Snowflake Cortex Analyst の Semantic Model を 1 から自作してみた
こんにちは、データ事業本部のまっきーです。
前回までの記事で、PDF を Snowflake に取り込んで AI_EXTRACT で構造化メタデータを抽出し、Stream + Task で自動化する仕組みを作りました。これで「ドキュメントが届くと document_metadata テーブルに行が増える」状態になっています。
ただ、テーブルに行が増えるだけだと「Snowflake に関する whitepaper を一覧で見たい」「プロダクト別の件数を出して」みたいな自然言語の問い合わせには答えられません。SQL を書ける人にしか使えない仕組みになってしまいます。
そこで今回は、Snowflake Cortex Analyst の Semantic Model(YAML) を 1 から自分で書いて、document_metadata テーブルに対する自然言語問い合わせを動かしてみます。実機で試してみると、YAML を書くだけで動かない質問もあり、改善方法も含めて書き残しておきます。
結論を先に
80 行ほどの YAML を書いて Stage にアップロードしただけで、Snowsight の Cortex Analyst Playground 上で日本語の質問が SQL に変換され、結果テーブルが返ってきました。
LLM の補完が想像以上に強く、YAML を完璧に書かなくても周辺列まで検索を広げてくれる一方で、書き方次第では LLM が「クエリを書けません」と諦める質問もあります。YAML の書き方は試行錯誤前提だと感じました。
Cortex Analyst と Semantic Model が何をしてくれるか
Cortex Analyst は、自然言語の質問を SQL に変換して実行してくれる Snowflake のサービスです。LLM が裏で動いていて、ユーザーの質問を解釈し、テーブルから答えを引き出します。
ただし LLM はテーブル定義を見ただけでは「pub_date が何を意味するか」「amt が金額か数量か」を正確には判断できません。そこで必要になるのが Semantic Model です。
Semantic Model は、テーブルの列に「ビジネス用語との対応」「集計の意味」「日付かカテゴリかメトリクスか」を書き加えた YAML 仕様の定義です。LLM はこの YAML を読んで「ユーザーの質問」を「適切な SQL」に翻訳します。
簡単に言うと LLM に対するテーブルの取説 です。テーブル定義(DDL)が機械向けなら、Semantic Model は LLM 向け、という位置付けになります。
たとえば「Snowflake 関連の whitepaper を一覧で」と日本語で投げると、LLM が Semantic Model を見て WHERE 句や ORDER BY の付いた SQL を組み立て、結果テーブルが返ってくる、という流れになります。
Cortex Search との棲み分け
Snowflake には自然言語で問い合わせる仕組みがもう一つ、Cortex Search があります。棲み分けは以下のとおりです。
| Cortex Search | Cortex Analyst | |
|---|---|---|
| 対象データ | 非構造化テキスト(ドキュメント本文等) | 構造化テーブル |
| 主な質問 | 「~について書かれた文書は?」 | 「~の件数は?」「平均は?」「~でフィルタして一覧」 |
| 内部処理 | ベクトル検索(埋め込み + 類似度) | LLM が SQL を生成して実行 |
| 結果の形 | 関連ドキュメントのリスト | 集計済みテーブル |
