
CSVから始める製造業データ分析:S3 Tablesで差分更新し、Bedrock Knowledge Baseから自然言語でクエリしてみた
製造ビジネステクノロジー部コネクテッドカーチーム、サーバーサイドエンジニアの木村幸介です。
当エントリは クラスメソッド発 製造業 Advent Calendar 2025の24日目のエントリです。
はじめに
製造業の現場データ活用は、理想の姿がさまざまある一方で、いきなり完璧なデータ基盤を作るのは大変です。
一方で、Excelや各種システムから「まずはCSVで出せる」ことは多いので、そこを起点にして段階的に進められないか、というのが今回の話です。
このポストでは、CSV → Athena → S3 Tables(Iceberg) → Amazon Bedrock Knowledge Base(以下、KB。自然言語→SQL)までを最小構成で扱います。
細かい手順やコマンドは サンプルリポジトリのREADME.md にまとめてあるのでそちらをご覧ください。
なお、サンプルとして製造業のQC(品質管理)検査データを題材にしたデータを用意していますが、生成AIが生成した架空のものであり、実在の団体・物品とは関係ありません。
全体像
まずは全体像です。

流れは次のとおりです。
- CSVをS3に置く
- AthenaでCSVを外部テーブルとして読めるようにする
- AthenaでS3 Tables(Icebergテーブル)へMERGEして、状態更新型のデータとして扱えるようにする
- KBから自然言語で問い合わせる(内部ではSQLを組み立てて実行する)
今回の工夫ポイントを補足すると、KB(SQL Knowledge Base)からS3 Tables上のテーブルを参照させる際、Glue Data Catalog側に S3 Tablesカタログを指すResource Link(リソースリンクDB) を作り、KBにはそのResource Link配下のテーブル(例: awsdatacatalog.sample_rl_<stack-name>.<table>)を見せる形にしています。ここが分かると一気に進めやすくなります(本リポジトリではCDKで sample_rl_<stack-name> を作っています)。
なぜこの形にしたか
CSVから始める理由
Excelを含む色々な媒体がCSVエクスポートに対応していて、現場の運用を大きく変えずに始めやすいからです。
「まずはデータを集める」段階ではCSV出力までは詰まりにくいという想定です。
S3 Tablesを使う理由
今回の題材はQC検査データで、日々増えるだけでなく、後から値が補正されたり、マスタの内容が更新されたりします。
