
「Aurora DSQLはサーバーレスアーキテクチャの常識を変えるのか」というタイトルでDevelopersIO 2025 Osakaに登壇しました #devio2025
リテールアプリ共創部@大阪の岩田です。
2025/9/3に開催されたDevelopersIO 2025 Osakaにて「Aurora DSQLはサーバーレスアーキテクチャの常識を変えるのか?」というテーマで登壇させて頂きました。
当日は持ち時間が20分しか無かったので色々と端折った部分があるのですが、その部分も含め改めて登壇内容を紹介させて頂きます。
サーバーレスアーキテクチャにおけるデータストアの選定
サーバーレスアーキテクチャにおけるデータストアの選定は悩ましい問題です。様々な選択肢が考えられますが、それぞれにメリット・デメリットが存在し、万能な解決策は存在しません。データストアに何を採用すべきか悩んだ経験をお持ちの方も多いのではないでしょうか。

このセッションでは代表的なデータストアとしてはDynamoDBとAuroraを挙げています。実際には他にも様々な選択肢が存在しますが、よく出てくる選択肢としてはこの2つかと思います。また、DynamoDBを利用する場合はDAXの有無やプロビジョンドキャパシティモード・オンデマンドキャパシティモードのどちらを使うかも検討が必要です。Auroraの場合もData APIを使うのか?RDS Proxyを挟むのか?Serverlessv2にするのかそれともProvisionedにするのか?なども検討するでしょう。最近だとLimitless Databaseなんていう選択肢も出てきましたね。もう少し深掘って考えてみましょう。
DynamoDB
まずDynamoDBです。

サーバーレスアーキテクチャにおけるファーストチョイスと言える選択肢です。VPC不要ですぐに利用開始でき、オンデマンドモードを利用すればアイドル時間に課金されることは無くなり、スケールアウトも自動でやってくれます。セキュリティパッチを適用するためのメンテナンスウィンドウなども管理する必要がなく、開発者をインフラの管理から解放してくれる、まさに「サーバーレス」を体現したようなデータベースです。
そんなDynamoDBですが、弱点としてはクエリが挙げられます。JOINや集計ができないため、開発者には検索要件に応じた高度なテーブル/インデックス設計が要求されます。あとから「やっぱりこういう検索要件を追加したい」と言われた時にテーブル設計を根本的に見直した経験のある方も多いのではないでしょうか。RDBであればALTER文でカラム追加してインデックスの定義を修正するだけで済むことが多いですし、テーブル設計が大きく変更になってもINSERT INTO ... SELECT ... FROM ...といったSQLスクリプトでマイグレーションできることもあります。DynamoDBだとこうはいきません。Glueを使うなど楽をする選択肢はありますが、それでもSQLのお手軽さには敵いません。
こうした検索の弱さを補うためにCQRSを導入することもあるでしょう。CQRSによって書き込みの耐久性と柔軟な検索の両方が手に入りますが、システム構成は複雑化し、書き込み用データベースと読み込み用データベースの両方に料金が発生します。読み込み用のデータベースにRDBを利用するのであれば、最初から書き込み用のデータベースもRDBにした方が良くないか?書き込み用のデータベースとして別途DynamoDBを用意するのはオーバースペックではないか?という葛藤も生まれます。
Amazon Aurora

DynamoDBの対抗馬になるのがAuroraに代表されるRDSです。※以後は全てRDS = Auroraとして扱います。
データストア単体で見た時の安定性・汎用性は抜群です。やっぱりSQLは便利ですよね。しかしサーバーレスアーキテクチャとの組み合わせにおいては考慮事項が必要です。AuroraにVPCが必要になるため必然的にLambdaもVPCにアタッチする必要があります。いわゆるVPC Lambdaですね。2019年にVPC Lambdaは改善され、以前はコールドスタート時に毎回発生していたENIの作成が無くなりました。この改善によってVPC Lambda × Auroraというアーキテクチャも現実的な選択肢となりましたが、それでもステートレスなLambdaとステートフルなAuroraは相性が悪いことに変わりはありません。ENIあたりの接続/ポート上限、DNSクエリの上限などにも注意が必要です。
また全ての操作がステートレスなDynamoDBのAPIとは異なり、Auroraに対する操作は「接続」を意識する必要があります。短命なコンピューティング環境が多数生まれては消えていくLambdaにおいて「接続」をどう管理するかは難しい問題です。
他にもDynamoDBがパーティションキーに基づいてワークロードを分散するのに対してAuroraはライターインスタンス1台が書き込みを担うため、大規模な書き込みが発生するワークロードにおいては書き込みがスケールアウトしないという課題もあります。そういえばAuroraのマルチマスタークラスターって実質もう使いない状態なんですね。
(参考)
Amazon Aurora × Data API
というわけでAuroraを利用するにあたっては追加の考慮事項が色々と発生します。まずはData APIについて考えてみましょう。