「whitepaper の本文を検索したい」なら Cortex Search、「whitepaper のメタデータを集計したい」なら Cortex Analyst、という棲み分けになります。今回扱う document_metadata テーブルは構造化済みのメタデータなので、Cortex Analyst の出番です。
やったこと
前回までのハンズオンで作った document_metadata テーブル(AI_EXTRACT の出力先、Snowflake 公式 whitepaper を 7 件投入済み)に対して、自然言語問い合わせができるようにしました。
具体的なステップは以下のとおりです。
- Semantic Model YAML を置く Stage を作る
document_metadataテーブルの VARIANT 列をフラットなビューに展開する- Semantic Model YAML を 1 から書く(dimensions / time_dimensions / measures の 3 種類を定義)
- YAML を Stage にアップロードする
- Snowsight の Cortex Analyst Playground で自然言語クエリを試す
- うまく変換されないクエリがあれば YAML を改善して再実行する
手順
Step 1: Semantic Model 置き場の Stage を作成
Cortex Analyst は Semantic Model YAML を Stage 経由で読み込みます。専用の Stage を作っておくと、PDF を置く Stage(前回までのハンズオンで作った whitepaper_stage)と分離できて管理しやすくなります。
USE ROLE SYSADMIN;
USE DATABASE makita_doc_ai_db;
USE SCHEMA doc_ai_schema;
USE WAREHOUSE COMPUTE_WH;
CREATE STAGE IF NOT EXISTS semantic_model_stage
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')
DIRECTORY = (ENABLE = TRUE);
SHOW STAGES LIKE 'semantic_model_stage';
専用 Stage にしておく実務的な理由は 2 つあります。1 つは「YAML と PDF が同じ Stage にあると混在して見づらい」こと、もう 1 つは「PDF を置く Stage に Stream を張っていると、YAML を置いた時に Stream が誤動作する可能性がある」こと。後者は地味に重要です。
Step 2: VARIANT 列をフラットなビューに展開
前回のハンズオンで作った document_metadata テーブルは、extracted_data という VARIANT 列に AI_EXTRACT の出力 JSON を格納しています。
SELECT file_name, extracted_data FROM document_metadata LIMIT 1;
Cortex Analyst の Semantic Model は VARIANT 列を直接扱えなくはないですが、最初はフラットなテーブル/ビューを対象にした方が LLM の精度が出やすいです。そこで、JSON のキーを列として展開したビューを 1 つ作ります。
CREATE OR REPLACE VIEW document_metadata_v AS
SELECT
file_name,
file_size,
last_modified,
snowflake_file_url,
extracted_data:title::STRING AS doc_title,
