
dbt Cloud の Seed で作成されるテーブルを開発環境でのみ Source として扱う

はじめに
dbt Cloud を使用する際、環境分離の制約で本番環境のデータを開発環境で利用できない場面があるとします。Seed を使うと、CSV ファイルから DWH 側のテーブルとして作成できます。また、Seed により作成されたテーブルはソースとして使用することも可能です。
開発環境以外では、本番環境相当のデータを使用できるとして、開発環境でのみ Seed を実行し、他環境と同じソースとして使用してみましたので、試した内容を記事としました。
前提条件
以下の環境で検証しています。
- DWH:Snowflake
- 環境:Snowflake アカウントレベルで分離
- PROD:
- 本番環境
target.name:prdschema:prd
- STG:
- 統合テスト環境。複数の開発者が作成したモデルをマージし、品質保証を行う環境
target.name:stgschema:stg
- DEV:
- 各ユーザーが新しいデータを開発する、個人の開発環境
target.name:devschema:デフォルト(dbt_<ユーザー名>)- 本番環境のデータは使用できない設定と仮定
- PROD:
- データベース構成
- 各環境(アカウント)で dbt による開発結果を出力する単一のデータベースを用意
- 例:<env>_db
- 各環境(アカウント)で dbt による開発結果を出力する単一のデータベースを用意
- ブランチ戦略
mainブランチと同期されたstgブランチを作成stgブランチからfeature/xxブランチを派生させ、開発を行う- 開発完了後、
