15.adv_ci_sample)
where event_time >= '2026-02-09 16:47:29.990000'
and event_time <= '2026-02-15 16:47:29.990000'
),
・
・
・
さいごに
Advanced CI 機能の event_time による最適化機能適用時の比較内容を確認してみました。
こちらの内容がどなたかの参考になれば幸いです。