extracted_data:product_name::STRING AS product_name,
extracted_data:target_audience::STRING AS target_audience,
-- 文字列の "None" を NULL 扱いに揃えてから DATE 型へ
TRY_TO_DATE(
NULLIF(extracted_data:publication_date::STRING, 'None')
) AS publication_date,
-- ARRAY をカンマ区切り文字列に展開(Semantic Model 側で扱いやすくするため)
ARRAY_TO_STRING(extracted_data:key_features, ', ') AS key_features,
ARRAY_TO_STRING(extracted_data:use_cases, ', ') AS use_cases
FROM document_metadata;
SELECT * FROM document_metadata_v;
このビューで意識したポイントは 3 つです。
1. ARRAY 型は文字列に展開しておく
key_features や use_cases は AI_EXTRACT の出力で配列になっています。Cortex Analyst の Semantic Model は配列を素直に扱いにくいので、ARRAY_TO_STRING でカンマ区切り文字列に変換しておくと、WHERE use_cases LIKE '%dbt%' のような部分一致クエリが組めるようになります。
2. 日付の "None" 対策に NULLIF + TRY_TO_DATE
AI_EXTRACT は publication_date が見つからないときに文字列 "None" を返すことがあります。普通に ::DATE でキャストするとエラーになるので、まず NULLIF で "None" を NULL に置換し、TRY_TO_DATE で失敗時も NULL を返す形にしています。
なお今回投入した 7 件は、AI_EXTRACT が publication_date を取れず全件 NULL になりました。そのため後述の Semantic Model では publication_date ではなく last_modified(Stage アップロード日時)を時系列軸として使う方針にしています。
3. ベースを VIEW にする利点
Cortex Analyst の Semantic Model は base_table に VIEW を指定できます。元テーブル(VARIANT 列付き)はそのままに、LLM 向けの整形だけ VIEW に閉じ込めると、AI_EXTRACT 側の出力スキーマが変わったときに VIEW だけ直せばよくなります。
このビューを Semantic Model の対象にします。
Step 3: Semantic Model YAML を 1 から書く
Semantic Model の構造は、ざっくり次の 4 要素です。
| 要素 | 役割 |
|---|---|
name / description |
モデル全体の名前と説明(LLM の文脈用) |
tables.dimensions |
カテゴリ系の列(フィルタ・グループ化に使う) |
tables.time_dimensions |
日付系の列(期間フィルタ・時系列分析に使う) |
tables.measures |
集計対象(SUM / COUNT / AVG 等のメトリクス) |
各要素に synonyms(言い換え)を付けることで、ユーザーが投げる自然言語クエリの揺れに対応できます。日本語クエリ対応の鍵がこれです。
実際に書いた YAML がこちらです。