Data APIを使うとHTTPリクエストを介してステートレスにAuroraが操作できるようになります。Data APIの基盤側でよしなにコネクションプールを管理してくれるため、開発者が考えるべきことは減ります。とはいえ裏でAuroraが動いていることには変わらないので、BEGINしたトランザクションのトランザクションIDを管理してCOMMIT/ROLLBACKするのはアプリケーション側の責務として残ります。トランザクションIDを意識する必要があるという点においては通常のDBドライバ利用に比べると複雑さが増しますし、Data APIに対応したライブラリが無い場合はトランザクションIDを自前で管理する必要があります。
他にも色々な制約事項がありますが、ORMやクエリビルダのような各種ライブラリがData APIをサポートしているか次第で開発体験は大きく変わってきます。
(参考)
-
Aurora ServerlessのData APIは裏側でコネクションプーリングを実現してくれているという話 | DevelopersIO
-
Aurora ServerlessのData APIがプーリングするコネクション数について調べてみた | DevelopersIO
-
HIGOBASHI.AWS 第12回 活用編で「Aurora ServerlessのData APIについて」というテーマで話しました #higobashiaws | DevelopersIO
Amazon Aurora × RDS Proxy
Data APIとは別のアプローチでLambdaとAuroraの相性問題を緩和するのがRDS Proxyです。

最大同時接続数への抵触や接続リクエストがスパイクした時のDB過負荷に対する緩衝材としてRDS Proxyは有用なサービスです。しかしピン留めについて正しく理解した上で利用しないと、RDS Proxyを導入したものの実は全く有効活用できていなかったというケースも起こり得るため注意が必要です。実際に私も多くの失敗例を見てきました。ピン留めについてはPostgreSQLの拡張クエリプロトコルが対象外になったため以前と比べてかなり使いやすくなりましたが、それでもライブラリの仕様では必ずピン留めが発生し得ることに注意は必要です。
また、あくまでRDS ProxyはVPC Lambda × Auroraの相性問題を緩和するだけであって、Auroraの限界を超えた性能が引き出せるわけではありません。ロングトランザクションの有無など、ワークロードに依存してRDS Proxyがどこまで活躍できるかは変わってきます。あとはコストも気になるところですね。
(参考)
- RDS Proxyが拡張クエリプロトコルに対応し、ピン留めの発生条件が緩和されました | DevelopersIO
- そのRDS Proxyホントに必要?立ち止まって一度考えよう | DevelopersIO
- [動画公開] RDSプロキシは未来を変えるか #devio2020 | DevelopersIO
Amazon Aurora Serverless
コストの話が出たのでAurora Serverlessについても触れておきましょう。

オンデマンドモードのDynamoDBはサーバーレスのメリットである完全従量課金を体現したようなサービスです。それと比較すると利用度の有無によらず起動時間に対して課金が発生するAuroraはコスト的に不利になる場面が出てきます。従量課金でAuroraを使いたい場合はAurora Serverlessが選択肢になりますが、仕様を理解せぬまま採用してしまうと逆にコストが増えることもあるので注意が必要です。
最近ACUを0に設定できるようになりましたが、一時停止状態から再接続する場合は15秒以上かかることもあるので、それが許容できるのかは注意が必要です。
(参考)
Amazon Aurora PostgreSQL Limitless Database
DyanmoDBのようなNoSQLとAuroraを比較した場合、ネックになるのが書き込み処理です。Auroraは書き込みがライターインスタンスに集中するためスケールアウトできず、大量の書き込みが発生するようなワークロードでは書き込み性能が不足する可能性があります。この問題を解決してくれるのがLimitlessDatabaseです。

