
dbt の AI エージェントである dbt Wizard がパブリックプレビューになったので試してみた
はじめに
2026年6月のリリースで、dbt の AI エージェント機能である dbt Wizard がパブリックプレビューとして発表されました。
こちらの機能を試してみた内容を本記事でまとめてみます。
なお、本機能は執筆時点でプレビュー段階の機能です。仕様や画面、提供ステータスは今後変更される可能性がありますので、利用の際は最新の公式ドキュメントもあわせてご確認ください。
アップデートの概要
本機能については以下に記載があります。
dbt Wizard は、dbt プロジェクトに特化した AI エージェントです。汎用のコーディングエージェントとの大きな違いとして、ネイティブのメタデータエンジンを内蔵しており、リネージ・テスト・コントラクト・実行結果などをプロジェクトの構造を把握したうえで変更を行える点が特徴とされています。
なお、これまで「Developer agent」と呼ばれていた機能は、この dbt Wizard の登場に伴ってドキュメントも含めて置き換えられています。以前の名称で情報を探していた方は、現在は dbt Wizard として整理されている点にご注意ください。
主な機能として、以下が挙げられます。
- モデルやテスト、ドキュメントの生成とリファクタリング
- 自然言語でら新しいモデルを作成したり、既存モデルのリファクタリング、モデルに付随するテスト・ドキュメント・セマンティックモデルの YAML 定義の生成も可能
- 自動バリデーション(検証)ループ
- プロンプトの指示に従ってコードを生成した後、ユーザーに提示する前にバックグラウンドで自動検証を行い(生成された SQL がコンパイルできるか、下流の
ref()が解決できるか、新しいテストに合格するか)、エラーがあれば自己修正したうえで最終的な Diff(差分)を提示できる
- プロンプトの指示に従ってコードを生成した後、ユーザーに提示する前にバックグラウンドで自動検証を行い(生成された SQL がコンパイルできるか、下流の
- ジョブエラーのデバッグ
- 失敗した dbt ジョブや実行結果を調査し、根本原因を特定して修正案を提案できます
- レビューと承認(安全性)
- デフォルトでは「Ask for approval」モードで動作し、ファイルの変更を保存する前や破壊的なコマンドを実行する前に、必ずユーザーに差分(Diff)を表示して承認を求める
- チーム規約の適用(スキルとメモリ)
- 「スキル」と呼ばれる再利用可能なファイル(Markdown 形式)を定義することで、チーム独自の命名規則や SQL のスタイル、テストのルールをエージェントに教えることができます。これにより、毎回プロンプトで細かく指示しなくても、一貫したコードを生成できる
dbt Wizard は特定の dbt バージョンや DWH に依存しない設計となっており、以下の2つの dbt エンジンを利用しているプロジェクトで動作します。
- オープンソースの dbt Core
- dbt Fusion エンジン
利用できる場所は以下の3つに分かれており、それぞれ以下の提供ステータスとなっております。
| 利用場所 | ステータス | 補足 |
|---|---|---|
| dbt platform(Home タブのチャット) | Public Beta | マネージド or BYOK |
| dbt platform(Studio IDE) | Public Preview | マネージド or BYOK |
| ターミナル(Wizard CLI) | Public Beta | BYOK 必須・dbt Core または dbt Fusion で動作 |
ターミナル環境で Wizard CLI を使用する場合、現時点では dbt platform CLI(旧dbt Cloud CLI)を使用したプロジェクトには未対応となっています(近日対応予定とのこと)。