name: document_metadata_semantic
description: |
AI_EXTRACT で抽出した技術ドキュメントのメタデータに対する
自然言語問い合わせ用の Semantic Model。
Snowflake 公式 whitepaper 等を題材とする。
tables:
- name: documents
description: 技術ドキュメント(主に Snowflake 公式 whitepaper)のメタデータ
base_table:
database: makita_doc_ai_db
schema: doc_ai_schema
table: document_metadata_v
dimensions:
- name: file_name
synonyms: [ファイル名, PDF名]
description: Stage にアップロードされた PDF のファイル名
expr: file_name
data_type: VARCHAR
- name: doc_title
synonyms: [タイトル, 文書タイトル]
description: AI_EXTRACT で抽出したドキュメントのタイトル
expr: doc_title
data_type: VARCHAR
- name: product_name
synonyms: [プロダクト, プロダクト名, 製品]
description: ドキュメントが扱うプロダクト名
expr: product_name
data_type: VARCHAR
- name: key_features
synonyms: [主要機能, 機能, 特徴, キーワード]
description: |
ドキュメントで紹介されている主要機能をカンマ区切りで保持。
部分一致検索に使う。
expr: key_features
data_type: VARCHAR
- name: use_cases
synonyms: [ユースケース, 用途, 適用範囲]
description: |
ドキュメントで紹介されているユースケースをカンマ区切りで保持。
部分一致検索に使う。
expr: use_cases
data_type: VARCHAR
time_dimensions:
- name: last_modified
synonyms: [最終更新日, アップロード日時, 追加日]
description: |
ドキュメントが Stage にアップロードされた日時。
AI_EXTRACT 由来の publication_date は欠損が多いため、
時系列分析は last_modified を主軸とする。
expr: last_modified
data_type: TIMESTAMP_NTZ
measures:
- name: document_count
synonyms: [件数, ドキュメント数, 何件]
description: ドキュメントの総件数(file_name のユニーク件数で算出)
expr: file_name
data_type: VARCHAR
default_aggregation: count_distinct
- name: total_file_size
synonyms: [合計サイズ, 合計ファイルサイズ]
description: ファイルサイズの合計(bytes)
expr: file_size
data_type: NUMBER
default_aggregation: sum
- name: average_file_size
synonyms: [平均サイズ, 平均ファイルサイズ]
description: ファイルサイズの平均(bytes)
expr: file_size
data_type: NUMBER
