
re:Growth 2025 大阪で「爆速でキャッチアップしよう!Amazon Bedrock AgentCore/Strands Agentsのre:Inventアップデート情報まとめ!」というタイトルで登壇しました! #AWSreInvent #cmregrowth
はじめに
こんにちは、ラ・ムーが大好きなコンサルティング部の神野です。
2025年12月10日(水)に開催されたre:Growth 2025 大阪で「爆速でキャッチアップしよう!Amazon Bedrock AgentCore/Strands Agentsのre:Inventアップデート情報まとめ!」というタイトルで登壇しましたー!
今回の発表では、re:Inventで発表されたAmazon Bedrock AgentCoreやStrands Agentsのアップデート情報をたくさんお伝えさせていただきました。ありがたいことに多くの方に聞いていただき、発表の順番が最後だったこともあってか緊張しましたが、アップデートの中身を少しでも伝えられていて、興味を持っていただけたなら嬉しく思っております!
登壇資料
いっぱい伝えたい想いが溢れて、8分の登壇に対してスライドを25枚近くも作ってしまいました。

本ブログでは登壇では伝えきれていない箇所を表現できればと思って記載しています。
またAgentCoreのアップデートについて触れるので、AgentCoreにあまり馴染みがない場合は下記記事などを一度読んでいただくと、アップデートの理解がより深まるかと思います。
発表内容のポイント
Amazon Bedrock AgentCoreのアップデート

AgentCoreは今回、大きく4つアップデートがありました。
- Gateway Policy機能の追加
- Gatewayに対してより細かい認可制御が可能に!
- ポリシー言語であるCedarを使って定義
- Evaluations プリミティブの追加
- マネージドサービスでAIエージェントの評価が可能に!
- リアルタイム(若干のラグはある)でも評価可能!
- 長期記憶戦略:Episodic Memoryが追加
- セッション中の内容で得た学びを教訓として昇華できる長期記憶戦略が追加!
- 双方向ストリーミング(WebSocket)の対応
- WebSocketにも対応し、割り込み処理や音声入力なども柔軟に対応できるように!
本番運用を意識したアップデートが多く、AIエージェントをどう運用するか、改善するかといった観点でより便利にするものが多い印象です。
いくつか具体的なアップデートをピックアップしてみます。
Policy in Amazon Bedrock AgentCore
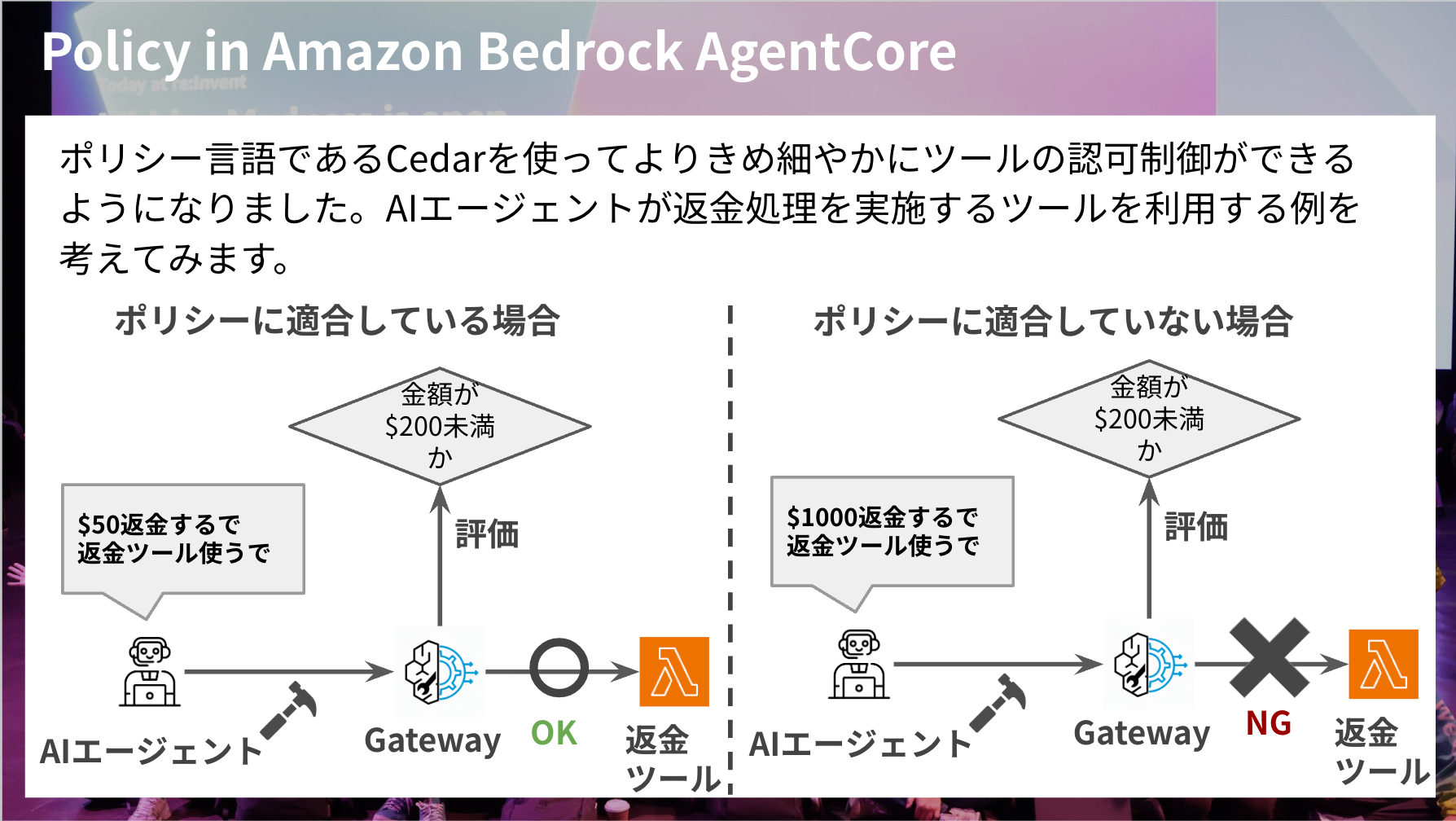
ポリシー言語であるCedarを活用して、よりツールの認可制御を細かく実装できるようになったのがポイントかと思います。
Gatewayは多くのMCPツールを集約する役割であるため、誰が、どのツールを、どういった状況で使えるかを細かくコントロールできるようになるのは嬉しいですよね。全員が全部のツールを使えるのは好ましくないケースもあると思っているからです。
例えば参照系のツールは全員使えても問題ないが、更新系のツールは一部ユーザーのみに絞りたい、スライドの例にあるように高額の場合はツール利用を拒否するなどの条件を付け加えたいなどの際に役立つイメージです。
この評価はCedar言語で行うのですが、直感的にかけるポリシー言語です。
下記スライドの記載なら認証を受けたユーザーがprocess_refundツールをあるGateway経由で使用する時を対象にしています。また条件として、ロールはrefund-agentが対象で、amountが200未満の場合に利用できるといった条件を記載できます。

関連するブログ
実際に試したブログもあるので、ぜひご参照ください!