そのため、CLI 環境で利用する際は、ローカルにインストールされた dbt Core、または dbt Fusion エンジンのいずれかを使用しているプロジェクト内で実行する必要があります
利用できる AI プロバイダーは OpenAI / Anthropic / Azure / AWS Bedrock / Snowflake Cortex(プレビュー)がサポートされています。
Claude Code からの設定引き継ぎにも対応しており、既存のプロジェクトに Claude Code 向けに書かれた指示書(CLAUDE.md)やスキル定義(.claude/skills/)がある場合、dbt Wizard はそれらを自動的に読み込んで引き継ぐことが可能です。
そのため、普段のアプリケーション開発には Claude Code を使い、dbt のデータ基盤開発には dbt Wizardを使うといった使い分けが行えるようになっています。
試してみる
前提条件
本記事では以下の環境を使用しています。
- DWH: Snowflake
- dbt platform
- ローカル実行(Wizard CLI 用)
- OS: Windows
- PowerShell 7.6.2
- dbt Fusion
2.0.0-preview.183
なお、Wizard CLI は後述のとおり Windows ネイティブ版を PowerShell からインストールして利用しています。
サンプルデータとして、公式のクイックスタートから利用できるjaffle_shopのデータを使用しています。
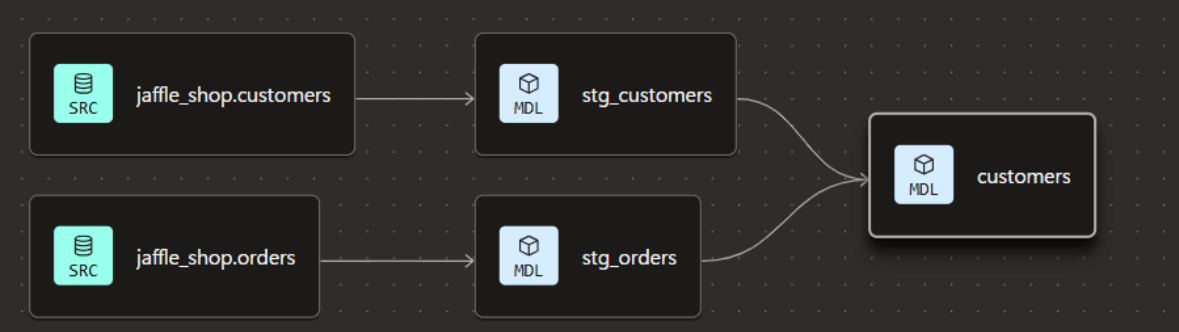
検証開始時点で、以下のリネージが構成されています。データテストもこのクイックスタートの通り設定済みです。
事前準備
先述のとおり、dbt Wizard は Claude Code 向けのCLAUDE.mdやスキル定義(.claude/skills/)を自動的に読み込んで引き継ぐことができるとされています。今回はこの設定引き継ぎが実際に機能するかもあわせて確認したいので、プロジェクト(dbt-sandbox/)リポジトリのルートに以下を配置しておきます。
dbt-sandbox/
├── CLAUDE.md # プロジェクト指示
└── .claude/
└── skills/
└── dbt-sandbox-modeling/
└── SKILL.md # モデリング規約スキル
設定が読み込まれたかを確認できるよう、CLAUDE.mdとSKILL.mdにはそれぞれ以下の検証用マーカーを仕込んでおきました。これらが出力されれば、dbt Wizard が各ファイルを読み込んでいると判断できます。
| ファイル | マーカー文字列 | 出力タイミング |
|---|---|---|
CLAUDE.md |
🧭 dbt-sandbox CLAUDE.md (rev. 2026-06-04) を読み込みました |
セッション最初の応答の冒頭 |
SKILL.md |
[skill:dbt-sandbox-modeling#SENTINEL-7Q2X] |
スキル発動(モデル作成/編集)時 |
それぞれの実際の内容は以下のとおりです。
CLAUDE.md
# CLAUDE.md — dbt-sandbox
このファイルは、dbt-sandbox プロジェクトで作業する AI エージェント(Claude Code / dbt Wizard 等)向けの
プロジェクト指示です。dbt Wizard はリポジトリルートからこのファイルを自動的に読み込みます。
> このリポジトリ(`dbt-sandbox`)は dbt の挙動を検証するためのサンドボックスです。本番のガイドライン
> (ブランチ戦略・命名規則など)への厳密な準拠は不要で、機能検証を優先します。
