Snowsightから見る、Model Registryに登録した機械学習モデルのSPCSへのデプロイ・モニタリングの仕組み
データ事業本部の鈴木です。
SnowflakeはAI Data CloudとしてAI/MLの機能も続々と強化されています。
業界全体の流れとして、しばらくはCortex SearchやCortex Analystなどをはじめ生成AI向けの機能のアップデートがメインなのかなと思っていましたが、従来のMLOps向けの機能もしっかりアップデートされていました。
既に一般提供開始していますが、1年半ほど前には、当時はまだプレビュー提供中でしたSnowpark ML Model Registryをご紹介しました。この機能も機械学習モデル活用の動線の中核として非常に強化されています。
Model Registryに登録した機械学習モデルに対して、Snowsightからも便利に機能を利用できるようになっており、今回は以下機能を改めてご紹介します。
- SnowSightからのモデル管理
- MLリネージ
- Snowpark Container Services(SPCS)へのデプロイ(パブリックプレビュー)
- モデルモニター
モデルモニターは複数データセットを用意する必用があるため、後半で題材を分けて紹介します。
Snowpark ML Model Registryについて
Model RegistryはSnowpark MLにおけるMLOps向けの機能の一つで、Snowflakeで機械学習モデルとそのメタデータを安全に管理することができます。
Model Registryがなかった頃は、モデルをUDFとしてデプロイするのがオーソドックスな方法でしたが、実装がそこそこ複雑で、モデルのバージョン管理もユーザーが気を配る必用がありました。