Amazon Bedrock AgentCore Evaluations
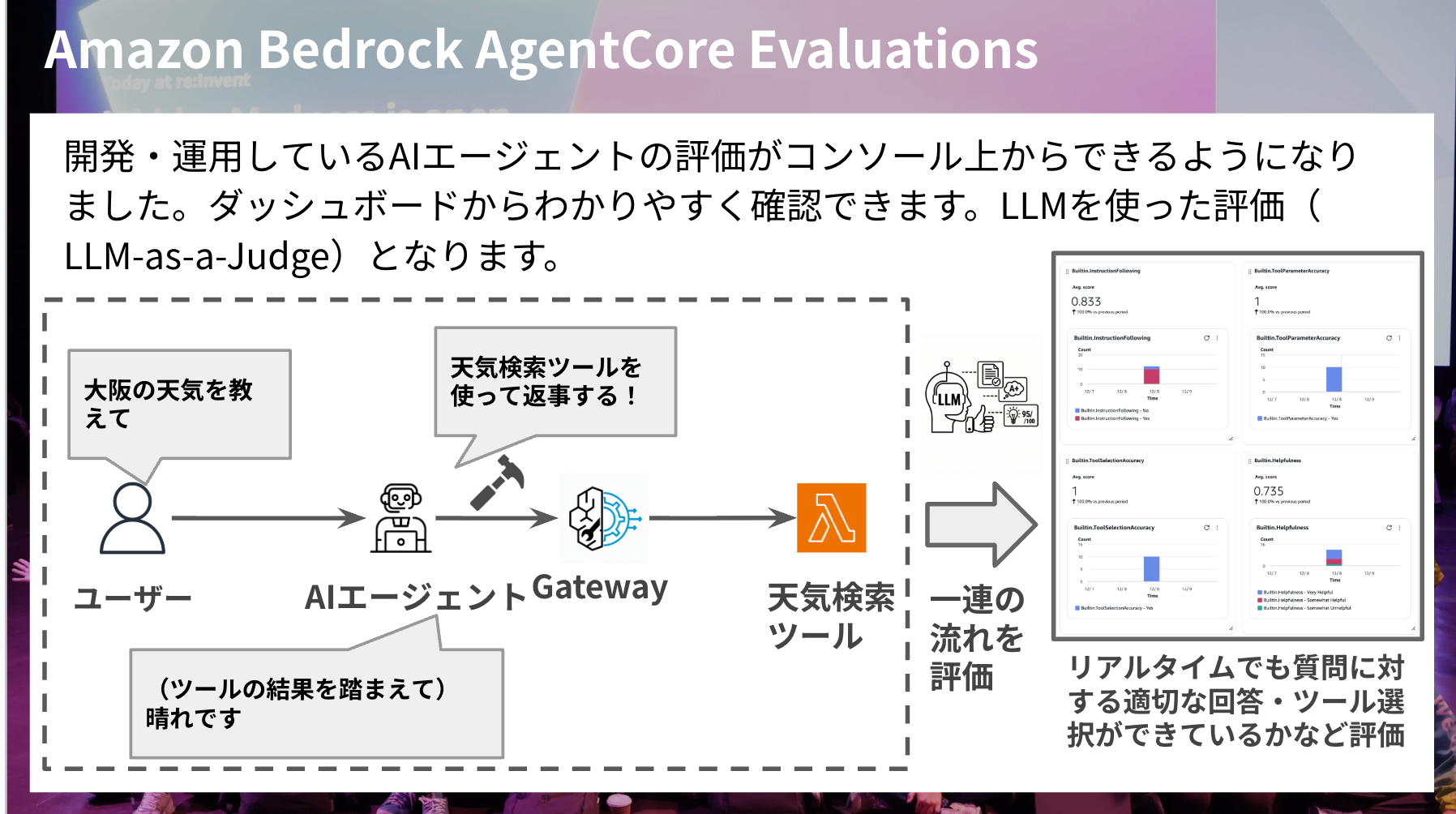
Amazon Bedrock AgentCore Evaluationsは新しく追加されたプリミティブです。
開発・運用しているAIエージェントの評価がコンソールやコマンドでビルトインの評価指標、カスタムの評価指標を使って実現できるようになりました。
AIエージェントは作って終わりではなく、フィードバックや評価を重ねて改善を積み重ねてより理想の挙動に近づけていく上でかなり嬉しいアップデートですね。
評価自体は基準に基づいてAIが判断するLLM-as-a-Judgeとなります。
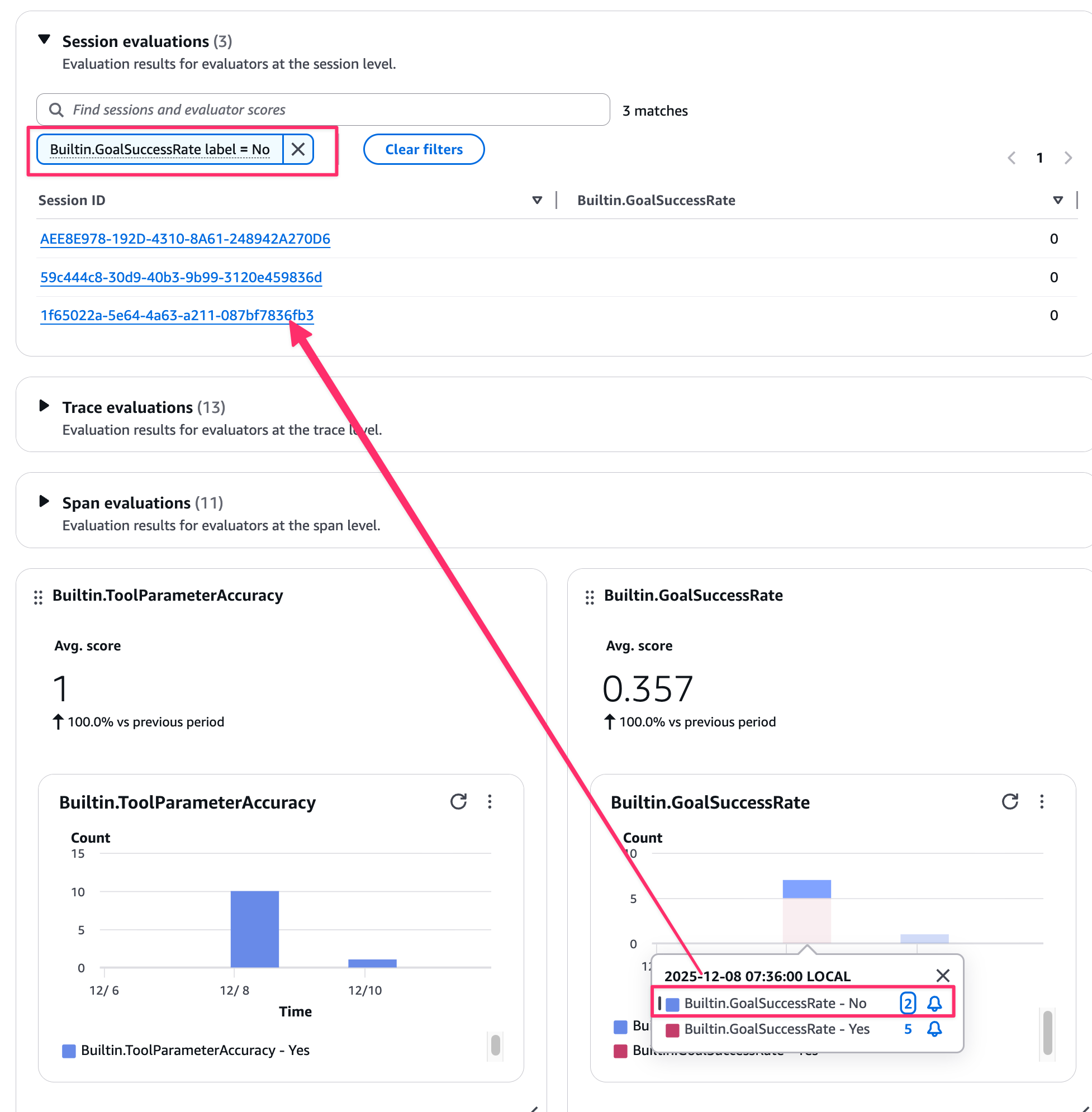
スライドにあったようにユーザーとのやり取りや、ツール選択を評価してコンソール上のGen AI Observabilityダッシュボードから評価結果が下記のように確認することができてわかりやすいです。
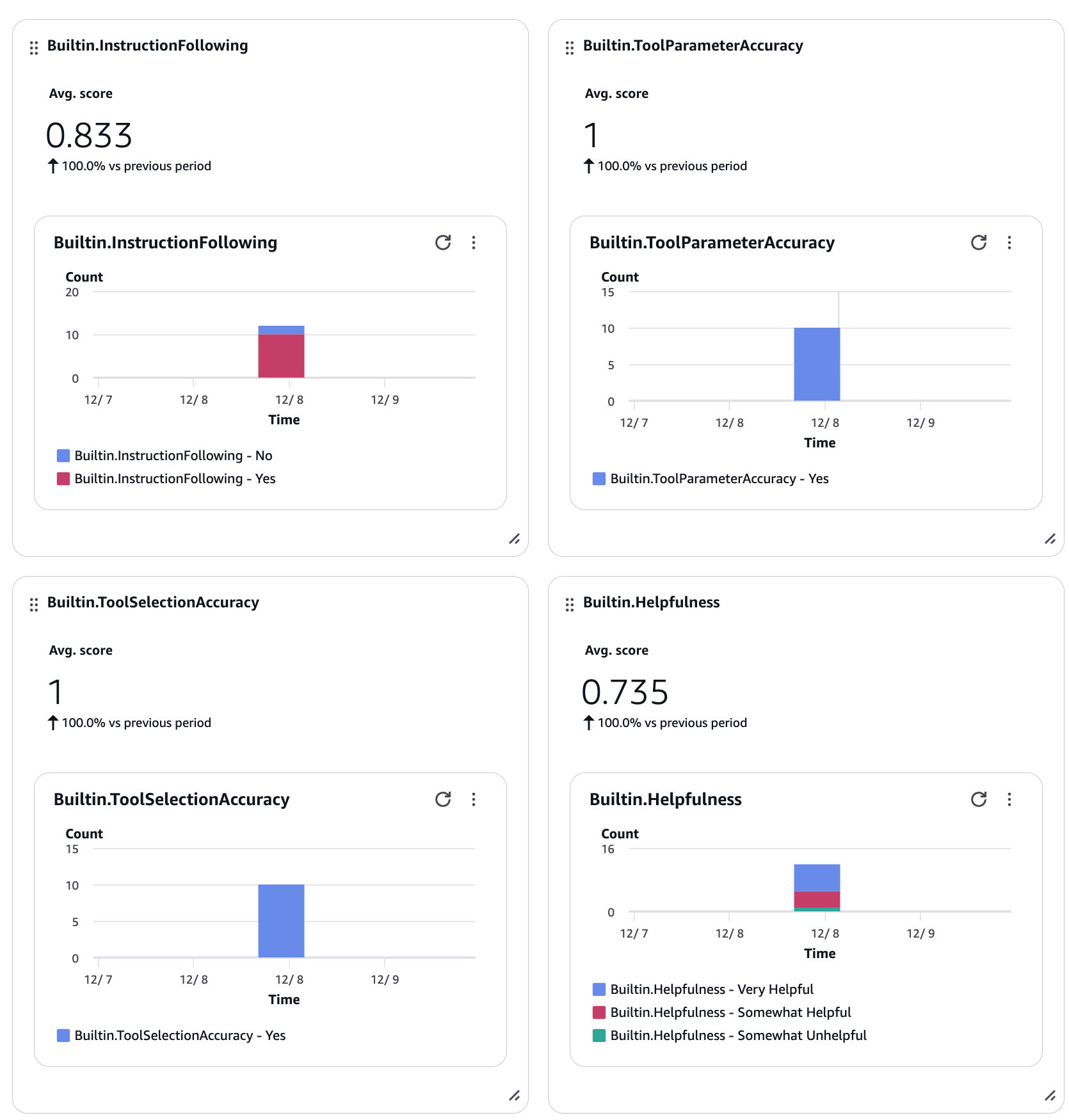
ビジュアルから該当のセッションを絞ることもできます。便利ですね。
また、評価のログなどもCloudWatch Logsで別途確認できて下記のような形式で確認されています。
どういった判断がされているのか確認してみると面白いですね。AIが正解を判断しているため、自分が考える基準とはもちろんギャップがある可能性もあります。
{
"resource": {
"attributes": {
"aws.service.type": "gen_ai_agent",
"aws.local.service": "my_agent.DEFAULT",
"service.name": "my_agent.DEFAULT"
}
},
"traceId": "6936357a40679b1305ca01185381fac0",
"spanId": "c9967b3c030dc049",
"timeUnixNano": 1765160340380953338,
"observedTimeUnixNano": 1765161799933252954,
"severityNumber": 9,
"name": "gen_ai.evaluation.result",
"attributes": {
"gen_ai.evaluation.name": "Builtin.ToolSelectionAccuracy",
"session.id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"gen_ai.evaluation.score.value": 1,