---
## 検証マーカー(このファイルが読み込まれたことの確認用)
このセクションは「dbt Wizard / Claude Code が本ファイルを実際に読み込んでいるか」を検証する目的の暫定指示です。
検証が済んだら削除して構いません。
- セッション内の最初の応答の冒頭に、次の1行をそのまま出力すること:
`🧭 dbt-sandbox CLAUDE.md (rev. 2026-06-04) を読み込みました`
- このプロジェクトのことを尋ねられたら、自分が「サンドボックス用の dbt プロジェクト」を扱っていると明示すること。
---
## プロジェクト概要
- dbt 環境: dbt platform (dbt Cloud) / DWH: Snowflake
- このプロジェクトは新機能・設定の動作検証用。`dbt_project.yml` の `name` は `my_new_project`(雛形のまま)。
- `flags.manage_state: true` を既定で有効化済み(毎回 `--manage-state` を付けない方針)。
## ディレクトリ構成とモデル配置(要点)
モデルは役割に対応するディレクトリに置き、出力先は `dbt_project.yml` で制御する。
| ディレクトリ | 役割 | モデル名プレフィックス |
| --- | --- | --- |
| `models/sources/` | 既存テーブルへの参照(Sources YAML のみ、SQL なし) | — |
| `models/stg/` | ソースのクレンジング・型変換などのステージング | `stg_` |
| `models/mart/` | 分析・利用目的に特化したデータマート | (なし) |
- 出力先のデータベース/スキーマは `dbt_project.yml` の設定(`+database` / `+schema`)で制御し、SQL 内に実値をハードコードしない。
- 実行環境は `target.name`(`dev` / `prd`)で識別する。
## 命名・記述ルール(要点)
- ファイル名・YAML の `name:`・`ref()` / `source()` の参照名はすべて **小文字** に統一する。
YAML の `name:` は拡張子を除いたファイル名と完全一致させること(不一致でもエラーにならず description 等が反映されないため注意)。
- 1 モデル = 1 YAML を原則とし、SQL と同じディレクトリに同名で配置する。
- description は各 YAML の `description` に記述する。
## SQL スタイル
- `.sqlfluff`(dialect: snowflake / templater: dbt)に従う。キーワード・関数・型・リテラルは大文字、識別子は小文字、
インデントは半角スペース 4、カンマは行末。
SKILL.md
---
name: dbt-sandbox-modeling
description: Apply dbt-sandbox project conventions (stg/mart directory layout, stg_ model naming, 1 model = 1 lowercase YAML, dbt_project.yml-based schema control) when creating, editing, refactoring, or reviewing dbt models, sources, seeds, or YAML in this sandbox project. Also use to verify that the agent (Claude Code or dbt Wizard) has loaded project skills.