Model RegistryはNotebookなどからSnowpark MLを使って簡単に利用が可能です。モデルのバージョン管理もでき、メトリクスなどの記録もできます。
直近ではSPCSへのデプロイもパブリックプレビューですがサポートされており、モデルの管理・運用の中核としてますます便利になっています。
例えば、以下の例ではModel Registryに登録したモデルのエイリアスを変えることで、利用側のコードを変更することなく簡単にモデルを切り替えできるようになっております。
続く内容で、Model Registryに比較的新しく登場した強力な機能についてご紹介します。
1. Model Registryへのモデルの登録
この後に記載する2~4の内容向けに、IRISデータを予測するモデルを事前にNotebookで作成し、Model Registryに登録しておきました。
登録方法は冒頭に記載した『パブリックプレビュー版のSnowpark ML Model Registryで、SnowflakeでのMLOpsのポイントを確認してみた』を参考にしてください。
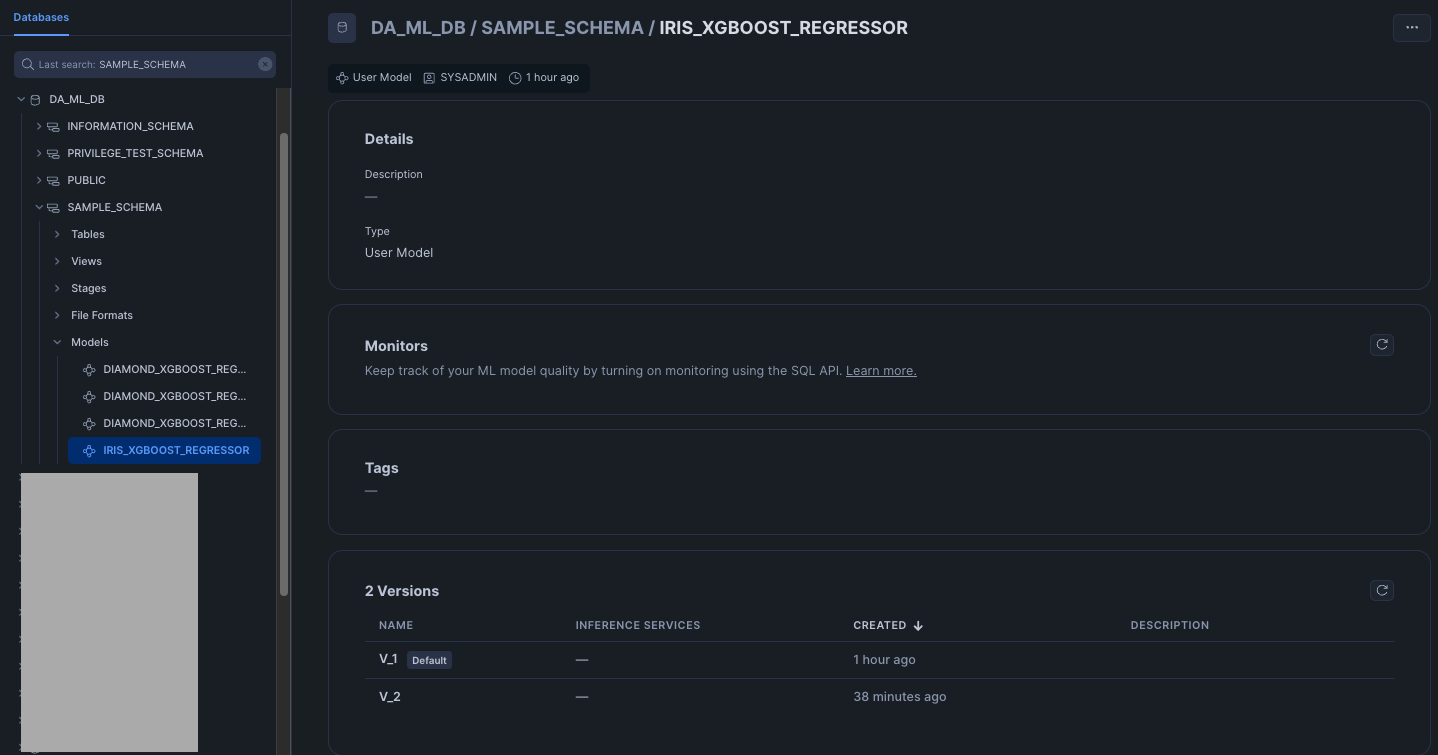
モデルはバージョン管理が可能です。個々の機械学習モデルは「モデルバージョン」に対応しており、複数バージョンのモデルバージョンを含んだ大きい枠組みとして「モデル」があります。「モデル」には後ほど紹介するようにMLリネージのようなメタデータを登録したり、モデルモニターを作成したり、SPCSへのデプロイの動線が用意されていたりします。
多くの場合はネイティブのNotebookでモデルを作成するのが簡単と思いますが、Snowpark MLで訓練した機械学習モデルは例えば以下のようにModel Registryへ登録できます。
-- https://docs.snowflake.com/en/developer-guide/snowflake-ml/model-registry/overview#registering-models-and-versions