feature/xxからstgへブランチにマージする - STG 環境でテストが完了したら、
stgブランチの変更をmainブランチにマージする
- ジョブ構成
- 本番環境へのデプロイジョブ
mainブランチの変更を本番環境へ反映するdbt buildを実行
- STG 環境へのデプロイジョブ
stgブランチの変更を STG 環境へ反映する- カスタムブランチとして
stgを指定する dbt buildを実行
- 本番環境へのデプロイジョブ
試してみる
事前準備
Snowflake 側で3つのアカウントを用意し、各環境で環境を表す変数名を変更し、以下を実行しました。今回の設定上、開発環境アカウントではデータロード以降の内容(テーブル作成・データロード)は実行しないようにします。
これにより、dbt Cloud の出力先となるデータベースと生データ用のスキーマが作成されます。ステージング、本番環境では、本番と同様のデータがrawスキーマにロードされている設定となります。
サンプルデータは Quickstart で提供される jaffle_shop のデータを使用しました。
--変数を定義
--環境名: prd, stg, dev
SET env_name = '<env>';
--データベースを作成
SET db_name = concat($env_name,'_db');
create database if not exists identifier($db_name);
--スキーマを作成
use database identifier($db_name);
--raw
create schema raw;
--ウェアハウスを作成
create warehouse if not exists transforming;