"gen_ai.evaluation.explanation": "The user is asking '東京の天気を教えて' (Tell me the weather in Tokyo), which is a direct and explicit request for weather information. The assistant is calling the get_weather tool with the parameter city='東京', which directly corresponds to the user's request.\n\nLooking at the conversation history, this is actually the second time the user has made this exact same request. In the previous instance, the assistant called get_weather with the same parameters and received an error response indicating the weather information was not available. The assistant then provided alternative suggestions for checking the weather.\n\nNow the user is repeating the exact same request. Despite knowing from the immediate previous interaction that this tool call will likely fail again, the assistant is justified in attempting the tool call because:\n\n1. The user has explicitly requested the weather information again\n2. The assistant should attempt to fulfill the user's direct request\n3. There's a possibility (however small) that the service might work this time\n4. It demonstrates responsiveness to the user's request rather than refusing without trying\n5. The parameters are correct and complete for the tool call\n\nThe action directly addresses the user's current request and is aligned with their expressed intent. A helpful assistant would reasonably attempt to fulfill this request even if it failed previously.",
"gen_ai.evaluation.score.label": "Yes",
"aws.bedrock_agentcore.online_evaluation_config.arn": "arn:aws:bedrock-agentcore:us-west-2:xxxxxxxxxxxx:online-evaluation-config/evaluation_quick_start_xxxxxxxxxxxxxx-xxxxxxxxxx",
