
Aqua Voice × Claude Cowork:毎週の自動分析で音声入力のカスタマイズを仕組み化する
こんにちは、けーまです。
音声入力を使ったことはあるでしょうか?
私自身、最近はほとんどの業務を音声入力で済ませていて、タイピングする時間がかなり減りました。
ただ、固有名詞や技術用語が誤認識される、自分の口癖や言い回しのクセがそのままテキストに残ってしまう、という悩みがあります。
私が使っている Aqua Voice では、dictionary(辞書)・replacements(置換)・customInstructions(カスタム指示)の3つの機能で精度をカスタマイズできますが、これを毎回自分で考えて登録するのは結構な手間です。
そこで本記事では、Aqua Voice の音声入力ログを Claude に分析させて、dictionary・replacements・customInstructions の改善提案を毎週自動で受け取る仕組みを取り上げます。
Claude Code の Cowork スケジュール機能と Slack 通知を利用しています。
音声入力の精度を継続的に高めたい方の参考にしていただければと思います。
Aqua Voiceとは?
Aqua Voice をご存じない方もいると思うので、簡単に紹介します。
Aqua Voice は Mac / Windows / iOS / Chrome 拡張で使える音声入力アプリです。
料金プランは Free(Starter)・Pro($8 / 月、年払い)・Team($12 / 月、年払い)・Enterprise の4種類があり、customInstructions や 800 件までの Custom Dictionary は Pro プラン以上で利用できます。
引用元: Aqua Voice - Fast and Accurate Voice Dictation for Mac and Windows | Aqua Voice
Starter プランの記載には Custom Instructions が含まれず、Pro プランの記載で初めて Tune with Custom Instructions が登場するため、customInstructions を使うには Pro プラン以上の契約が必要です。
Aqua Voice には Avalon という技術用語を高精度に認識できるモデルがあります。
私のように IT の単語を音声入力する機会が多い人にとっては、誤認識が少なく快適です。
さらに、認識結果を自分用にカスタマイズするための機能が3つあります。
- dictionary(辞書):固有名詞や専門用語を登録して、誤認識を減らす(例:
AgentCoreをカタカナで「エージェントコア」と認識されるのを防ぐ) - replacements(置換):特定の発話フレーズを別のテキストに丸ごと置き換える(例:「メアド」と話したら
taro.yamada@example.comと入力される) - customInstructions(カスタム指示):文字起こし結果のスタイル・文体・整形ルールを自然言語で指定する(例:フィラー除去、改行コマンドの扱い、文体の統一)
この3機能を使うことで、音声入力の精度を自分の使い方に合わせて伸ばしていけます。
重要: カスタム指示(
customInstructions)を正しく動作させるには、設定画面で ストリーミングモードを「Always(常に)」 に変更してください。デフォルトのままだとカスタム指示が反映されない場合があります。
今回実装すること
customInstructions・dictionary・replacements のメンテナンスは、自分の音声入力のクセや誤認識傾向を観察しながら手作業で更新する必要があり、結構な手間がかかります。
そこで本記事では、その手間を Claude に肩代わりさせる仕組みを作ります。
具体的には、1週間に1回、Aqua Voice の音声入力ログを Claude に投げて、
- どの単語を dictionary に追加すべきか
- どの発話フレーズを replacements に登録すべきか
- どんなスタイル指示を customInstructions に加えるべきか
を分析させて、その提案を Slack に通知させます。
週次の自動実行には、Claude Code の Cowork スケジュールタスク を使います。
全体像
実装する仕組みの全体像は以下のとおりです。
要点:
- Mac 側の常時処理(5分ごと):Aqua Voice の
settings.jsonに新しい履歴が増えるたびに、aqua_archive.pyが差分を取り、別フォルダにミラーする - Cowork 側の週次処理:先週分のログと、現在の Aqua Voice 設定を読み込んで Claude が分析。改善提案をナレッジベースに保存しつつ、Slack の DM に通知
- わたしの作業:Slack で届いた提案を確認し、必要なものだけ Aqua Voice の UI に手動で登録する(自動反映はしない設計)
設定手順
設定手順は次の2ステップです。
本記事のパスや設定値は、プレースホルダで表記しています。以下の表に合わせて、ご自身の環境に置き換えてください。
| プレースホルダ | 置き換える内容 |
|---|---|
<YOUR_USER> |
macOS のユーザー名(例: taro.yamada) |
<ARCHIVE_PATH> |
音声ログのアーカイブ保存先(絶対パス)。Cowork から読める場所であれば任意のフォルダで OK。例: /Users/taro.yamada/Documents/aqua-voice-archive |
<KNOWLEDGE_PATH> |
分析結果のナレッジ保存先(絶対パス)。例: /Users/taro.yamada/Documents/aqua-voice-knowledge |
<YOUR_SLACK_EMAIL> |
Slack 通知先の自分のメールアドレス |
0. 前提環境
以下を満たしている前提で進めます。
- macOS(本記事では Darwin 25.5 で検証)
- Aqua Voice のインストールと Pro プラン契約(
customInstructionsを使うには Pro プランが必要です) - Aqua Voice の Streaming Mode を「Always」 に設定済み(Mac の場合のみ。
customInstructionsを動作させるために必要) - Claude Code の Cowork が使える環境
- Cowork セッションに Slack MCP が接続済み(Claude Code の MCP 設定から Slack コネクタを有効化しておく)
- Python 3 が
/usr/bin/python3で利用できること(macOS 標準)
1. 音声ログを別フォルダに自動アーカイブする仕組みを作る
Aqua Voice の音声ログは ~/Library/Application Support/Aqua Voice/settings.json の history キーに保存されていますが、直近100件で FIFO 上書きされるため、放置すると約22時間で古いログが消えていきます。
これを消える前に Cowork から読めるフォルダ へ吸い出すスクリプトと、それを定期実行する launchd を仕込みます。本記事では保存先を <ARCHIVE_PATH> というプレースホルダで表記します(~/Documents/aqua-voice-archive/ 等の通常フォルダで構いません)。
補足: なぜ
~/Library/Application Support/から直接読まないかというと、Cowork のスケジュールタスクは サンドボックス制約で~/Library/Application Support/を読めないためです。読めるパス(~/Documents/~/Downloads/~/Library/CloudStorage/...など)にミラーする必要があります。
1-1. アーカイブスクリプトを配置する
アーカイブ用ディレクトリを作成し、Python スクリプトを置きます。
mkdir -p "$HOME/Library/Application Support/aqua-voice-archive/data"