裏側で自動的にシャーディングしてくれるので、設計が適切であれば書き込み処理がLimitlessにスケールアウトしてくれるのが最大のウリです。しかし、3種類のテーブルの違いを意識した設計が要求される点には注意が必要です。
そして何より気になるのがコストです。気軽に検証できるようなコスト感ではないので、必然的に大規模環境向けの選択肢となります。
(参考)
- 【セッションレポート】Amazon Aurora Limitless Database 内部アーキテクチャ詳解 〜 スケーラビリティと高可用性の秘密 〜(AWS-40) #AWSSummit | DevelopersIO
- Amazon Aurora Limitless Databaseの3種類のテーブルの違い ~ Standard/Sharded/Reference ~ | DevelopersIO
- AWS、「Amazon Aurora PostgreSQL Limitless Database」を正式提供開始 | DevelopersIO
- Amazon Aurora Limitless Databaseの利用費を試算してみる | DevelopersIO
そこでAurora DSQL
ここまで見てきたようにデータストアの選定は悩ましい問題でサーバーレスアーキテクチャにおいては特にその傾向が顕著です。様々な選択肢にメリット・デメリットがあり万能の選択肢がありません。そこで登場したのがDSQLです。DSQLはPostgreSQL互換のサーバーレス分散 SQL データベースで、re:Invent 2024で発表された比較的新しいサービスになっています。

DSQLの開発には元々LambdaチームにいたMark Brooker氏が関わっており、Lambdaユーザーの要望に応えるためのデータベースとして開発された経緯があります。
(参考)
-
Building Global Applications with Amazon Aurora DSQL - YouTube
-
[新サービス] Aurora が真にサーバーレスでマルチリージョンに対応!リージョンを超えて強い一貫性を持つ Amazon Aurora DSQL が発表されました! | DevelopersIO
-
PostgreSQL互換な分散SQLデータベースのAmazon Aurora DSQLを公開情報から学んでみた | DevelopersIO
DSQLは「サーバーレス」
実際にクラスタを作ってみると分かるのですが、DSQLはまさに「サーバーレス」です。

良くも悪くも設定項目がほとんど存在せず、利用者がインフラを意識する必要はありません。メンテナンスウィンドウやバージョンアップグレードといった概念も存在せず、DynamoDBと同じ感覚でインフラをAWS任せにできます。これは従来のAuroraが成し得なかった体験です。
Aurora DSQLは従来のAuroraを置き換えるのか?
このように素晴らしいDSQLですが、従来のAuroraを(もっといえばDynamoDBも)完全に置き換える上位互換なのでしょうか?決してそうではなく、様々な制限事項が存在します。例えばですが、DB作成後にとりあえずpgbenchを流してみるとエラーになります。これはDSQLでは外部キーが使えないとか、TRUNCATE文が使えないことに起因するエラーです。このようにPostgreSQL互換と言いながらも互換性のない部分が多数存在します。「PostgreSQLと互換性がある」という表現は「PostgreSQLのワイヤプロトコルが利用できる」という意味合いで捉えておくのが良さそうです。

