Snowflake AI_EXTRACT を Stream + Task で自動化してみた
こんにちは、データ事業本部のまっきーです。
前回の Snowflake AI_EXTRACT で複数の文書種を構造化抽出してみた では、PDF を Stage に置いて extract_document_data('@stage', 'file.pdf', 'TEMPLATE_ID') を叩くと構造化 JSON が返ってくる、というラッパー関数を作りました。
ただし「Stage に PDF が追加されたら毎回手で SQL を叩く」運用だと、業務に乗せたときに使い物になりません。今回はこれを Stream + Task で自動化します。
結論を先に
whitepaper_stage に新しい PDF をアップロードしてから 1 分前後で、document_metadata テーブルに自動で 1 行追加される状態を作りました。手で SQL を叩く必要はゼロです。これで「ファイルが届く → メタデータ化される」フローが SQL だけで完結します。
Stream と Task が何をしてくれるか
Snowflake には変更検知と自動実行のための仕組みが標準で組み込まれています。
Stream は、テーブルや Stage への変更を「キュー」として持つオブジェクトです。INSERT / UPDATE / DELETE / ファイル追加といった変更を時系列に蓄積し、SELECT で取り出すと「前回 SELECT 以降に何が変わったか」が分かります。
Task は、SQL を定期実行 / 他 Task の完了でトリガー実行できる仕組みです。
SCHEDULE = '1 minutes'のような時間ベース、AFTER another_taskのような依存ベース、いずれも書けます。
この 2 つを組み合わせると、「Stream にデータが入ったら Task が走って処理する」という変更検知ベースのパイプラインが SQL だけで組めます。
ポイントは Task の WHEN 句で SYSTEM$STREAM_HAS_DATA を使うこと。Stream にデータがなければ Task は実行されず、空振りでウェアハウスを起動する無駄が出ません。
やったこと
前回ハンズオンで作った whitepaper_stage(Stage)、document_metadata(メタデータ保存用テーブル)、extract_document_data(ラッパー関数)をそのまま使います。今回追加するのは以下の 3 つです。
- Stage の変更を検知する Stream を作る。
- Stream にデータがあったら走る Task を作る。
- 新しい PDF を Stage に置いて、自動で
document_metadataに行が追加されるか確認する。
手順
事前準備として、ロールとデータベース・スキーマ・ウェアハウスを揃えておきます。前回ハンズオンの環境をそのまま使うので、whitepaper_stage (Stage) / document_metadata (テーブル) / extract_document_data (ラッパー関数) が既に作成済みの前提です。
USE ROLE SYSADMIN;
USE DATABASE makita_doc_ai_db;
USE SCHEMA doc_ai_schema;
USE WAREHOUSE COMPUTE_WH;
1. Stream を作る
whitepaper_stage の変更を追う Stream を作ります。
-- Stage に対する Stream を作る
CREATE OR REPLACE STREAM whitepaper_stream ON STAGE whitepaper_stage;
-- Stage のディレクトリカタログを更新(Stream に変更を流し込む準備)
ALTER STAGE whitepaper_stage REFRESH;
-- 中身を確認
SELECT * FROM whitepaper_stream;
ON STAGE を指定することで、Stage 上のファイル追加を Stream が拾ってくれます。