from snowflake.ml.model import type_hints
mv = reg.log_model(clf,
model_name="my_model",
version_name="v1",
conda_dependencies=["scikit-learn"],
comment="My awesome ML model",
metrics={"score": 96},
sample_input_data=train_features,
task=type_hints.Task.TABULAR_BINARY_CLASSIFICATION)
なお、IRISデータセットは、下記リンクにて公開されています。
データ自体は今回は拘らないため、冒頭のブログで紹介したような方法でモデルを作成したというようにお考えください。
また、後ほど記載するSPCSへのデプロイのため、Notebookへインストールしたライブラリは以下のようにしました。
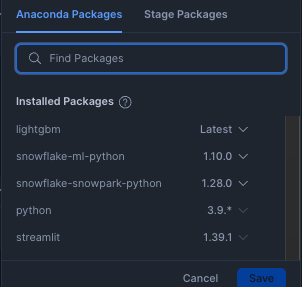
特にsnowflake-snowpark-pythonとsnowpark-ml-pythonはコンテナのビルド時に相性があるようで、何度か試行錯誤して決めました。この指定は今後の時間経過とともに変わっていくと思います。
2. Snowsightからの管理
Model Registryに登録したモデルはSnowsightから確認できるようになっています。
モデルは左サイドバーのAI&ML機能からと、データベースの両方から確認できます。
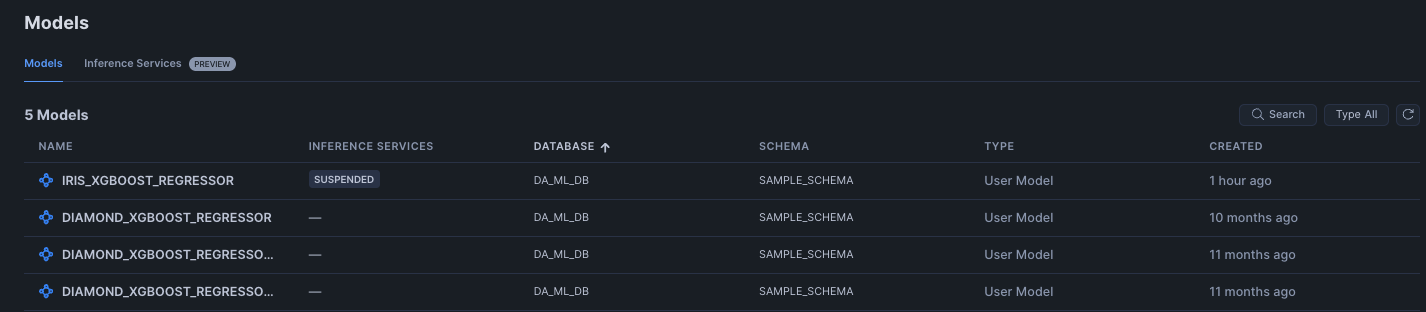