$HOME/Library/Application Support/aqua-voice-archive/aqua_archive.py を作成して、以下を貼り付けてください。スクリプト中の <ARCHIVE_PATH> をご自身が選んだ保存先の絶対パスに書き換えてください。
aqua_archive.py の全文(クリックすると展開します)
#$HOME/Library/Application Support/aqua-voice-archive/aqua_archive.py
"""
Aqua Voice の文字起こし履歴を指定フォルダに永続アーカイブするスクリプト。
settings.json の history 配列を読み、未保存エントリを timestamp に応じた
週フォルダ別の history.jsonl に追記する。
さらに dictionary / replacements / customInstructions などの主要設定を
settings-snapshot.json にミラーする(Cowork から参照できるようにするため)。
"""
import json
import os
import sys
import traceback
from datetime import datetime, timedelta, timezone
from pathlib import Path
HOME = Path.home()
SETTINGS_PATH = HOME / "Library/Application Support/Aqua Voice/settings.json"
# アーカイブ保存先(Cowork から読める場所であれば任意のフォルダで OK)
ARCHIVE_DIR = Path("<ARCHIVE_PATH>")
SNAPSHOT_PATH = ARCHIVE_DIR / "snapshot.json"
SETTINGS_SNAPSHOT_PATH = ARCHIVE_DIR / "settings-snapshot.json"
DATA_DIR = ARCHIVE_DIR / "data"
# settings.json から保存対象とする主要キー
SETTINGS_SNAPSHOT_KEYS = [
"dictionary",
"replacements",
"customInstructions",
"transcriptionModel",
"language",
"deepContext",
"casualMessaging",
"promptSet",
"computerControlCustomInstructions",
]
# JST (UTC+9) 固定。Aqua Voice の timestamp は UTC なので変換が必要
JST = timezone(timedelta(hours=9))
def parse_iso_to_jst(iso_str: str) -> datetime:
"""ISO 8601 文字列を JST の datetime に変換。'Z' サフィックス対応。"""
normalized = iso_str.replace("Z", "+00:00")
dt_utc = datetime.fromisoformat(normalized)
return dt_utc.astimezone(JST)
def week_folder_name(dt_jst: datetime) -> str:
"""JST の datetime から月曜起点の週フォルダ名を生成 (YYYY-MMDD_YYYY-MMDD)。"""
days_since_monday = dt_jst.weekday()
monday = dt_jst.date() - timedelta(days=days_since_monday)
sunday = monday + timedelta(days=6)
return f"{monday.strftime('%Y-%m%d')}_{sunday.strftime('%Y-%m%d')}"
def collect_known_session_ids() -> set[int]:
"""data/ 配下の全 history.jsonl から既知の sessionId を収集。"""
known: set[int] = set()
if not DATA_DIR.exists():
return known
for jsonl_path in DATA_DIR.glob("*/history.jsonl"):
try:
with jsonl_path.open("r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
try:
entry = json.loads(line)
sid = entry.get("sessionId")
if sid is not None:
known.add(sid)
except json.JSONDecodeError:
continue
except OSError:
continue
return known
def append_entries_to_week(entries: list[dict]) -> dict[str, int]:
"""エントリを週フォルダ別に振り分けて history.jsonl に追記。"""
by_week: dict[str, list[dict]] = {}
for entry in entries:
ts = entry.get("timestamp")
if not ts:
continue
try:
dt_jst = parse_iso_to_jst(ts)
except ValueError:
continue
week_name = week_folder_name(dt_jst)
by_week.setdefault(week_name, []).append(entry)
result: dict[str, int] = {}
for week_name, week_entries in by_week.items():
week_dir = DATA_DIR / week_name
week_dir.mkdir(parents=True, exist_ok=True)
week_entries.sort(key=lambda e: e.get("timestamp", ""))
jsonl_path = week_dir / "history.jsonl"
with jsonl_path.open("a", encoding="utf-8") as f:
for entry in week_entries:
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
result[week_name] = len(week_entries)
return result
def write_archive_log(lines: list[str]) -> None:
"""実行時刻が属する週の archive.log に動作ログを追記。"""
now_jst = datetime.now(JST)
week_name = week_folder_name(now_jst)
week_dir = DATA_DIR / week_name
week_dir.mkdir(parents=True, exist_ok=True)
log_path = week_dir / "archive.log"
with log_path.open("a", encoding="utf-8") as f:
for line in lines:
f.write(line + "\n")
f.write("---\n")
def main() -> int:
log_lines: list[str] = []
now_str = datetime.now(JST).strftime("%Y-%m-%d %H:%M:%S")
log_lines.append(f"[{now_str}] start")
