![[レポート]生成AIのためのデータカタログとガバナンス #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]生成AIのためのデータカタログとガバナンス #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS re:Invent2024に参加してきた、データ事業本部の渡部です。
2日目のChalkTalk【ANT323 | Catalog and govern your data for generative AI】に参加してきたので、内容をまとめさせていただきます。
生成AIを触らない日はなくなってきた今日。
その生成AIはファインチューニング・RAG・・・と裏側にデータを必要とします。
今回はそのためのデータ管理をするためにさらに必要なカタログやガバナンスについて学びたいと思い、本チョークトークに参加しました。
セッション概要
説明
Unlocking the full potential of generative AI depends on data quality, effective data sharing, and data governance. Learn how to use Amazon DataZone, a comprehensive solution that empowers organizations to catalog, govern, and securely share data assets for generative AI initiatives. Discover how to streamline data discovery, ensure compliance with data policies, and foster secure collaboration across teams, mitigating risks associated with generative AI models while enabling responsible innovation. This chalk talk offers practical strategies to harness the power of generative AI while maintaining data integrity and trustworthiness.
AI翻訳
生成AIの可能性を最大限に引き出すには、データ品質、効果的なデータ共有、データガバナンスが不可欠です。組織がデータ資産をカタログ化し、管理し、生成AIイニシアチブのために安全に共有することを可能にする包括的なソリューションであるAmazon DataZoneの使用方法について学びます。
データの発見を効率化し、データポリシーへの準拠を確保し、チーム間の安全なコラボレーションを促進する方法を発見します。これにより、生成AIモデルに関連するリスクを軽減しながら、責任ある革新を実現します。
このチョークトークでは、データの整合性と信頼性を維持しながら、生成AIのパワーを活用するための実践的な戦略を提供します。
スピーカー
- Praveen Kumar, Principal Analytics Solutions Architect, Amazon
- Durga Mishra, Principal Architect, AWS
セッション内容
アジェンダは以下の通りです。
- Amazon DataZoneを使用したAWS上の構造化データのガバナンス
- 構造化データガバナンスのデモ
- 生成AI向け非構造化データのガバナンス
- 生成AI向け非構造化データガバナンスのデモ
- Q&A

まず初めに生成AIアプリケーションは氷山の一角であり、水面の下にはそれを支えるものが隠れていると説明がありました。
具体的には、スライドのとおり以下のような重要なインフラストラクチャやガバナンスの要素があるとのことです。
- Storage(ストレージ)
- Structured and unstructured data(構造化データと非構造化データ)
- Operational databases(運用データベース)
- SQL, NoSQL, document, graph, vector(SQL、NoSQL、ドキュメント、グラフ、ベクター)
- Analytics and data lakes(分析とデータレイク)
- Search, streaming, batch, interactive(検索、ストリーミング、バッチ、インタラクティブ)
- Data Integration(データ統合)
- Capture, transformation, streaming(取得、変換、ストリーミング)
- Data governance(データガバナンス)
- Catalog, quality, privacy, access controls(カタログ、品質、プライバシー、アクセス制御)

