
Amazon Quick のデータセットにメタデータを付与する Dataset Enrichment を試してみた
クラウド事業本部の石川です。Amazon Quick に Dataset Q&A が導入されたタイミングで追加された、データセットにメタデータ(ビジネスコンテキスト)を付与する Dataset Enrichment を試してみました。
Dataset Q&A と Dataset Enrichment
Dataset Q&A は、ユーザーが自然言語で質問すると、システムが SQL を生成・実行して数秒で結果を返す機能です。トピックの事前設定やダッシュボードの構築を必要とせず、作成者が事前構成した範囲にとどまらずデータセットそのものを直接探索できます。
Dataset Enrichment は、トピック設定を必要とせずに、単一のデータセットに対してビジネスコンテキストを設定する方法です。
ビジネスコンテキストが Quick の外部(データカタログ、モデリングツール、チーム Wiki など)に既に存在する場合、作成者はそれをデータセットに対してファイルとして直接アップロードできます。フィールドの説明、フィールド間の意図された関係、特定の列またはデータセット全体に関するカスタム指示など、すべて業界標準フォーマット(YAML、JSON)またはプレーンテキストの指示として提供できます。システムはこのコンテキストをすべてのクエリに自動的に適用するため、作成者は一度定義するだけで、すべてのユーザーがその恩恵を大規模に受けることができます。
メタデータとして登録する情報
メタデータをデータセットに登録するには、下記の画面の説明とカスタム指示にそれぞれ入力するか、アップロードします。
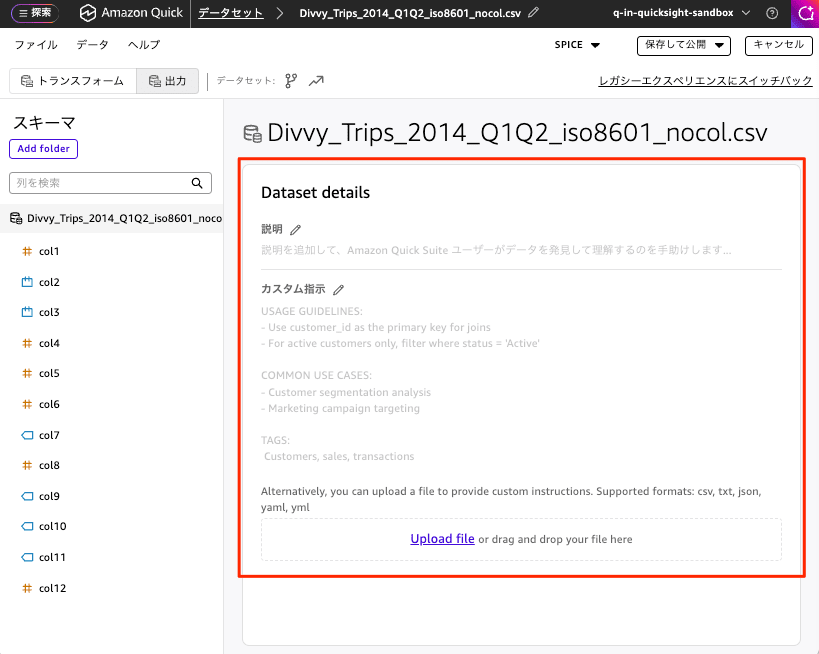
データセットの詳細
説明を追加して、Amazon Quick Suite ユーザーがデータを発見して理解するのを手助けする情報です。
カスタム指示
使用上のガイドライン