if not SETTINGS_PATH.exists():
log_lines.append(f"[{now_str}] error: settings.json not found at {SETTINGS_PATH}")
write_archive_log(log_lines)
return 1
try:
with SETTINGS_PATH.open("r", encoding="utf-8") as f:
settings = json.load(f)
except (OSError, json.JSONDecodeError) as e:
log_lines.append(f"[{now_str}] error: failed to read settings.json: {e}")
write_archive_log(log_lines)
return 1
history = settings.get("history", [])
if not isinstance(history, list):
log_lines.append(f"[{now_str}] error: history is not a list")
write_archive_log(log_lines)
return 1
log_lines.append(f"[{now_str}] settings.json read: {len(history)} entries")
known_ids = collect_known_session_ids()
log_lines.append(f"[{now_str}] known sessionIds: {len(known_ids)}")
new_entries = [
e for e in history
if isinstance(e, dict) and e.get("sessionId") is not None and e["sessionId"] not in known_ids
]
log_lines.append(f"[{now_str}] new entries detected: {len(new_entries)}")
if new_entries:
result = append_entries_to_week(new_entries)
for week_name in sorted(result.keys()):
log_lines.append(f"[{now_str}] appended: {week_name}/history.jsonl +{result[week_name]} entries")
else:
log_lines.append(f"[{now_str}] skip (no new entries, but snapshot refreshed)")
try:
ARCHIVE_DIR.mkdir(parents=True, exist_ok=True)
with SNAPSHOT_PATH.open("w", encoding="utf-8") as f:
json.dump(history, f, ensure_ascii=False, indent=2)
log_lines.append(f"[{now_str}] snapshot.json updated")
except OSError as e:
log_lines.append(f"[{now_str}] error: failed to write snapshot.json: {e}")
write_archive_log(log_lines)
return 1
try:
settings_snapshot = {"snapshotAt": datetime.now(JST).isoformat()}
for key in SETTINGS_SNAPSHOT_KEYS:
settings_snapshot[key] = settings.get(key)
with SETTINGS_SNAPSHOT_PATH.open("w", encoding="utf-8") as f:
json.dump(settings_snapshot, f, ensure_ascii=False, indent=2)
log_lines.append(f"[{now_str}] settings-snapshot.json updated")
except OSError as e:
log_lines.append(f"[{now_str}] error: failed to write settings-snapshot.json: {e}")
write_archive_log(log_lines)
return 1
end_str = datetime.now(JST).strftime("%Y-%m-%d %H:%M:%S")
log_lines.append(f"[{end_str}] done")
write_archive_log(log_lines)
return 0
if __name__ == "__main__":
try:
sys.exit(main())
except Exception:
traceback.print_exc(file=sys.stderr)
sys.exit(1)
スクリプトは以下を行います。
~/Library/Application Support/Aqua Voice/settings.jsonを読むdata/**/history.jsonlから既知のsessionIdを集めて、未保存エントリを抽出- JST 月曜起点の週フォルダ別に
history.jsonlへ追記 snapshot.json(直近 history 100件のミラー)とsettings-snapshot.json(dictionary・replacements・customInstructions等のミラー)を更新
補足:Python で書いている理由: 本記事は Mac での運用前提ですが、Windows でも動くようにあえて Python で書いています。
1-2. launchd の plist を 2 つ配置する
Aqua Voice は settings.json を atomic rename(一時ファイルに書いてから差し替える)で更新するため、launchd の WatchPaths ではファイルを見失うことがあります。そのため定期実行で運用します。
2 種類の plist を作成します。
| plist | 役割 | トリガー |
|---|---|---|
com.user.aquavoice-archiver |
5分ごとに aqua_archive.py を実行 |
StartInterval: 300 |
com.user.aquavoice-snapshot-weekly |
月曜 00:55 に強制同期 | StartCalendarInterval |
月曜 00:55 の強制同期は、後述する Cowork のスケジュールタスクが 01:00 に走る前に 最新の settings-snapshot.json を確実に揃える ための仕組みです。
補足:5分間隔はお好みで OK:
StartIntervalの値は 5分(300秒)でなくても構いません。最初は「5分ごとに動かしたら処理が重くなるかも」と心配していましたが、実際は 1 回の処理が 0.1〜0.5 秒程度で終わるので、間隔を 1 分にしても問題ありません。逆に 10〜15 分にしても、historyは直近 100 件保持されるので取りこぼしません。
$HOME/Library/LaunchAgents/com.user.aquavoice-archiver.plist を作成して、以下を貼り付けます。<YOUR_USER> は書き換えてください。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.aquavoice-archiver</string>
<key>ProgramArguments</key>
<array>
<string>/usr/bin/python3</string>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/aqua_archive.py</string>