IoTの温湿度・圧力のような時系列データは、更新はせずに追記していくパターンが多いと思います。一方で「最新の状態」を見たい場合、追記型のままだと毎回どこかで集計・集約して断面を作る必要が出てきます。
人が見るのが前提のデータだと、そもそも追記型で整っていないことも多いので、最新状態をきちんと持つ側に寄せたいこともあると思います。
今回は、S3 Tables上のIcebergテーブルに対して MERGE で冪等に流し込みできるようにしてあります(同じSQLを何度実行しても同じ状態になる想定)。
KBを使う理由
データを扱う人が全員SQLを書けるとは限りません。
自然言語で「これを知りたい」を投げて、必要に応じてSQLを生成して問い合わせできる入口があると、データ分析のハードルを下げられます。
やってみた
ここからは手順を進めるパートです。詳細は README.md に寄せつつ、つまずきやすいポイントだけ取り上げます。
CDKでデプロイ
まずは依存関係を入れて、CDKをデプロイします。
pnpm install
pnpm cdk deploy
デプロイ後はCloudFormation Outputsに出る値(CSVバケット名、S3 TablesバケットARN、Athena Workgroup名、KB用ロールARNなど)をメモしておきます。
このプロジェクトでは、CDKはS3 Tablesの基盤(TableBucketとNamespace)までを用意し、テーブル作成やスキーマはAthena側のSQLで管理する方針です。
サンプルCSVをアップロード
サンプルCSVをCSVバケットへ置きます。
aws s3 cp sample_csv/ s3://{CsvBucketName}/sample_csv/ --recursive
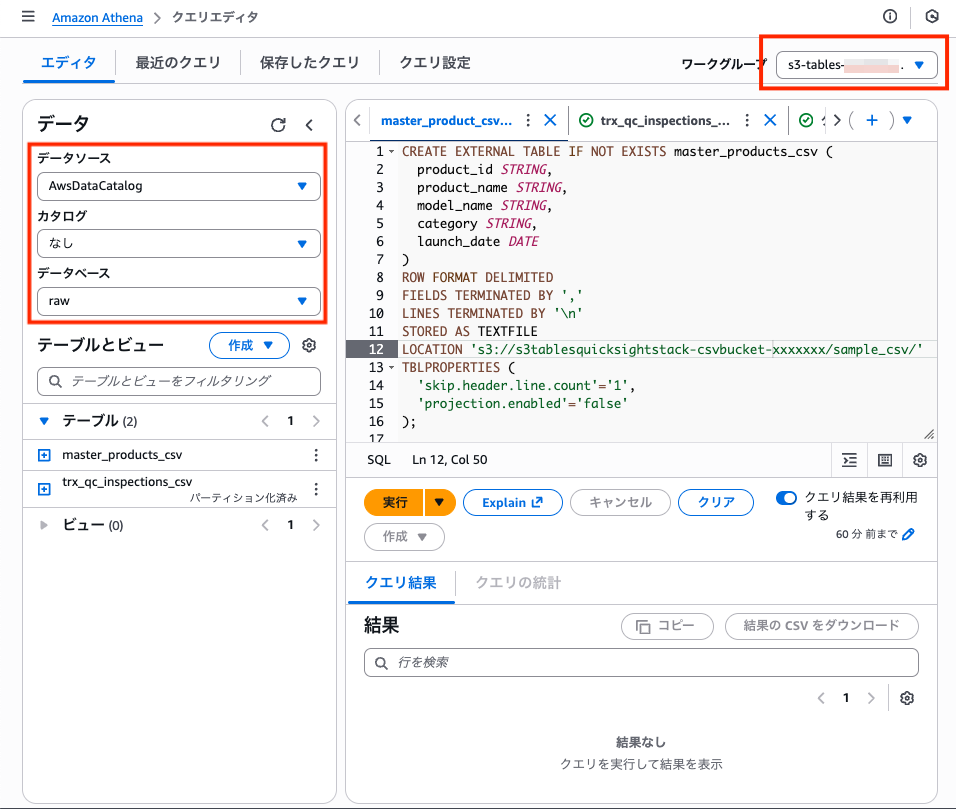
AthenaでCSVを参照する(外部テーブル作成)
Athenaで athena-queries/01-create-external-tables.sql を実行して、CSVを外部テーブルとして参照できるようにします。
このとき、Workgroupとデータカタログの選択を誤ると、参照先が意図したものにならないため注意が必要です。
AthenaでS3 Tablesへ流し込む(スキーマ作成とMERGE)
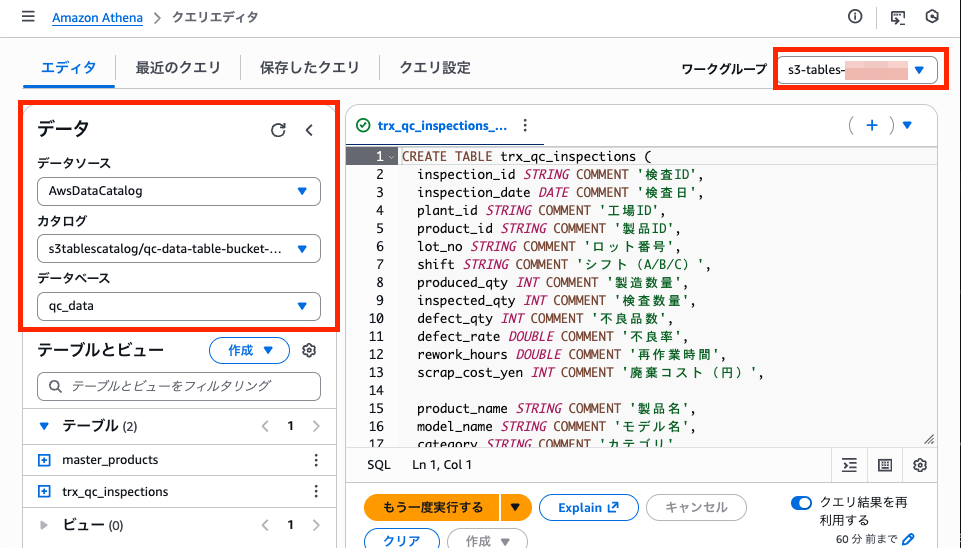
次に athena-queries/00-initialize-s3-tables-schema.sql を初回のみ実行して、S3 Tables上のIcebergテーブルにスキーマを定義します。