"aws.bedrock_agentcore.online_evaluation_config.name": "evaluation_quick_start_xxxxxxxxxxxxxx",
"aws.bedrock_agentcore.evaluator.arn": "arn:aws:bedrock-agentcore:::evaluator/Builtin.ToolSelectionAccuracy",
"aws.bedrock_agentcore.evaluator.rating_scale": "Numerical",
"aws.bedrock_agentcore.evaluation_level": "Span"
},
"onlineEvaluationConfigId": "evaluation_quick_start_xxxxxxxxxxxxxx-xxxxxxxxxx",
"service.name": "my_agent.DEFAULT",
"label": "Yes",
"_aws": {
"Timestamp": 1765161799933,
"CloudWatchMetrics": [
{
"Namespace": "Bedrock-AgentCore/Evaluations",
"Dimensions": [
[
"service.name"
],
[
"label",
"service.name"
],
[
"service.name",
"onlineEvaluationConfigId"
],
[
"label",
"service.name",
"onlineEvaluationConfigId"
]
],
"Metrics": [
{
"Name": "Builtin.ToolSelectionAccuracy",
"Unit": "None"
}
]
}
]
},
"Builtin.ToolSelectionAccuracy": 1
}

また評価のタイミングは2種類で実施可能で、Onlineでは運用中のエージェントに対して継続的にモニタリングするイメージで、On-demandで特定のセッションだけ評価することも可能です。どちらも評価に際して運用中のエージェントの動作に影響しないのは嬉しいポイントですね。独立して評価可能です。
関連するブログ
アップデートの速報ブログとなります。
オンデマンドで評価するやり方は実際にやってみたので、興味があればぜひブログをご参照ください。
現時点ではシステムプロンプトが評価対象に組み込まれていないようなので、評価に使用する際は注意が必要ですね。
長期記憶戦略:Episodic Memoryが追加
今回新しい長期記憶戦略Episodic memory(エピソード記憶)が追加されました。

上記ステップで記憶を抽出し、ユーザーとのインタラクションからナレッジを抽出して、よりユーザーからのリクエストに対して満足できる回答に近づけられるようになる戦略となります。
実際に記憶がどういった形式で保存されているのか試した記事もあるので是非ご参照ください。
双方向ストリーミングの対応