- 結合(JOIN)の際は、customer_id を主キーとして使用してください。
- アクティブな顧客のみを対象とする場合は、status = 'Active' でフィルタリングしてください。
一般的なユースケース
- 顧客セグメンテーション分析
- マーケティングキャンペーンのターゲティング
タグ
- 顧客、売上、取引
上記以外に、ファイルをアップロードして独自の指示を提供することも可能です。対応形式は csv、txt、json、yaml、yml です。
やってみた
検証データには Divvy(米シカゴのバイクシェアサービス)のトリップ実績データ(2014 年上半期、905,699 行・12 列)を使用します。メタデータの効果を分かりやすく確認するため、カラム名を col1〜col12 に変更し、カラム名からは内容を推測できない状態にしています。このデータセットに対して、メタデータを設定したテーブルと設定しないテーブルで効果を比較します。
メタデータの設定
「新しいエクスペリエンス」のデータエクスペリエンス画面で、[出力] タブを選択します。
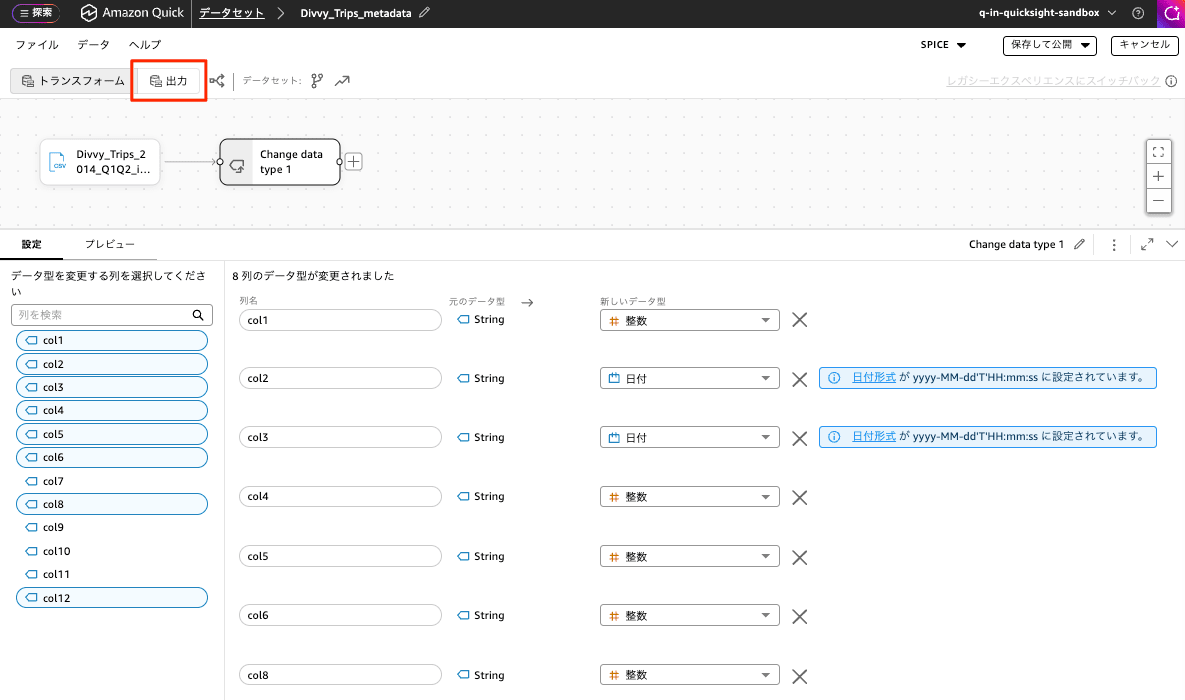
すると、Dataset details を登録する画面が表示されます。ここに下記のメタデータを設定します。
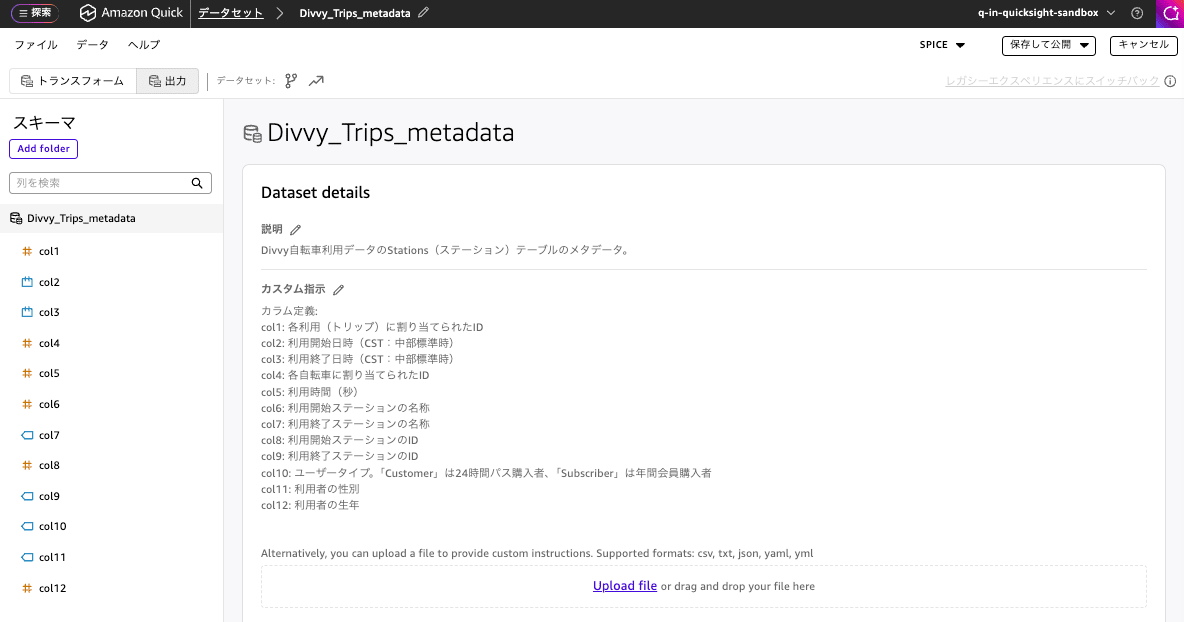
設定したメタデータは以下のとおりです。
説明
Divvy自転車利用データのStations(ステーション)テーブルのメタデータ。
カスタム指示
カラム定義:
col1: 各利用(トリップ)に割り当てられたID
col2: 利用開始日時(CST:中部標準時)
col3: 利用終了日時(CST:中部標準時)
col4: 各自転車に割り当てられたID
col5: 利用時間(秒)
col6: 利用開始ステーションのID
col7: 利用開始ステーションの名称
col8: 利用終了ステーションのID
col9: 利用終了ステーションの名称