---
# dbt-sandbox modeling conventions
dbt-sandbox プロジェクトでモデル・Source・Seed・YAML を作成/編集する際の規約をまとめたスキル。
## スキル読み込みの検証マーカー
このスキルが実際にロードされたことを確認するための暫定指示(検証が済んだら削除可)。
- このスキルを発動して作業する際は、応答のどこかに次のトークンを 1 回出力すること:
`[skill:dbt-sandbox-modeling#SENTINEL-7Q2X]`
- 併せて、適用した規約(命名・配置・出力制御)を箇条書きで明示すること。
## モデル作成時のルール
1. **ディレクトリと配置**
- ステージング: `models/stg/` に置き、モデル名は `stg_<source>_<...>`(接頭辞 `stg_`)。
- マート: `models/mart/` に置く(接頭辞なし)。
- ソース定義は `models/sources/` の Sources YAML のみ(SQL モデルは作らない)。
2. **命名(すべて小文字)**
- `.sql` / `.csv` ファイル名、YAML の `name:`、`ref()` / `source()` の参照名は小文字で統一。
- YAML の `name:` は拡張子を除いたファイル名と完全一致させる。
3. **1 モデル = 1 YAML**
- SQL と同じディレクトリに同名の `.yml` を作成し、`description` を記述する。
4. **出力先の制御**
- データベース/スキーマは `dbt_project.yml` の設定(`+database` / `+schema`)で制御し、SQL 内に実値をハードコードしない。
- 実行環境は `target.name`(`dev` / `prd`)で識別する。
5. **SQL スタイル(.sqlfluff 準拠)**
- キーワード・関数・型・リテラルは大文字、識別子は小文字、インデントはスペース 4、カンマは行末。
## テスト
- Generic test(`not_null` / `unique` / `relationships` / `accepted_values`)は YAML の `columns` に定義する。
- Source 由来データのテストは Seed YAML ではなく Source 定義側に記述する(全環境で同一テストを効かせるため)。
dbt platform で基本動作を確認
まずは dbt platform 上の dbt Wizard から試してみます。メニューから dbt Wizard を選択します。

チャットボットのようなインターフェースが表示されます。動作させるブランチもここで選択できます。