</array>
<key>StartInterval</key>
<integer>300</integer>
<key>RunAtLoad</key>
<true/>
<key>StandardOutPath</key>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/data/launchd-stdout.log</string>
<key>StandardErrorPath</key>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/data/launchd-stderr.log</string>
</dict>
</plist>
続けて、$HOME/Library/LaunchAgents/com.user.aquavoice-snapshot-weekly.plist を作成します。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.aquavoice-snapshot-weekly</string>
<key>ProgramArguments</key>
<array>
<string>/usr/bin/python3</string>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/aqua_archive.py</string>
</array>
<key>StartCalendarInterval</key>
<dict>
<key>Weekday</key>
<integer>1</integer>
<key>Hour</key>
<integer>0</integer>
<key>Minute</key>
<integer>55</integer>
</dict>
<key>StandardOutPath</key>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/data/launchd-weekly-stdout.log</string>
<key>StandardErrorPath</key>
<string>/Users/<YOUR_USER>/Library/Application Support/aqua-voice-archive/data/launchd-weekly-stderr.log</string>
</dict>
</plist>
1-3. launchd に登録する
以下のコマンドで 2 つの plist を読み込みます。
launchctl load "$HOME/Library/LaunchAgents/com.user.aquavoice-archiver.plist"
launchctl load "$HOME/Library/LaunchAgents/com.user.aquavoice-snapshot-weekly.plist"
com.user.aquavoice-archiver は RunAtLoad: true を付けているため、登録した瞬間に 1 回実行されます。
登録できているか確認します。
launchctl list | grep aquavoice
# 出力例
- 0 com.user.aquavoice-archiver
- 0 com.user.aquavoice-snapshot-weekly
エラーがある場合は標準エラーログに出力されます。
cat "$HOME/Library/Application Support/aqua-voice-archive/data/launchd-stderr.log"
空ファイルなら正常です。
2. Cowork のスケジュールタスクを作る
ここから Claude(Cowork)に分析させる仕組みを作ります。
2-1. Cowork で新規スケジュールタスクを作成する
-
Cowork サイドバーの 「Scheduled」 をクリックして、Scheduled tasks 画面を開く
-
画面右上の 「+ New task」 ボタンをクリックし、出てくるドロップダウンから 「Set up manually」 を選択する
- 「スケジュールタスクを作成」ダイアログが開きます。以下のように入力してください
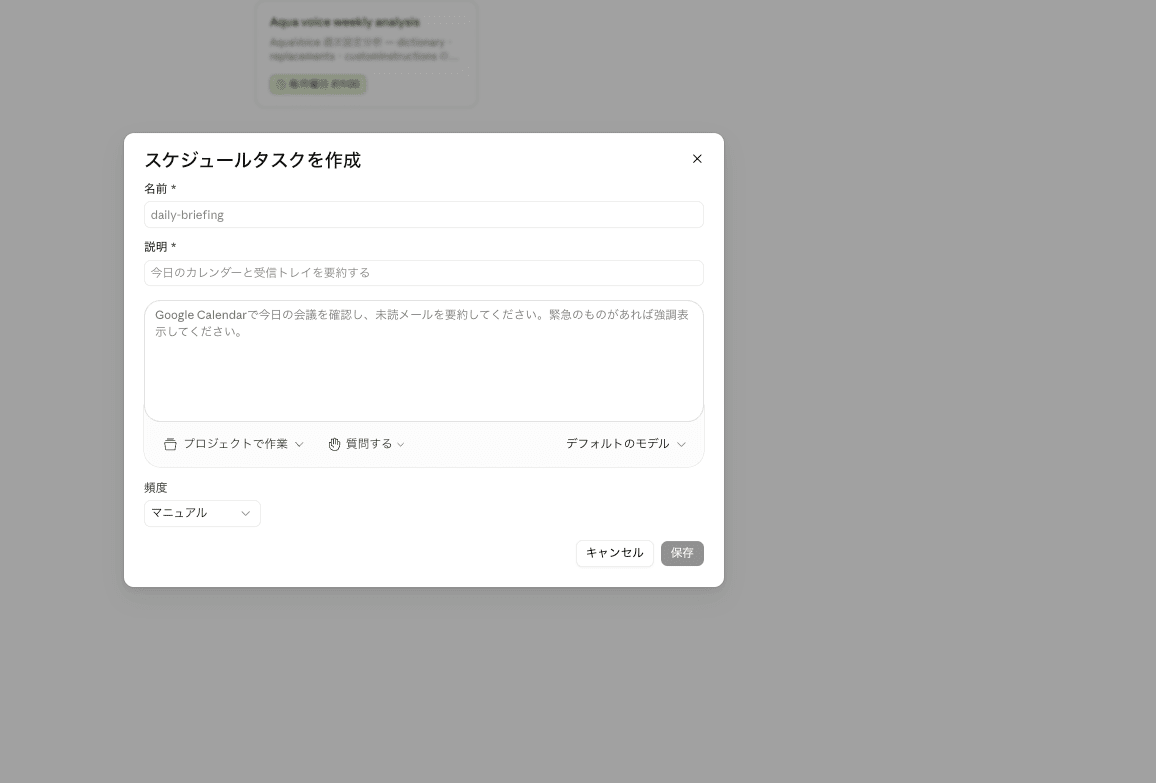
| 項目 | 入力内容 |
|---|---|
| 名前 | aqua-voice-weekly-analysis |
| 説明 | Aqua Voice 週次設定分析タスク |
| プロンプト本文 | 後述の SKILL.md と同等の内容(プロンプトを直接書く) |
| 頻度 | 「週次」 を選択し、毎週月曜 01:00 を指定 |
| モデル | Claude Sonnet 4.6 推奨 |
- 「保存」 ボタンを押すとタスクが作成されます
2-2. タスクに渡すプロンプト本文
生成された SKILL.md を以下の内容に書き換えます。フロントマターの name はタスク作成時の ID を保ち、description のみ差し替えてください。<ARCHIVE_PATH> と <KNOWLEDGE_PATH> をご自身が選んだ保存先の絶対パスに書き換えてください。
プロンプトには 追加候補 だけでなく 削除候補 の検出ロジックも入れています。Aqua Voice の Pro プランでは dictionary を 800 エントリまで登録できるので、最初のうちは削除を気にしなくても運用できます。ただ、長く使っていれば登録単語は増え続けるので、上限に達したときに困らないよう、8 週連続で出現しなくなった単語を削除候補として提案する仕組み を最初から組み込んでおきました。
SKILL.md の全文(クリックすると展開します)
---
name: aqua-voice-weekly-analysis
description: Aqua Voice 週次設定分析 — dictionary・replacements・customInstructions の改善提案を生成しナレッジベースに保存する
---
# Aqua Voice 週次設定分析タスク
毎週月曜 01:00 に自動実行される。Aqua Voice の音声ログを分析し、dictionary・replacements・customInstructions の改善提案を生成してナレッジベースに保存し、Slack に通知する。
すべてのデータは Cowork から読める指定フォルダにミラー保存されている。`~/Library/Application Support/` には直接アクセスしないこと(サンドボックスから読めない)。
---
## Step 1: 先週の history.jsonl を特定・読み込む
アーカイブディレクトリ:
`<ARCHIVE_PATH>/data/`
実行日(月曜日)の「前週(月〜日)」のフォルダを Bash で特定する:
```bash
python3 -c "
from datetime import datetime, timedelta
today = datetime.today()
last_monday = today - timedelta(days=today.weekday() + 7)
last_sunday = last_monday + timedelta(days=6)
print(f'{last_monday.strftime(\"%Y-%m%d\")}_{last_sunday.strftime(\"%Y-%m%d\")}')
"
```
上記で得たフォルダ名を使い `history.jsonl` を全行読み込む。フォルダが存在しない場合は「先週のログなし」と記録して Step 7・8 で出力し終了。
---
## Step 2: 現在の設定スナップショットを読み込む
以下のファイルを読み込む:
`<ARCHIVE_PATH>/settings-snapshot.json`