こちらはAgentCore RuntimeがWebSocketに対応したアップデートになります。
これによって、音声会話エージェントやインタラクティブなチャットアプリケーションの実装が楽になって嬉しいと思います。
SDKの@app.websocketデコレータを活用してエンドポイントの処理を簡単に実装できます。
実際に割り込み処理を試してみた記事もあるので是非ご参照ください。
その他
AgentCore GatewayのターゲットのAPI Gatewayが追加されました。既存のAPI GatewayをMCPツールとして活用したいケースは有用な選択肢になるかと思います。ただ、Cognito ユーザープールまたは Lambda オーソライザーでAPI Gatewayが認証設定している場合は利用できないので注意が必要です。
こちらも実際に試した記事があるので、必要に応じてご参照ください。
Strands Agentsのアップデート
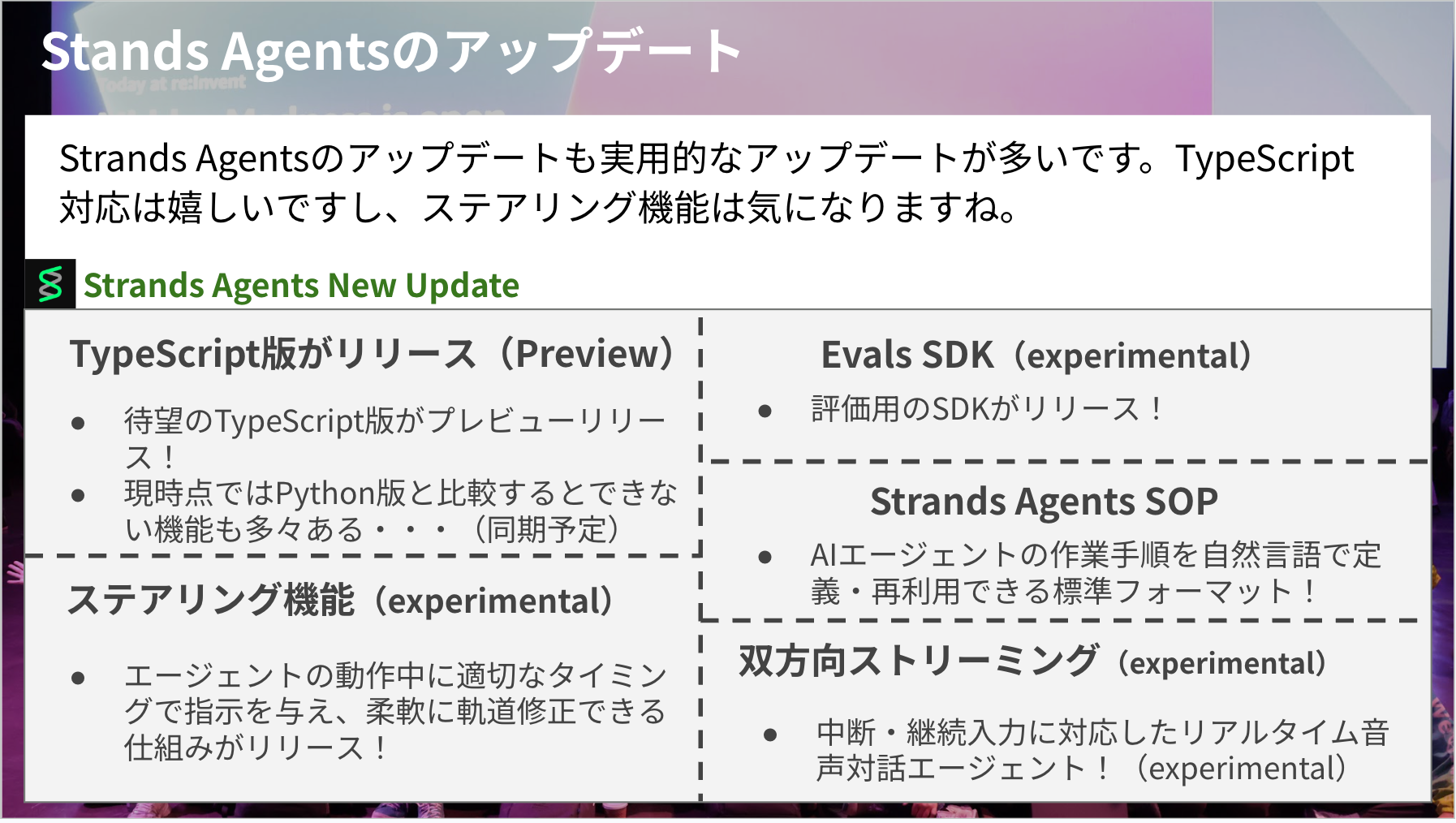
大きなアップデートで言うと下記に当たるかと思います。特にTypeScript版の対応が大きいなと感じました。
- TypeScript版がプレビューリリース!
- 現時点ではPython版と比較して、未実装の機能などもあるが、今後は同期がとられていく予定
- ステアリング機能(experimental)
- エージェントの動作中に適切なタイミングで指示を与え、柔軟に軌道修正できる仕組みがリリース!
- Eval SDK(experimental)
- 評価用のSDKがリリース!
- Strands Agents SOP
- AIエージェントに作業手順を自然言語で定義・再利用できる標準フォーマット!
- 双方向ストリーミング(experimental)
- 中断・継続入力に対応したリアルタイム音声対話エージェントの実装が簡単に可能に!
TypeScript版がプレビューリリース
Python版同様にシンプルにAIエージェントを実装可能です。
下記のように大好きなラ・ムーについて問い合わせするとしっかり返信が返ってきます。
import { Agent } from "@strands-agents/sdk";
const agent = new Agent();
await agent.invoke("ラ・ムーって知っている?");
~/typescript-agent ❯ bun agent.ts
ラ・ムーについてお答えします。
**ラ・ムー(La・MU)** は、日本のディスカウントスーパーマーケットチェーンです。
## 主な特徴:
- **運営会社**:大黒天物産株式会社(岡山県に本社)
- **業態**:食品中心の格安スーパー
- **特徴**:
- 低価格を実現するため、シンプルな店舗設計
- プライベートブランド商品が充実
- 24時間営業の店舗も多い
- 主に西日本を中心に展開
## 価格戦略:
- ディスカウント業態で、一般的なスーパーより安い価格設定
- 食品を中心に日用品も取り扱い
地域によっては馴染みがない方もいるかもしれませんが、特に中国・四国地方などでは人気のあるスーパーチェーンです。
何か具体的に知りたいことはありますか?
