Profllyを支えるアーキテクチャや技術スタックを紹介します(月刊Proflly2022年2月号)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
新規事業統括部 Profllyチームの持田です。
私達のチームでは、Profllyというプロフィールビューアーサービスを開発・提供しています。
Profllyってなんぞや?と興味を持っていただけた方は、以下のブログや紹介動画をご参照いただけると嬉しいです。
これまでの月刊Profllyのバックナンバーでは、プロダクトに関する最近のアップデートやお客様からのフィードバックなどを中心に紹介してきました。
今回のエントリでは、「ProfllyというSaaSがどのようなアーキテクチャや技術スタックで開発・運用されているのか?」について紹介してみたいと思います。
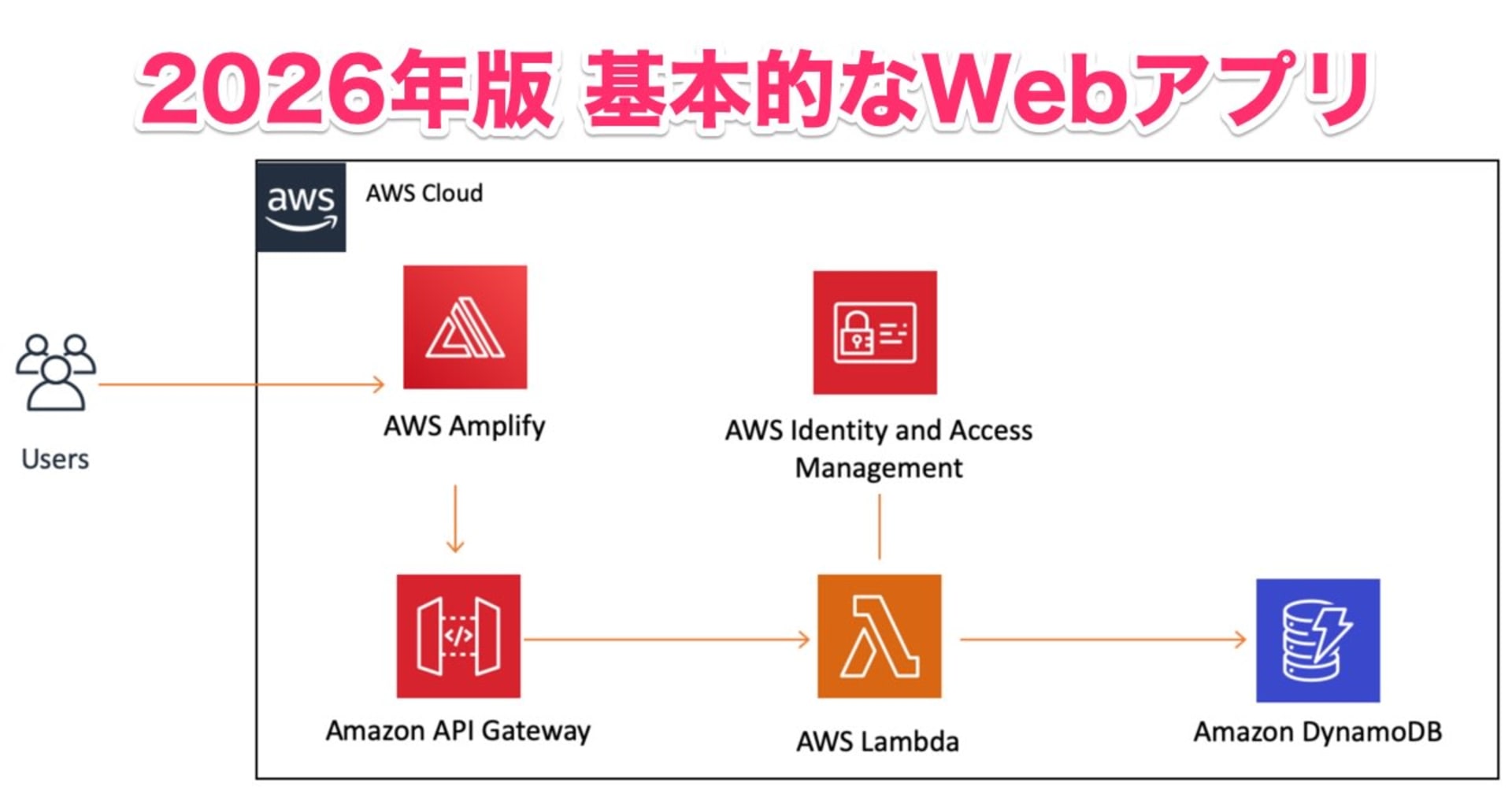
アーキテクチャ全体像

まずはじめに、こちらがProflly全体のアーキテクチャ構成図になります(ユーザー向けのアプリケーション部分を抜粋)。
基本的にインフラはAWSで構成されており、できるだけマネージドサービスを使ったサーバーレスアーキテクチャ構成となっています。
また、プログラミング言語はバックエンド/フロントエンド/インフラ構築(IaC)において全てTypeScriptで統一しています。
次に、それぞれの項目についての技術スタック詳細や選定理由について触れていきます。
なお、Profllyは2019年に企画がスタートしており、大枠の技術スタックについては2019年夏〜秋時点で選定したものを(特に変更や改善を急ぐ必要がないものは)そのまま採用し続けている箇所が多いです。
バックエンド + インフラ
API

バックエンドAPIはAPI Gateway + LambdaによるREST APIとしています。
1 Function/1 Lambda とし、APIリソース数×メソッド数分のLambda関数を作成するベーシックなパターンを採用しています。
言語はTypeScript(Node.js)で、Expressなどのフレームワークは特に利用していません(ミドルウェアエンジンとしてmiddyを採用していたりはします)。
なお、Lambdaのソースコードは、DDDの文脈で言うところのオニオンアーキテクチャに近いような構成にしています(全部に適用できているわけではありませんが。。)。
また、APIドキュメントの管理はapiDocを利用しています。
? 技術選定の理由/この構成にしてよかったこと
企画当時のチーム内の別プロダクトで既にサーバーレスアーキテクチャの利用実績があったことや、スケーラブルなMVPを開発するためにこちらの構成になりました。
Lambdaではなくコンテナサービス(ECS/Fargate)も検討しましたが、コストメリットの観点からLambdaを採用した経緯があります。
2022年2月現在、プロダクト全体で200本近くのLambda Functionがありますが、Lambdaの利用料金は $3/month 程度で収まっています。
? 困っていることや今後の展望
Lambdaを採用しているので、やはりコールドスタートの影響があります。コールドスタートによるパフォーマンス遅延が発生するため、一部ユーザーのUXが悪くなってしまう課題です。