含まれているキー: `dictionary`, `replacements`, `customInstructions`, `transcriptionModel`, `language`, `deepContext`, `casualMessaging`, `promptSet`, `computerControlCustomInstructions`, `snapshotAt`
---
## Step 3: 過去の提案ファイルを読み込む(直近4週・dictionary削除は直近8週)
`<KNOWLEDGE_PATH>/notes/` 配下の `aqua-voice-suggestions-*.md` を、追加候補は直近4週分、dictionary削除候補は直近8週分読み込む。
各提案について、過去ファイルから以下を集計する:
- 出現週数(継続スコア算出用)
- 各週の出現件数(履歴)
同一提案の判定基準:
- dictionary: 追加する単語が一致
- replacements: from と to が両方一致
- customInstructions: 意味が同等(テキスト類似度 80% 以上)
---
## Step 4: 分析
### 4-1. dictionary 追加候補の検出
重要: `rawText` と `content` の単純な乖離だけで判定しない(LLM補正で content が正しく直っているケースを誤検出するため)。
判定対象は content(最終出力)に問題が残っているケース:
| 検出条件 | 例 |
|---|---|
| 表記揺れ:同じ意図で content 内に複数表記混在 | `Claude` と `クロード` の両方が出る |
| カタカナ残り:固有名詞が英語表記すべきなのに content でカタカナ | `プレジデント`(本来 `Presigned`) |
| 誤変換残り:明らかに意図と違う変換が content で定着 | `蔵人`(本来 `Claude`) |
既に dictionary 登録済みの単語と意味的に重複していないこと。
### 4-2. dictionary 削除候補の検出
既存 dictionary 登録単語のうち、直近8週連続で content にも rawText にも出現していないもの。
### 4-3. replacements 追加候補の検出
- content 内で同じURL・コマンド・定型文が、類似パターン含めて3回以上出現
- 「from(発話フレーズ)→ to(変換先)」を必ずペアで提示
### 4-4. replacements 削除候補の検出
既存 replacements の `from` フレーズが、直近8週連続で content にも rawText にも出現していない。
### 4-5. customInstructions 追加候補の検出
| カテゴリ | 検出条件 |
|---|---|
| フィラー除去 | 「あー」「えー」「えーと」「あのー」「まあ」「なんか」が content に各5回以上残っている |
| コマンド語漏れ | 「改行」「かっこ」「かぎかっこ」が content に文字列として残っている |
| 重複言い直し | 同じ表現が連続している |
| 表記揺れ(スタイル系) | 半角全角の数字混在、カタカナ長音の有無不統一など |
### 4-6. 推薦度の算出ロジック(全種別共通)
```
推薦度 = max(頻度スコア, 継続スコア) + 一致ボーナス + 減衰
```
頻度スコア(今週単独の強さ):
| 今週の出現件数 | スコア |
|---|---|
| 20件以上 | 90% |
| 10〜19件 | 75% |
| 5〜9件 | 55% |
| 3〜4件 | 40% |
| 1〜2件 | 20% |
| 0件 | 0% |
継続スコア(直近4週で出現した週数):
| 出現週数 | スコア |
|---|---|
| 4週連続 | 95% |
| 3週 | 75% |
| 2週 | 55% |
| 1週 | 30% |
| 0週 | 0% |
- 一致ボーナス(過去ペンディング提案と一致): +10%
- 減衰(今週0件 + 過去ペンディングのみで存在): -15%
- 推薦度は 0〜100% にクリップ
自動アーカイブ:
- 追加候補: 直近4週連続で出現がゼロなら提案リストから除外
- dictionary 削除候補: 8週連続ゼロで初めて提案
---
## Step 5: 提案の生成
各提案を以下の形式でまとめる(dictionary 追加・削除、replacements 追加・削除、customInstructions 追加):
```
### [種別] 値: <内容>
- 種別: <種別>
- 推薦度: XX%
- 頻度スコア: XX%(今週 N 件)
- 継続スコア: XX%(直近4週で N 週出現)
- 調整: +10% / -15% / なし
- 出現履歴: [今週 N 件, 1週前 N 件, 2週前 N 件, 3週前 N 件]
- 状態: 確定候補(80%以上) / ペンディング(80%未満)
```
---
## Step 6: ナレッジベースへの保存
以下のパスに Markdown ファイルを作成(既存ファイルがあれば上書き更新):
`<KNOWLEDGE_PATH>/notes/aqua-voice-suggestions-YYYY-MM-DD.md`
フロントマター:
```yaml
---
created: YYYY-MM-DD
tags: [aqua-voice, wip]
summary: Aqua Voice 週次分析 YYYY-MM-DD - 確定候補N件・ペンディングN件
---
```
本文構成:
1. 確定候補(推薦度 80% 以上)
2. ペンディング(推薦度 80% 未満)
3. アーカイブされた提案(あれば)
4. 今週の統計
---
## Step 7: 通知サマリーの出力(チャット)
ファイルパスは必ずフルパスで書く。
```
Aqua Voice 週次分析レポート YYYY-MM-DD
【今週の統計】
• 分析エントリ数: N件
• 確定候補(80%以上): N件
• ペンディング: N件
【確定候補(推薦度80%以上)】
• [dictionary追加] <単語> — 推薦度XX%(今週N件・直近4週中N週出現)
• [replacements追加] from「<発話>」→ to「<変換先>」 — 推薦度XX%
• [customInstructions追加] <カテゴリ>: <一行説明> — 推薦度XX%
【ペンディング(推薦度80%未満)】
(同上)
【詳細ファイル】
<KNOWLEDGE_PATH>/notes/aqua-voice-suggestions-YYYY-MM-DD.md
```
確定候補・ペンディングが両方 0 件なら「今週は提案なし」とだけ短く送る。
---
## Step 8: Slack 自分宛 DM への通知
1. `slack_search_users` で `<YOUR_SLACK_EMAIL>` を検索して自分のユーザーIDを取得
2. `slack_send_message` で取得したユーザーID宛にDM送信
Slack MCP が使えない・送信失敗した場合は、その旨をチャット出力にだけ記載して終了する。
2-3. タスクを手動で 1 回テスト実行する
スケジュールどおりの実行を待たずに、まずは 手動で 1 回テスト実行 して、正しく動くことを確認します。
- Cowork サイドバーの 「Scheduled」 から、作成した
aqua-voice-weekly-analysisのタスクをクリック - タスク詳細画面の 「今すぐ実行」(Run now) ボタンを押す
- 実行結果のチャットに、分析レポートが出力されることを確認する
初回実行時には、Cowork が以下の アクセス許可ダイアログ を順番に出してきます。すべて 「許可」 を押してください。
- アーカイブフォルダ(
<ARCHIVE_PATH>)の読み取り許可 - ナレッジフォルダ(
<KNOWLEDGE_PATH>)の読み書き許可 - Slack MCP の
slack_send_message実行許可
承認した内容は userSelectedFolders や approvedPermissions に自動で記録されます。