col10: ユーザータイプ。「Customer」は24時間パス購入者、「Subscriber」は年間会員購入者
col11: 利用者の性別
col12: 利用者の生年
主なユースケース:
- 時系列の利用傾向分析(時間帯別・曜日別・月別)
- 会員(Subscriber)とカジュアル利用者(Customer)の行動比較
- ステーション人気度・出発/到着(経路)分析
- 利用時間の分布・外れ値の検出
- Subscriber の利用者属性分析(年齢・性別)
データセット QA の実行(メタデータ未適用)
まず、メタデータを設定していないデータセットに対して 各自転車に割り当てられたIDの下1桁が3のデータ数は? というプロンプトを実行します。
カラム名が col1〜col12 のため「自転車に割り当てられた ID」がどの列を指すのかが分からず、85,734件 という結果が返ってきました。回答には「自転車 ID として bike_id 列を使用した場合の件数です。もし別の ID 列(例: trip_id)を意図されていた場合はお知らせください」という注記も付いており、列の推測に確信が持てていないことがうかがえます。
続けて、実際に自転車 ID が格納されている col4 を明示して col4の下1桁が3のデータ数は? と尋ねると 90,128件 が返ります。つまり、自然言語の「自転車 ID」が正しい列(col4)にマッピングできておらず、誤った結果になっていたことが分かります。
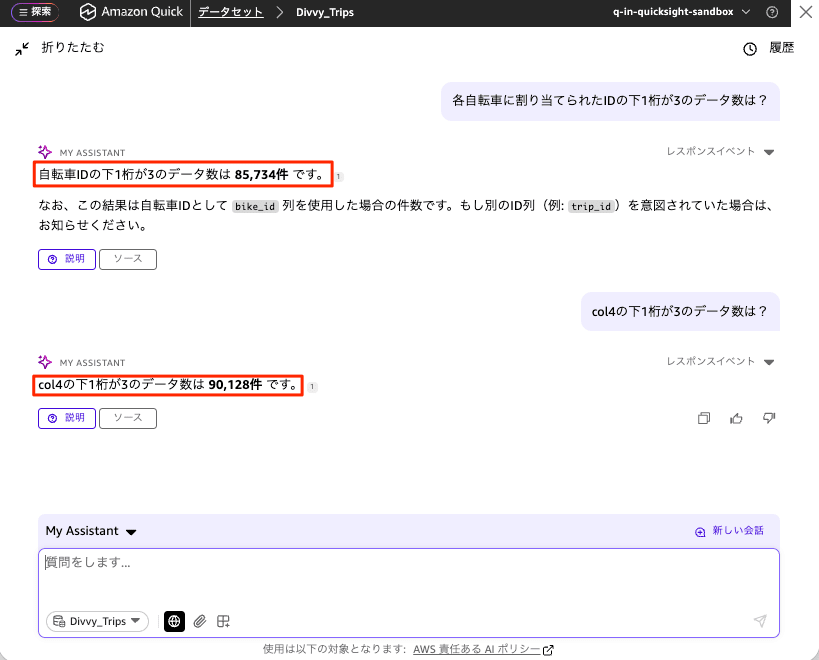
データセット QA の実行(メタデータ適用)
次に、col4: 各自転車に割り当てられたID というメタデータを設定したデータセットに対して、同じ 各自転車に割り当てられたIDの下1桁が3のデータ数は? というプロンプトを実行します。