メモリを調整したり、さらに一部のAPIではProvisioned Concurrencyを設定してコールドスタートを回避している箇所もありますが、全体に適用するとコストが跳ね上がってしまうこともあり、現状では一部での利用のみに留めています。
こちらは、パフォーマンス課題やデプロイが遅い問題(後述します)を解決するため、LambdaからApp Runner/Fargateといった別のサービスに移行する、といった対策を検討中です。
データストア

データストアでは、DynamoDB + OpenSearch Service (+ S3)を利用しています。
アプリケーションのデータベースにはDynamoDBを採用し、DynamoDBが苦手とするユースケース(検索や集計など)をOpenSearchでカバーする構成としています。
また、画像ファイルや各種イベント・分析用ログの保管にはS3を利用しています。
? 技術選定の理由/この構成にしてよかったこと
技術選定時(2019年)にはLambda + RDSの組み合わせはあまり相性が良くなかったことと、検索にOpenSearch(当時はElasticsearch)を利用したかったため、このような構成にしています。
プロダクトの性質上、莫大なデータを扱ったり大量のI/Oがあるわけではないので、DynamoDBのコストメリットがあります(ただし、OpenSearch Serviceはインスタンスを立ち上げる必要があるため、圧倒的にお安いLambdaやDynamoDBと比べるとそれなりのコストがかかります)。
DynamoDB -> OpenSearchへのデータ連携はDynamoDB Streamsを利用することで簡単に連携できるので、比較的扱いやすいと感じています。
? 困っていることや今後の展望
(MVP開発時には想定していなかった)大きめの機能が増えるごとにDynamoDBのテーブルが増えてしまう、といった課題があります。
DynamoDBのテーブル設計では、できるだけテーブル数を少なくするというベストプラクティスがありますが、それにあまり則れていない現状があります。
なかなか難しいところではありますが、テーブルを集約するなどの見直しが必要かもしれません。
また、新たにOpenSearchでのクエリが必要になった場合に必要に応じてreindex等を実施していますが、現状ではエンジニアによる手動作業となっているため、うまく自動化できるような仕組みを構築したいところです(トイルの撲滅)。
認証認可

サービスのIDaaSとしては、Auth0を採用しています。
マルチテナント構成とし、1つのAuth0テナントに対してProfllyのテナント分だけAuth0アプリケーション/コネクションを用意するような構成としています。
? 技術選定の理由/この構成にしてよかったこと
管理機能の豊富さや充実したAPI、またデベロッパーフレンドリーなサービスであることが主な選定理由です。
Rules/Actionsのカスタムロジック(Node.js)を使った拡張も容易で、とても便利です。
利用料金はそれなりにかかるものの、それに見合うだけの恩恵を受けることができていると感じています。
? 困っていることや今後の展望
技術選定時はAuth0の日本リージョンが開設されていなかったため、現在までUSリージョンにて利用しています。
現状気になるほど遅くはありませんが、レイテンシーを少しでも抑えるためにプロダクトの利用者が最も多い地域である日本リージョンへの移行を実施したいところです。