以降の自動実行ではダイアログなしで動くようになるため、scheduled-tasks.json を手作業で書き換える必要はありません。
補足: Cowork のスケジュールタスクはサンドボックスで動くため、許可されたパスしか読めません。ただし
~/Library/Application Support/自体はサンドボックス対象外で許可できないため、Aqua Voice 本体のsettings.jsonを直接読むことはできません。Step 1 で別フォルダにミラーしているのはこのためです。
動作確認
「2-3. タスクを手動で 1 回テスト実行する」で実行したテストの結果を、以下の 2 点で確認します。
Cowork タスクの動作確認
レポートは Slack DM のサマリー と ナレッジベースの Markdown 詳細ファイル の 2 つで届きます。
それぞれの中身を見ていきましょう。
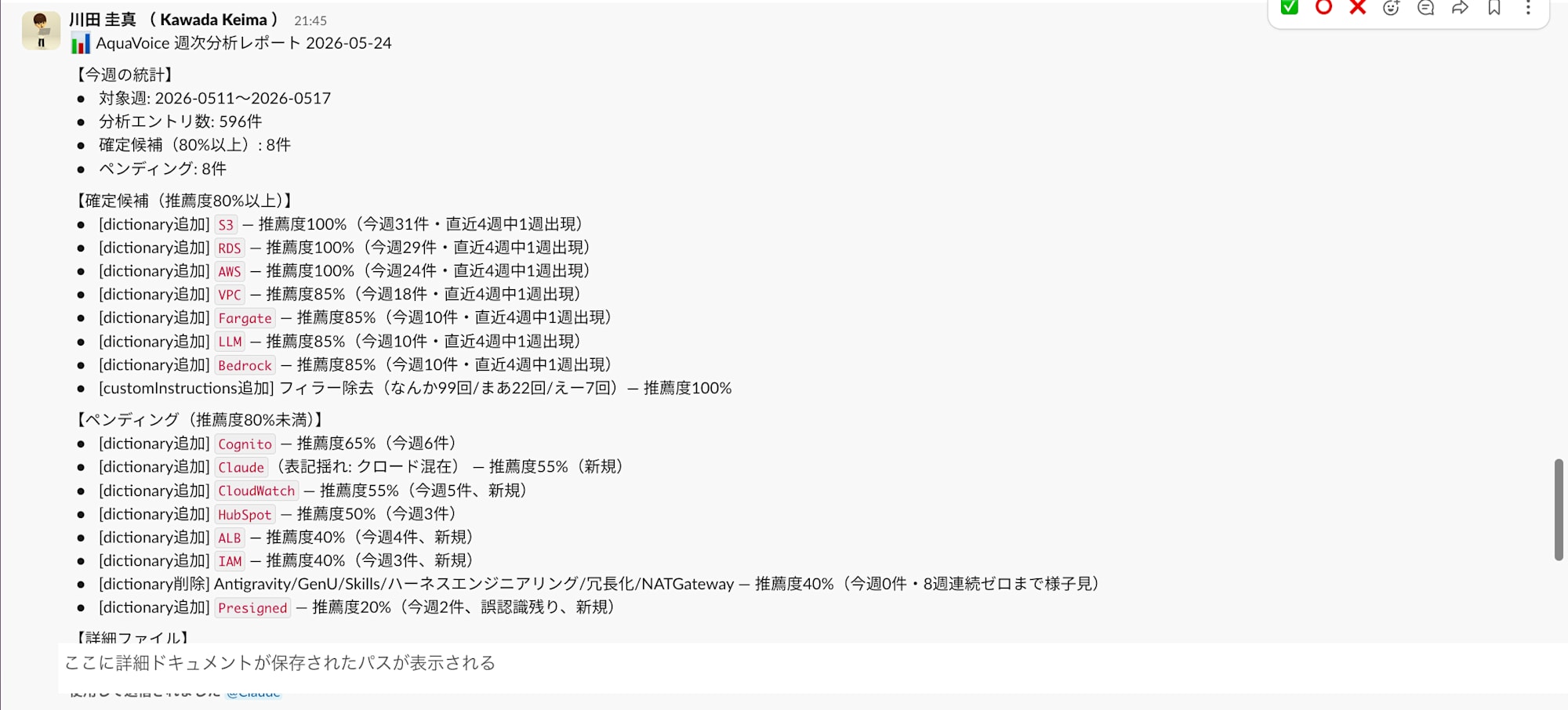
Slack DM に届くサマリー
「2-3. タスクを手動で 1 回テスト実行する」で実行したテスト結果が Slack に届けば成功です。実際に届くレポートは次のような見た目になります。
本文はテキストで以下のような形になります(種別・推薦度・件数の 1 行サマリー のみ)。
Aqua Voice 週次分析レポート 2026-05-24
【今週の統計】
• 分析エントリ数: 596 件
• 確定候補(80%以上): 8 件
• ペンディング: 8 件
【確定候補(推薦度80%以上)】
• [dictionary追加] S3 — 推薦度100%(今週31件)
• [dictionary追加] Bedrock — 推薦度85%(今週10件)
• [customInstructions追加] フィラー除去: 「なんか」「まあ」「えー」を除去する指示文 — 推薦度100%(今週なんか99件)
【ペンディング(推薦度80%未満)】
• [dictionary追加] Cognito — 推薦度65%(今週6件)
• [dictionary削除] Antigravity / GenU / ハーネスエンジニアリング / 冗長化 — 推薦度65%
【詳細ファイル】
<KNOWLEDGE_PATH>/notes/aqua-voice-suggestions-2026-05-24.md
Slack 側にあるのは 「何が提案されたか」の一覧 までです。
customInstructions の登録に使う具体的な指示文ブロックは、Slack 本文には含まれません。
Markdown 詳細ファイルを開く
Slack 本文の末尾にある 「詳細ファイル」 のパスを開くと、ナレッジベースに保存された Markdown レポートを参照できます。
open "<KNOWLEDGE_PATH>/notes/aqua-voice-suggestions-2026-05-24.md"
実際に届いたレポートの全文は以下のとおりです。
aqua-voice-suggestions-2026-05-24.md の全文(クリックすると展開します)
---
created: 2026-05-24
tags: [aqua-voice, wip]
summary: AquaVoice 週次分析 2026-05-24 - 確定候補8件・ペンディング8件(2026-0511〜0517の596件を分析)
---
# AquaVoice 週次分析レポート 2026-05-24
対象週: 2026-0511〜2026-0517(596件)。設定スナップショット: 2026-05-24T18:53:37+09:00。
---
## 1. 確定候補(推薦度 80% 以上)
### [dictionary追加] 値: S3
- 種別: dictionary追加
- 追加する単語: `S3`
- 検出理由: content に出現するが rawText には皆無(deep context による補正)
- 推薦度: 100%
- 頻度スコア: 90%(今週 31 エントリに出現)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 31 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: RDS
- 種別: dictionary追加
- 追加する単語: `RDS`
- 検出理由: content に出現するが rawText には皆無("RTS" 等と誤認識)
- 推薦度: 100%
- 頻度スコア: 90%(今週 29 エントリに出現)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 29 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: AWS
- 種別: dictionary追加
- 追加する単語: `AWS`
- 検出理由: content に出現するが rawText には皆無
- 推薦度: 100%
- 頻度スコア: 90%(今週 24 エントリに出現)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 24 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: VPC
- 種別: dictionary追加
- 追加する単語: `VPC`
- 検出理由: content 18 エントリ / rawText 20 エントリ(rawText でも出現しているが補正乖離あり)
- 推薦度: 85%
- 頻度スコア: 75%(今週 18 エントリ、10〜19 件レンジ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 18 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: Fargate
- 種別: dictionary追加
- 追加する単語: `Fargate`
- 検出理由: content に出現するが rawText には皆無
- 推薦度: 85%
- 頻度スコア: 75%(今週 10 エントリ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 10 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: LLM
- 種別: dictionary追加
- 追加する単語: `LLM`
- 検出理由: content に出現するが rawText には皆無
- 推薦度: 85%
- 頻度スコア: 75%(今週 10 エントリ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 10 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [dictionary追加] 値: Bedrock
- 種別: dictionary追加
- 追加する単語: `Bedrock`
- 検出理由: content に出現するが rawText には皆無
- 推薦度: 85%
- 頻度スコア: 75%(今週 10 エントリ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 10 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
### [customInstructions追加] フィラー除去
- 種別: customInstructions追加
- カテゴリ: フィラー除去
- 登録する指示文(英語推奨、コピペ可能な形):
```
Remove filler words and verbal tics from the transcription output. Specifically, remove or omit: 「なんか」「まあ」「えー」「えーと」「あのー」when used as fillers (not meaningful words). Do not remove these if they carry semantic meaning.
