
OllamaとOpenCodeでローカルAIコーディング環境を構築してみた
現在各社がしのぎを削ってAIの精度を高め合っている。その結果、AIシステムの運用コストは増加傾向にあり、将来的に定額制から従量課金制への移行が進むのではないかと考えている。
現在 Claude Pro を個人利用しているが、実際にコスト圧力の兆候は見え始めている。2026年3月にはピークタイム(平日のPT 5:00〜11:00)にセッション制限の消費速度が引き上げられたほか、5時間ごとのセッション制限とは別に週単位での計算リソース使用量にも上限が設けられている。今後さらに定額制プランの制限が強まる、あるいは従量課金へ移行する可能性は否定できない。そのとき慌てて移行先を探さなくても良いように、ローカルLLMを触ってみることにした。
本記事では、ローカルLLMの実行環境としてOllamaを、AIコーディングエージェントとしてOpenCodeをインストールし、完全にローカルで動作するAIコーディング環境を構築する手順を紹介する。
検証環境
- MacBook Pro (M1 Pro / 32GB)
- macOS 26.4 (25E246)
- Ollama 0.20.5
- OpenCode 1.4.3
- gemma4:26b(Ollama経由で実行)
Ollama とは
Ollamaは、ローカル環境でLLMを実行するためのオープンソースツールである。Meta LlamaやGoogle Gemmaなど、さまざまなオープンソースモデルをコマンドひとつでダウンロード・実行できる。
OpenCode とは
OpenCodeは、オープンソースのターミナルベースAIコーディングエージェントである。Claude CodeやGitHub Copilot CLIと同様に、ターミナル上で自然言語の指示に基づいてコードの作成・編集をおこなう。
OpenCodeの特徴は、75以上のLLMプロバイダに対応している点だ。OpenAI、Anthropic、Googleといったクラウドのモデルに加え、Ollamaを通じてローカルで動作するモデルも利用できる。つまり、外部のAPIに依存せず、完全にローカルでAIコーディングエージェントを動作させられる。
手順1:Ollama をインストールする
まずはOllamaをインストールする。Homebrew でもインストールできるようだが、公式GitHubのREADME.md には、公式が推奨するインストールスクリプトを使ってインストールする方法が紹介されていたので、こちらの方法を利用する。
curl -fsSL https://ollama.com/install.sh | sh
インストールが完了したら、Ollamaを起動する。
ollama
ターミナル上で Ollama のメニューが表示される。