/*==========
以降の内容は開発環境では実行しない
==========*/
--データロード
use schema raw;
--customers
create table customers
( id integer,
first_name varchar,
last_name varchar
);
copy into customers (id, first_name, last_name)
from 's3://dbt-tutorial-public/jaffle_shop_customers.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
--orders
create table orders
( id integer,
user_id integer,
order_date date,
status varchar,
_etl_loaded_at timestamp default current_timestamp
);
copy into orders (id, user_id, order_date, status)
from 's3://dbt-tutorial-public/jaffle_shop_orders.csv'
file_format = (
type = 'CSV'
field_delimiter = ','
skip_header = 1
);
--データを確認
select * from customers;
select * from orders;
最終的には、以下のパイプラインを作成するとします。この際、開発環境でのみ seed で作成されるテーブルをソースとして参照させます。
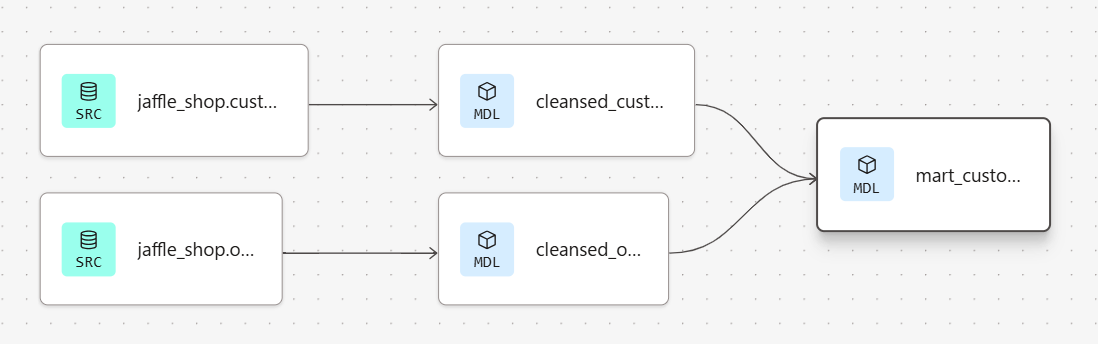
Seed を環境ごとに有効化または無効化する
Seed に関する設定項目は以下に記載があります。
この内、General configurations 内に記載がある enabled プロパティを使用します。これにより、特定のリソースの有効化または無効化を制御できます。
ここでは dbt_project.yml内で以下のように設定しました。
seeds:
+enabled: "{{ target.name == 'dev' }}"
jaffle_shop:
+database: "{{ env_var('DBT_DATABASE') }}"
+schema: raw
ポイントは以下の通りです。
target.name- 前提条件として開発環境の
target.nameはdevとしているので、開発環境で Seed が有効化される設定です。その他の環境では無効化されます
- 前提条件として開発環境の
- 出力先データベース
- 今回の設定では各環境(アカウント)で dbt による開発結果を出力する単一のデータベースを用意しているため、こちらを出力先としています
- 出力先スキーマ
- seed により出力されるテーブルを開発環境ではソースとして扱いたいので、他環境と同様に生データであることがわかる名称(
raw)としています - カスタムスキーマ マクロは特に設定していないので、開発環境での実行時は、ユーザーごとに異なる
dbt_<ユーザー名>_raw({{ default_schema }}_{{ custom_schema_name | trim }})の名称からなるスキーマに出力されます