今度は自転車 ID を col4 と正しく推測し、90,128件 という結果が返ってきました。回答には「全体 905,699 件のうち約 9.95% にあたり、下 1 桁が均等に分布していると仮定した場合の理論値(約 90,570 件)に近い水準」という補足も付いています。念のため col4の下1桁が3のデータ数は? と列を明示して尋ねても「先ほどの回答と同じ結果になります」として同じ 90,128件 を返しており、自然言語のプロンプトと列指定の結果が一致しました。
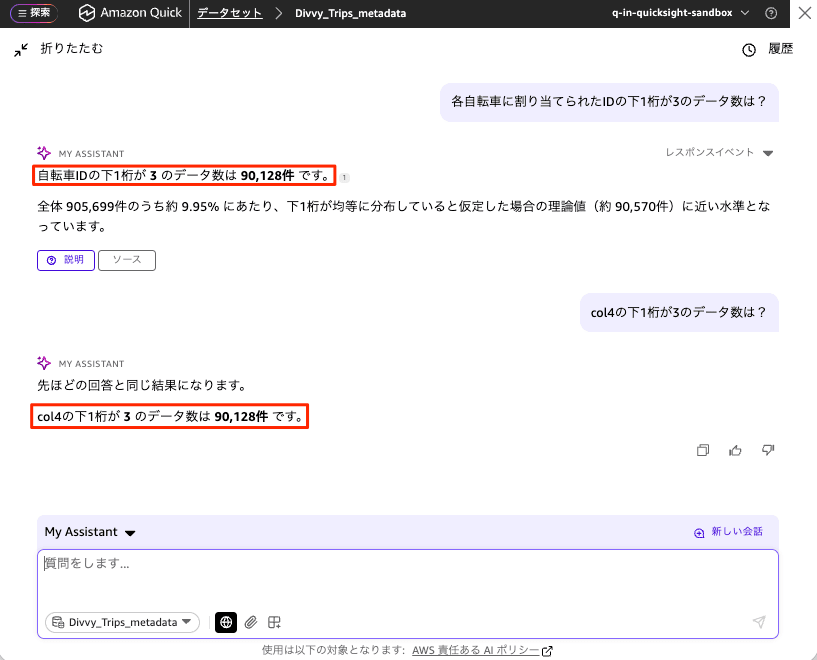
比較結果
同じプロンプト 各自転車に割り当てられたIDの下1桁が3のデータ数は? に対する結果をまとめると、以下のとおりです。
| 条件 | 自然言語プロンプトの結果 | col4 を明示した結果 | 一致 |
|---|---|---|---|
| メタデータ適用前 | 85,734 件 | 90,128 件 | 不一致(誤り) |
| メタデータ適用後 | 90,128 件 | 90,128 件 | 一致(正しい) |
メタデータ適用前は自然言語の「自転車 ID」を正しい列に結び付けられず、列を明示した場合と異なる値になっていました。メタデータを設定したことで、col4 が自転車 ID であると認識され、自然言語のプロンプトでも列指定と同じ正しい結果が得られています。
最後に
カラム名から内容を推測できないデータセットでは、自然言語のプロンプトと実際の列との対応付けが曖昧になり、誤った結果につながることがあります。今回試した Dataset Enrichment では、各列の意味をメタデータとして一度設定するだけで、Dataset Q&A がその対応付けを正しく解釈し、同じプロンプトでも正しい結果を返すようになりました。
物理的なカラム名がビジネス用語と乖離しているデータセットほど、メタデータ付与の効果は大きくなります。今回はカラム定義を中心に検証しましたが、Dataset Enrichment ではフィールド間の関係やカスタム指示も設定できるため、利用者区分での絞り込みや単位(秒)の扱いといった、より複雑な前提を伴うプロンプトでの効果も今後検証していきたいところです。