(参考)
- Aurora DSQLの制約を知ってより理解を深める | DevelopersIO
- Cluster quotas and database limits in Amazon Aurora DSQL - Amazon Aurora DSQL
制限事項についてもう少し掘り下げて考えてみましょう。
接続(コネクション関連)
接続関連には以下のような制限事項が存在します。
- 接続にはパスワードではなく一時トークンを利用
- クラスターあたりの最大接続レート 100 接続/秒
- クラスターあたりの最大接続バーストキャパシティ 1,000接続
- 接続のリフィルレート 100接続/秒
- クラスターあたりの最大接続数 10,000 接続
- 最大接続時間 60分
レートリミットやバーストキャパシティに関しては以下のブログで検証しています。
上記ブログの検証結果では25万リクエストのうち約6%で接続エラーが発生しており、2~3分程度で収束していました。
※登壇時の資料では56%としていましたが、これはLambdaのスケールアウトが追いつかずにAPI GW→Lambdaの呼び出しが失敗することによるエラーです。DSQLへの接続部分としては約6%のエラーでした。
この結果を受けてどう考えるかは人それぞれですが、個人的には十分な耐久性を持っていると感じました。古めのAWSアカウントであってもLambdaの同時実行数はデフォルトで1,000であり、Lambdaの上限緩和申請が不要なレベルのワークロードであればDSQLへの接続エラーは発生しないことになります。※もちろん変な実装をすれば話は別ですが。
注意しておきたいのは最大接続時間が60分に制限されていることです。これは従来のAuroraと大きく異なる点です。DSQL利用時に以下のような実装をしてしまうと60分の制限に抵触してしまいます。
//...略
const client = new Client({
//...略
});
await client.connect();
export const handler = async (event, context) => {
// クエリを発行する処理
};
詳細については別途以下のブログにまとめていますが、コネクションプールを活用して接続時間が60分に到達しないよう未然防止したり、エラー発生時に自動的に接続リトライさせたりといった対策が有効です。
トランザクション関連の考慮事項
続いてトランザクション関連の考慮事項です。主要なところでは以下のような制限事項があります。
| 項目 | 制限値 |
|---|---|
| トランザクションブロックで変更できるテーブル行とインデックス行の最大数 | 3,000 行/トランザクション |
| 書き込みトランザクションで変更されたすべてのデータの最大サイズ | 10 MiB |
| クエリオペレーションで使用できるメモリの基本最大量 | 128 MiB |
| 最大トランザクション時間 | 5分 |
単一のトランザクション内で大量データを操作するような処理は組めないと考えた方が良いでしょう。例えば月次の夜間バッチ処理で1ヶ月分のデータを集計して...といった処理には向きません。あとはDELETE→INSERTによるマスタデータの洗い替えなども実施できないと思った方が良いでしょう。
さらに重要なのが楽観的同時実行制御...つまりロックを取らないということです。在庫テーブルから在庫を引き当てて受注データにデータを登録するようなトランザクションを例に考えてみましょう。通常のAuroraであれば以下のような動作になります。

1つ目のトランザクションがSELECT FOR UPDATEで在庫のレコードをロックしているので、2つ目のトランザクションはロックが開放されるのを待ちます。その後1つ目のトランザクションがコミットされると2つ目のトランザクションがロックを取得できるので後続処理が流れていきます。
DSQLの場合はこうなります。

2つ目のトランザクションのSELECT FOR UPDATEはロック待ちにならず、後続処理はそのまま進んでいきます。そしてコミットのタイミングで初めてエラーが発生します。この辺りの同時実行制御は通常のAuroraと大きく異なるので注意が必要です。別の例としては以下のようなケースを挙げています。