なお、ここで SELECT * FROM whitepaper_stream を叩くと結果は空でした。Stream 作成時点で既に Stage にあるファイルは Stream に乗ってこない仕様で、これは後述の「印象に残ったポイント 1」で詳しく扱います。
2. Task を作る
Stream にデータがあったときだけ走る Task を作ります。
CREATE OR REPLACE TASK auto_extract_whitepaper
WAREHOUSE = COMPUTE_WH
SCHEDULE = '1 minutes'
WHEN SYSTEM$STREAM_HAS_DATA('whitepaper_stream')
AS
INSERT INTO document_metadata
SELECT
RELATIVE_PATH AS file_name,
SIZE AS file_size,
LAST_MODIFIED AS last_modified,
FILE_URL AS snowflake_file_url,
extract_document_data(
'@whitepaper_stage',
RELATIVE_PATH,
'TECHNICAL_WHITEPAPER'
) AS extracted_data
FROM whitepaper_stream
WHERE METADATA$ACTION = 'INSERT';
-- Task は作成直後は停止状態なので、明示的に RESUME する
ALTER TASK auto_extract_whitepaper RESUME;
-- Task の状態を確認
SHOW TASKS;
Task は作成直後は SUSPENDED(停止)状態で、ALTER TASK ... RESUME で初めて動き出します。これを忘れると「Task を作ったのに動かない」とハマるので注意です。
METADATA$ACTION = 'INSERT' で「ファイル追加」だけを対象にしています。Stage からの削除は 'DELETE' で取れますが、今回はメタデータ追加に絞ります。
3. 動作確認
新しい PDF を whitepaper_stage に追加して、自動でメタデータ化されるか確認します。今回は Snowsight 上の「+ Files」から cloud-data-engineering-for-dummies.pdf (2.1MB、Snowflake 公式 ebook) をアップロードしました。
-- Stage のカタログを更新
ALTER STAGE whitepaper_stage REFRESH;
-- 1 分待つ(Task の SCHEDULE が 1 minutes なので)
-- document_metadata テーブルに自動で行が追加されているか確認
SELECT
file_name,
file_size,
last_modified,
extracted_data:title::STRING AS title
FROM document_metadata
ORDER BY last_modified DESC;
実行結果は以下のとおりです (本記事で実際に検証した結果):
FILE_NAME FILE_SIZE LAST_MODIFIED TITLE
cloud-data-engineering-for-dummies.pdf 2,151,953 2026-05-21 06:05:15 +0000 Cloud Data Engineering For Dummies, Snowflake Special Edition
ebook-the-essential-guide-to-data-engineering-updated.pdf 16,967,909 2026-05-19 06:52:15 +0000 Snowflake
アップロードした新しい PDF が、SQL を手で叩かずに document_metadata テーブルへ自動で追加されています。前回ハンズオンでアップロードした古い方の PDF (2026-05-19) と並んで、新しい行が追加されている状態です。
Task が実際に動いた履歴は Snowsight の Task 詳細画面の Run History タブで確認できます。