特に大きく変わった点としてはモデルの性能監視のためのモデルモニターがSnowsightの同一の動線上から確認できるようになっています。
また、モデルバージョンからはMLリネージも確認できます。直近でSPCS Model Servingへのデプロイもサポートしました。(パブリックプレビュー)
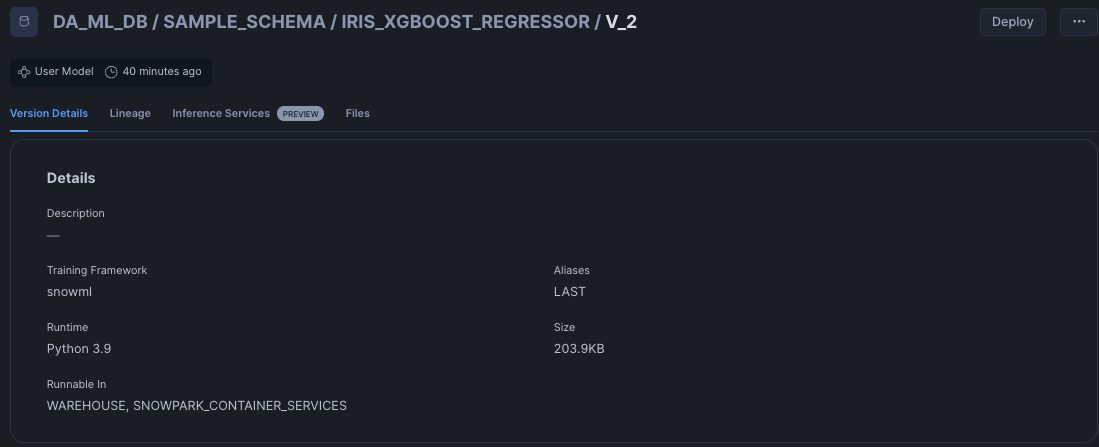
※デプロイの試行錯誤していたためモデルバージョンがV2ですが気にしないでください。
3. MLリネージ
機械学習パイプラインを通過したデータのトレース情報を確認できます。
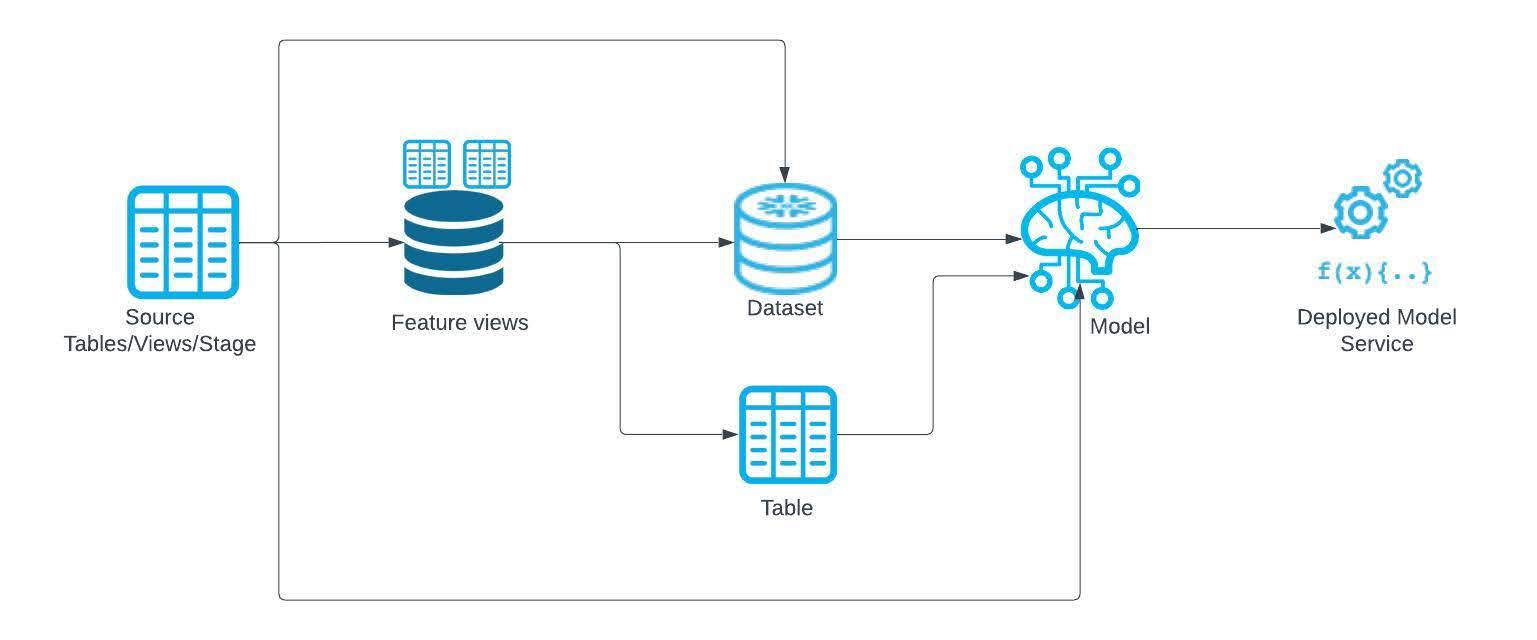
(上記ガイドより)
リネージはモデルレジストリに登録される際に取得され、Snowpark MLを使ってモデルをトレーニングし、Snowpark DataFrameを入力に使っている場合は自動で反映されます。そうでない場合も設定可能のようです。
今回は以下のように確認できました。
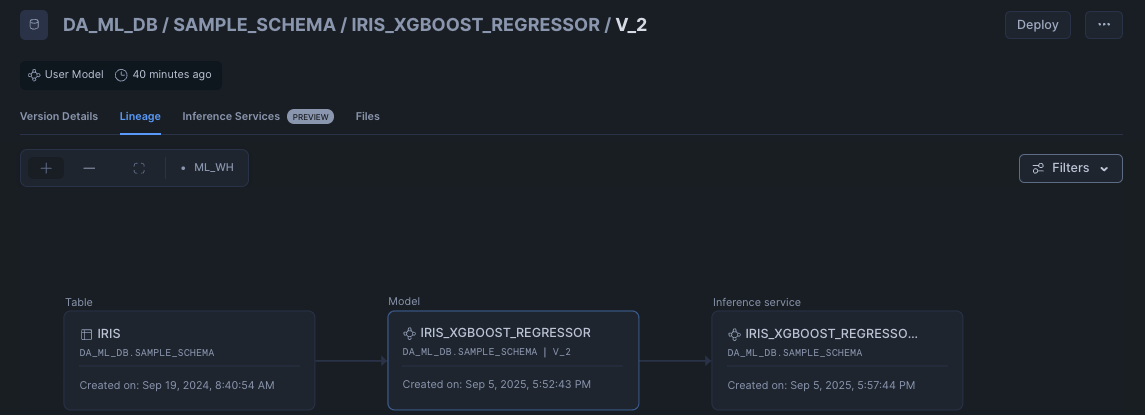
ガイドではサービスは未対応との記載でしたが、直近で見られるようになっているようです。
モデルバージョン単位で、データが何でどのサービスにデプロイされているか管理できるのは非常に良いです。
4. SPCS Model Servingへのデプロイ
直近の8/28に上記のモデル画面からSPCSへモデルのデプロイができるようになりました。
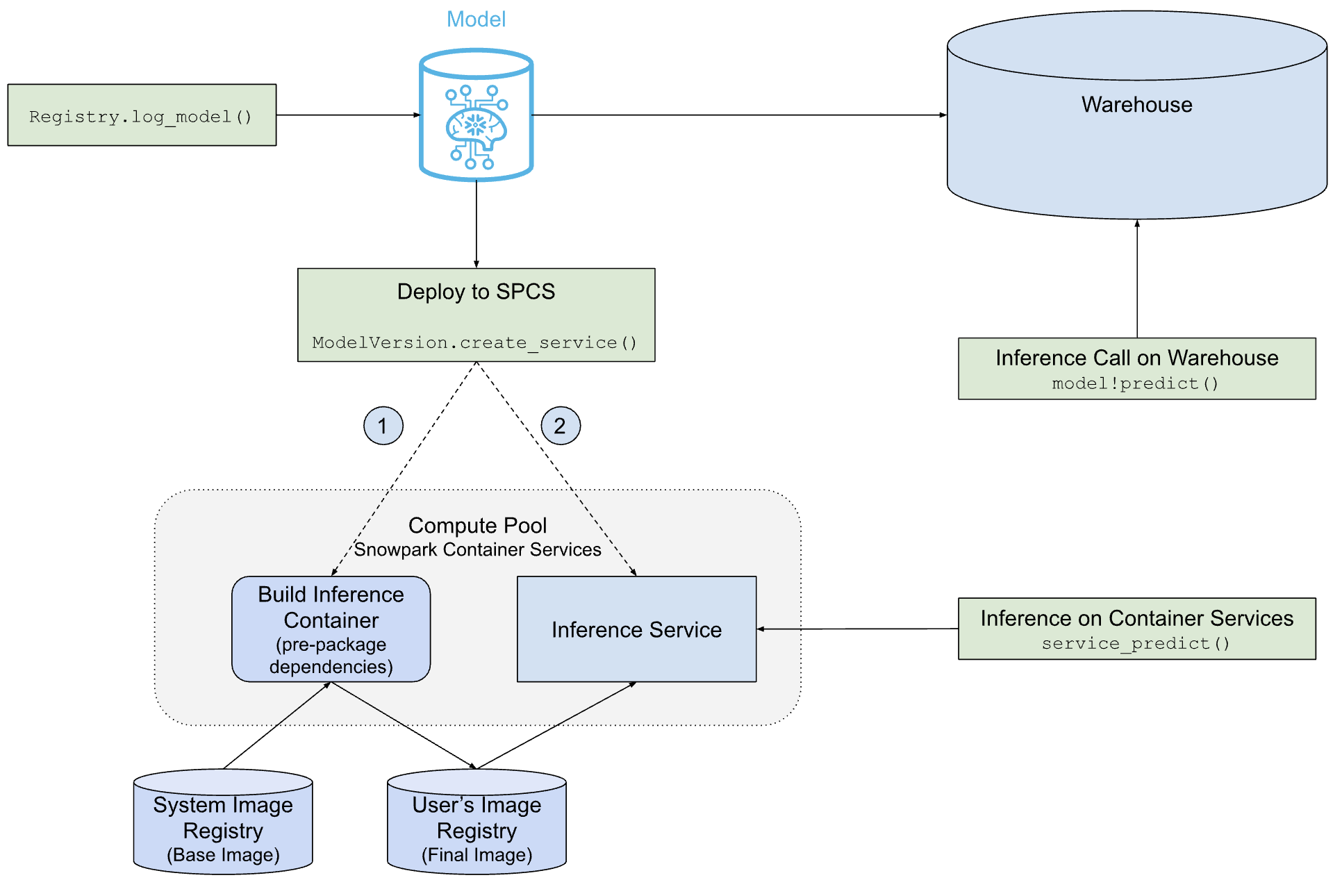
Model Registryに登録したモデルをコンテナで実行できる機能です。特にGPUが必要なモデルを実行する際にメリットが大きい機能になります。
上記ガイドに掲載の以下の図が非常に分かりやすいです。
i. Compute Poolの作成
まずはCompute Poolの作成が必要です。