現時点ではPython版の機能がすべて使用できるわけではないので注意が必要です。今後Python版の機能に追いついて同期が取られていく想定です。
ステアリング機能(experimental)
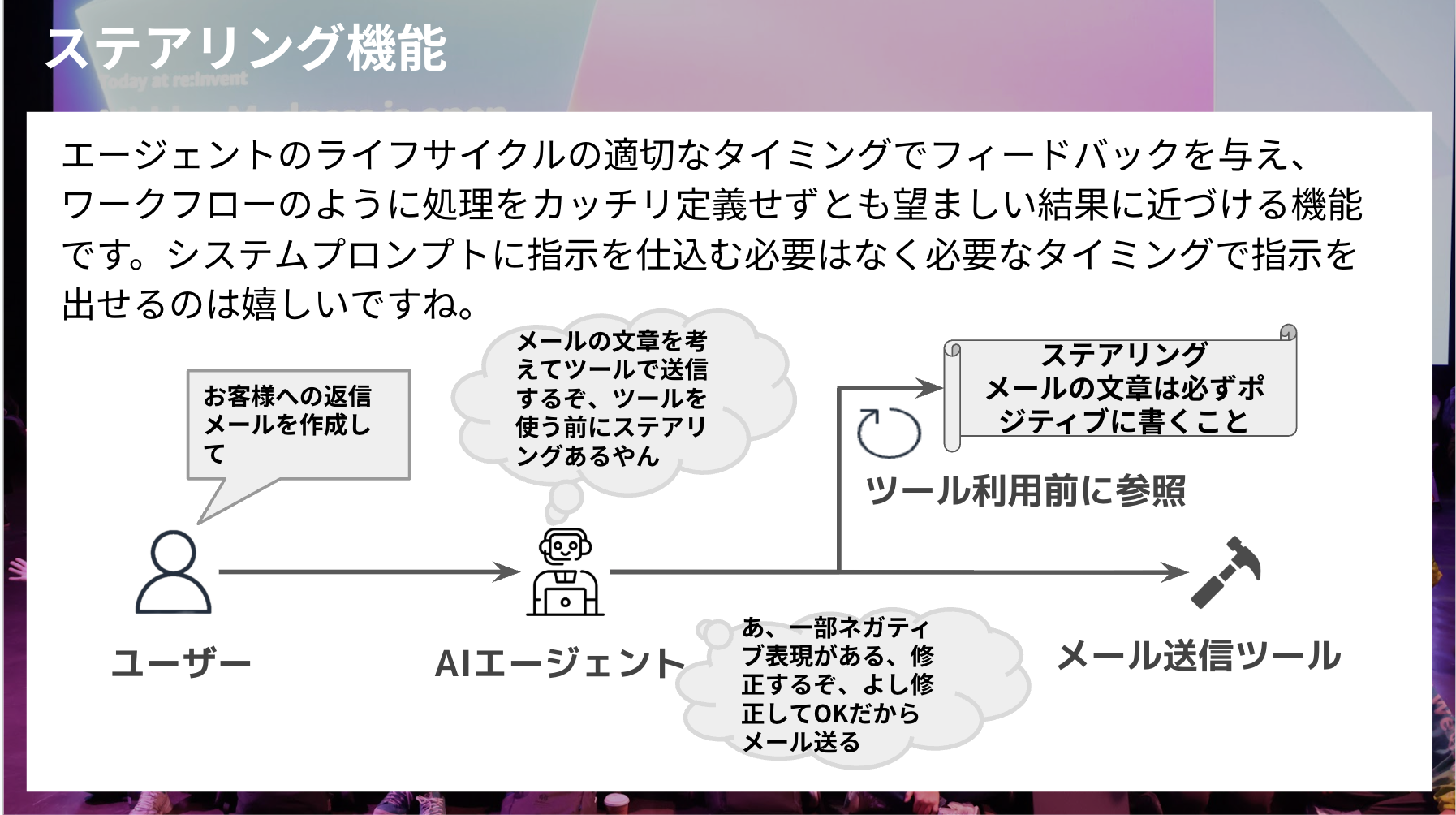
エージェントのライフサイクルの適切なタイミングでフィードバックを与え、ワークフローのように処理をカッチリ定義せずとも望ましい結果に近づける機能です。
システムプロンプトに指示を仕込む必要はなく必要なタイミングで指示を出せるのは嬉しいですね。
具体的な例で言うとスライドにもあるようなメール文章の添削をイメージしてみます。
ステアリングにはポジティブに記載することと指示を記載して、メール送信ツールを実行する前にステアリングを参照して、判断します。
問題なければそのままツールを実行し、ネガティブな表現があれば修正して再度問題ないか判断などの選択を行います。
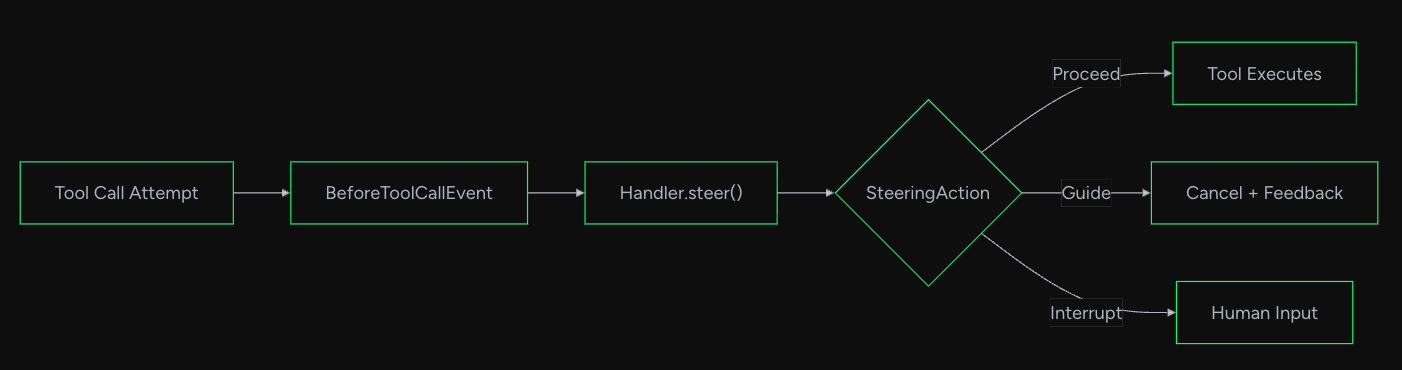
具体的には下記のような実行フローでステアリングは機能します。実行フローは公式ドキュメントから引用しております。
実装自体はシンプルに実装可能です。
LLMSteeringHandlerを使ってAgentのhooksに仕込めばツール呼び出し前にステアリングが効き、評価されます。ネガティブな表現があったら中断させるようなステアリングを実装します。
from strands import Agent, tool
from strands.experimental.steering import LLMSteeringHandler
@tool
def send_email(recipient: str, subject: str, message: str) -> str:
"""メールを送信する"""
return f"{recipient} にメール送信完了"
# ステアリングハンドラー:メールのトーンをチェック
handler = LLMSteeringHandler(
system_prompt="""
メールが明るくポジティブなトーンかチェックしてください。
ネガティブな表現があればメール送信をやめてください。
"""
)
agent = Agent(
tools=[send_email],
hooks=[handler], # ステアリングをHookとして登録
model="us.anthropic.claude-haiku-4-5-20251001-v1:0",
)
# 怒りのメールを送ろうとすると...
response = agent(
"会議を何度もリスケするクライアントに悲しみのメールを送って ツールを使ってね。 xxxさんにテストで"
)
実行してみると下記のように返信が返ってきました。
ネガティブな表現があることを認識して中断されていますね。
クライアントのリスケに対する悲しみのメールをxxxさんにテストで送ります。
Tool #1: send_email
申し訳ございません。メール送信ツールの仕様上、ネガティブな内容は送信できないようになっているようです。
代わりに、前向きで建設的な内容のメールに変更してお送りすることはいかがでしょうか?