default_aggregation: avg
書きながら理解した重要ポイントを 3 つに整理します。
1. dimensions / time_dimensions / measures の使い分けが LLM の判断材料
列を分類して書いておくことで、LLM が「これはフィルタに使う列」「これは集計対象」と判断できます。今回試した範囲では、同じ NUMBER 型でも ID 列は dimensions、ファイルサイズのように集計したい列は measures に置くのが自然でした。
2. synonyms は日本語クエリ対応の必須要素
列名が英語、ユーザーの質問が日本語、というケースでは synonyms に日本語を入れないとマッチしません。検証で精度が出ない場合の改善ポイントは大抵ここです。
3. description は LLM への補足文
列名やデータ型だけでは伝わらない「業務上の意味」を書きます。例えば last_modified に「時系列分析は last_modified を主軸とする」と書くことで、「最新の」「直近の」といった曖昧な表現を解釈しやすくなります。後述する Step 8 でも、description に明記したことが LLM の挙動に直接効いた事例が出てきます。
Step 4: YAML を Stage にアップロード
Snowsight UI からアップロードするのが手軽です。
- Data > Databases >
makita_doc_ai_db>doc_ai_schema> Stages >semantic_model_stageを開く + Filesボタンからdocument_metadata_semantic.yamlを選択
CLI 派なら PUT file://document_metadata_semantic.yaml @semantic_model_stage でも可です。
アップロード確認:
LIST @semantic_model_stage;
Snowsight の AI & ML > Studio > Cortex Analyst で YAML を選択すると、Semantic Model の構造がパースされて表示されます。
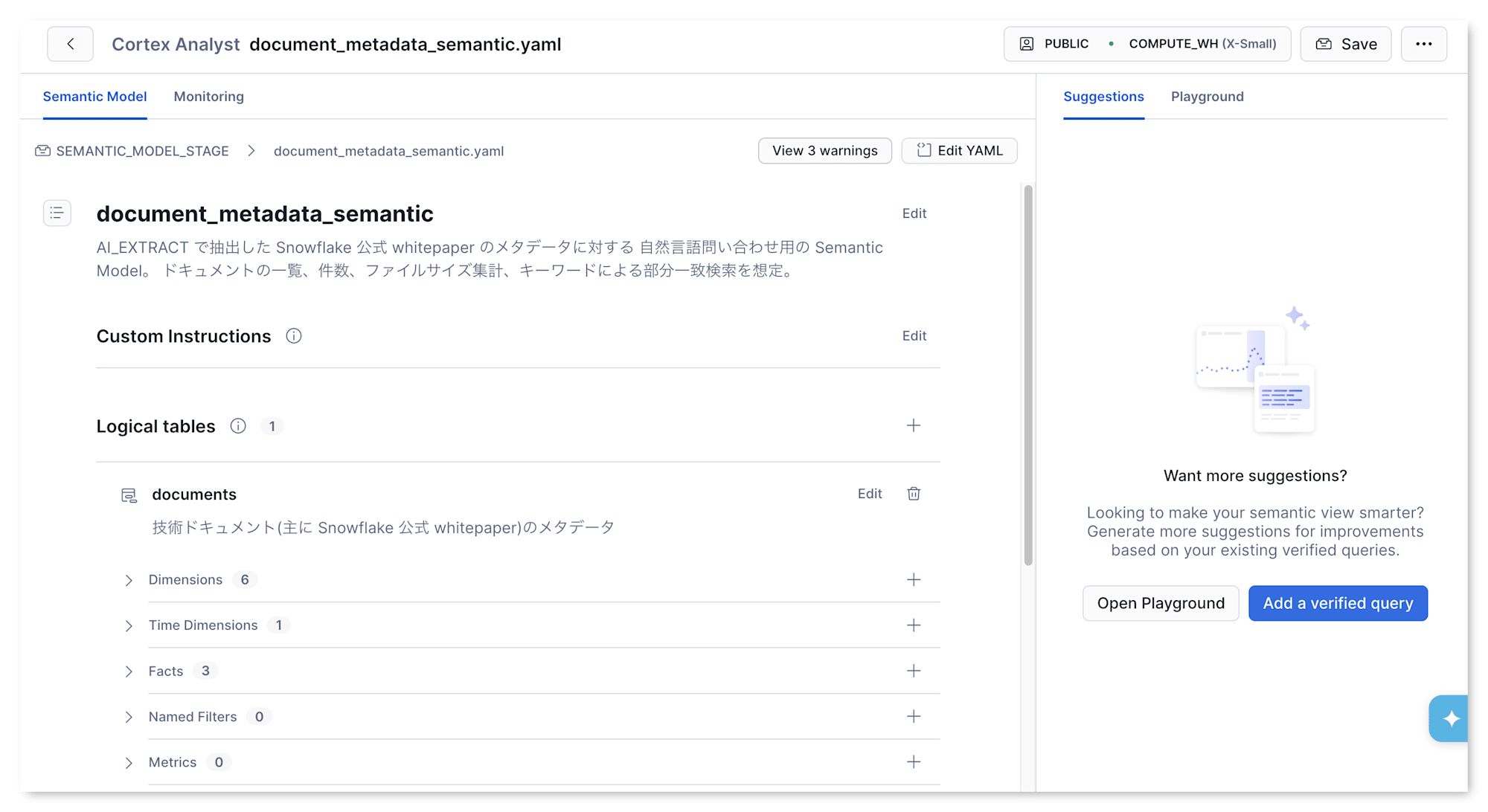
ここで UI 上は Facts という表示になりますが、YAML 上の measures と同じものを指しています。Snowflake のドキュメント内でも measure と fact が混在していて、初見では少し混乱しました。
YAML がパースされて Dimensions / Time Dimensions / Facts の件数が想定通りに認識されていれば準備完了です。構文エラーがあれば画面上部に warning として表示されるので、件数と warning の有無を見れば状態が判断できます。
Step 5: Cortex Analyst Playground で動作確認
Snowsight の Cortex Analyst 画面右側の Playground タブを開き、自然言語クエリを投げます。
ここからは実際に試した質問と返ってきた SQL を順に紹介します。投げた順そのままではなく、印象に残った発見順に並べ替えています。
Step 6: 同じ質問でも SQL が揺れる
検証中に最初に面食らったのは、同じ自然言語クエリを 2 回投げると違う SQL が返ってきたことです。
1 回目「ドキュメントは何件ある?」:
SELECT COUNT(DISTINCT file_name) AS document_count
FROM documents
2 回目(同じ質問):
SELECT
MIN(last_modified) AS start_date,
MAX(last_modified) AS end_date,