- seed により出力されるテーブルを開発環境ではソースとして扱いたいので、他環境と同様に生データであることがわかる名称(
Seed により作成されるテーブルをソースに指定
Seed を実行後に作成されるテーブルもソースに指定可能です。ここでは models ディレクトリ内に YAML ファイルを作成し、以下のように設定しました。
version: 2
sources:
- name: jaffle_shop
description: This is a replica of the Postgres database used by our app
database: "{{ env_var('DBT_DATABASE') }}"
schema: "{{ 'raw' if target.name == 'prd' or target.name == 'stg' else target.schema ~ '_raw' }}"
tables:
- name: customers
description: One record per customer.
- name: orders
description: One record per order. Includes cancelled and deleted orders.
開発環境以外では本番環境相当のデータを使用できる設定なので、raw レイヤーとなるスキーマが指定されます。開発環境ではtarget.schema ~ '_raw'により、開発者ごとのdbt_<ユーザー名>_raw({{ default_schema }}_{{ custom_schema_name | trim }})の名称からなるスキーマがこのソーススキーマとして使用されます。
開発環境で実行
seeds/jaffle_shopディレクトリ内に以下の CSV ファイルを配置しました。
ここでは簡単に他環境と同じデータからレコードを絞った形で配置しています。
ID,FIRST_NAME,LAST_NAME
1,Michael,P.
2,Shawn,M.
3,Kathleen,P.
4,Jimmy,C.
5,Katherine,R.
ID,USER_ID,ORDER_DATE,STATUS,_ETL_LOADED_AT
1,1,2018-01-01,returned,2025-09-10 15:27:29.140
2,3,2018-01-02,completed,2025-09-10 15:27:29.140
3,94,2018-01-04,completed,2025-09-10 15:27:29.140
4,50,2018-01-05,completed,2025-09-10 15:27:29.140
5,64,2018-01-05,completed,2025-09-10 15:27:29.140
6,54,2018-01-07,completed,2025-09-10 15:27:29.140
7,88,2018-01-09,completed,2025-09-10 15:27:29.140
8,2,2018-01-11,returned,2025-09-10 15:27:29.140
9,53,2018-01-12,completed,2025-09-10 15:27:29.140
10,7,2018-01-14,completed,2025-09-10 15:27:29.140
この状態から、開発環境でdbt seedを実行してみます。