また、現状活用しきれていないAuth0の機能(MFAの実装やブランディングなど)も沢山あるので、こちらもうまく活用できるようにしていきたいですね。
ホスティング・CI/CD・インフラ構築(IaC)

ホスティングおよびCI/CDにはAmplify Console (+ GitHub)を採用しています。
Amplify ConsoleとGitHubリポジトリを連携し、CI/CD〜ホスティングまでをまるっとお任せしています。
CI/CDについては、フロントだけでなくバックエンドもAmplify Consoleに載せる形にしています。
また、全体のインフラ構築(IaC)にはAWS CDKを利用しています。CDKの言語はTypeScriptです。
? 技術選定の理由/この構成にしてよかったこと
MVP開発時にはAmplify Consoleが提供する機能で要件を十分満たせそうだったので、Amplify Consoleを活用することにしました。
CI/CDやホスティングをサクッと設定・管理できるので、とても楽ちんです。
また、Route53との連携が容易なので、カスタムドメインを利用したマルチテナント構成の設定や管理もAmplify Console上で簡単に行うことができています。
CDKに関しては、技術選定時にはちょうど正式リリースされたばかりであったものの、TypeScriptでのIaCは型やIDEの恩恵が受けれられることもあり、開発生産性が高いと感じています。
また、プロダクト内はほぼTypeScriptで統一できていることで、フロントエンド/バックエンド/インフラ間でのスイッチングコストが低く抑えられていることも大きいですね。
? 困っていることや今後の展望
現状では、PRレビュー時には開発者ごとにそれぞれの環境でデプロイしていたりするので、今後はAmplify Consoleのプレビュー機能を導入・活用することで、レビューをもう少し効率的にできないかな、と考えています。
また、CDKに関しては関連するリソースが多くCDKのデプロイに時間がかかってしまう(30分以上・・)という課題があります。
こちらはCDKというよりCloudFormationに起因するものですが、Lambdaを採用しているためその分リソース数が増えてしまっているのもデプロイが遅くなっている要因のひとつです。
スタックを分けて並列デプロイするなど最低限の工夫はしているものの、デプロイの遅さは開発速度の低下(=> Developer eXperienceの低下?)やリリースにおけるリスクの増大を招きます。
こちらは、CloudFormationのChangeSetの作成と実行を分離させることでリリースにおけるデプロイを早くしたり、Lambdaをやめるなどリソースそのものを減らすことで高速化を図りたいな、と考えています。
また、機能追加によるリソースの増加によって徐々にCDK内の依存関係が複雑になってきているため、こちらもどこかのタイミングでリファクタリングしたいなーと考えています。
フロントエンド
フレームワーク/ライブラリ

フロントエンドではNuxt.js(Vue.js) + SPAを採用しています。言語はTypeScriptです。
UIライブラリにはVuetifyを利用しており、UIコンポーネントの分割にはAtomic Designの手法を参考にしています。
また、UIデザインのツールはFigmaを使っています。