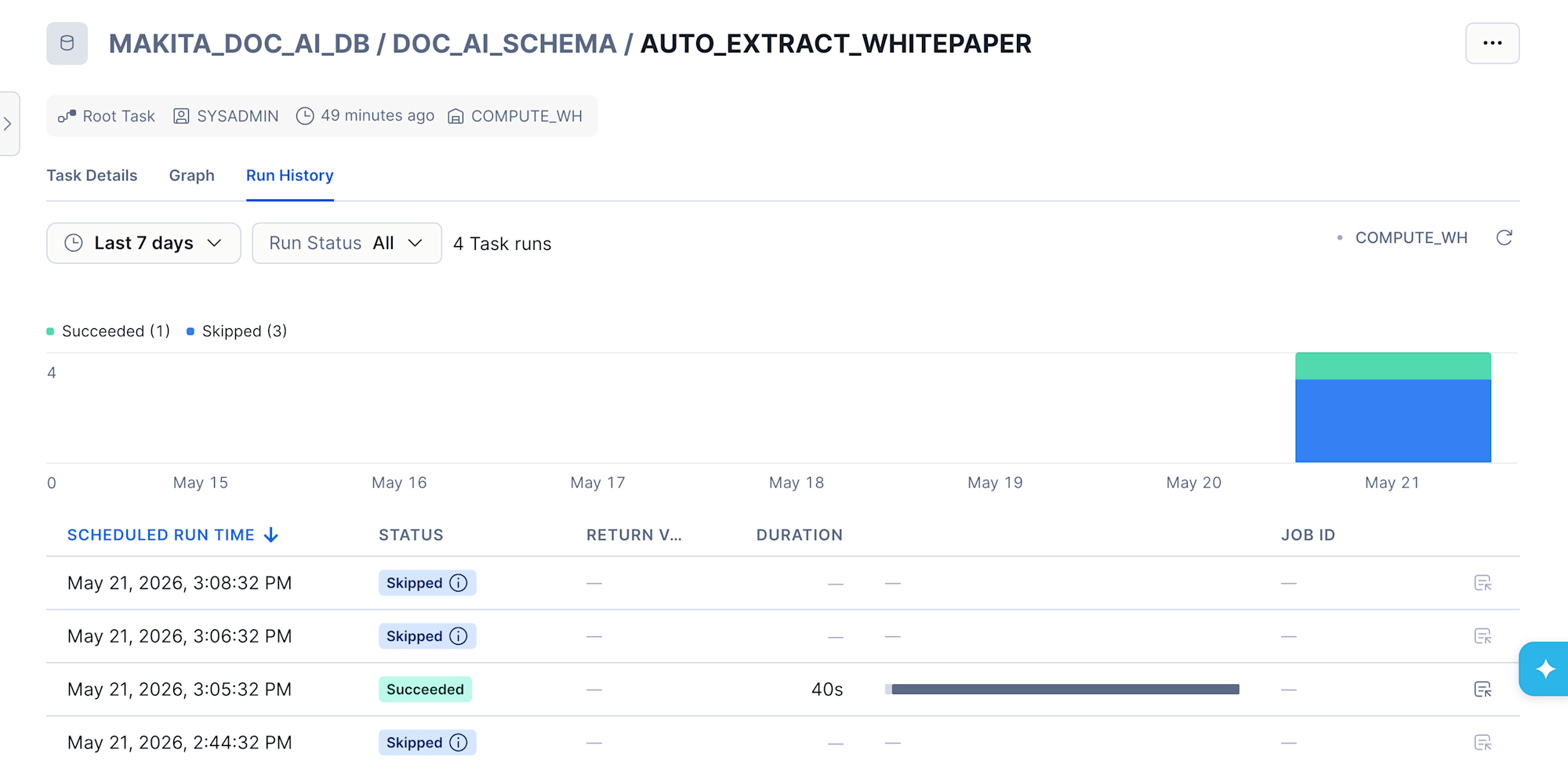
スケジュールされた 4 回のうち、Stream にデータがあった 1 回だけが Succeeded (40 秒で完走)、残り 3 回は Skipped です。SYSTEM$STREAM_HAS_DATA が空振りを防いでいる挙動が一目で分かります。
抽出結果の JSON は以下のような構造になっていました:
{
"title": "Cloud Data Engineering For Dummies, Snowflake Special Edition",
"product_name": "Snowflake",
"key_features": [
"Continuous and extensible data processing",
"The elasticity and agility of the cloud to expand storage capacity",
"Isolated and independent resources for data processing",
"Democratized data access and self-service management",
"Support for continuous integration/continuous delivery processes"
],
"use_cases": [
"データの精度",
"データの形式",
"データの速度",
"データの形式"
],
"target_audience": "エンジニア",
"publication_date": "None"
}
抽出スキーマ通りの 6 項目が JSON で返ってきています。前回記事でも触れた「description の言語が出力 JSON の言語に影響する」現象がここでも再現していて、use_cases だけ日本語値が返ってきました (英語 PDF を入力したのに description が日本語だったため、ユースケース項目だけ翻訳されたような結果になっています)。
印象に残ったポイント
1. Stream は作成時点以降の変更だけを記録する
手順 1 で触れたとおり、CREATE STREAM の直後に SELECT * FROM whitepaper_stream を叩いたら結果は空でした。前回ハンズオンで既にアップロード済みの PDF があるのに、Stream には乗ってこない、という挙動です。
公式ドキュメントを確認したところ、Stream は作成時に offset(時点マーカー) を設定し、それ以降の変更だけを返す仕様でした。
"When created, a stream logically takes an initial snapshot of every row in the source object... by initializing a point in time (called an offset) as the current transactional version of the object."
(Streams - Snowflake 公式ドキュメント)
つまり Stream は「未消費の変更を貯めるキュー」のような性質で、Stage やテーブルの「現在の状態」のスナップショットを保持しているわけではありません。これは仕様通りの挙動です。
Stream の動作を確認するには、Stream を作成した後で新しいファイルを Stage に追加します。そうして初めて、Stream に「INSERT 来た」と変更レコードが記録されます。
2. Stage に対する Stream は insert-only(追加のみ捕捉、削除は追跡されない)
公式ドキュメントによると、Stage(外部テーブル扱い)に対する Stream は insert-only ストリームに限定されます。
"Insert-only streams are supported for streams on externally managed Apache Iceberg or external tables."