トランザクション内で外部サービスのAPIを利用した処理を行い、その外部APIの処理済みフラグをDBで管理するような設計です。先にUPDATEを完了させておいて、外部APIの呼び出しが成功すればあとはコミットするのみ!という流れでSQLを実行していきます。通常のAuroraであればコミットに失敗する可能性は限りなく低いですが、DSQLではコミットに失敗するというのは普通に起こり得ることなので、こういった設計を採用する場合は注意が必要です。まあ外部APIの呼び出しはレイテンシが大きくなるのでトランザクション中にやるべきではないとか、処理済みフラグを管理するようなトランザクションが別トランザクションと競合するのか?といった疑問もあるかもしれませんが、楽観的同時実行制御においてはコミット時の競合エラーが普通に発生し得るということを意識しましょう。楽観的同時実行制御については以下のブログでも色々と解説されています。
改めてまとめると、楽観的同時実行制御ではコミット時のエラーが発生し得ることを考慮し、コミット時のエラーハンドリングや必要に応じたリトライを必ず実装しましょう。また、SELECT FOR UPDATEと違ってどのテーブルに対する操作で競合が発生したのか判断できない点にも注意が必要です。OC000というエラーコードからはどの操作が何と競合したのかが分からないので、アプリケーションからユーザーに対して操作の競合をフィードバックする際はエラーメッセージにも考慮必要です。
コストはどうなる?
少し視点を変えてコストについても考えてみましょう。東京リージョンでDSQLを利用する場合の料金体系は以下の通りです。
- DPU:$10.00/100万ユニット
- ストレージ:$0.40/GB-月
- データ転送料金: EC2データ転送料金
- Warmバックアップストレージ: $0.12/GB-月
- Coldバックアップストレージ: $0.036/GB-月
- Warmバックアップリストア: $0.024/GB
- Coldバックアップリストア: $0.0036/GB
通常のAuroraのようにインスタンス単位の課金は発生しません。同じくインスタンス単位の課金が存在しないDynamoDBの類似項目は以下のような料金体系です。
-
書き込み要求単位 (WRU): $0.89/100万
-
読み出し要求単位 (RRU): $0.178/100万
-
ストレージ料金(Standardテーブルクラスの場合): $0.285/GB-月
-
データ転送料金: EC2データ転送料金
-
ウォームバックアップストレージ: $0.114/GB-月
-
コールドバックアップストレージ: $0.0342/GB-月
-
ウォームバックアップストレージからのリストア: $0.171/GB
-
コールドバックアップストレージからのリストア: $0.228/GB
似たような項目が並んでいますが気になるのは「DPU」という聞き慣れぬ項目ですね。