続いて athena-queries/02-merge-to-core-layer.sql を実行して、CSV側のデータをS3 Tablesへ MERGE します。
ここも、Workgroupとデータカタログの選択を誤ると、意図しない参照先になりやすいです。
権限周り(Lake Formation / Redshift)
Lake FormationやRedshiftに関連した権限周りは、普段このあたりのリソースを触らない筆者にとって、つまずきやすい点でした。
まずLake Formationでの権限付与が必要です。
aws lakeformation grant-permissions \
--principal "DataLakePrincipalIdentifier=<BedrockKnowledgeBaseRoleArn>" \
--resource '{"Database":{"CatalogId":"<your-account-id>","Name":"sample_rl_<stack-name>"}}' \
--permissions "DESCRIBE"
aws lakeformation grant-permissions \
--principal "DataLakePrincipalIdentifier=<BedrockKnowledgeBaseRoleArn>" \
--resource '{"Table":{"CatalogId":"<your-account-id>:s3tablescatalog/<table-bucket-name>","DatabaseName":"qc_data","TableWildcard":{}}}' \
--permissions "SELECT" "DESCRIBE"
特に前者は、KBのサービスロールがResource Link(GlueのリソースリンクDB)を参照できるようにする設定で、見落としやすいポイントです。Resource LinkのデータベースにDESCRIBEを付与します。加えて、S3 Tables側のテーブルに対しても、同じロールにSELECTとDESCRIBEを付与します。
加えて、Query engineとして使っているRedshift Serverless側でも、IAMR:{KBサービスロール} がクエリできるように権限を付与する必要があります。
aws redshift-data execute-statement \
--workgroup-name <RedshiftWorkgroupName> \
--database dev \