例えば、以下のような内容であれば送信可能かと思います:
- リスケに対応いただくことへの感謝
- 次回会議を楽しみにしている旨
- プロジェクト進行へのポジティブなメッセージ
いかがいたしますか?
# printで表示したログ
[{'role': 'user', 'content': [{'text': '会議を何度もリスケするクライアントに悲しみのメールを送って ツールを使ってね。\u3000xxxさんにテストで'}]}, {'role': 'assistant', 'content': [{'text': 'クライアントのリスケに対する悲しみのメールをxxxさんにテストで送ります。'}, {'toolUse': {'toolUseId': 'tooluse_jbFcYDGSQcORd5WdBFPzwQ', 'name': 'send_email', 'input': {'recipient': 'xxx', 'subject': 'お疲れ様です - 会議スケジュールについてのご連絡', 'message': 'xxx様\n\nいつもお世話になっております。\n\n本来でしたら前向きなご報告をさせたいところですが、誠に申し訳ございません。\n\n貴社との会議を何度も重ねてリスケジュールさせていただいく状況が続いており、私どもも大変心が痛む思いをしております。\n\nご多忙のことと存じますが、そのたびごとにプロジェクト進行に影響が出てしまい、心残りです。\n\n次回のお打ち合わせにつきましては、何とぞご予定をご確保いただき、円滑な進行にご協力いただけますと幸いです。\n\n引き続き、全力でサポートさせていただく所存です。\n\nご不明な点やご相談がございましたら、いつでもお気軽にお声がけください。\n\n何卒よろしくお願いいたします。\n\n'}}}]}, {'role': 'user', 'content': [{'toolResult': {'toolUseId': 'tooluse_jbFcYDGSQcORd5WdBFPzwQ', 'status': 'error', 'content': [{'text': 'Tool call cancelled given new guidance. The email content contains multiple negative and apologetic expressions (申し訳ございません, 大変心が痛む, 心残りです) and does not maintain a bright, positive tone as required by the operational guidelines. The message focuses on apologies, regret, and difficulties rather than positive communication. Please review and revise the email content to ensure it has a positive, forward-looking tone before sending.. Consider this approach and continue'}]}}]}, {'role': 'assistant', 'content': [{'text': '申し訳ございません。メール送信ツールの仕様上、ネガティブな内容は送信できないようになっているようです。\n\n代わりに、前向きで建設的な内容のメールに変更してお送りすることはいかがでしょうか?\n\n例えば、以下のような内容であれば送信可能かと思います:\n- リスケに対応いただくことへの感謝\n- 次回会議を楽しみにしている旨\n- プロジェクト進行へのポジティブなメッセージ\n\nいかがいたしますか?'}]}]
Strands Agents SOP
このアップデートはパッと見て?と思う方がいるかもしれません。
AIエージェント用の作業手順書フォーマットとイメージいただくとわかりやすいです。
人間向けの手順書と同じように、エージェントに「この手順で作業して」と渡せる標準フォーマットで、ワークフローほどガチガチに実装せずとも自然言語で手順チックに動かすことを可能にするのが嬉しいポイントですね。
# コードアシスト
## 概要
このSOPは、テスト駆動開発の原則に基づいてコードタスクを実装します。
「調査 → 計画 → 実装 → コミット」のワークフローに従います。
## パラメータ
- **task_description**(必須): 実装するタスクの説明
- **mode**(任意、デフォルト: "interactive"): "interactive" または "fsc"(完全自動)
## ステップ
### 1. セットアップ
プロジェクト環境を初期化し、必要なディレクトリ構造を作成する。
**制約:**
- ドキュメントディレクトリ構造を検証・作成すること【MUST】
- findコマンドで既存の指示ファイルを探索すること【MUST】
- ディレクトリ作成に失敗した場合は続行しないこと【MUST NOT】