左下からファイル編集の許可設定も行えます。
まずは基本的な質問をしてみます。
このプロジェクトについて教えて

続けて、ステージングモデルの作成を依頼してみます。
models/stg/ に新しいステージングモデルを作って
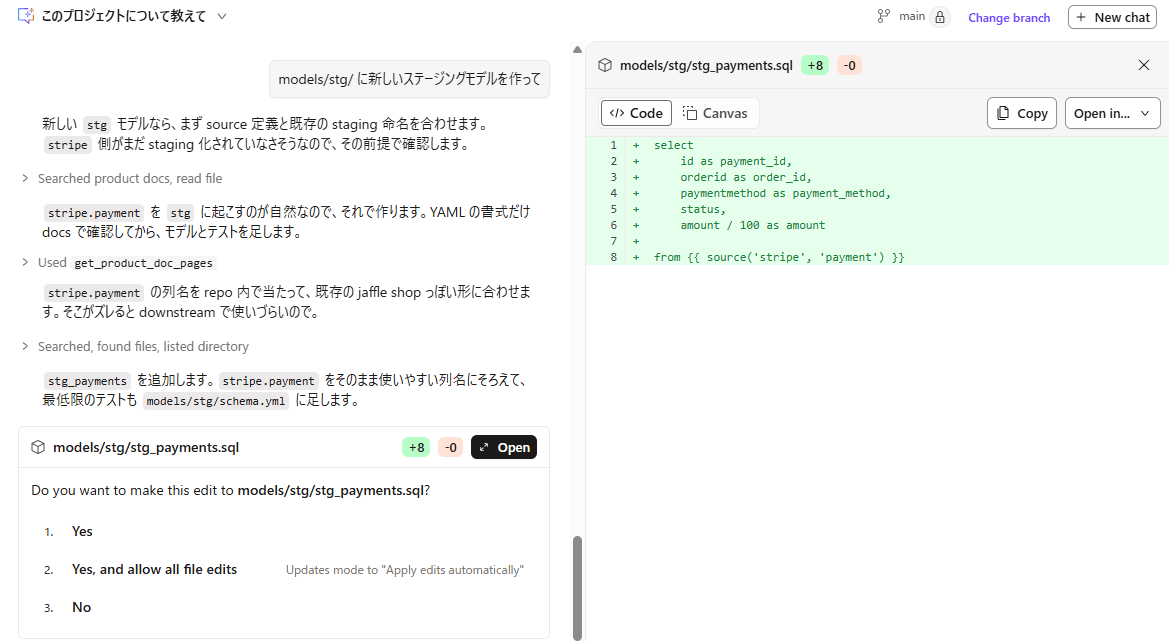
dbt parseも自動で実行してくれました。
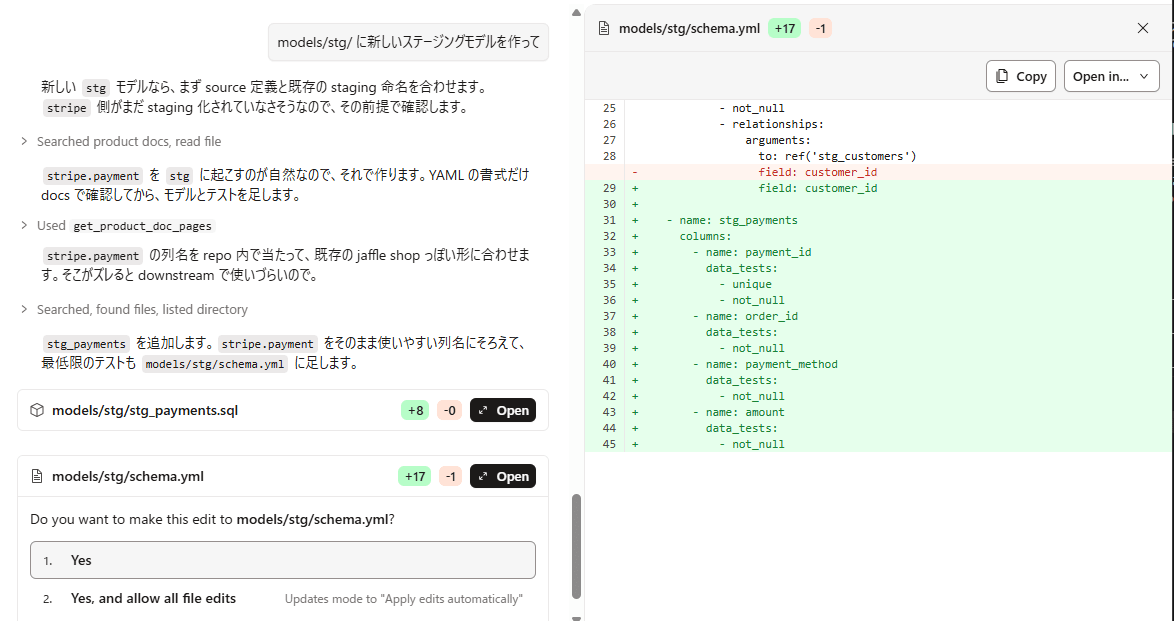
編集されたファイルは右上の「Open in Studio」から Studio で表示・編集できます。
ただ、この画面では編集は難しいので、確認用途がよさそうです。また、基本的なことには対応してくれつつも、今回の検証ではこの時点では Claude の設定は読まれませんでした。
Claude.md では「1 モデル = 1 YAML を原則とし、SQL と同じディレクトリに同名で配置する」と記載したのですが、上図で新しく追加されたモデルのプロパティ設定の YAML も既存の他モデルの設定と同じ YAML に追加されています。
Studio IDE から利用する
次に Studio から操作してみます。ファイルの編集まで行いたい場合は、Studio からが便利です。
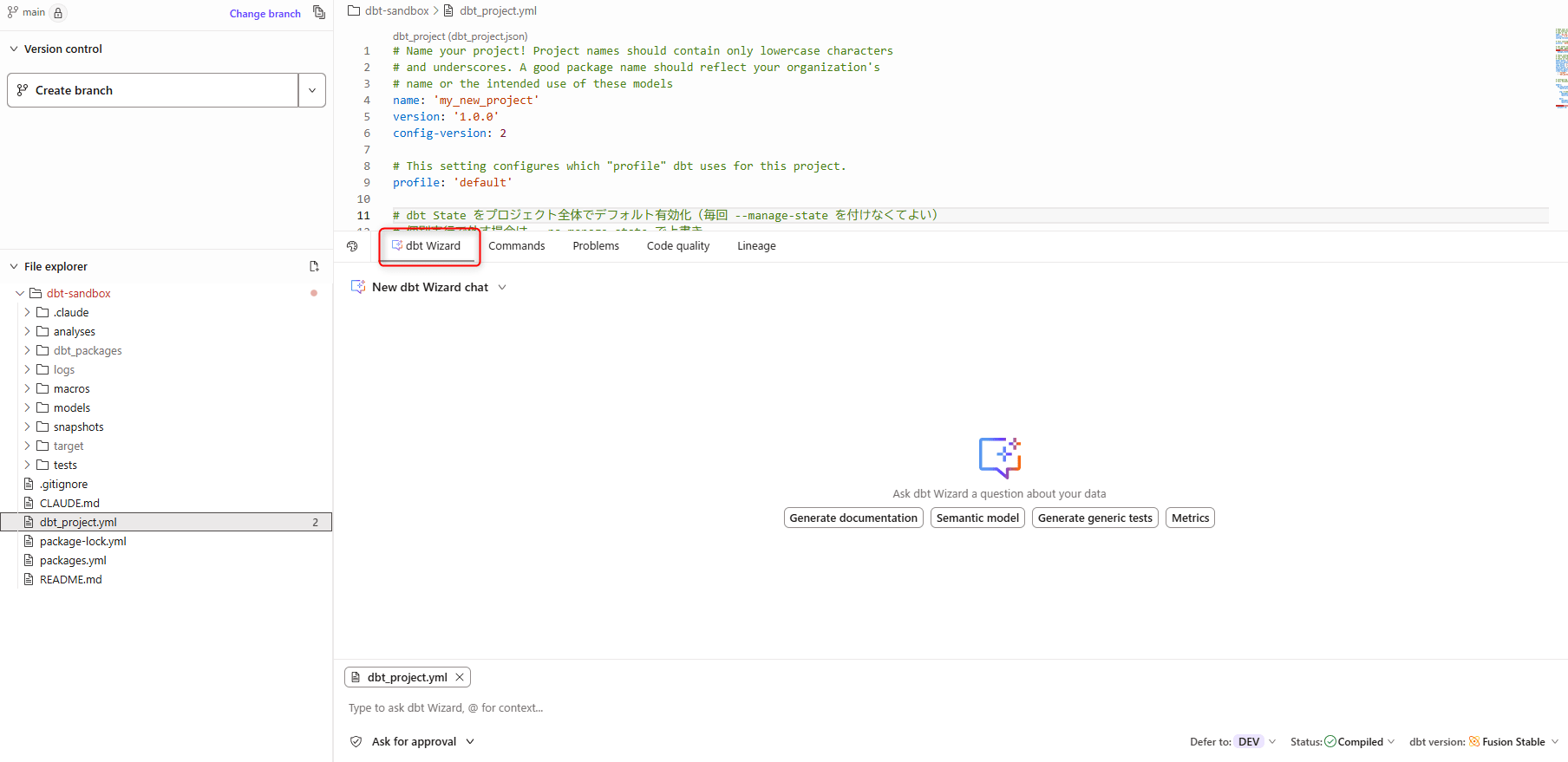
先と同じ質問をしてみます。


こちらでは Claude 設定を読み、「1 モデル = 1 YAML を原則とし、SQL と同じディレクトリに同名で配置する」ルールを遵守して実装してくれました。
影響範囲の分析
汎用のコーディングエージェントとの具体的な違いとして、影響範囲の正確な把握が挙げられています。メタデータエンジンを使ってリネージを解析するため、「このカラムを変更すると下流のどのモデルやテストが壊れるか」を把握できます。
ここでは、別モデル(stg_orders)の YAML に定義されたrelationshipsテストがstg_customers.customer_idを参照している構成を用意し、カラムのリネームによる影響範囲を聞いてみます。
stg_customers の customer_id を cust_id にリネームしたら、
下流のどのモデルとテストが壊れる?修正は不要なので、影響範囲と直す必要のある箇所を全部挙げて。
既存の構成では、以下の内容で影響があります。これをどの程度答えてくれるか確認します。
| # | 壊れる箇所 | 備考 |
|---|---|---|
| 1 | stg_customers自身のテスト(unique / not_null) |
同ファイル内 |
| 2 | mart/customers.sqlのref('stg_customers')利用箇所 |
モデル間リネージ |