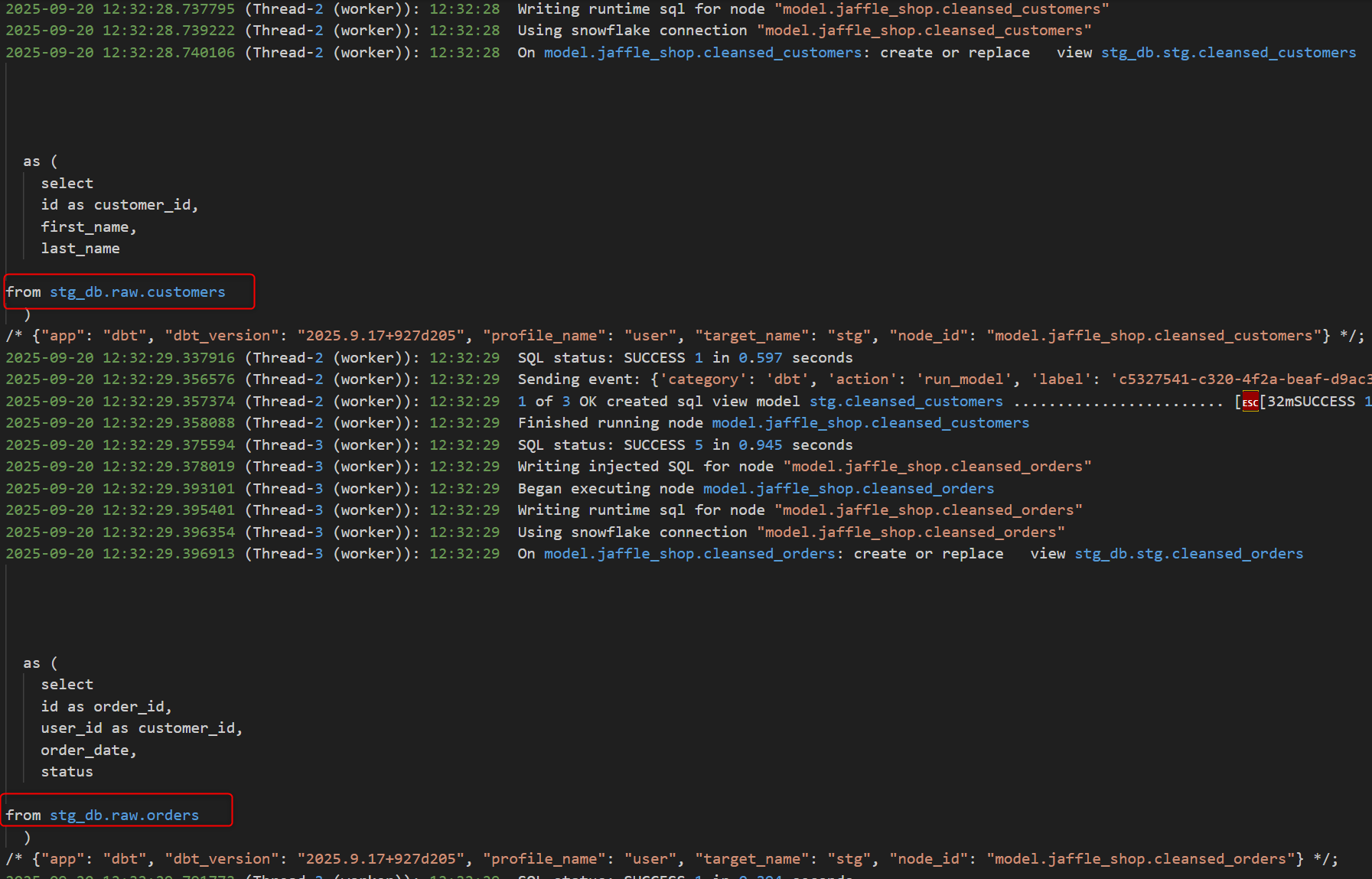
下図は、生データから次の加工段階のビューとなるモデル作成時のログですが、ソースで指定のデータベース スキーマ(dbt_<ユーザー名>_raw)から作成されていることが確認できます。
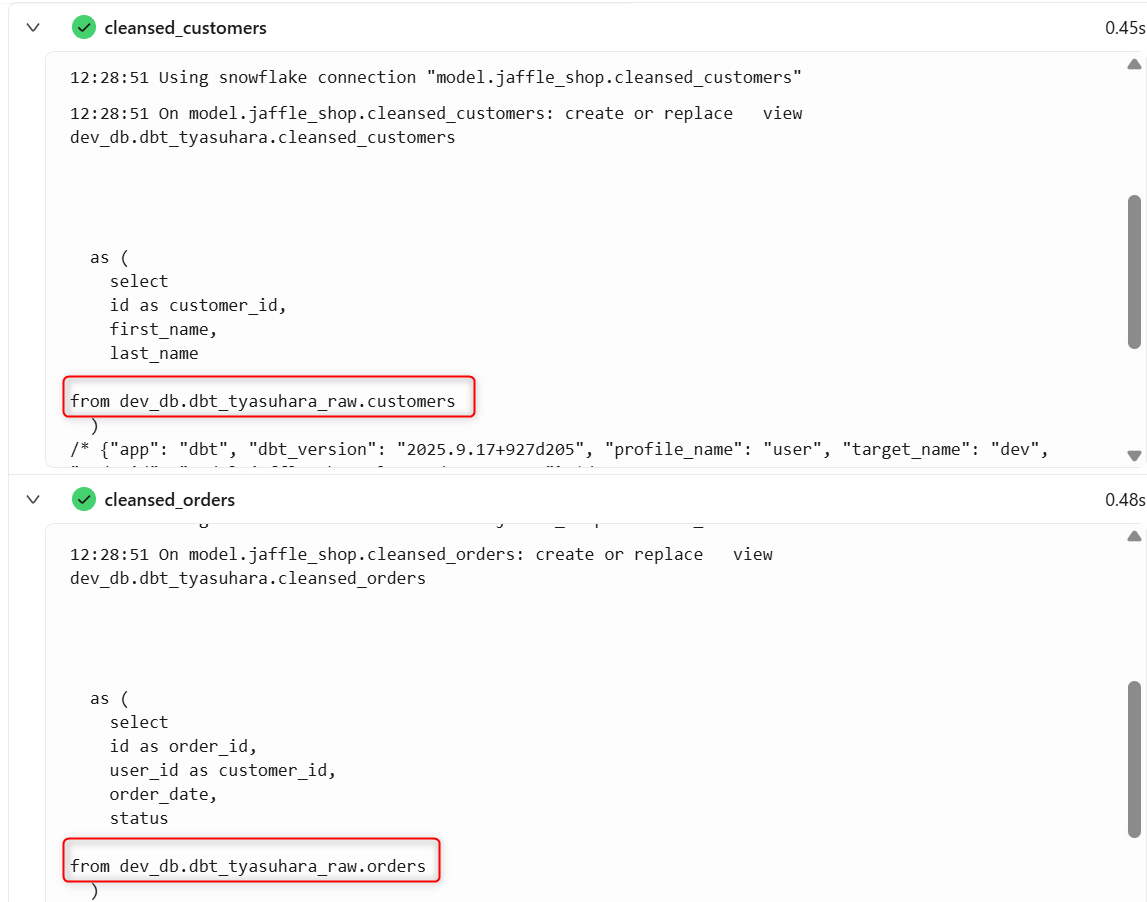
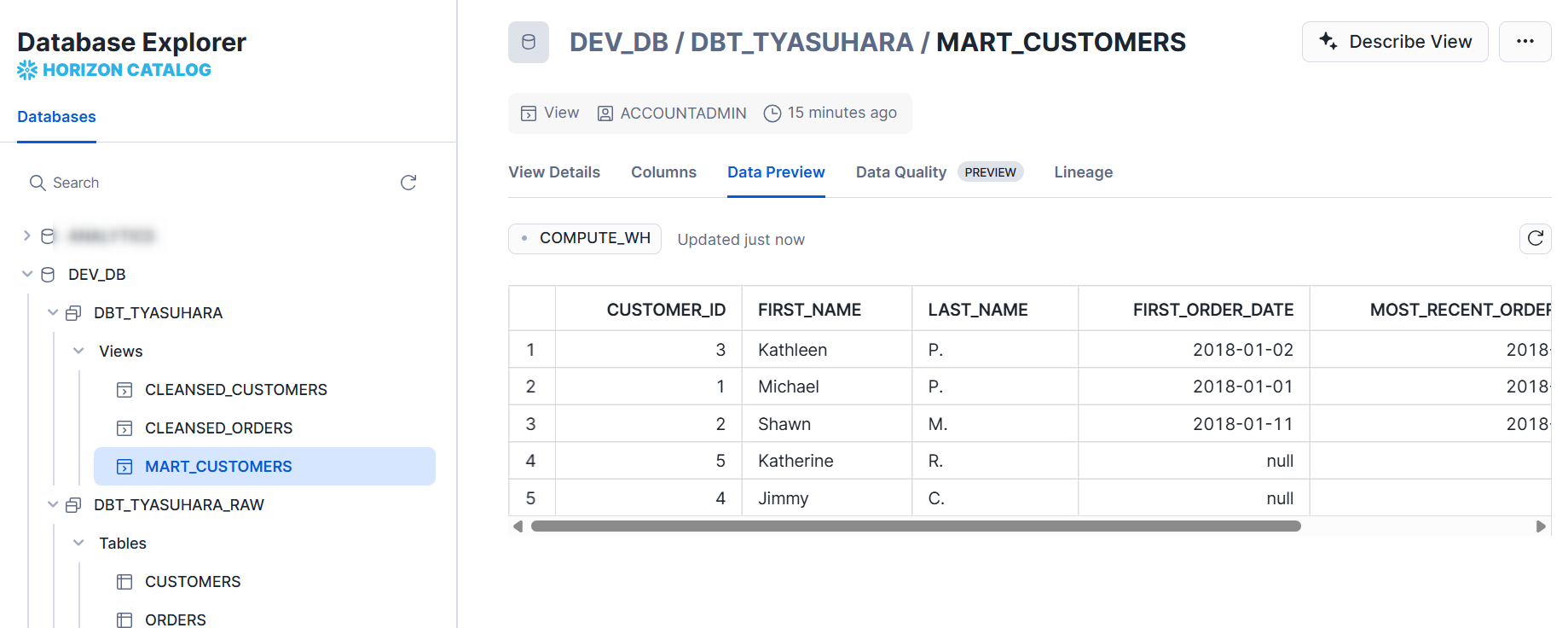
Snowflake 側で確認すると、開発環境アカウントのデフォルトスキーマで各種モデルが作成されています。最終的なマートテーブルを見ると、ここでは seed により作成されたテーブルを使用しているので、レコード数が限られています。
ステージング環境へのデプロイジョブを実行
変更をstgブランチにマージ後、ステージング環境へのデプロイジョブを実行します。
事前準備で、ステージング環境では本番環境相当のデータをロードしているため、最終的なマートテーブルを確認すると開発環境よりもレコード数が多いことが確認できます。
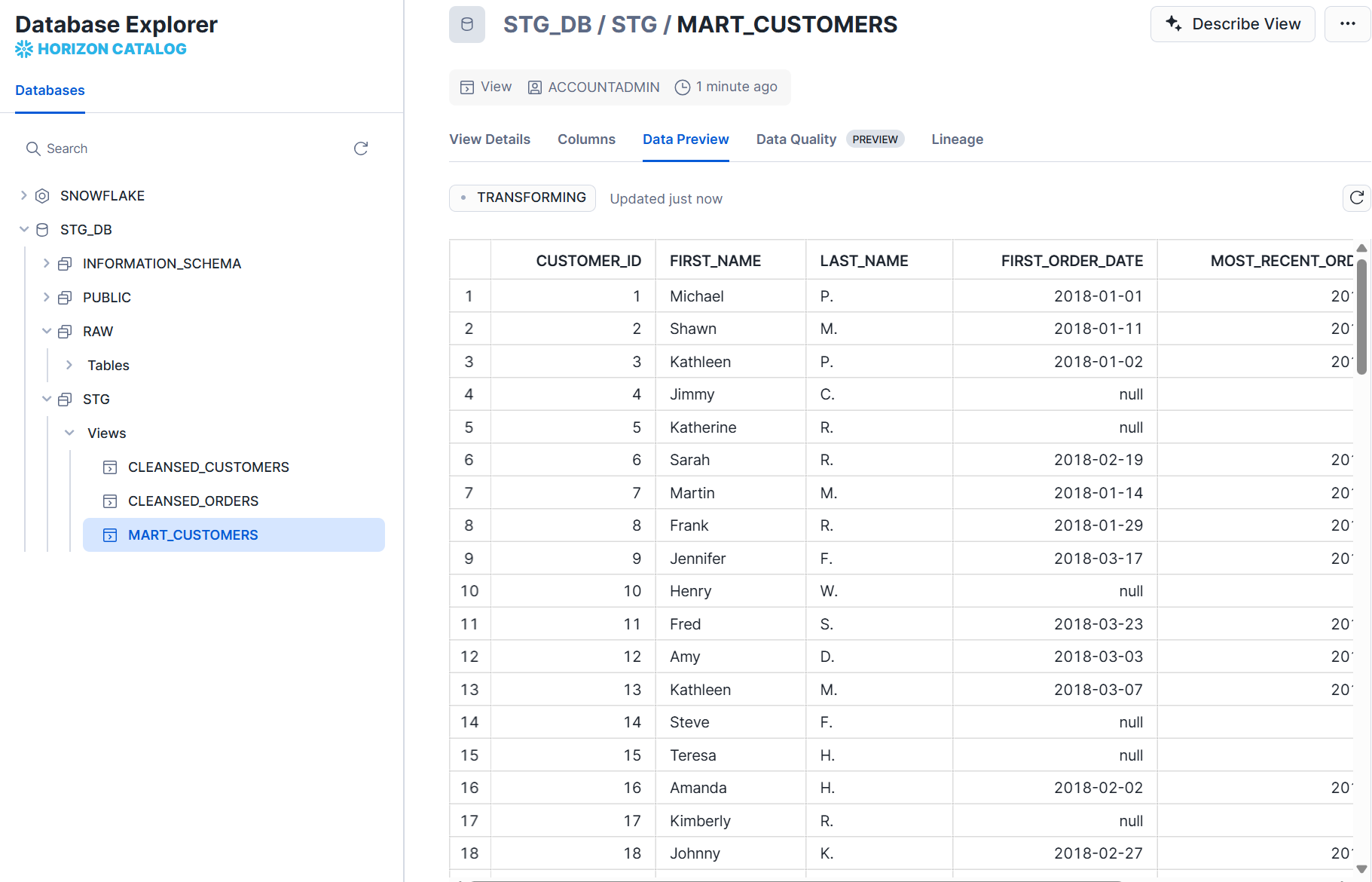
ジョブのログを確認すると、ソースの YAML ファイルで指定した通り、環境ごとのデータベース内のrawスキーマが参照されています。
ジョブではdbt buildを実行することとしていますが、今回の設定上、開発環境以外では seed のリソースは作成されません。
本番環境へのデプロイジョブを実行
変更を main ブランチへマージ後、同様に本番環境へのデプロイジョブを実行します。
最終的なマートテーブルは、開発環境よりもレコード数が多いことが確認できます。
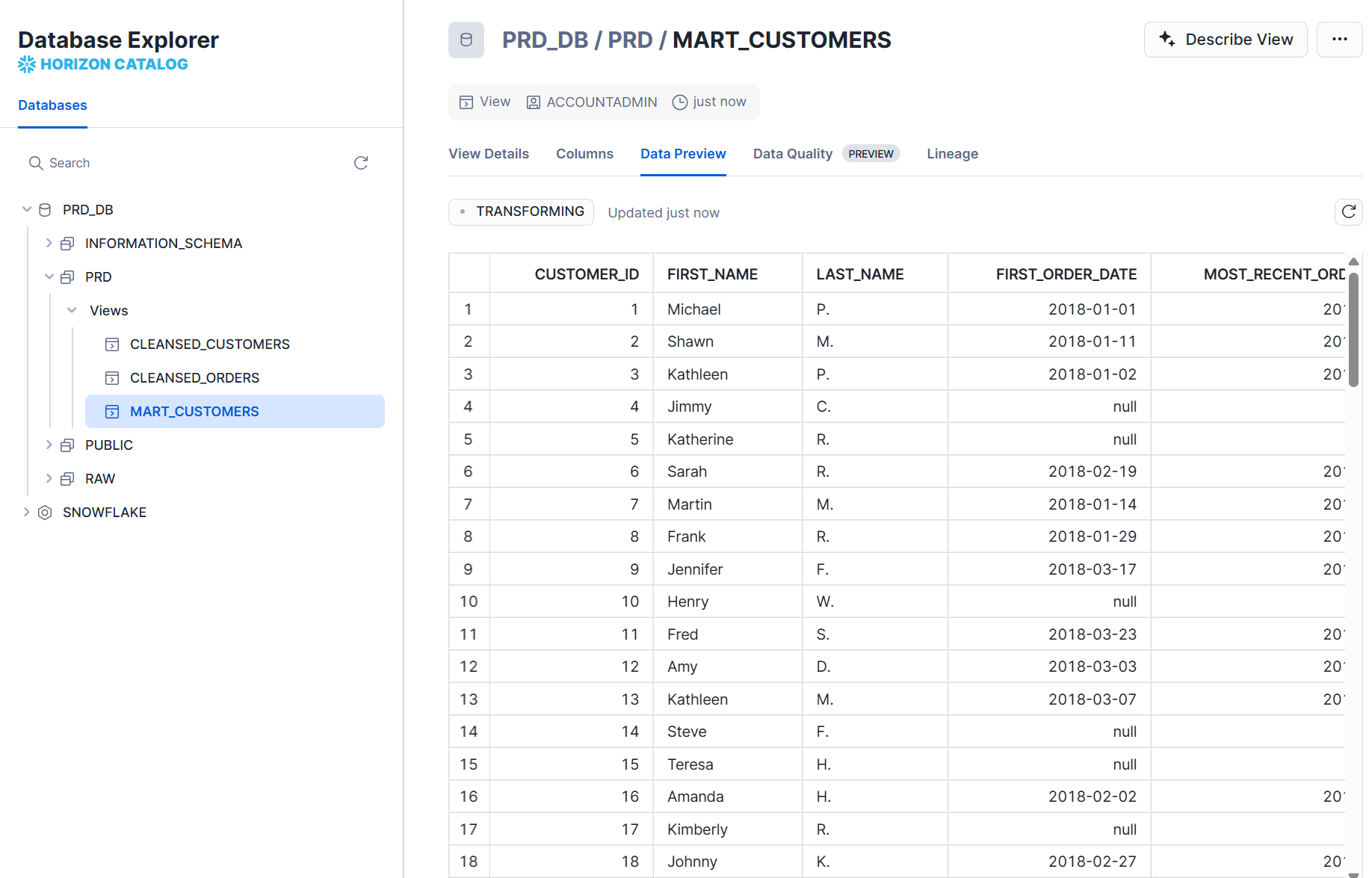