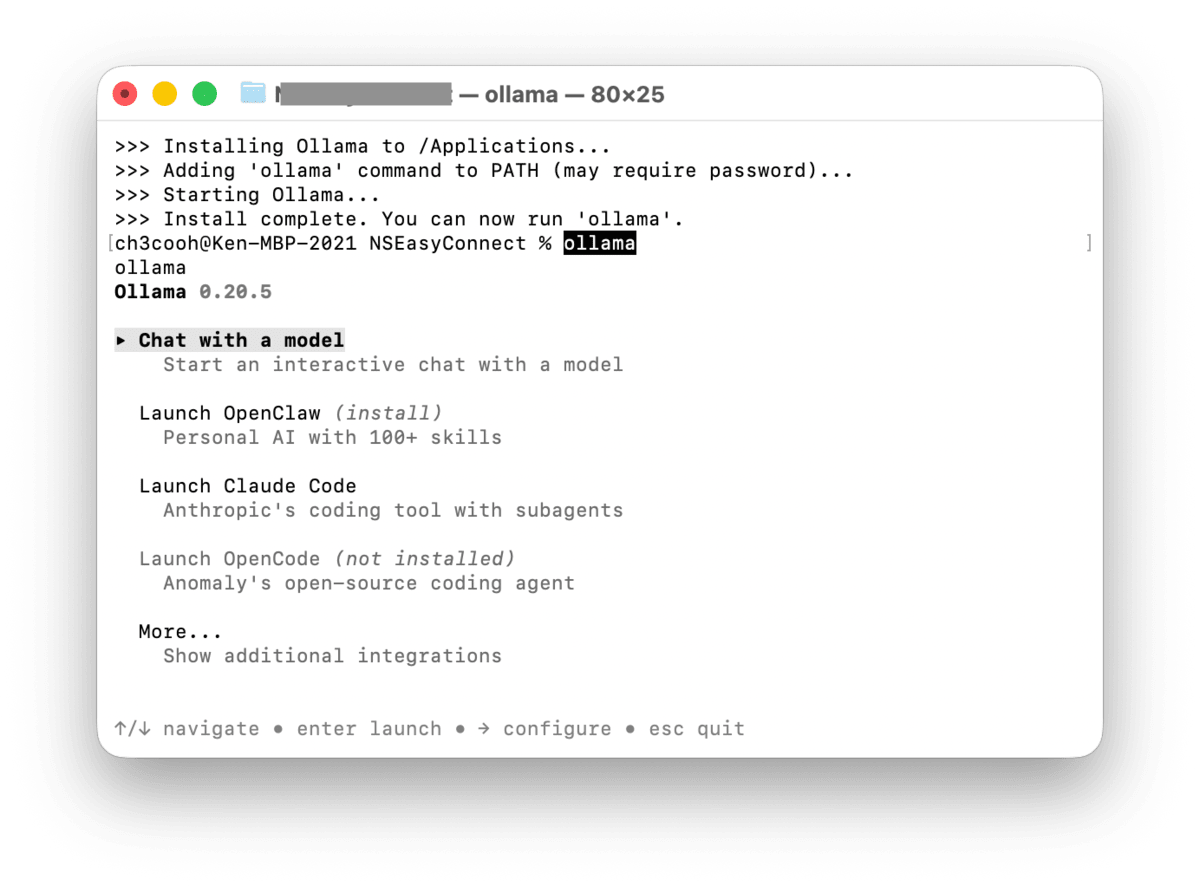
Chat with a model を選択すると、いくつかのモデルから選択できる。今回はローカルLLMを試したいので、gemma4を選択する。
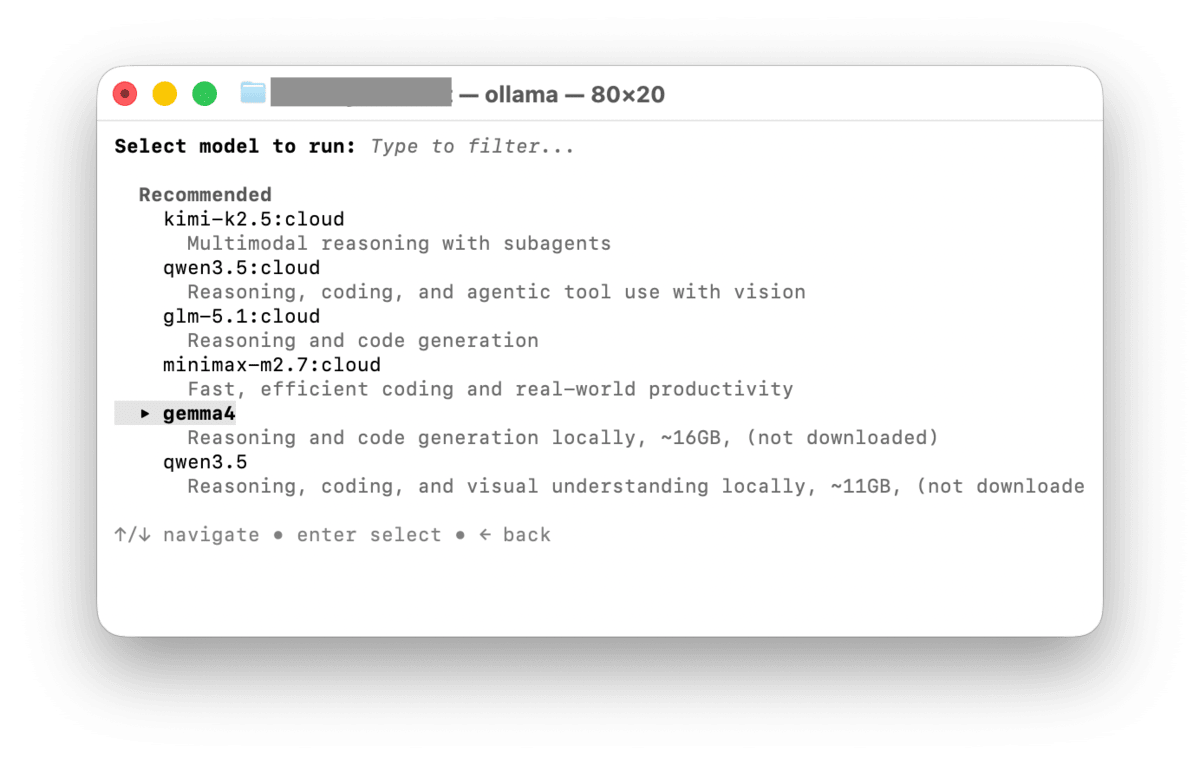
ダウンロードが完了すると、そのままチャットが開始される。正常に応答が返ってくれば、Ollamaのインストールは成功だ。

一旦 /exit と入力して、Ollamaを終了させる。
手順2:モデルをダウンロードする
手順1のセットアップでは初回起動時のインタラクティブな選択でモデルをダウンロードしたが、OpenCodeで使用するモデルはパラメータサイズを明示的に指定してダウンロードする。
今回はgemma4:26bを使用する。gemma4はGoogleがGeminiをベースに公開しているオープンモデルで、2026年4月にリリースされたばかりの新しいモデルだ。後述するが、レスポンス速度が速く、ローカル実行でも快適に利用できる点が選定の理由である。
ollama pull gemma4:26b
ダウンロードが完了したら、動作確認をおこなう。
ollama run gemma4:26b "こんにちは。あなたはどのモデルですか?"