? 技術選定の理由/この構成にしてよかったこと
企画当時のチーム内の別プロダクトで既にNuxt.jsの利用実績があったりと、開発の立ち上がりが早そうだったのでProfllyでもNuxt.jsを採用しました。
また、技術選定時にはまだデザイナーがアサインされていなかったため、アサイン後のHTMLやCSS設計タスクの移譲しやすさなども考慮しました。
Vuetifyに関しては、(当初のプロダクトに)最低限必要なUIコンポーネントが揃っていたことや、メンテナンスが活発に行われていることを理由に採用しました。
Nuxt.jsではSPAモードを利用することで、フロントエンドとバックエンドの切り分けが明確になり開発・運用がしやすいと感じています。
? 困っていることや今後の展望
SPA(CSR)だとどうしても初回レンダリングに時間がかかってしまうため、多少なりともUXに影響が出てしまっている課題があります。
また、現在はNuxt 2を利用していますが、そろそろNuxt 3が正式リリースされそう(2022年2月18時点ではパブリックベータ)なので、そちらへのアップグレードも検討する必要があります。
SPAをやめるのであれば、いっそのことAmplifyとも相性が良いNext.js + SSRに乗り換えるという選択肢もありますが、Vue.js -> Reactへの移行コストも高く、現時点ではNuxt.jsからNext.jsへ乗り換えるまでの意思決定はできていません。。
この辺りの意思決定については、もう少しチームで議論を進めていきたいところです。
その他技術要素群
今回は紹介しきれなかったものも多数ありますが、参考までにProfllyでは2022年2月時点で以下のような技術要素群を利用しています。
- バックエンド: API Gateway, Lambda, DynamoDB, OpenSearch Service, CloudFront, S3, IAM, SQS, SNS, SES, Pinpoint, Amplify Console, CloudWatch, Lambda Insights, EventBridge, Compute Optimizer, X-Ray, Kinesis Data Firehose, Glue, Athena, WAF, CDK, CodeBuild, (Comprehend), (Amazon Personalize)
- フロントエンド: Vue.js(Nuxt.js), Vuetify, Atomic Design, Figma
- 言語: TypeScript, JavaScript (Auth0 Rules/Actionsのみ)
- その他: GitHub, Slack App, Auth0, google/zx, Google Data Portal, Google Analytics, apiDoc, Cloudflare
おわりに
プロフィールビューアーサービスProfllyにおけるアーキテクチャや技術スタックを紹介しました。
各項目で言及した各種課題や今後の展望など、プロダクトの裏側についてやりたいことや改善していきたいところは無数にあるのですが、正直手が足りていません。。
現在Profllyチームでは、一緒にサービスを成長させていくためのプロダクト開発エンジニアを絶賛募集中ですので、もし興味のある方は以下をご覧いただけると嬉しいです!
ご応募お待ちしております!!