DPUは作業量を表す論理的な指標で以下の要素とその合計値であるTotalDPUの5種類が存在します。
- ReadDPU
- WriteDPU
- ComputeDPU
- MultiRegionWriteDPU
このDPUについてはDynamoDBのRequest Unitのように試算できるものではないため、実際にワークロードを流してみた結果を元に試算するしかないと思います。ということでいくつかのパターンでSQLを実行し、メトリクスからDPU消費を確認してみました。詳しくは以下のブログでも解説しています。
まず10万レコードスキャンしてMAX値を取得する処理です。
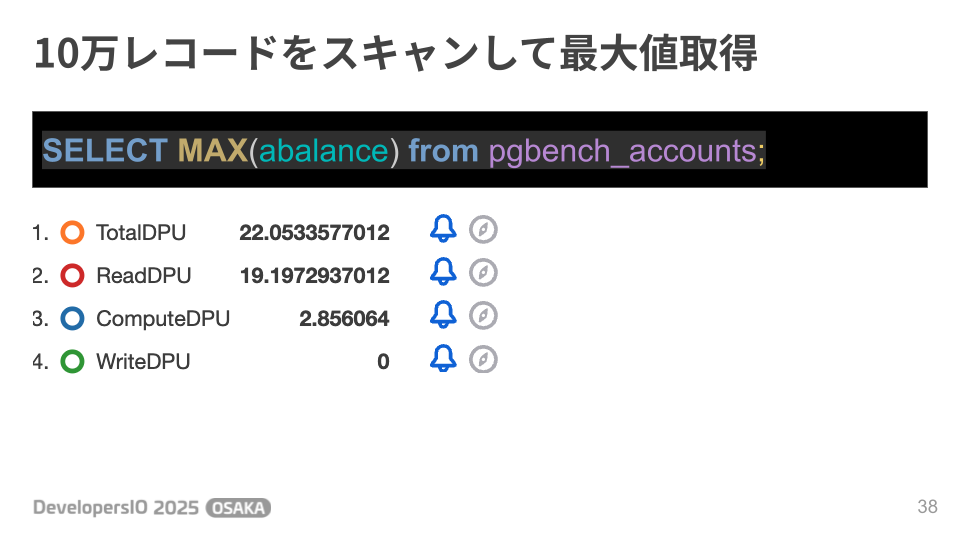
ReadDPUが約19、TotalDPUは約22という結果になりました。ざっくり計算すると19 / 10万で1件の読み取りに0.00019ReadDPUということになります。※実際にはページ単位でDPUを消費するような気はしますが。
取得した10万レコードから最大値を取得するためのソート処理等必要になりますが、ComputeDPUは約2.8の消費でした。
続いてSQLを少し変更し、MAX値を取得する対象を主キーに変更してみました。こちらはクラスタインデックスを降順に辿って1件取得するだけでMAX値を取得できるので効率的なアクセスパスとなります。そうそう、DSQLはPostgreSQL互換ですがストレージレイヤではPostgreSQLとは異なりクラスタインデックスに行データを格納します。ここに関してはMySQLの方が近いですね。
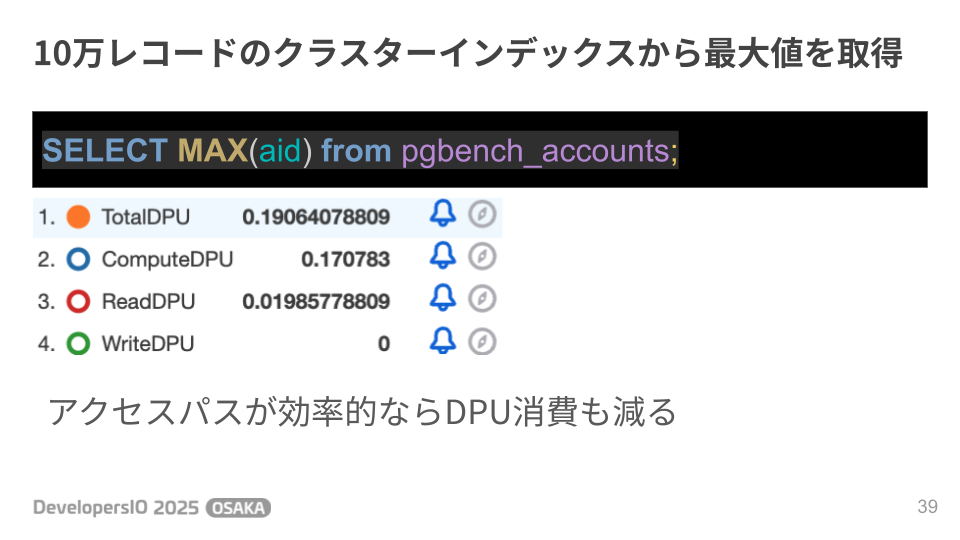
DPU消費の実績を見るとReadDPUは約0.02、ComputeDPUも約0.17まで減少していました。良いSQLを書けばその分DPU消費が減ってコストも減る。SQLの改善が即コストに反映されるのはゲーム感覚で楽しめそうですね。
続いて別パターンの検証です。
CTEで100万レコード生成してから最大値を取得してみました。
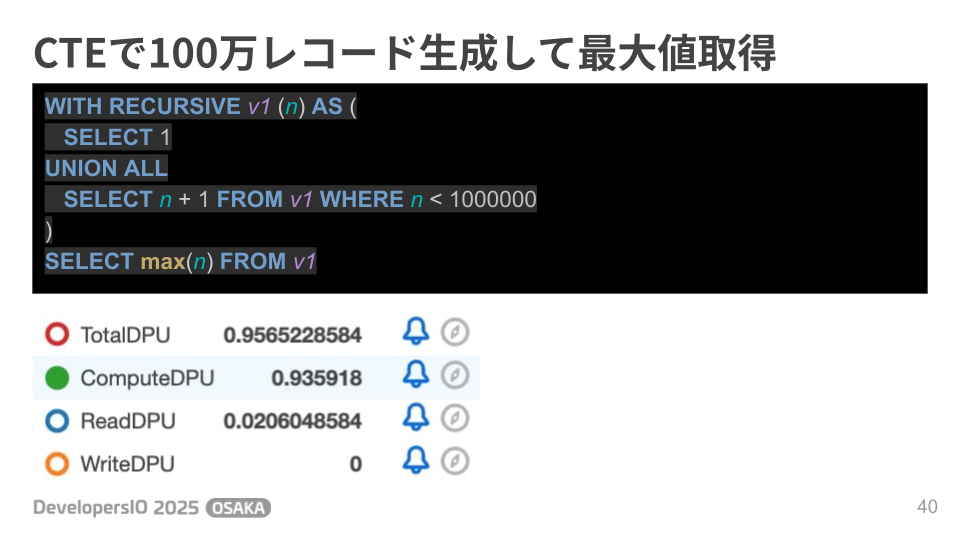
テーブルのデータにはアクセスしていないのでReadDPUは約0.02と低い値でしたが、ComputeDPUに関しては約0.93消費しています。