今回は試してみたいだけだったため以下のように作成しました。
CREATE COMPUTE POOL IF NOT EXISTS cm_nayuts_pool
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = 'CPU_X64_XS'
AUTO_RESUME = TRUE;
作成したCompute PoolはAdminメニューから確認・操作できました。
ii. SPCSへのデプロイ
作成しておいたモデルバージョンを開き、右上のDeployからデプロイできました。
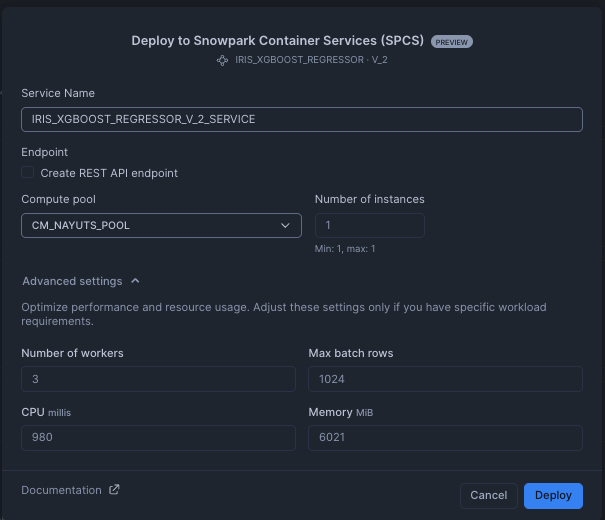
クリックすると、ポップアップが表示され、サービスの設定ができました。
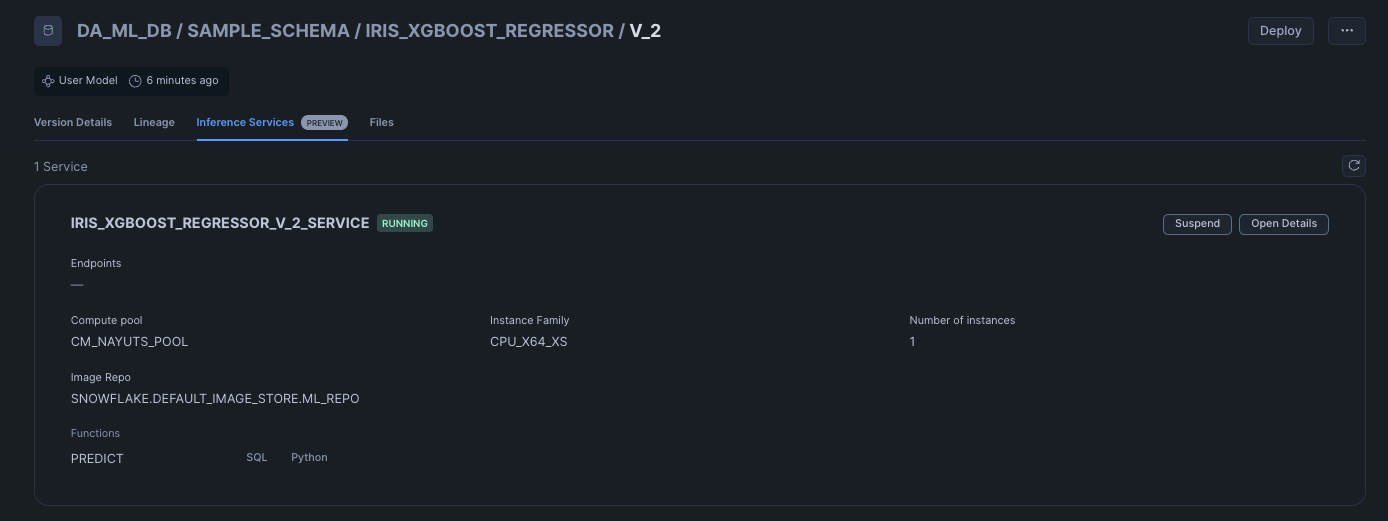
デプロイできるとInference Servicesタブが以下のようになります。
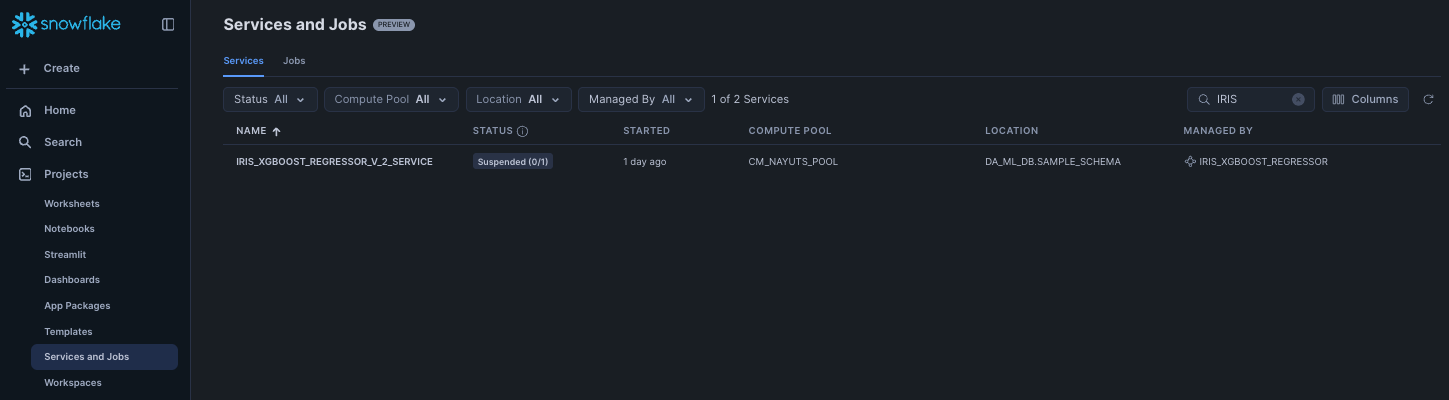
Services and Jobsの画面からも確認できました。
まずサービス自体はServicesタブで確認できました。
サービス向けのコンテナのビルドはJobsタブから確認できました。デプロイに失敗するようだとここからログを確認できました。

iii. 推論の実行
SHOW FUNCTIONS IN SERVICE サービス名でサービスが提供している関数を確認できました。

推論はSQLからだと以下のように推論ができました。
-- https://docs.snowflake.com/en/developer-guide/snowflake-ml/model-registry/container#sql
-- See signature of the inference function in SQL.