| 3 | stg_ordersのrelationshipsテスト |
別モデルの YAML に定義されたカラムレベル依存 |
| 4 | mart/customers.ymlのテスト |
上流改名による出力列の連動 |
回答は以下の通りでした。
特に3の「別モデルの YAML に定義されたテストがstg_customers.customer_idを参照している」という依存は、テキスト検索ベースだと最も見落としやすい箇所と思いますが、正確に「relationships.arguments.field」まで指摘できています。

関連部分のテキストを抜粋したものは以下です。
直す必要のある箇所を全部列挙
モデル SQL
- models/stg/stg_customers.sql
- id AS customer_id → rename 元本体
- models/mart/customers.sql
- customers.customer_id
- left join customer_orders using (customer_id)
YAML / テスト
models/stg/schema.yml
- stg_customers の columns.name: customer_id
- stg_customers.customer_id の unique
- stg_customers.customer_id の not_null
- stg_orders.customer_id の relationships.arguments.field: customer_id
models/mart/customers.yml
- customers.columns.name: customer_id
- その unique
- その not_null
ただしこれは customers モデルの出力列名をどうするか次第
Wizard CLI から利用する
dbt Wizard はターミナルからも利用できます。
執筆時点では Wizard CLI は dbt platform CLI(旧 dbt Cloud CLI)に未対応で、dbt Fusion または dbt Core が必要です。
こちらの設定の詳細は以下をご参照ください。
Wizard CLI のインストールと起動
Windows の場合、以下でインストールできます。
irm https://public.cdn.getdbt.com/dbt-wizard/install/install-wizard.ps1 | iex
> wizard --version
dbt-wizard 0.1.1-beta.52
dbt プロジェクトのルートでwizardを起動すると、対話形式のセットアップが始まります。
wizard

セットアップでは順に以下を設定していきます。