その氷山を作り上げる一角のガバナンスはDataZoneで担えるということで、DataZoneの紹介に移りました。
大規模な組織では各部門がデータを生成していて、そのデータをデータプロデューサーとして組織内で活用したいと考えているとのことです。
ただ単純なデータ公開や誰でもアクセスができるというようにはしたくないという課題を抱えていると。
その課題を解決するのがDataZoneであるということです。
データプロデューサーはデータマーケットプレイスで細かなアクセス制御で公開することができ、データコンシューマーはデータポータルでデータを検索することができる。アクセス要求に関しては簡単なワークフローを組むこともできると話がありました。
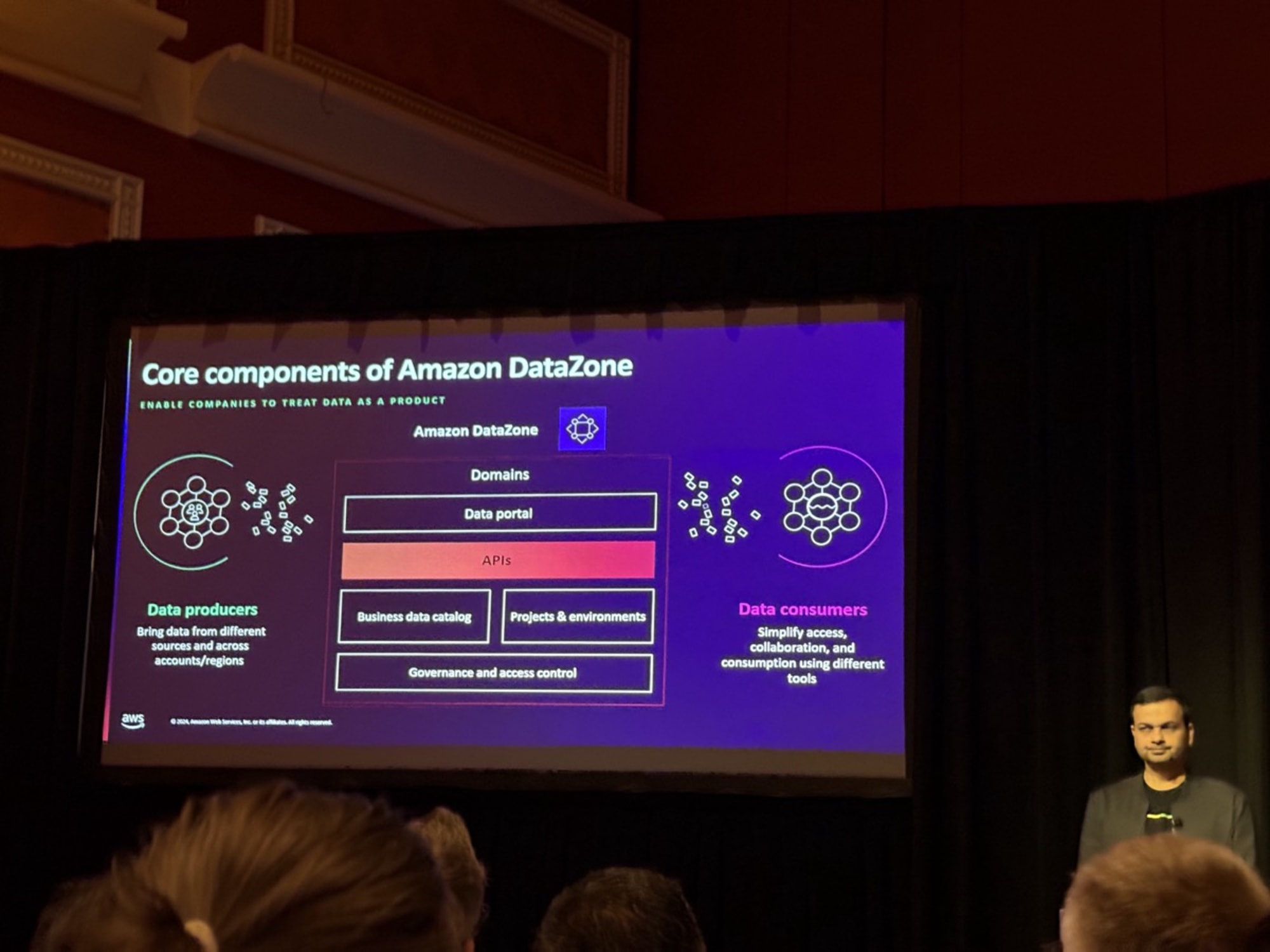
また新しくなったSageMakerはDataZoneのガバナンスとカタログ上で動作すると言及がありました。
今後BIなども統合される統合環境Amazon SageMaker Unified Studioが生まれた理由としては、顧客から「異なるツールを組み合わせるのではなく、ユースケースを直接解決したい」という要望があったからとのことです。


ここでSageMakerでのDataZoneを使用したガバナンス・品質・データリネージュのデモがありました。
新しく統合されたUnified Studioでシームレスに確認ができるデータ・メタデータを確認することができました。
特に印象的だったのは、デモが保険金請求データを例としていたのですが、claimsと検索したときに単なるキーワードマッチではなくて、意味的に近しいものも検索として表示されていたことでした。
デモのあとはQAがあったのですが、2つ抜粋します。
前者のQAは別のセッションでもあったので、皆が気になる質問と思います。
Q: 「非AWSソースについて、特に購読ワークフローについてはどのように扱いますか?」
A: 「サードパーティのソースの検出は比較的簡単です。クロールして取り込むことができます。購読ワークフローについては、パートナー(SnowflakeやDatabricksなど)と協力して実現を進めています。それまでの間は、Lambdaを使用してカスタムワークフローを構築したり、ServiceNowと連携したりすることで購読を管理できます。」
Q: 「いったんデータセットを選択した後、自動化された履行(フルフィルメント)の仕組みはありますか?」(アクセス承認から実際に自動でアクセス可能になるまでの自動の仕組みがあるかという質問です)
A: 「はい。EventBridgeへのイベントの公開があります。Lambdaがこれらのイベントをリッスンし、処理します。EventBridgeにペイロードが送信され、そこには、誰がリクエストし、誰が承認したか、IAMロールは何か、場所は何処かといった情報が含まれます。
その後、必要なポリシーやIAMメンバーシップが自動的に設定されます。
このプロセスはユーザーからは見えない形で管理されます」
QA後は非構造化データのデモに移りました。
内容としては保険物件の衛生画像を持つマーケティン部部門のデータを、営業部門が使用して保険料の見積もりに活かすというものでした。

実際に以下の画像データから得たメタデータをプロデューサーがDataZone APIを通じてカタログに公開し、そのメタデータをコンシューマーが生成AIアプリケーションに読み込ませることで、それぞれの画像で違う結果が得られることまで確認できました。

このデモで重要なことはデータ形式は違えど、DataZoneの基本的な使い方は構造・非構造データで同じであることということでした。
さいごに
生成AIのためのDataZoneの使用方法がデモとともに理解することができました。
構造・非構造データ両対応で、データアクセス制限といったガバナンスをかけられ、またアクセス承認後の自動的な仕組みが揃っているDataZone。今後さらに増大するデータの前で、よりデータガバナンスがセキュリティの意味でも利活用の意味でも重要性が増してきます。
DataZoneはAWSのサービスであるということもあり、非常に触りやすいです。
私も今後もっと触って理解を深めていこうと思います。