(Streams - Snowflake 公式ドキュメント)
Stage からファイルが削除されても Stream は何も検知しません(no-op として扱われる)。今回作る自動化パイプラインでは「新しいファイルを処理する」のが目的なのでこの制約は影響しませんが、「Stage から消したものを追跡したい」というユースケースには別の仕組みが必要です。
3. SYSTEM$STREAM_HAS_DATA による空振り防止
Task の WHEN 句に SYSTEM$STREAM_HAS_DATA('whitepaper_stream') を入れることで、Stream にデータがない時は Task が走らない設計にできます。これによって「1 分ごとにスケジュール実行する Task」でも、新しいファイルが来ていないときはウェアハウスを起動せずスキップします。
定期実行型のパイプラインを組むときに、無駄なコンピュート消費を避ける定石パターンです。
料金体系について
「1 分ごとに走り続ける Task を作ったら、課金が膨らむのでは?」と気になったので、Task まわりの料金体系を公式ドキュメントベースで整理しておきます。
WAREHOUSE 指定 Task の課金
Introduction to tasks - Snowflake 公式ドキュメント には WAREHOUSE 指定 Task の課金について以下の記述があります。
"Snowflake bills your account for credit usage based on warehouse usage while a task is running."
つまり「Task が実行されている間 (while a task is running) のウェアハウス使用量」に基づいて課金される、というのが基本ルールです。
Skipped 時の挙動
WAREHOUSE 指定 Task が WHEN 句で false 判定されて Skipped になった場合の課金挙動について、公式に明示する記述は見つかりませんでした。これは推測ベースで断定できる話ではないので、実機で観察した事実を残しておきます。
今回の検証で得られた事実は以下のとおりです。
Run History画面で Skipped の 3 回は Duration が空欄 (実行時間として記録なし)。Succeededの 1 回だけ Duration40sが記録されている。
「Task が実行されている間にウェアハウス課金が発生する」という公式記述と、「Skipped 時は Duration が記録されない」という観察事実を合わせると、Skipped 時はウェアハウスが起動していないため課金も発生していないと読み取れます。ただしこれは私の解釈であり、厳密な保証ではない点はご了承ください。料金まわりで確実な情報が必要な場合は、Snowflake サポートや営業窓口への確認をおすすめします。
クラウドサービス層のコスト
ウェアハウスとは別に、Snowflake には「クラウドサービス層」(クエリの最適化や Stream の判定処理など、Snowflake の制御プレーン側のコンピュート) のコストがあります。
Understanding compute cost - Snowflake 公式ドキュメント によると以下のように記載されています。
"Cloud Services compute is only billed if the daily consumption of cloud services exceeds 10% of the daily warehouse usage."
つまりクラウドサービスのコストは「1 日のウェアハウス使用量の 10% を超えた分のみ請求」される従量制で、Stream の有無判定のような軽量な処理が大きな金額になりにくい構造になっています。
検証用に作った Task の止め方
検証や PoC で作ったまま放置すると後で「これ何だっけ」となるオブジェクトが増えるので、用が済んだら明示的に停止しておくのが筋です。
-- Task を停止(スケジュール実行をキャンセル)
ALTER TASK auto_extract_whitepaper SUSPEND;
-- 状態確認 (state = suspended になるはず)
SHOW TASKS LIKE 'AUTO_EXTRACT_WHITEPAPER';
SUSPEND した Task はオブジェクト自体は残るので、再開したくなったら ALTER TASK ... RESUME でいつでも復活できます。完全に消したい場合は DROP TASK auto_extract_whitepaper; を叩きます。
まとめ
- Stream は Stage / テーブルの変更を時系列に蓄積するキュー、Task は SQL を定期実行 / イベント駆動できる仕組み。
- 2 つを組み合わせると「ファイルが置かれたら自動でメタデータ化される」フローを SQL だけで組める。
SYSTEM$STREAM_HAS_DATAで空振り実行を防げるので、ウェアハウス課金が無駄に増えない。- Task は作成直後は SUSPENDED 状態。
ALTER TASK ... RESUMEを忘れずに。 - 検証や PoC で動かしたら、用が済んだら
ALTER TASK ... SUSPENDで停止しておく。
おわりに
非構造化データを扱うときの「ファイル取り込み → メタデータ化 → 検索可能化」というパイプラインは、AWS ベースの構成だと Lambda や EventBridge を組み合わせる構成がよく採られる印象です。Snowflake ユーザーの観点からは、Stream + Task により Snowflake 内で完結させることで、外部サービス連携の保守コストを削減できる場面が多そうだと感じました。
次は Cortex Analyst の Semantic Model を自分で 1 から書いて、document_metadata テーブルに自然言語で問い合わせる動作確認をやってみる予定です。