### 2. 調査フェーズ
...
SOPのレポジトリも必要に応じてご参照ください。使い方なども記載があります。
自分でSOPを作成して、MCP ServerとしてSOPを参照させることも可能です。
ステアリングとSOPの活用
re:InventのセッションでもステアリングとSOPの活用について言及されていました。
Strands Agentsはモデル自身に推論 -> 実行 -> 判断のループを管理させるモデル駆動開発であり、ワークフロー駆動開発とは異なります。
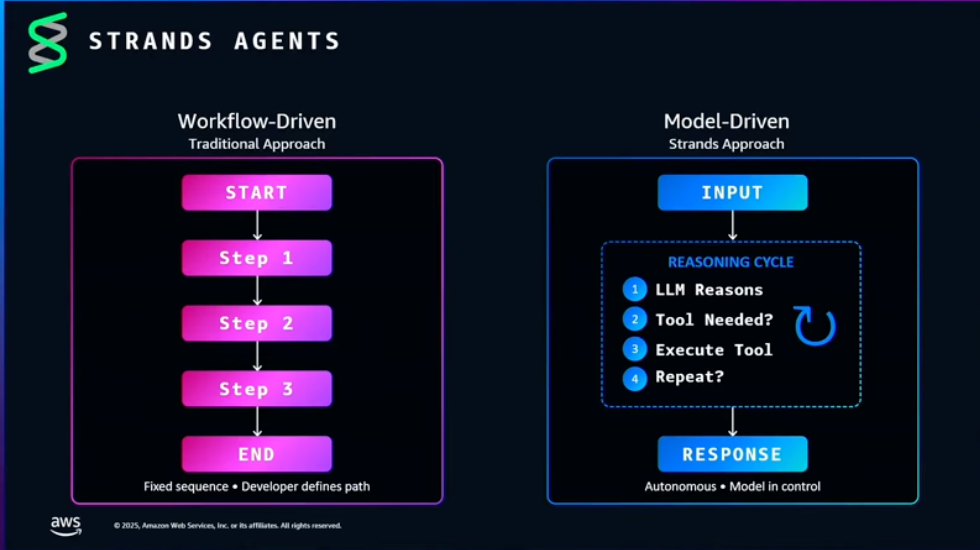
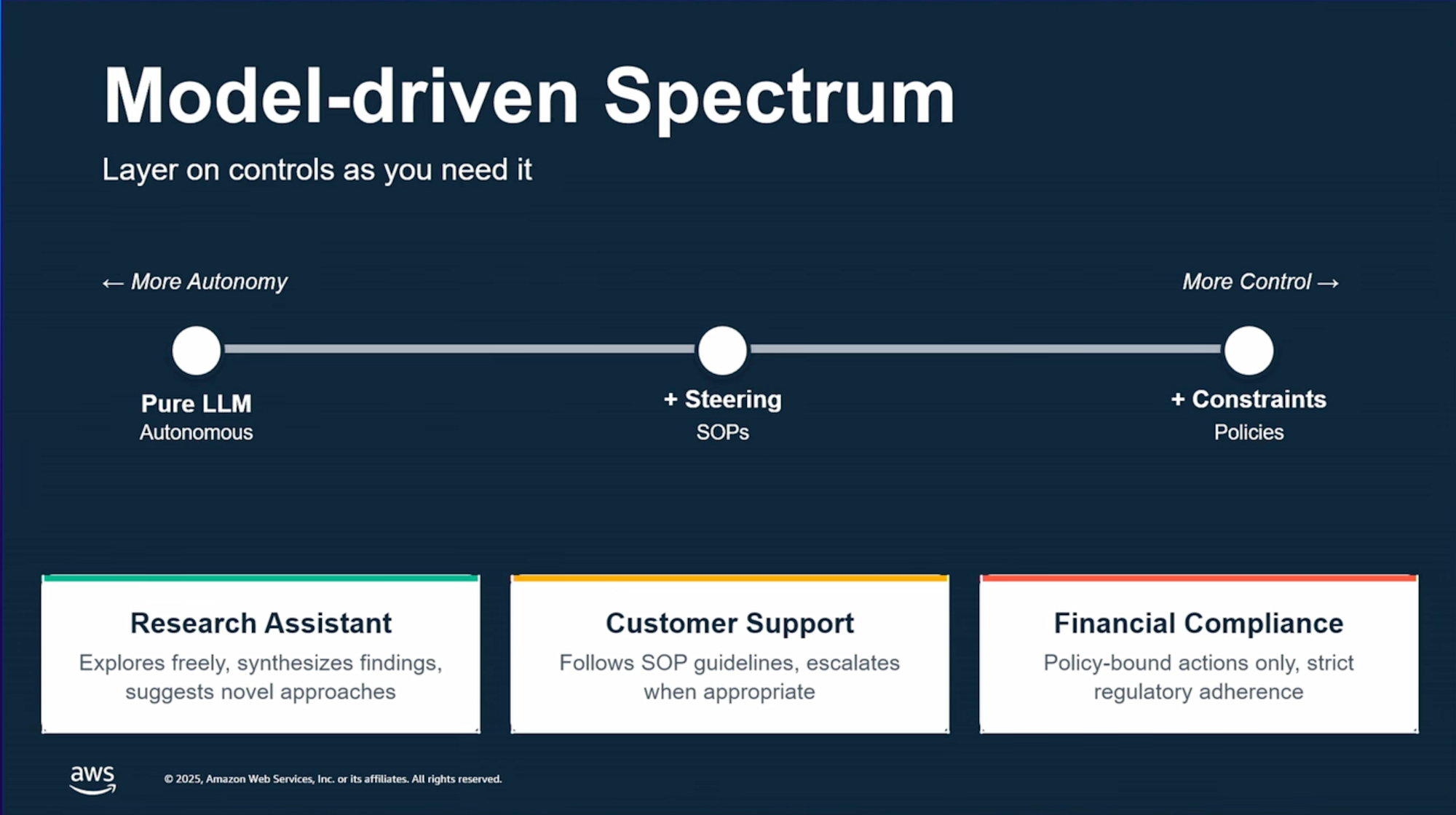
そのためモデルが自由に行動していくため、ビジネス要件を満たすのが難しいケースもあるため、ステアリング機能やSOPを活用して目指す挙動になるようコントロールしていくイメージです。
双方向ストリーミング
Strands Agents側では実験的な機能になりますが、BidiAgentを使って、
簡単に双方向ストリーミングも下記のように実装可能です。
import asyncio
from strands.experimental.bidi import BidiAgent, BidiAudioIO
from strands.experimental.bidi.models import BidiNovaSonicModel
# Create a bidirectional streaming model
model = BidiNovaSonicModel()
# Create the agent
agent = BidiAgent(
model=model,
system_prompt="You are a helpful voice assistant. Keep responses concise and natural."
)
# Setup audio I/O for microphone and speakers
audio_io = BidiAudioIO()
# Run the conversation
async def main():
await agent.run(
inputs=[audio_io.input()],
outputs=[audio_io.output()]
)
asyncio.run(main())
関連するブログ
弊社たかくにさんが実際に試したブログもあるので、ぜひご参照ください!
評価機能
Strandsでも評価機能が追加されました。テストケースを作成して、LLMに評価(LLM-as-a-Judge)させる形になります。
評価メトリクスは自分で作成でもいいですし、ツールを適切に使用できたかなどのビルトインメトリクスも存在します。
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import OutputEvaluator
# テストケース定義
test_cases = [
Case(name="knowledge-1", input="フランスの首都は?", expected_output="パリ"),
Case(name="math-1", input="5 × 12 × 1.08 は?", expected_output="64.8"),
Case(
name="knowledge-2",
input="神野雄大は誰?",
expected_output="知らないです",
),
]
# タスク関数
def get_response(case: Case) -> str:
agent = Agent(system_prompt="正確な情報を提供するアシスタント")
return str(agent(case.input))
# LLM Judge評価器
evaluator = OutputEvaluator(rubric="正確性と完全性を1.0-0.0で評価")
# 実験実行
experiment = Experiment(cases=test_cases, evaluators=[evaluator])
reports = experiment.run_evaluations(get_response)
reports[0].run_display()
実行すると下記のように評価結果が表示されます。
テストコードみたいに表示されてわかりやすいです。

おわりに
今回のアップデートはAIエージェントを作っているのは前提で、より本番で活用したりどう運用していくかを手助けするアップデートが多かった印象です。
まだAIエージェントを作成したことない方は今回のアップデートを機に少し触ってみると、AIエージェントでこんなことできるんだと面白い発見があるかもしれませんね。
ガンガンAgentCoreやStrands Agentsを触ってより便利なAIエージェントを作成していきましょう!
本記事が少しでも役に立ちましたら幸いです。最後までご覧いただきありがとうございましたー!!










