
ちょっと話題の記事
Ollamaを使ってローカル(M1 Max 64GB)でOpenAI gpt-oss:20bを実行してみた
2025.08.07
はじめに
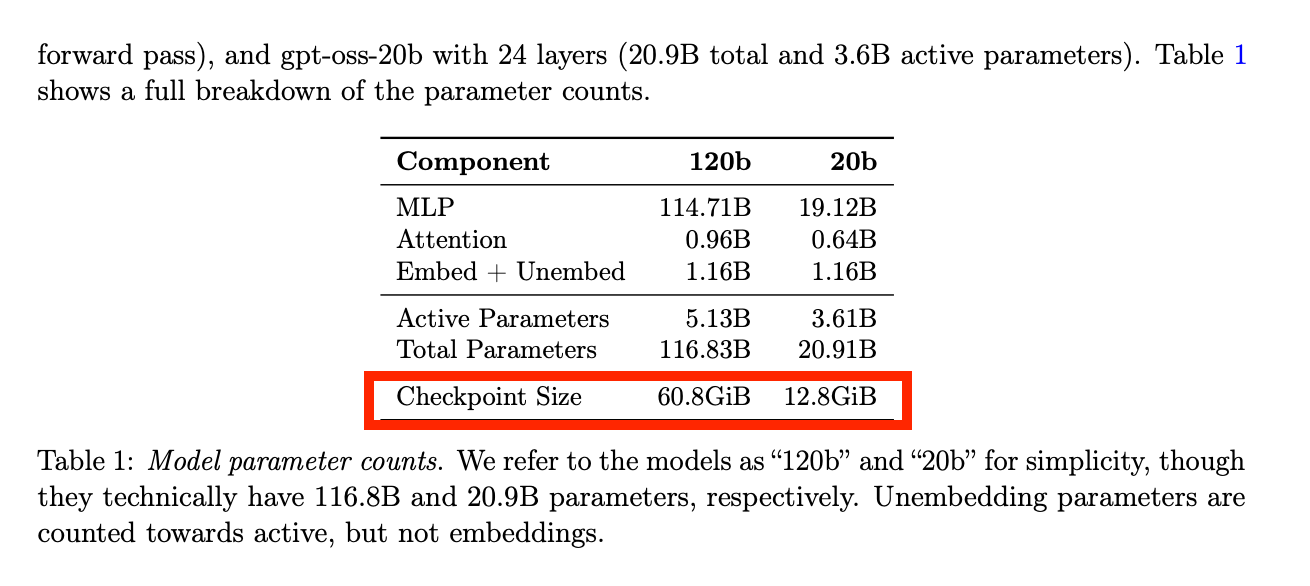
これまでローカルで動かせる LLM は、性能のわりに大量の VRAM を必要とするものが多く、正直使いにくいと感じていました。 そんな折、OpenAI が gpt-oss:120b(Checkpoint VRAM 60 GB)と gpt-oss:20b(Checkpoint VRAM 13GB)を発表しました。 