なお、qwen3.5:27bも試したが、私の環境ではレスポンスが遅くて使い勝手が悪いように感じた。対してgemma4:26bはレスポンスが速くて、それなりに正しい推論をおこなってくれているように思える。この辺りはメモリ容量の多寡によってパフォーマンスが変わるだろう。
qwen3.5についてはコーディング性能が高いと評価されているようなので、後日改めて試してみたいと考えている。
手順3:OpenCode をインストールする
次に、OpenCodeをインストールする。
curl -fsSL https://opencode.ai/install | bash
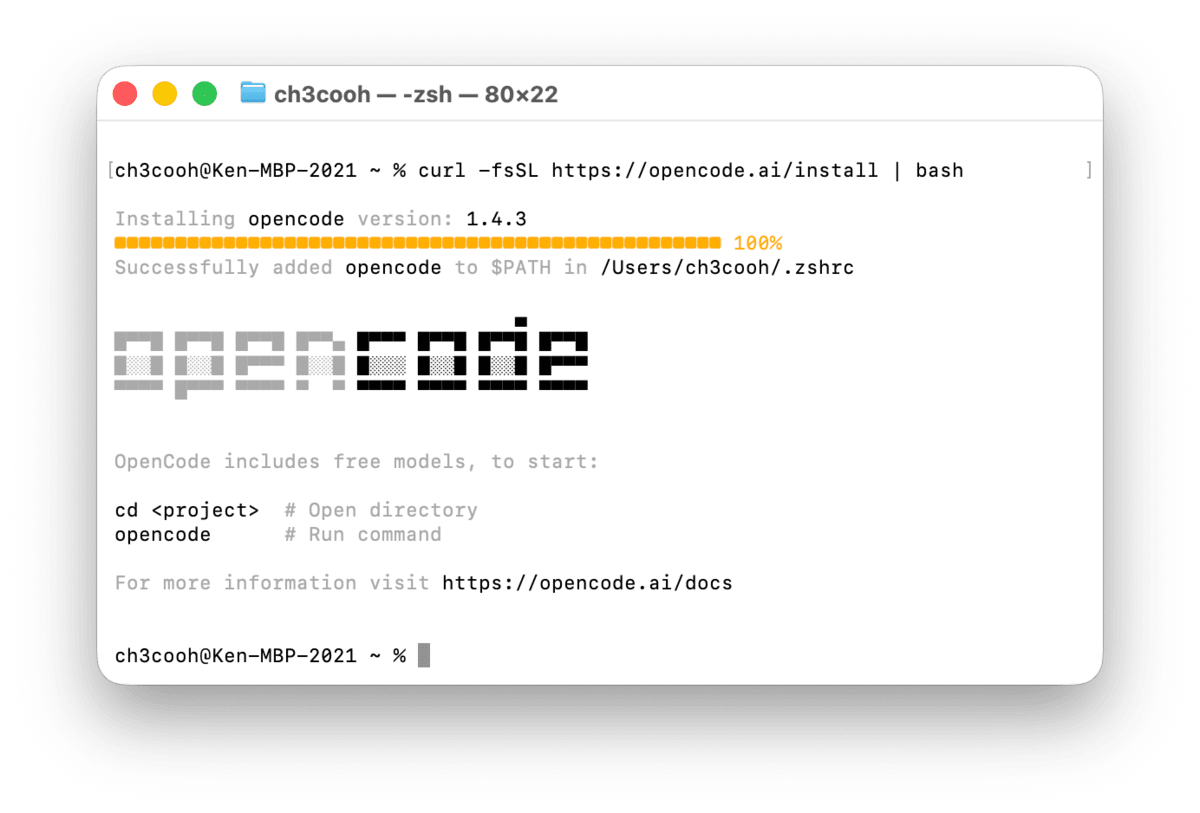
インストールが完了したら、バージョンを確認する。
opencode --version
1.4.3
手順4:OpenCode の設定
OpenCodeでOllamaのモデルを利用するには、設定ファイルを作成する必要がある。プロジェクトのルートディレクトリ、またはグローバル設定として~/.config/opencode/opencode.jsonに以下の内容を記述する。
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"gemma4:26b": {
"name": "Gemma 4 26B"
}
}
}
}
}
設定のポイントは以下の通りだ。