ジョブのログを確認すると、こちらもソースの YAML ファイルで指定した通り、環境ごとのデータベース内のrawスキーマが参照されています。
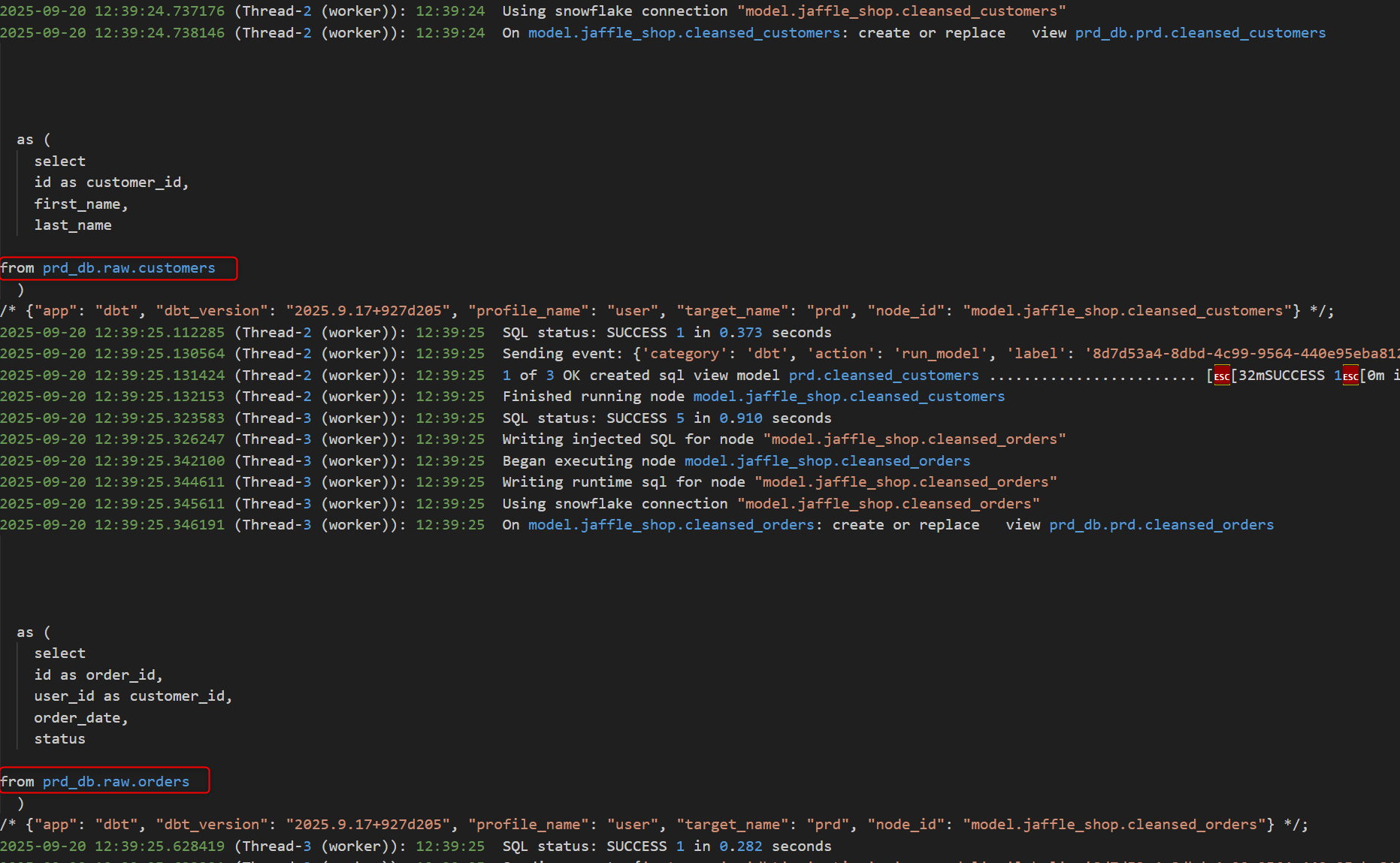
ステージング環境と同様に、今回の設定上、開発環境以外では seed のリソースは作成されません。
本番環境で Seed を有効化してみる
試しにdbt_project.ymlを以下のように変更し、本番環境で seed のリソースを有効化してみます。
seeds:
+enabled: "{{ target.name == 'dev' or target.name == 'prod' }}"
jaffle_shop:
+database: "{{ env_var('DBT_DATABASE') }}"
+schema: raw
本番環境へのデプロイジョブを実行すると、下図のように seed のリソースが作成されます。スキーマ名は{{ default_schema }}_{{ custom_schema_name | trim }}となります(前提条件より、デフォルトスキーマはprd)。
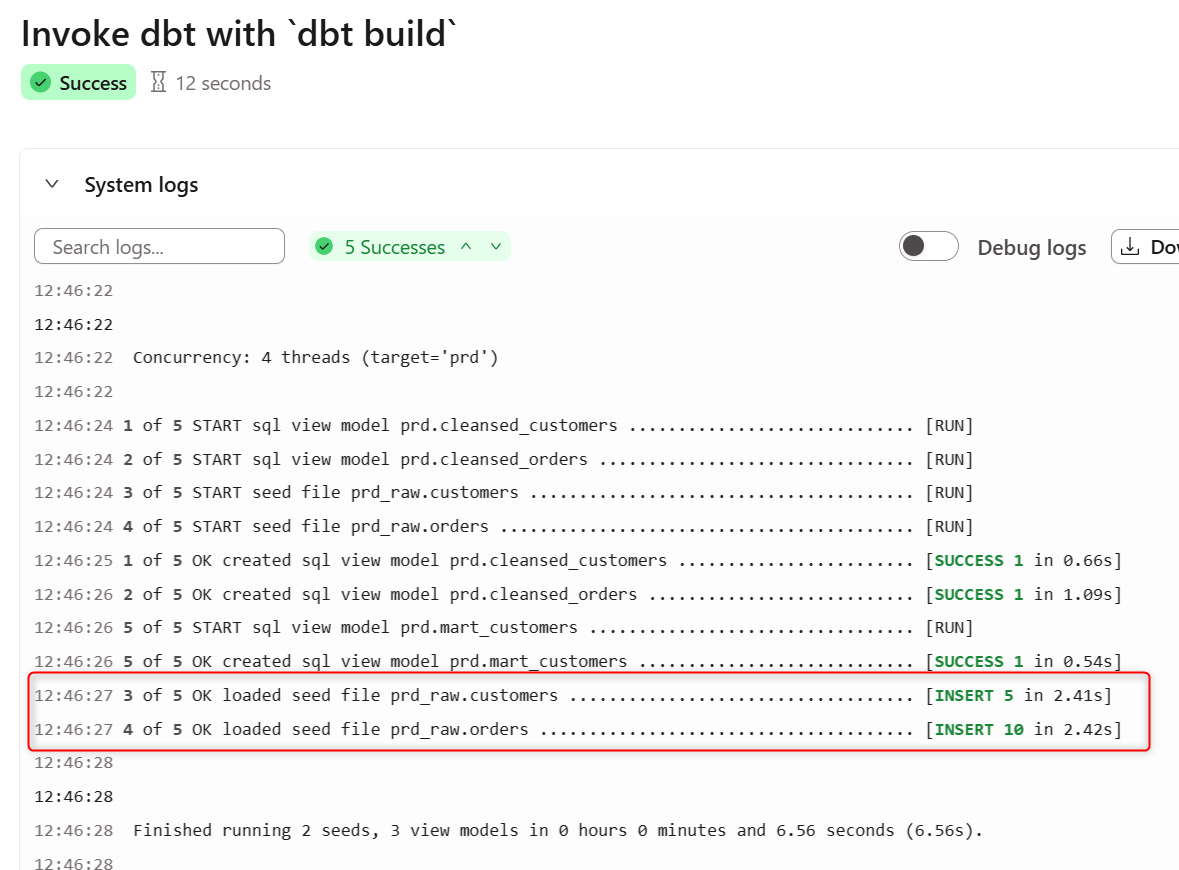
注意点として、ソースの場合、実行順は考慮されないようです(ソースとして seed で作成されるテーブルを参照する場合、事前に seed の実行が必要)。
さいごに
Seed で作成されるテーブルを開発環境でのみソースに指定してみました。
ここでは設定しませんでしたが、seed によって作成されるテーブルカラムのデータ型も指定可能です。
こちらの内容が何かの参考になれば幸いです。