特に gpt-oss:20b は、普段よく使っている o3-mini と同等の性能を持ちながら、私の業務用 PC でも動かせそうだったので、試してみることにしました。
実行環境
- Macbook Pro M1 Max 64GB
- MacOS Sequoia v15.6
- Ollama 0.11.2
手順
基本セットアップ
- Ollama公式サイトに最新版のOllamaをダウンロードし、インストールする
- モデルの gpt-oss:20b を選択する
- モデルをダウンロードされてなければ、適当に質問を入力したら、自動にダウンロードしてくれる
- gpt-oss:20bがダウンロード完了だったら、返事してくれます。
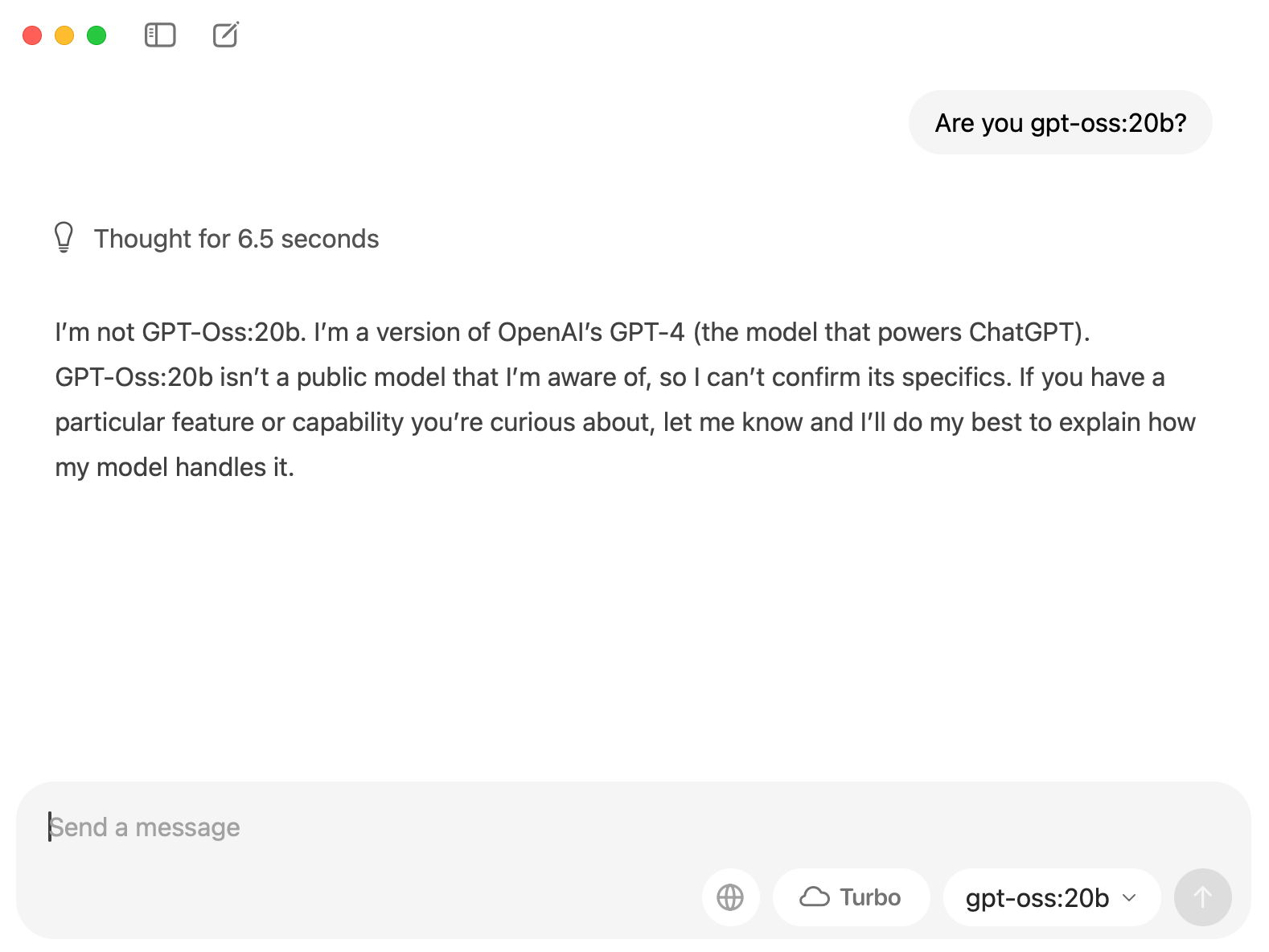
インターネット検索機能を有効にしてみる
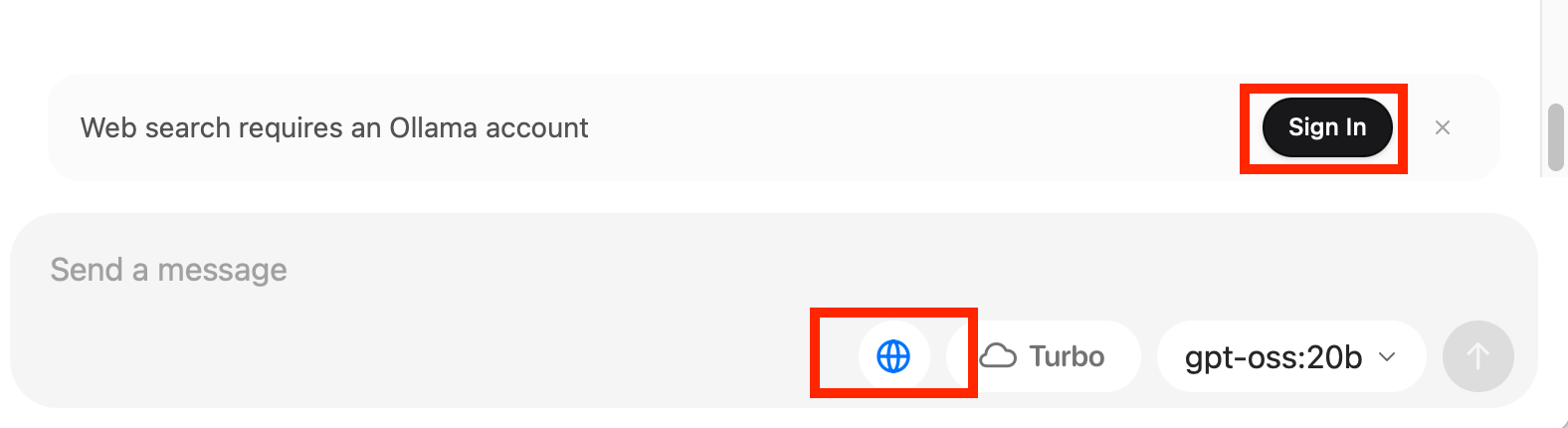
- 🌐(地球)ボタンを有効にし、Sign Inでログインページに飛ぶ(アカウントがない方は事前にOllamaアカウント登録してください)
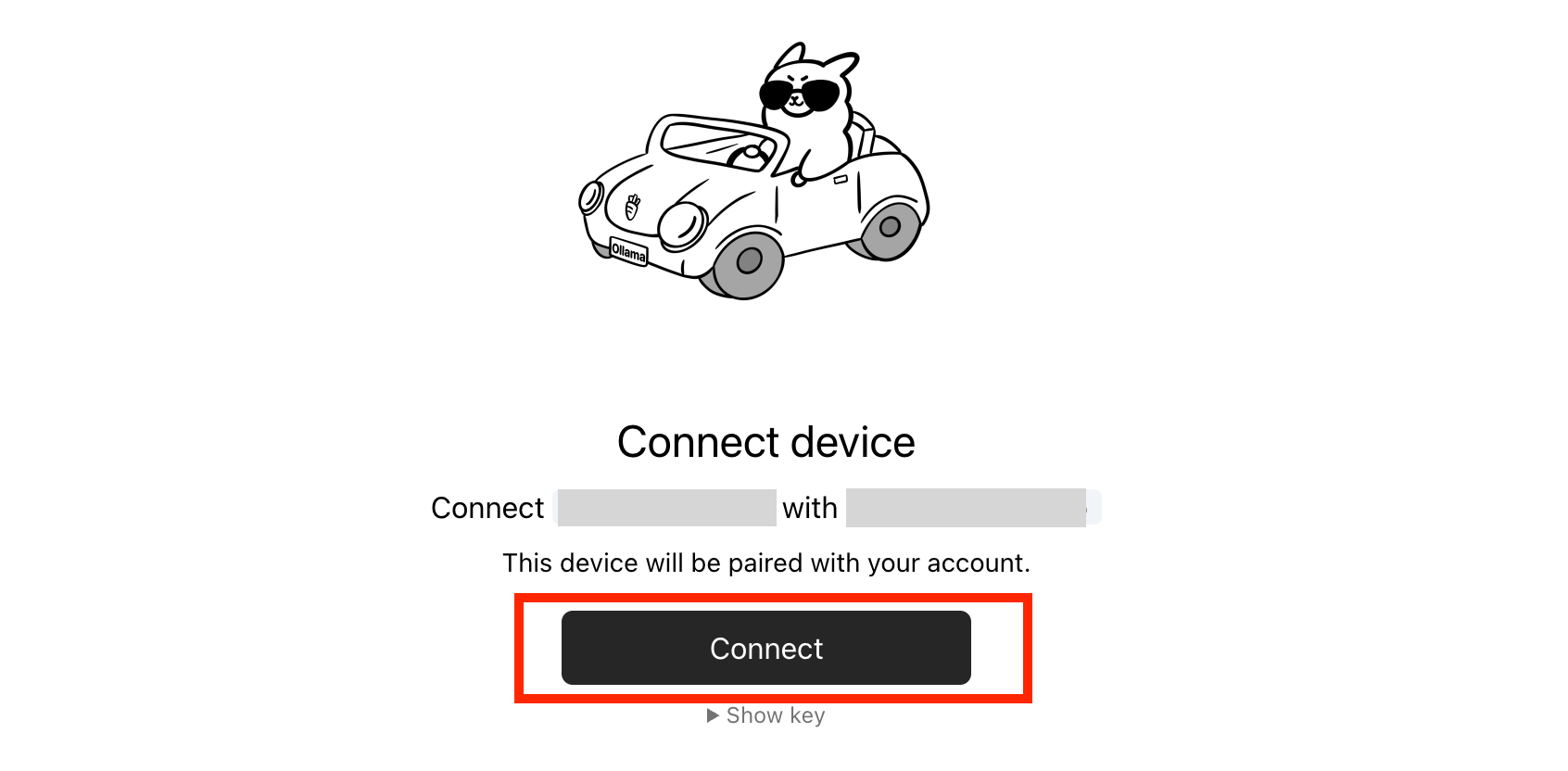