npmにはOpenCodeが内部で使用するAI SDKのプロバイダパッケージを指定する。Ollama連携では@ai-sdk/openai-compatibleを使用する。このパッケージはOpenCodeが自動でインストールするため、手動でのインストールは不要だbaseURLはOllamaのOpenAI互換エンドポイント(http://localhost:11434/v1)を指定する。Ollamaのネイティブエンドポイント(/api)ではなく、/v1を使う点に注意modelsにはOllamaでダウンロード済みのモデル名を指定する
Ollamaのデフォルトコンテキストウィンドウは、利用可能なVRAMによって異なる。今回の検証環境(32GBユニファイドメモリ)では32Kトークンがデフォルトとなった。変更したい場合はOllamaのnum_ctxパラメータで調整できる。
手順5:動作確認
Ollamaが起動していることを確認した上で、OpenCodeを起動する。
opencode
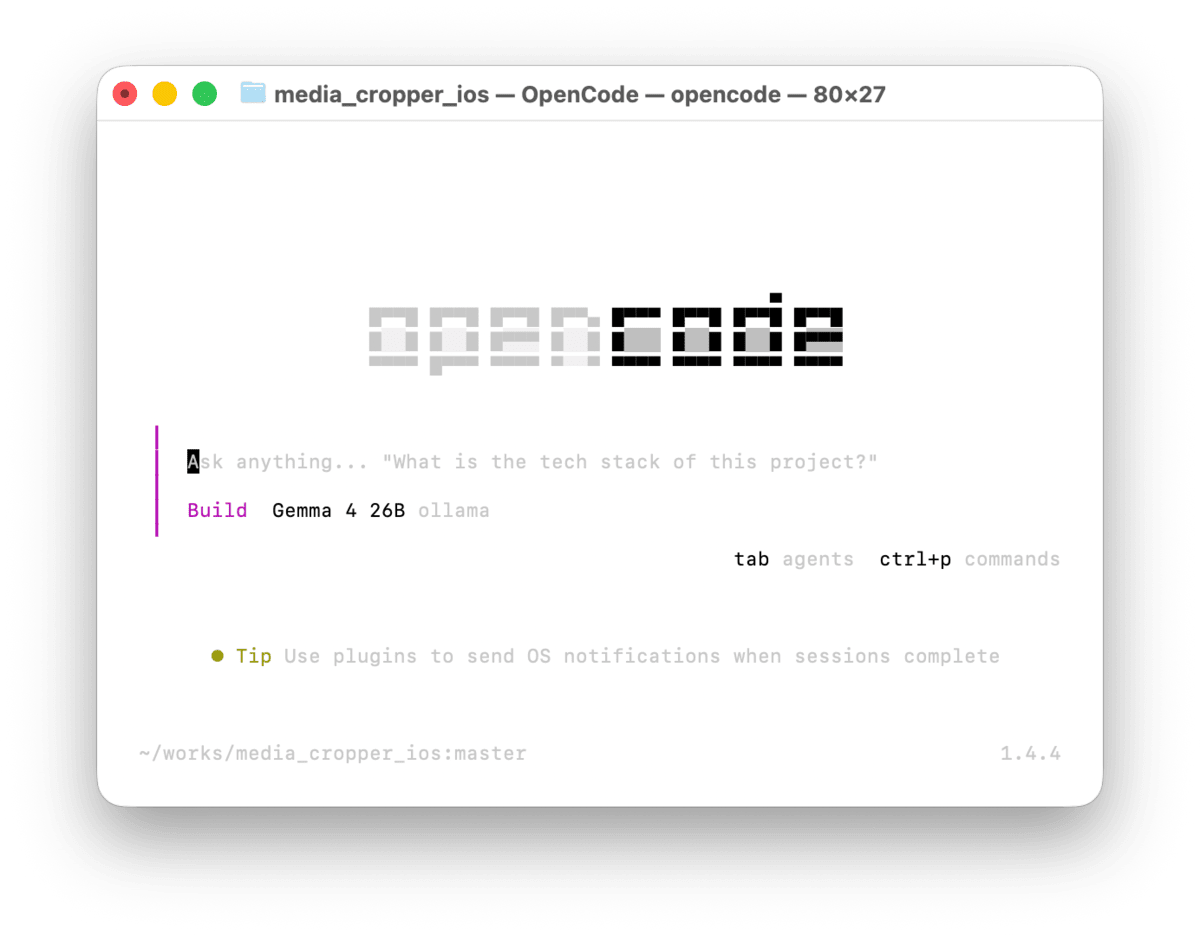
起動後、/models を入力して、Ollamaのgemma4:26bが選択肢に表示されていれば、設定は正しく反映されている。
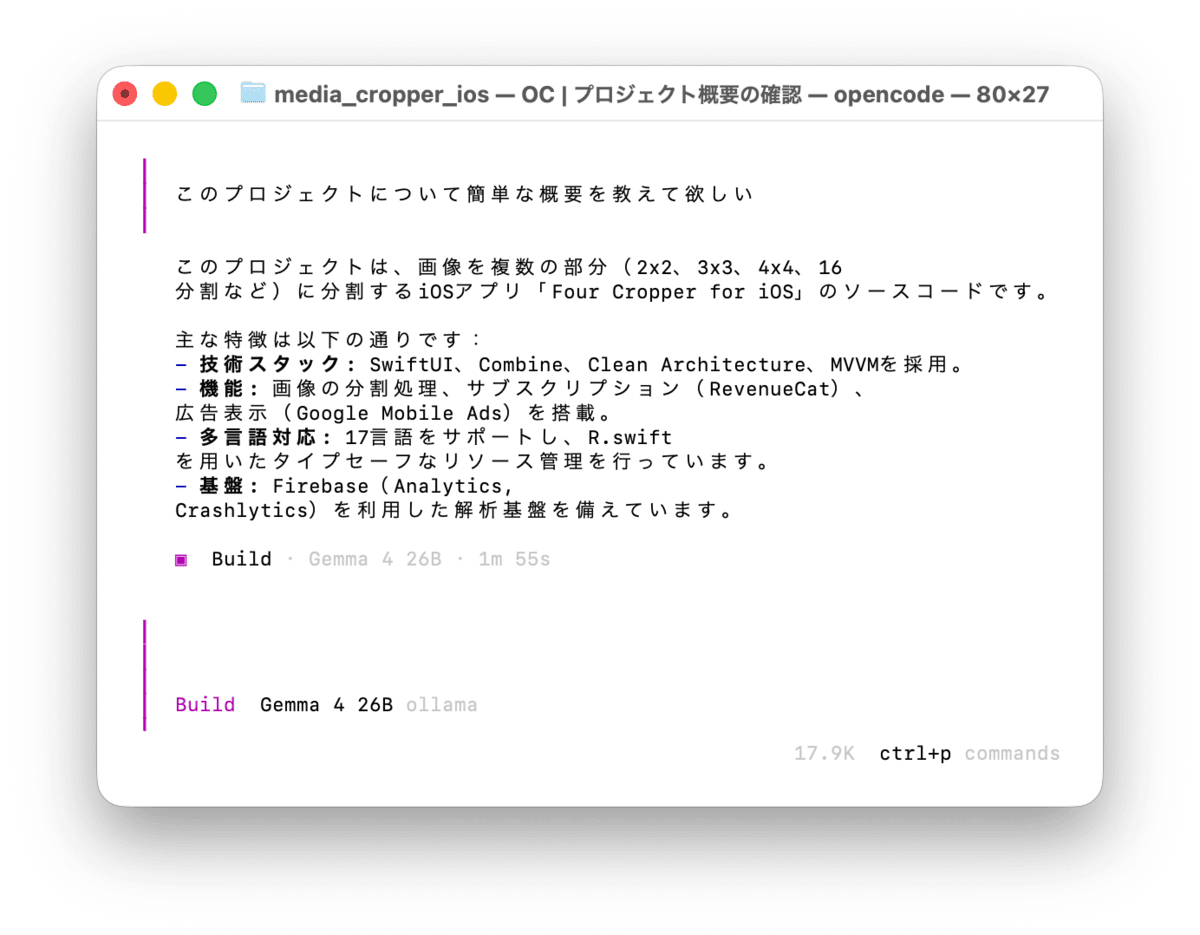
適当なプロンプトを入力して、ローカルモデルで応答が返ってくることを確認した。
まとめ