--secret-arn <RedshiftAdminSecretArn> \
--sql 'GRANT USAGE ON DATABASE awsdatacatalog TO "IAMR:<BedrockKnowledgeBaseRoleName>";'
併せてREADME.md の「Lake Formationで権限を付与」「Redshift内でGRANT実行」もご確認ください。
KBの同期
BedrockコンソールでKBを開き、Query engine(Redshift Serverless)の設定を確認してから同期します。
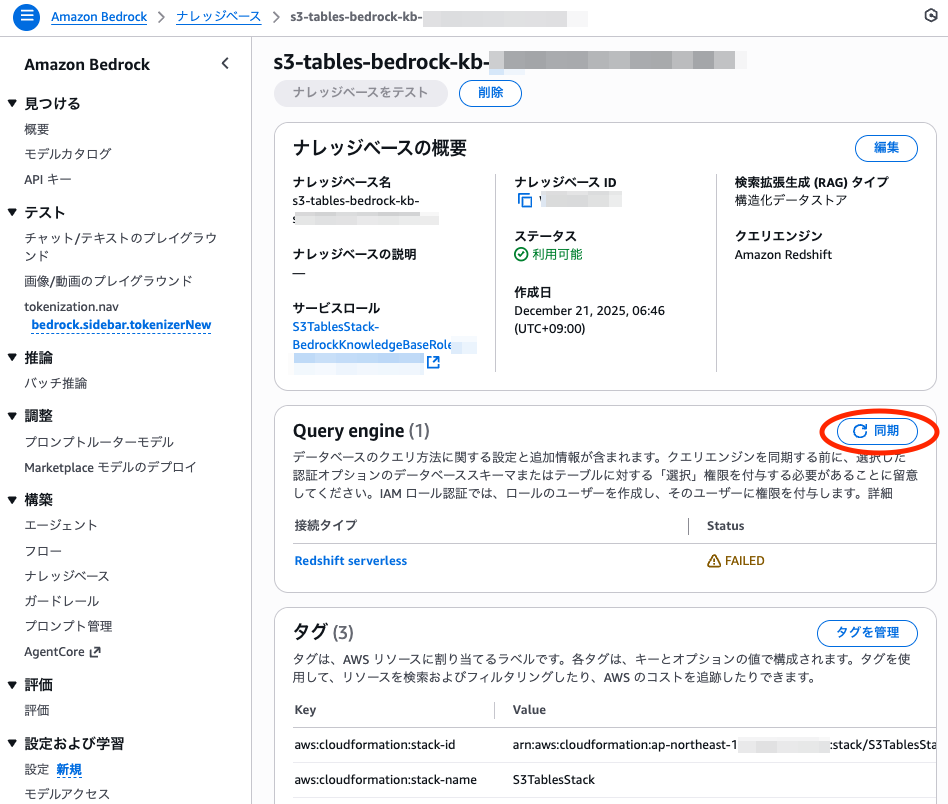
同期が通ったら、自然言語で問い合わせできる状態になっています。
トラブルシュート
同期やテストで、エラーメッセージに AccessDenied / not authorized / is not authorized to perform のような文言が出る場合は、まずKBのサービスロール(Bedrockが引き受けるロール)の信頼ポリシーとIAMポリシーを見直します。ここが崩れていると、後段の設定が正しくても通りません。
database is empty / no databases found のように「中身が空」を示す文言が出る場合は、KBから見えるカタログが空扱いになっている状態を疑います。Lake FormationでResource LinkにDESCRIBE、S3 TablesのテーブルにSELECT/DESCRIBEが付いているか、加えてRedshift側で IAMR:{KBサービスロール} に必要な GRANT が入っているかを確認します。
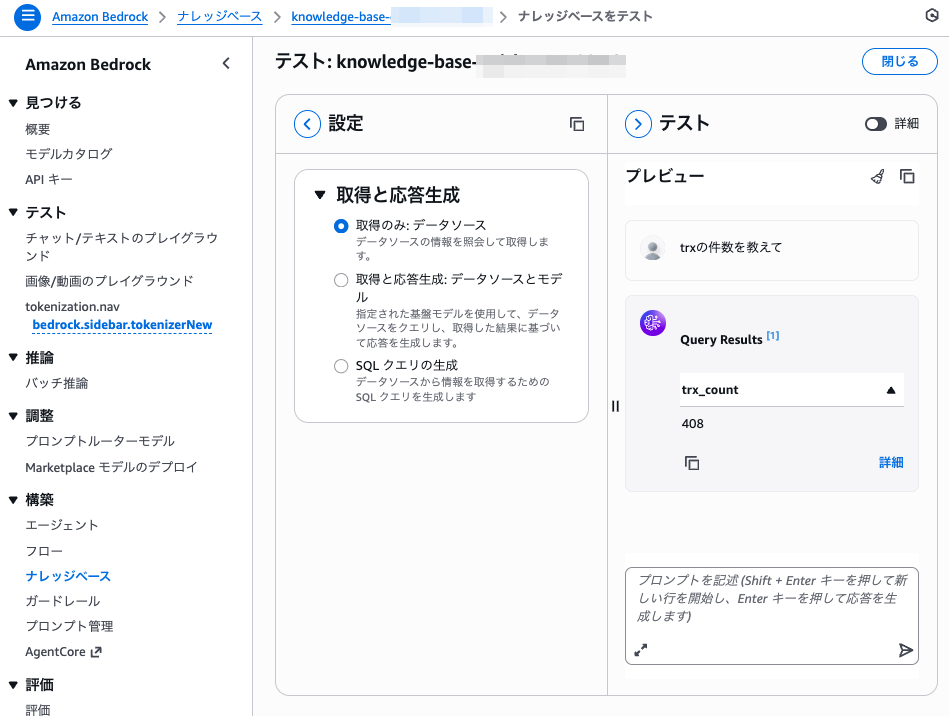
自然言語で聞いてみる
「trxの件数を教えて」のように大まかに聞いても、SQLを組み立てて結果が返ります。
さらに、KB側の「説明」や「内包・除外」の設定を調整していくと、用語や言い回しの揺れ(たとえば略称や言い換え)にも対応しやすくなります。
片付け
試し終わったら削除します。
pnpm cdk destroy
おわりに
Glue / Lake Formation / S3 Tables あたりのデータ系スタックは、カタログ管理と権限管理が複数の層で成り立っており、IAMだけ整えても解決しないことがよくあります。
加えて、マネジメントコンソール上だけだと見通しが立てづらかったり、そもそもコンソールから触れない設定が混ざっていたりして、「気軽に試したい」局面でつまずきやすいです。この記事が、同じところで立ち止まったときの手がかりになれば嬉しいです。