SHOW FUNCTIONS IN SERVICE MY_SERVICE;
-- Call the inference function in SQL following the same signature (from `arguments` column of the above query)
SELECT MY_SERVICE!PREDICT(feature1, feature2, ...) FROM input_data_table;
Pythonからだとウェアハウスを使った推論と同様に以下のように推論ができるようです。service_nameでサービス名を指定します。
## https://docs.snowflake.com/en/developer-guide/snowflake-ml/model-registry/container#python
# Get signature of the inference function in Python
# mv is a snowflake.ml.model.ModelVersion object
mv.show_functions()
# Call the function in Python
service_prediction = mv.run(
test_df,
function_name="predict",
service_name="my_service")
5. モデルモニターでのモニタリング
モデルはモデルモニターでモニタリングすることができました。
以下のクイックスタートでは簡単にデータの用意と動作の確認をすることができるため、こちらを参考にご紹介します。
i. モデルモニターの作成
モデルレジストリに登録済みのモデルバージョンに対して、SQLまたはPythonで作成できました。
-- https://github.com/Snowflake-Labs/sfguide-getting-started-with-ml-observability-in-snowflake/blob/main/notebook/1_notebook.ipynb
CREATE OR REPLACE MODEL MONITOR CHURN_MODEL_MONITOR
WITH
MODEL=QS_CustomerChurn_classifier
VERSION=v1
FUNCTION=predict
SOURCE=CUSTOMERS_DRIFTED
BASELINE=CUSTOMERS
TIMESTAMP_COLUMN=TRANSACTIONTIMESTAMP
PREDICTION_CLASS_COLUMNS=(PREDICTED_CHURN)
ACTUAL_CLASS_COLUMNS=(EXITED)
ID_COLUMNS=(CUSTOMERID)
WAREHOUSE=ML_WH
REFRESH_INTERVAL='1 min'
AGGREGATION_WINDOW='1 day';
作成されたモデルモニターはモデルの画面から確認できました。
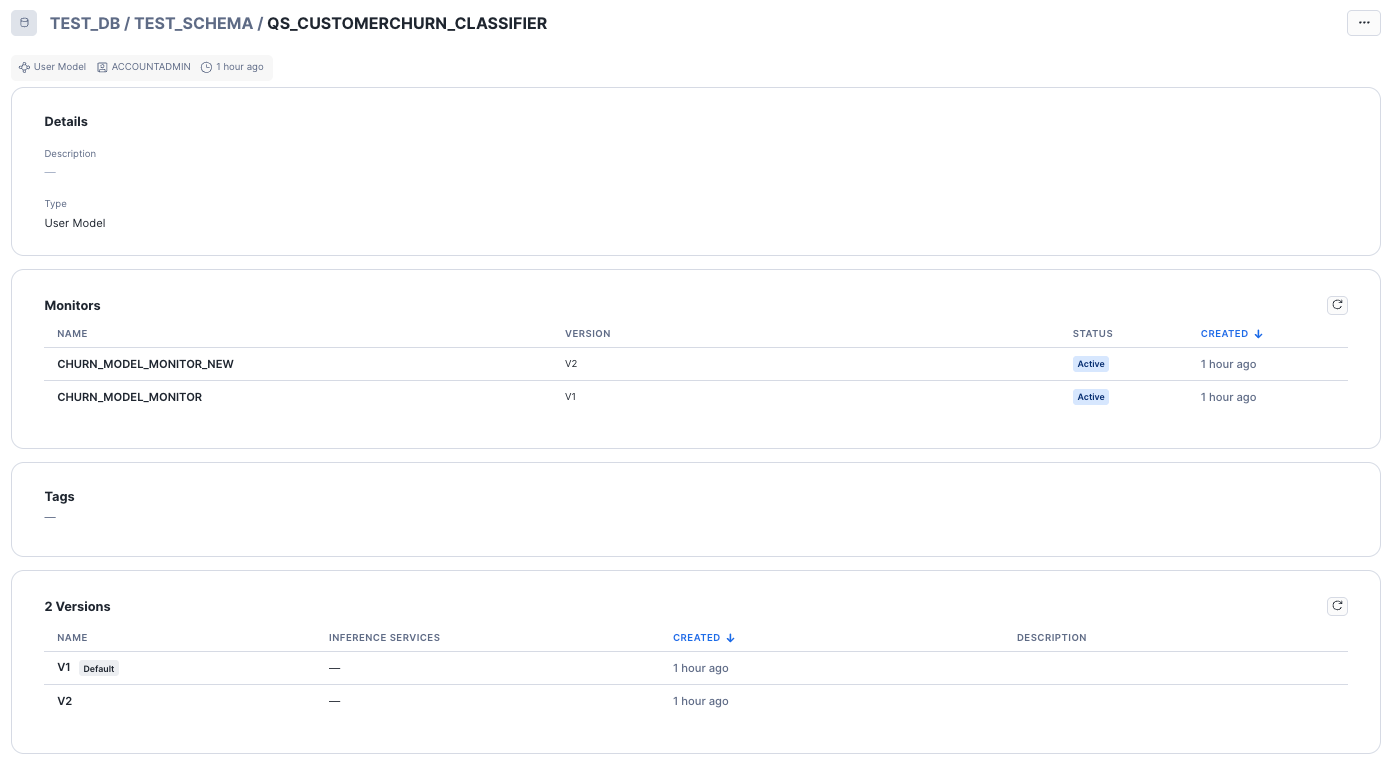
各引数は以下です。
MODEL: モデル名VERSION: モデルバージョンFUNCTION: 監視対象とするモデルバージョンの特定の関数名SOURCE: 監視対象の関数で推論する対象のデータセットBASELINE: ドリフト計算向けのデータセットTIMESTAMP_COLUMN: ソースデータのタイムスタンプ列名PREDICTION_CLASS_COLUMNS: ソースデータの予測クラス列名ACTUAL_CLASS_COLUMNS: ソースデータの実際のクラス列名ID_COLUMNS: ソースデータの各行を一意に識別する文字列列名WAREHOUSE: モニターの内部計算に使用するウェアハウス名REFRESH_INTERVAL: モニターが内部状態を更新する間隔AGGREGATION_WINDOW: モニターがデータを集計する期間
ii. モニタリング内容の確認
モデルモニターではTIMESTAMP_COLUMN列を軸にAGGREGATION_WINDOWの粒度で集計したメトリクスを確認できました。
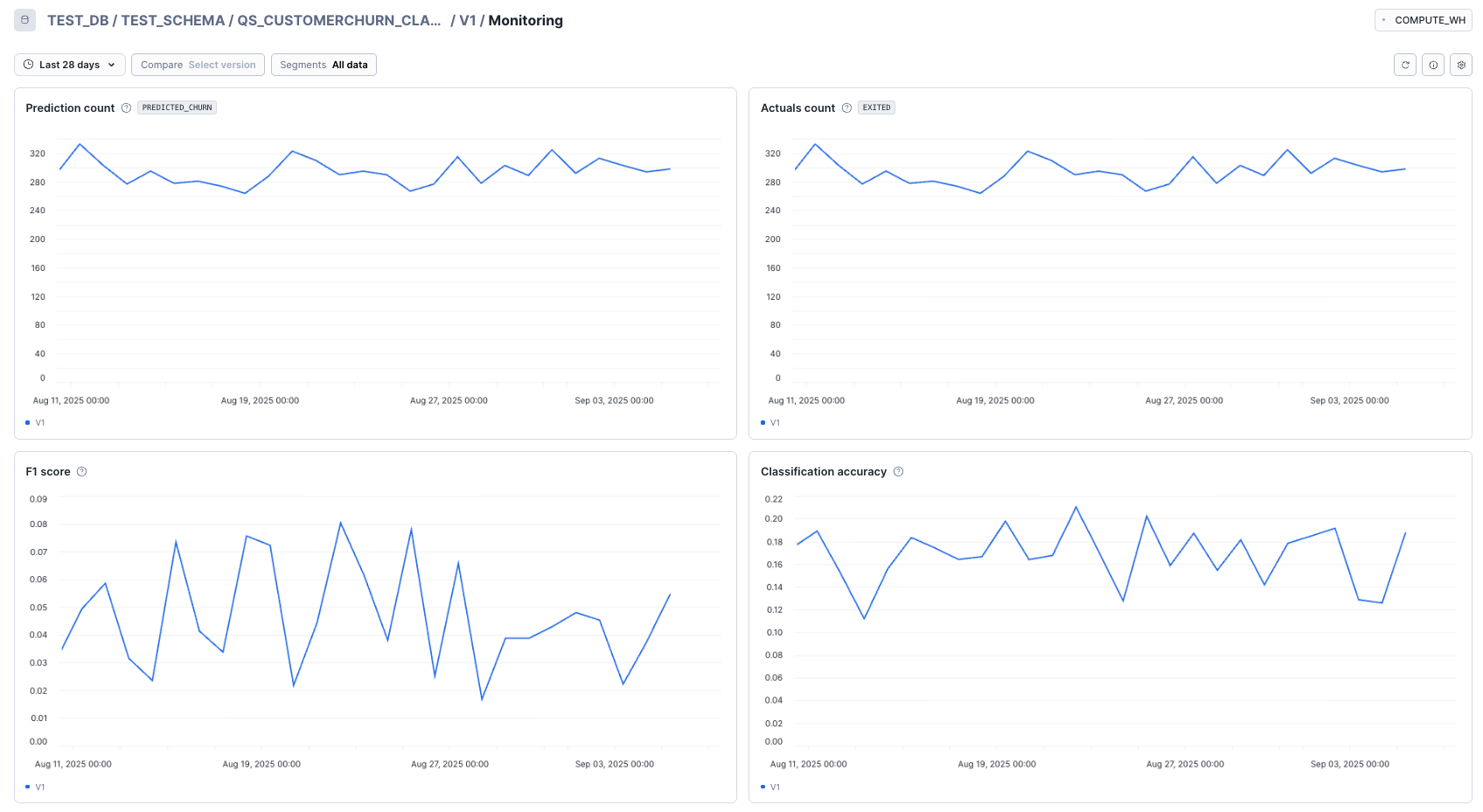