次はCROS JOINで100万レコード生成してみます。テーブルから100件のレコードを取得するサブクエリを3回実行し、取得した100件のデータをCROSS JOINで100万レコードまで増殖させます。
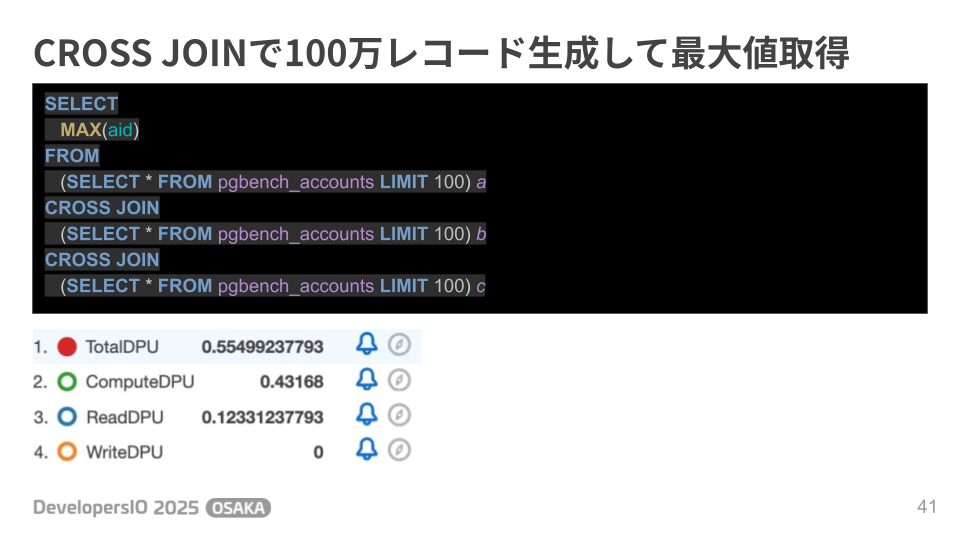
今度は実際にテーブルのデータを読み込んでいるのでReadDPUの消費が約0.12まで増えました。先ほどのざっくり計算で算出した0.00019ReadDPU/1件を使って試算すると0.057DPUになるので全然外れてますね。具体的なページサイズがどうとかDSQLの内部的なアーキテクチャが分かっていないと正確な見積もりは出せなさそうですね。そしてReadDPUが増えたのに対してComputeDPUは約0.43と先ほどのパターンよりは減少しています。何の違いが影響しているんでしょう?色々妄想してみるのも楽しそうです。
これまで見てきたのは全て読み取り処理でしたが、最後に書き込み処理も確認しておきましょう。pgbenchのテスト用テーブルの中身約10件をpg_dumpでバックアップしてpsqlからリストアした時のDPU消費は以下の通りでした。DSQLではCOPYが使えないのでpg_dumpはINSERT分の形式で取得しています。
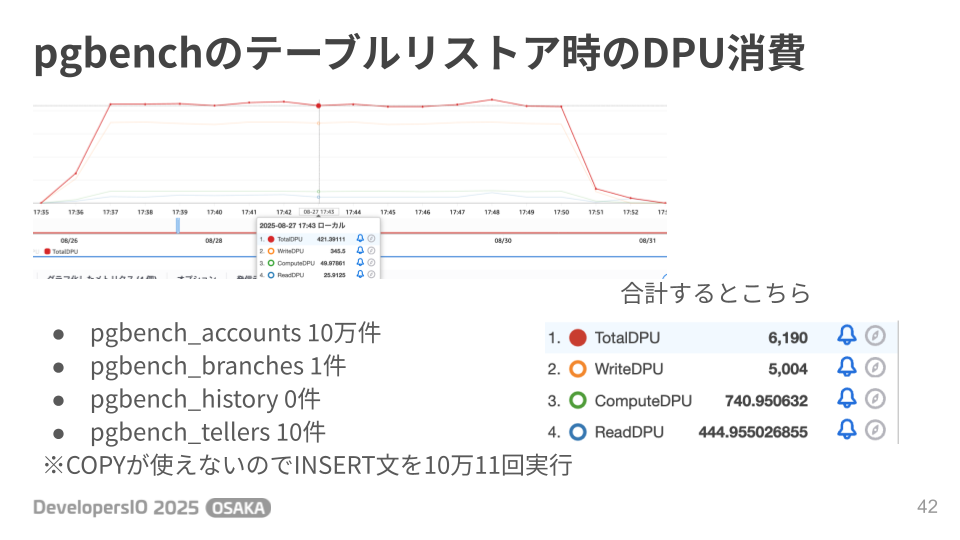
Total DPUとしては6,190なので、コスト試算としては(6190DPU / 100万DPU) × $10= $0.0619となります。オンデマンドモードのDynamoDBに置き換えて考えると(10万WRU / 100万WRU) × $0.715 = $0.0715となり、DSQLの方が安いということになります。※テスト用のレコードをDynamoDBのアイテムに置き換えて考えるとサイズは1K以下なので1アイテムにつき1WRU消費の試算
実際にはテーブル定義やレコードのサイズによってDPUの消費が変わってくるので、DSQLの方がDynamoDBより安いと一概に言えるものではありませんが、コスト的にDynamoDBより大きく不利になるということは無いように思います。
(参考)
その他気になるところ
その他気になるトピックです。
まず開発時のデータベースはどうやって用意すれば良いのでしょう?