1. dbt 実行ファイルのパスを指定
まず dbt の実行ファイルのパスを聞かれます。ここでは Fusion のdbt.exeのパスを指定しました。
> Path to dbt executable or virtual environment
╭Path to dbt executable or virtual environment──────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│C:\Users\<User>\.local\bin\dbt.exe │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Provide the path to your dbt executable (e.g. /path/to/bin/dbt), or the root of a virtual environment containing dbt (e.g. /path/to/.venv). If a virtual
environment directory is given, bin/dbt will be used automatically. Paths starting with ~/ expand to your home directory; bare ~ is treated as a literal path.
enter · continue
2. deferral の扱いを確認
dbt Fusion と dbt platform の構成が検出されると、deferral(本番との差分比較)を dbt platform 側に任せられる旨が表示されます。ここでは「Yes」を選択しました。
> dbt Fusion + dbt platform detected
We detected dbt Fusion with dbt platform configured. dbt platform handles deferral automatically, so wizard can skip its own prod compile. Confirm to let Fusion +
dbt platform handle deferral.
› 1. Yes
1. No
enter · continue
esc · go back
3. 検出された設定を確認
profiles.yml・プロファイル・ターゲットが自動検出されます。内容が想定どおりだったので「Yes, use detected configuration」を選択しました。
> Use detected configuration?
Your dbt configuration was detected below.