- Connect deviceページに、Connectボタンを押す
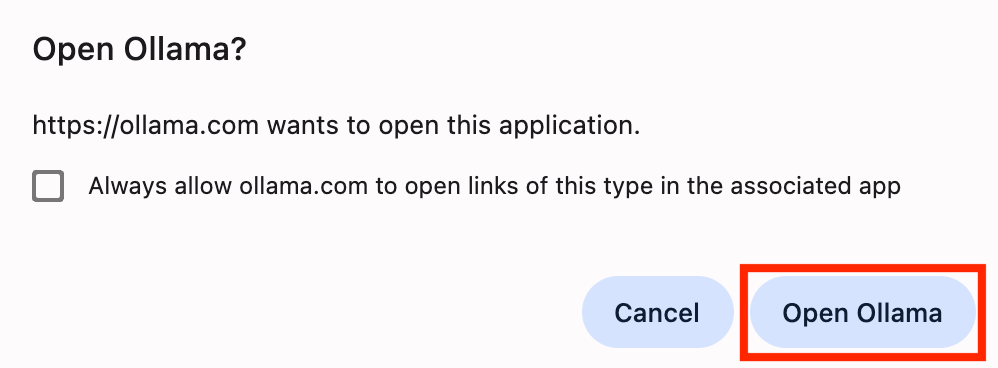
- Open OllamaボタンでOllamaアプリにリダイレクトする
- ログインできたら「xxxをネットで検索してください」と指示すれば検索してくれます
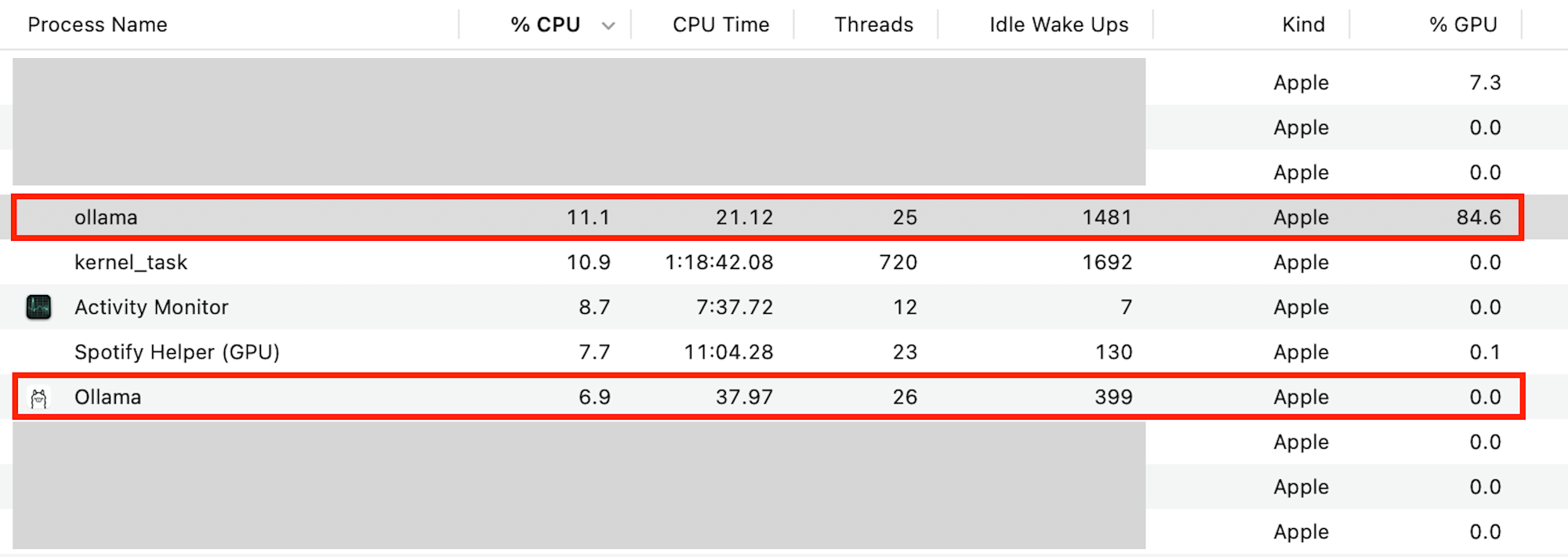
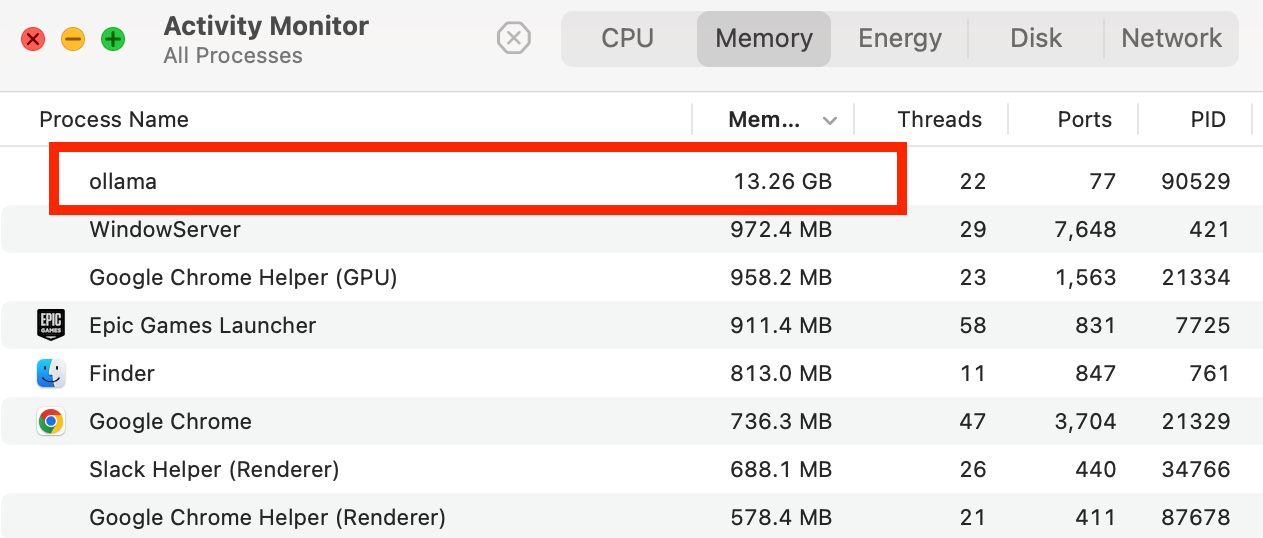
CPU・GPU・メモリの利用状況
- CPU:20%前後 (Ollamaアプリ 10-% + gpt-oss:20b 10+%)
- GPU:80% 〜 90% (最大限に使われる)
- メモリ:13GB+
使ってみた感想
- 基本的にサクサク動いてくれて、普段のQ&Aには利用できる(公式によりますと gpt-oss:20bはo3-miniと同等性能を持つ)
- 簡単な検索指示(例えば:今日東京の天気)は余計に多く検査を行い、結果が出るまでは2分ほどかけてしまって、賢くない印象(推論モデルでしょうがないか...)
以上