Auroraを採用する場合、ローカル環境ではMySQL/PostgreSQL on Dockerを利用することも多いですが、DSQLの場合はやめておいた方がよいでしょう。DSQLとPostgreSQLで互換性の無いSQLが多いためです。DynamoDBであればLocal StackやDynamoDB localという選択肢もありますが、DSQLにはそういったエミュレーターが存在しないので普通にAWS上にDSQLのクラスタを立ち上げてローカルマシンから接続するのが良いでしょう。ただし、良くも悪くも従量課金なので大量データをスキャンするようなクエリを試行錯誤する場合などは注意が必要です。
実際のアプリケーション開発を考えるとDBスキーマのマイグレーションも気になるところです。
以下のブログでも紹介されていますが、通常のPostgreSQLを同じ感覚でマイグレーションツールを使おうとすると....失敗します。DSQLではSERIAL等の型が使えないためです。
上記ブログはdrizzleの例ですが、他のツールでも大体似たような状況のようです。色々と検索してみましたが、私が探した範囲ではDSQLでも問題なく動作するマイグレーションツールは見つかりませんでした。もしDSQLにも対応したツールをご存知の方がいればぜひ教えてください。
まとめ
これまで色々と考察してきましたが、結局のところDSQLはどのようなユースケースで使うべきなのでしょうか?実は公式ドキュメントに書いてあります。

「マイクロサービス、サーバーレス、イベント駆動型アーキテクチャのアプリケーションパターンに最適」とのことです。逆説的に考えると、モノリスなアプリケーションに適しているとはどこにも書いていません。モノリスなアプリケーションの新規開発にDSQLを採用したり、既存のモノリスなアプリケーションのデータストアを通常のAuroraからDSQLに移行したり、といったことはやめた方が良いでしょう。近年はモノリスが悪であるかのような意見を聞く機会もあるのですが、モノリスにはモノリスの良さがあります。モノリスが適しているユースケースではDSQLを使用せずモノリスな構成を使うのが良いでしょう。教科書的な話になりますが、結局のところ銀の弾丸は存在せず何事も適材適所ですね。ということで本セッションでは以下のように結論づけさせて頂きました。
- DSQLは他のデータストアの上位互換ではない
- 良いサービスであることに間違いは無いが、あくまで選択肢の1つ
- 制限事項について良く理解した上で採用しよう
(参考)
登壇資料
登壇資料はこちらです