```
- 推薦度: 100%
- 頻度スコア: 90%(なんか=99回・まあ=22回・えー=7回が content に残存)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 なんか99/まあ22/えー7/えーと4, 1週前 -, 2週前 -, 3週前 -]
- 状態: **確定候補**
- 補足: 「なんか」は意味語として使われるケースも多い(76エントリ中、明確フィラーは約5件)。指示文で「意味語は残す」と明示することが重要。
---
## 2. ペンディング(推薦度 80% 未満)
### [dictionary追加] 値: Cognito
- 種別: dictionary追加
- 追加する単語: `Cognito`
- 検出理由: content 6 エントリ / rawText 0 エントリ
- 推薦度: 65%
- 頻度スコア: 55%(今週 6 エントリ、5〜9 件レンジ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 6 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング
### [dictionary追加] 値: Claude(表記揺れ)
- 種別: dictionary追加
- 追加する単語: `Claude`
- 検出理由: content に "Claude"(7件)と "クロード"(4件)が混在。rawText では "クロード" が主(6件)、"Claude" はゼロ。
- 推薦度: 55%
- 頻度スコア: 55%(今週 7 エントリ、5〜9 件レンジ)
- 継続スコア: 0%(前回提案なし、新規)
- 調整: なし
- 出現履歴: [今週 7 件(+クロード 4 件混在), 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(新規)
- 補足: Anthropic は既に登録済み。Claude 単体を追加で "クロード" → "Claude" への統一が期待できる。
### [dictionary追加] 値: CloudWatch
- 種別: dictionary追加
- 追加する単語: `CloudWatch`
- 検出理由: content 5 エントリ / rawText 0 エントリ("クラウドウォッチドッグス" 等と誤認識)
- 推薦度: 55%
- 頻度スコア: 55%(今週 5 エントリ、5〜9 件レンジ)
- 継続スコア: 0%(前回提案なし、新規)
- 調整: なし
- 出現履歴: [今週 5 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(新規)
### [dictionary追加] 値: HubSpot
- 種別: dictionary追加
- 追加する単語: `HubSpot`
- 検出理由: content 3 エントリ / rawText 0 エントリ
- 推薦度: 50%
- 頻度スコア: 40%(今週 3 エントリ、3〜4 件レンジ)
- 継続スコア: 30%(直近4週で 1 週出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 3 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング
### [dictionary追加] 値: ALB
- 種別: dictionary追加
- 追加する単語: `ALB`
- 検出理由: content 4 エントリ / rawText 0 エントリ
- 推薦度: 40%
- 頻度スコア: 40%(今週 4 エントリ、3〜4 件レンジ)
- 継続スコア: 0%(前回提案なし、新規)
- 調整: なし
- 出現履歴: [今週 4 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(新規)
### [dictionary追加] 値: IAM
- 種別: dictionary追加
- 追加する単語: `IAM`
- 検出理由: content 3 エントリ / rawText 0 エントリ
- 推薦度: 40%
- 頻度スコア: 40%(今週 3 エントリ、3〜4 件レンジ)
- 継続スコア: 0%(前回提案なし、新規)
- 調整: なし
- 出現履歴: [今週 3 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(新規)
### [dictionary削除] Antigravity / GenU / Skills / ハーネスエンジニアリング / 冗長化 / NATGateway
- 種別: dictionary削除
- 対象単語: `Antigravity`, `GenU`, `Skills`, `ハーネスエンジニアリング`, `冗長化`, `NATGateway`
- 検出理由: 今週 content・rawText ともに出現ゼロ
- 推薦度: 40%
- 頻度スコア: 0%(今週 0 件)
- 継続スコア: 30%(直近4週で 1 週ペンディング出現)