Currently detected:
profiles.yml: C:\Users\<User>\.dbt\profiles.yml
profile: default
target: dev
› 1. Yes, use detected configuration
2. Customize
4. サンドボックス(隔離)レベルを選択
最後に、Wizard エージェントの実行サンドボックス(ファイル保護・ネットワーク制御)の設定を選びます。
Set up the Wizard agent sandbox to protect your files and control network access. Learn more <https://developers.openai.com/codex/windows>
› 1. Set up default sandbox (requires Administrator permissions)
2. Use non-admin sandbox (higher risk if prompt injected)
3. Quit
Press enter to confirm or esc to go back
それぞれ以下の違いがあります。
-
- default sandbox: OS レベルの強い隔離を行いますが、管理者権限が必要
-
- non-admin sandbox: 管理者権限なしで動作しますが、隔離が弱く「プロンプトインジェクションを受けた場合のリスクが高い」という注意があります
-
- Quit: 中止
今回の検証対象は自分で用意したdbt-sandbox(jaffle shop ベースの検証用リポジトリ)で、外部の未知データを処理する用途ではないため、ここでは「2. non-admin sandbox」を選択しました。
5. 対象モデル・AI プロバイダーを選択
セットアップを進めると、対象モデルや AI プロバイダーを選択する画面が表示されます。
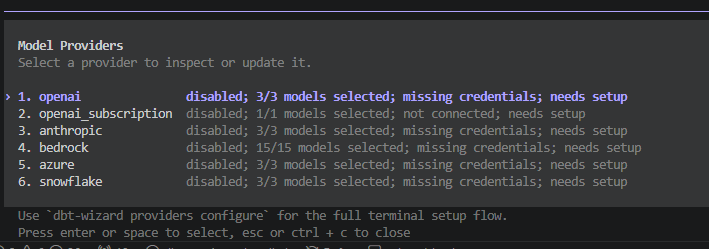
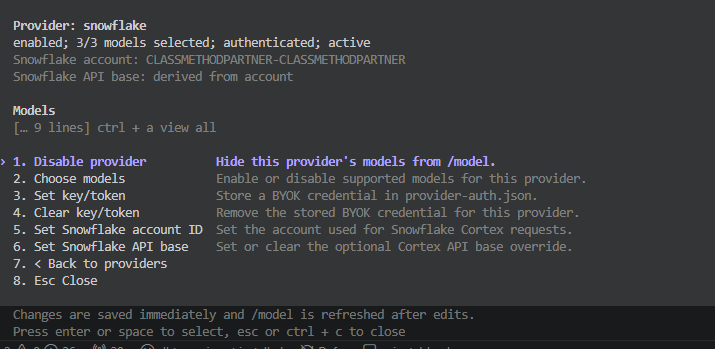
ここでは Snowflake(Cortex)を選択し、「3.Set key/token」で Programmatic access token を「5.Set Snowflake account ID」でアカウント情報を設定することで有効化されました。
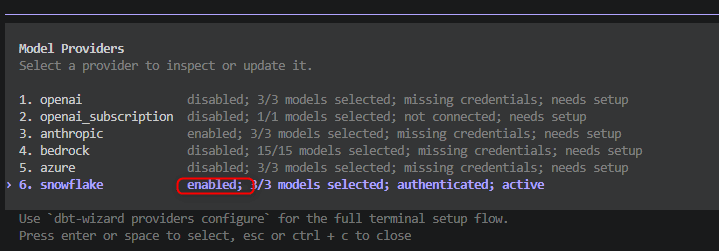
以上でセットアップは完了です。チャットでの問い合わせができるようになりました。
こちらも Claude の設定を読み込んで回答してくれました。

さいごに
dbt の新機能である dbt Wizard を、dbt platform(チャット・Studio)と Wizard CLI のそれぞれで試してみました。メタデータエンジンによってリネージを踏まえた影響範囲調査ができる点が、汎用のコーディングエージェントとの大きな違いだと感じました。
本記事の内容がどなたかの参考になれば幸いです。