COUNT(*) AS document_count
FROM documents
どちらも結果として件数は正しく返ってきたのですが、SQL の形が違います。2 回目は LLM が「件数だけじゃなくデータの期間も親切に添えた方がいい」と判断したように見えます。
これは Cortex Analyst(というより LLM ベースの SQL 生成全般)の宿命で、同じプロンプトでも応答が揺れます。業務に組み込むときは「毎回違う SQL が返る前提で運用設計する」必要があります。
対策として Snowsight 側に Add a verified query(検証済みクエリ)の機能があり、「この質問にはこの SQL を返す」と固定できます。本番運用では、よく投げる質問パターンをここに登録しておくのが現実的だと感じました。
Step 7: 想定以上の推論をしてくれる
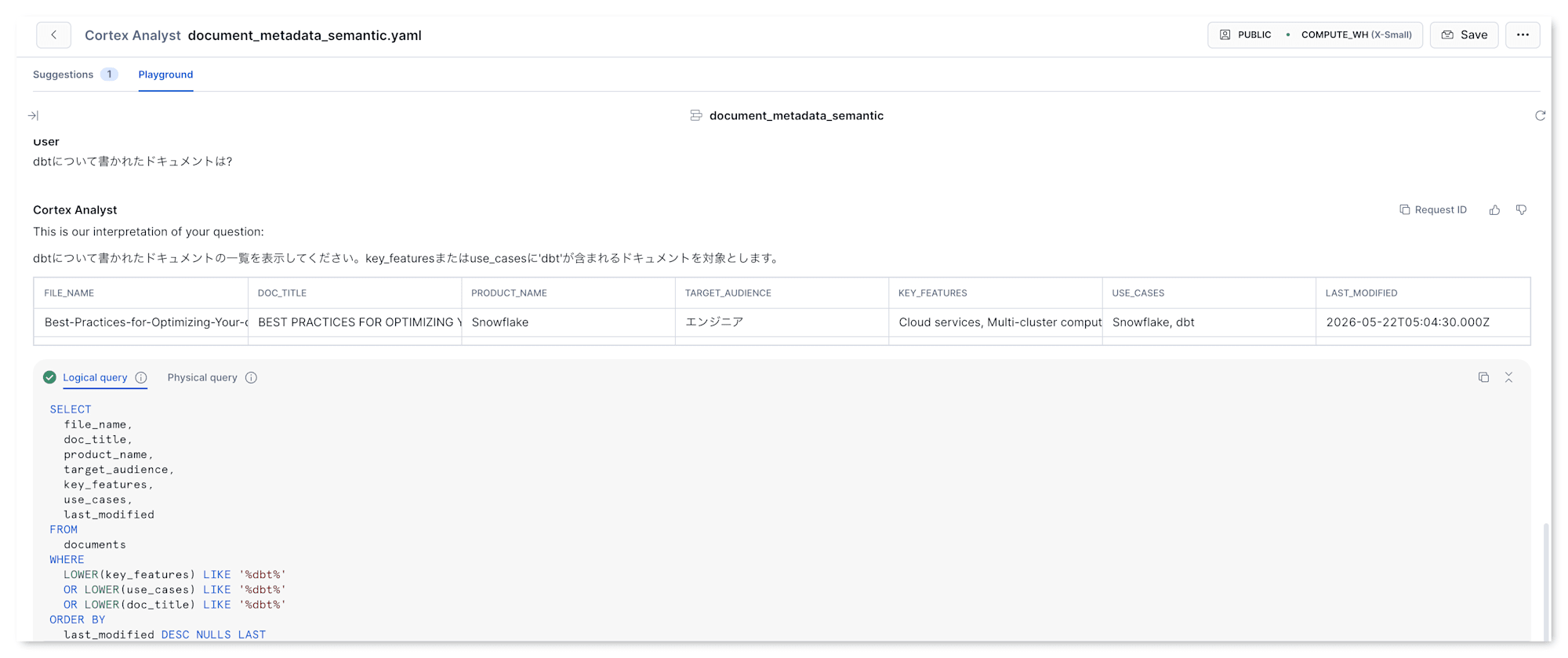
「dbt について書かれたドキュメントは?」と聞いたら、こんな SQL が返ってきました。
SELECT file_name, doc_title, product_name, target_audience,
key_features, use_cases, last_modified
FROM documents
WHERE LOWER(key_features) LIKE '%dbt%'
OR LOWER(use_cases) LIKE '%dbt%'
OR LOWER(doc_title) LIKE '%dbt%'
ORDER BY last_modified DESC NULLS LAST
期待していたのは WHERE key_features LIKE '%dbt%' 程度でしたが、実際は以下の気の利いた変換が入りました。
LOWER(...)で大文字小文字を吸収。投入データの doc_title は... YOUR DBT AND SNOWFLAKE ...のように大文字でしたが、dbtの小文字検索でもヒットしました。doc_titleも検索対象に追加。YAML 上は dbt 検索用に書いていない列ですが、LLM が「タイトルに入っている可能性もある」と推測して OR 条件に加えました。ORDER BY last_modified DESCを自動で付与。「並び順」の指示がない質問に対し、新しい順が親切と判断したようです。
別の単語でも試したくなり、「Security に関する内容のドキュメントは?」と聞いたところ、同じ 3 列 OR + LOWER のパターンで SQL が組まれて 3 件返ってきました。Cortex Analyst が「キーワード検索」の型を覚えてくれていて、別のキーワードでも同じ形の SQL を出してくれたのは、繰り返し使う場面で頼れる挙動だと感じました。
ここから読み取れる学びは、Cortex Analyst では YAML を完璧に書かなくても、LLM が周辺列まで広げて検索してくれる場面が多いということです。AI_EXTRACT の出力が多少揺れても、Semantic Model 側で synonyms と description を丁寧に書いておけば、LLM が周辺の列まで広げて検索してくれます。
逆に言うと、LLM の補完に頼りすぎると挙動の予測が難しくなるので、本番運用では Add a verified query で「この質問にはこの SQL」と固定する設計が要りそうです。
Step 8: 「LLM が書けない」と諦める質問もある
「プロダクト別に件数を教えて」と聞いたら、こう返ってきました。
I apologize, but I couldn't write a query to answer that question.