- 調整: +10%(過去ペンディング一致)
- 出現履歴: [今週 0 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(連続8週ゼロが必要。現時点は 1 週のみ)
### [dictionary追加] 値: Presigned(誤認識残り)
- 種別: dictionary追加
- 追加する単語: `Presigned`
- 検出理由: rawText では "プレゼント URL"・"プレザイン" と誤認識。content でも一部補正しきれていないケースあり。
- 推薦度: 20%
- 頻度スコア: 20%(今週 2 エントリ、1〜2 件レンジ)
- 継続スコア: 0%(前回提案なし、新規)
- 調整: なし
- 出現履歴: [今週 2 件, 1週前 -, 2週前 -, 3週前 -]
- 状態: ペンディング(新規)
---
## 3. アーカイブされた提案
なし
---
## 4. 今週の統計
- 分析エントリ数: 596 件
- 確定候補(推薦度 80% 以上): 8 件
- ペンディング(推薦度 80% 未満): 8 件
- replacements 追加候補: なし(3回以上の繰り返しパターンなし)
- replacements 削除候補: なし
- 主要 dictionary 語の使用状況: AgentCore=20件・Anthropic=8件・Markdown=8件・ナレッジ=5件(いずれも継続利用中)
---
_自動生成: AquaVoice 週次分析タスク(2026-05-24 実行)。適用判断は手動で。_
このレポートが届けば、あとは 「確定候補」セクションに並んでいる項目をそのまま Aqua Voice の UI に登録するだけ です。読者が自分で英語の指示文を考えたり、誤認識傾向を解析したりする必要はありません。
- dictionary 追加:各項目の
追加する単語(例:S3、RDS、AWS、VPC...)を Dictionary タブの「+ Add」からそのまま登録 - customInstructions 追加:
登録する指示文のコードブロックを丸ごとコピーして Instructions タブに貼り付け、保存 - dictionary 削除:
対象単語に挙がっているものを Dictionary タブから削除
レポートに書かれたものを そのまま反映するだけ で、毎週の運用が回ります。具体的な登録手順は次の「提案を Aqua Voice に反映する」セクションで説明します。
提案を Aqua Voice に反映する
レポートで出てきた候補のうち、納得感のあるものを Aqua Voice の UI から手動で登録 します(自動反映はしません)。
登録先は、レポートの種別([dictionary追加] / [replacements追加] / [customInstructions追加])に対応する 3 つのタブです。
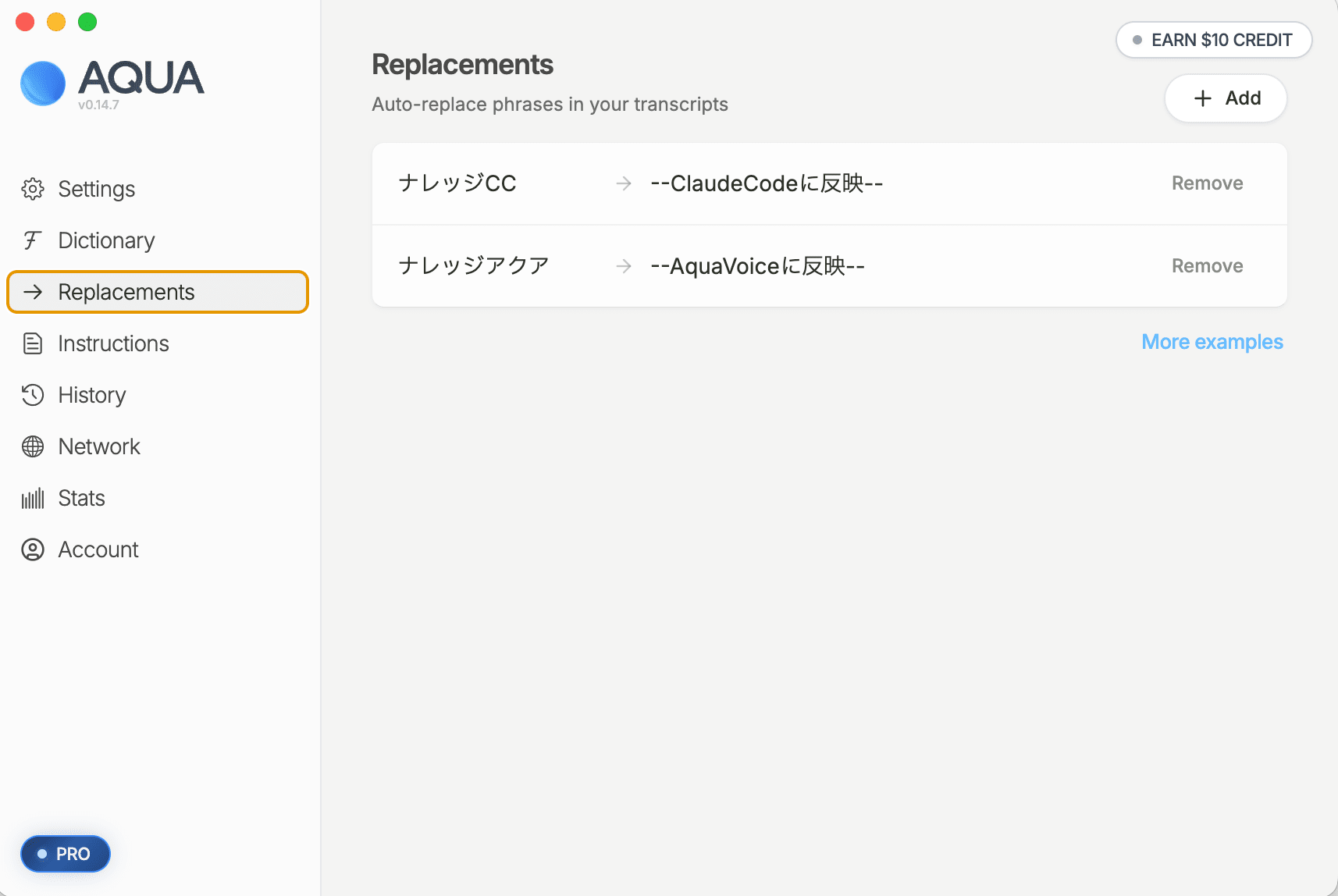
Dictionary タブの 「+ Add」 で、レポートの [dictionary追加] に挙がった単語を貼り付けて登録します。
Replacements タブの 「+ Add」 で、レポートの [replacements追加] に挙がった from(発話フレーズ)と to(変換先テキスト)をそのまま貼り付けて登録します。
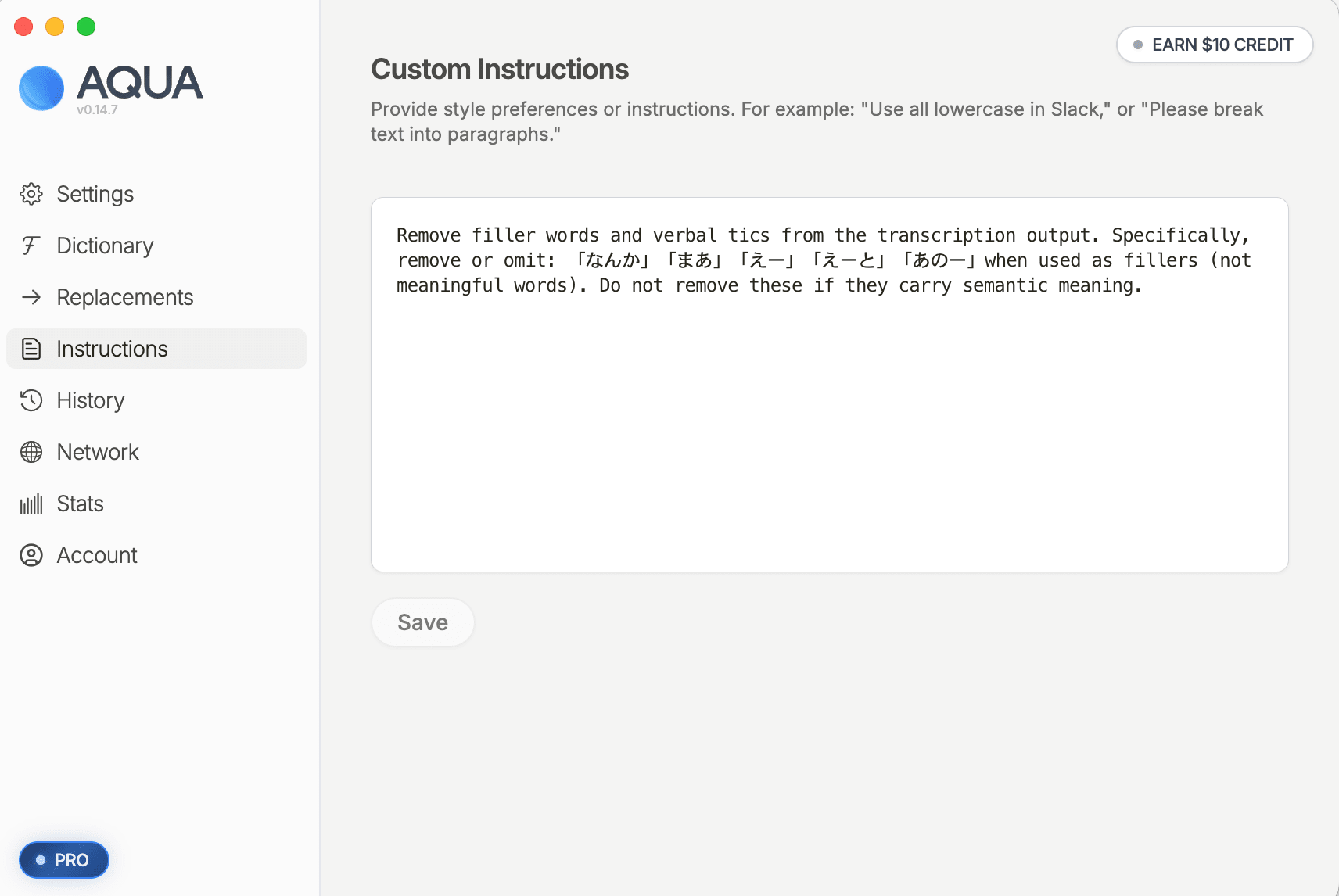
Instructions タブには、レポートの [customInstructions追加] で提示された Markdown 形式の指示文 を貼り付けて 「Save」 を押します。
書式は英語の自然文ではなく、Claude が生成したそのままの Markdown(見出し・箇条書き・コード例を含む形)を貼ればよく、構造化された記述のほうが Aqua Voice 側でも安定して効きます。
ここまでで一連の動作確認は完了です。あとは 毎週決まった日に Slack を見て、納得感のある提案を Aqua Voice に登録する という運用に入ります。実行スケジュール(曜日・時刻)は「2-1. Cowork で新規スケジュールタスクを作成する」で指定したタイミングに従って動くので、ご自身の生活リズムに合わせて自由に決めてください。
まとめ
最近、ハーネスエンジニアリングという言葉を耳にする機会が増えました。
主に Claude Code のようなコーディング AI を使う文脈で出てきますが、AI を導入して終わりではなく、運用しながら継続的に改善していくという発想は、今後もっと広く一般化していくと考えられます。
音声入力もその対象です。
ログを取得して AI に投げて、改善提案を受け取る。
この流れを回すだけで、音声入力の品質は使えば使うほど上がっていきます。
加えて、自分の思考を声に出してログに残しておけば、それ自体が個人のナレッジになります。思考の言語化や暗黙知の形式知化といった用途にも、音声入力ログの活用は広げていけると考えています。
音声入力についてはまだまだ語りたいことが多くあるので、今後も DevelopersIO で関連記事を出していければと思っています。