モデルモニターを跨いで異なるモデルバージョンのメトリクスも比較可能でした。
メトリクスはほかにも選ぶことができ、ダッシュボードに表示される順番もカスタマイズ可能でした。
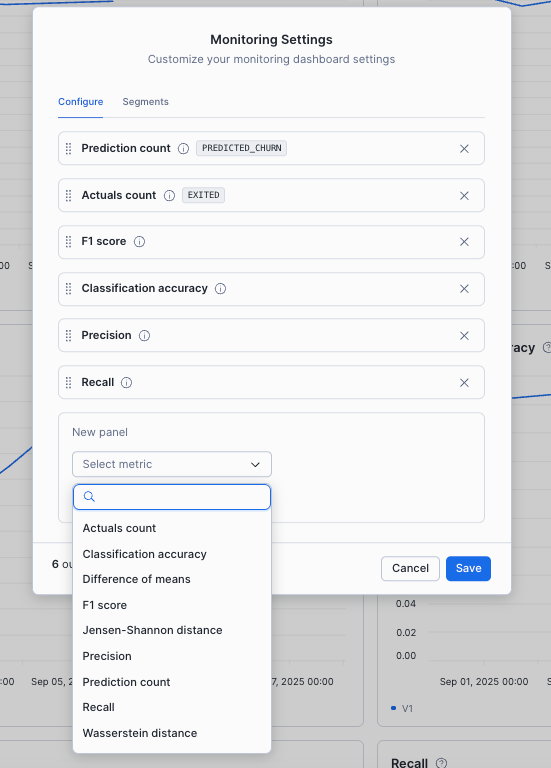
パフォーマンスメトリクス、統計値、データドリフトの検出はSQLでも行えました。
以下はドリフト検出の例です。
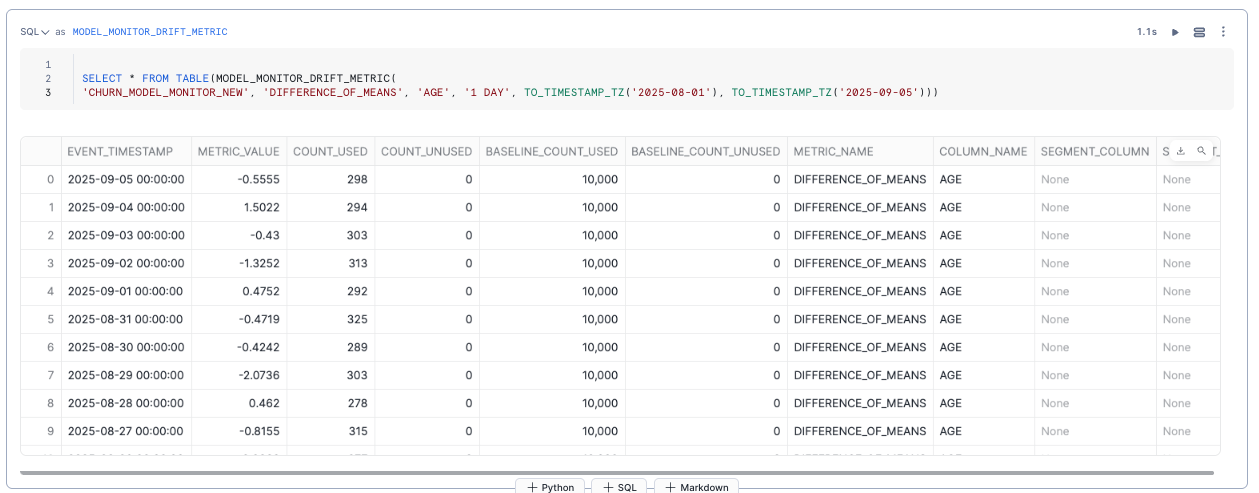
各SQLは以下にガイドがあります。
クイックスタートではドリフトの発生有無に対してアラートを設定する例が紹介されていました。アラートをトリガーにメール通知などをすることも可能で、方法は以下も参考にしてください。
最後に
Model Registryに登録した機械学習モデルはSnowsightをはじめ様々なインターフェースから利用できるようになっております。
今回はSnowsightからの利用を想定して、以下の機能をご紹介しました。
- モデル管理
- MLリネージ
- Snowpark Container Services(SPCS)へのデプロイ(パブリックプレビュー)
- モデルモニター
運用としてはモデルモニターで継続して性能やドリフト発生の有無が監視できるため、劣化があれば再学習・新バージョンの登録ができます。GPUが必用なケースではSPCSへのデプロイも必用です。MLリネージでモデルバージョンがどのテーブルを学習し、どのSPCSへデプロイされているのか一目で分かるため管理も簡単ですね。
Model Registryはモデルの管理・運用の中核としてますます便利になっています。
これらの機能により、SnowflakeはCPUのみだけではなくGPUが必用なモデルも簡単に学習・デプロイ可能になりました。
今回は取り合げませんでしたが、大規模なデータに対して複数のモデルを並列で学習する機能が発表されており、機械学習モデルの開発・運用のプラットフォームとしても大きな強みを持つサービスとなっています。
Snowflakeでの機械学習モデルの開発・運用の参考になりましたら幸いです。