SQL は返ってこず、Cortex Analyst が潔く諦めた形です。
原因を YAML 側で考えると、document_count measure を最初こう定義していました。
- name: document_count
expr: COUNT(*)
data_type: NUMBER
default_aggregation: count
expr が既に集計式(COUNT(*))になっていて、さらに default_aggregation: count が乗っています。GROUP BY product_name の文脈で扱おうとすると入れ子が崩れる、というのが推測です。
これを以下に変更しました。
- name: document_count
description: ドキュメントの総件数(file_name のユニーク件数で算出)
expr: file_name
data_type: VARCHAR
default_aggregation: count_distinct
ポイントは 2 つです。
exprは列名そのままにし、集計関数はdefault_aggregation側に寄せます。LLM が GROUP BY の文脈で組み立てやすくなります。descriptionに「file_name のユニーク件数で算出」と明記します。LLM はこれをユーザーへの解釈文("This is our interpretation of your question...")にも流用してくれました。
修正後に同じ質問を投げたら、想定通りの SQL が返ってきました。
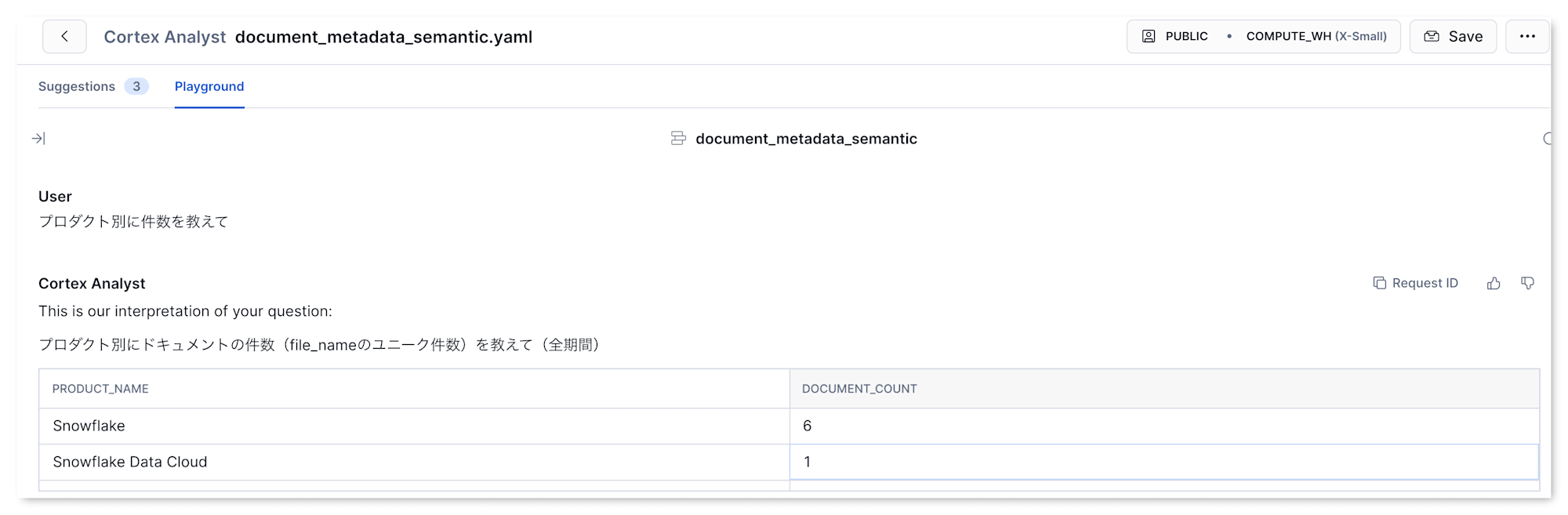
SELECT product_name, COUNT(DISTINCT file_name) AS document_count
FROM documents
GROUP BY product_name
ORDER BY document_count DESC NULLS LAST
結果も意図通り、Snowflake が 6 件、Snowflake Data Cloud が 1 件と分かれて表示されました。
ここで気付いたのは、「LLM が無理に変な SQL を返さず、書けないと明示する」設計になっている点です。予期しない SQL でデータを返されるよりは安心感があります。ただしエラーメッセージから原因を特定しづらい面もあるので、Semantic Model 側で書き方を変えながら試行錯誤するスキルが要りそうです。
Step 9: その他に気付いた挙動
- measure を GROUP BY なしで SELECT する SQL も生成される。たとえば「ファイルサイズが大きい順にトップ3」では、measure として定義した