OllamaとOpenCodeを組み合わせて、ローカルで動作するAIコーディング環境を構築する手順を紹介した。
ローカルLLMはクラウドのモデルと比較すると精度は劣るが、インターネット接続が不要で、APIの利用料金もかからない。個人開発でのちょっとしたコード生成や、プライバシーが重要なプロジェクトでの利用には十分な選択肢だと考えている。
今回使用したgemma4:26bは、期待していたほどコーディング用途には使えなかったが、通常の質問応答や調べものには十分実用的だと感じている。今後は通常利用で活用していきたい。コーディング性能が高いと評価されているqwen3.5:27bなど、他のモデルも改めて試していきたいと考えている。
クラウドサービスの将来的な価格変動に備えて、ローカルLLMの環境を整えておくことは無駄にはならないだろう。同じようにローカルLLMの導入を検討している方の参考になれば幸いだ。
参考資料
求人情報: クラスメソッドでは iOSエンジニアを募集しています
スターバックスデジタルテクノロジー部では、iOSアプリ開発のできるエンジニアを募集しています。misc-iosなどで、新しいXcodeやiOSの機能についてあれこれ共有しながら一緒に働いてくれる方の応募をお待ちしております!
その他の領域でもiOS/Androidエンジニアを募集しています。一緒にモバイルアプリ開発についてお話ししましょう!