total_file_sizeを直接 SELECT 句に置く SQL が返ってきました。動作的には問題ありませんでしたが、measure と dimension の境界はやや緩めに扱われている印象です。 - 「直近の」を LIMIT 1 と解釈する。「直近にアップロードされたドキュメントは?」と聞くと、最新タイムスタンプの 1 件しか返ってきません。本来は同じ秒に登録された複数件があっても 1 件しか返さないので、複数件欲しい場合は「最新 5 件」のように件数を明示した方が安全でした。
- synonyms が日本語と英語を相互補完してくれる。「エンジニア向けのドキュメントは?」と聞くと、
target_audienceに対してLIKE '%engineer%' OR LIKE '%エンジニア%' OR LIKE '%developer%' OR LIKE '%開発者%'のように、YAML に書いていない英訳・同義語まで LLM が補ってくれました。 - 生成 SQL の末尾に request_id が埋め込まれる。
/* Generated by Cortex Analyst (request_id: ...) */というコメントが入るので、後で監査ログから追跡できる作りになっています。
ハマったところまとめ
- AI_EXTRACT の出力キーが思っていたのと違った。事前に「主要機能」「ユースケース」のような日本語キーで返ると思って Semantic Model の下書きを作っていましたが、実際は
key_features/use_casesのような英語キーでした。先に VARIANT 列の中身を確認してから VIEW と YAML を書き始めるべきでした。 - publication_date が全件 NULL。AI_EXTRACT が PDF からうまく抽出できなかったため、time_dimensions の動作確認に使えませんでした。
last_modifiedを代わりに使う形に切り替えて回避しています。 measureのexprに集計式を書くと「クエリ書けない」になることがある。Step 8 の事例の通り、expr: COUNT(*)ではなくexpr: file_name+default_aggregation: count_distinctの形にしたら期待通り動きました。
まとめ
80 行ほどの YAML と 1 つの VIEW を準備するだけで、document_metadata テーブルに対する日本語問い合わせが動くようになりました。LLM の補完が想像以上に強い反面、measures の書き方や曖昧な日本語表現の解釈には癖があり、書いて投げて直してを繰り返すフローが前提だと感じました。
業務に乗せる前提では以下が次の論点になりそうです。
Add a verified queryで頻出質問の SQL を固定する運用- VARIANT 列のままでどこまで戦えるか(フラット VIEW を介さない構成)
- 複数テーブルにまたがる Semantic Model を書いた時の精度
次回は、AI_EXTRACT で抽出したメタデータと、PDF 本文を対象にした Cortex Search を組み合わせて、「メタデータでフィルタしつつ本文を検索する」構成を試してみる予定です。








